作者选择了 开放式互联网 / 自由言论基金作为 写给捐赠计划的一部分接受捐款。
介绍
Database sharding是将通常在同一表或集合中保持的记录分割成多个机器,称为 shards。
在本教程中,您将学习如何部署两个碎片的碎片 MongoDB 集群.本指南还将概述如何选择合适的碎片密钥,以及如何验证您的 MongoDB 文档是否正確地和均匀地分布在碎片中。
<$>[警告] 警告:本指南的目的是描述如何在MongoDB中分解工作。 为此,它展示了如何快速设置和运行分解群集用于开发环境。
此外,MongoDB 建议分裂集群的分裂服务器和配置服务器都部署为至少有三名成员的复制集合,然而,为了使分裂集群快速运行,本指南概述了如何将这些组件部署为单节复制集合。
如果您打算在生产环境中使用碎片集群,我们强烈建议您查看有关 [内部/会员身份验证] 的官方 MongoDB 文档(https://docs.mongodb.com/manual/core/security-internal-authentication/),以及我们关于 [如何在 Ubuntu 20.04 上配置 MongoDB 复制集合] 的教程(https://andsky.com/tech/tutorials/how-to-configure-a-mongodb-replica-set-on-ubuntu-20-04)。
前提条件
要遵循本教程,您将需要:
- 四个单独的服务器. 每个服务器都应该有一个常规的非根用户,具有
sudo特权和与UFW配置的防火墙。 本教程是通过使用运行Ubuntu 20.04的四个服务器进行验证的,您可以通过遵循此(Ubuntu 20.04的初始服务器安装教程)(https://andsky.com/tech/tutorials/initial-server-setup-with-ubuntu-20-04)在每个服务器上 *MongoDB安装在每个服务器上。 要设置此,请遵循我们的教程(如何在Ubuntu 20.04上安装MongoDB)(https://andsky.com/tech/tutorials/how-to-install-mongodb-on-ubuntu-20-04)对每个服务器 - 您的所有四个服务器都配置了对每个其他实例的远程访问。 为此,请遵循我们的教程(如何在Ubuntu 20.0
<$>[注] **注:**有关如何配置服务器,安装MongoDB,然后允许远程访问MongoDB的链接教程都参考Ubuntu 20.04.本教程专注于MongoDB本身,而不是潜在的操作系统。
为了澄清,本教程将参考以下四个服务器:
- mongo-config,它将作为集群的配置服务器
- mongo-shard1和 mongo-shard2,它将作为数据实际分布的碎片服务器
- mongo-router,它将运行一个
mongos实例并作为碎片集群的查询路由器
有关这些角色是什么以及它们如何在碎片 MongoDB 集群中运作的更多细节,请阅读以下关于理解 MongoDB 的碎片 Topology 的部分。
必须在 mongo-config上执行的命令将具有蓝色背景,如下:
1[environment second]
必须在 mongo-shard1上执行的命令将具有红色背景:
1[environment third]
在 mongo-shard2上运行的命令将具有绿色背景:
1[environment fourth]
并且 mongo-router服务器的命令将具有紫色背景:
1[environment fifth]
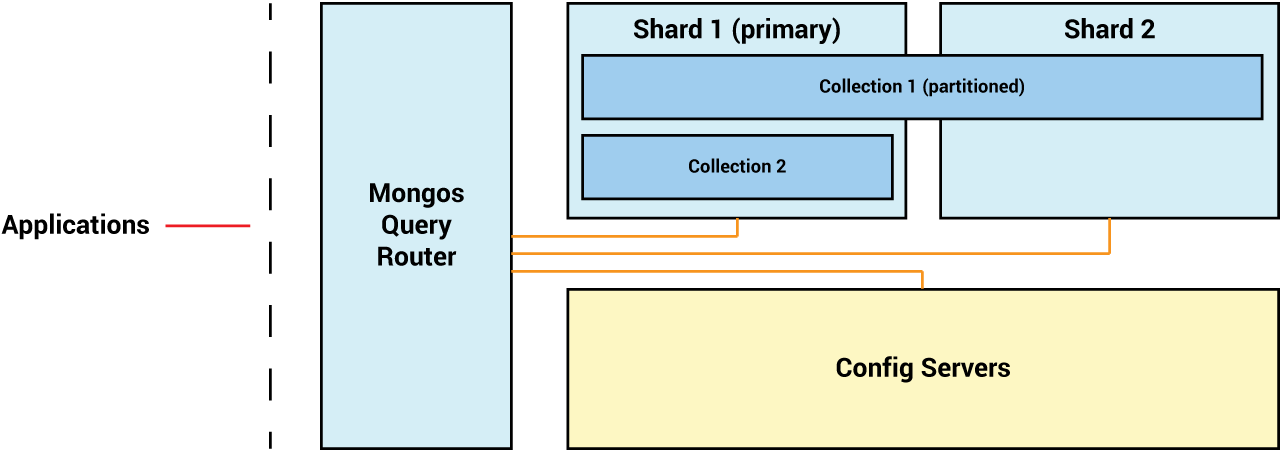
了解 MongoDB 的 Sharding Topology
当您使用独立的 MongoDB 数据库服务器工作时,您连接到该实例并使用它来直接管理您的数据. 在一个未分割的复制集中,您连接到群集的主要成员,并且您对数据的任何更改都会自动转移到群集的次要成员。
Sharding 旨在帮助水平扩展,也被称为 escaling out,因为它将从一个数据集分成多个机器的记录。如果工作负载变得太大,以便您的群集中的碎片,您可以通过添加另一个单独的碎片来扩展您的数据库,以承担部分工作。
由于数据在分布式数据库架构中被物理地分为多个数据库节点,有些文档只在一个节点上可用,而其他文档则位于另一个服务器上。
为了减轻这些风险,MongoDB中的碎片集群由三个单独的组件组成:
每个shard服务器必须始终作为复制集部署,必须在shard集群中至少有一个shard,但要从sharding中获取任何好处,你需要至少两个 *集群的 _config服务器是一个存储sharded集群的元数据和配置设置的MongoDB实例,集群使用此元数据用于设置和管理目的,就像shard服务器一样,配置服务器必须作为复制集部署,以确保这个元数据仍然高度可用 *mongos是一个特殊类型的MongoDB实例,它作为一个查询路由器。
由于 MongoDB 中的分割是在集合层面进行的,所以单个数据库可以包含分割和未分割集合的混合物. 虽然分割集合被分割和分布在集群的多个分割中,但一个分割总是被选为主要分割。
由于每个应用连接都必须通过mongos实例,因此mongos查询路由器负责使所有数据始终可用并分布在单个片段中。
步骤 1 — 设置一个 MongoDB 配置服务器
完成前提后,您将有四个 MongoDB 安装在四个单独的服务器上运行。 在此步骤中,您将将其中一个实例 mongo-config转换为可用于测试或开发的复制集。
<$>[警告] 警告:从 MongoDB 3.6 开始,单个碎片和配置服务器都必须作为复制集部署。建议在生产环境中始终具有至少三名成员的复制集。使用三名或以上成员的复制集有助于保持数据的可用性和安全性,但这也大大增加了分裂架构的复杂性。
为了重申先前介绍中所述的警告,本指南概述了如何快速安装和运行分裂集群,因此,它概述了如何使用分裂服务器和配置服务器部署分裂集群,每个集合由单节点复制组成。
在 mongo-config上,打开您喜爱的文本编辑器中的 MongoDB 配置文件。
1[environment second]
2sudo nano /etc/mongod.conf
查找配置部分,这些行向文件底部读取#复制:和#sharding::
1[environment second]
2[label /etc/mongod.conf]
3
4. . .
5#replication:
6
7#sharding:
然后在复制:线下添加一个replSetName指令,然后添加一个名称 MongoDB 将用来识别复制集。
1[environment second]
2[label /etc/mongod.conf]
3. . .
4replication:
5 replSetName: "config"
6
7#sharding:
8. . .
请注意,新replSetName指令之前有两个空格,其config值被引用标记包装。
接下来,在接下来的行后,添加一个具有configsvr值的clusterRole指令:
1[environment second]
2[label /etc/mongod.conf]
3. . .
4replication:
5 replSetName: "config"
6
7sharding:
8 clusterRole: configsvr
9. . .
clusterRole指令告诉MongoDB,这个服务器将是分裂集群的一部分,并将扮演 config 服务器的角色(如configsvr值所示)。
<$>[注]
**注:当复制和安全线在mongod.conf文件中被启用时,MongoDB还要求您配置其他身份验证手段,如加密身份验证或设置x.509证书。
而不是设置更高级的安全措施,为本教程的目的,在你的mongod.conf文件中禁用安全块是明智的。
1[label /etc/mongod.conf]
2. . .
3
4#security:
5# authorization: enabled
6
7. . .
但是,如果您打算在未来使用此MongoDB实例来存储任何敏感数据, ** 请确保删除这些行以重新启用身份验证** <$>
在更新文件的这两个部分后,保存并关闭文件. 如果您使用了nano,您可以通过按CTRL + X,Y,然后按ENTER来完成此操作。
然后,重新启动mongod服务:
1[environment second]
2sudo systemctl restart mongod
因此,您已为服务器启用复制功能,但MongoDB实例尚未复制任何数据,您需要通过MongoDB壳启动复制功能,因此使用以下命令打开它:
1[environment second]
2mongo
从 MongoDB 壳提示,运行以下命令来启动此复制集:
1[environment second]
2rs.initiate()
此命令将以 MongoDB 服务器推断的默认配置开始复制。当设置由多个单独服务器组成的复制集时,就像你部署一个生产准备的复制集一样,你会将文档传输到描述新复制集的配置的 `rs.initiate() 方法。
MongoDB 会自动从运行配置中读取复制件集名及其在碎片集群中的作用. 如果该方法在输出中返回OK : 1,则意味着复制件集已成功启动:
1[environment second]
2[secondary_label Output]
3{
4 "info2" : "no configuration specified. Using a default configuration for the set",
5 . . .
6 "ok" : 1,
7 . . .
8}
假设是这样的情况,您的 MongoDB 壳提示将更改,表示该壳的实例已连接到现在是rs0复制组的一员:
1[environment second]
此新提示的第一个部分将是您之前配置的复制组的名称。
请注意,本示例提示的第二部分显示该 MongoDB 实例是复制组的次要成员,这是可以预期的,因为通常在复制组启动的时间和其成员之一成为主要成员的时间之间存在差距。
如果您要运行命令,甚至仅仅在等待几分钟后按ENTER,提示会更新以反映您已连接到复制组的主要成员:
1[environment second]
您可以通过在 MongoDB 壳中执行以下命令来验证复制件集是否正确配置:
1[environment second]
2rs.status()
这将返回很多关于复制组配置的输出,但一些关键是特别重要的:
1[environment second]
2[secondary_label Output]
3{
4 . . .
5 "set" : "config",
6 . . .
7 "configsvr" : true,
8 "ok" : 1,
9 . . .
10}
「設定」鍵顯示了複製集的名稱,這在本例中是「config」。「configsvr」鍵顯示了它是否是一個 config 伺服器複製集中的集合,在這種情況下顯示了「真」。
在此步骤中,您已为分裂集群中的配置服务器配置了第一个复制集合,在下一步中,您将对两个单独的分裂集合进行类似的配置。
步骤 2 — 配置 Shard 服务器复制集
在完成前一步后,您将有一个完全配置的复制集,可以作为分裂集群的配置服务器。 在此步骤中,您将将 mongo-shard1 和 mongo-shard2 实例转换为复制集。
要设置此设置,您需要对 mongo-shard1和 mongo-shard2的配置文件进行一些更改,因为您正在设置两个单独的复制集,但是每个配置将使用不同的复制集名称。
**在mongo-shard1和mongo-shard2上,请在您偏好的文本编辑器中打开MongoDB配置文件:
1[environment third]
2sudo nano /etc/mongod.conf
1[environment fourth]
2sudo nano /etc/mongod.conf
查找配置部分,这些行在文件的底部读取#replication:和#sharding:。
1[label /etc/mongod.conf]
2#replication:
3
4#sharding:
在两种配置文件中,通过删除英镑符号(#)来解析#replication:``行。然后,在replication:``行下面添加一个replSetName指令,其次是MongoDB的名称将用于识别复制组。
1[environment third]
2[label /etc/mongod.conf]
3. . .
4replication:
5 replSetName: "shard1"
6
7#sharding:
8. . .
1[environment fourth]
2[label /etc/mongod.conf]
3. . .
4replication:
5 replSetName: "shard2"
6
7#sharding:
8. . .
然后对#sharding:行进行评论,并在每个配置文件中在该行下方添加一个clusterRole指令. 在两个文件中,将clusterRole指令值设置为shardsvr。
1[environment third]
2[label /etc/mongod.conf]
3. . .
4replication:
5 replSetName: "shard1"
6
7sharding:
8 clusterRole: shardsvr
9. . .
1[environment fourth]
2[label /etc/mongod.conf]
3. . .
4replication:
5 replSetName: "shard2"
6
7sharding:
8 clusterRole: shardsvr
9. . .
更新这两个文件部分后,保存并关闭文件,然后在两个服务器上重新启动mongod服务,发出以下命令:
1[environment third]
2sudo systemctl restart mongod
1[environment fourth]
2sudo systemctl restart mongod
与您在上一步设置的 config 服务器一样,这些复制集也必须通过 MongoDB 壳进行启动,才能使用。
1[environment third]
2mongo
1[environment fourth]
2mongo
要重申,本指南概述了如何部署一个分裂集群,其中包含一个配置服务器和两个分裂服务器,这些服务器都由单节点复制集组成。
由于您正在设置这些 MongoDB 实例以作为单节点复制集的功能,您可以通过执行 rs.initiate() 方法在两个分割服务器上启动复制 **,而无需任何进一步的论点:
1[environment third]
2rs.initiate()
1[environment fourth]
2rs.initiate()
如果这些命令在输出中返回OK : 1,则意味着初始化成功:
1[environment third]
2[secondary_label Output]
3{
4 "info2" : "no configuration specified. Using a default configuration for the set",
5 . . .
6 "ok" : 1,
7 . . .
8}
1[environment fourth]
2[secondary_label Output]
3{
4 "info2" : "no configuration specified. Using a default configuration for the set",
5 . . .
6 "ok" : 1,
7 . . .
8}
與 config 伺服器複製集一樣,這些 shard 伺服器的每一個都會在幾分鐘後被選為主要成員,儘管他們的提示可能首先讀到「SECONDARY>」,但如果您在幾分鐘後按下 shell 中的「ENTER」鍵,則提示會改變以確認每個伺服器是各自複製集合的主要實例。兩個部分上的提示只會以名稱為別,其中一個表示「shard1:PRIMARY>」,另一個表示「shard2:PRIMARY>」。
您可以通过在 MongoDB 壳中执行 rs.status() 方法来验证每个复制组是否正确配置。
1[environment third]
2rs.status()
如果此方法的输出包含OK : 1,则意味着复制组正常运作:
1[environment third]
2[secondary_label Output]
3{
4 . . .
5 "set" : "shard1",
6 . . .
7 "ok" : 1,
8 . . .
9}
在 mongo-shard2上执行相同的命令会显示不同的复制组名称,但否则将几乎相同:
1[environment fourth]
2rs.status()
1[environment fourth]
2[secondary_label Output]
3{
4 . . .
5 "set" : "shard2",
6 . . .
7 "ok" : 1,
8 . . .
9}
因此,您已成功将 mongo-shard1 和 mongo-shard2 配置为单节点复制集,但在此时,无论是这两个复制集还是您在上一步创建的 config 服务器复制集都彼此不知道。
步骤 3 – 运行mongos并将碎片添加到集群中
您迄今为止配置的三个复制集,一个 config 服务器和两个单独的碎片,目前正在运行,但尚未成为一个碎片集群的一部分。 要将这些组件作为碎片集群的一部分连接,您需要另一个工具:一个mongos查询路由器。
您将使用您的第四个和最后的 MongoDB 服务器 - mongo-router - 运行mongos并作为您的碎片集群的查询路由器。
首先,连接到 mongo-router服务器,并停止运行 MongoDB 数据库服务:
1[environment fifth]
2sudo systemctl stop mongod
由于此服务器不会作为数据库本身,因此,在服务器启动时,禁用mongod服务:
1[environment fifth]
2sudo systemctl disable mongod
现在,运行mongos,并将其连接到 config 服务器复制组,使用以下命令:
1[environment fifth]
2mongos --configdb config/mongo_config_ip:27017
这个命令的连接字符串的第一个部分,config是您之前定义的复制品的名称,如果不同,请确保更改这个名称,并将mongo_config_ip更新到您的 mongo-config服务器的IP地址。
默认情况下,mongos在前台运行,仅与本地接口结合,从而不允许远程连接.除了限制所有服务器之间的流量的防火墙设置之外,没有额外的安全配置,这是一个强大的安全措施。
<$>[注] 注: 在 MongoDB 中,通常会区分 Config 服务器和 Shard 服务器运行的端口,而「27019」通常用于 Config 服务器复制集和「27018」用于 Shards。
之前的mongos命令将以类似系统日志的格式生成简洁而详细的输出。
1[environment fifth]
2[secondary_label Output]
3{"t":{"$date":"2021-11-07T15:58:36.278Z"},"s":"W", "c":"SHARDING", "id":24132, "ctx":"main","msg":"Running a sharded cluster with fewer than 3 config servers should only be done for testing purposes and is not recommended for production."}
4. . .
这意味着查询路由器已正确连接到 config 服务器副本设置,并注意到它只使用单个节点构建,这种配置 不建议用于生产环境。
<$>[注]
**注:**虽然在前沿运行,如此是其默认行为,但mongos通常以系统d等过程运行为戴蒙。
运行mongos作为系统服务超出本教程的范围,但我们鼓励您通过阅读官方文档(https://docs.mongodb.com/manual/reference/program/mongos/)来了解更多有关使用和管理mongos查询路由器的信息。
现在您可以将您之前配置的碎片添加到碎片集群中,因为mongos在前面运行,因此 **打开与mongo-router连接的另一个壳窗口。
1[environment fifth]
2mongo
此命令将打开连接到本地 MongoDB 实例的 MongoDB 壳,而不是 MongoDB 服务器,而是运行的mongos查询路由器。
您可以通过运行 sh.status() 方法来验证查询路由器是否连接到 config 服务器:
1[environment fifth]
2sh.status()
此命令返回分割集群的当前状态 在此时,它将在分割键中显示连接分割的空列表:
1[environment fifth]
2[secondary_label Output]
3--- Sharding Status ---
4 sharding version: {
5 "_id" : 1,
6 "minCompatibleVersion" : 5,
7 "currentVersion" : 6,
8 "clusterId" : ObjectId("6187ea2e3d82d39f10f37ea7")
9 }
10 shards:
11 active mongoses:
12 autosplit:
13 Currently enabled: yes
14 balancer:
15 Currently enabled: yes
16 Currently running: no
17 Failed balancer rounds in last 5 attempts: 0
18 Migration Results for the last 24 hours:
19 No recent migrations
20 databases:
21 { "_id" : "config", "primary" : "config", "partitioned" : true }
22 . . .
在本示例中,shard1是第一个shard的复制设置名称,而mongo_shard1_ip是运行该shard mongo-shard1的服务器的IP地址:
1[environment fifth]
2sh.addShard("shard1/mongo_shard1_ip:27017")
此命令會返回成功訊息:
1[environment fifth]
2[secondary_label Output]
3{
4 "shardAdded" : "shard1",
5 "ok" : 1,
6 "operationTime" : Timestamp(1636301581, 6),
7 "$clusterTime" : {
8 "clusterTime" : Timestamp(1636301581, 6),
9 "signature" : {
10 "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
11 "keyId" : NumberLong(0)
12 }
13 }
14}
然后再添加第二个碎片:
1[environment fifth]
2sh.addShard("shard2/mongo_shard2_ip:27017")
请注意,不仅此命令中的 IP 地址不同,而且复制的设置名称也不同。
1[environment fifth]
2[secondary_label Output]
3{
4 "shardAdded" : "shard2",
5 "ok" : 1,
6 "operationTime" : Timestamp(1639724738, 6),
7 "$clusterTime" : {
8 "clusterTime" : Timestamp(1639724738, 6),
9 "signature" : {
10 "hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
11 "keyId" : NumberLong(0)
12 }
13 }
14}
您可以通过再次发出 sh.status() 命令来检查是否已正确添加了两个片段:
1[environment fifth]
2sh.status()
1[environment fifth]
2[secondary_label Output]
3--- Sharding Status ---
4 sharding version: {
5 "_id" : 1,
6 "minCompatibleVersion" : 5,
7 "currentVersion" : 6,
8 "clusterId" : ObjectId("6187ea2e3d82d39f10f37ea7")
9 }
10 shards:
11 { "_id" : "shard1", "host" : "shard1/mongo_shard1_ip:27017", "state" : 1 }
12 { "_id" : "shard2", "host" : "shard2/mongo_shard2_ip:27017", "state" : 1 }
13 active mongoses:
14 "4.4.10" : 1
15 autosplit:
16 Currently enabled: yes
17 balancer:
18 Currently enabled: yes
19 Currently running: no
20 Failed balancer rounds in last 5 attempts: 0
21 Migration Results for the last 24 hours:
22 No recent migrations
23 databases:
24 { "_id" : "config", "primary" : "config", "partitioned" : true }
25 . . .
有了它,你有一个完全工作的分裂集群,由两个上行分裂组成,在下一步中,你将创建一个新的数据库,启用数据库的分裂,并开始在集合中分裂数据。
步骤 4 – 分区数据收集
每个分割 MongoDB 集群中的一个分区将被选为集群的主要分区,除了在集群中的每个分区中存储的分区数据外,主要分区还负责存储任何非分区数据。
在此时,您可以自由使用mongos查询路由器与数据库,文档和集合工作,就像您在典型的未分割的数据库中一样。
为了充分利用您的 MongoDB 集群,您必须为集群中的数据库启用 sharding. MongoDB 数据库只能包含 sharded 集合,如果它已启用 sharding。
要更好地了解 MongoDB 的数据分区行为,您需要一组可以使用的文档。本指南将使用代表世界上一些人口最多的城市的文档集合。
1[label The Tokyo document]
2{
3 "name": "Tokyo",
4 "country": "Japan",
5 "continent": "Asia",
6 "population": 37.400
7}
您将将这些文档存储在一个名为人口的数据库和一个名为城市的集合中。
在明确创建数据库之前,您可以启用数据库的 sharding。
1[environment fifth]
2sh.enableSharding("populations")
命令會返回成功訊息:
1[environment fifth]
2[secondary_label Output]
3{
4 . . .
5 "ok" : 1,
6 . . .
7}
现在数据库已配置为允许分区,您可以启用城市集合的分区。
MongoDB 提供两种方法来分解集合,并确定哪些文档将存储在哪个分布式: ranged sharding和 hashed sharding.本指南专注于如何实施分布式分布式,其中 MongoDB 在已选择为群集的分布式密钥的字段上保持自动分布式索引。
在实施基于哈希的 sharding 策略时,数据库管理员有责任选择合适的 shard 密钥。
在 MongoDB 中,一个作为 shard 密钥的文档字段应该遵循以下原则:
- 联合国 所选领域应当具有高度的至高无上性,即它可以具有许多可能的价值。 每个添加到集合中的文档最终都会被存储在一个单块的硬块上,因此如果被选为硬键的字段将只有几个可能的值,在集群中加入更多的硬块不会有利于性能. 考虑到 " 人口 " 数据库的例子, " 大陆 " 字段不是一个好的硬键,因为它只能包含几个可能的值。 () ( )* 硬键应具有较低的重复值频率. 如果大多数文档都共享用作硬键的字段的重复值,那么很可能会使用一些硬块来存储比其他的多的数据. 在整个收藏中,被磨损的密钥中数值的分布越平,就越好。 ( ( )* 硬密钥应有助于查询。 例如,一个经常被作为查询过滤器的字段对于一个硬键来说是一个很好的选择. 在一个已磨损的集群中,查询路由器使用单个磨损来返回查询结果,只有在查询中包含磨损的密钥. 否则,该查询会被广播到所有shards进行评价,尽管返回的文档将来自单一shard. 因此,`人口 ' 领域不是最佳的关键,因为大多数查询不太可能涉及精确的人口值过滤。 (_) (英语)
对于本指南中使用的示例数据,该国家名称字段对于集群的碎片密钥来说是一个很好的选择,因为它具有最高的所有字段的核心性,这些字段在过滤查询中很可能经常使用。
将尚未创建的城市集合分割为国家字段,运行以下shardCollection()方法:
1[environment fifth]
2sh.shardCollection("populations.cities", { "country": "hashed" })
此命令的第一部分指的是人口数据库中的城市集合,而第二部分则使用哈希分区方法选择国家作为分割键。
命令會返回成功訊息:
1[environment fifth]
2[secondary_label Output]
3{
4 "collectionsharded" : "populations.cities",
5 "collectionUUID" : UUID("03823afb-923b-4cd0-8923-75540f33f07d"),
6 "ok" : 1,
7 . . .
8}
现在,您可以将一些样本文档插入碎片集群. 首先,切换到人口数据库:
1[environment fifth]
2use populations
然后使用以下insertMany命令插入 20 个样本文档:
1[environment fifth]
2db.cities.insertMany([
3 {"name": "Seoul", "country": "South Korea", "continent": "Asia", "population": 25.674 },
4 {"name": "Mumbai", "country": "India", "continent": "Asia", "population": 19.980 },
5 {"name": "Lagos", "country": "Nigeria", "continent": "Africa", "population": 13.463 },
6 {"name": "Beijing", "country": "China", "continent": "Asia", "population": 19.618 },
7 {"name": "Shanghai", "country": "China", "continent": "Asia", "population": 25.582 },
8 {"name": "Osaka", "country": "Japan", "continent": "Asia", "population": 19.281 },
9 {"name": "Cairo", "country": "Egypt", "continent": "Africa", "population": 20.076 },
10 {"name": "Tokyo", "country": "Japan", "continent": "Asia", "population": 37.400 },
11 {"name": "Karachi", "country": "Pakistan", "continent": "Asia", "population": 15.400 },
12 {"name": "Dhaka", "country": "Bangladesh", "continent": "Asia", "population": 19.578 },
13 {"name": "Rio de Janeiro", "country": "Brazil", "continent": "South America", "population": 13.293 },
14 {"name": "São Paulo", "country": "Brazil", "continent": "South America", "population": 21.650 },
15 {"name": "Mexico City", "country": "Mexico", "continent": "North America", "population": 21.581 },
16 {"name": "Delhi", "country": "India", "continent": "Asia", "population": 28.514 },
17 {"name": "Buenos Aires", "country": "Argentina", "continent": "South America", "population": 14.967 },
18 {"name": "Kolkata", "country": "India", "continent": "Asia", "population": 14.681 },
19 {"name": "New York", "country": "United States", "continent": "North America", "population": 18.819 },
20 {"name": "Manila", "country": "Philippines", "continent": "Asia", "population": 13.482 },
21 {"name": "Chongqing", "country": "China", "continent": "Asia", "population": 14.838 },
22 {"name": "Istanbul", "country": "Turkey", "continent": "Europe", "population": 14.751 }
23])
输出将类似于典型的 MongoDB 输出,因为从用户的角度来看,碎片集群的行为就像一个正常的 MongoDB 数据库:
1[environment fifth]
2[secondary_label Output]
3{
4 "acknowledged" : true,
5 "insertedIds" : [
6 ObjectId("61880330754a281b83525a9b"),
7 ObjectId("61880330754a281b83525a9c"),
8 ObjectId("61880330754a281b83525a9d"),
9 ObjectId("61880330754a281b83525a9e"),
10 ObjectId("61880330754a281b83525a9f"),
11 ObjectId("61880330754a281b83525aa0"),
12 ObjectId("61880330754a281b83525aa1"),
13 ObjectId("61880330754a281b83525aa2"),
14 ObjectId("61880330754a281b83525aa3"),
15 ObjectId("61880330754a281b83525aa4"),
16 ObjectId("61880330754a281b83525aa5"),
17 ObjectId("61880330754a281b83525aa6"),
18 ObjectId("61880330754a281b83525aa7"),
19 ObjectId("61880330754a281b83525aa8"),
20 ObjectId("61880330754a281b83525aa9"),
21 ObjectId("61880330754a281b83525aaa"),
22 ObjectId("61880330754a281b83525aab"),
23 ObjectId("61880330754a281b83525aac"),
24 ObjectId("61880330754a281b83525aad"),
25 ObjectId("61880330754a281b83525aae")
26 ]
27}
然而,在帽子下,MongoDB将文件分布在碎片节点上。
您可以使用getShardDistribution()方法访问有关数据如何在您的碎片中分布的信息:
1[environment fifth]
2db.cities.getShardDistribution()
此方法的输出为群集中的每个碎片提供统计数据:
1[environment fifth]
2[secondary_label Output]
3Shard shard2 at shard2/mongo_shard2_ip:27017
4 data : 943B docs : 9 chunks : 2
5 estimated data per chunk : 471B
6 estimated docs per chunk : 4
7
8Shard shard1 at shard1/mongo_shard1_ip:27017
9 data : 1KiB docs : 11 chunks : 2
10 estimated data per chunk : 567B
11 estimated docs per chunk : 5
12
13Totals
14 data : 2KiB docs : 20 chunks : 4
15 Shard shard2 contains 45.4% data, 45% docs in cluster, avg obj size on shard : 104B
16 Shard shard1 contains 54.59% data, 55% docs in cluster, avg obj size on shard : 103B
此结果表明,在国家领域的自动化哈希策略导致在两个分区中几乎均匀分布。
现在,您已配置了一个功能齐全的碎片集群和插入的数据,这些数据已被自动分割到多个碎片中,在下一步,您将学习如何在执行查询时监控碎片使用。
步骤5 – 分析shard的使用
Sharding 用于扩展数据库系统的性能,因此,如果有效地使用它来支持数据库查询,则效果最好。
此步骤侧重于验证查询是否优化为仅使用单个分片,或者是否扩展到多个分片以获取结果。
首先,选择城市集合中的每个文档,因为您想要获取所有文档,所以每个分片都必须被用来执行查询:
1[environment fifth]
2db.cities.find()
查询将毫不奇怪地返回所有城市. 重新运行查询,这一次使用附加于其末尾的 explain() 方法:
1[environment fifth]
2db.cities.find().explain()
长输出将提供查询如何执行的详细信息:
1[environment fifth]
2[secondary_label Output]
3{
4 "queryPlanner" : {
5 "mongosPlannerVersion" : 1,
6 "winningPlan" : {
7 "stage" : "SHARD_MERGE",
8 "shards" : [
9 {
10 "shardName" : "shard1",
11 . . .
12 },
13 {
14 "shardName" : "shard2",
15 . . .
16 }
17 ]
18 }
19 },
20. . .
请注意,获胜计划是指SHARD_MERGE策略,这意味着用于解决查询的多个片段。在片段键中,MongoDB返回了参与评估的片段列表。
现在测试结果是否会有所不同,如果您对大陆字段进行查询,而这不是所选的分割键:
1[environment fifth]
2db.cities.find({"continent": "Europe"}).explain()
这一次,MongoDB也不得不使用两个片段来满足查询. 数据库没有办法知道哪个片段包含欧洲城市的文档:
1[environment fifth]
2[secondary_label Output]
3{
4 "queryPlanner" : {
5 "mongosPlannerVersion" : 1,
6 "winningPlan" : {
7 "stage" : "SHARD_MERGE",
8 . . .
9 }
10 },
11. . .
尝试过滤仅来自日本的城市,使用您之前选择为 shard 键的国家字段:
1[environment fifth]
2db.cities.find({"country": "Japan"}).explain()
1[environment fifth]
2[secondary_label Output]
3{
4 "queryPlanner" : {
5 "mongosPlannerVersion" : 1,
6 "winningPlan" : {
7 "stage" : "SINGLE_SHARD",
8 "shards" : [
9 {
10 "shardName" : "shard1",
11 . . .
12 }
13. . .
这一次,MongoDB 使用了不同的查询策略:SINGLE_SHARD而不是SHARD_MERGE。这意味着只需要一个片段来满足查询。在片段键中,只提到一个片段。
通过使用查询路由器上的解释功能,您可以检查您正在运行的查询是否包含一个或多个片段,反过来,它还可以帮助您确定查询是否会通过同时访问每个片段来过载集群。
结论
Sharding 已被广泛应用为提高大数据集群的性能和可扩展性的一种策略。当与复制相结合时,sharding 还具有提高可用性和数据安全性的潜力。
通过完成本教程,您已经学会了如何在MongoDB中分解工作,如何配置配置配置服务器和单个分解,以及如何将它们连接在一起以形成分解集群。
这种策略带来了许多好处,但也带来了管理挑战,如需要管理多个复制集和更复杂的安全考虑。 要了解更多关于在开发环境以外的分裂集群的分裂和运行,我们鼓励您查看有关该主题的官方 MongoDB 文档(https://docs.mongodb.com/manual/sharding/)。