简介
在前面的教程中,我们展示了如何可视化和操作时间序列data,,以及如何利用ARIMA方法从时间序列data](https://andsky.com/tech/tutorials/a-guide-to-time-series-forecasting-with-arima-in-python-3).生成预测我们注意到ARIMA模型的正确参数化可能是一个复杂的手动过程,需要一定的时间。
其他统计编程语言,如R‘提供了[自动ways](https://www.rdocumentation.org/packages/forecast/versions/7.3/topics/auto.arima)]来解决这个问题,但这些语言还没有正式移植到Python语言上。幸运的是,Facebook的核心数据科学团队最近发布了一种名为[Prophet`](https://facebookincubator.github.io/prophet/),的新方法,它使数据分析师和开发人员都可以在Python3中大规模地执行预测。
前提条件
本指南将介绍如何在本地桌面或远程服务器上进行时间序列分析。处理大型数据集可能会占用大量内存,因此在任何一种情况下,计算机都将至少需要2 GB内存 来执行本指南中的一些计算。
在本教程中,我们将使用Jupyter Notebook 来处理数据。如果您还没有,您应该按照我们的[教程]来安装和设置Jupyter Notebook for Python 3](https://andsky.com/tech/tutorials/how-to-set-up-jupyter-notebook-for-python-3).
Step 1 -拉取数据集并安装包
要使用Prophet设置我们的时间序列预测环境,让我们首先进入本地编程环境或基于服务器的编程环境:
1cd environments
1. my_env/bin/activate
从这里开始,让我们为我们的项目创建一个新目录。我们将其命名为timeseries,然后移到目录中。如果您给项目起了不同的名字,请务必在整个指南中用您的名字替换timeseries:
1mkdir timeseries
2cd timeseries
我们将使用Box和Jenkins(1976)Airline Passengers dataset,其中包含1949年至1960年期间每月航空公司乘客数量的时间序列数据。您可以使用带有-O标志的curl命令将输出写入文件并下载CSV来保存数据:
1curl -O https://assets.digitalocean.com/articles/eng_python/prophet/AirPassengers.csv
本教程将需要anda as、matplotlib、numpy、cython和fbpromiet库。与大多数其他Python包一样,我们可以使用pip安装anda as、numpy、cython和matplotlib库:
1pip install pandas matplotlib numpy cython
为了计算它的预测,fbpreset图书馆依赖于STAN‘编程语言,该语言是以数学家[Stanislaw Ulam](https://en.wikipedia.org/wiki/Stanislaw_Ulam).]的名字命名的因此,在安装fbpreset之前,我们需要确保已经安装了STAN的pystan`Python包装器:
1pip install pystan
完成后,我们可以使用pip安装Prophet:
1pip install fbprophet
现在我们都设置好了,我们可以开始使用已安装的包了。
第二步-导入包和加载数据
为了开始使用我们的数据,我们将启动Jupyter Notebook:
1jupyter notebook
要创建新的notebook文件,请在右上方的下拉菜单中选择 新建 > ** Python 3** :
这将打开一个笔记本,允许我们加载所需的库。
作为最佳实践,首先在笔记本顶部导入您将需要的库(请注意用于引用pandas、matplotlib和statsModels的标准速记):
1%matplotlib inline
2import pandas as pd
3from fbprophet import Prophet
4
5import matplotlib.pyplot as plt
6plt.style.use('fivethirtyeight')
注意,我们还为我们的地块定义了FiveThirtyEight`matplotlib‘style。
在本教程中的每个代码块之后,您应该键入ALT+Enter来运行代码,并移到笔记本中的新代码块中。
让我们从读取时间序列数据开始。我们可以加载CSV文件并使用以下命令打印出前5行:
1df = pd.read_csv('AirPassengers.csv')
2
3df.head(5)

我们的DataFrame明显包含了一个Month和AirPassengers列。Prophet库需要一个DataFrame作为输入,其中一列包含时间信息,另一列包含我们希望预测的指标。重要的是,time列应该是datetime类型,所以让我们检查列的类型:
1df.dtypes
1[secondary_label Output]
2Month object
3AirPassengers int64
4dtype: object
因为Month列不是Datetime类型,所以我们需要对其进行转换:
1df['Month'] = pd.DatetimeIndex(df['Month'])
2df.dtypes
1[secondary_label Output]
2Month datetime64[ns]
3AirPassengers int64
4dtype: object
我们现在看到我们的Month列是正确的DateTime类型。
Prophet还强加了严格的条件,必须将输入列命名为ds(时间列)和y(公制列),因此让我们重命名DataFrame中的列:
1df = df.rename(columns={'Month': 'ds',
2 'AirPassengers': 'y'})
3
4df.head(5)

将我们要处理的数据可视化是一种很好的做法,因此让我们绘制时间序列图:
1ax = df.set_index('ds').plot(figsize=(12, 8))
2ax.set_ylabel('Monthly Number of Airline Passengers')
3ax.set_xlabel('Date')
4
5plt.show()

现在我们的数据已经准备好了,我们准备使用Prophet库来产生我们的时间序列的预测。
使用Prophet进行第三步时间序列预测
在本节中,我们将描述如何使用Prophet库来预测时间序列的未来值。Prophet的作者已经抽象出了时间序列预测的许多固有的复杂性,并使分析师和开发人员处理时间序列数据变得更加直观。
首先,我们必须实例化一个新的Prophet对象。Prophet使我们能够指定许多论点。例如,我们可以通过设置Interval_Width参数来指定不确定性区间的期望范围。
1# set the uncertainty interval to 95% (the Prophet default is 80%)
2my_model = Prophet(interval_width=0.95)
既然我们的Prophet模型已经被初始化,我们可以使用DataFrame作为输入来调用它的fit方法。试模时间不应超过几秒钟。
1my_model.fit(df)
您应该会收到类似以下内容的输出:
1[secondary_label Output]
2<fbprophet.forecaster.Prophet at 0x110204080>
为了获得时间序列的预测,我们必须向Prophet提供一个新的DataFrame,其中包含一个保存我们想要预测的日期的ds列。方便的是,我们不必担心手动创建此DataFrame,因为Prophet提供了make_Future_dataframe助手函数:
1future_dates = my_model.make_future_dataframe(periods=36, freq='MS')
2future_dates.tail()

在上面的代码块中,我们指示Prophet在未来生成36个日期戳。
在使用Prophet时,重要的是要考虑我们的时间序列的频率。因为我们使用的是月度数据,所以我们明确指定了时间戳的期望频率(在本例中,MS是月份的开始)。因此,make_Future_dataframe为我们生成了36个月的时间戳。换句话说,我们希望预测3年后我们的时间序列的未来价值。
未来日期的DataFrame然后用作拟合模型的predict方法的输入。
1forecast = my_model.predict(future_dates)
2forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()

Prophet返回一个包含许多有趣列的大型DataFrame,但我们将输出设置为与预测最相关的列,这些列是:
ds:预测值的日期戳yhat:我们指标的预测值(在统计学中,yhat是一个传统上用来表示一个值y的预测值的符号)yhat_lower:我们预测的下限yhat_upper:我们预测的上限
由于Prophet依赖于马尔可夫链蒙特卡罗(MCMC)方法来生成其预测,因此上述产出的值的变化是意料之中的。MCMC是一个随机过程,因此每次的数值都会略有不同。
Prophet还提供了一个方便的功能,可以快速绘制我们预测的结果:
1my_model.plot(forecast,
2 uncertainty=True)
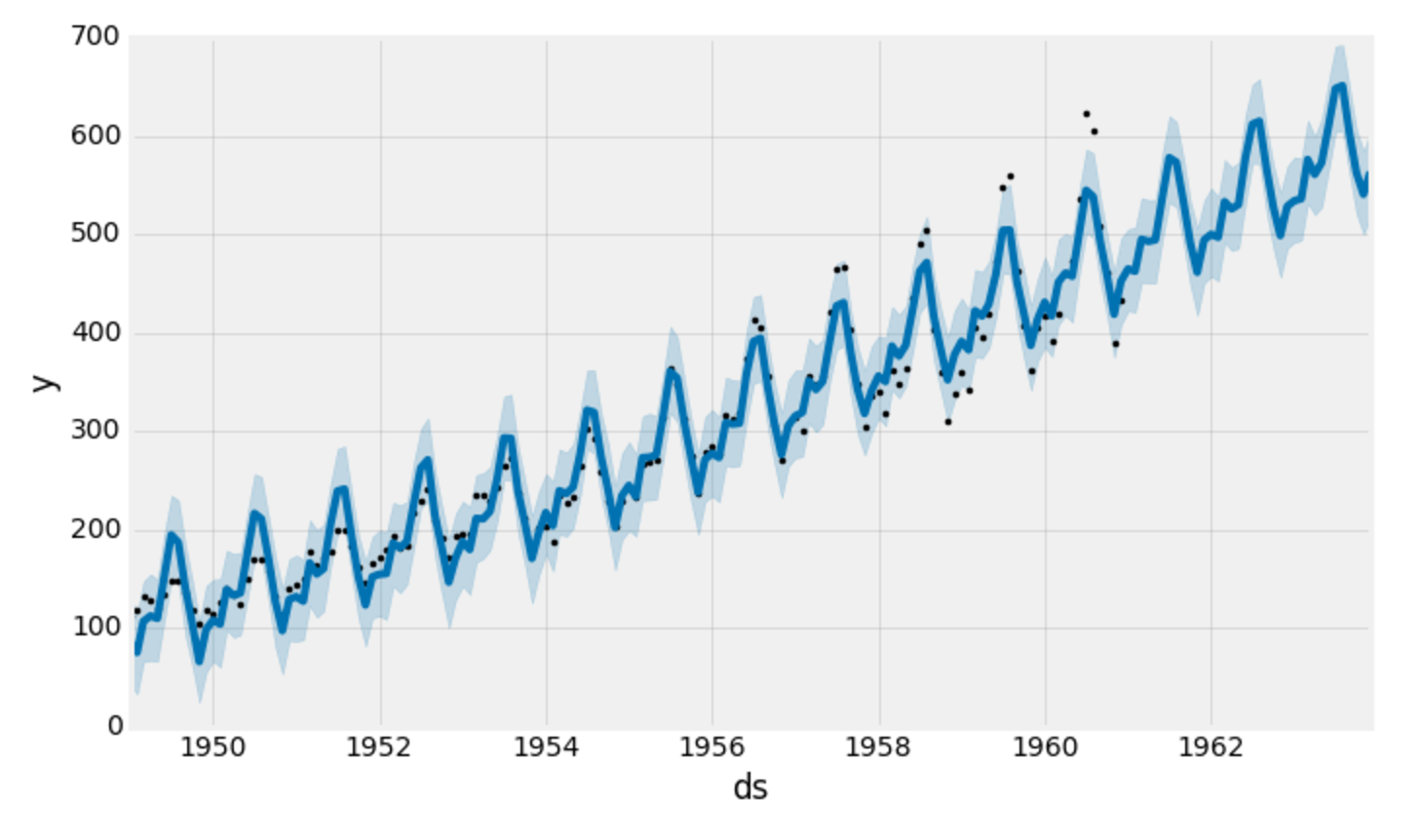
Prophet绘制了时间序列的观测值(黑点)、预测值(蓝线)和预测的不确定区间(蓝色阴影区域)。
Prophet的另一个特别强大的功能是它能够返回我们预测的组成部分。这有助于揭示时间序列的每日、每周和年度模式如何影响总体预测值:
1my_model.plot_components(forecast)
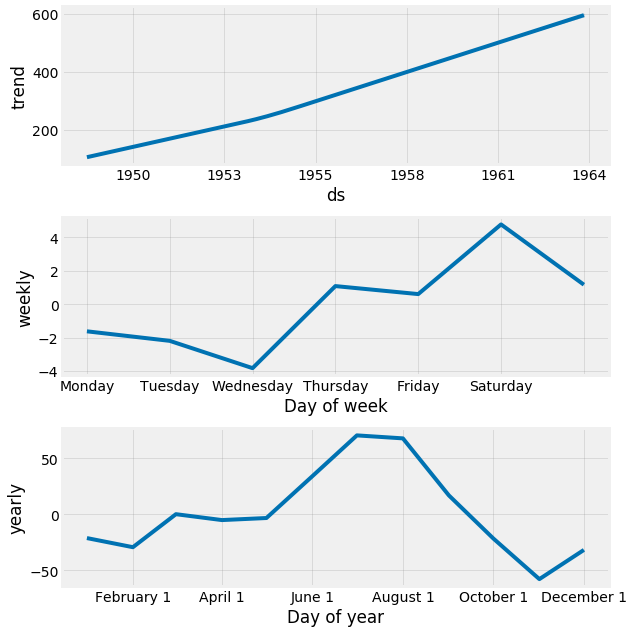 的组件
的组件
上面的情节提供了有趣的见解。第一个图表显示,航空公司每月的客运量随着时间的推移一直呈线性增长。第二个曲线图突出了这样一个事实,即每周的客运量在接近周末和周六时达到峰值,而第三个曲线图显示,最大的客流量出现在7月和8月的假日月份。
结论
在本教程中,我们描述了如何使用Prophet库在Python中执行时间序列预测。我们一直在使用开箱即用的参数,但Prophet使我们能够指定更多的参数。特别是,Prophet提供了将您自己关于时间序列的知识带到桌面上的功能。
以下是你可以尝试的其他一些事情:
- 评估假期的影响,包括您对假日月份的先验知识(例如,我们知道12月份是假日月份)。关于建模holidays的官方文档将会很有帮助。
- 改变不确定性区间的范围,或进一步预测未来。
为了进行更多的实践,您还可以尝试加载另一个时间序列数据集来生成您自己的预测。总体而言,Prophet提供了许多引人注目的功能,包括根据用户的需求定制预测模型的机会。