学 学 学
 Scikit-learn is a machine learning library for Python. It features several regression, classification and clustering algorithms including SVMs, gradient boosting, k-means, random forests and DBSCAN. It is designed to work with Python Numpy and SciPy. The scikit-learn project kicked off as a Google Summer of Code (also known as GSoC) project by David Cournapeau as scikits.learn. It gets its name from "Scikit", a separate third-party extension to SciPy.
Scikit-learn is a machine learning library for Python. It features several regression, classification and clustering algorithms including SVMs, gradient boosting, k-means, random forests and DBSCAN. It is designed to work with Python Numpy and SciPy. The scikit-learn project kicked off as a Google Summer of Code (also known as GSoC) project by David Cournapeau as scikits.learn. It gets its name from "Scikit", a separate third-party extension to SciPy.
Python 学习
Scikit是用Python(其中大部分)写的,其中一些核心算法是用Cython写的,以获得更好的性能。Scikit-learn用于构建模型,不建议用于读取、操纵和总结数据,因为有更好的框架可用于此目的。
安装 学习 学习
Scikit假设您在设备上运行 Python 2.7 或更高版本的平台,具有 NumPY (1.8.2 或更高版本) 和 SciPY (0.13.3 或更高版本) 套件。一旦我们安装了这些套件,我们可以继续安装。
1pip install scikit-learn
如果你喜欢conda,你也可以使用conda来安装包,运行以下命令:
1conda install scikit-learn
使用Sikit-Learn
一旦安装完成,您可以轻松地在 Python 代码中使用 scikit-learn,将其导入为:
1import sklearn
学习加载数据集
让我们来加载一个简单的名为Iris的数据集,这是一个花的数据集,它包含了150个关于花的不同测量的观察。
1# Import scikit learn
2from sklearn import datasets
3# Load data
4iris= datasets.load_iris()
5# Print shape of data to confirm data is loaded
6print(iris.data.shape)
We are printing shape of data for ease, you can also print whole data if you wish so, running the codes gives an output like this: 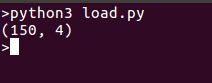
Scikit学习SVM - 学习和预测
现在我们已经加载了数据,让我们尝试从中学习并对新数据进行预测. 为此,我们必须创建一个估计器,然后调用其合适的方法。
1from sklearn import svm
2from sklearn import datasets
3# Load dataset
4iris = datasets.load_iris()
5clf = svm.LinearSVC()
6# learn from the data
7clf.fit(iris.data, iris.target)
8# predict for unseen data
9clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
10# Parameters of model can be changed by using the attributes ending with an underscore
11print(clf.coef_ )
Here is what we get when we run this script: 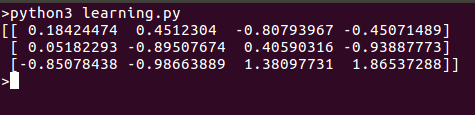
学习线性回归
使用 scikit-learn 创建各种模型相当简单,让我们从一个简单的回归例子开始。
1#import the model
2from sklearn import linear_model
3reg = linear_model.LinearRegression()
4# use it to fit a data
5reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
6# Let's look into the fitted data
7print(reg.coef_)
Running the model should return a point that can be plotted on the same line: 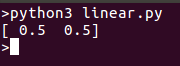
k-近邻分类器
让我们尝试一个简单的分类算法,这个分类器使用基于球树的算法来表示训练样本。
1from sklearn import datasets
2# Load dataset
3iris = datasets.load_iris()
4# Create and fit a nearest-neighbor classifier
5from sklearn import neighbors
6knn = neighbors.KNeighborsClassifier()
7knn.fit(iris.data, iris.target)
8# Predict and print the result
9result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
10print(result)
Let’s run the classifier and check results, the classifier should return 0. Let's try the example: 
K 表示集群
这是最简单的集合算法. 该集合被分为k集群,每个观察被分配给一个集群. 这样做是迭代的,直到集群相聚。
1from sklearn import cluster, datasets
2# load data
3iris = datasets.load_iris()
4# create clusters for k=3
5k=3
6k_means = cluster.KMeans(k)
7# fit data
8k_means.fit(iris.data)
9# print results
10print( k_means.labels_[::10])
11print( iris.target[::10])
On running the program we’ll see separate clusters in the list. Here is the output for above code snippet: 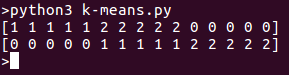
结论
在本教程中,我们已经看到Scikit-Learn可以轻松地使用多种机器学习算法。我们已经看到回归、分类和分类的例子。Scikit-Learn仍处于开发阶段,并由志愿者开发和维护,但在社区中非常受欢迎。