介绍
GraphQL 是 API 的查询语言,也是用现有数据来填写这些查询的运行时间。
它简化了随着时间的推移,并允许强大的开发工具. 在本指南中,我们将看看GraphQL的优点和缺点,以便您可以自己决定它是否适合您的项目。
如果您正在尋找一個 GraphQL 安裝指南,我們有教程,涵蓋使用 GraphQL with Ruby on Rails和 GraphQL with Node.js。
精确数据捕获
不能夸大GraphQL精确数据采集功能的重要性和有用性. 使用GraphQL,您可以向API发送查询,并获得您所需要的,不多也不少。
GraphQL 可通过根据客户端应用程序的需求对数据进行选择性来最大限度地减少通过线程传输的数据量,因此,移动客户端可以获取更少的信息,因为它可能不需要在小屏幕上,而不是对于 Web 应用程序的更大屏幕。
因此,而不是返回固定数据结构的多个终端点,GraphQL服务器只暴露一个终端点,并用客户端要求的数据来响应。
考虑一个情况,你想调用一个 API 终端,它有两个资源,艺术家和他们的曲目。
为了能够要求一个特定的艺术家或他们的音乐曲目,你将有一个API结构,如下:
1METHOD /api/:resource:/:id:
使用传统的 REST 模式,如果我们要使用所提供的 API 查找每个艺术家的列表,我们将不得不这样向根源资源终端发送 GET 请求:
1GET /api/artists
如果我们想从艺术家列表中查询一个单独的艺术家呢?那么我们将不得不像这样将资源ID附加到终端:
1GET /api/artists/1
基本上,我们必须调用两个不同的终端来获取所需的数据. 使用 GraphQL,每个请求都可以在一个终端执行,采取的操作和返回的数据都被定义在查询本身。
1GET /api?query={ artists(id:"1") { track, duration } }
此查询指示 API 查找具有 1 的 ID 的艺术家,然后返回其轨迹和持续时间,这正是我们想要的,既不多也不少。
一个要求,很多资源
GraphQL 的另一个有用的功能是,它可以简单地通过一个单一的请求获取所有所需的数据,而 GraphQL 服务器的结构允许声明性地获取数据,因为它只暴露一个终端点。
考虑一个用户想要请求特定艺术家的详细信息的情况,比如姓名,ID,轨迹等. 使用传统的REST直观模式,这将需要至少两个请求到两个终端点 /artists 和 /tracks。
1// the query request
2
3artists(id: "1") {
4 id
5 name
6 avatarUrl
7 tracks(limit: 2) {
8 name
9 urlSlug
10 }
11}
在这里,我们定义了一个单一的 GraphQL 查询来请求多个资源(艺术家和曲目)。
1// the query result
2{
3 "data": {
4 "artists": {
5 "id": "1",
6 "name": "Michael Jackson",
7 "avatarUrl": "https://artistsdb.com/artist/1",
8 "tracks": [
9 {
10 "name": "Heal the world",
11 "urlSlug": "heal-the-world"
12 },
13 {
14 "name": "Thriller",
15 "urlSlug": "thriller"
16 }
17 ]
18 }
19 }
20}
正如上面的响应数据所示,我们通过单个 API 调用收集了/artists和/tracks的资源,这是 GraphQL 提供的强大功能。
现代兼容性
现代应用程序现在是内置的全面的方式,其中一个后端应用程序提供运行多个客户端所需的数据。Web应用程序,移动应用程序,智能屏幕,手表等现在只能依赖一个后端应用程序,以便数据有效地运作。
GraphQL 拥抱了这些新趋势,因为它可以用来连接后端应用程序并满足每个客户端的要求(嵌入的数据关系,只收集所需的数据,网络使用要求等),而无需为每个客户端分配单独的 API。
大多数情况下,为了做到这一点,后端将被分解为多种具有不同的功能的微服务,这样,通过我们称之为 schema stitching,可以轻松地将特定功能分配给微服务。
之后,您可以使用架构缝合来将所有单个架构组织成一个通用架构,然后可以由每个客户端应用程序访问。最终,每个微服务都可以有自己的 GraphQL 端点,而一个 GraphQL API 网关将所有架构整合成一个全球架构,使其可供客户端应用程序使用。
为了演示图案缝,让我们考虑到Sakho Stubailo(https://blog.apollographql.com/@stubailo)在解释我们有两个相关API的缝时使用的相同情况。
首先,通过Universe API,我们可以获取有关特定事件ID的详细信息:
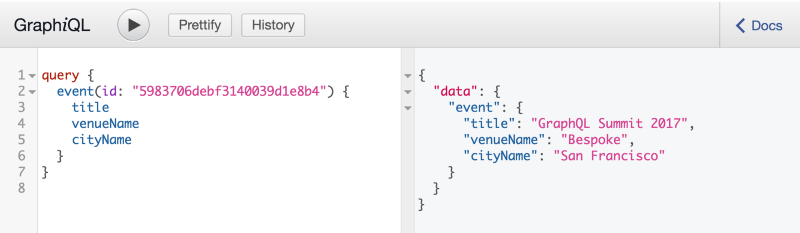
使用黑天天气API,我们可以获得相同位置的细节:
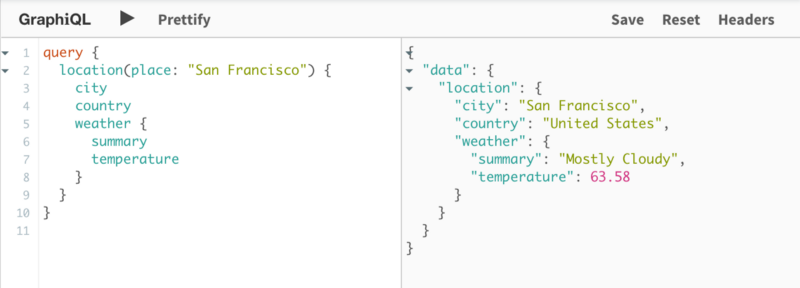
现在使用 GraphQL 架构缝合,我们可以做一个操作来合并这两个架构,以便我们可以轻松地将这两个查询并行发送:
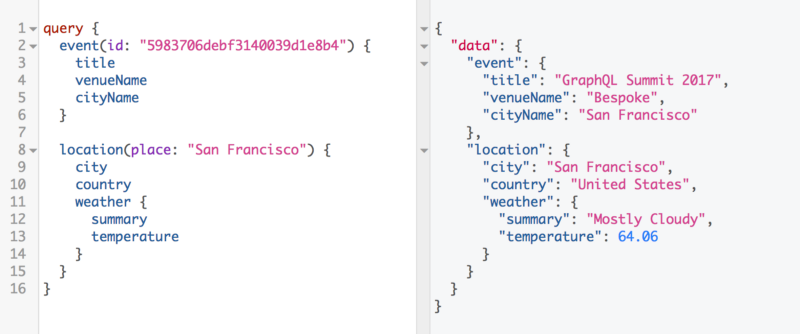
您可以仔细看看Sashko Stubailo的 GraphQL 方案缝制以更深入地了解相关概念。
通过这种方式,GraphQL可以将不同的方案合并为一个通用方案,让所有客户都能从那里获得资源,轻松地接受新的现代开发风格。
地面水平下降
作为开发人员,我们习惯了调用不同的API版本,并经常得到非常奇怪的响应。传统上,当我们对资源或我们目前所拥有的资源结构进行更改时,我们会版本API,因此需要削减和发展新版本。
例如,我们可以有一个API,如api.domain.com/resources/v1,在后几个月或几年中,会发生一些变化,资源或资源的结构会发生变化,因此,下一个最好的事情是将这个API演变为api.domain.com/resources/v2以捕捉所有最近的变化。
在此时,v1中的某些资源将被贬值(或暂时保持活跃,直到用户迁移到新版本),并在收到这些资源的请求时,将收到意想不到的响应,如贬值通知。
在 GraphQL 中,可以在一个字段级别上删除 API。当某个特定字段被删除时,客户端在查询该字段时会收到删除警告。
因此,而不是完全版本化API,它可以随着时间的推移逐步发展API,而无需重组整个API方案。
缓存
缓存是数据的存储,以便未来对该数据的请求可以更快地进行服务;缓存中存储的数据可能是先前计算的结果或其他地方存储的数据的重复。
在 REST 中,您可以使用 URL 访问资源,因此您可以在资源级别内缓存,因为您有资源 URL 作为标识符。
在一个查询中,您可能只对一个艺术家的名字感兴趣,但是在下一个查询中,您可能想要获取艺术家的曲目和发布日期。
也就是说,GraphQL社区认识到这种困难,并且一直在努力让GraphQL用户更容易缓存。像Prisma和Dataloader这样的库(建立在GraphQL上)已经开发了以帮助类似的场景。
想要的表演
GraphQL为客户提供了执行查询的权力,以获得他们需要的内容,这是一个令人惊叹的功能,但这可能有点有争议,因为这也意味着用户可以在他们想要的资源中要求尽可能多的字段。
例如,用户定义了一个查询,该查询要求列出对特定艺术家的所有曲目发表评论的所有用户。
1artist(id: '1') {
2 id
3 name
4 tracks {
5 id
6 title
7 comments {
8 text
9 date
10 user {
11 id
12 name
13 }
14 }
15 }
16}
这个查询可能会获得数万个数据的响应。
因此,尽管允许用户在一定程度上要求他们需要的任何东西是件好事,但类似的请求可能会降低性能,并极大地影响GraphQL应用程序的效率。
对于复杂的查询,REST API可能更容易设计,因为您可以为特定需求设有多个终端,而对于每个终端,您可以定义特定查询以有效地检索数据。
数据错误
正如我们之前在构建与GraphQL在后端时所示的那样,您的数据库和GraphQL API通常会具有相似但不同的方案,这些方案会转化为不同的文档结构。 因此,来自数据库的跟踪将具有跟踪属性,而通过您的API获取的相同的跟踪将有客户端的跟踪属性。
考虑在客户端上找到特定曲目的艺术家的名字,它会看起来像这样:
1const getArtistNameInClient = track => {
2 return artist.user.name
3}
然而,在服务器侧做同样的事情会导致完全不同的代码:
1const getArtistNameInServer = track => {
2 const trackArtist = Users.findOne(track.userId)
3 return trackArtist.name
4}
通过扩展,这意味着你错过了GraphQL在服务器上的数据查询的绝佳方法。幸运的是,这不是没有修复的。 事实证明,你可以运行服务器对服务器的GraphQL查询,只是很好。
1const result = await graphql(executableSchema, query, {}, context, variables);
根据Sesha Greif(https://medium.freecodecamp.org/@sachagreif),重要的是不只是将GraphQL视为纯粹的客户端服务器协议,GraphQL可以在任何情况下查询数据,包括客户端与Apollo链接状态(https://github.com/apollographql/apollo-link-state),甚至在静态构建过程中使用Gatsby(https://www.gatsbyjs.org/)。
方案相似
当您在后端使用 GraphQL 构建时,您似乎无法避免重复和代码重复,特别是当涉及到方案时,首先,您需要您的数据库和您的 GraphQL 终端的方案;这涉及类似但不完全相同的代码,特别是当涉及到方案时。
您需要定期为您的计划编写非常相似的代码是足够困难的,但更令人沮丧的是,您还必须不断保持它们的同步。
显然,其他开发人员已经注意到这种困难,到目前为止,GraphQL社区已经努力修复它,这里是我们发现的两个最流行的修复:
- PostGraphile会从您的 PostgreSQL 数据库中生成 GraphQL 方案,以及
- Prisma还会帮助您生成查询和突变类型。
结论
GraphQL是一个令人兴奋的新技术,但在做出昂贵和重要的架构决策之前,重要的是要了解这些交易。一些API,例如具有很少实体和跨实体的关系,如 _analytics API,可能不适合 GraphQL。
GraphQL是一个强大的工具,在您的项目中选择它有很多原因,但不要忘记,最重要的,而且往往是最好的选择是选择哪个工具是正确的项目考虑。
如果您正在尋找一個 GraphQL 安裝指南,我們有教程,涵蓋使用 GraphQL with Ruby on Rails和 GraphQL with Node.js。