介绍
本教程是一个 ELK Stack (Elasticsearch, Logstash, Kibana) 故障排除指南. 它假定您遵循了 如何在 Ubuntu 14.04 上安装 Elasticsearch, Logstash 和 Kibana (ELK Stack) 教程,但它可能对其他一般 ELK 设置的故障排除有用。
本教程结构为一系列常见问题,以及这些问题的潜在解决方案,以及步骤,以帮助您验证您的ELK堆栈的各个组件的正常运作。
Kibana No Default 指数模式警告
当您通过 Web 浏览器访问 Kibana 时,您可能会遇到有此警告的页面:
1[secondary_label Kibana warning:]
2Warning No default index pattern. You must select or create one to continue.
3...
4Unable to fetch mapping. Do you have indices matching the pattern?
以下是警告的屏幕截图:
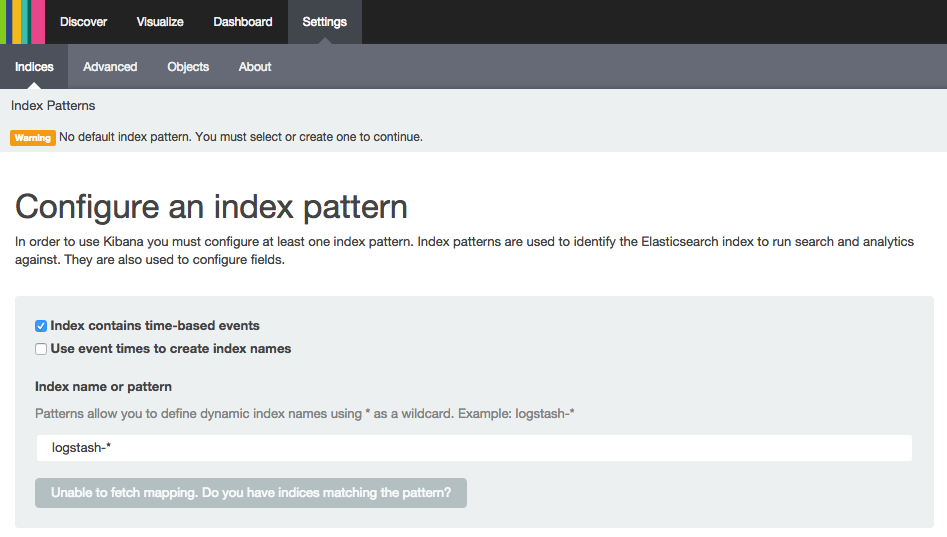
无法检索地图表示Elasticsearch不包含与默认logstash-*模式相匹配的任何条目。通常,这意味着您的日志不会在Elasticsearch中存储,因为从Logstash到Elasticsearch的通信问题,或从您的日志发送商(例如FileBeat)到Logstash。
要解决 Logstash 和 Elasticsearch 之间的通信问题,请通过 Logstash 故障排除部分运行。
如果您将 Logstash 配置为使用非默认索引模式,则可以通过在文本框中指定适当的索引模式来解决该问题。
问题:Kibana无法连接到Elasticsearch
当您通过 Web 浏览器访问 Kibana 时,您可能会遇到包含此错误的页面:
1[secondary_label Kibana error:]
2Fatal Error
3Kibana: Unable to connect to Elasticsearch
4
5Error: Unable to connect to Elasticsearch
6Error: Bad Gateway
7...
以下是错误的屏幕截图:
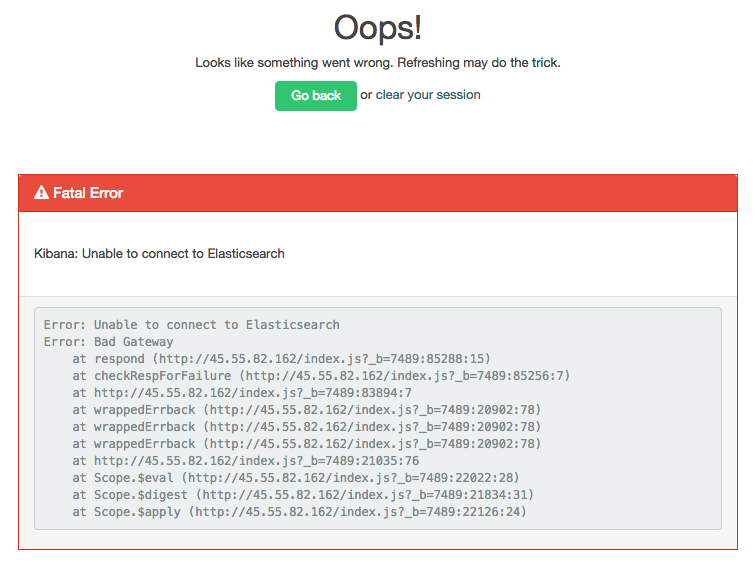
这意味着 Kibana 无法连接到 Elasticsearch. Elasticsearch 可能无法运行,或者 Kibana 可能已配置为在错误的主机和端口上搜索 Elasticsearch。
若要解决此问题,请通过遵循 Elasticsearch 故障排除部分来确保 Elasticsearch 正在运行,然后确保 Kibana 已配置为连接到 Elasticsearch 正在运行的主机和端口。
例如,如果 Elasticsearch 在端口9200上运行本地主机,请确保 Kibana 配置正确。
打开 Kibana 配置文件:
1sudo vi /opt/kibana/config/kibana.yml
然后确保elasticsearch_url设置正确。
1[secondary_label /opt/kibana/config/kibana.yml excerpt:]
2# The Elasticsearch instance to use for all your queries.
3elasticsearch_url: "http://localhost:9200"
保存和退出。
现在,重新启动Kibana服务,将您的更改执行:
1sudo service kibana restart
在 Kibana 重新启动后,请在 Web 浏览器中打开 Kibana,并验证错误已解决。
问题:Kibana不可用
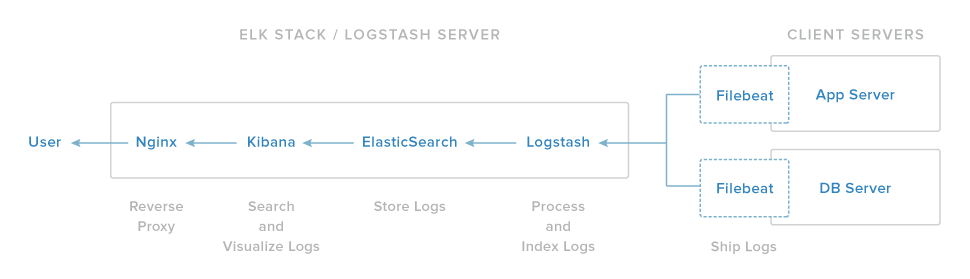
ELK 堆栈的 Nginx 组件作为对 Kibana 的反向代理服务。如果 Nginx 没有正确运行或配置,您将无法访问 Kibana 接口。
原因: Nginx 不运行
如果 Nginx 未运行,并且您尝试在 Web 浏览器中访问 ELK 堆栈,您可能会看到类似于此的错误:
1[secondary_label Nginx Error:]
2This webpage is not available
3ERR_CONNECTION_REFUSED
这通常表明 Nginx 没有运行。
您可以使用此命令检查 Nginx 服务的状态:
1sudo service nginx status
如果它报告服务不运行或未被识别,请按照 ELK 堆栈教程的 安装 Nginx 部分中的说明来解决您的问题。
原因: Nginx 正在运行,但无法连接到 Kibana
如果 Kibana 无法访问,并且您收到502 Bad Gateway错误,则 Nginx 正在运行,但无法连接到 Kibana。
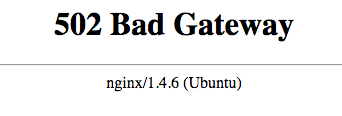
解决此问题的第一步是检查 Kibana 是否运行此命令:
1sudo service kibana status
如果 Kibana 无法运行或无法识别,请遵循 ELK 堆栈教程的 安装 Kibana 部分中的说明。
如果这不能解决问题,您可能会遇到您的 Nginx 配置问题. 您应该检查 ELK 堆栈教程的 安装 Nginx 部分的配置部分。
1sudo tail /var/log/nginx/error.log
这应该告诉你为什么 Nginx 无法连接到 Kibana。
原因:无法验证用户身份
如果您已启用基本身份验证,并且您在通过身份验证步骤时遇到问题,您应该查看 Nginx 错误日志,以确定问题的具体性。
要查看最近的 Nginx 错误,请使用以下命令:
1sudo tail /var/log/nginx/error.log
如果您看到用户未找到错误,则该用户在htpasswd文件中不存在。
1[secondary_label Nginx error logs (user was not found):]
22015/10/26 12:11:57 [error] 3933#0: *242 user "NonExistentUser" was not found in "/etc/nginx/htpasswd.users", client: 108.60.145.130, server: example.com, request: "GET / HTTP/1.1", host: "45.55.252.231"
如果您看到密码不匹配错误,则用户存在,但您提供了错误的密码。
1[secondary_label Nginx error logs (user password mismatch):]
22015/10/26 12:12:56 [error] 3933#0: *242 user "kibanaadmin": password mismatch, client: 108.60.145.130, server: example.com, request: "GET / HTTP/1.1", host: "45.55.252.231"
解决这两个错误的办法是提供正确的登录信息,或者用你预期会存在的用户登录来修改现有的htpasswd文件,例如,在htpasswd.users文件中创建或重写一个名为kibanaadmin的用户,请使用以下命令:
1sudo htpasswd /etc/nginx/htpasswd.users kibanaadmin
然后输入您想要的密码,并确认它。
如果您看到没有此类文件或目录错误,则在 Nginx 配置中指定的htpasswd文件不存在。
1[secondary_label Nginx error logs (htpasswd file does not exist):]
22015/10/26 12:17:38 [error] 3933#0: *266 open() "/etc/nginx/htpasswd.users" failed (2: No such file or directory), client: 108.60.145.130, server: example.com, request: "GET / HTTP/1.1", host: "45.55.252.231"
在这里,你应该创建一个新的 /etc/nginx/htpasswd.users 文件,并用以下命令添加一个用户(在本例中, kibanaadmin)到它:
1sudo htpasswd -c /etc/nginx/htpasswd.users kibanaadmin
输入新的密码,并确认它。
现在,尝试验证为您刚刚创建的用户。
Logstash:如何检查它是否在运行
如果 Logstash 不运行,您将无法从日志发送商(如 Filebeat)接收和解析日志,并在 Elasticsearch 中存储处理日志。
检查服务正在运行
最基本的检查是Logstash状态的状态:
1sudo service logstash status
如果 Logstash 正在运行,您将看到此输出:
1[secondary_label Logstash status (OK):]
2logstash is running
否则,如果服务不运行,您将看到此消息:
1[secondary_label Logstash status (Bad):]
2logstash is not running
如果 Logstash 不运行,请尝试使用此命令启动:
1sudo service logstash start
然后再检查其状态,几秒钟后。Logstash是一个Java应用程序,它将在每次启动尝试后几秒钟内报告为运行,所以在检查不运行状态之前等待几秒钟很重要。
问题:Logstash不运行
如果 Logstash 不运行,有几个潜在的原因,本节将涵盖各种常见情况,其中 Logstash 将失败,并提出潜在的解决方案。
原因:配置包含语法错误
如果 Logstash 在其配置文件中有错误,这些错误位于 `/etc/logstash/conf.d 目录中,服务将无法正确启动。
向您的服务器打开两个终端会话,以便在尝试启动服务时查看 Logstash 日志。
在第一个终端会话中,我们将看看日志:
1tail -f /var/log/logstash/logstash.log
这将显示最近的日志条目,以及任何未来的日志条目。
在第二个终端会话中,尝试启动Logstash服务:
1sudo service logstash start
返回第一个终端会话,查看在 Logstash 启动时生成的日志。
如果您看到包含错误消息的日志条目,请尝试阅读该消息(信息)以找出错误的内容. 以下是您可能看到的错误日志的例子,如果 Logstash 配置有语法错误(不匹配的曲线):
1[secondary_label Logstash logs (Syntax error):]
2...
3{:timestamp=>"2015-10-28T11:51:09.205000-0400", :message=>"Error: Expected one of #, => at line 12, column 6 (byte 209) after input {\n lumberjack {\n port => 5043\n type => \"logs\"\n ssl_certificate => \"/etc/pki/tls/certs/logstash-forwarder.crt\"\n ssl_key => \"/etc/pki/tls/private/logstash-forwarder.key\"\n \n}\n\n\nfilter {\n if "}
4{:timestamp=>"2015-10-28T11:51:09.228000-0400", :message=>"You may be interested in the '--configtest' flag which you can\nuse to validate logstash's configuration before you choose\nto restart a running system."}
最后一个消息说,我们可能对验证配置感兴趣,表明配置包含语法错误. 前一个消息提供了更具体的错误消息,在这种情况下,在配置的输入部分中缺少一个关闭的曲线。
1sudo vi /etc/logstash/conf.d/01-lumberjack-input.conf
查找具有错误输入的行,并修复它,然后保存和退出。
现在,在第二个终端上,启动Logstash服务:
1sudo service logstash start
如果问题已经解决,不应该有新的日志条目(Logstash 不会登录成功的启动)。
1sudo service logstash status
如果它在运行,你已经解决了问题。
您可能遇到与我们的例子不同的配置问题. 我们将涵盖其他一些常见的 Logstash 配置问题. 如既往,如果您能够弄清楚错误意味着什么,请尝试自己修复它。
原因:SSL文件不存在
Logstash 无法运行的另一个常见原因是与 SSL 证书和密钥文件有问题.例如,如果它们不存在,您的 Logstash 配置指定它们的地方,您的日志将显示这样的错误:
1[secondary_label Logstash logs (SSL key file does not exist):]
2{:timestamp=>"2017-12-01T16:51:31.656000+0000", :message=>"Invalid setting for beats input plugin:\n\n input {\n beats {\n # This setting must be a path\n # File does not exist or cannot be opened /etc/pki/tls/certs/logstash-forwarder.crt\n ssl_certificate => \"/etc/pki/tls/certs/logstash-forwarder.crt\"\n ...\n }\n }", :level=>:error}
3{:timestamp=>"2017-12-01T16:51:31.671000+0000", :message=>"Invalid setting for beats input plugin:\n\n input {\n beats {\n # This setting must be a path\n # File does not exist or cannot be opened /etc/pki/tls/private/logstash-forwarder.key\n ssl_key => \"/etc/pki/tls/private/logstash-forwarder.key\"\n ...\n }\n }", :level=>:error}
4{:timestamp=>"2017-12-01T16:51:31.685000+0000", :message=>"Error: Something is wrong with your configuration.", :level=>:error}
要解决这个特定问题,你需要确保你有一个 SSL 密钥文件(如果你忘记了它,将它放置在正确的位置(`/etc/pki/tls/private/logstash-forwarder.key,例如)。
现在,开始使用 Logstash 服务:
1sudo service logstash start
如果问题已经解决,不应该有新的日志条目。几秒钟后,检查Logstash服务的状态:
1sudo service logstash status
如果它在运行,你已经解决了问题。
问题:Logstash在 Elasticsearch 中运行但不存储日志
如果 Logstash 正在运行,但不会在 Elasticsearch 中存储日志,那是因为它无法到达 Elasticsearch. 通常情况下,这是由于 Elasticsearch 无法运行。
1[secondary_label Logstash logs (Elasticsearch isn't running):]
2{:timestamp=>"2017-12-01T16:53:29.571000+0000", :message=>"Connection refused (Connection refused)", :class=>"Manticore::SocketException", :backtrace=>[ruby-backtrace-info-here], :level=>:error}
在这种情况下,通过遵循 Elasticsearch 故障排除步骤来确保 Elasticsearch 运行。
你也可以看到这样的错误:
1[secondary_label Logstash logs (Logstash is configured to send its output to the wrong host):]
2{:timestamp=>"2017-12-01T16:56:26.274000+0000", :message=>"Attempted to send a bulk request to Elasticsearch configured at '[\"http://localhost:9200/\"]', but Elasticsearch appears to be unreachable or down!", :error_message=>"Connection refused (Connection refused)", :class=>"Manticore::SocketException", :client_config=>{:hosts=>["http://localhost:9200/"], :ssl=>nil, :transport_options=>{:socket_timeout=>0, :request_timeout=>0, :proxy=>nil, :ssl=>{}}, :transport_class=>Elasticsearch::Transport::Transport::HTTP::Manticore, :logger=>nil, :tracer=>nil, :reload_connections=>false, :retry_on_failure=>false, :reload_on_failure=>false, :randomize_hosts=>false}, :level=>:error}
3{:timestamp=>"2017-12-01T16:57:49.090000+0000", :message=>"SIGTERM received. Shutting down the pipeline.", :level=>:warn}
这表明您的 Logstash 配置中的输出部分可能指向错误的主机. 要解决此问题,请确保 Elasticsearch 运行,并检查您的 Logstash 配置:
1sudo vi /etc/logstash/conf.d/30-elasticsearch-output.conf
检查hosts => [localhost:9200]行是否指向正在运行 Elasticsearch 的主机
1[secondary_label Logstash output configuration excerpt]
2output {
3 elasticsearch {
4 hosts => ["localhost:9200"]
5 sniffing => true
6. . .
保存和退出. 此示例假定 Elasticsearch 在本地中运行。
重启 Logstash 服务。
1sudo service logstash restart
然后检查 Logstash 日志以发现任何错误。
Filebeat:如何检查它是否在运行
Filebeat 运行在您的 客户端机器上,并将日志发送到您的 ELK 服务器. 如果 Filebeat 没有运行,您将无法将各种日志发送到 Logstash. 因此,日志不会存储在 Elasticsearch 中,并且不会出现在 Kibana 中. 本节将向您展示如何检查 Filebeat 是否正常工作。
验证日志已成功发送
了解 Filebeat 是否正确地向 Logstash 发送日志的最简单的方法是检查 syslog 日志中的 Filebeat 错误。
1sudo tail /var/log/syslog | grep filebeat
如果一切都设置正确,您应该在停止或启动 Filebeat 流程时看到一些日志条目,但没有其他东西。
如果你看不到任何日志条目,你应该验证Filebeat正在运行。
检查服务正在运行
最基本的检查是Filebeat的状态:
1sudo service filebeat status
如果 Filebeat 正在运行,您将看到此输出:
1[secondary_label Output]
2* filebeat is running
否则,如果服务不运行,您将看到此消息:
1[secondary_label Output]
2 * filebeat is not running
如果 Filebeat 不运行,请尝试使用此命令启动:
1sudo service filebeat start
然后再次检查状态 如果这并未解决问题,以下部分将帮助您解决您的 Filebeat 问题,我们将涵盖常见的 Filebeat 问题以及如何解决这些问题。
问题:Filebeat 不运行
如果 Filebeat 无法在您的客户端机器上运行,则有几个潜在原因。本节将涵盖各种常见情况,其中 Filebeat 将无法运行,并提出潜在的解决方案。
原因:配置包含语法错误
如果 Filebeat 在其配置文件中有错误,该文件位于 /etc/filebeat/filebeat.yml,该服务将无法正常启动。
1[secondary_label Output]
2Loading config file error: YAML config parsing failed on /etc/filebeat/filebeat.yml: yaml: line 13: could not find expected ':'. Exiting.
在这种情况下,配置文件中出现一个键盘。 若要解决这个问题,请编辑 Filebeat 配置的侵犯部分。 如需指导,请遵循 ELK 堆栈教程中的 Set Up Filebeat (Add Client Servers)的 Configure Filebeat子部分。
编辑 Filebeat 配置后,请尝试重新启动服务:
1sudo service filebeat start
如果没有看到错误输出,问题已解决。
原因:SSL证书缺失或无效
Filebeat 和 Logstash 之间的通信需要 SSL 证书来进行身份验证和加密. 如果 Filebeat 没有正常启动,您应该检查 syslog 是否存在类似于以下的错误:
1[secondary_label Output]
2Error Initialising publisher: open /etc/pki/tls/certs/logstash-forwarder.crt: no such file or directory
這表示「logstash-forwarder.crt」檔案不在適當的位置. 要解決這個問題,請將 SSL 證書從 ELK 伺服器複製到您的客戶端機器,根據 ELK 堆積教程的 [設定檔案(添加客戶伺服器)]部分(https://andsky.com/tech/tutorials/how-to-install-elasticsearch-logstash-and-kibana-elk-stack-on-ubuntu-14-04#set-up-filebeat-(add-client-servers))的適當子節。
将相应的 SSL 证书文件放到正确的位置后,请尝试重新启动 Filebeat。
如果 SSL 证书无效,日志应该是这样的:
1[secondary_label syslog (Certificate is invalid):]
2transport.go:125: SSL client failed to connect with: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "elk.example.com")
请注意,错误消息表示证书存在,但无效. 在这种情况下,您需要遵循 ELK 堆栈教程的 生成 SSL 证书部分,然后将 SSL 证书复制到客户端机(Set Up Filebeat (Add Client Servers))。
在确保证书有效且位于正确位置后,您需要重新启动 Logstash(在 ELK 服务器上),强迫其使用新的 SSL 密钥:
1sudo service logstash restart
然后启动FileBeat(在客户端机上):
1sudo service filebeat start
再次检查日志,以确保问题已解决。
问题:Filebeat 无法连接到 Logstash
如果 Logstash (在 ELK 服务器上) 无法通过 Filebeat (您的客户端服务器) 访问,您将看到错误日志条目如下:
1[secondary_label syslog (Connection refused):]
2transport.go:125: SSL client failed to connect with: dial tcp 203.0.113.4:5044: getsockopt: connection refused
Logstash 无法访问的常见原因包括以下几点:
- Logstash 无法运行(在 ELK 服务器上)
- 每个服务器的防火墙都阻止了对端口
5043的连接 * Filebeat 未配置正确的 IP 地址、主机名称或端口
若要解决此问题,请首先检查 Logstash 是否在 ELK 服务器上运行,并按照本指南的 Logstash 故障排除部分进行检查。
Filebeat 配置可以用这个命令进行编辑:
1sudo vi /etc/filebeat/filebeat.yml
验证 Logstash 连接信息是否正确后,请尝试重新启动 Filebeat:
1sudo service filebeat restart
再次检查 Filebeat 日志,以确保问题已解决。
对于一般的 Filebeat 指南,请遵循 ELK 堆栈教程的 设置 Filebeat (添加客户端服务器) 的 ** Configure Filebeat**子部分。
Elasticsearch:如何检查它是否在运行
如果 Elasticsearch 没有运行,则您的 ELK 堆栈不会起作用. Logstash 将无法将新日志添加到 Elasticsearch,而 Kibana 将无法从 Elasticsearch 获取日志以进行报告。
检查服务正在运行
最基本的检查是 Elasticsearch 服务的状态:
1sudo service elasticsearch status
如果 Elasticsearch 正在运行,您将看到此输出:
1[secondary_label Elasticsearch status (OK):]
2 * elasticsearch is running
否则,如果服务不运行,您将看到此消息:
1[secondary_label Elasticsearch status (Bad):]
2 * elasticsearch is not running
在这种情况下,您应该遵循以下几个部分,这些部分涵盖了 Elasticsearch 故障排除。
检查它是否响应 HTTP 请求
默认情况下,Elasticsearch 在端口9200上响应 HTTP 请求(可以在配置文件中通过指定新的http.port值来定制)。
使用此命令使用 curl 发送 HTTP GET 请求(假设您的 Elasticsearch 可在localhost上访问):
1curl localhost:9200
如果 Elasticsearch 正在运行,您应该看到一个类似于此的响应:
1[secondary_label Output]
2{
3 "name" : "Hildegarde",
4 "cluster_name" : "elasticsearch",
5 "cluster_uuid" : "E8q9kr-0RxycYhSLNx8xeA",
6 "version" : {
7 "number" : "2.4.6",
8 "build_hash" : "5376dca9f70f3abef96a77f4bb22720ace8240fd",
9 "build_timestamp" : "2017-07-18T12:17:44Z",
10 "build_snapshot" : false,
11 "lucene_version" : "5.5.4"
12 },
13 "tagline" : "You Know, for Search"
14}
您也可以使用此命令检查您的 Elasticsearch 集群的状态:
1curl localhost:9200/_cluster/health?pretty
你的输出应该像这样的东西:
1[secondary_label Output]
2{
3 "cluster_name" : "elasticsearch",
4 "status" : "yellow",
5 "timed_out" : false,
6 "number_of_nodes" : 1,
7 "number_of_data_nodes" : 1,
8 "active_primary_shards" : 6,
9 "active_shards" : 6,
10 "relocating_shards" : 0,
11 "initializing_shards" : 0,
12 "unassigned_shards" : 6,
13 "delayed_unassigned_shards" : 0,
14 "number_of_pending_tasks" : 0,
15 "number_of_in_flight_fetch" : 0,
16 "task_max_waiting_in_queue_millis" : 0,
17 "active_shards_percent_as_number" : 50.0
18}
请注意,如果您的 Elasticsearch 集群由单个节点组成,则您的集群可能具有黄色状态,这对于单个节点集群来说是正常的;您可以通过添加至少一个节点到您的 Elasticsearch 集群来升级到绿色状态。
问题: Elasticsearch 不运行
如果 Elasticsearch 无法运行,有许多潜在的原因,本节将涵盖各种常见的 Elasticsearch 无法运行的情况,并提出潜在的解决方案。
原因:从未开始
如果 Elasticsearch 没有运行,它可能并未在第一时间启动; Elasticsearch 安装后不会自动启动。
1sudo service elasticsearch start
请等待大约 10 秒,然后再次检查 Elasticsearch 状态。
原因: Elasticsearch 服务未启用,服务器重新启动
如果 Elasticsearch 正常工作,但不再工作,则可能无法正常启用。 默认情况下,Elasticsearch 服务无法启动启动,您必须明确启用 Elasticsearch 启动自动启动:
1sudo update-rc.d elasticsearch defaults 95 10
Elasticsearch 现在应该自动启动,通过重新启动服务器来测试它是否有效。
原因: Elasticsearch 配置错误
如果 Elasticsearch 在其配置文件中有错误,该文件位于 /etc/elasticsearch/elasticsearch.yml,则该服务将无法正确启动。
向您的服务器打开两个终端会话,以便在尝试启动服务时查看 Elasticsearch 日志。
在第一个终端会话中,我们将看看日志:
1tail -f /var/log/elasticsearch/elasticsearch.log
这将显示最近的日志条目,以及任何未来的日志条目。
在第二个终端会话中,尝试启动 Elasticsearch 服务:
1sudo service elasticsearch start
返回第一个终端会话以查看 Elasticsearch 启动时生成的日志。
如果您看到显示错误或例外的日志条目(例如错误,例外或错误),请尝试找到一个说明错误的原因的行。
1[secondary_label Elasticsearch logs (Bad):]
2...
3[2015-10-27 15:24:43,495][INFO ][node ] [Shadrac] starting ...
4[2015-10-27 15:24:43,626][ERROR][bootstrap ] [Shadrac] Exception
5org.elasticsearch.transport.BindTransportException: Failed to resolve host [null]
6 at org.elasticsearch.transport.netty.NettyTransport.bindServerBootstrap(NettyTransport.java:402)
7 at org.elasticsearch.transport.netty.NettyTransport.doStart(NettyTransport.java:283)
8 at org.elasticsearch.common.component.AbstractLifecycleComponent.start(AbstractLifecycleComponent.java:85)
9 at org.elasticsearch.transport.TransportService.doStart(TransportService.java:153)
10 at org.elasticsearch.common.component.AbstractLifecycleComponent.start(AbstractLifecycleComponent.java:85)
11 at org.elasticsearch.node.internal.InternalNode.start(InternalNode.java:257)
12 at org.elasticsearch.bootstrap.Bootstrap.start(Bootstrap.java:160)
13 at org.elasticsearch.bootstrap.Bootstrap.main(Bootstrap.java:248)
14 at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:32)
15Caused by: java.net.UnknownHostException: incorrect_hostname: unknown error
16...
请注意,示例日志的最后一行表示出现了UnknownHostException: incorrect_hostname错误,此特定示例表明network.host已设置为incorrect_hostname,这不会解决任何问题。
若要解决此问题,请编辑 Elasticsearch 配置文件:
1sudo vi /etc/elasticsearch/elasticsearch.yml
在示例中,我们应该寻找指定 network.host: incorrect_hostname 的行,并将其更改为这样:
1[label /etc/elasticsearch/elasticsearch.yml excerpt]
2...
3network.host: localhost
4...
保存和退出。
现在,在第二个终端上,启动Elasticsearch服务:
1sudo service elasticsearch start
如果问题已解决,您应该看到无错误的日志,表明 Elasticsearch 已经启动。
1[secondary_label Elasticsearch logs (Good):]
2...
3[2015-10-27 15:29:21,980][INFO ][node ] [Garrison Kane] initializing ...
4[2015-10-27 15:29:22,084][INFO ][plugins ] [Garrison Kane] loaded [], sites []
5[2015-10-27 15:29:22,124][INFO ][env ] [Garrison Kane] using [1] data paths, mounts [[/ (/dev/vda1)]], net usable_space [52.1gb], net total_space [58.9gb], types [ext4]
6[2015-10-27 15:29:24,532][INFO ][node ] [Garrison Kane] initialized
7[2015-10-27 15:29:24,533][INFO ][node ] [Garrison Kane] starting ...
8[2015-10-27 15:29:24,646][INFO ][transport ] [Garrison Kane] bound_address {inet[/127.0.0.1:9300]}, publish_address {inet[localhost/127.0.0.1:9300]}
9[2015-10-27 15:29:24,682][INFO ][discovery ] [Garrison Kane] elasticsearch/WJvkRFnbQ5mLTgOatk0afQ
10[2015-10-27 15:29:28,460][INFO ][cluster.service ] [Garrison Kane] new_master [Garrison Kane][WJvkRFnbQ5mLTgOatk0afQ][elk-run][inet[localhost/127.0.0.1:9300]], reason: zen-disco-join (elected_as_master)
11[2015-10-27 15:29:28,561][INFO ][http ] [Garrison Kane] bound_address {inet[/127.0.0.1:9200]}, publish_address {inet[localhost/127.0.0.1:9200]}
12[2015-10-27 15:29:28,562][INFO ][node ] [Garrison Kane] started
13...
现在如果你检查 Elasticsearch 状态,你应该看到它正常运行。
您可能与我们的例子有不同的配置问题. 如果您能够弄清楚错误的含义,请尝试自行修复它. 如果这失败了,请尝试在互联网上搜索不包含服务器特定的信息的单个错误行(例如 IP 地址或自动生成的 Elasticsearch 节点名称)。
结论
希望这个解决问题指南帮助您解决您在 ELK 堆栈设置中遇到的任何问题. 如果您有任何问题或建议,请在下面的评论中留言!