介绍
DigitalOcean Managed Databases 允许您使用多种方法扩展您的 PostgreSQL 数据库。其中一种方法是内置的连接集群器,允许您高效处理大量客户端连接,并减少这些开放连接的 CPU 和内存足迹。
在本教程中,我们将使用pgbench,PostgreSQL的内置基准测试工具,在DigitalOcean Managed PostgreSQL Database上运行负载测试。我们将沉浸在连接池中,描述它们是如何工作的,并展示如何使用云控制面板创建一个。
前提条件
要完成本教程,您将需要:
要了解如何提供和配置一个DigitalOcean PostgreSQL群集,请参阅管理数据库(https://www.digitalocean.com/docs/databases)。
*安装了PostgreSQL的客户端机器。默认情况下,您的PostgreSQL安装将包含pgbench基准工具和psql客户端,这两者我们将在本指南中使用。请参阅(How To Install and Use PostgreSQL on Ubuntu 18.04)(https://andsky.com/tech/tutorials/how-to-install-and-use-postgresql-on-ubuntu-18-04)以了解如何安装PostgreSQL。如果您在客户端机器上没有运行Ubuntu,您可以使用版本检索器找到适当的教程
一旦你有一个DigitalOcean PostgreSQL集群并运行,并安装了pgbench的客户端机器,你已经准备好开始这个指南。
步骤 1 – 创建和初始化基准数据库
在我们为我们的数据库创建连接池之前,我们将首先在我们的PostgreSQL集群上创建基准数据库,并用一些愚蠢的数据填充它,其中pgbench将运行其测试。pgbench实用程序反复运行一系列的五个SQL命令(由SELECT,UPDATE和INSERT查询组成)在一个交易中,使用多个线程和客户端,并计算一个名为 Transactions per SSecond(TPS)的有用性能指标。
让我们从连接到我们的PostgreSQL集群开始,并创建基准数据库。
首先,通过导航到数据库并查找您的PostgreSQL集群来获取您的集群的 连接细节。 点击您的集群。 您应该看到一个集群概览页面,其中包含以下 连接细节框:
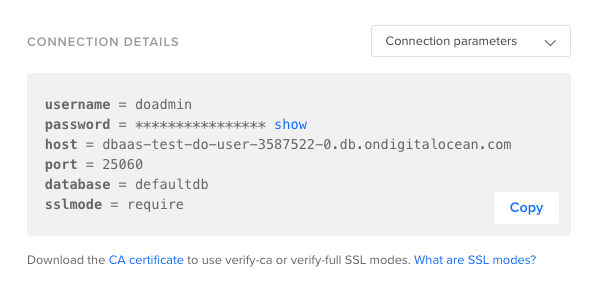
从此,我们可以解析以下 config 变量:
- 管理员用户:
doadmin - 管理员密码:
your_password - 集群终端:
dbaas-test-do-user-3587522-0.db.ondigitalocean.com - 连接端口:
25060 - 数据库连接到:
defaultdb - SSL 模式:
require(使用 SSL 加密连接以增加安全性)
请注意这些参数,因为您在使用psql客户端和pgbench工具时需要它们。
点击此框上方的下载框并选择 连接字符串. 我们将复制此字符串并将其传输到psql以连接到此PostgreSQL节点。
使用psql和您刚刚复制的连接字符串连接到群集:
1psql postgresql://doadmin:your_password@your_cluster_endpoint:25060/defaultdb?sslmode=require
您应该看到以下 PostgreSQL 客户端提示,表示您已成功连接到您的 PostgreSQL 集群:
1[secondary_label Output]
2psql (10.6 (Ubuntu 10.6-0ubuntu0.18.04.1))
3SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
4Type "help" for help.
5
6defaultdb=>
从这里创建基准数据库:
1CREATE DATABASE benchmark;
你应该看到以下结果:
1[secondary_label Output]
2CREATE DATABASE
现在,从集群中脱离:
1\q
在我们运行pgbench测试之前,我们需要填充这个基准数据库,其中包括运行测试所需的一些表和愚蠢数据。
要做到这一点,我们将运行pgbench与以下旗帜:
- 联合国 `-h': PostgreSQL 集群终点
- `-p': PostgreSQL 集群连接端口
-U':数据库用户名(_) ( )*-i':表示我们希望以基准表格及其模拟数据来初始化`基准 ' 数据库。s ': 设定一个150的比分系数,将表格大小乘以150。 " 1" 的默认比分因子产生如下大小的表格: QQ 行表# (_) (英语). ------------------------------------ -- ) pgbench_branches 1 (- ) pgbench_tellers 10 (- ) pgbench_ accounts 100000 (- ) pgbench_history 0 (- ) 使用比例尺为150,pgbench_ accounts表格将包含15,000,000行。 < $ > [注 (_) ) ** 注:** 为了避免交易被过度阻断,请确保将比例系数设定为至少与您打算测试的并行客户数量相同的数值。 在这个教程中,我们最多可以测试150个客户, 所以我们把s'设为150个。 为了解更多情况,请参考官方`pgbench ' 文件的这些建议做法。 (_) ) < $ >
运行完整的pgbench命令:
1pgbench -h your_cluster_endpoint -p 25060 -U doadmin -i -s 150 benchmark
运行此命令后,您将被要求输入您指定的数据库用户的密码。
你应该看到以下结果:
1[secondary_label Output]
2dropping old tables...
3NOTICE: table "pgbench_accounts" does not exist, skipping
4NOTICE: table "pgbench_branches" does not exist, skipping
5NOTICE: table "pgbench_history" does not exist, skipping
6NOTICE: table "pgbench_tellers" does not exist, skipping
7creating tables...
8generating data...
9100000 of 15000000 tuples (0%) done (elapsed 0.19 s, remaining 27.93 s)
10200000 of 15000000 tuples (1%) done (elapsed 0.85 s, remaining 62.62 s)
11300000 of 15000000 tuples (2%) done (elapsed 1.21 s, remaining 59.23 s)
12400000 of 15000000 tuples (2%) done (elapsed 1.63 s, remaining 59.44 s)
13500000 of 15000000 tuples (3%) done (elapsed 2.05 s, remaining 59.51 s)
14. . .
1514700000 of 15000000 tuples (98%) done (elapsed 70.87 s, remaining 1.45 s)
1614800000 of 15000000 tuples (98%) done (elapsed 71.39 s, remaining 0.96 s)
1714900000 of 15000000 tuples (99%) done (elapsed 71.91 s, remaining 0.48 s)
1815000000 of 15000000 tuples (100%) done (elapsed 72.42 s, remaining 0.00 s)
19vacuuming...
20creating primary keys...
21done.
在此时刻,我们已经创建了一个基准数据库,填充了运行pgbench测试所需的表和数据,现在我们可以继续运行基准测试,我们将使用它来比较连接组合启用之前和之后的性能。
步骤 2 – 运行基线pgbench测试
在我们运行我们的第一个基准之前,值得深入了解我们试图通过连接池优化的内容。
通常情况下,当客户端连接到 PostgreSQL 数据库时,主要的 PostgreSQL 操作系统流程会变成一个与这个新连接相匹配的婴儿流程。当只有少数连接时,这很少会出现问题。然而,随着客户端和连接的扩展,创建和维护这些连接的 CPU 和内存重量开始增加,特别是如果该应用程序没有有效地使用数据库连接。
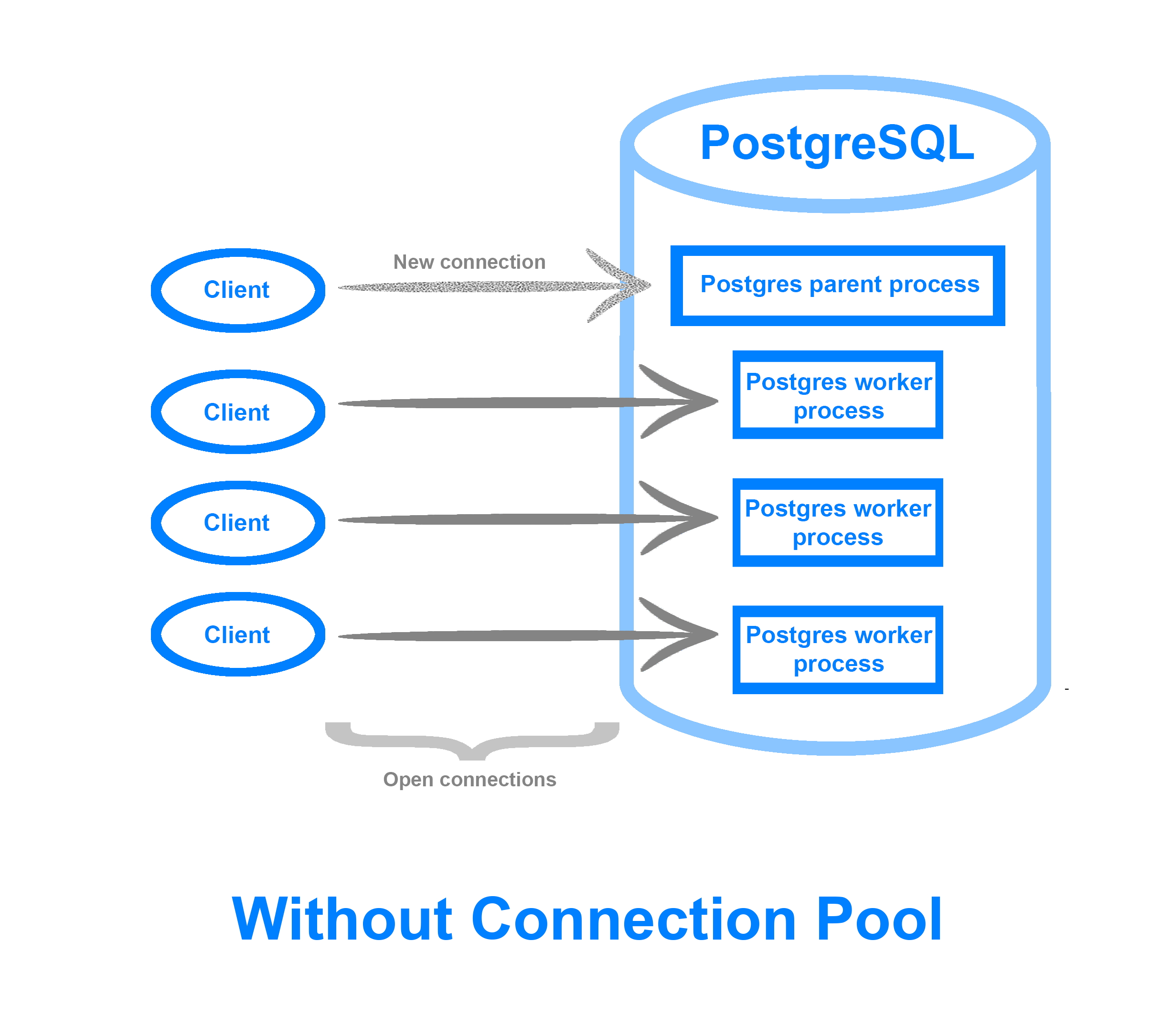
连接池可以保持固定数量的数据库连接,即 池大小,然后使用它来分发和执行客户端请求,这意味着您可以容纳更多的同时连接,有效地处理闲置或停滞的客户端,以及在流量高峰期间排队客户端请求,而不是拒绝它们。
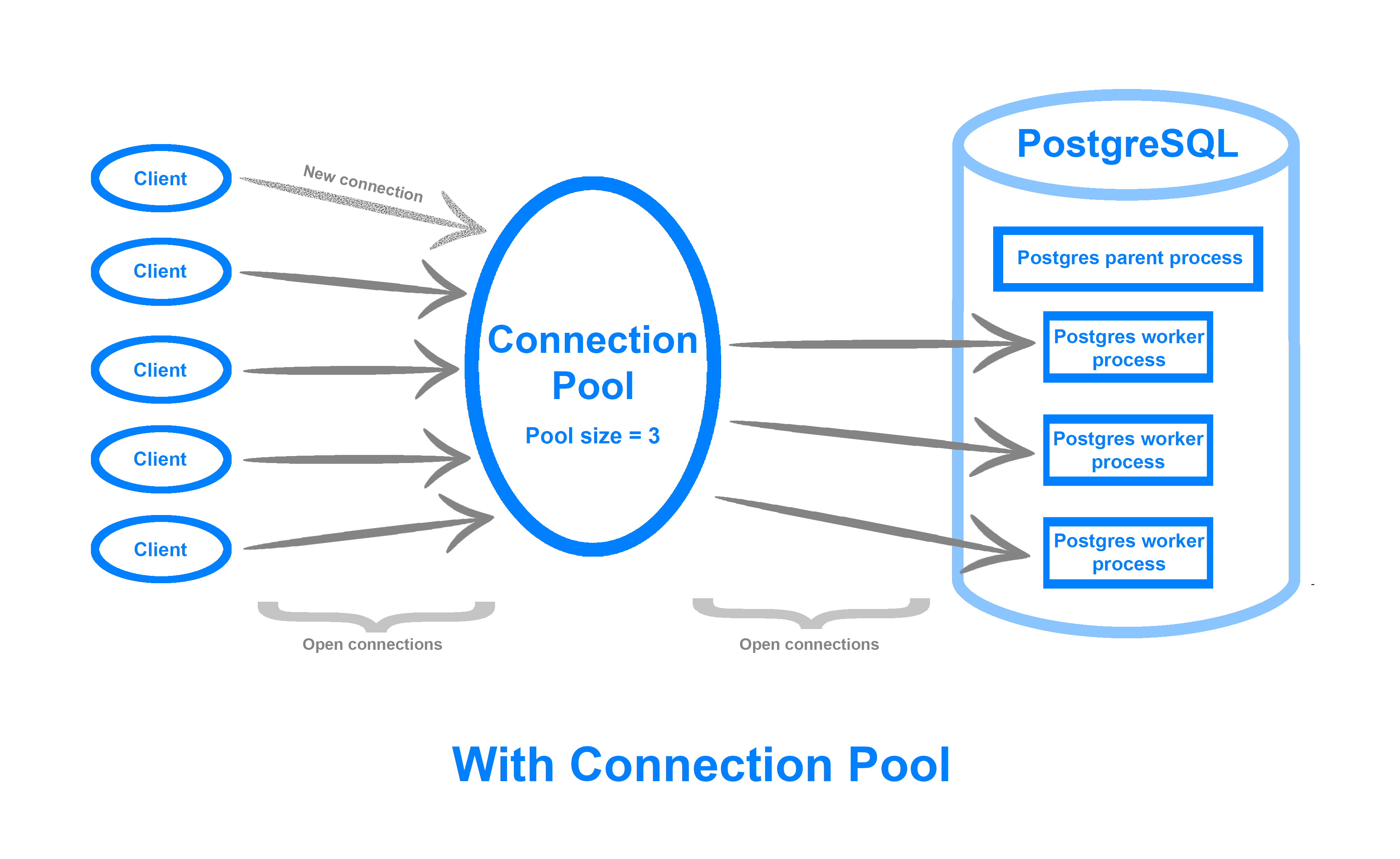
连接池可以部署在应用程序侧或作为数据库和应用程序之间的中间件。 管理数据库连接池是建立在 pgBouncer上,这是一个轻量级、开源的 PostgreSQL 中间件连接池。
在控制面板中导航到 ** 数据库**,然后点击您的 PostgreSQL 集群. 从这里,点击 ** 连接池**.然后点击 ** 创建连接池**. 您应该看到下面的配置窗口:
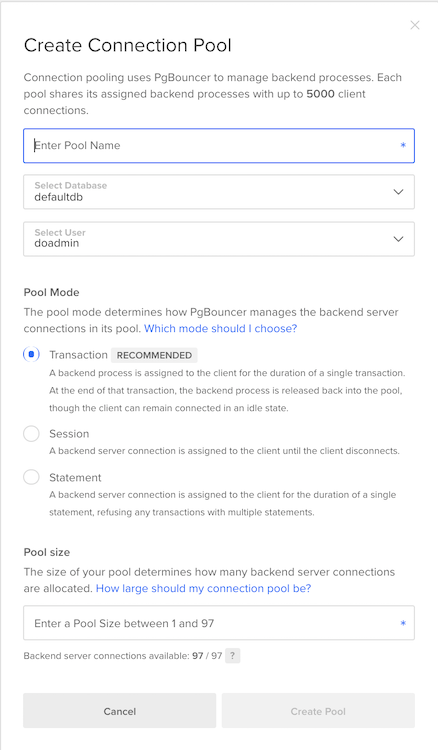
在这里,您可以配置以下字段:
- Pool Name: 您的连接池的唯一名称
- 数据库:您想要组连接的数据库
- 用户: PostgreSQL 用户将连接池的身份验证为
- 模式: 一个 Session, Transaction,或 Statement: 此选项控制了该池向客户端分配后端连接的时间
- Statement: 客户端一直保持连接,直到它明确断开连接
- **模式
- **交易:客户端获得连接,直到完成交易,然后连接返回数据库
- **Statement
在创建连接池之前,我们将运行基线测试,我们可以将数据库性能与连接组合进行比较。
在本教程中,我们将使用4 GB的RAM,2 vCPU,80 GB的磁盘,主要节点只有管理数据库设置。
DigitalOcean Managed Database 集群具有 PostgreSQL max_connections 参数预设为 1 GB RAM 每 25 个连接。 4 GB RAM PostgreSQL 节点因此有 max_connections 设置为 100. 此外,对于所有集群,3 个连接被保留用于维护。
考虑到这一点,让我们运行我们的第一个基线pgbench测试。
登录到您的客户端机器. 我们将运行pgbench,按常规方式指定数据库终端点、端口和用户。
-c:要模拟的同时客户端或数据库会话的数量. 我们将此设置为 50,以便模拟的同时连接数量小于我们的 PostgreSQL 集群的max_connections参数。-j: 将使用的劳动者线程pgbench的数量来运行基准。 如果您使用的是多CPU 机器,您可以向上调节以分配客户端的线程。 在两个核心机器上,我们将此设置为2-P: 每 60 秒显示进度和指标。-T: 运行基准值为600(10 分钟)。
我们还将指定我们希望对我们之前创建和人口化的基准数据库运行基准。
运行以下完整的「pgbench」命令:
1pgbench -h your_db_endpoint -p 25060 -U doadmin -c 50 -j 2 -P 60 -T 600 benchmark
点击ENTER,然后输入doadmin用户的密码,开始运行测试,您应该看到类似于以下的输出(结果将取决于您的PostgreSQL集群的规格):
1[secondary_label Output]
2starting vacuum...end.
3progress: 60.0 s, 157.4 tps, lat 282.988 ms stddev 40.261
4progress: 120.0 s, 176.2 tps, lat 283.726 ms stddev 38.722
5progress: 180.0 s, 167.4 tps, lat 298.663 ms stddev 238.124
6progress: 240.0 s, 178.9 tps, lat 279.564 ms stddev 43.619
7progress: 300.0 s, 178.5 tps, lat 280.016 ms stddev 43.235
8progress: 360.0 s, 178.8 tps, lat 279.737 ms stddev 43.307
9progress: 420.0 s, 179.3 tps, lat 278.837 ms stddev 43.783
10progress: 480.0 s, 178.5 tps, lat 280.203 ms stddev 43.921
11progress: 540.0 s, 180.0 tps, lat 277.816 ms stddev 43.742
12progress: 600.0 s, 178.5 tps, lat 280.044 ms stddev 43.705
13transaction type: <builtin: TPC-B (sort of)>
14scaling factor: 150
15query mode: simple
16number of clients: 50
17number of threads: 2
18duration: 600 s
19number of transactions actually processed: 105256
20latency average = 282.039 ms
21latency stddev = 84.244 ms
22tps = 175.329321 (including connections establishing)
23tps = 175.404174 (excluding connections establishing)
在这里,我们观察到,在10分钟的运行中,50次同时进行,我们处理了105,256笔交易,每秒的输出量大约为175笔交易。
现在,让我们运行同样的测试,这次使用150个同时客户端,这个值高于这个数据库的max_connections,以合成模拟客户端连接的大量流入:
1pgbench -h your_db_endpoint -p 25060 -U doadmin -c 150 -j 2 -P 60 -T 600 benchmark
你应该看到类似于以下的输出:
1[secondary_label Output]
2starting vacuum...end.
3connection to database "pgbench" failed:
4FATAL: remaining connection slots are reserved for non-replication superuser connections
5progress: 60.0 s, 182.6 tps, lat 280.069 ms stddev 42.009
6progress: 120.0 s, 253.8 tps, lat 295.612 ms stddev 237.448
7progress: 180.0 s, 271.3 tps, lat 276.411 ms stddev 40.643
8progress: 240.0 s, 273.0 tps, lat 274.653 ms stddev 40.942
9progress: 300.0 s, 272.8 tps, lat 274.977 ms stddev 41.660
10progress: 360.0 s, 250.0 tps, lat 300.033 ms stddev 282.712
11progress: 420.0 s, 272.1 tps, lat 275.614 ms stddev 42.901
12progress: 480.0 s, 261.1 tps, lat 287.226 ms stddev 112.499
13progress: 540.0 s, 272.5 tps, lat 275.309 ms stddev 41.740
14progress: 600.0 s, 271.2 tps, lat 276.585 ms stddev 41.221
15transaction type: <builtin: TPC-B (sort of)>
16scaling factor: 150
17query mode: simple
18number of clients: 150
19number of threads: 2
20duration: 600 s
21number of transactions actually processed: 154892
22latency average = 281.421 ms
23latency stddev = 125.929 ms
24tps = 257.994941 (including connections establishing)
25tps = 258.049251 (excluding connections establishing)
注意FATAL错误,表明pgbench达到由max_connections设置的100连接限制门槛,导致连接被拒绝。
在这一点上,我们可以调查连接池如何潜在地提高我们的数据库的输出量。
步骤 3 – 创建和测试连接池
在此步骤中,我们将创建一个连接池,并重新运行以前的pgbench测试,看看我们是否可以改善我们的数据库的输出量。
一般来说,max_connections的设置和连接池参数是对齐调节的,以最大限度地消除数据库的负载,但是,由于max_connections在DigitalOcean Managed Databases中是抽象的,我们这里的主要杠杆是连接池 Mode和 Size设置。
首先,让我们在交易模式中创建一个连接池,使所有可用的后端连接保持开放。
在控制面板中导航到 ** 数据库**,然后点击您的 PostgreSQL 集群. 从这里,点击 ** 连接池**.然后点击 ** 创建连接池**。
在出现的配置窗口中,填写以下值:
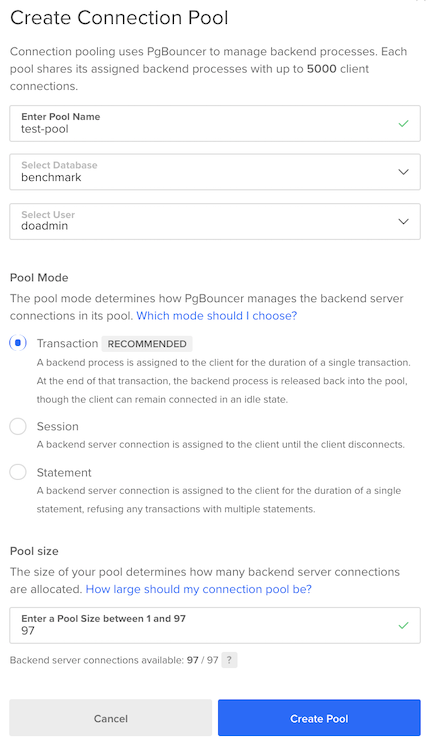
在这里,我们将我们的连接池命名为 test-pool,并与 benchmark数据库一起使用。 我们的数据库用户是 doadmin,我们将连接池设置为 Transaction模式。 记住从以前,对于具有4GB RAM的管理数据库集群,有97个可用的数据库连接。
完成后,点击创建池。
你现在应该在控制面板中看到这个池:

通过点击 连接细节来捕捉其URI。
1postgres://doadmin:password@pool_endpoint:pool_port/test-pool?sslmode=require
您应该在这里注意到一个不同的端口,并且可能有一个不同的终端点和数据库名称,相应于池名称测试池。
现在我们已经创建了测试池连接池,我们可以重新启动我们上面的pgbench测试。
主持人「pgbench」
从您的客户端计算机运行以下pgbench命令(与 150 个同步客户端),确保将突出值替换为连接池 URI 中的值:
1pgbench -h pool_endpoint -p pool_port -U doadmin -c 150 -j 2 -P 60 -T 600 test-pool
在这里,我们再次使用150个同时客户端,在2个线程上运行测试,每60秒打印进展,然后运行测试600秒。
一旦测试完成,您应该看到类似于以下的输出(请注意,这些结果将取决于数据库节点的规格):
1[secondary_label Output]
2starting vacuum...end.
3progress: 60.0 s, 240.0 tps, lat 425.251 ms stddev 59.773
4progress: 120.0 s, 350.0 tps, lat 428.647 ms stddev 57.084
5progress: 180.0 s, 340.3 tps, lat 440.680 ms stddev 313.631
6progress: 240.0 s, 364.9 tps, lat 411.083 ms stddev 61.106
7progress: 300.0 s, 366.5 tps, lat 409.367 ms stddev 60.165
8progress: 360.0 s, 362.5 tps, lat 413.750 ms stddev 59.005
9progress: 420.0 s, 359.5 tps, lat 417.292 ms stddev 60.395
10progress: 480.0 s, 363.8 tps, lat 412.130 ms stddev 60.361
11progress: 540.0 s, 351.6 tps, lat 426.661 ms stddev 62.960
12progress: 600.0 s, 344.5 tps, lat 435.516 ms stddev 65.182
13transaction type: <builtin: TPC-B (sort of)>
14scaling factor: 150
15query mode: simple
16number of clients: 150
17number of threads: 2
18duration: 600 s
19number of transactions actually processed: 206768
20latency average = 421.719 ms
21latency stddev = 114.676 ms
22tps = 344.240797 (including connections establishing)
23tps = 344.385646 (excluding connections establishing)
请注意,我们能够通过150个同时连接增加数据库的传输量,从257 TPS增加到344 TPS(增加33%),并且没有达到我们以前没有连接池的max_connections限制。
如果您运行相同的测试,但具有-c值为50(指定较少的客户端),使用连接池的收益变得更不明显:
1[secondary_label Output]
2starting vacuum...end.
3progress: 60.0 s, 154.0 tps, lat 290.592 ms stddev 35.530
4progress: 120.0 s, 162.7 tps, lat 307.168 ms stddev 241.003
5progress: 180.0 s, 172.0 tps, lat 290.678 ms stddev 36.225
6progress: 240.0 s, 172.4 tps, lat 290.169 ms stddev 37.603
7progress: 300.0 s, 177.8 tps, lat 281.214 ms stddev 35.365
8progress: 360.0 s, 177.7 tps, lat 281.402 ms stddev 35.227
9progress: 420.0 s, 174.5 tps, lat 286.404 ms stddev 34.797
10progress: 480.0 s, 176.1 tps, lat 284.107 ms stddev 36.540
11progress: 540.0 s, 173.1 tps, lat 288.771 ms stddev 38.059
12progress: 600.0 s, 174.5 tps, lat 286.508 ms stddev 59.941
13transaction type: <builtin: TPC-B (sort of)>
14scaling factor: 150
15query mode: simple
16number of clients: 50
17number of threads: 2
18duration: 600 s
19number of transactions actually processed: 102938
20latency average = 288.509 ms
21latency stddev = 83.503 ms
22tps = 171.482966 (including connections establishing)
23tps = 171.553434 (excluding connections establishing)
在这里,我们看到我们无法通过使用连接池来增加传输量,我们的传输量从175 TPS降至171 TPS。
虽然在本指南中我们使用pgbench与其内置的基准数据集,但确定是否使用连接池的最佳测试是基准负载,该负载准确地代表您的数据库上的生产负载,而不是生产数据。
<$>[注] 注: **池尺寸设置是高度工作负载特定的。 在本指南中,我们将连接池配置为使用所有可用的后端数据库连接。 这是因为在整个基准中,数据库很少实现充分利用(您可以从云控制面板中的 Metrics 卡监控数据库负载)。 根据数据库的负载,这可能不是最佳设置。 如果您注意到您的数据库始终完全饱和,缩小连接池可能会通过排列额外的请求来增加输出量并提高性能,而不是试图在已加载的服务器上同时执行所有请求。
结论
DigitalOcean Managed Databases 连接聚合是一个强大的功能,可以帮助您快速从数据库中提取额外的性能。 除了其他技术,如复制,缓存和分解,连接聚合可以帮助您扩展数据库层以处理更大的请求量。
在本指南中,我们专注于使用PostgreSQL内置的pgbench基准测试工具和默认基准测试的简化和合成测试场景,在任何生产场景中,您应该在模拟生产负载时对实际生产数据运行基准测试。
除了「pgbench」之外,还存在其他工具来基准和加载您的数据库。 Percona 开发的一种工具是 sysbench-tpcc。
有关 DigitalOcean Managed Databases 的更多信息,请参阅 Managed Databases 产品文档。 有关 sharding 的更多信息,另一种有用的扩展技术,请参阅 Understanding Database Sharding。