简介
时间序列分析属于统计学的一个分支,它涉及对有序的、通常是时态的数据的研究。当相关应用时,时间序列分析可以揭示意外趋势,提取有用的统计数据,甚至预测未来的趋势。由于这些原因,它被应用于许多领域,包括经济、天气预报和容量规划,仅举几例。
在本教程中,我们将介绍时间序列分析中使用的一些常见技术,并演练操作、可视化时间序列数据所需的迭代步骤。
前提条件
本指南将介绍如何在本地桌面或远程服务器上进行时间序列分析。处理大型数据集可能会占用大量内存,因此在任何一种情况下,计算机都将至少需要2 GB内存 来执行本指南中的一些计算。
在本教程中,我们将使用Jupyter Notebook 来处理数据。如果您还没有,您应该按照我们的[教程]来安装和设置Jupyter Notebook for Python 3](https://andsky.com/tech/tutorials/how-to-set-up-jupyter-notebook-for-python-3).
第一步-安装包
我们将利用pandas‘库,它在操作数据时提供了很大的灵活性,以及statsModels`库,它允许我们在Python中执行统计计算。结合使用,这两个库扩展了Python以提供更大的功能,并显著增加了我们的分析工具包。
和其他的Python包一样,我们可以用piap安装pandas和statsModels。首先,让我们进入本地编程环境或基于服务器的编程环境:
1cd environments
1. my_env/bin/activate
从这里开始,让我们为我们的项目创建一个新目录。我们将其命名为timeseries,然后移到目录中。如果您给项目起了不同的名字,请务必在整个指南中用您的名字替换timeseries
1mkdir timeseries
2cd timeseries
我们现在可以安装pandas、statsModels和数据绘图包matplotlib.还将安装它们的依赖项:
1pip install pandas statsmodels matplotlib
在这一点上,我们现在已经设置好开始使用熊猫‘和统计模型`。
第二步-加载时间序列数据
为了开始使用我们的数据,我们将启动Jupyter Notebook:
1jupyter notebook
要创建新的笔记本文件,请在右上角的下拉菜单中选择[新建]>[Python3]:
这将打开一个笔记本,允许我们加载所需的库(请注意用于引用pandas、matplotlib和statsModels的标准速记)。在笔记本的顶部,我们应该写下以下内容:
1import pandas as pd
2import statsmodels.api as sm
3import matplotlib.pyplot as plt
在本教程中的每个代码块之后,您应该键入ALT+Enter来运行代码,并移到笔记本中的新代码块中。
方便的是,statsModels带有内置的数据集,因此我们可以将时间序列数据集直接加载到内存中。
我们将使用一个名为来自美国夏威夷莫纳罗亚天文台连续空气样本的大气二氧化碳的数据集,该研究从1958年3月到2001年12月收集了二氧化碳样本。我们可以如下引入这些数据:
1data = sm.datasets.co2.load_pandas()
2co2 = data.data
让我们看看我们的时间序列数据的前5行是什么样子的:
1print(co2.head(5))
1[secondary_label Output]
2 co2
31958-03-29 316.1
41958-04-05 317.3
51958-04-12 317.6
61958-04-19 317.5
71958-04-26 316.4
导入我们的包并准备好二氧化碳数据集后,我们可以继续对数据进行索引。
第三步-使用时间序列数据进行索引
您可能已经注意到,日期已被设置为我们的‘熊猫’数据帧的索引。在使用Python处理时间序列数据时,我们应该确保将日期用作索引,因此确保始终检查日期,这可以通过运行以下命令来实现:
1co2.index
1[secondary_label Output]
2DatetimeIndex(['1958-03-29', '1958-04-05', '1958-04-12', '1958-04-19',
3 '1958-04-26', '1958-05-03', '1958-05-10', '1958-05-17',
4 '1958-05-24', '1958-05-31',
5 ...
6 '2001-10-27', '2001-11-03', '2001-11-10', '2001-11-17',
7 '2001-11-24', '2001-12-01', '2001-12-08', '2001-12-15',
8 '2001-12-22', '2001-12-29'],
9 dtype='datetime64[ns]', length=2284, freq='W-SAT')
dtype=DateTime[ns]字段确认我们的索引是由日期戳对象组成的,而long=2284和freq=‘W-SAT’则告诉我们,从星期六开始,我们有2,284个每周日期戳。
每周数据可能很难处理,所以让我们改用时间序列的月平均值。这可以通过使用方便的resample函数获得,该函数允许我们将时间序列分组为桶(1个月),对每组应用function(平均值),并合并结果(每组一行)。
1y = co2['co2'].resample('MS').mean()
这里的术语MS是指我们按月对数据进行存储桶分组,并确保使用每个月的开始作为时间戳:
1y.head(5)
1[secondary_label Output]
21958-03-01 316.100
31958-04-01 317.200
41958-05-01 317.120
51958-06-01 315.800
61958-07-01 315.625
7Freq: MS, Name: co2, dtype: float64
熊猫的一个有趣功能是它能够处理日期戳索引,这让我们可以快速地对数据进行切片。例如,我们可以对我们的数据集进行切片,以仅检索来自年份`1990‘之后的数据点:
1y['1990':]
1[secondary_label Output]
21990-01-01 353.650
31990-02-01 354.650
4 ...
52001-11-01 369.375
62001-12-01 371.020
7Freq: MS, Name: co2, dtype: float64
或者,我们可以对我们的数据集进行切片,以仅检索1995年10月到1996年10月之间的数据点:
1y['1995-10-01':'1996-10-01']
1[secondary_label Output]
21995-10-01 357.850
31995-11-01 359.475
41995-12-01 360.700
51996-01-01 362.025
61996-02-01 363.175
71996-03-01 364.060
81996-04-01 364.700
91996-05-01 365.325
101996-06-01 364.880
111996-07-01 363.475
121996-08-01 361.320
131996-09-01 359.400
141996-10-01 359.625
15Freq: MS, Name: co2, dtype: float64
为处理时态数据而对数据进行了适当的索引后,我们可以继续处理可能丢失的值。
第四步-处理时序数据中的缺失值
现实世界的数据往往是凌乱的。正如我们从曲线图中看到的那样,时间序列数据包含缺失值的情况并不少见。检查这些数据的最简单方法是直接绘制数据,或者使用下面的命令显示输出中缺少的数据:
1y.isnull().sum()
1[secondary_label Output]
25
这个输出告诉我们,在我们的时间序列中有5个月的缺失值。
一般来说,我们应该)`command](https://andsky.com/tech/tutorials/an-introduction-to-the-pandas-package-and-its-data-structures-in-python-3# handling-missing-values).来实现这一点为了简单起见,我们可以用时间序列中最接近的非空值来填充缺失的值,尽管需要注意的是,滚动平均值有时更可取。
1y = y.fillna(y.bfill())
填充了缺少的值后,我们可以再次检查是否存在任何空值,以确保我们的操作有效:
1y.isnull().sum()
1[secondary_label Output]
20
在执行这些操作之后,我们看到我们已经成功地填充了时间序列中的所有缺失值。
第五步-可视化时间序列数据
在处理时间序列数据时,通过可视化可以揭示很多信息。需要注意的几点是:
- 季节性 :数据是否有明显的周期性?
- 趋势 :数据是一致的上行还是下行?
- 噪声 :是否有与其他数据不一致的离群点或缺失值?
我们可以使用matplotlib接口的anda as包装器来显示我们的数据集的绘图:
1y.plot(figsize=(15, 6))
2plt.show()
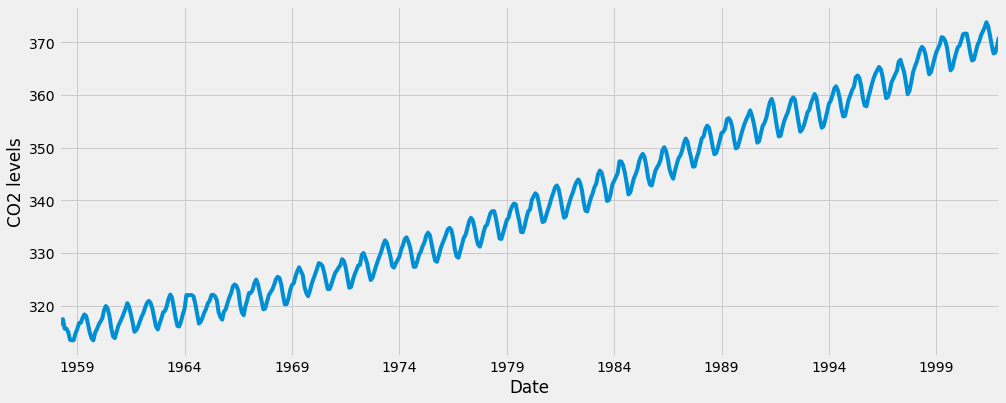
当我们绘制数据时,会出现一些可区分的模式。时间序列具有明显的季节性特征,总体呈上升趋势。我们还可以使用一种称为时间序列分解的方法来可视化数据。顾名思义,时间序列分解允许我们将时间序列分解成三个不同的组成部分:趋势、季节性和噪声。
幸运的是,statsModels提供了方便的季节性_分解函数来执行开箱即用的季节分解。如果您有兴趣了解更多信息,其原始实现的参考可以在下面的文章中找到,[stl:基于Loess](http://www.wessa.net/download/stl.pdf).的季节性趋势分解过程
下面的脚本展示了如何在Python中执行时间序列的季节分解。默认情况下,季节性_分解返回一个相对较小的数字,因此此代码块的前两行确保输出的数字足够大,可以让我们可视化。
1from pylab import rcParams
2rcParams['figure.figsize'] = 11, 9
3
4decomposition = sm.tsa.seasonal_decompose(y, model='additive')
5fig = decomposition.plot()
6plt.show()
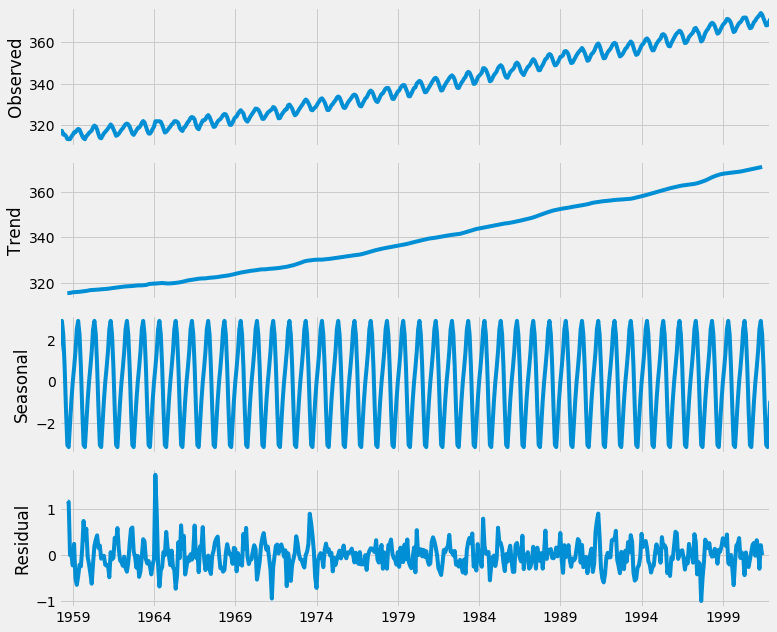
使用时间序列分解可以更容易地快速识别数据中不断变化的平均值或变化。上面的图表清楚地显示了我们的数据的上升趋势,以及它的年度季节性。这些可以用来理解我们时间序列的结构。时间序列分解背后的直觉很重要,因为许多预测方法都建立在这种结构化分解的概念上来产生预测。
结论
如果您已经按照本指南进行了操作,那么您现在已经有了在Python中可视化和操作时间序列数据的经验。
为了进一步提高技能,您可以加载另一个数据集并重复本教程中的所有步骤。例如,您可能希望使用pandas库读取CSV文件,或者使用statsmodels库中预装的sunspots数据集:data = sm.datasets.sunspots.load_pandas().data。