介绍
数据库管理系统(DBMS)是允许用户与数据库互动的计算机程序,DBMS允许用户控制访问数据库,写数据,运行查询,并执行与数据库管理相关的任何其他任务。
然而,为了执行这些任务,DBMS必须有某种基础模型来定义数据是如何组织的。 relational model 是组织数据的一种方法,自从它最初在1960年代末发明以来,它在数据库软件中得到广泛应用,因此,到目前为止,四个最受欢迎的五个DBMS(https://db-engines.com/en/ranking)是关系式的。
本概念文章概述了关系模型的历史、关系数据库如何组织数据以及今天如何使用数据。
关系模型的历史
数据库是逻辑上建模的信息集群,或 data. 任何数据集都是数据库,无论它是如何或在哪里存储的。 即使包含工资信息的文件柜也是数据库,就像是一堆医院病人表格一样,或者是一家公司的客户信息集分布在多个位置。
大约在20世纪中叶,计算机科学的发展导致了具有更多处理能力的机器,以及更大的本地和外部存储容量,这些进步促使计算机科学家开始认识到这些机器存储和管理越来越大的数据量的潜力。
但是,对于计算机如何以有意义的、逻辑的方式组织数据,没有任何理论。在机器上存储未分类的数据是一回事,但设计允许您以一致的、实用的方式添加、检索、排序和管理数据的系统更为复杂。
一个早期的数据库模型是 hierarchical model,其中数据被组织成类似树的结构,类似于现代文件系统。
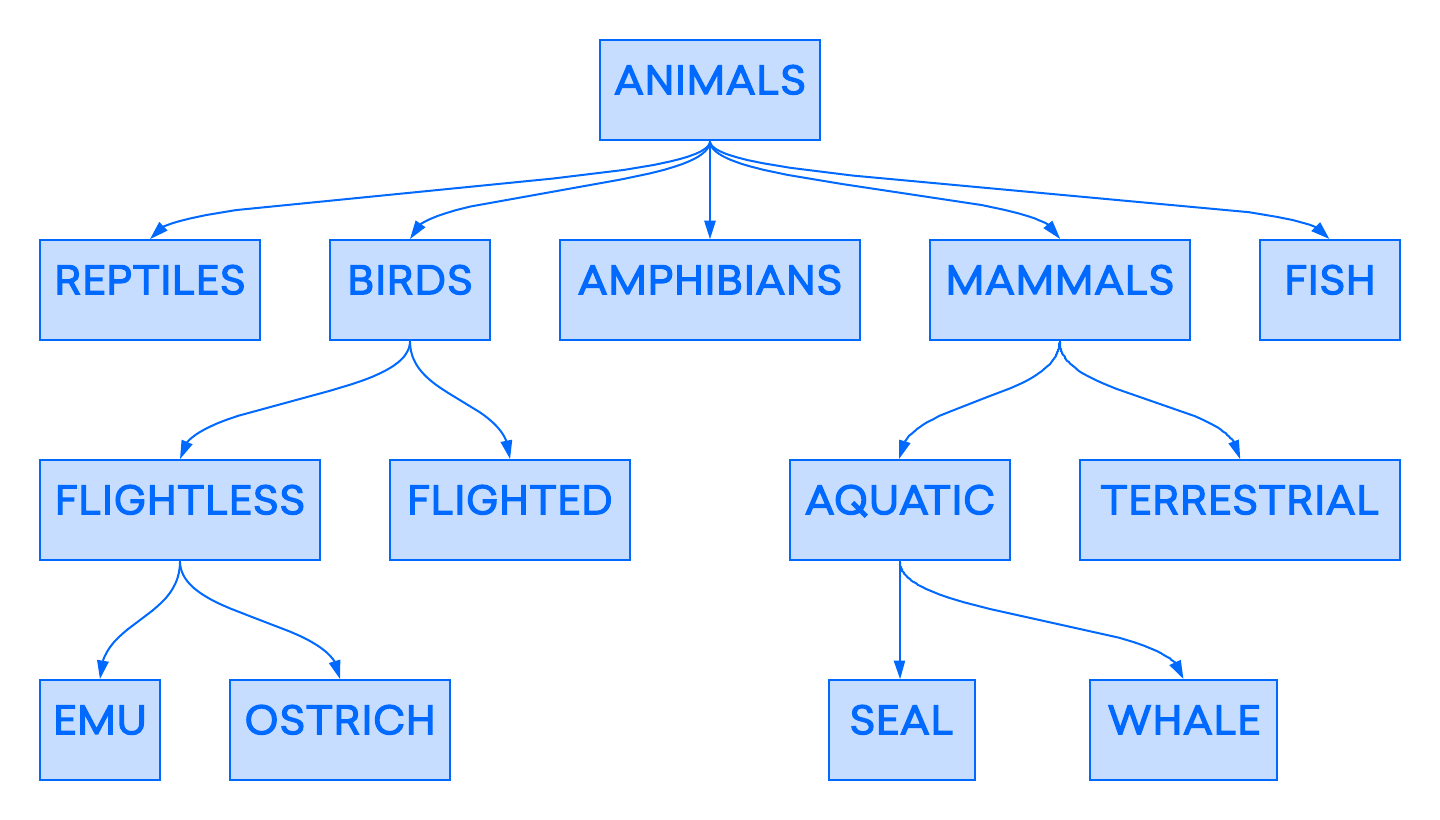
该等级模型在早期数据库管理系统中被广泛应用,但它也被证明有些不灵活. 在这个模型中,尽管单个记录可能有多个孩子,但每个记录在等级中只能有一个父母。
在1960年代末,IBM的计算机科学家Edgar F. Codd设计了数据库管理的关系模型,Codd的关系模型允许单个记录与多个表相关联,从而允许数据点之间的多对多关系以及一对多关系,这提供了比其他现有模型更大的灵活性来设计数据库结构,这意味着关系数据库管理系统(RDBMS)可以满足更广泛的业务需求。
Codd 提出了一种用于管理关系数据的语言,称之为 Alpha,这影响了后来的数据库语言的发展。 科德的两位IBM同事,唐纳德·切伯林和雷蒙德·博伊斯,创建了一种由阿尔法启发的语言。
由于硬件的限制,早期关系数据库仍然非常缓慢,并且需要一段时间才能将该技术广泛应用,但是到20世纪80年代中期,科德的关系模型已经被应用于一系列来自IBM和其竞争对手的商业数据库管理产品中。这些供应商也通过开发和实施自己的SQL方言来跟随IBM。
关系模型在多个行业的广泛使用导致它成为数据管理的标准模型,即使在最近几年出现了各种NoSQL数据库(https://andsky.com/tech/tutorials/a-comparison-of-nosql-database-management-systems-and-models),关系数据库仍然是存储和组织数据的主要工具。
关系数据库如何组织数据
现在,你对关系模型的历史有了一般的了解,让我们仔细看看模型如何组织数据。
关系模型中最基本的元素是 relations,用户和现代的 RDBMS 将其识别为 tables. A relationship is a set of tuples, or rows in a table, with each tuple sharing a set of attributes, or columns:
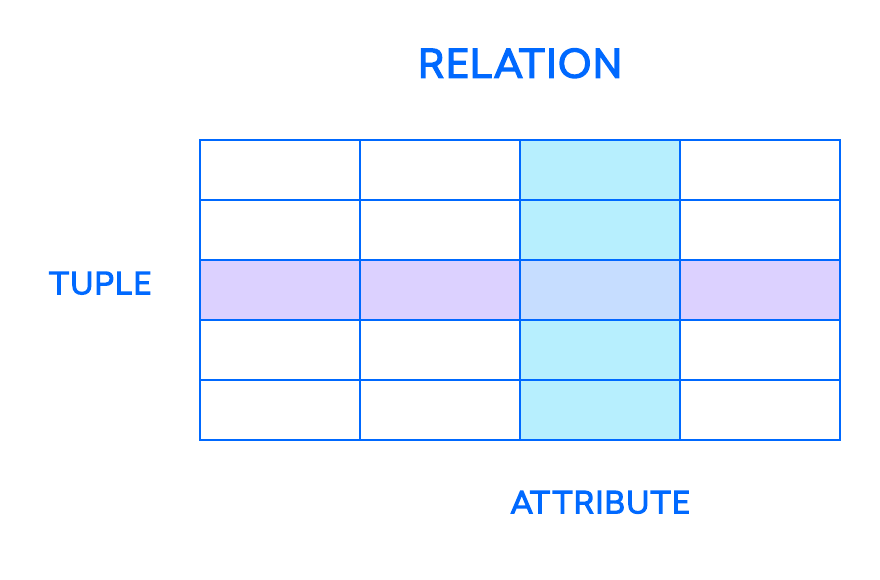
一个列是关系数据库中最小的组织结构,它代表了表中定义记录的各个方面,因此其更正式的名称、属性。你可以将每个 tuple 视为任何类型的人、对象、事件或协会的独特实例。这些实例可能是公司员工、在线业务的销售或实验室测试结果等。例如,在一所学校的教师员工记录的表中, tuples 可能具有名称、主题、开始日期等属性。
当创建列时,您指定一个 data type 来决定该列允许哪些类型的条目。RDBMS 通常会实施自己的独特数据类型,这些类型可能无法直接与其他系统中的类似数据类型交换。
在关系模型中,每个表至少包含一个列,可以用来独特地识别每个行,称为 primary key. 这很重要,因为这意味着用户不需要知道他们的数据在机器上物理存储在哪里;相反,他们的DBMS可以跟踪每个记录并以特定方式返回它们。
如果你有两个表,你想彼此关联,你可以这样做的一种方式是使用一个 foreign key. 外部密钥基本上是将一个表(父母表)的主要密钥插入另一个表(孩子)的列的副本。
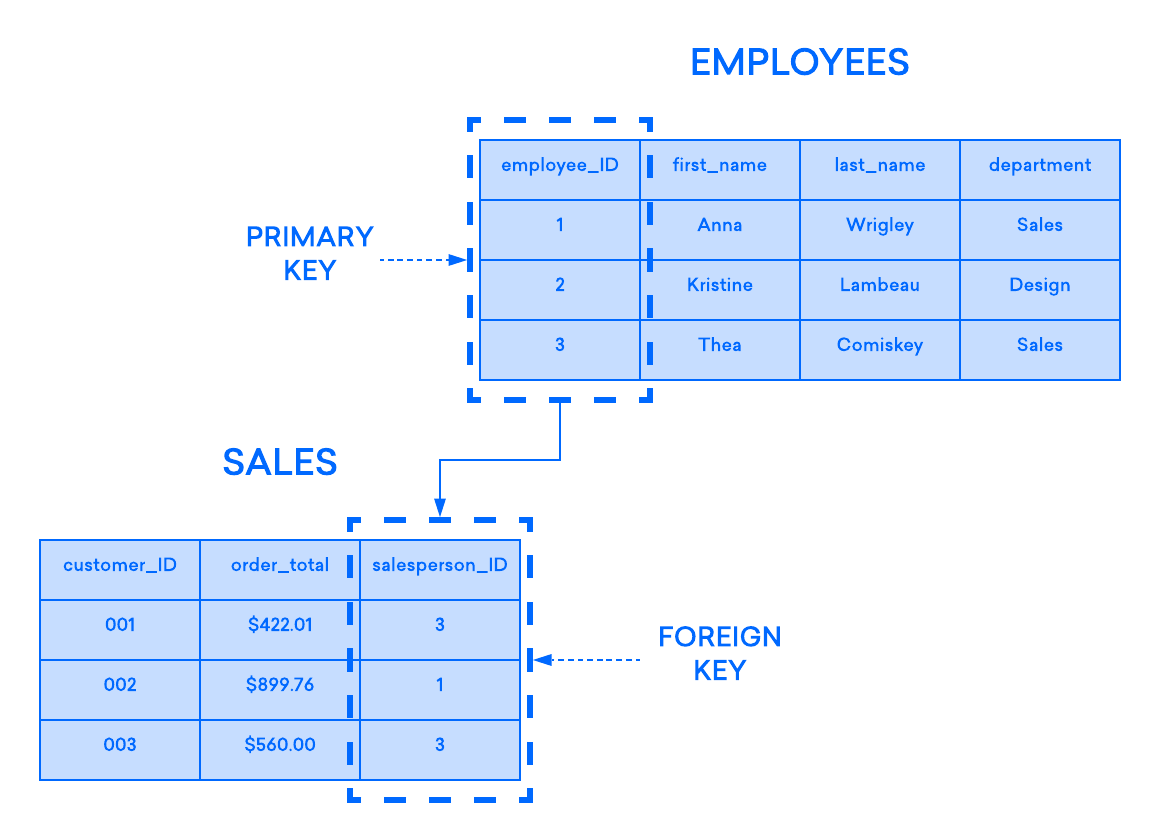
如果您尝试将记录添加到子表中,而输入到外部密钥列中的值不存在于母表的主要密钥中,插入声明将无效,这有助于保持关系级别的完整性,因为两个表中的行将始终正确相关。
关系模型的结构元素有助于以有组织的方式存储数据,但存储数据只有在您可以获取数据时才有用。 从 RDBMS 获取信息时,您可以发出 query 或对一组信息的结构化请求。
关系数据库的优势和局限性
考虑到关系数据库的潜在组织结构,让我们考虑一下它们的一些优点和缺点。
例如,科德的模型规定表中的每个行应该是独一无二的,而为了实用性,大多数现代的关系数据库允许重复的行。有些数据库不认为SQL数据库是真正的关系数据库,如果它们不遵守Codd的关系模型规格。
尽管关系数据库的普及迅速增长,但由于数据变得更有价值,关系模型的几个缺点开始变得显而易见,并且企业开始存储更多的数据库,首先,将关系数据库水平扩展可能很难。 Horizontal scaling,或 escaling out,是将更多的机器添加到现有的堆栈,以便分散负载,并允许更多的流量和更快的处理。
如果你要在多个机器上横向扩展一个关系数据库,那么很难确保一致性,因为客户端可以将数据写入一个节点,而不是其他节点。
RDBMS提出的另一个局限性是,关系模型旨在管理结构化数据,或与预定义数据类型一致的数据,或者至少是以某种预定义的方式组织的数据,使其易于分类和搜索。
这一切都不是说关系数据库没有用处,相反,关系模型在40多年后仍然是数据管理的主要框架。它们的普及性和寿命意味着关系数据库是一个成熟的技术,这本身就是它们的主要优势之一。有许多应用程序旨在与关系模型合作,以及许多职业数据库管理员,他们是关系数据库的专家。在印刷和在线中,对于那些希望开始使用关系数据库的人来说,也有广泛的资源。
关系数据库的另一个优点是,几乎每个 RDBMS 都支持 _transactions。 一个交易由一个或多个单独的 SQL 陈述组成,以单一的工作单位顺序执行。
最后,关系数据库非常灵活. 它们已经被用来构建各种不同的应用程序,并继续高效工作,即使有非常大的数据量. SQL 也是非常强大的,允许您随时添加和更改数据,以及改变数据库方案和表的结构,而不会影响现有数据。
结论
由于它们的灵活性和数据完整性设计,关系数据库仍然是管理和存储数据的主要方式,超过50年后,它们最初被设计了,即使在近年来各种NoSQL数据库的兴起,了解关系模型和如何使用RDBMS是任何想要构建利用数据力量的应用程序的关键。
要了解更多关于一些流行的开源 RDBMS,我们鼓励您查看 我们对各种开源关系 SQL 数据库的比较。