作者选择了 多样性在技术基金作为 写给捐款计划的一部分接受捐款。
介绍
在本教程中,您将设置一个本地部署的 Great Expectations,一个开源数据验证和文档库,用Python编写。 数据验证对于确保您在管道中处理的数据是正确的,并且没有任何数据质量问题,因为错误的输入或转换错误可能发生。
完成后,您将能够将大期望连接到数据,创建一套期望,使用这些期望验证一批数据,并生成数据质量报告,其中包含验证结果。
前提条件
要完成本教程,您将需要:
- Python 3.6 或更高版本的本地开发环境. 您可以在本系列中遵循操作系统的教程: 如何安装和设置 Python 3 的本地编程环境. 建议使用本地编程环境以避免与浏览器连接的问题。
- 一些熟悉 Python。 您可以查看 如何在 Python 电子书中编码 了解更多。
- 一些熟悉 Jupyter 笔记本 。
- 运行安装 Git 。
第一步:建立大期望并启动一个大期望项目
在此步骤中,您将在本地Python环境中安装Great Expectations包,下载本教程中使用的样本数据,并启动Great Expectations项目。
首先,打开终端,并确保激活您的虚拟Python环境. 使用以下命令安装Great Expectations Python包和命令行工具(CLI):
1pip install great_expectations==0.13.35
<$>[注] 注:本教程是针对Great Expectations版本 0.13.35开发的,可能不适用于其他版本。
若要访问示例数据存储库,请运行以下 git 命令来克隆目录并将其更改为工作目录:
1git clone https://github.com/do-community/great_expectations_tutorial
2cd great_expectations_tutorial
存储库只包含一个名为数据的文件夹,其中包含两个示例 CSV 文件,其中包含您将在本教程中使用的数据。
1ls data
您将看到以下输出:
1[secondary_label Output]
2yellow_tripdata_sample_2019-01.csv yellow_tripdata_sample_2019-02.csv
Great Expectations 与许多不同类型的数据一起工作,例如连接到关系数据库、Spark 数据框架和各种文件格式。 为本教程的目的,您将使用包含一小组出租车旅行数据的这些 CSV 文件来开始。
最后,通过运行下面的命令将目录初始化为大期望项目,请确保使用--v3-api旗帜,因为这会将您切换到使用包中最新的API:
1great_expectations --v3-api init
当被问到OK 继续? [Y/n]:时,按ENTER来继续。
这将创建一个名为大_期望的文件夹,其中包含您的大期望项目的基本配置,也被称为 Data Context。
1ls great_expectations
您将看到在大_期望文件夹中创建的文件和子目录的第一级:
1[secondary_label Output]
2checkpoints great_expectations.yml plugins
3expectations notebooks uncommitted
文件夹存储所有相关的内容,为您的 Great Expectations 设置. The great_expectations.yml 文件包含所有重要的配置信息. 请自由探索文件夹和配置文件稍微更多,然后继续到下一个步骤在教程中。
在下一步中,您将添加一个数据源,以指向您的数据大期望。
步骤 2 – 添加数据源
在此步骤中,您将在大期望中配置数据源,这允许您自动创建称为 Expectations 的数据声明,并使用该工具验证数据。
在项目目录中,运行以下命令:
1great_expectations --v3-api datasource new
请输入提示为数据目录配置基于文件的数据源时显示的选项:
1[secondary_label Output]
2What data would you like Great Expectations to connect to?
3 1. Files on a filesystem (for processing with Pandas or Spark)
4 2. Relational database (SQL)
5: 1
6
7What are you processing your files with?
8 1. Pandas
9 2. PySpark
10: 1
11
12Enter the path of the root directory where the data files are stored. If files are on local disk enter a path relative to your current working directory or an absolute path.
13: data
通过ENTER确认目录路径后,Great Expectations将在您的 Web 浏览器中打开一个 _Jupyter 笔记本,允许您完成数据源的配置并将其存储到您的数据背景中。
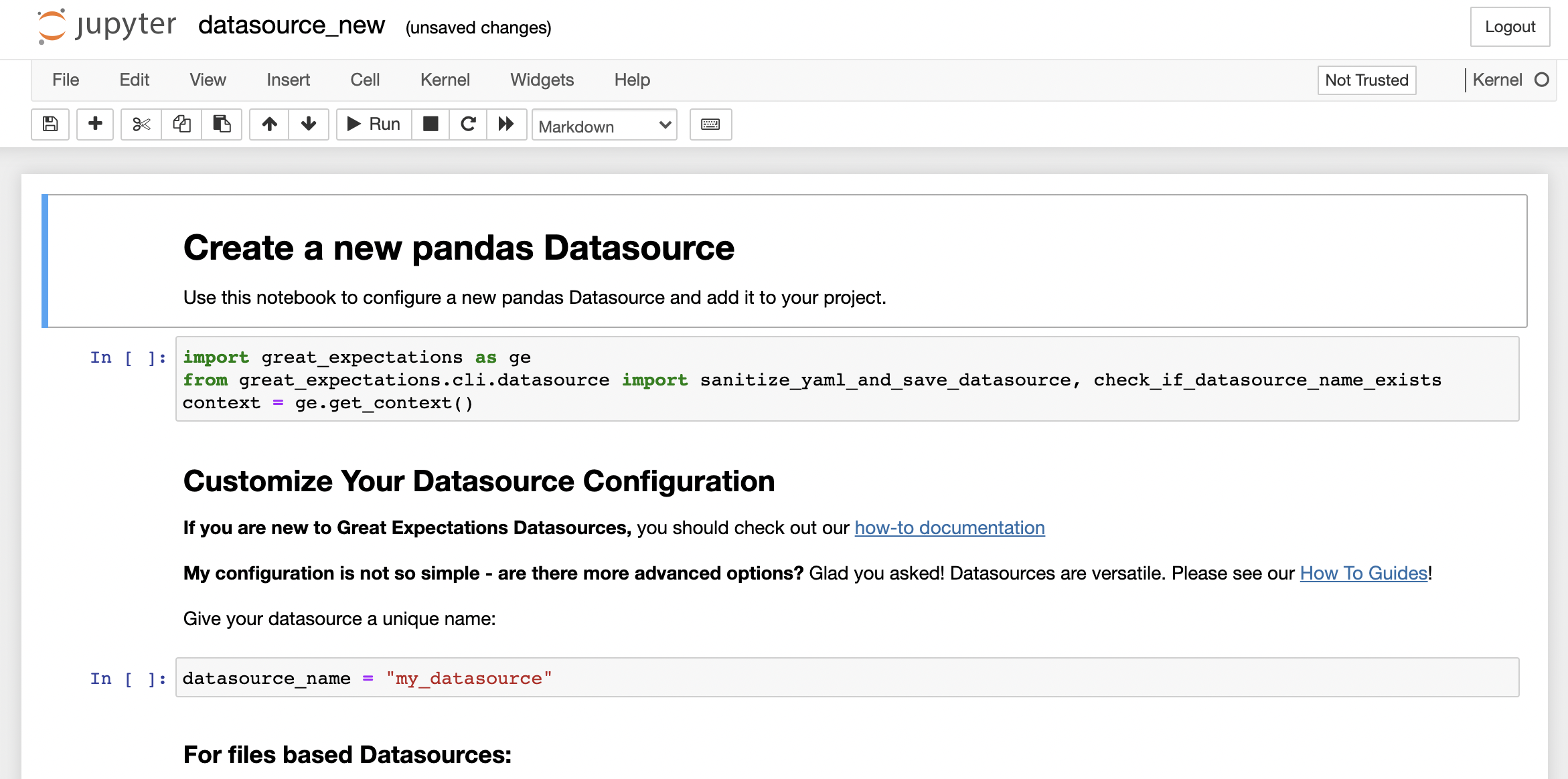
笔记本中包含几个预先填充的Python代码单元格来配置您的数据源。您可以更改数据源的设置,如名称,如果您喜欢的话。但是,为本教程的目的,您将把一切都留在原地,并使用Cell > Run All菜单选项执行所有单元格。
1[secondary_label Output]
2[{'data_connectors': {'default_inferred_data_connector_name': {'module_name': 'great_expectations.datasource.data_connector',
3 'base_directory': '../data',
4 'class_name': 'InferredAssetFilesystemDataConnector',
5 'default_regex': {'group_names': ['data_asset_name'], 'pattern': '(.*)'}},
6 'default_runtime_data_connector_name': {'module_name': 'great_expectations.datasource.data_connector',
7 'class_name': 'RuntimeDataConnector',
8 'batch_identifiers': ['default_identifier_name']}},
9 'module_name': 'great_expectations.datasource',
10 'class_name': 'Datasource',
11 'execution_engine': {'module_name': 'great_expectations.execution_engine',
12 'class_name': 'PandasExecutionEngine'},
13 'name': 'my_datasource'}]
这表明您已将名为my_datasource的新数据源添加到您的数据背景中。
<$>[警告]
** 警告:** 前往前,用笔记本关闭浏览器选项卡,返回终端,然后按CTRL+C关闭正在运行的笔记本服务器,然后继续。
您现在已经成功设置了一个数据源,指向数据目录,这将允许您通过大期望访问目录中的CSV文件。
步骤 3 — 使用自动配置文件创建预期套件
在本教程的这一步中,您将使用内置的 Profiler 创建一组基于某些现有数据的期望. 为此,让我们仔细看看您下载的样本数据:
- 文件
yellow_tripdata_sample_2019-01.csv和yellow_tripdata_sample_2019-02.csv分别包含 2019 年 1 月和 2 月的出租车旅行数据。 - 本教程假定您知道 1 月的数据是正确的,并且您希望确保任何后续的数据文件在数字或行、列以及某些列值的分布方面匹配 1 月的数据。
为此,您将基于1月数据的某些属性创建期望(数据声明),然后在稍后的一步中使用这些期望验证2月数据。
1great_expectations --v3-api suite new
通过选择下面的输出中显示的选项,您将指定您希望使用配置文件自动生成预期,使用yellow_tripdata_sample_2019-01.csv数据文件作为输入。
1[secondary_label Output]
2Using v3 (Batch Request) API
3How would you like to create your Expectation Suite?
4 1. Manually, without interacting with a sample batch of data (default)
5 2. Interactively, with a sample batch of data
6 3. Automatically, using a profiler
7: 3
8
9A batch of data is required to edit the suite - let's help you to specify it.
10
11Which data asset (accessible by data connector "my_datasource_example_data_connector") would you like to use?
12 1. yellow_tripdata_sample_2019-01.csv
13 2. yellow_tripdata_sample_2019-02.csv
14: 1
15
16Name the new Expectation Suite [yellow_tripdata_sample_2019-01.csv.warning]: my_suite
17
18When you run this notebook, Great Expectations will store these expectations in a new Expectation Suite "my_suite" here:
19
20 <path_to_project>/great_expectations_tutorial/great_expectations/expectations/my_suite.json
21
22Would you like to proceed? [Y/n]: <press ENTER>
这将打开另一个Jupyter笔记本,允许您完成预期套件的配置。笔记本包含足够的代码来配置内置配置器,该笔记本会查看您选择的CSV文件,并根据数据中所发现的数据为文件中的每个列创建某些类型的预期。
滚动到笔记本中的第二个代码单元格,其中包含一个列表的忽略_列。默认情况下,配置文件将忽略所有列,所以让我们评论其中的一些,以确保配置文件创建对它们的期望。
1ignored_columns = [
2# "vendor_id"
3# , "pickup_datetime"
4# , "dropoff_datetime"
5# , "passenger_count"
6 "trip_distance"
7, "rate_code_id"
8, "store_and_fwd_flag"
9, "pickup_location_id"
10, "dropoff_location_id"
11, "payment_type"
12, "fare_amount"
13, "extra"
14, "mta_tax"
15, "tip_amount"
16, "tolls_amount"
17, "improvement_surcharge"
18, "total_amount"
19, "congestion_surcharge"
20,]
请确保在trip_distance之前删除字符串。 通过评论列vendor_id,pickup_datetime,dropoff_datetime和passenger_count,您会告诉个人资料分析师为这些列生成期望。 此外,个人资料分析师还会生成 table-level Expectations,例如数据中的列数和名称,以及行数。 再次,使用Cell > Run All菜单选项在笔记本中执行所有单元格。
执行本笔记本中的所有单元格时,会发生两件事:
- 代码使用自动配置文件创建一个期望套件,并使用您要求使用的
yellow_tripdata_sample_2019-01.csv文件。 - 笔记本中的最后一个单元格也配置为运行验证并打开一个新的浏览器窗口 Data Docs,这是数据质量报告。
在下一步中,您将更仔细地查看在新浏览器窗口中打开的数据文档。
步骤 4 – 探索数据文件
在本教程的这一步,你会检查数据文件,大期望生成的,并学习如何解释不同的信息片段. 去刚刚打开的浏览器窗口,并看看页面,显示在下面的屏幕截图。
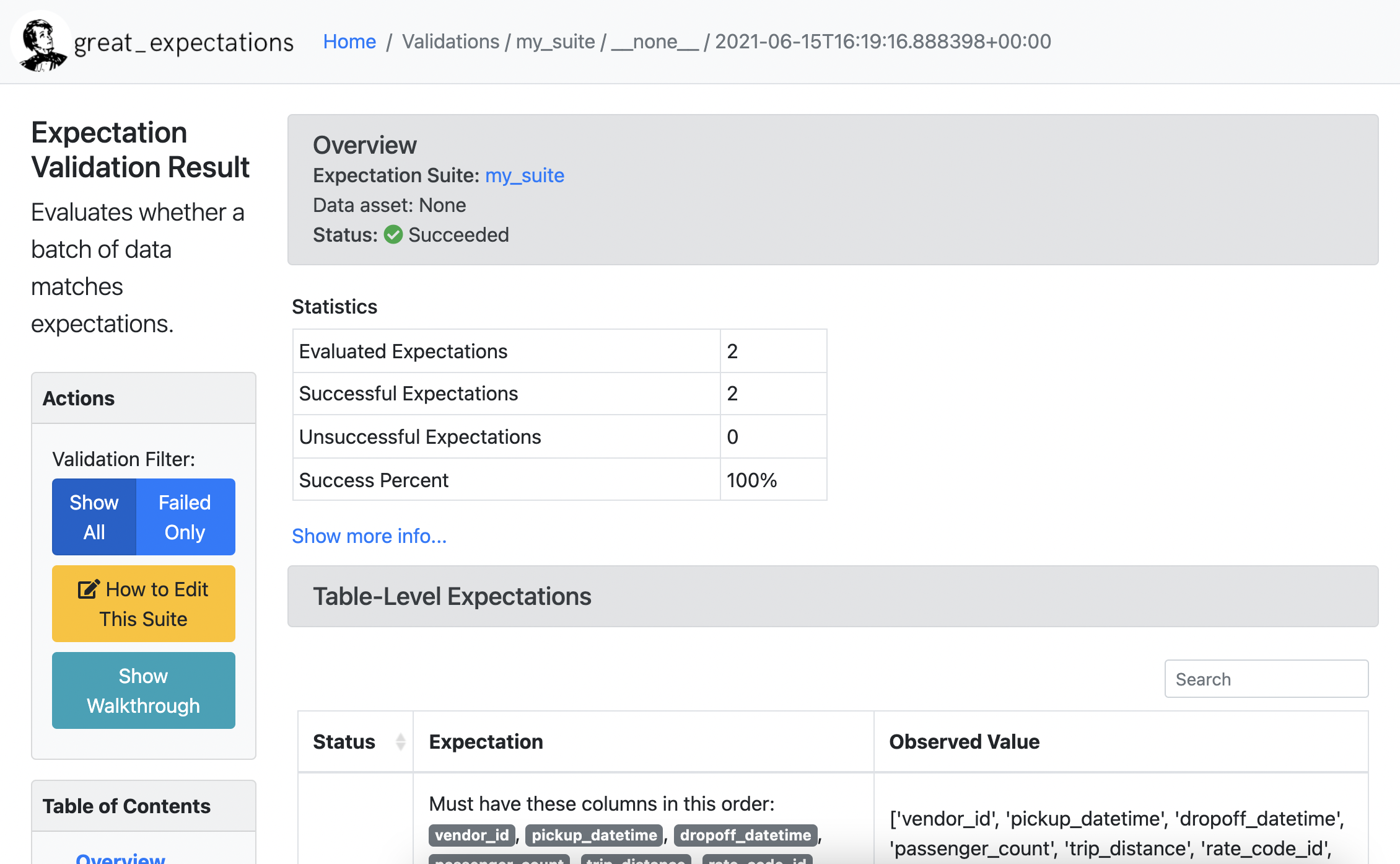
在页面顶部,你会看到一个名为概览的框,其中包含一些关于你刚刚使用新创建的期望套件my_suite运行验证的信息。它会告诉你状态:成功,并显示一些关于运行了多少期望的基本统计数据。如果您向下滚动,你会看到一个名为表级期望的部分。
让我们专注于一个特定的预期:在passenger_count列中,有一个预期表示值必须属于这个集合:1 2 3 4 5 6``,该列被标记为绿色标记,并具有0%意外的观察值。这告诉您,在1月CSV文件中,配置文件查看了passenger_count列中的值,并仅检测到1到6的值,这意味着所有出租车旅行中有1到6名乘客。大预期随后为这一事实创建了一个预期。笔记本中的最后一个单元格然后触发了1月CSV文件的验证,并发现没有任何意外值。
在此步骤中,您审查了数据文档,并观察了其预期的passenger_count列,在下一步,您将看到如何验证不同的数据批。
步骤 5 – 创建检查点和运行验证
在本教程的最后一步中,您将创建一个新的检查点,该检查点将一组期望套件和一批数据组合,以执行该数据的验证。创建检查点后,您将运行它来验证2月的出租车数据CSV文件,并查看该文件是否通过了您之前创建的预期。 首先,返回您的终端并停止Jupyter笔记本,如果它仍在运行,按CTRL+C。 下面的命令将启动工作流程,创建一个名为My_checkpoint的新检查点:
1great_expectations --v3-api checkpoint new my_checkpoint
这将打开一个 Jupyter 笔记本,其中包含一些预定义的代码来配置检查点。笔记本中的第二个代码单元将有从现有数据源预定义的data_asset_name,这将是您之前看到的data目录中的两个 CSV 文件之一。确保data_asset_name是yellow_tripdata_sample_2019-02.csv,并在需要时修改代码以使用正确的文件名。
1my_checkpoint_name = "my_checkpoint" # This was populated from your CLI command.
2
3yaml_config = f"""
4name: {my_checkpoint_name}
5config_version: 1.0
6class_name: SimpleCheckpoint
7run_name_template: "%Y%m%d-%H%M%S-my-run-name-template"
8validations:
9 - batch_request:
10 datasource_name: my_datasource
11 data_connector_name: default_inferred_data_connector_name
12 data_asset_name: yellow_tripdata_sample_2019-02.csv
13 data_connector_query:
14 index: -1
15 expectation_suite_name: my_suite
16"""
17print(yaml_config)
18"""
此配置片段将配置一个新的检查点,它会读取yellow_tripdata_sample_2019-02.csv数据资产,即您的 2 月 CSV 文件,并使用期望套件my_suite验证它。
最后,要运行这个新的检查点并验证二月数据,请滚动到笔记本中的最后一个单元格。
1context.run_checkpoint(checkpoint_name=my_checkpoint_name)
2context.open_data_docs()
选择单元格并使用Cell > Run Cells菜单选项或SHIFT+ENTER键盘捷径运行它。
在验证结果概览页面上,点击顶部运行以导航到验证结果详细信息页面. 验证结果详细信息页面将看起来非常类似于您在上一步中看到的页面,但现在将显示预期套件失败,验证新的CSV文件。
在您在上一步中查看的乘客_计数列中查找预期值:值必须属于此集:‘1 2 3 4 5 6’。您会注意到它现在显示为失败,并突出显示1579 发现的意外值。 ≈15.79% 的 10000 行总值。 行还显示了列中发现的意外值的样本,即值 `0’。
请注意,每次在最后一个笔记本单元格中执行 Run_checkpoint 方法时,都会启动另一个验证运行,而在生产数据管道环境中,每次处理新批数据时,都会在笔记本外调用 Run_checkpoint 命令,以确保新数据通过所有验证。
结论
在本文中,您创建了 Great Expectations 数据验证框架的第一个本地部署,初始化了 Great Expectations 数据背景,创建了基于文件的新数据源,并使用内置的配置文件自动生成了 Expectation Suite。
本教程只教你大期望的基本知识。该套件包含更多配置数据源的选项,以连接到其他类型的数据,例如关系数据库。它还配备了一个强大的机制,可以根据表名或文件名中的模式匹配自动识别新数据集,这允许您只配置一个检查点一次以验证任何未来的数据输入。