作者选择了 开源精神疾病以作为 写给捐赠计划的一部分获得捐赠。
介绍
神经网络在许多领域实现了最先进的准确性,如计算机视觉、自然语言处理和增强学习。然而,神经网络是复杂的,很容易包含数十万甚至数百万的操作([MFLOPs 或 GFLOPs])(https://en.wikipedia.org/wiki/FLOPS))。这种复杂性使得解释神经网络变得困难。例如:网络是如何到达最终预测的?输入的哪些部分影响了预测?这种缺乏理解对于像像这样的高维输入加剧了:图像分类的解释甚至是什么样子?
在这个教程中,你将特别探索两种类型的解释: 1. _Saliency 地图,突出输入图像的最重要的部分;和 2. _decision 树,将每个预测分解为一个中间决策序列。
沿途,您还将使用深度学习的Python库PyTorch,计算机视觉库OpenCV,线性算法库numpy。
前提条件
要完成本教程,您将需要以下内容:
您可以遵循 如何安装和设置Python 3的本地编程环境来配置您所需的一切 *建议您审查 构建基于情绪的狗过滤器;我们不会明确使用本教程,但如果需要,它会引入分类的概念 *还建议您审查 Bias-Variance Tradeoff来了解为什么模型复杂性不仅会损害解释性,而且可能会损害准确性
您可以在本教程中的所有代码和资产中找到(https://github.com/do-community/visualizing-neural-networks)。
步骤 1 – 创建您的项目和安装依赖
让我们为这个项目创建一个工作空间,并安装你需要的依赖,你将把你的工作空间称为XAI,简称可解释的人工智能:
1mkdir ~/XAI
导航到XAI目录:
1cd ~/XAI
创建一个目录,存储您的所有资产:
1mkdir ~/XAI/assets
然后为项目创建一个新的虚拟环境:
1python3 -m venv xai
激活你的环境:
1source xai/bin/activate
然后安装 PyTorch,您将在本教程中使用的Python深度学习框架。
在 macOS 上,使用以下命令安装 PyTorch:
1python -m pip install torch==1.4.0 torchvision==0.5.0
在 Linux 和 Windows 上,使用以下命令为仅 CPU 构建:
1pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
2pip install torchvision
现在为OpenCV、Pillow和numpy安装预先包装的二进制,它们分别是计算机视觉和线性 algebra的库。
1python -m pip install opencv-python==3.4.3.18 pillow==7.1.0 numpy==1.14.5 matplotlib==3.3.2
在Linux发行版中,您需要安装libSM.so:
1sudo apt-get install libsm6 libxext6 libxrender-dev
最后,安装nbdt,一个深度学习库用于神经系统支持的决策树,我们将在本教程的最后一步中讨论:
1python -m pip install nbdt==0.0.4
随着依赖性安装,让我们运行已经训练过的图像分类器。
步骤 2 - 运行预训练分类器
在此步骤中,您将设置已经训练过的图像分类器。
首先,一个 image classifier 接受图像作为输入,并输出一个预测的类(如猫或狗)。第二, pretained 意味着这个模型已经受过训练,并将能够准确地预测类,直接。
首先,下载一个 JSON 文件,将神经网络输出转换为人类可读的类名称:
1wget -O assets/imagenet_idx_to_label.json https://raw.githubusercontent.com/do-community/tricking-neural-networks/master/utils/imagenet_idx_to_label.json
下载下面的Python脚本,它会加载图像,加载神经网络及其重量,并使用神经网络来分类图像:
1wget https://raw.githubusercontent.com/do-community/tricking-neural-networks/master/step_2_pretrained.py
<$>[注] 注: 对于这个文件的更详细的步骤_2_pretrained.py,请参阅如何欺骗神经网络教程 中的 步骤 2 - 运行预训练动物分类器
接下来,您还将下载下面的猫和狗的图像,以运行图像分类器。

1wget -O assets/catdog.jpg https://assets.digitalocean.com/articles/visualize_neural_network/step2b.jpg
最后,在新下载的图像上运行预训练的图像分类器:
1python step_2_pretrained.py assets/catdog.jpg
这将产生以下输出,显示您的动物分类器按预期工作:
1[secondary_label Output]
2Prediction: Persian cat
这结束了与您的预先训练的模型进行推断。
虽然这个神经网络正确地产生预测,但我们不明白该模型是如何达到预测的。
图像分类器预测波斯猫。你可以问的一个问题是:模型在左边看猫? 或者在右边看狗? 该模型使用了哪些像素来做这个预测? 幸运的是,我们有一个可视化,可以回答这个确切的问题。

该模型将图像归类为波斯猫,通过观察猫。 对于本教程,我们将把像这个例子这样的可视化称为 saliency maps,我们将其定义为热地图,突出影响最终预测的像素。
这些方法不需要访问模型重量。一般来说,这些方法改变图像,并观察改变图像对准确性的影响。例如,你可能会删除图像的中心(如下图像)。直觉是:如果图像分类器现在错误分类图像,图像中心必须是重要的。我们可以重复这一点,并随机删除图像的一部分。这样,我们可以像以前一样制作热图,突出损坏精度最多的补丁

- ** 模型意识的 Saliency 地图** (通常被称为
白盒方法):这些方法需要访问模型的重量。
在下一步中,您将实施一种名为Class Activation Map(CAM)的模型意识技术。
步骤 3 – 生成类激活地图(CAM)
类激活地图(CAMs)是一种模型意识的突出方法. 要了解 CAM 是如何计算的,我们首先需要讨论分类网络中的最后几个层是怎么做的。
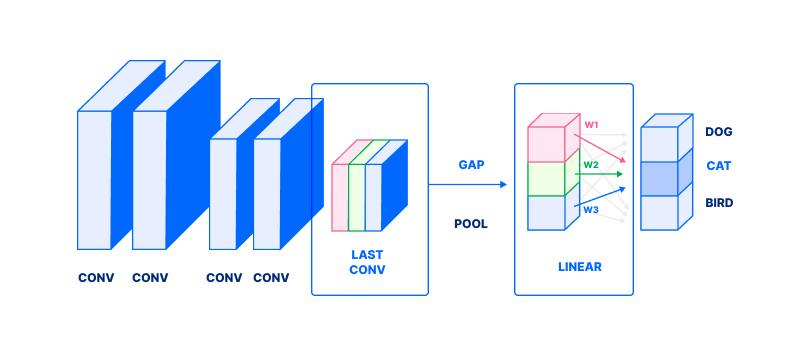
请注意,图像被表示为一堆直角;对于如何将图像作为压缩器表示的更新的信息,请参阅 如何在Python 3中构建一个以情绪为基础的狗过滤器(步骤 4):
注重第二到最后一层的输出,标记为 LAST CONV与蓝色、红色和绿色直角
2. 这个输出经过一个全球平均池(标记为 GAP)。 GAP平均值在每个渠道(彩色直角)产生一个单一值(相应的彩色框,在 LINEAR)。
3. 最后,这些值被组合成一个重量的总和(与重量标记为 w1, w2, w3)产生一个类的概率(暗灰色框)在这种情况下,这些重量相当于 CAT。 基本上,每个 wi回答:如何重要 **ith**频道检测一个 Cat?((M_BRK1_)4.
现在,我们可以用它来计算CAM. 让我们再看一遍这个数字的扩展版本,仍然在同一篇论文中的方法(https://arxiv.org/pdf/1512.04150.pdf)。
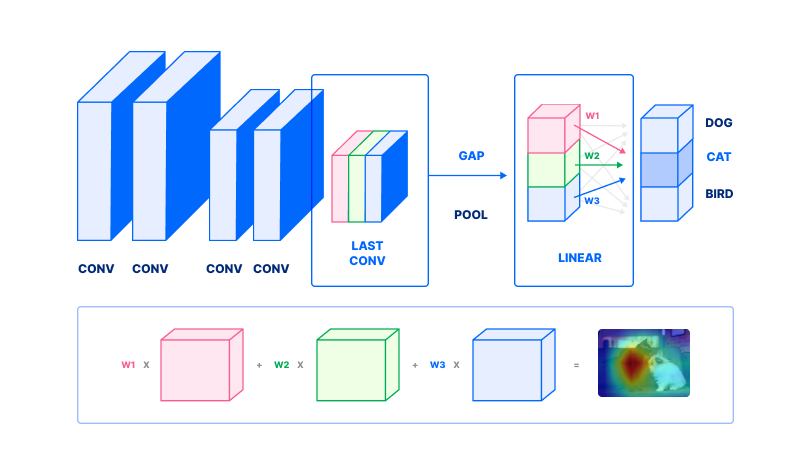
- 要计算一类激活地图,采取二层到最后一层的输出。这在第二行中描绘,由相应的蓝色,红色和绿色直角对应于第一行相同的彩色直角
2。 选择一类。 在这种情况下,我们选择
澳大利亚特里尔。 查找与该类相符的重量 w1, w2... wn3. 每个频道(彩色直角)随后被重量 w1, w2... wn。 注意我们不执行一个全球平均池(从上一个数字的步骤2)。 计算重量的总和,以获得一个激活地图(远右,第二行)。
这个最终加权的总和是类激活地图。
接下来,我们将实施类激活地图,本节将分为我们已经讨论的三个步骤:
- 取第二层到最后层的输出
- 查找重量
w1,w2...wn. - 计算出输出的重量总和
开始创建一个新的文件 step_3_cam.py:
1nano step_3_cam.py
首先,添加 Python 锅板;导入必要的包,并声明一个主要函数:
1[label step_3_cam.py]
2"""Generate Class Activation Maps"""
3import numpy as np
4import sys
5import torch
6import torchvision.models as models
7import torchvision.transforms as transforms
8import matplotlib.cm as cm
9
10from PIL import Image
11from step_2_pretrained import load_image
12
13def main():
14 pass
15
16if __name__ == '__main__':
17 main()
创建一个图像加载器,它会加载、调整尺寸和剪辑您的图像,但不会影响颜色。这确保您的图像具有正确的尺寸。
1[label step_3_cam.py]
2. . .
3def load_raw_image():
4 """Load raw 224x224 center crop of image"""
5 image = Image.open(sys.argv[1])
6 transform = transforms.Compose([
7 transforms.Resize(224), # resize smaller side of image to 224
8 transforms.CenterCrop(224), # take center 224x224 crop
9 ])
10 return transform(image)
11. . .
在load_raw_image中,您首先访问过的单个参数为sys.argv[1]脚本,然后打开使用Image.open指定的图像。
transforms.Resize(224):将图像的较小侧重调整为224。例如,如果您的图像为448 x 672,则此操作会将图像降示到224 x 336.transforms.CenterCrop(224):从图像的中心取出224 x 224的大小。
这就结束了图像加载。
接下来,加载预先训练的模型. 在第一个load_raw_image函数之后,但在main函数之前添加此函数:
1[label step_3_cam.py]
2. . .
3def get_model():
4 """Get model, set forward hook to save second-to-last layer's output"""
5 net = models.resnet18(pretrained=True).eval()
6 layer = net.layer4[1].conv2
7
8 def store_feature_map(self, _, output):
9 self._parameters['out'] = output
10 layer.register_forward_hook(store_feature_map)
11
12 return net, layer
13. . .
在get_model函数中,您:
- 实时预先训练的模型
models.resnet18(pretrained=True). - 通过调用
.eval()3 来改变模型的推断模式。 定义layer...,第二到最后的层,我们将在以后使用 - 添加一个
向前的链接函数。 这个函数在执行层时会保存层的输出。 我们在两个步骤中做到这一点,首先定义一个store_feature_map链接,然后将链接与register_forward_hook5 连接。 返回网络和第二到最后的层
这就结束了装载模式。
接下来,计算类激活地图本身,在主要函数之前添加此函数:
1[label step_3_cam.py]
2. . .
3def compute_cam(net, layer, pred):
4 """Compute class activation maps
5
6 :param net: network that ran inference
7 :param layer: layer to compute cam on
8 :param int pred: prediction to compute cam for
9 """
10
11 # 1. get second-to-last-layer output
12 features = layer._parameters['out'][0]
13
14 # 2. get weights w_1, w_2, ... w_n
15 weights = net.fc._parameters['weight'][pred]
16
17 # 3. compute weighted sum of output
18 cam = (features.T * weights).sum(2)
19
20 # normalize cam
21 cam -= cam.min()
22 cam /= cam.max()
23 cam = cam.detach().numpy()
24 return cam
25. . .
compute_cam函数反映了本节开始和前面的三个步骤。
- 取第二至最后一层的输出,使用功能地图,我们在
layer._parameters2中保存的前行链,以获取我们预测类的重量 3中找到w1,w2...wn的重量,在最终的线性层net.fc_parameters("weight"))中找到w1,w2...wn。 论点2意味着我们计算了指数2`尺寸的指数( _4)4中的重量,以便在预测类中获得重量 - 计算出输出的重量值在 0 和 1 之间,以便所有值在 cammin(); / cam=max
这结束了类激活地图的计算。
我们的最后一个辅助函数是一个实用程序,可以保存类激活地图,然后在主要函数之前添加此函数:
1[label step_3_cam.py]
2. . .
3def save_cam(cam):
4 # save heatmap
5 heatmap = (cm.jet_r(cam) * 255.0)[..., 2::-1].astype(np.uint8)
6 heatmap = Image.fromarray(heatmap).resize((224, 224))
7 heatmap.save('heatmap.jpg')
8 print(' * Wrote heatmap to heatmap.jpg')
9
10 # save heatmap on image
11 image = load_raw_image()
12 combined = (np.array(image) * 0.5 + np.array(heatmap) * 0.5).astype(np.uint8)
13 Image.fromarray(combined).save('combined.jpg')
14 print(' * Wrote heatmap on image to combined.jpg')
15. . .
此实用程序「save_cam」执行如下操作:
此外,输出(1)包含第四个alpha频道,(2)颜色频道以BGR为顺序。我们使用索引()来解决两个问题,放下alpha频道并逆转颜色频道的顺序为RGB。 最后,发射到未签名的整数
2.将图像Image.fromarray转换为PIL图像,并使用图像的图像重复实用程序resize(...),然后使用.save(...)实用程序 3. 使用实用程序load_raw_image将图像转换为我们之前写过的load_raw_image 4. 将图像的顶部加热到图像上,以0.5__1`的每个重量
接下来,用一些代码填充主函数,在提供的图像上运行神经网络:
1[label step_3_cam.py]
2. . .
3def main():
4 """Generate CAM for network's predicted class"""
5 x = load_image()
6 net, layer = get_model()
7
8 out = net(x)
9 _, (pred,) = torch.max(out, 1) # get class with highest probability
10
11 cam = compute_cam(net, layer, pred)
12 save_cam(cam)
13. . .
在主要中,运行网络以获取预测。
- 加载图像
- 获取预训练的神经网络
- 在图像上运行神经网络
- 用
torch.max找到最高概率。pred现在是最有可能类别的索引数 - 使用
compute_cam5 计算 CAM。
现在结束了我们的类激活脚本. 保存并关闭你的文件. 检查你的脚本是否匹配 step_3_cam.py 在这个存储库中 。
然后运行脚本:
1python step_3_cam.py assets/catdog.jpg
你的脚本将产生如下:
1[secondary_label Output]
2 * Wrote heatmap to heatmap.jpg
3 * Wrote heatmap on image to combined.jpg
这将产生类似于以下图像的heatmap.jpg和combined.jpg,显示与猫/狗图像相结合的热图和热图。
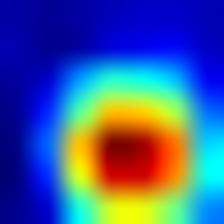

您已经制作了您的第一个突出地图,我们将用更多链接和资源来生成其他类型的突出地图结束这篇文章,同时,让我们探索第二种可解释的方法,即使模型本身能够被解释。
步骤4 – 使用神经元支持的决策树
决策树属于一个基于规则的模型家族,决策树是显示可能的决策路径的数据树,每个预测都是一系列预测的结果。
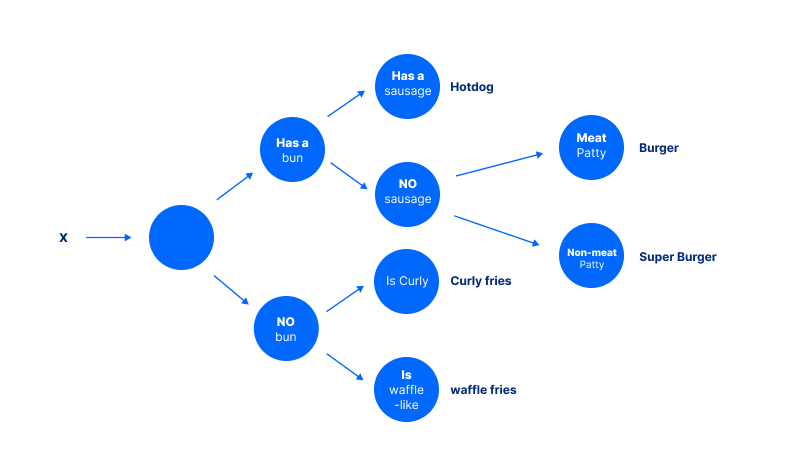
例如,为了得出这个数字的热狗结论,模型必须首先问:它是否有子?然后问:它是否有子?这些中间决策可以单独验证或挑战。
一个问题是:这些规则是如何创建的? 决策树要求自己进行更详细的讨论,但简而言之,规则是为了尽可能地分开类别而创建的。
现在,我们将继续使用神经网络和决策树混合物。 有关决策树的更多信息,请参阅 分类和回归树(CART)概述。
现在,我们将在神经网络和决策树混合物上进行推断,正如我们所发现的那样,这给了我们另一种解释性:直接模型解释性。
首先,创建一个名为「step_4_nbdt.py」的新文件:
1nano step_4_nbdt.py
首先,添加 Python 锅板. 导入必要的包,并声明一个主要函数. `maybe_install_wordnet’ 设定了一个前提条件,我们的程序可能需要:
1[label step_4_nbdt.py]
2"""Run evaluation on a single image, using an NBDT"""
3
4from nbdt.model import SoftNBDT, HardNBDT
5from pytorchcv.models.wrn_cifar import wrn28_10_cifar10
6from torchvision import transforms
7from nbdt.utils import DATASET_TO_CLASSES, load_image_from_path, maybe_install_wordnet
8import sys
9
10maybe_install_wordnet()
11
12def main():
13 pass
14
15if __name__ == '__main__':
16 main()
首先,像以前一样,加载预训练的模型,然后在主要函数之前添加以下内容:
1[label step_4_nbdt.py]
2. . .
3def get_model():
4 """Load pretrained NBDT"""
5 model = wrn28_10_cifar10()
6 model = HardNBDT(
7 pretrained=True,
8 dataset='CIFAR10',
9 arch='wrn28_10_cifar10',
10 model=model)
11 return model
12. . .
这个函数执行如下:
- 创建一个名为 WideResNet 的新模型
wrn28_10_cifar10(). - 然后,它创建了该模型的神经支持的决策树变体,用
HardNBDT(..., model=model)包装。
这就结束了装载模式。
接下来,加载并预处理模型推断图像,然后在主要函数之前添加以下内容:
1[label step_4_nbdt.py]
2. . .
3def load_image():
4 """Load + transform image"""
5 assert len(sys.argv) > 1, "Need to pass image URL or image path as argument"
6 im = load_image_from_path(sys.argv[1])
7 transform = transforms.Compose([
8 transforms.Resize(32),
9 transforms.CenterCrop(32),
10 transforms.ToTensor(),
11 transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
12 ])
13 x = transform(im)[None]
14 return x
15. . .
在load_image中,您首先从提供的 URL 上加载图像,使用名为load_image_from_path的自定义实用方法。
例如,如果您的图像是 448 x 672,则此操作将图像降示为 32 x 48
transforms.CenterCrop(224):从图像的中心,大小为 32 x 32transforms.ToTensor():将图像转换为 PyTorch 紧张器。所有 PyTorch 模型都需要 PyTorch 紧张器作为输入transforms.Normalize(mean=..., std=...):通过抽取平均值,然后通过标准偏差来标准化您的输入。
最后,将图像转换应用于图像transform(im)[None]。
接下来,定义一个实用函数来记录预测和导致它的中间决策。
1[label step_4_nbdt.py]
2. . .
3def print_explanation(outputs, decisions):
4 """Print the prediction and decisions"""
5 _, predicted = outputs.max(1)
6 cls = DATASET_TO_CLASSES['CIFAR10'][predicted[0]]
7 print('Prediction:', cls, '// Decisions:', ', '.join([
8 '{} ({:.2f}%)'.format(info['name'], info['prob'] * 100) for info in decisions[0]
9 ][1:])) # [1:] to skip the root
10. . .
print_explanations函数计算和记录预测和决定:
- 开始计算最高概率类的索引
outputs.max(1). - 然后,它将该预测转换为可读的人类类名称,使用字典
DATASET_TO_CLASSES['CIFAR10'][predicted[0]]. - 最后,它打印了预测
cls和决定info['name'], info['prob'....
通过填充我们迄今为止所写的实用工具的主要来完成脚本:
1[label step_4_nbdt.py]
2. . .
3def main():
4 model = get_model()
5 x = load_image()
6 outputs, decisions = model.forward_with_decisions(x) # use `model(x)` to obtain just logits
7 print_explanation(outputs, decisions)
我们在几个步骤中执行模型推断,并提供解释:
- 加载模型
get_model. - 加载图像
load_image. - 运行模型推断
model.forward_with_decisions. - 最后,打印预测和解释
print_explanations.
关闭你的文件,并双检查你的文件内容匹配 step_4_nbdt.py。
1python step_4_nbdt.py assets/catdog.jpg
这将产生如下,预测和相应的理由。
1[secondary_label Output]
2Prediction: cat // Decisions: animal (99.34%), chordate (92.79%), carnivore (99.15%), cat (99.53%)
这结束了神经元支持的决策树部分。
结论
你现在运行了两种类型的可解释的AI方法:像突出地图这样的后期解释和使用基于规则的系统进行修改的可解释模型。
对于进一步的阅读,请确保查看其他方式来可视化和解释神经网络;实用工具数量众多,从调试到消除灾难性错误,以避免灾难性错误。
- 其他模型意识的突出方法: Grad-CAM:从深层网络通过基于格拉迪恩的本地化论文的视觉解释, Grad-CAM++:改进的视觉解释 Deep Convolutional Networks,和这个代码在Pytorch存储中的Grad-CAM实现(https://github.com/jacobgil/pytorch-grad-cam) 。 模型突出方法: RISE, LIME,以及在PyTorch存储中的LIME实现(https://github.com/marcotcr/lime). 模型可以通过神经网络和决策树混合物进行解释: Neural-Backed Decisiones, [Deepural