介绍
对于数据驱动的应用程序和网站,重要的是以确保其数据的安全性和完整性的方式进行扩展。
在这篇概念文章中,我们将讨论一个这样的数据库架构:sharded databases。sharding近年来一直受到很多关注,但许多人没有清楚地了解它是什么或在哪些情况下它可能有意义的数据库sharding。
什么是sharding?
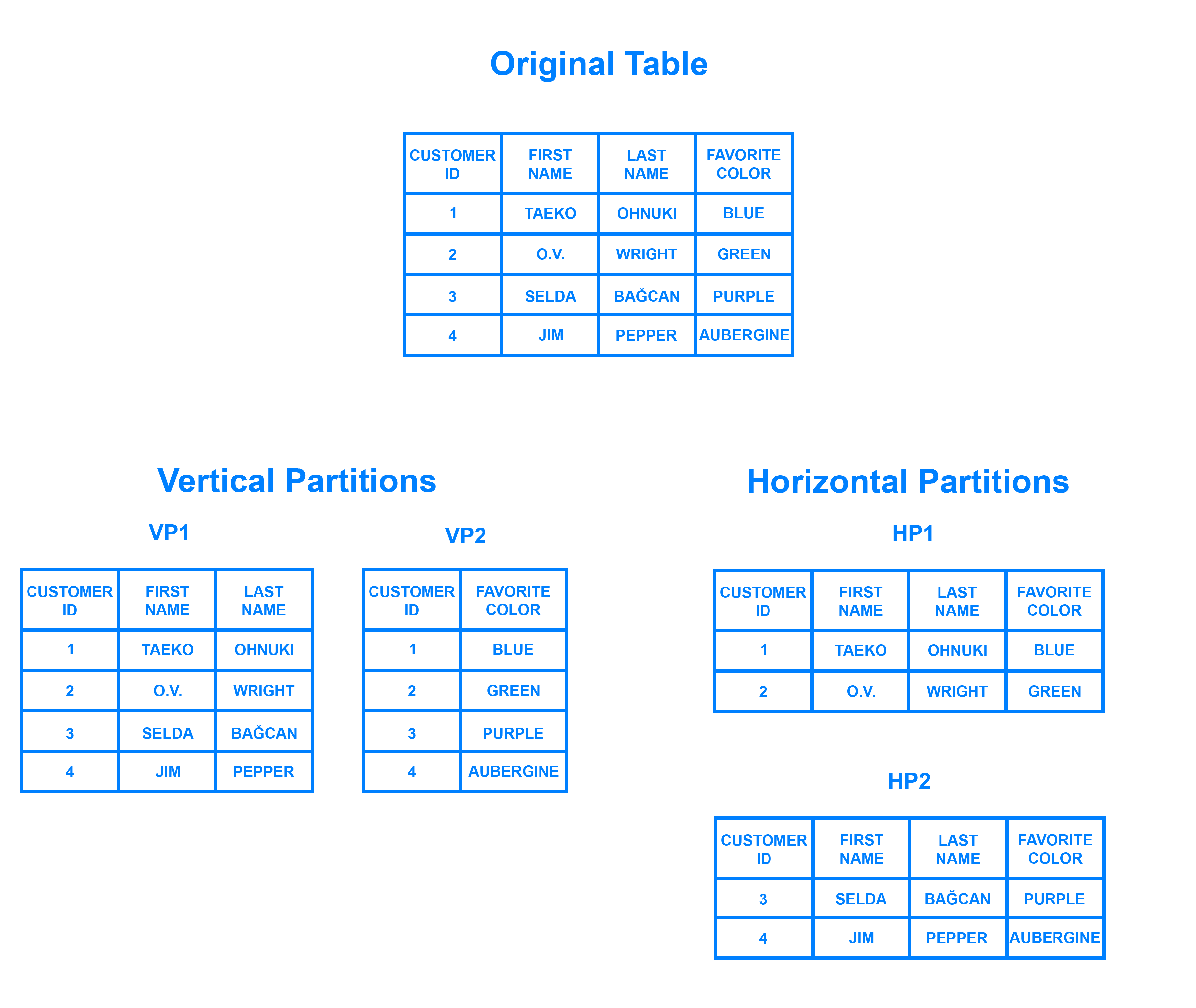
Sharding 是与 _horizontal partitioning 相关的数据库架构模式,即将一个表的行分为多个不同的表,称为分区,每个分区都有相同的格局和列,但也有完全不同的行。
在垂直划分的表中,整个列被分开并放入新的、不同的表中。一个垂直划分内的数据与其他所有数据独立,每个列都包含不同的行和列。
Sharding 涉及将数据分割成两个或多个较小的碎片,称为 logical shards. 然后在单独的数据库节点上分布,称为 physical shards,这些碎片可以容纳多个逻辑碎片。
数据库碎片示例为 shared-nothing architecture。这意味着碎片是自主的;它们不共享任何相同的数据或计算资源,但在某些情况下,可以合理地将某些表复制到每个碎片中以作为参考表。例如,假设一个应用程序有一个数据库,它依赖于重量测量的固定转换率。 通过复制包含必要转换率数据的表到每个碎片,这将有助于确保每个碎片中保留所有查询所需的数据。
通常,sharding是在应用层面实现的,这意味着应用程序包含定义传输哪个shard读取和写入的代码,然而,一些数据库管理系统内置了sharding功能,允许您在数据库层面直接实施sharding。
考虑到这个 sharding 的总体概述,让我们来看看与此数据库架构相关的一些正面和负面。
Sharding 的好处
破解数据库的主要吸引力是,它可以帮助促进 horizontal scaling,也被称为 scaling out. 水平扩展是将更多机器添加到现有堆栈的做法,以便分散负载并允许更多的流量和更快的处理。
在单一机器上运行关系数据库是相对简单的,并根据需要通过升级其计算资源来扩展它,但最终,任何非分布式数据库在存储和计算能力方面都将受到限制,因此具有水平扩展的自由使您的设置更加灵活。
有些人可能选择分割数据库架构的另一个原因是加速查询响应时间。当您在未分割的数据库上提交查询时,它可能需要搜索查询的表中的每个行,才能找到您正在寻找的结果集。
Sharding 还可以通过减轻中断的影响来帮助使应用程序更可靠。如果您的应用程序或网站依赖于未分割的数据库,则中断有可能使整个应用程序不可用。
Sharding 的回归
虽然分割数据库可以使扩展更容易,并提高性能,但它也可以强加某些限制,在这里,我们将讨论其中一些,以及为什么它们可能是避免分割的原因。
人们遇到的第一个困难是正确实施分布式数据库架构的复杂性。如果执行错误,则有可能导致分布过程导致数据丢失或损坏表的重大风险。即使正确执行,分布可能会对团队的工作流程产生重大影响。
用户在破解数据库后有时会遇到的一个问题是,碎片最终会变得不平衡,例如,假设你有一个数据库有两个单独的碎片,其中一个是为客户的最后一个名字从字母A开始到M,另一个是为那些名字从字母N开始到Z的用户。然而,你的应用程序为大量的人提供服务,他们的最后一个名字从字母G开始。因此,A-M碎片会逐渐积累更多的数据,比N-Z碎片,导致应用程序会减慢和停滞,使您的大部分用户都停滞不前。
另一个主要的缺点是,一旦数据库被分割,将其返回其未分割的架构可能非常困难。在分割之前对数据库进行的任何备份将不包括分割后所写的数据。因此,重建原始未分割的架构将需要将新分割的数据与旧的备份合并,或者替代地将分割的DB转化为单一的DB,这两者都将是昂贵且耗时的努力。
要考虑的最后一个缺点是,sharding并不是每个数据库引擎都支持的。例如,PostgreSQL不包括自动sharding作为功能,尽管有可能手动sharding PostgreSQL数据库。有许多Postgres叉子,其中包括自动sharding,但这些通常跟踪最新的PostgreSQL发行版,缺乏某些其他功能。 一些专门的数据库技术(如MySQL Cluster或某些数据库作为服务的产品,如MongoDB Atlas)也包括自动sharding作为功能,但这些数据库管理系统的版并不如此。
这些,当然,只是一些一般问题要考虑在碎片化之前. 根据其使用情况,碎片化数据库可能有更多的潜在缺点。
现在,我们已经涵盖了碎片化的一些缺点和好处,我们将讨论碎片化数据库的几种不同的架构。
Sharding 建筑
一旦你决定分割你的数据库,下一步你需要弄清楚的是你将如何做到这一点。当运行查询或向分割表或数据库分发入口数据时,它必须进入正确的分割。
基于关键的 Sharding
基于密钥的 sharding_,也称为基于 hash 的 sharding_,涉及使用从新编写的数据中获取的值 - 例如客户 ID 号码、客户应用程序的 IP 地址、ZIP 代码等 - 并将其插入到一个 _hash 函数中,以确定数据应该进入哪个 shard。
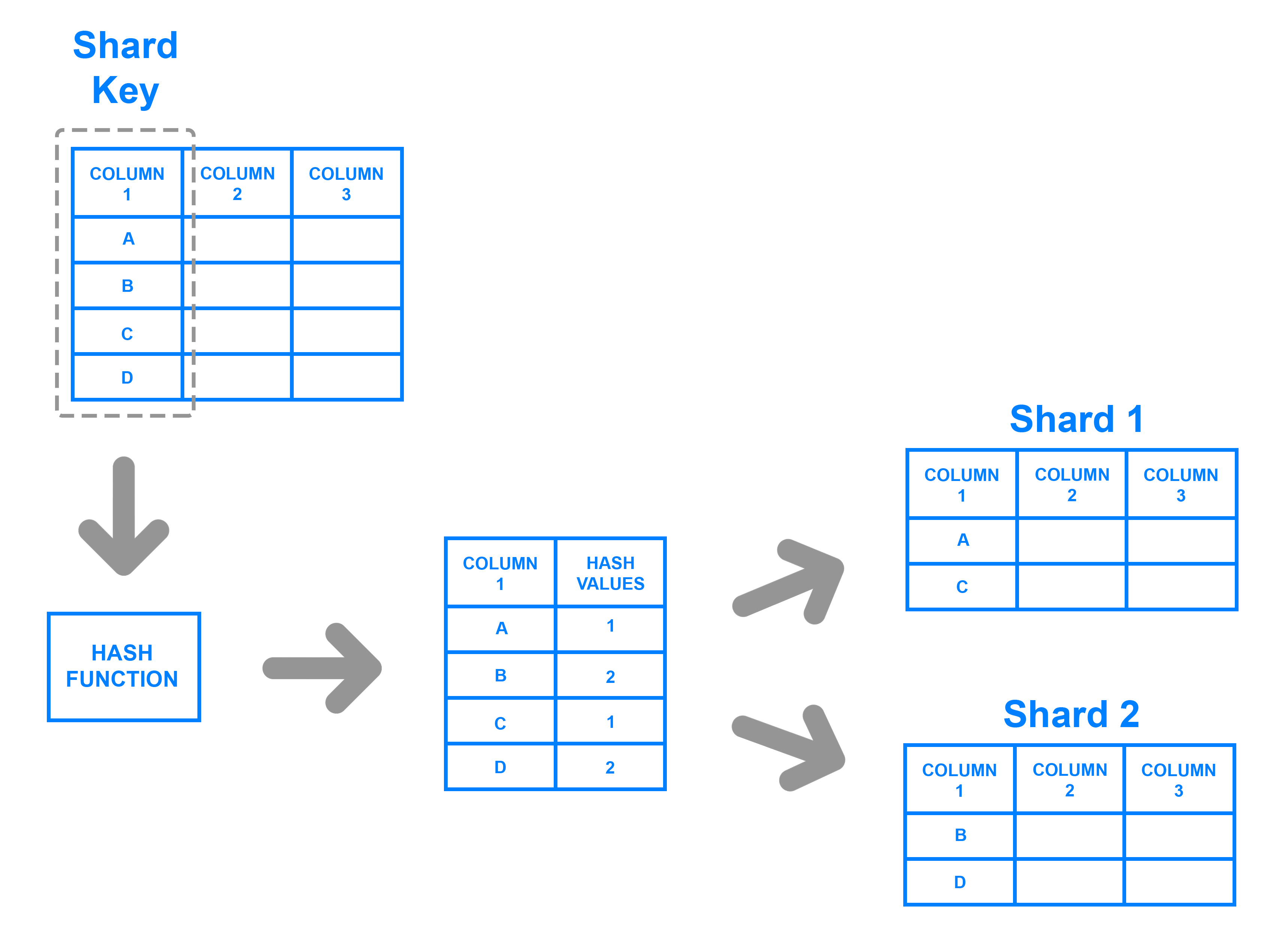
为了确保输入被放置在正确的碎片和一致的方式,输入到哈希函数的值都应该来自同一个列. 这个列被称为 shard key. 简单地说,碎片密钥与 primary keys相似,因为它们都是用于为单个行建立一个独特的标识符的列。 一般来说,碎片密钥应该是静态的,这意味着它不应该包含可能随着时间的推移而改变的值。
虽然基于密钥的 sharding 是一个相当常见的 sharding 架构,但在尝试动态添加或删除数据库的额外服务器时,它可能会使事情变得困难。当您添加服务器时,每个服务器都需要相应的 hash 值,并且许多现有条目,如果不是所有条目,都需要重新编写到新的,正确的 hash 值,然后迁移到适当的服务器。
该策略的主要吸引力是,它可以被用来均匀地分布数据以防止热点;此外,由于它算法上分布数据,因此不需要维护所有数据所在地的地图,就像其他策略如范围或基于目录的划分一样。
基于范围的 Sharding
Range based sharding 涉及基于给定值的范围的数据 sharding. 为了说明,假设您有一个存储零售商目录中的所有产品信息的数据库。
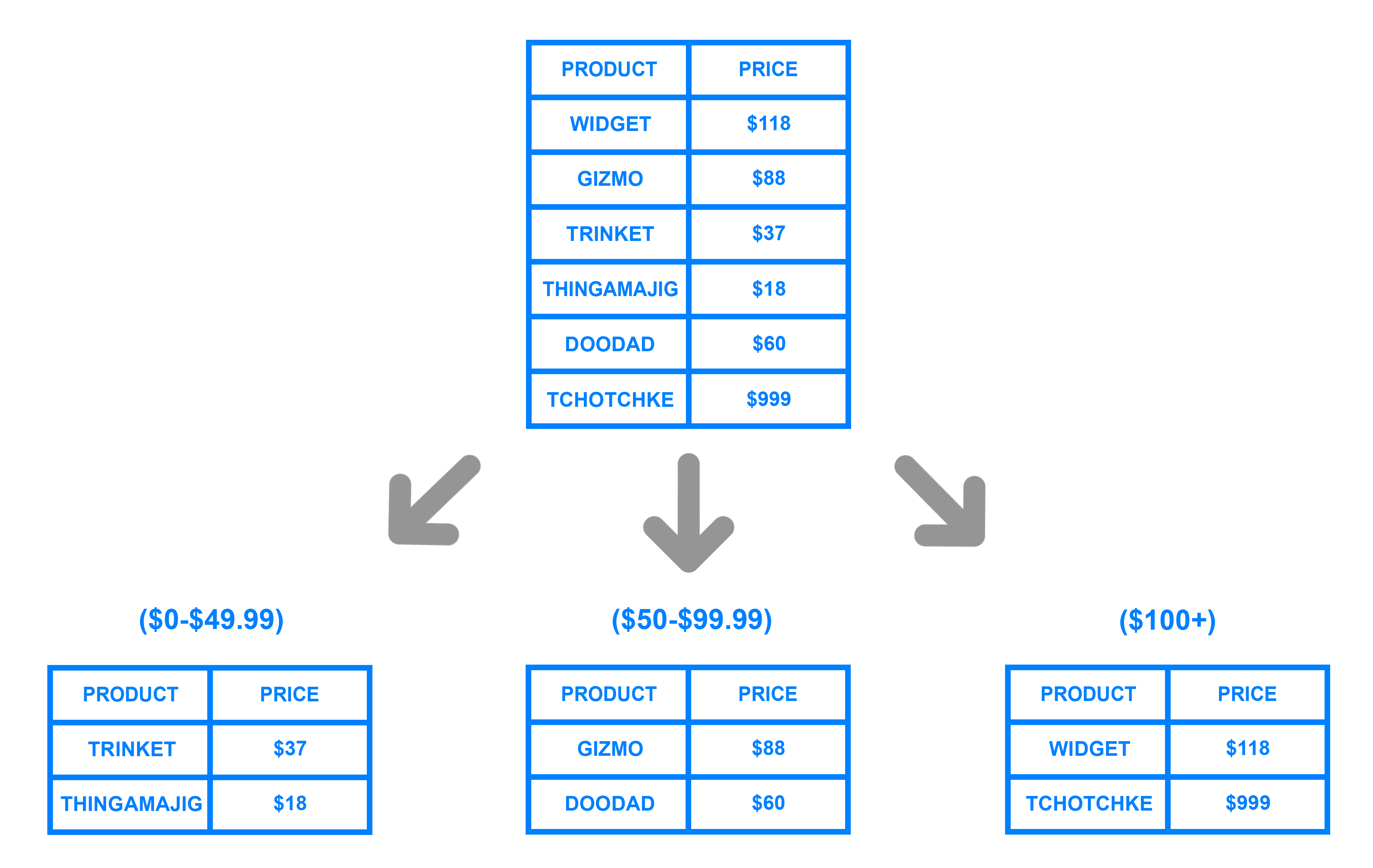
基于范围的sharding的主要好处在于它相对简单地实现,每个shard都包含不同的数据集,但它们都具有相同的图表,以及原始数据库。
另一方面,基于范围的碎片不会保护数据不均匀分布,导致上述数据库热点。 观察示例图,即使每个碎片包含相同数量的数据,很可能某些产品将获得比其他产品更多的关注。
基于目录的 Sharding
要实现基于目录的 sharding,必须创建和维护一个 _lookup 表,该表使用 shard 键来跟踪哪个 shard 持有哪些数据。
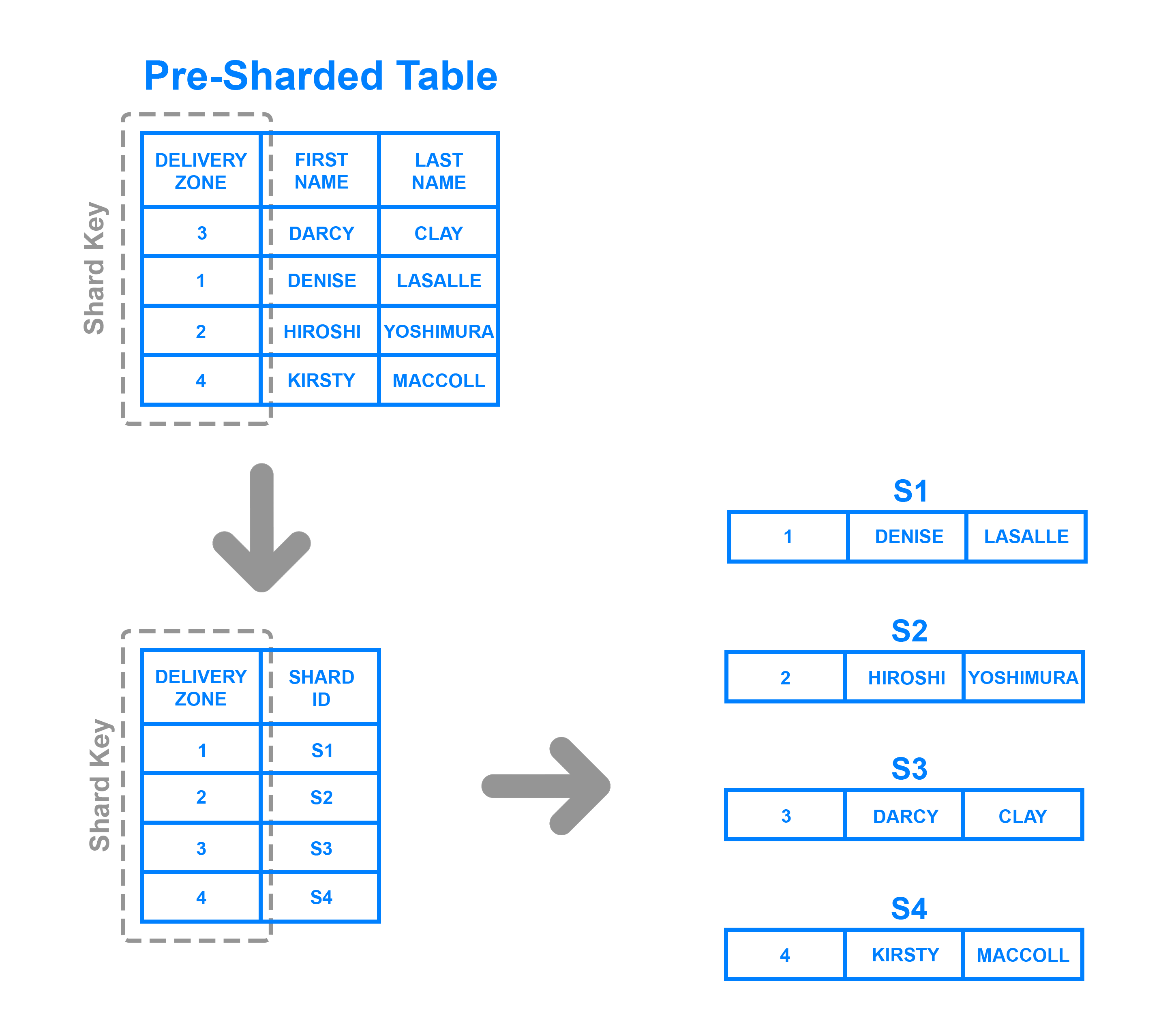
在这里, ** 交付区** 列被定义为 shard 密钥。来自 shard 密钥的数据被写入搜索表,以及每个相应行应该写的任何 shard. 这类似于基于范围的 sharding,但而不是确定 shard 密钥的数据属于哪个范围,每个密钥都与其自己的特定 shard 绑定。 基于目录的 sharding 是对基于范围的 sharding 的良好选择,如果 shard 密钥具有较低的 cardinality - 也就是说,它具有很少的可能值 - 并且它对 shard 存储一系列的密钥没有任何意义。
基于目录的 sharding 的主要吸引力是其灵活性. 基于范围的 sharding 架构限制您指定值范围,而基于密钥的架构限制您使用固定的哈希函数,如前所述,可以非常难以更改。
虽然基于目录的分解是这里讨论的分解方法中最灵活的,但在每个查询或写入之前需要连接到搜索表可能会对应用程序的性能产生负面影响。
我应该分割吗?
是否应该实施碎片化数据库架构几乎总是是一个辩论的问题,有些人认为碎片化是达到一定规模的数据库的必然结果,而其他人则认为这是一个头痛,除非它是绝对必要的,因为碎片化增加的操作复杂性。
由于这种增加的复杂性,通常只在处理非常大的数据量时才会进行碎片化,以下是可能有益于碎片化数据库的一些常见情况:
- 应用程序数据量会增加,超过单个数据库节点的存储容量
- 写入或读取数据库的量超过单个节点或其读取复制品所能处理的数量,导致响应时间或时间延迟
- 应用程序所需的网络带宽超过单个数据库节点和任何读取复制品可用的带宽,导致响应时间或时间延迟
在切割之前,您应该用尽所有其他优化数据库的选项,其中一些您可能需要考虑的优化包括:
- 建立远程数据库**。 如果你正在使用一个单一的应用程序,其中它的所有组件都居住在同一个服务器上,你可以通过移动到自己的机器来提高数据库的性能. 由于数据库的表格保持完好无损,这并不像硬化那样复杂. 然而,它仍然允许您在其它基础设施之外垂直放大您的数据库。 () ( )* ** 执行[取 (https://en.wikipedia.org/wiki/Database_caching)**。 如果你的应用程序的读取性能 才是给你带来麻烦的原因, 缓存是一个能帮助改进它的策略。 缓存涉及暂时存储内存中已经请求的数据,允许您在更后更快的时间访问. ( ( )* ** 创建一个或多个读取的复制品**。 另一个可以帮助提高读取性能的策略,这涉及到将数据从一个数据库服务器(primary server)复制到一个或一个以上的_second server_. 之后,每出新作在被复制到第二作之前会被送入主机,而读取则会被专门给第二作服务器. 散发读取和写作这样可以防止任何一台机器承担过多的负载,有助于防止减速和坠机. 请注意,创建可读复制品涉及更多的计算资源,从而花费更多的资金,这对一些人可能是一个重大制约。 (_ ( )* ** 升级到更大的服务器**。 在多数情况下,将个人的数据库服务器扩大为资源较多的机器需要付出比磨损更少的努力. 与创建可读复制品一样,一个拥有更多资源的升级服务器可能花费更多的资金. 因此,只有在真正成为你的最佳选择时,你才应该重新调整大小。 (_) (英语)
请记住,如果您的应用程序或网站增长超过一定的点,这些策略都不足以单独提高性能。
结论
Sharding 对于那些希望将数据库水平扩展的人来说,可能是一个很好的解决方案,但它也增加了大量的复杂性,并为您的应用程序创造了更多潜在的故障点。
通过阅读这篇概念文章,您应该更清楚地了解分解的优点和缺点。前进,您可以使用此见解来做出有关分解数据库架构是否适合您的应用程序的更明智的决定。