介绍
除了跟踪和日志,监控和警报是 Kubernetes 可观察性堆栈的重要组成部分,为您的 Kubernetes 集群设置监控允许您跟踪资源使用情况,分析和调试应用程序错误。
监控系统通常由一个包含计量数据和可视化层的时间序列的数据库组成,此外,一个警报层会创建和管理警报,根据需要将它们传递给集成和外部服务。
一个流行的监控解决方案是开源的 Prometheus, Grafana和 Alertmanager堆栈:
- Prometheus是一个时间序列数据库和监控工具,通过测量指标终端点以及扫描和处理这些终端点暴露的数据来工作。它允许您使用PromQL(https://prometheus.io/docs/prometheus/latest/querying/basics/)来查询这些数据,这是一个时间序列数据查询语言。
- Grafana是一个数据可视化和分析工具,允许您为您的指标数据构建仪表板和图表。
此外,诸如 kube-state-metrics和 node_exporter等工具暴露了集群级的Kubernetes对象指标以及机器级的指标,如CPU和内存使用率。
在 Kubernetes 集群上实施此监控堆栈可能很复杂,但幸运的是,一些这种复杂性可以通过 Helm 包管理器和 CoreOS 的 Prometheus Operator 和 kube-prometheus 项目来管理。这些项目在 Prometheus 和 Grafana 的标准配置和仪表板中进行管理,并抽象一些较低级别的 Kubernetes 对象定义。
在本教程中,我们将展示如何在DigitalOcean Kubernetes群集(https://www.digitalocean.com/products/kubernetes)上安装Prometheus-operator头盔图表。
前提条件
要遵循本教程,您将需要:
- 一个 DigitalOcean Kubernetes集群.
- 在本地计算机上安装的
kubectl命令行接口,并配置为连接到您的集群. 您可以阅读有关安装和配置kubectl的更多信息(https://kubernetes.io/docs/tasks/tools/install-kubectl/)。 - 在本地计算机上安装的
Helm(https://helm.sh/)包管理器 (2.10+)和在您的集群上安装的Tiller,如下所述。
步骤 1 – 创建自定义值文件
在我们安装Prometheus-operator Helm 图表之前,我们将创建一个自定义值文件,用 DigitalOcean 特定的配置参数来排除图表中的某些默认值. 有关排除默认图表值的更多信息,请参阅 Helm 文件的 Helm Install部分。
首先,在本地计算机上创建并打开名为custom-values.yaml的文件,使用nano或您最喜欢的编辑器:
1nano custom-values.yaml
复制和粘贴以下自定义值,允许 Prometheus、Grafana 和 Alertmananger 组件的持久存储,并禁用在 DigitalOcean Kubernetes 上未暴露的 Kubernetes 控制板组件的监控:
1[label custom-values.yaml]
2# Define persistent storage for Prometheus (PVC)
3prometheus:
4 prometheusSpec:
5 storageSpec:
6 volumeClaimTemplate:
7 spec:
8 accessModes: ["ReadWriteOnce"]
9 storageClassName: do-block-storage
10 resources:
11 requests:
12 storage: 5Gi
13
14# Define persistent storage for Grafana (PVC)
15grafana:
16 # Set password for Grafana admin user
17 adminPassword: your_admin_password
18 persistence:
19 enabled: true
20 storageClassName: do-block-storage
21 accessModes: ["ReadWriteOnce"]
22 size: 5Gi
23
24# Define persistent storage for Alertmanager (PVC)
25alertmanager:
26 alertmanagerSpec:
27 storage:
28 volumeClaimTemplate:
29 spec:
30 accessModes: ["ReadWriteOnce"]
31 storageClassName: do-block-storage
32 resources:
33 requests:
34 storage: 5Gi
35
36# Change default node-exporter port
37prometheus-node-exporter:
38 service:
39 port: 30206
40 targetPort: 30206
41
42# Disable Etcd metrics
43kubeEtcd:
44 enabled: false
45
46# Disable Controller metrics
47kubeControllerManager:
48 enabled: false
49
50# Disable Scheduler metrics
51kubeScheduler:
52 enabled: false
在此文件中,我们将一些与图表在其 values.yaml 文件中包装的默认值列表。
首先,我们为 Prometheus、Grafana 和 Alertmanager 启用永久性存储,以便它们的数据在 Pod 重启过程中继续存储。 幕后,这为每个组件定义了 5 Gi 永久性量声明 (PVC),使用 DigitalOcean Block Storage 存储类别。 您应该调整这些 PVC 的大小以满足您的监控存储需求。 有关 PVC 的更多信息,请参阅 Persistent Volumes 来自官方 Kubernetes 文件。
接下来,用一个安全的密码代替your_admin_password,您将使用它与 admin用户登录到 Grafana指标仪表板。
然后我们将为 node-exporter配置不同的端口。 Node-exporter 运行在每个 Kubernetes 节点上,并向 Prometheus 提供操作系统和硬件指标。我们必须更改其默认端口以绕过 DigitalOcean Kubernetes 防火墙的默认设置,这将阻止端口 9100,但允许在 30000-32767 范围内的端口。 或者,您可以为 node-exporter 配置自定义防火墙规则。 要了解如何,请参阅 如何配置防火墙规则从官方的 DigitalOcean Cloud Firewalls 文件中。
最后,我们将禁用在DigitalOcean Kubernetes上不暴露指标的三个Kubernetes 控制平面组件的指标收集:Kubernetes 时间表和控制器管理器,以及集群数据存储。
若要查看prometheus-operator图表的可配置参数的完整列表,请参阅图表 repo README 或默认值文件中的 Configuration部分。
完成编辑后,保存并关闭文件. 现在我们可以使用 Helm 安装图表。
步骤 2 — 安装普罗米修斯操作员图表
Prometheus-operator Helm 图表将安装以下监控组件到您的 DigitalOcean Kubernetes 集群中:
- Prometheus 运算符, 一个 Kubernetes_ 操作器_ , 它允许您配置和管理 Prometheus 集群 。 Kubernetes运算器将特定域逻辑整合到与Kubernetes的包装,部署,以及应用程序的管理过程中. 为了更多地了解Kubernetes运营商,请参考CoreOS运营商概览. 为了更深入地了解普罗米修斯接线员的情况,请参看[此入门帖 (https://coreos.com/blog/the-prometheus-operator.html) 关于普罗米修斯接线员和普罗米修斯接线员[GitHub repo] (https://github.com/coreos/prometheus-operator). Prometheus 运算器将作为[调 (https://kubernetes.io/docs/concepts/workloads/controllers/deployment/)安装.
- 普罗米修斯,被安装为[statefulSet] (https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/).
- Alertmanager,是处理由普罗米修斯服务器发送的警报并引导其到PagerDuty等集成的服务. 要了解更多关于"提醒管理者"(Alerting)(https://prometheus.io/docs/practices/alerting/)的信息,请参考"普罗米修斯"文件. 警报管理器将安装为状态集.
- Grafana,一个时间序列数据可视化工具,它允许您对自己的Prometheus度量衡进行可视化并创建仪表板. Grafana将作为部署装置。 *节点-导出器,是Prometheus的导出器,运行在集群节点上,为Prometheus提供OS和硬件度量. 咨询node-exporters GitHub repo以学习更多. 节点出口器将安装为 [DeamonSet] (https://kubernetes.io/docs/concepts/workloads/controllers/daemonset/).
- kube- state- meters,一种能收听Kubernetes API服务器并生成关于部署和Pods等Kubernetes天体状态的参数的附加代理. 通过查阅kube-state-meters GitHub repo,可以学到更多. 库贝状态计量仪将作为部署装置安装。 (英语)
默认情况下,除了通过节点出口器、立方体状态指数和上述其他组件生成的扫描指数外,Prometheus 将配置为从以下组件中扫描指数:
- kubernetes API 服务器(https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/)。
- CoreDNS是 Kubernetes 集群 DNS 服务器。
- kubelet是与 kubernetes API 服务器相互作用的主要节点代理,用于管理节点上的 Pods 和容器。
- cAdvisor是发现运行容器并收集其 CPU、内存、文件系统和网络使用指标的节点代理。
在您的本地计算机上,让我们开始安装Prometheus-operator Helm 图表,并通过我们上面创建的自定义值文件:
1helm install --namespace monitoring --name doks-cluster-monitoring -f custom-values.yaml stable/prometheus-operator
在这里,我们运行头盔安装并将所有组件安装到监控名称空间中,我们同时创建它,这使我们能够清晰地将监控堆栈与Kubernetes群集的其他部分分离开来。我们将头盔发布命名为Doks-cluster-monitoring,然后传入我们在 步骤 1中创建的自定义值文件中。
你应该看到以下结果:
1[secondary_label Output]
2NAME: doks-cluster-monitoring
3LAST DEPLOYED: Mon Apr 22 10:30:42 2019
4NAMESPACE: monitoring
5STATUS: DEPLOYED
6
7RESOURCES:
8==> v1/PersistentVolumeClaim
9NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
10doks-cluster-monitoring-grafana Pending do-block-storage 10s
11
12==> v1/ServiceAccount
13NAME SECRETS AGE
14doks-cluster-monitoring-grafana 1 10s
15doks-cluster-monitoring-kube-state-metrics 1 10s
16
17. . .
18
19==> v1beta1/ClusterRoleBinding
20NAME AGE
21doks-cluster-monitoring-kube-state-metrics 9s
22psp-doks-cluster-monitoring-prometheus-node-exporter 9s
23
24NOTES:
25The Prometheus Operator has been installed. Check its status by running:
26 kubectl --namespace monitoring get pods -l "release=doks-cluster-monitoring"
27
28Visit https://github.com/coreos/prometheus-operator for instructions on how
29to create & configure Alertmanager and Prometheus instances using the Operator.
这表明 Prometheus Operator, Prometheus, Grafana 和上述其他组件已成功安装到您的 DigitalOcean Kubernetes 集群中。
按照 Helm install输出中的注释,使用kubectl get pods检查发布的Pods的状态:
1kubectl --namespace monitoring get pods -l "release=doks-cluster-monitoring"
你应该看到以下:
1[secondary_label Output]
2NAME READY STATUS RESTARTS AGE
3doks-cluster-monitoring-grafana-9d7f984c5-hxnw6 2/2 Running 0 3m36s
4doks-cluster-monitoring-kube-state-metrics-dd8557f6b-9rl7j 1/1 Running 0 3m36s
5doks-cluster-monitoring-pr-operator-9c5b76d78-9kj85 1/1 Running 0 3m36s
6doks-cluster-monitoring-prometheus-node-exporter-2qvxw 1/1 Running 0 3m36s
7doks-cluster-monitoring-prometheus-node-exporter-7brwv 1/1 Running 0 3m36s
8doks-cluster-monitoring-prometheus-node-exporter-jhdgz 1/1 Running 0 3m36s
这表明所有监控组件都已启动并运行,您可以使用Grafana及其预配置仪表板开始探索Prometheus指标。
步骤 3 – 访问 Grafana 和探索指数数据
Prometheus-operator Helm 图表将 Grafana 显示为ClusterIP服务,这意味着它只能通过集群内部 IP 地址访问。 要访问 Kubernetes 集群之外的 Grafana,您可以使用kubectl 补丁将现有的服务更新到NodePort或LoadBalancer等面向公众的类型,或者kubectl 端口向前将本地端口转发到 Grafana Pod 端口。
在本教程中,我们将转发端口,但要了解更多关于kubectl 补丁和Kubernetes服务类型,您可以从官方的 Kubernetes 文档中查阅 Update API Objects in Place Using kubectl patch和 Services。
首先,在监控名称空间中列出正在运行的服务:
1kubectl get svc -n monitoring
您应该看到以下服务:
1[secondary_label Output]
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 34m
4doks-cluster-monitoring-grafana ClusterIP 10.245.105.130 <none> 80/TCP 34m
5doks-cluster-monitoring-kube-state-metrics ClusterIP 10.245.140.151 <none> 8080/TCP 34m
6doks-cluster-monitoring-pr-alertmanager ClusterIP 10.245.197.254 <none> 9093/TCP 34m
7doks-cluster-monitoring-pr-operator ClusterIP 10.245.14.163 <none> 8080/TCP 34m
8doks-cluster-monitoring-pr-prometheus ClusterIP 10.245.201.173 <none> 9090/TCP 34m
9doks-cluster-monitoring-prometheus-node-exporter ClusterIP 10.245.72.218 <none> 30206/TCP 34m
10prometheus-operated ClusterIP None <none> 9090/TCP 34m
我们将将本地端口8000转移到80端口的Doks-cluster-monitoring-grafana服务,这将反过来转移到运行的Grafana Pod的端口3000。
1kubectl port-forward -n monitoring svc/doks-cluster-monitoring-grafana 8000:80
你应该看到以下结果:
1[secondary_label Output]
2Forwarding from 127.0.0.1:8000 -> 3000
3Forwarding from [::1]:8000 -> 3000
这表明本地端口8000正在成功转发到Grafana Pod。
在您的浏览器中访问 http://localhost:8000. 您应该看到以下 Grafana 登录页面:

输入 admin作为您在custom-values.yaml中配置的用户名和密码。
您将被带到以下 ** Home 仪表板**:
在左侧的导航栏中,选择 Dashboards按钮,然后单击 Manage:
您将被带到以下仪表板管理界面,该界面列出了由Prometheus-operator Helm 图表安装的仪表板:
这些仪表板由kubernetes-mixin生成,这是一个开源项目,允许您创建一个标准化的集群监控Grafana仪表板和Prometheus警报。
点击Kubernetes/Nodes仪表板,可视化特定节点的CPU、内存、磁盘和网络使用情况:
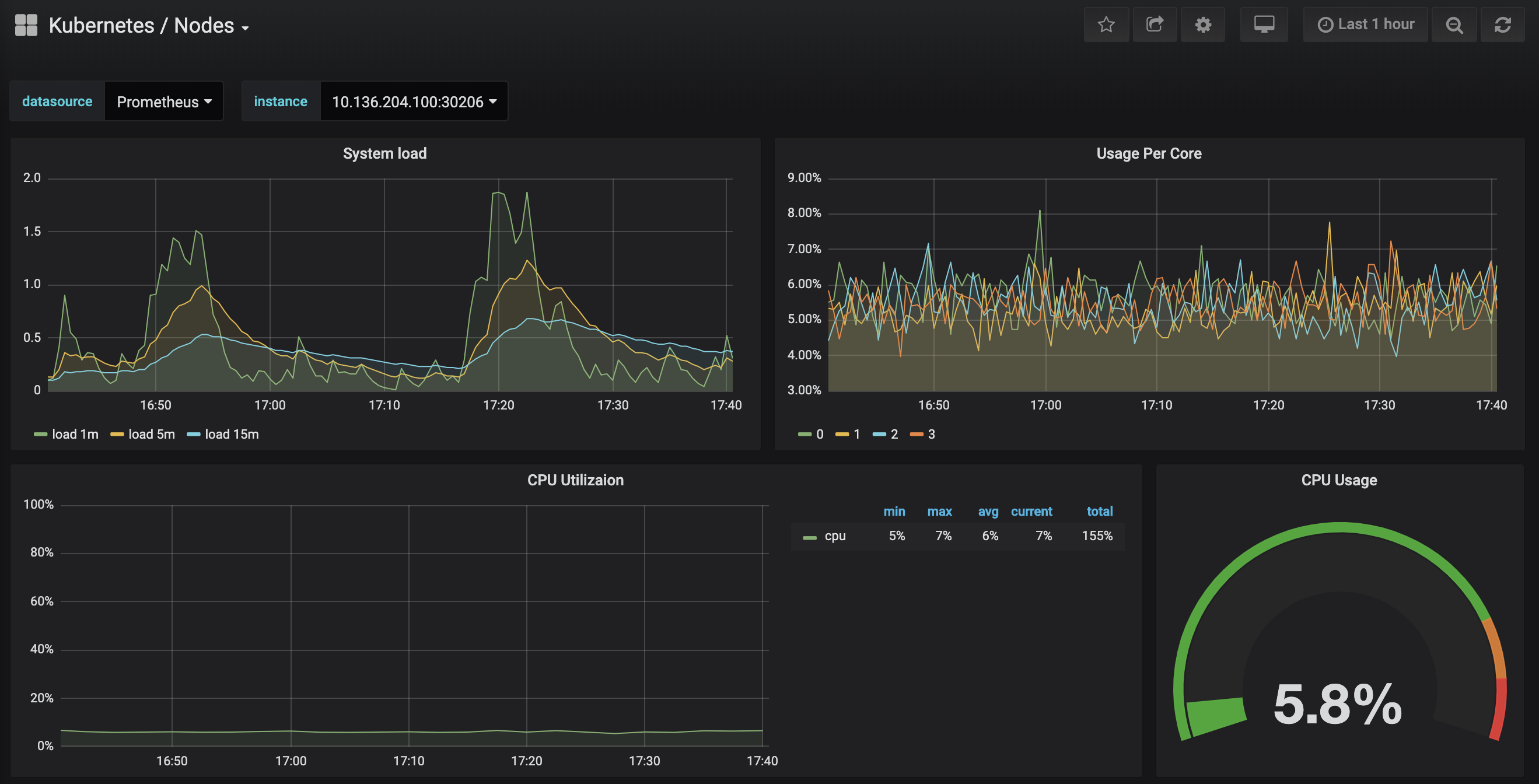
描述每个仪表板以及如何使用它们来可视化群集的指标数据超出了本教程的范围。 有关分析系统性能的使用方法的更多信息,请参阅 Brendan Gregg 的 The Utilization Saturation and Errors (USE) Method 页面。 Google 的 SRE Book 是另一个有用的资源,特别是第 6 章: Monitoring Distributed Systems 。
在下一步,我们将遵循类似的过程来连接并探索普罗米修斯监控系统。
步骤 4 – 访问 Prometheus 和 Alertmanager
要连接到 Prometheus Pods,我们再一次必须使用kubectl 端口前进来传输到本地端口. 如果您已经完成了探索Grafana,您可以通过打击CTRL-C来关闭端口前进隧道。
首先,在监控名称空间中列出正在运行的服务:
1kubectl get svc -n monitoring
您应该看到以下服务:
1[secondary_label Output]
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 34m
4doks-cluster-monitoring-grafana ClusterIP 10.245.105.130 <none> 80/TCP 34m
5doks-cluster-monitoring-kube-state-metrics ClusterIP 10.245.140.151 <none> 8080/TCP 34m
6doks-cluster-monitoring-pr-alertmanager ClusterIP 10.245.197.254 <none> 9093/TCP 34m
7doks-cluster-monitoring-pr-operator ClusterIP 10.245.14.163 <none> 8080/TCP 34m
8doks-cluster-monitoring-pr-prometheus ClusterIP 10.245.201.173 <none> 9090/TCP 34m
9doks-cluster-monitoring-prometheus-node-exporter ClusterIP 10.245.72.218 <none> 30206/TCP 34m
10prometheus-operated ClusterIP None <none> 9090/TCP 34m
我们将将本地端口9090转发到9090的Doks-cluster-monitoring-pr-prometheus服务:
1kubectl port-forward -n monitoring svc/doks-cluster-monitoring-pr-prometheus 9090:9090
你应该看到以下结果:
1[secondary_label Output]
2Forwarding from 127.0.0.1:9090 -> 9090
3Forwarding from [::1]:9090 -> 9090
这表明本地端口9090正在成功转发到Prometheus Pod。
在您的浏览器中访问 http://localhost:9090. 您应该看到以下 Prometheus ** 图表**页面:
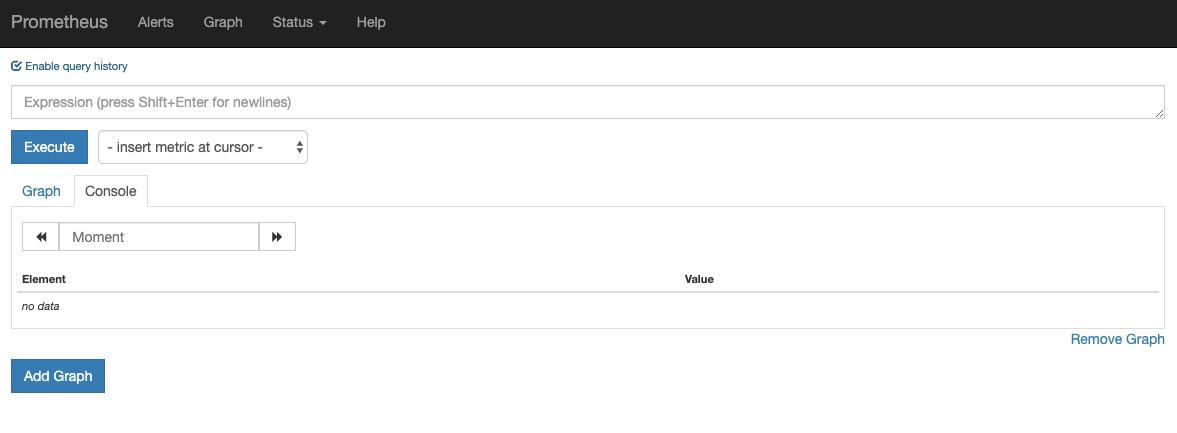
从这里,您可以使用PromQL,Prometheus查询语言,选择和汇总存储在其数据库中的时间序列指标。 有关PromQL的更多信息,请参阅Prometheus官方文件中的 Querying Prometheus。
在 Expression字段中,键入 machine_cpu_cores 并点击 Execute. 你应该看到一个列表的时间序列与计量 machine_cpu_cores 报告的CPU核心数量在给定节点上。
最后,在顶部的导航栏中,点击 状态,然后点击 目标,以查看 Prometheus 已配置的目标列表。
要了解更多关于Promtheus和如何查询您的集群指标,请参阅官方 Prometheus docs。
我们将遵循类似的过程来连接到 AlertManager,该程序管理 Prometheus 生成的 Alerts. 您可以通过点击 Prometheus 顶部导航栏中的 Alerts 来探索这些 Alerts。
要连接到 Alertmanager Pods,我们将再次使用kubectl 端口前进来转发本地端口. 如果您已经完成探索 Prometheus,您可以通过打击CTRL-C来关闭端口前进隧道。
首先,在监控名称空间中列出正在运行的服务:
1kubectl get svc -n monitoring
您应该看到以下服务:
1[secondary_label Output]
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 34m
4doks-cluster-monitoring-grafana ClusterIP 10.245.105.130 <none> 80/TCP 34m
5doks-cluster-monitoring-kube-state-metrics ClusterIP 10.245.140.151 <none> 8080/TCP 34m
6doks-cluster-monitoring-pr-alertmanager ClusterIP 10.245.197.254 <none> 9093/TCP 34m
7doks-cluster-monitoring-pr-operator ClusterIP 10.245.14.163 <none> 8080/TCP 34m
8doks-cluster-monitoring-pr-prometheus ClusterIP 10.245.201.173 <none> 9090/TCP 34m
9doks-cluster-monitoring-prometheus-node-exporter ClusterIP 10.245.72.218 <none> 30206/TCP 34m
10prometheus-operated ClusterIP None <none> 9090/TCP 34m
我们将将本地端口9093转移到9093的Doks-cluster-monitoring-pr-alertmanager服务端口。
1kubectl port-forward -n monitoring svc/doks-cluster-monitoring-pr-alertmanager 9093:9093
你应该看到以下结果:
1[secondary_label Output]
2Forwarding from 127.0.0.1:9093 -> 9093
3Forwarding from [::1]:9093 -> 9093
这表明本地端口9093正在成功转发到 Alertmanager Pod。
在您的浏览器中访问 http://localhost:9093. 您应该看到以下警报管理器 警报页面:
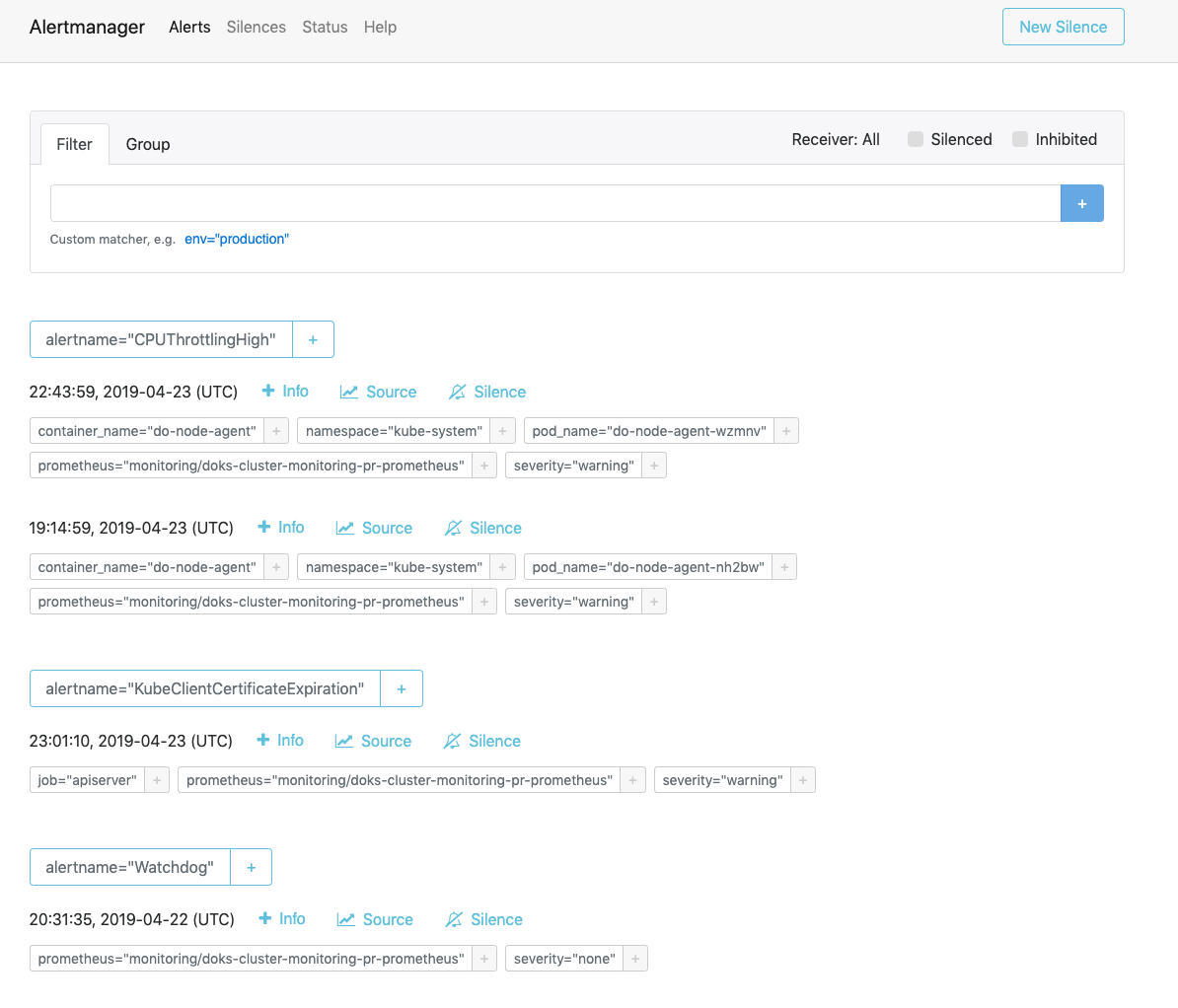
从这里,您可以探索发射警报,并可选地对它们保持沉默. 有关 Alertmanager 的更多信息,请参阅 官方 Alertmanager 文档。
结论
在本教程中,您已在您的 DigitalOcean Kubernetes 集群中安装了 Prometheus、Grafana 和 Alertmanager 监控堆栈,其中包含了一组标准的仪表板、Prometheus 规则和警报。由于使用了头盔,您可以使用头盔升级,头盔滚动和头盔删除来升级、滚动或删除监控堆栈。 有关这些功能的更多信息,请参阅 如何使用头盔包管理器在 Kubernetes 集群上安装软件。
您可能想手动构建、部署和配置 Prometheus Operator。 要做到这一点,请参阅 Prometheus Operator和 kube-prometheus GitHub repos。