介绍
Kubernetes 是一个强大的集装箱管制系统,可以管理跨服务器集群的集装箱应用程序的部署和操作,除了协调集装箱工作负载外,Kubernetes 还提供维护应用程序和服务之间可靠网络连接所需的基础设施和工具。
Kubernetes集群网络文档指出,Kubernetes网络的基本要求是:
所有集装箱可以与所有其他集装箱无NAT
所有节点可以与所有集装箱无NAT 无NAT 所有节点可以与所有集装箱无NAT 所有节点可以与所有集装箱无NAT 所有节点可以与所有集装箱无NAT 通信。
在本文中,我们将讨论Kubernetes如何在集群中满足这些网络需求:数据如何在集群内,在集群之间和节点之间移动。
我们还将展示 Kubernetes 服务如何为应用程序提供单个静态 IP 地址和 DNS 输入,简化与服务的通信,这些服务可以分布在多个不断扩展和切换的 pods 之间。
如果您不熟悉 Kubernetes pods 和 nodes 或其他基本术语,我们的文章 An Introduction to Kubernetes涵盖了相关的一般架构和组件。
首先,让我们看看单个平台内的网络情况。
如果您正在寻找一个管理的Kubernetes托管服务,请查看我们的简单的,用于增长的管理的Kubernetes服务(https://www.digitalocean.com/products/kubernetes)。
网络下
在 Kubernetes 中,一个 _pod 是最基本的组织单位:一组紧密相连的容器,它们都密切相关,并执行一个单一的功能或服务。
在网络上,Kubernetes 处理 pods 类似于传统的虚拟机或单一的纯金属主机:每个 pod 都会收到一个单一的 IP 地址,并且pod 内的所有容器都共享该地址,并通过 lo loopback 接口相互通信,使用 localhost 主机名。
这种情况应该让任何在集装箱化之前在单个主机上部署了多个服务的人都熟悉,所有服务都需要使用一个独特的端口来聆听,但否则通信是不复杂的,负担率很低。
点击下载网络
大多数 Kubernetes 集群都需要部署每个节点的多个 pods. Pod to pod 通信可能发生在同一个节点上的两个 pods 之间,或者在两个不同的节点之间。
Pod to Pod 通信在一个节点上
在单个节点上,你可以有多个节点,需要彼此直接通信。在我们跟踪节点之间的包的路径之前,让我们检查节点的网络设置。
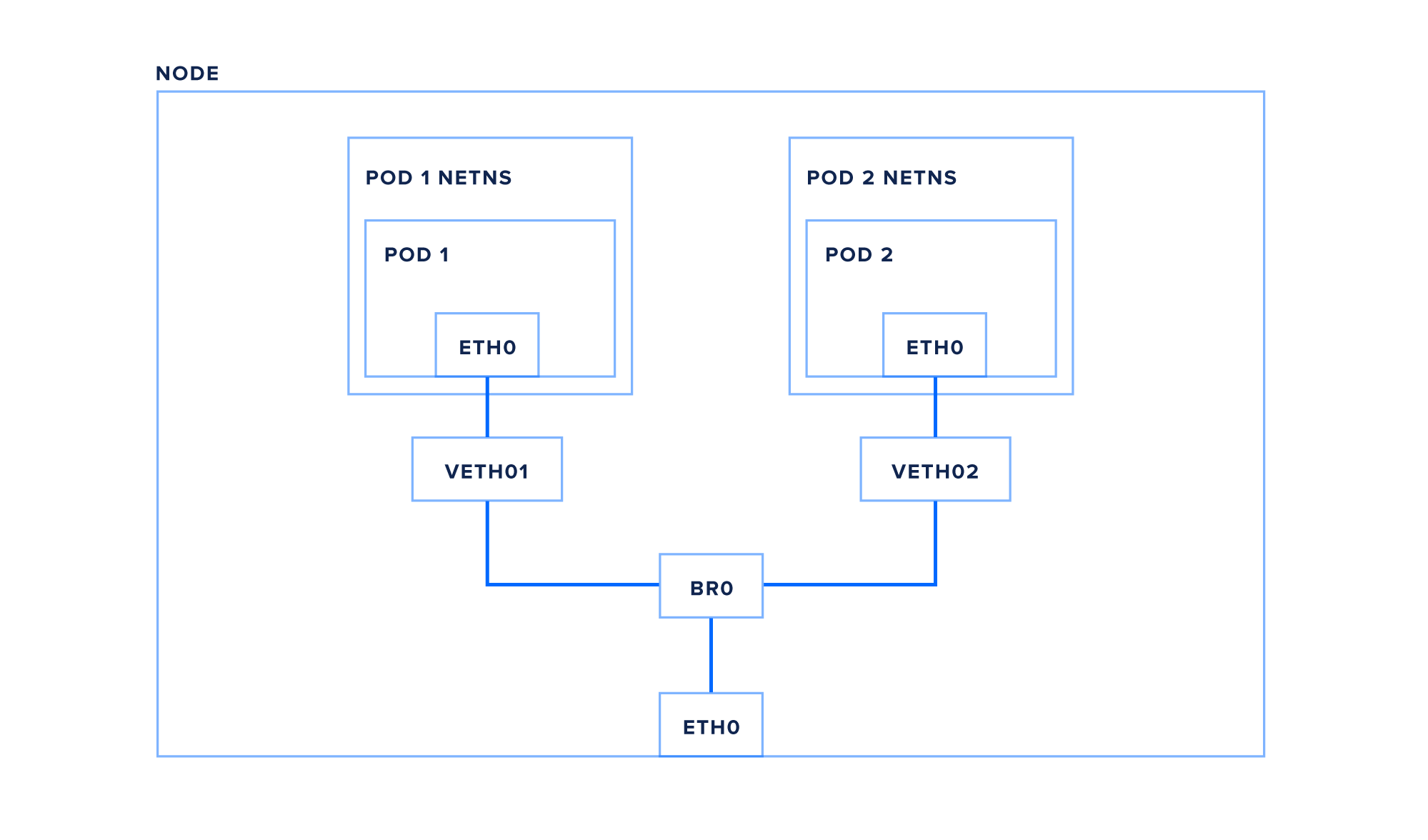
每个节点都有一个连接到Kubernetes集群网络的网络接口 - 这个例子中的 eth0. 这个接口位于节点的 root网络命名空间内。
正如进程名空间允许容器彼此隔离运行应用程序一样,网络名空间隔离网络设备,如接口和桥梁。
Pod 命名空间通过虚拟以太网对连接到 root的命名空间,本质上是两个命名空间之间的管道,每个端都有接口(在这里我们在 root的命名空间中使用 veth1,在 pod 中使用 eth0)。
最后, pods 通过桥梁连接到彼此以及节点的 eth0接口, br0(您的节点可能使用类似的 cbr0或 docker0)。
让我们现在跟踪一个包从 pod1到 pod2:
- pod1创建一个具有 pod2的IP作为目的地的包 *包通过虚拟以太网对前往根网络命名空间 *包继续到桥 br0 *由于目的地pod位于同一个节点上,桥将包发送到 pod2的虚拟以太网对 *包通过虚拟以太网对,进入 pod2的网络命名空间和pod的 eth0网络接口
现在,我们已经从一个节点中跟踪了一个包,让我们看看节点之间的 pod 流量是如何移动的。
两个节点之间的通信
由于集群中的每个pod都有一个独特的IP,并且每个pod可以直接与所有其他pods通信,所以在两个不同的节点上的pods之间移动的包类似于前一个场景。
让我们跟踪一个包从 pod1到 pod3,它位于不同的节点上:
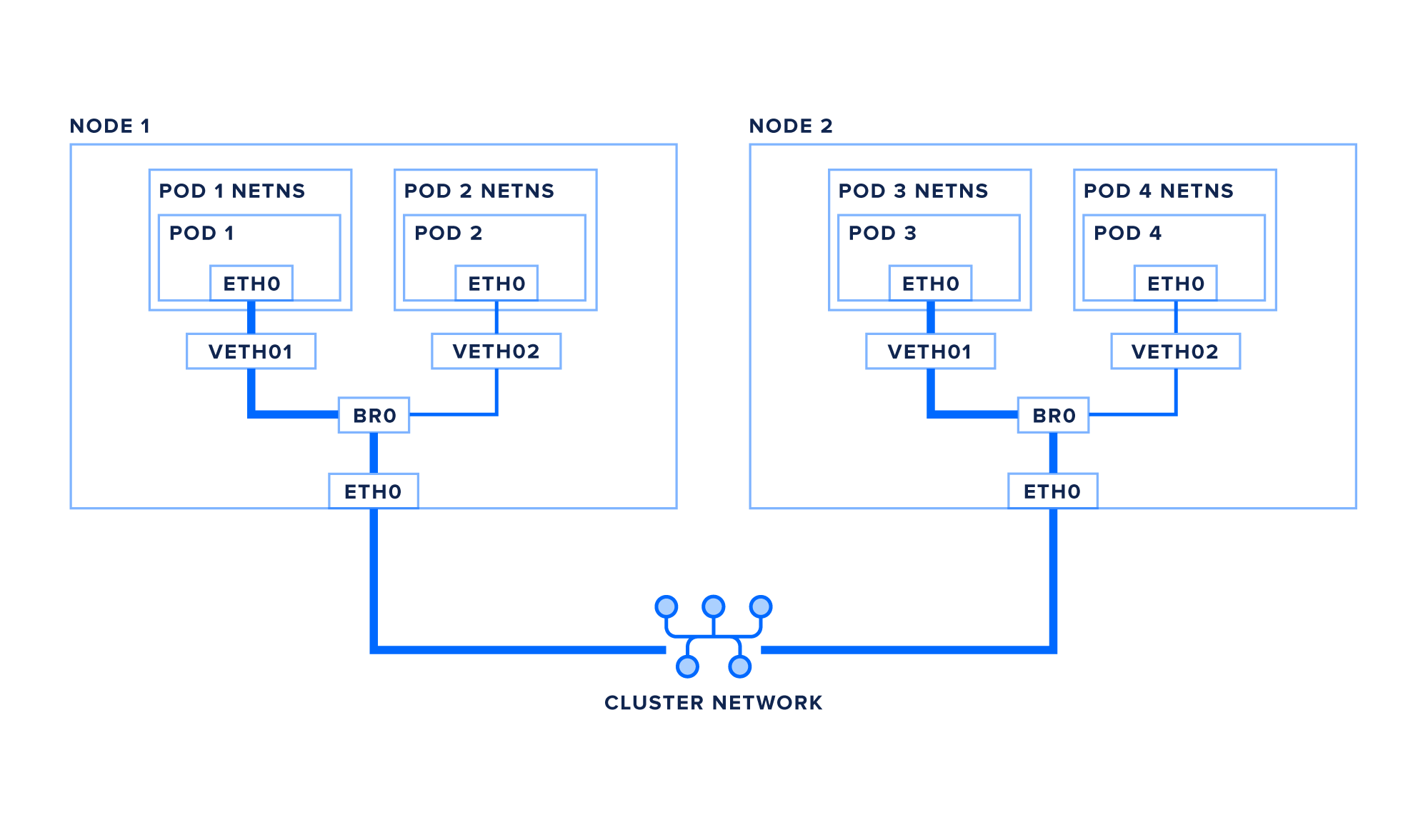
pod1创建了以pod3*的IP为目的地的包
- 包通过虚拟醚网对到根网命名空间
- 包接通了桥br0
- 该桥找不到本地接口可前往的路由, 因此数据包将发送到 eth0
- 的默认路由 。 可选择性: 如果您的集群需要网络覆盖才能正确路由包到节点,则该包可能先被封入VXLAN包(或其他网络虚拟化技术)后再向网络行走. 换句话说,网络本身可能与适当的静态路线相接而成,在这种情况下,数据包会前往eth0,并流出没有改变的网络() ( )* 数据包进入集群网络并被引导到正确的节点. () ( )* 包在eth0 上进入目的地节点* 可选: 如果您的包被封装, 它将在此点被去封装( ) * 包接通了桥br0
- 桥将包通到目的地的虚拟网对
- 包通过虚拟醚网对接到吊舱的eth0接口( (英语)
现在我们已经熟悉了如何通过pod IP 地址路由包,让我们看看 Kubernetes services 以及它们如何建立在这一基础设施之上。
Pod to 服务网络
将流量发送到某个特定应用程序只使用pod IP 是困难的,因为Kubernetes群集的动态性质意味着pods可以移动,重新启动,升级或扩展。
Kubernetes 通过 Services 解决了这个问题. 服务是一个 API 对象,它将单个虚拟 IP (VIP) 映射到一组 pod IP. 此外,Kubernetes 还为每个服务的名称和虚拟 IP 提供 DNS 输入,因此服务可以很容易地通过名称进行地址。
将虚拟 IP 绘制为群集中的 pod IP 是由每个节点的cube-proxy过程协调的。 这个过程设置了 iptables 或 IPVS,在将包发送到群集网络之前自动将 VIP 转换为 pod IP。 单个连接被跟踪,以便在返回时可以正确地转换包。 IPVS 和 iptables 都可以将单一服务的虚拟 IP 负载平衡成多个 pod IP,尽管 IPVS 在其可以使用的负载平衡算法中具有更大的灵活性。
<$>[注] **注:**这种翻译和连接跟踪流程完全发生在Linux内核中。 kube-proxy从Kubernetes API读取并更新iptables ip IPVS,但它不在单个包的数据路径中。
让我们跟随一个包从一个pod, pod1再次,到一个服务, service1的路线:
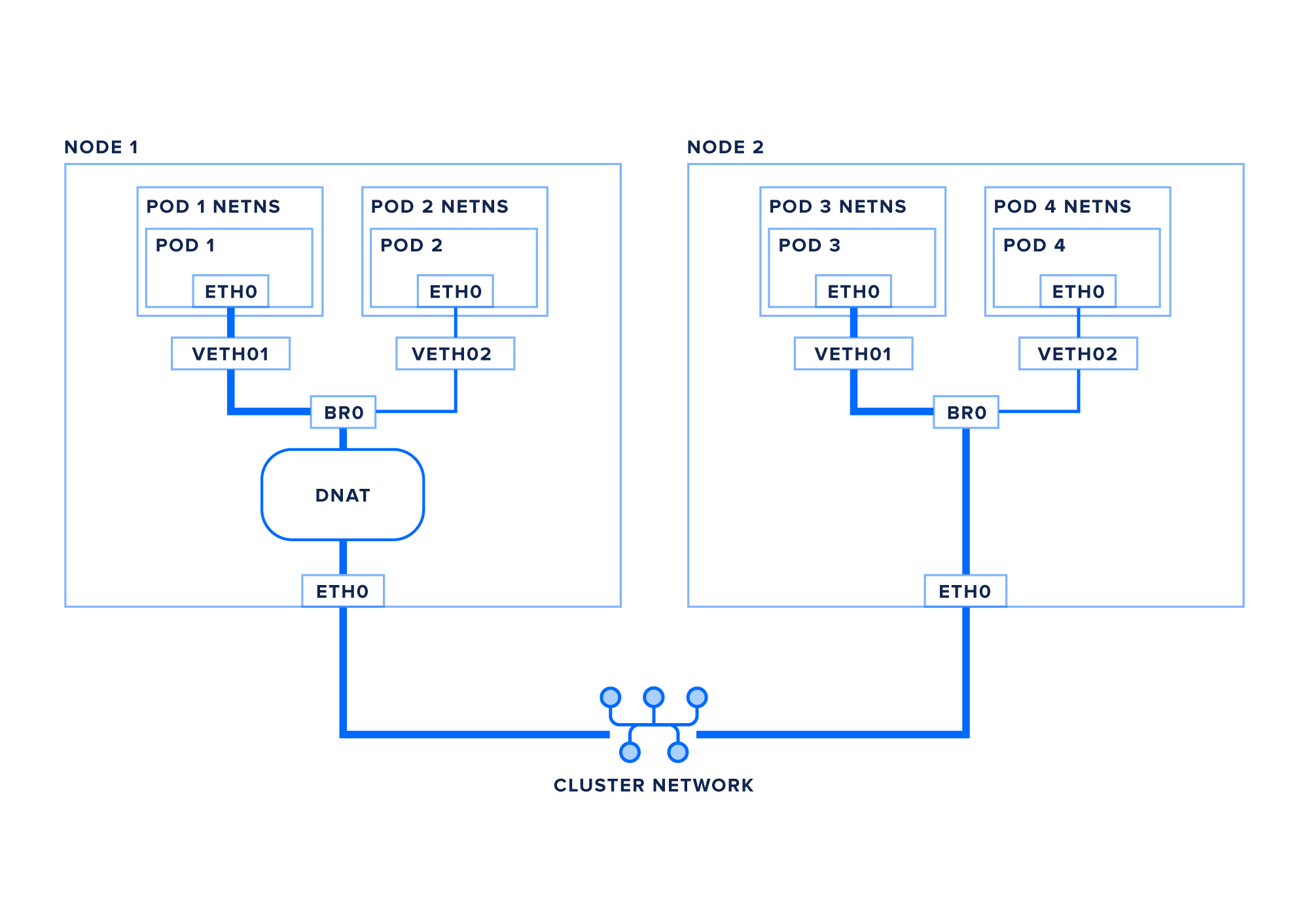
- ** pod1** 创建以** service1** 的IP作为其目的地的包
- 包通过虚拟醚网对到根网命名空间
- 包接通了桥br0
- 桥找不到本地接口来引导数据包, 因此数据包会被发送到 eth0 ** (_) 的默认路径 。 (
) 由
kube- proxy设置的 Ippables 或 IPVS , 匹配包的目的地 IP, 并将其从虚拟 IP 翻译为服务的一个 sock IP , 使用任意的负载平衡算法可用或指定( _) ( ) 可选: 您的包可能在此时被封装, 如上一节所讨论 - 数据包进入集群网络并被引导到正确的节点. (_) ( )* 包在eth0 上进入目的地节点* 可选: 如果您的包被封装, 它将在此点被去封装( ) * 包接通了桥br0
- 该包通过veth1()发送给虚拟醚网对. ( )* 该包通过虚拟醚网对并经由其进入被子网络命名空间 eth0 网络接口() (英语)
当包返回 node1时,VIP to pod IP 翻译将被逆转,并且包将通过桥梁和虚拟接口返回正确的pod。
结论
在本文中,我们审查了Kubernetes集群的内部网络基础设施,讨论了构成网络的构建块,并详细介绍了不同场景中包的跳跃之旅。
有关Kubernetes的更多信息,请参阅我们的Kubernetes教程标签(https://andsky.com/tags/kubernetes?type=tutorials)和官方Kubernetes文档(https://kubernetes.io/docs/home/)。