介绍
在本文中,您将尝试使用 scikit-learn,也称为 sklearn,在Python中使用一些不同的方法来正常化数据. 当您正常化数据时,您会更改数据的规模。 数据通常被调整到0和1之间,因为机器学习算法倾向于表现更好,或更快地汇聚,当不同功能在较小的规模时。 在训练数据上的机器学习模型之前,通常会首先正常化数据以获得更好的,更快的结果。
通过重新扩展来使功能更适合训练的过程称为 _feature scaling。
本教程使用 Python 版本 3.9.13 和 scikit-learn 版本 1.0.2 进行了测试。
使用 scikit-learn preprocessing.normalize() 函数来正常化数据
您可以使用 scikit-learn preprocessing.normalize() 函数来规范类似数组的数据集。
「normalize()」函数将矢量单独缩小为单位规范,以便矢量具有一个长度。「normalize()」的默认标准为L2,也被称为欧克利底标准。L2规范公式是每个值的平方数的总和的平方根。尽管使用「normalize()」函数会产生0和1之间的值,但它并不等于简单地将值缩小为0和1之间。
使用normalize()函数来正常化一个数组
您可以使用normalize()函数将一个单维NumPy数组正常化。
导入sklearn.preprocessing模块:
1from sklearn import preprocessing
导入 NumPy 并创建一个数组:
1import numpy as np
2
3x_array = np.array([2,3,5,6,7,4,8,7,6])
使用数组上的normalize()函数在一个行上正常化数据,在这种情况下是一个维数组:
1normalized_arr = preprocessing.normalize([x_array])
2print(normalized_arr)
运行完整的示例代码,以演示如何使用normalize()函数来规范 NumPy 数组:
1[label norm_numpy.py]
2from sklearn import preprocessing
3import numpy as np
4
5x_array = np.array([2,3,5,6,7,4,8,7,6])
6
7normalized_arr = preprocessing.normalize([x_array])
8print(normalized_arr)
产量是:
1[secondary_label Output]
2[[0.11785113 0.1767767 0.29462783 0.35355339 0.41247896 0.23570226
3 0.47140452 0.41247896 0.35355339]]
输出显示所有值在 0 到 1 范围内。
使用normalize()函数从数据框中正常化列
在 Pandas DataFrame 中,功能是列,行是样本. 您可以将 DataFrame 列转换为 NumPy 数组,然后将数组中的数据正常化。
本文和以下部分中的示例使用了 加州住房数据集。
示例代码的第一部分导入模块,加载数据集,创建数据框,并打印数据集的描述:
1import numpy as np
2from sklearn import preprocessing
3from sklearn.datasets import fetch_california_housing
4
5# create the DataFrame
6california_housing = fetch_california_housing(as_frame=True)
7
8# print the dataset description
9print(california_housing.DESCR)
请注意,as_frame参数设置为True,以创建california_housing对象为 Pandas DataFrame。
输出包含以下数据集描述的摘要,您可以使用它来选择一个功能来正常化:
1[secondary_label Output]
2.. _california_housing_dataset:
3
4California Housing dataset
5--------------------------
6
7**Data Set Characteristics:**
8
9 :Number of Instances: 20640
10
11 :Number of Attributes: 8 numeric, predictive attributes and the target
12
13 :Attribute Information:
14 - MedInc median income in block group
15 - HouseAge median house age in block group
16 - AveRooms average number of rooms per household
17 - AveBedrms average number of bedrooms per household
18 - Population block group population
19 - AveOccup average number of household members
20 - Latitude block group latitude
21 - Longitude block group longitude
22...
接下来,将列(功能)转换为数组,然后打印它. 此示例使用‘HouseAge’列:
1x_array = np.array(california_housing['HouseAge'])
2print("HouseAge array: ",x_array)
最后,使用normalize()函数来正常化数据并打印结果的数组:
1normalized_arr = preprocessing.normalize([x_array])
2print("Normalized HouseAge array: ",normalized_arr)
运行完整示例,以展示如何使用normalize()函数来规范特征:
1[label norm_feature.py]
2from sklearn import preprocessing
3import numpy as np
4from sklearn.datasets import fetch_california_housing
5
6california_housing = fetch_california_housing(as_frame=True)
7# print(california_housing.DESCR)
8
9x_array = np.array(california_housing.data['HouseAge'])
10print("HouseAge array: ",x_array)
11
12normalized_arr = preprocessing.normalize([x_array])
13print("Normalized HouseAge array: ",normalized_arr)
产量是:
1[secondary_label Output]
2HouseAge array: [41. 21. 52. ... 17. 18. 16.]
3Normalized HouseAge array: [[0.00912272 0.00467261 0.01157028 ... 0.00378259 0.0040051 0.00356009]]
输出显示,正常化()函数改变了中间房龄值的数组,以至于值的平方数总的平方根等于1。
按行或按列正常化数据集 使用normalize()函数
当您将数据集正常化而不将特征或列转换为用于处理的数组时,数据将通过行正常化。
以下示例显示使用默认轴来规范加利福尼亚住房数据集:
1[label norm_dataset_sample.py]
2from sklearn import preprocessing
3import pandas as pd
4
5from sklearn.datasets import fetch_california_housing
6california_housing = fetch_california_housing(as_frame=True)
7
8d = preprocessing.normalize(california_housing.data)
9scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
10print(scaled_df)
产量是:
1[secondary_label Output]
2 MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
30 0.023848 0.117447 0.020007 ... 0.007321 0.108510 -0.350136
41 0.003452 0.008734 0.002594 ... 0.000877 0.015745 -0.050829
52 0.014092 0.100971 0.016093 ... 0.005441 0.073495 -0.237359
63 0.009816 0.090449 0.010119 ... 0.004432 0.065837 -0.212643
74 0.006612 0.089394 0.010799 ... 0.003750 0.065069 -0.210162
8... ... ... ... ... ... ... ...
920635 0.001825 0.029242 0.005902 ... 0.002995 0.046179 -0.141637
1020636 0.006753 0.047539 0.016147 ... 0.008247 0.104295 -0.320121
1120637 0.001675 0.016746 0.005128 ... 0.002291 0.038840 -0.119405
1220638 0.002483 0.023932 0.007086 ... 0.002823 0.052424 -0.161300
1320639 0.001715 0.011486 0.003772 ... 0.001879 0.028264 -0.087038
14
15[20640 rows x 8 columns]
输出显示,值沿行正常化,以便每个样本都正常化,而不是每个特征。
但是,您可以通过指定轴来按特征正常化。
下面的示例展示了使用 `axis=0' 将加利福尼亚住房数据集规范为函数:
1[label norm_dataset_feature.py]
2from sklearn import preprocessing
3import pandas as pd
4
5from sklearn.datasets import fetch_california_housing
6california_housing = fetch_california_housing(as_frame=True)
7
8d = preprocessing.normalize(california_housing.data, axis=0)
9scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
10print(scaled_df)
产量是:
1[secondary_label Output]
2 MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
30 0.013440 0.009123 0.008148 ... 0.001642 0.007386 -0.007114
41 0.013401 0.004673 0.007278 ... 0.001356 0.007383 -0.007114
52 0.011716 0.011570 0.009670 ... 0.001801 0.007381 -0.007115
63 0.009110 0.011570 0.006787 ... 0.001638 0.007381 -0.007116
74 0.006209 0.011570 0.007329 ... 0.001402 0.007381 -0.007116
8... ... ... ... ... ... ... ...
920635 0.002519 0.005563 0.005886 ... 0.001646 0.007698 -0.007048
1020636 0.004128 0.004005 0.007133 ... 0.002007 0.007700 -0.007055
1120637 0.002744 0.003783 0.006073 ... 0.001495 0.007689 -0.007056
1220638 0.003014 0.004005 0.006218 ... 0.001365 0.007689 -0.007061
1320639 0.003856 0.003560 0.006131 ... 0.001682 0.007677 -0.007057
14
15[20640 rows x 8 columns]
当您检查输出时,您会注意到HouseAge列的结果与您在将HouseAge列转换为数组并在上一个示例中正常化的结果相匹配。
使用 scikit-learn preprocessing.MinMaxScaler() 函数来正常化数据
您可以使用 scikit-learn preprocessing.MinMaxScaler())函数通过将数据扩展到一个范围来规范每个函数。
MinMaxScaler()函数将每个函数单独扩展,使值具有给定的最低值和最大值,默认值为 0 和 1。
将特征值缩放到 0 和 1 之间的公式是:
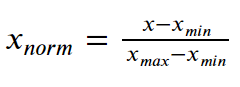
从每个输入中扣除最小值,然后将结果分为范围,其中范围是最大值和最小值之间的差异。
下面的示例展示了如何使用MinMaxScaler()函数来规范加州住房数据集:
1[label minmax01.py]
2from sklearn import preprocessing
3import pandas as pd
4
5from sklearn.datasets import fetch_california_housing
6california_housing = fetch_california_housing(as_frame=True)
7
8scaler = preprocessing.MinMaxScaler()
9d = scaler.fit_transform(california_housing.data)
10scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
11print(scaled_df)
产量是:
1[secondary_label Output]
2 MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
30 0.539668 0.784314 0.043512 ... 0.001499 0.567481 0.211155
41 0.538027 0.392157 0.038224 ... 0.001141 0.565356 0.212151
52 0.466028 1.000000 0.052756 ... 0.001698 0.564293 0.210159
63 0.354699 1.000000 0.035241 ... 0.001493 0.564293 0.209163
74 0.230776 1.000000 0.038534 ... 0.001198 0.564293 0.209163
8... ... ... ... ... ... ... ...
920635 0.073130 0.470588 0.029769 ... 0.001503 0.737513 0.324701
1020636 0.141853 0.333333 0.037344 ... 0.001956 0.738576 0.312749
1120637 0.082764 0.313725 0.030904 ... 0.001314 0.732200 0.311753
1220638 0.094295 0.333333 0.031783 ... 0.001152 0.732200 0.301793
1320639 0.130253 0.294118 0.031252 ... 0.001549 0.725824 0.309761
14
15[20640 rows x 8 columns]
输出显示,值被缩放到具有 0 的默认最低值和 1 的最大值。
您还可以指定不同的最小值和最大值来扩展。在下面的示例中,最小值为 0 和最大值为 2:
1[label minmax02.py]
2from sklearn import preprocessing
3import pandas as pd
4
5from sklearn.datasets import fetch_california_housing
6california_housing = fetch_california_housing(as_frame=True)
7
8scaler = preprocessing.MinMaxScaler(feature_range=(0, 2))
9d = scaler.fit_transform(california_housing.data)
10scaled_df = pd.DataFrame(d, columns=california_housing.data.columns)
11print(scaled_df)
产量是:
1MedInc HouseAge AveRooms ... AveOccup Latitude Longitude
20 1.079337 1.568627 0.087025 ... 0.002999 1.134963 0.422311
31 1.076054 0.784314 0.076448 ... 0.002281 1.130712 0.424303
42 0.932056 2.000000 0.105513 ... 0.003396 1.128587 0.420319
53 0.709397 2.000000 0.070482 ... 0.002987 1.128587 0.418327
64 0.461552 2.000000 0.077068 ... 0.002397 1.128587 0.418327
7... ... ... ... ... ... ... ...
820635 0.146260 0.941176 0.059538 ... 0.003007 1.475027 0.649402
920636 0.283706 0.666667 0.074688 ... 0.003912 1.477152 0.625498
1020637 0.165529 0.627451 0.061808 ... 0.002629 1.464400 0.623506
1120638 0.188591 0.666667 0.063565 ... 0.002303 1.464400 0.603586
1220639 0.260507 0.588235 0.062505 ... 0.003098 1.451647 0.619522
13
14[20640 rows x 8 columns]
输出显示,值被缩小为具有最低值为 0 和最大值为 2。
结论
在本文中,您使用了两个 scikit-learn 函数以不同的方式以样本(序列)和函数(列)来规范数据。