作者选择了 开放式互联网 / 自由言论基金作为 写给捐赠计划的一部分接受捐款。
介绍
MongoDB 壳允许您访问数据库,只要您已经可以访问运行 MongoDB 的服务器,但是命令行界面并不总是适合使用数据库,因为可能不清楚如何找到或分析他们的数据。
使用 MongoDB Compass,有时缩短为 Compass,您可以通过直观的视觉显示访问MongoDB数据库引擎提供的大部分功能,您可以浏览数据库,集合和单个文档,互动地创建查询,操纵现有文档,并通过专用界面设计聚合管道。
在本教程中,您将在本地机器上安装MongoDB Compass,并熟悉如何使用图形工具执行各种数据库管理。
前提条件
要遵循本教程,您将需要:
- 具有`sudo'权限和UFW配置防火墙的普通非根用户的服务器。 使用运行 Ubuntu 20.04 的服务器验证了此教程, 您可以遵循此[ Ubuntu 20. 04 的初始服务器设置教程( https://andsky.com/tech/tutorials/initial-server-setup-with-ubuntu-20-04) 来准备您的服务器 。
- 在您的服务器上安装了 MongoDB 。 要设置此功能,请遵循我们关于[如何在Ubuntu 20.04上安装MongoDB]的教程(https://andsky.com/tech/tutorials/how-to-install-mongodb-on-ubuntu-20-04)。
- 您服务器的MongoDB 实例通过启用认证和创建行政用户而获得安全 。 为了保证蒙戈DB的安全,请遵守我们关于
如何保证蒙戈DB在Ubuntu 200.04的教程(https://andsky.com/tech/tutorials/how-to-secure-mongodb-on-ubuntu-20-04)。 - 您的蒙戈 为允许本地机器连接而配置的 DB 实例 。 遵循我们的指南 [如何配置 Ubuntu 20.04 上的 MongoDB 远程访问 (https://andsky.com/tech/tutorials/how-to-configure-remote-access-for-mongodb-on-ubuntu-20-04 )来设置此功能 。 在您遵循此向导时, ** 请使用您的本地机器代替第二个远程 Ubuntu 服务器 ** 。
- 本地机器, 您可以安装 MongoDB Compass 。 这个教程有如何在运行Ubuntu和基于RHEL的操作系统的机器上安装Compass的指示,但它也包括了与MongoDB在Windows和MacOS上安装Compass的指示的链接. (英语)
<$>[注] **注:**有关如何配置您的服务器,安装,然后安全MongoDB安装的链接教程参考Ubuntu 20.04.本教程专注于MongoDB本身,而不是潜在的操作系统。
步骤 1 – 安装 MongoDB Compass
要使用 MongoDB Compass,您必须在本地计算机上安装它. MongoDB 为 Ubuntu 和基于 RHEL 的 Linux 发行版以及 Windows 和 MacOS 提供官方图形工具包。
要找到适合您的系统的软件包,请导航到您的 Web 浏览器中的 MongoDB Compass Downloads 页面。 在那里,找到页面右侧的 ** Available Downloads** 部分,并从下载菜单中选择您想要的 Version 和 Platform。本教程的示例将安装版本 1.28.4,这是本文写作时最新的稳定版本。
在做出选择后,点击 Copy Link按钮,将下载链接复制到您的剪辑板. 如果您选择了Ubuntu作为您的平台,此链接将下载一个 .deb包,但如果您选择了RedHat链接将下载一个 .rpm包。
然后,在本地机器上打开终端会话 **。
如果你的本地机器正在运行Ubuntu,你复制的链接是.deb包,运行一个wget命令,并将你刚刚复制的链接传递给它作为一个论点。
1[environment local]
2wget https://downloads.mongodb.com/compass/mongodb-compass_1.28.4_amd64.deb
然后安装.deb包与apt:
1[environment local]
2sudo apt install ./mongodb-compass_1.28.4_amd64.deb
此命令将安装Compass包以及所有必要的依赖。
但是,如果您正在使用基于 RHEL 的发行版,如 CentOS、Fedora 或 Rocky Linux,您可以通过单个命令直接从 Web 下载和安装 .rpm 包。
1[environment local]
2sudo dnf install -y https://downloads.mongodb.com/compass/mongodb-compass-1.26.1.x86_64.rpm
<$>[注] 注: MongoDB Compass 也适用于 Mac 和 Windows 系统. 若要在非 Linux 系统上设置 MongoDB Compass,请遵循 [官方 MongoDB Compass 文档] 的安装说明(https://docs.mongodb.com/compass/current/install/)。
安装 MongoDB Compass 包后,您可以通过执行下列操作来运行安装的软件:
1[environment local]
2mongodb-compass
Compass将用欢迎屏幕欢迎您:
现在,您已在本地机器上安装了 MongoDB Compass,您可以将其连接到在远程服务器上运行的 MongoDB 实例。
步骤 2 – 连接到 MongoDB 服务器
要使用 MongoDB Compass 与在您的远程服务器上运行的 MongoDB 实例,您必须首先连接到它,就像您通过壳访问数据库时一样。
Compass 允许您使用 connection string 连接 - 包含所有必要的数据库连接信息的单行文本 - 或单独填写所有连接细节。
在欢迎屏幕的顶部点击 单独填写连接字段. 新连接字段将显示一个空的字段列表:
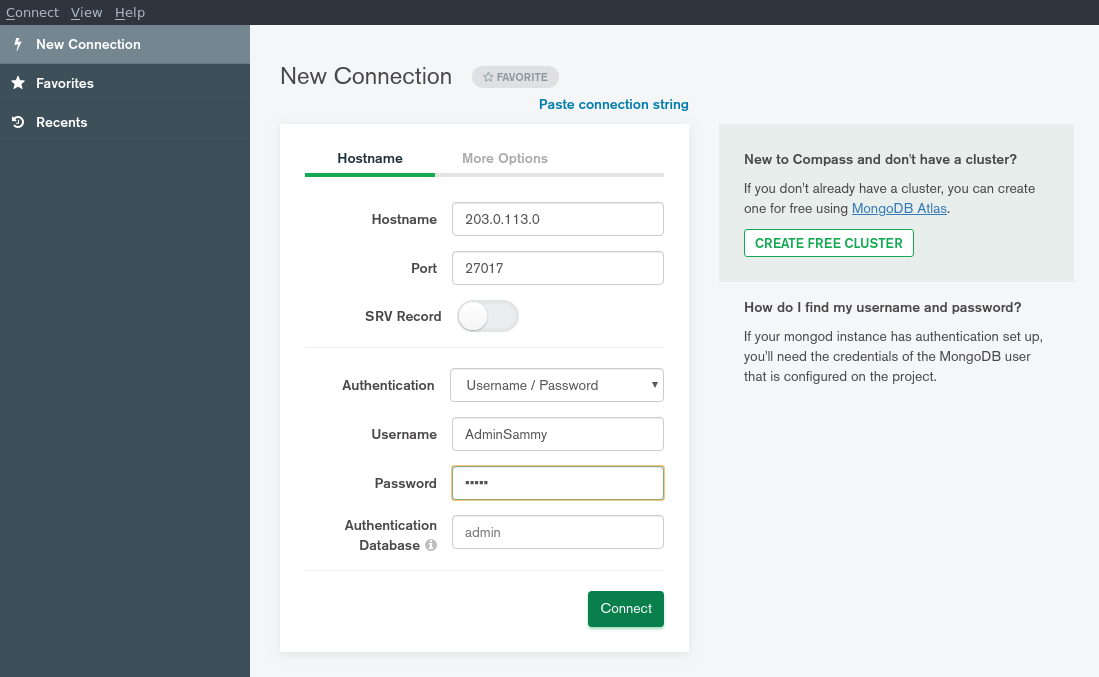
将您 MongoDB 实例运行的远程服务器的 IP 地址输入到 Hostname 字段中。 留下默认 Port 值,除非您更改了您的 MongoDB 实例正在收听连接的端口。 由于服务器被安全地使用了启用身份验证,您还需要将 Authentication 选项切换为 Username / Password。 选择此选项后,请在三个新字段中输入您的管理 MongoDB 用户名、与此帐户相关的密码和该用户的身份验证数据库。
点击 ** 连接** 按钮后,Compass 将尝试连接到 MongoDB 实例. 如果成功,您将被带到主屏幕,显示该实例中所有数据库的列表。
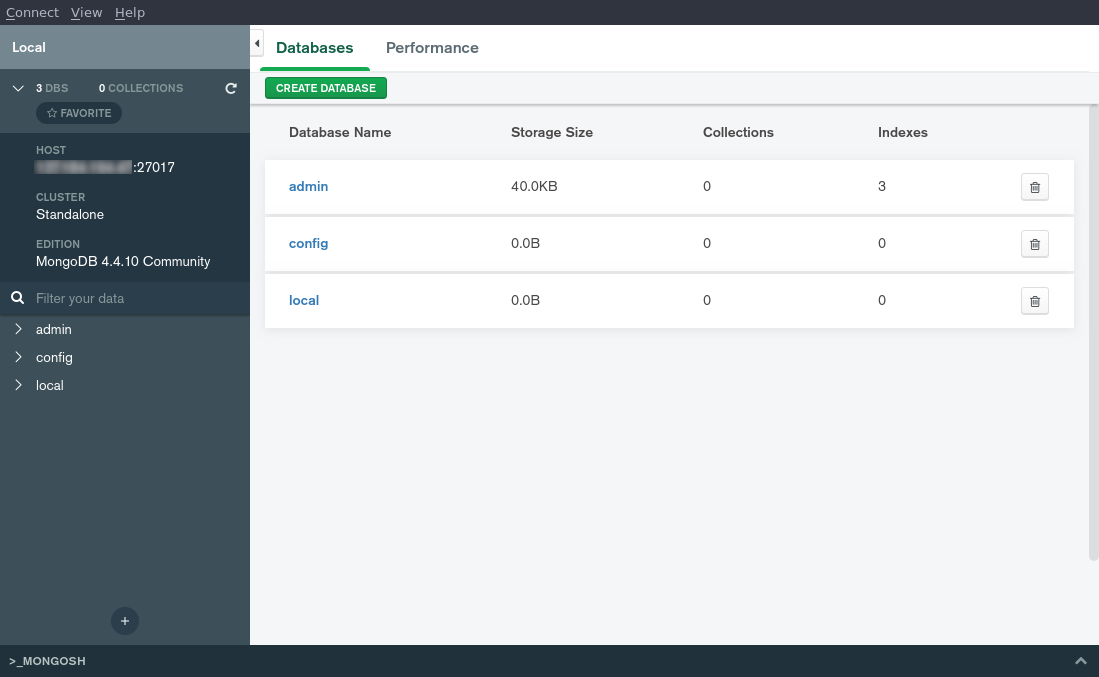
如果连接尝试失败,请确保您正确输入所有连接细节。
成功将本地 Compass 安装连接到远程 MongoDB 服务器实例后,您可以创建新的测试数据库并将测试数据插入到新的集合中。
步骤 3 – 准备测试数据
为了说明 MongoDB Compass 的不同功能,本指南将使用其示例中的一组样本文档。
此样本收集包含代表世界20个人口最多的城市的文档,东京的样本文档将遵循以下结构:
1[label Example document representing Tokyo]
2{
3 "name": "Tokyo",
4 "country": "Japan",
5 "continent": "Asia",
6 "population": 37.400
7}
该文件包含有关城市的名称,它所在的国家,大陆,及其人口以百万计表示的信息.本指南将命名样本数据库人口,将存储文件的集合命名为城市。
首先,点击首页屏幕顶部的 CREATE DATABASE按钮,也可以点击左侧面板底部的加号(+)。
在MongoDB中,当第一个文档被插入到集合中时,通常会创建数据库和集合,而不需要对这些结构进行明确的创建操作。
键入数据库名称字段和城市字段的数据库名称字段,留下所有其他字段的默认值,然后单击创建数据库字段:
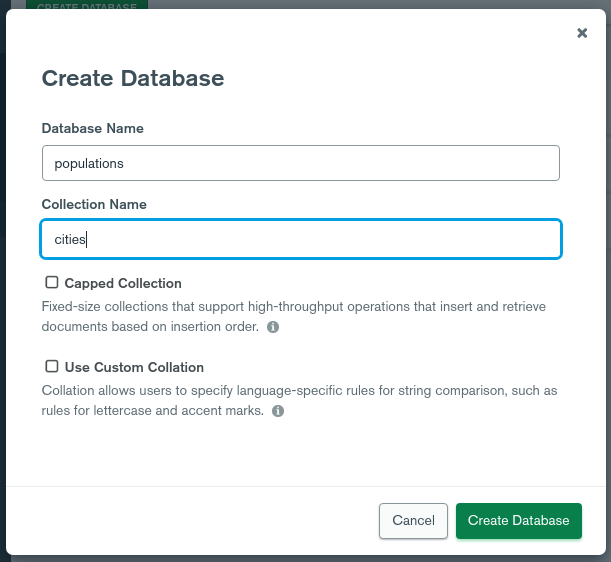
Compass 将创建数据库. 点击人口数据库以访问数据库视图. 然后,点击城市以访问空集合视图:
现在数据库和集合已经创建,您可以将未分类的文档列表插入到城市集合中。
会出现一个窗口,您可以在 JSON 格式中输入一个或多个数据文档,就像您使用 shell 命令一样。
1[
2 {"name": "Seoul", "country": "South Korea", "continent": "Asia", "population": 25.674 },
3 {"name": "Mumbai", "country": "India", "continent": "Asia", "population": 19.980 },
4 {"name": "Lagos", "country": "Nigeria", "continent": "Africa", "population": 13.463 },
5 {"name": "Beijing", "country": "China", "continent": "Asia", "population": 19.618 },
6 {"name": "Shanghai", "country": "China", "continent": "Asia", "population": 25.582 },
7 {"name": "Osaka", "country": "Japan", "continent": "Asia", "population": 19.281 },
8 {"name": "Cairo", "country": "Egypt", "continent": "Africa", "population": 20.076 },
9 {"name": "Tokyo", "country": "Japan", "continent": "Asia", "population": 37.400 },
10 {"name": "Karachi", "country": "Pakistan", "continent": "Asia", "population": 15.400 },
11 {"name": "Dhaka", "country": "Bangladesh", "continent": "Asia", "population": 19.578 },
12 {"name": "Rio de Janeiro", "country": "Brazil", "continent": "South America", "population": 13.293 },
13 {"name": "São Paulo", "country": "Brazil", "continent": "South America", "population": 21.650 },
14 {"name": "Mexico City", "country": "Mexico", "continent": "North America", "population": 21.581 },
15 {"name": "Delhi", "country": "India", "continent": "Asia", "population": 28.514 },
16 {"name": "Buenos Aires", "country": "Argentina", "continent": "South America", "population": 14.967 },
17 {"name": "Kolkata", "country": "India", "continent": "Asia", "population": 14.681 },
18 {"name": "New York", "country": "United States", "continent": "North America", "population": 18.819 },
19 {"name": "Manila", "country": "Philippines", "continent": "Asia", "population": 13.482 },
20 {"name": "Chongqing", "country": "China", "continent": "Asia", "population": 14.838 },
21 {"name": "Istanbul", "country": "Turkey", "continent": "Europe", "population": 14.751 }
22]
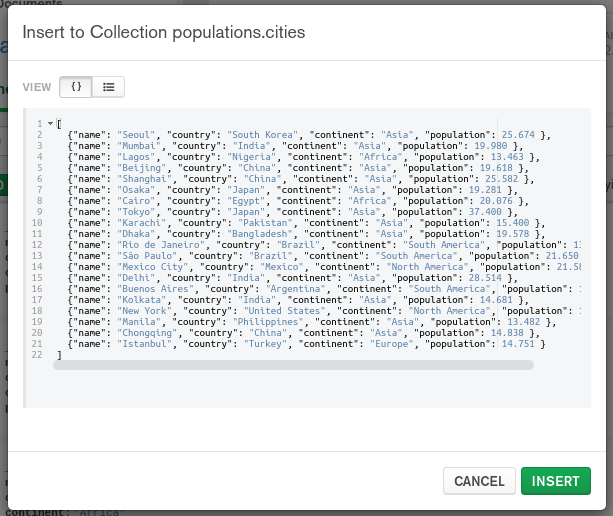
点击 INSERT按钮,Compass将插入文档列表,然后在收藏浏览器中自动显示它们:
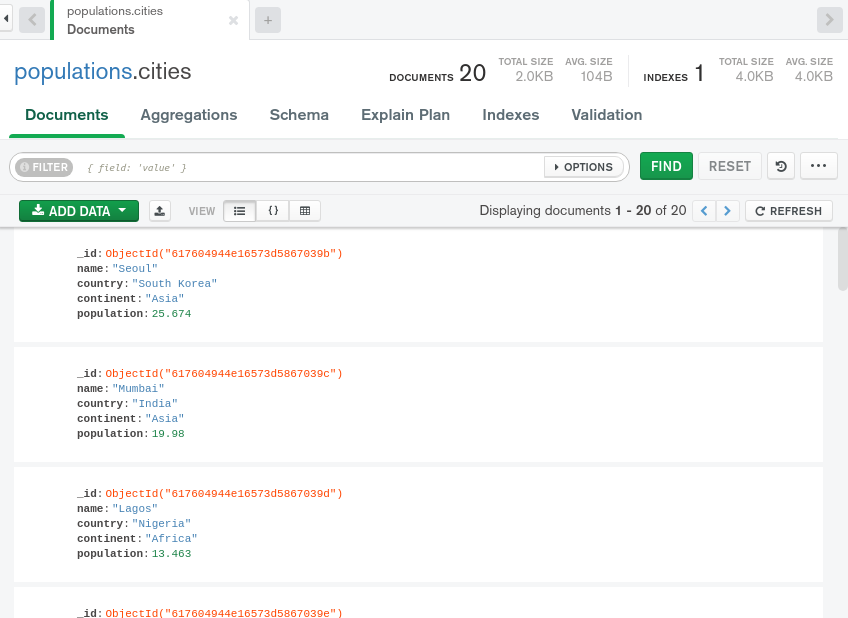
通过此,您已成功创建了一组代表世界人口最多的城市的样本文档,该集合将作为本指南的示例数据,当您探索MongoDB Compass时。
步骤 4 – 导航和过滤数据
MongoDB Compass 是一个方便的工具,可以通过图形界面浏览存储在 MongoDB 数据库中的数据,消除需要记住模糊数据库或集合的名称的负担,您可以轻松地导航到您的 MongoDB 服务器上的任何数据库或集合。
Compass 中的主要导航工具是左面面板,它就像一棵树,显示数据库的内容。
要导航到您在上一步创建的城市集合,请单击人口数据库名称,并显示每个集合的列表。在准备测试数据后,单个集合将可用。
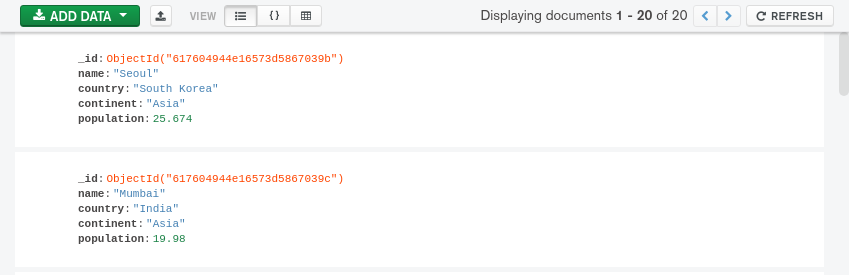
默认情况下,Compass 会显示在所选集合中以空查询返回的最初 20 个未过滤的结果. 在前一步使用的 ADD DATA 按钮的右侧,您将找到一个 View 部分,有三个单独的显示模式,您可以选择:
- 列表视图:默认视图将文档显示为密钥值对,显示一连串。这个显示模式类似于JSON文档格式,但其语法颜色和额外的界面功能,如可崩溃的嵌套文档,有助于使其更易于阅读:
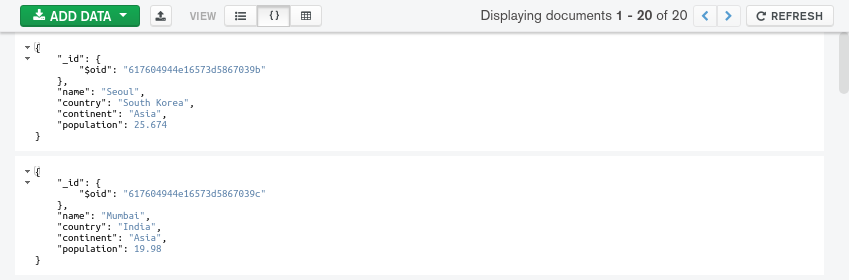
- ** JSON 视图**:此视图显示了 JSON 中的实际文档结构:
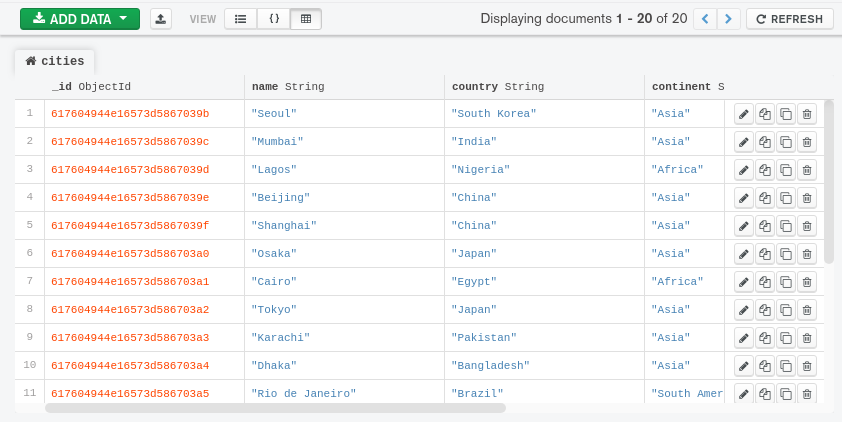
- ** 表格视图**:在表格界面中显示数据,类似于关系数据库中的数据。如果文档遵循明确的平面结构,但在文档中出现嵌入式文档或数组时不那么可读,这可能是有用的:
无论您使用哪种视图,您可以使用数据浏览器屏幕快速查询您的数据,就像您在 MongoDB 壳中的 find() 方法一样。
1db.cities.find({ "continent": "North America" })
在这个find()方法中,{大陆:北美 }是 query document. 这是命令中告诉 MongoDB 如何过滤数据的部分。
继续,将此查询文档输入到 FILTER字段,然后按 FIND:
1{ "continent": "North America" }
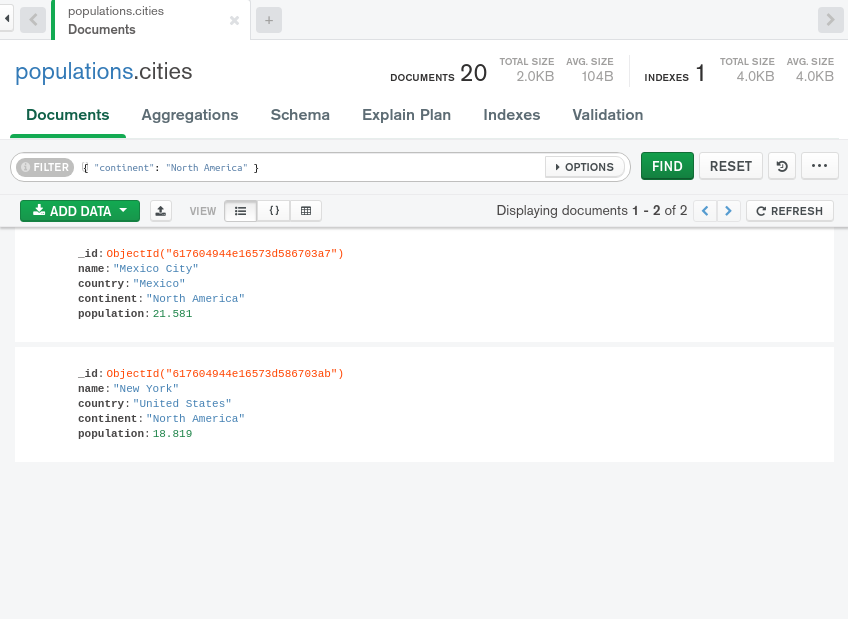
MongoDB Compass 将文档列表缩小到匹配过滤标准的两个条目. 您可以使用任何有效的查询文档,您可以在 find() 命令中使用,以在 FILTER 字段中过滤日期。
您还可以对结果进行排序并应用预测,以使用数据浏览器界面仅返回有限的子集字段。 点击选项按钮附近的过滤查询栏,以揭示进一步的选项。
两个 PROJECT和 SORT字段都接受相同的文档,你会转移到壳中的 find()和 sort() 方法. 例如,尝试限制返回的字段只显示城市名称和人口,然后按人口顺序排序结果。
若要将字段列表限制为名称和人口,请将以下投影文档添加到 PROJECT字段:
1{ "_id": 0, "name": 1, "population": 1 }
若要以上升顺序按人口排序列表,请将下列排序文档添加到 SORT 字段:
1{ "population": 1 }
再次点击 ** FIND** 按钮来应用这些投影和排序文档:
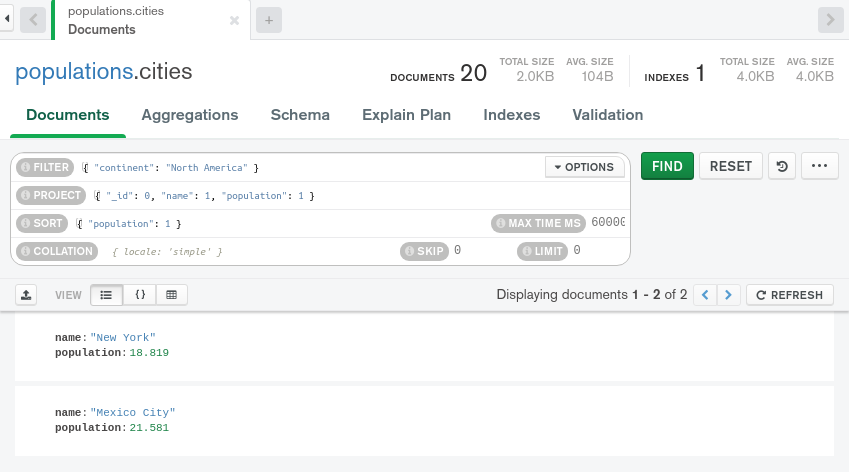
Compass 现在显示了代表纽约和墨西哥城的两个简化文件,结果相当于在 MongoDB 壳中运行以下查询:
1db.cities.find(
2 { "continent": "North America" },
3 { "_id": 0, "name": 1, "population": 1 }
4).sort(
5 { "population": 1 }
6)
与过滤查询文档一样,投影和排序设置中的语法错误会导致相应字段的标签变为红色,从而在出现问题时更容易发现。
要清除所应用的过滤器、投影和排序文档,您可以点击 RESET按钮。
<$>[注] 注:使用数据浏览器,您还可以更改单个文档的内容。从列表视图中,向列表中的文档滚动,然后在出现的背景菜单中点击铅笔图标:
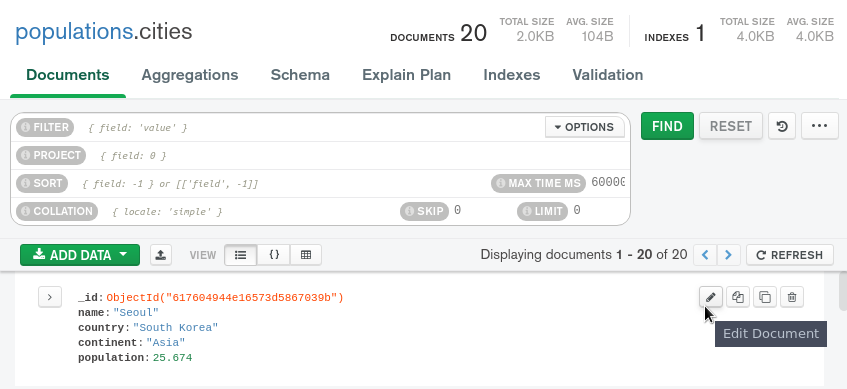
静态显示器将更改为可编辑的字段列表,您可以自由修改以快速更改文档:

完成所需的更改后,点击更新按钮,它们将被写入数据库中。
步骤 5 — 使用互动聚合管道建设器
Compass 的聚合管道构建器是一个图形工具,帮助创建多步聚合管道. 此步骤解释了如何通过添加连续聚合步骤来构建一个管道。
<$>[注] **注: **本步中的示例是从使用类似的测试数据的 How to Use Aggregations教程中使用的聚合管道。
举个例子,说现在的任务是列出收藏中代表的国家中人口最多的城市,但只有在亚洲和北美发现的城市。 管道只能返回城市的名称和人口。
1[label Example document structure]
2{
3 "location" : {
4 "country" : "Japan",
5 "continent" : "Asia"
6 },
7 "most_populated_city" : {
8 "name" : "Tokyo",
9 "population" : 37.4
10 }
11}
要开始构建一个能够满足这些要求的聚合管道,请打开城市收藏的聚合选项卡。
首先,过滤来自城市收藏的初始文件,以便仅包含亚洲和北美国家。
聚合管道构建器视图的顶部部分显示了集合中的源文档. 这允许您快速查看将用于聚合管道输入的文档. 请注意,如果文档不立即显示,您可能需要按下更新按钮(****)以使这些文档以默认方式出现。
在这个例子中,这些是城市文件,其原始,不变的结构.第二行,最初是空的,是第一次聚合阶段。
构建此示例管道的第一步是过滤来自城市集合的初始文档,以便它们仅包含代表北美和亚洲城市的文档。 为此,请使用下滑式 Select... 菜单并选择$match阶段。
输入以下内容,仅匹配来自北美和亚洲的城市:
1{
2 "continent": { $in: ["North America", "Asia"] }
3}
Compass 会自动预览应用第一个步骤的结果,并在右侧显示过滤的文档,这样你就可以快速验证每个步骤的运作如意:
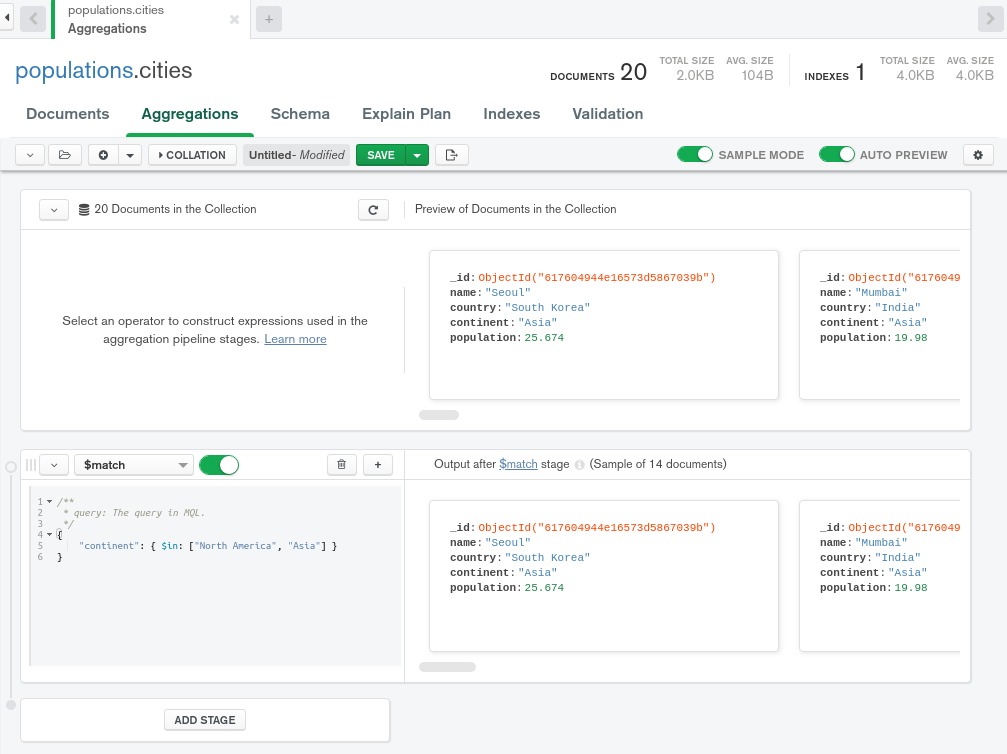
第二步是按人口排序排序。使用 ADD STAGE 按钮添加一个额外的阶段。会出现另一个空的阶段行。
1{ "population": -1 }
再次,返回的文档将具有相同的结构,但东京首先出现在预览面板中,现在显示了排序结果:
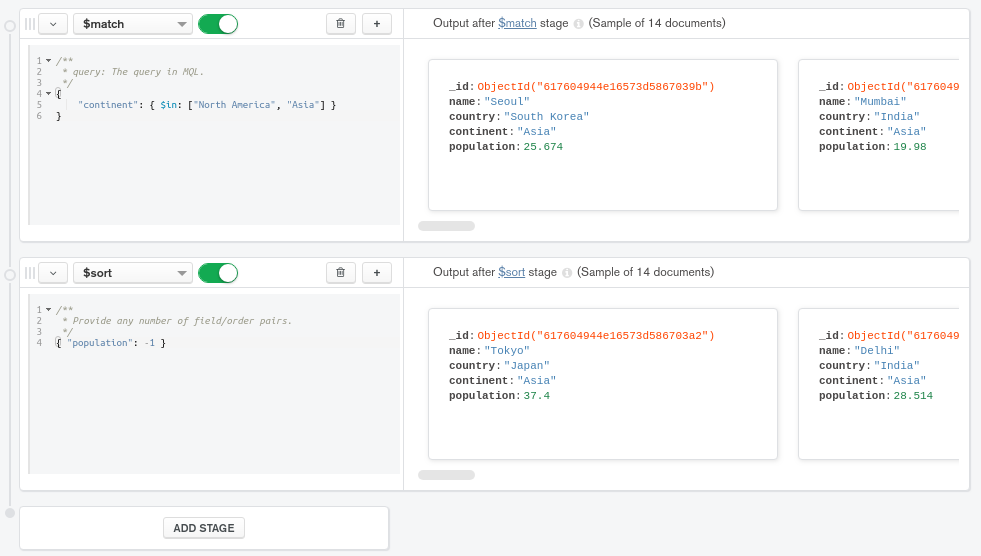
由于城市列表现在按预期大陆的人口排序,下一个必要的步骤是按各自国家组合城市,只从每个组中选择人口最多的城市。
若要按独特的大陆和国家对组合城市,并通过仅显示其人口最多的城市的名称和人口来总结这些对,请输入以下组合设置:
1{
2 "_id": {
3 "continent": "$continent",
4 "country": "$country"
5 },
6 "first_city": { $first: "$name" },
7 "highest_population": { $max: "$population" }
8}
highest_population 值使用 $max 积累运算器来查找组中最高的人口,而 first_city 得到第一个城市的名称。
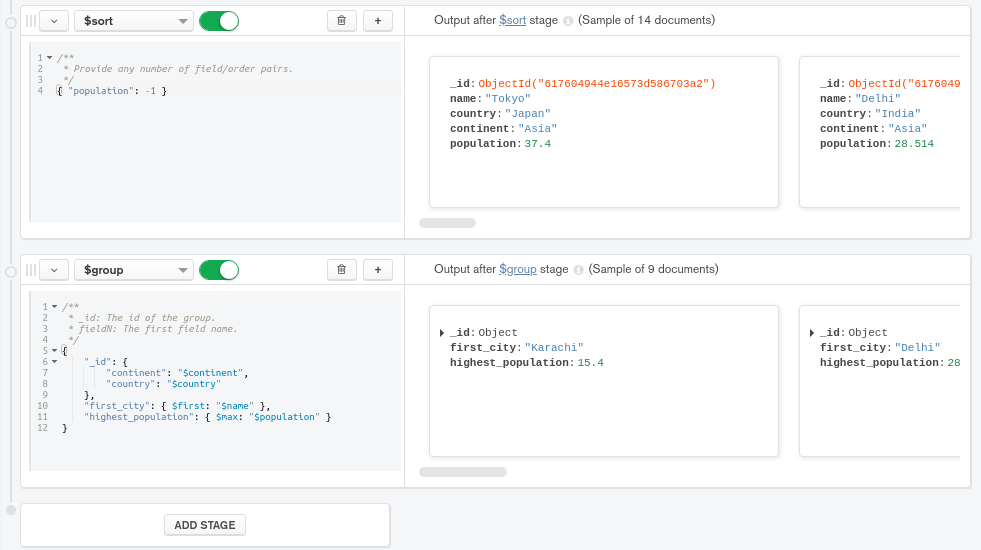
应用组合阶段后,文档列表被缩小到 9 个条目,但文档结构现在与以前不同. Compass 可预览右侧的组合阶段的输出,显示新计算的highest_population和first_city值,以及在_id字段中的组合表达式值。
满足本节开头所述的要求的最后一步是转换文档的结构. 您可以通过添加另一个阶段行并选择$project作为阶段来完成此操作。
1{
2 "_id": 0,
3 "location": {
4 "country": "$_id.country",
5 "continent": "$_id.continent",
6 },
7 "most_populated_city": {
8 "name": "$first_city",
9 "population": "$highest_population"
10 }
11}
此文档首先删除_id字段,以便它不会出现在输出中。接下来,它会创建一个位置字段,用两个字段写成嵌入式文档:国家和大陆。每个字段都指来自输入文档的值。most_populated_city遵循类似的原则,嵌入了名称和人口字段。这两个字段都指的是顶级字段first_city和highest_population。
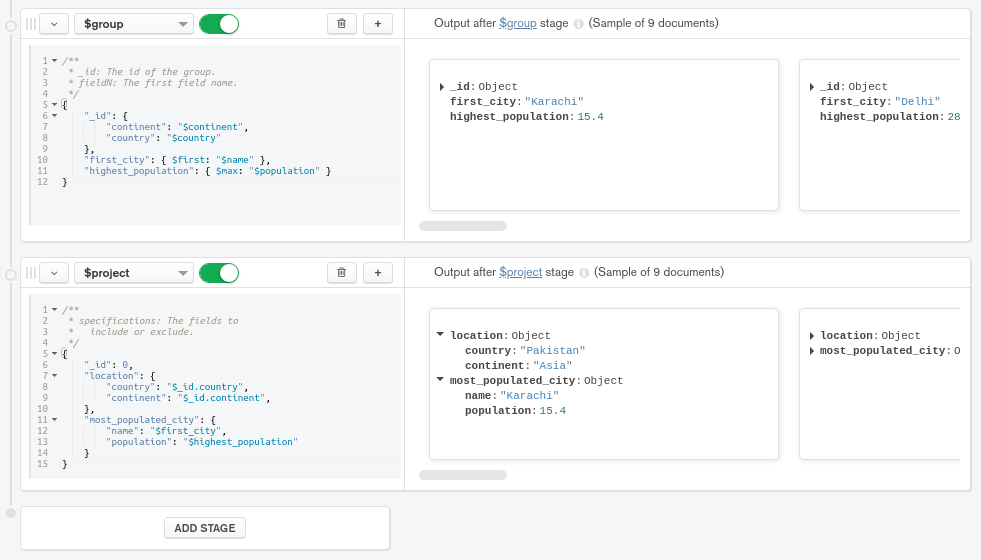
请注意,此聚合阶段右侧的预览窗格显示了转换后的样本输出,您可以快速确认投影阶段导致预期转换。
通过使用聚合管道构建程序,您可以方便地逐步构建聚合,而无需担心单个聚合命令的复杂语法。
通过每个阶段的预览面板,您可以验证每个阶段是否提供预期结果,您还可以使用转换交换机禁用并启用单个阶段,以了解聚合管道将如何工作,而没有部分阶段被激活。
步骤6:分析方案结构
在之前的步骤中,您使用 MongoDB Compass 浏览数据,使用交互式工具. 通过这些示例,Compass 更有助于执行 MongoDB 中的常规函数,但在此步骤中,您将探索 Compass 独特的功能:它的架构可视化界面。
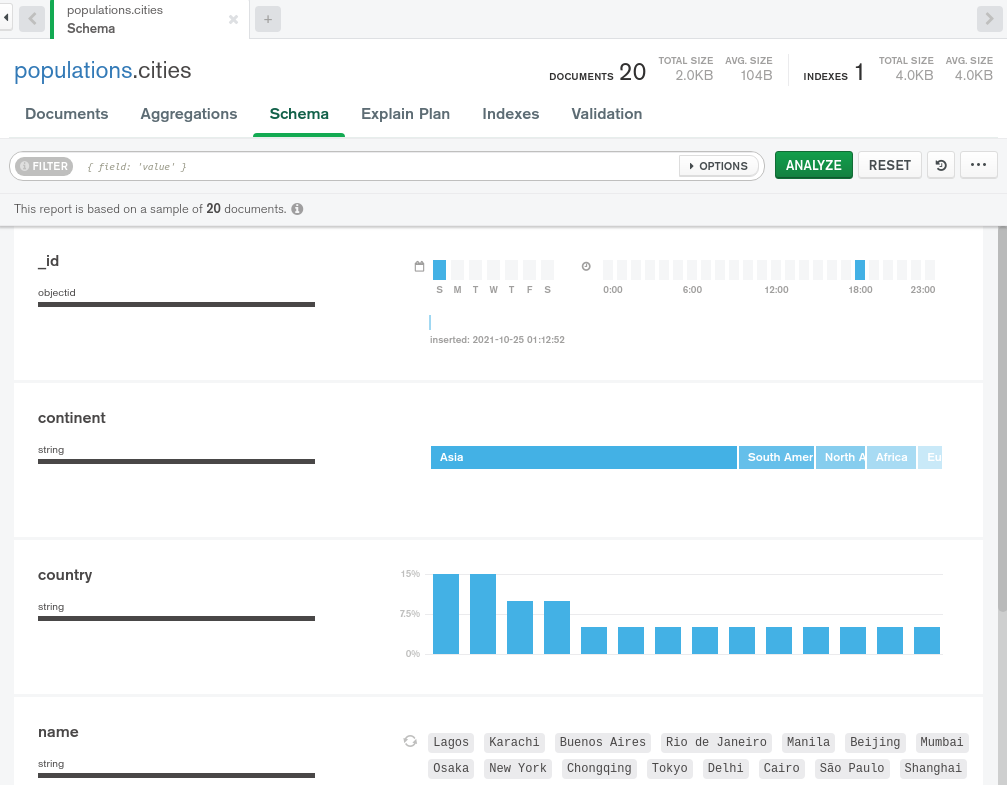
要使用它,首先在城市集合视图中选择 ** Schema** 选项卡. 视图最初将是空的,但当您按下 Analyze 按钮时,Compass 将对数据进行筛选,以揭示其形式、大小和内容的见解:
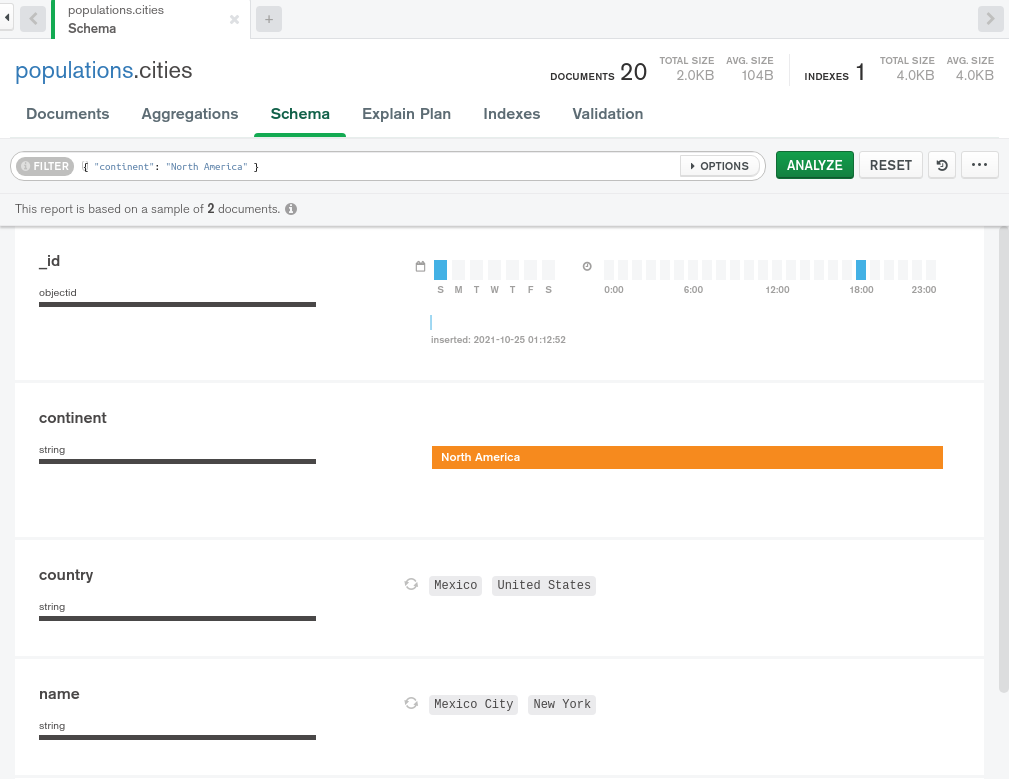
<$>[注] 注: 类似于简单地浏览数据,您可以使用过滤查询文档来缩小选择,并强迫 MongoDB Compass 向集合文档的子集提供见解:
 <$>
<$>
对于每个文档字段,方案可视化程序将提供数据库中发现的数据的见解。
例如,在 Schema Visualizer 中注意_id字段。 MongoDB 要求每个文档都具有_id字段作为主要密钥。在 Compass 的 Schema Visualizer 中,它显示了文档被插入数据库的时刻。在本示例中,所有文档在周日晚上被插入到一个单一的时刻。 然而,在活数据库中,数据库的输入将在整个数据库使用过程中分布。
对于大陆和国家字段,这两个字段都包含字符串值,但集合中出现的值不止一次,Compass便于默认显示数据集中的每个值的出现频率。
名称字段也是一个字符串值字段,但这一次每个字段都是独一无二的。
通过将Compass的方案可视化器与MongoDB的过滤功能相结合,您可以快速扫描您的数据和生成的可视化,允许您分析您的数据,而无需写出复杂的查询。
结论
在本文中,您熟悉了MongoDB Compass,一个GUI,允许您通过方便的视觉显示来管理MongoDB数据。您使用该工具创建一个新的收藏,插入新的文档,过滤和导航数据,创建一个多阶段聚合管道,并使用方案可视化工具可视化收藏的方案。
该教程仅描述了MongoDB Compass功能的子集,其中包括许多与MongoDB管理相关的其他功能,如索引管理,查询执行计划可视化和服务器实时性能指标的视图。