介绍
镜像是扩展下载网站的一种方式,因此下载负载可以分布在世界许多地方的许多服务器上。镜像托管文件的副本,并由镜像目录管理。镜像目录是任何镜像系统的中心。
Mirroring 是一个独特的系统,有其自身的优点和缺点。 与基于 DNS 的系统不同, mirroring 更具灵活性。 不需要等待 DNS 或甚至信任 mirroring 服务器( mirror director 可以扫描镜子以检查其有效性和完整性)。
不幸的是,镜像系统会增加任何HTTP请求的覆盖率,因为请求必须前往镜像目录,然后重定向到真实文件,因此,镜像通常用于托管下载(单个大文件),但不建议网站(许多小文件)。
本教程将展示如何在一个服务器上设置 MirrorBrain 实例(一个流行的、功能丰富的镜子目录)和 rsync 服务器(rsync 允许镜子与目录同步文件)。
要求: *
在不同区域的两个Ubuntu 14.04Dropplets;一个目录和至少一个镜子。
步骤一:设置Apache
首先我们需要编译和安装 MirrorBrain。本教程的整个第一部分应该在 ** mirror director**服务器上完成。我们会让你知道何时切换到镜子。
如有必要,使用 sudo 访问根壳:
1sudo -i
MirrorBrain是一个大型的Apache模块,所以我们需要使用Apache来服务我们的文件。
1apt-get install apache2 libapache2-mod-geoip libgeoip-dev apache2-dev
GeoIP 是位置服务的 IP 地址,它将支持 MirrorBrain 将用户重定向到最佳下载位置的能力。我们需要更改 GeoIP 的配置文件以使其与 MirrorBrain 一起工作。
1nano /etc/apache2/mods-available/geoip.conf
添加 GeoIPOutput Env 行,删除 GeoIPDBFile 行,并添加 MMapCache 设置:
1<IfModule mod_geoip.c>
2 GeoIPEnable On
3 GeoIPOutput Env
4 GeoIPDBFile /usr/share/GeoIP/GeoIP.dat MMapCache
5</IfModule>
关闭并保存文件(Ctrl-x,然后 y,然后 Enter)。
将 GeoIP 数据库链接到 MirrorBrain 希望找到的位置:
1ln -s /usr/share/GeoIP /var/lib/GeoIP
接下来,让我们启用我们刚刚安装和配置的模块:
1a2enmod dbd
2a2enmod geoip
geoip 模块可能已经启用了;这很好。
步骤二:安装和编译 MirrorBrain
现在我们需要编译 MirrorBrain 模块,首先安装一些依赖:
1apt-get install python-pip python-dev libdbd-pg-perl python-SQLObject python-FormEncode python-psycopg2 libaprutil1-dbd-pgsql
2
3pip install cmdln
使用 Perl 来安装更多依赖。
1perl -MCPAN -e 'install Bundle::LWP'
你应该能够按 Enter或说 y来接受默认值。
你应该看到相当多的输出,以行结束:
1/usr/bin/make install -- OK
如果您收到警告或错误,您可能希望通过重新执行 perl -MCPAN -e 'install Bundle::LWP' 命令来重新运行配置。
安装最后的依赖。
1perl -MCPAN -e 'install Config::IniFiles'
现在我们可以下载并提取 MirrorBrain 源:
1wget http://mirrorbrain.org/files/releases/mirrorbrain-2.18.1.tar.gz
2tar -xzvf mirrorbrain-2.18.1.tar.gz
接下来我们需要在 MirrorBrain 中添加表单模块源:
1cd mirrorbrain-2.18.1/mod_mirrorbrain/
2wget http://apache.webthing.com/svn/apache/forms/mod_form.h
3wget http://apache.webthing.com/svn/apache/forms/mod_form.c
现在我们可以编译和启用 MirrorBrain 和表单模块:
1apxs -cia -lm mod_form.c
2apxs -cia -lm mod_mirrorbrain.c
然后是 MirrorBrain 自动索引模块:
1cd ~/mirrorbrain-2.18.1/mod_autoindex_mb
2apxs -cia mod_autoindex_mb.c
让我们来编译 MirrorBrain GeoIP 助手:
1cd ~/mirrorbrain-2.18.1/tools
2
3gcc -Wall -o geoiplookup_city geoiplookup_city.c -lGeoIP
4gcc -Wall -o geoiplookup_continent geoiplookup_continent.c -lGeoIP
将助手复制到命令目录:
1cp geoiplookup_city /usr/bin/geoiplookup_city
2cp geoiplookup_continent /usr/bin/geoiplookup_continent
安装其他内部工具:
1install -m 755 ~/mirrorbrain-2.18.1/tools/geoip-lite-update /usr/bin/geoip-lite-update
2install -m 755 ~/mirrorbrain-2.18.1/tools/null-rsync /usr/bin/null-rsync
3install -m 755 ~/mirrorbrain-2.18.1/tools/scanner.pl /usr/bin/scanner
4install -m 755 ~/mirrorbrain-2.18.1/mirrorprobe/mirrorprobe.py /usr/bin/mirrorprobe
然后添加 mirrorprobe 的日志文件( mirrorprobe 检查镜子是否在线):
1mkdir /var/log/mirrorbrain
2touch /var/log/mirrorbrain/mirrorprobe.log
现在,我们可以安装 MirrorBrain 命令行管理工具:
1cd ~/mirrorbrain-2.18.1/mb
2python setup.py install
第三步:安装PostgreSQL
MirrorBrain 使用 PostgreSQL,易于在 Ubuntu 上设置。 首先,让我们安装 PostgreSQL:
1apt-get install postgresql postgresql-contrib
现在,让我们进入PostgreSQL admin shell:
1sudo -i -u postgres
让我们创建一个 MirrorBrain 数据库用户,为这个用户创建密码,并记下它,因为你以后会需要它:
1createuser -P mirrorbrain
然后,为 MirrorBrain 设置数据库:
1createdb -O mirrorbrain mirrorbrain
2createlang plpgsql mirrorbrain
如果您收到通知,该语言已经安装了,那就没问题了:
1createlang: language "plpgsql" is already installed in database "mirrorbrain"
我们需要从本地机器允许数据库的密码身份验证(由 MirrorBrain 要求)。
1nano /etc/postgresql/9.3/main/pg_hba.conf
然后找到 90 行(应该是第二行看起来像这样):
1# "local" is for Unix domain socket connections only
2 local all all peer
更新它以使用基于 md5 的密码身份验证:
1local all all md5
保存您的更改并重新启动 PostgreSQL:
1service postgresql restart
现在让我们放弃PostgreSQL壳(Ctrl-D)。
接下来,通过导入 MirrorBrain 的数据库方案来完成数据库设置:
1cd ~/mirrorbrain-2.18.1
2psql -U mirrorbrain -f sql/schema-postgresql.sql mirrorbrain
当被提示时,请输入我们之前为 ** mirrorbrain**数据库用户设置的密码。
输出应该是这样的:
1BEGIN
2CREATE TABLE
3CREATE TABLE
4CREATE TABLE
5CREATE VIEW
6CREATE TABLE
7CREATE INDEX
8CREATE TABLE
9CREATE TABLE
10CREATE TABLE
11CREATE FUNCTION
12CREATE FUNCTION
13CREATE FUNCTION
14CREATE FUNCTION
15CREATE FUNCTION
16CREATE FUNCTION
17CREATE FUNCTION
18CREATE FUNCTION
19CREATE FUNCTION
20COMMIT
添加初始数据:
1psql -U mirrorbrain -f sql/initialdata-postgresql.sql mirrorbrain
预期产量:
1INSERT 0 1
2INSERT 0 6
3INSERT 0 246
您现在已经安装了 MirrorBrain 并设置了一个数据库!
第四步:出版镜子
现在将一些文件添加到镜子中,我们建议将下载目录命名为您的域名,让我们创建一个目录来服务这些文件(仍然是根):
1mkdir /var/www/download.example.org
输入此目录:
1cd /var/www/download.example.org
现在我们需要添加一些文件. 如果您已经在您的服务器上有文件,您将希望将其 cp 或 mv 放入此文件夹:
1cp /var/www/example.org/downloads/* /var/www/download.example.org
如果它们位于不同的服务器上,您可以使用 scp (镜子目录服务器需要 SSH 访问到其他服务器):
1scp root@other.server.example.org:/var/www/example.org/downloads/* download.example.org
您也可以像任何其他文件一样上传新文件,例如使用 SSHFS或 SFTP。
为了测试,您可以添加三个样本文件:
1cd /var/www/download.example.org
2touch apples.txt bananas.txt carrots.txt
接下来,我们需要设置 rsync. rsync 是一个 UNIX 工具,允许我们在服务器之间同步文件。 我们将使用它来保持我们的镜子与镜子目录同步。 Rsync 可以通过 SSH 或公共 URL 操作。 我们将设置 rsync daemon (rsync:// URL) 选项。 首先,我们需要创建配置文件:
1nano /etc/rsyncd.conf
该路径应该是您的下载目录,评论可以是任何你想要的:
1[main]
2 path = /var/www/download.example.org
3 comment = My Mirror Director with Very Fast Download Speed!
4 read only = true
5 list = yes
保存文件. 启动 rsync daemon:
1rsync --daemon --config=/etc/rsyncd.conf
现在我们可以通过在 *NIX 系统上运行以下操作来测试这一点,您可以使用解决到您的服务器或服务器的 IP 地址的域名:
1rsync rsync://server.example.org/main
你应该看到你的文件列表。
步骤五:启用 MirrorBrain
现在我们已经准备好了我们的文件,我们可以启用 MirrorBrain. 首先,我们需要一个 MirrorBrain 用户和组:
1groupadd -r mirrorbrain
2useradd -r -g mirrorbrain -s /bin/bash -c "MirrorBrain user" -d /home/mirrorbrain mirrorbrain
现在,让我们创建 MirrorBrain 配置文件,允许 MirrorBrain 管理工具连接到数据库:
1nano /etc/mirrorbrain.conf
然后添加此配置. 这些设置中的大多数是为了设置数据库连接. 请确保为 dbpass 设置添加 mirrorbrain数据库用户密码:
1[general]
2instances = main
3
4[main]
5dbuser = mirrorbrain
6dbpass = password
7dbdriver = postgresql
8dbhost = 127.0.0.1
9dbname = mirrorbrain
10
11[mirrorprobe]
现在让我们为 MirrorBrain 设置我们的 Apache VirtualHost 文件:
1nano /etc/apache2/sites-available/download.example.org.conf
然后添加此 VirtualHost 配置. 您需要修改所有 download.example.org 使用的位置,以便您拥有自己的域名或 IP 地址,以解决您的服务器。 您还应该为 ServerAdmin 设置设置设置自己的电子邮件地址。 请确保您在 DBDParams 行中使用 mirrorbrain 数据库用户密码:
1<VirtualHost *:80>
2 ServerName download.example.org
3 ServerAdmin webmaster@example.org
4 DocumentRoot /var/www/download.example.org
5
6 ErrorLog /var/log/apache2/download.example.org/error.log
7 CustomLog /var/log/apache2/download.example.org/access.log combined
8
9 DBDriver pgsql
10 DBDParams "host=localhost user=mirrorbrain password=database password dbname=mirrorbrain connect_timeout=15"
11
12 <Directory /var/www/download.example.org>
13 MirrorBrainEngine On
14 MirrorBrainDebug Off
15 FormGET On
16
17 MirrorBrainHandleHEADRequestLocally Off
18 MirrorBrainMinSize 2048
19 MirrorBrainExcludeMimeType application/pgp-keys
20
21 Options FollowSymLinks Indexes
22 AllowOverride None
23 Order allow,deny
24 Allow from all
25 </Directory>
26</VirtualHost>
值得看看在目录标签下可用的 MirrorBrain 选项:
......................................................................................................................................................................................................
可在 MirrorBrain 网站上找到完整的配置选项列表(http://svn.mirrorbrain.org/viewvc/mirrorbrain/trunk/mod_mirrorbrain/mod_mirrorbrain.conf?view=markup)。
如果您想了解有关基本的 Apache VirtualHost 设置的更多信息,请查看 本教程。
** 保存和退出文件。
确保您的日志目录存在:
1mkdir /var/log/apache2/download.example.org/
在启用网站目录中链接到配置文件:
1ln -s /etc/apache2/sites-available/download.example.org.conf /etc/apache2/sites-enabled/download.example.org.conf
重新启动Apache:
1service apache2 restart
恭喜,你现在有 MirrorBrain 并运行!
要测试 MirrorBrain 是否正在工作,请先在 Web 浏览器中访问您的下载网站以查看文件索引,然后点击其中一个文件以查看它。 将 ".mirrorlist" 附加到 URL 末尾。 (示例 URL: http://download.example.org/apples.txt.mirrorlist) 如果一切都在工作,您应该看到这样的页面:
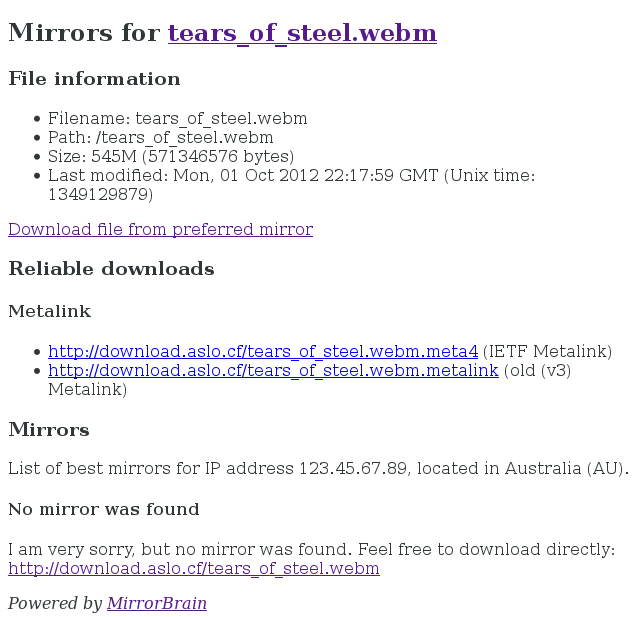
Cron 工作配置
在我们开始添加镜子之前,我们仍然需要设置一些镜子扫描和维护 cron 工作,首先,让我们设置 MirrorBrain 来检查哪些镜子在网上(使用 mirrorprobe 命令)每分钟:
1echo "* * * * * mirrorbrain mirrorprobe" | crontab
还有一个Cron任务,每小时扫描镜子的内容(查找文件的可用性和正确性):
1echo "0 * * * * mirrorbrain mb scan --quiet --jobs 4 --all" | crontab
如果你有非常快速的内容变化,它将是明智的添加更多的扫描频繁,例如,0.30 * * * *每半小时. 如果你有一个非常强大的服务器,你可以增加--工作的数量来扫描更多的镜子在同一时间。
清理周一上午1点30分的数据库:
1echo "30 1 * * mon mirrorbrain mb db vacuum" | crontab
周一上午2点30分左右更新 GeoIP 数据(梦想是减少 GeoIP 服务器上不必要的负载峰值):
1echo "31 2 * * mon root sleep $(($RANDOM/1024)); /usr/bin/geoip-lite-update" | crontab
步骤六:在另一个服务器上反射内容
现在我们已经设置了镜子目录,让我们创建我们的第一个镜子. 您可以遵循此部分为您想要添加的每一个镜子。
对于本节,请使用不同的 Ubuntu 14.04 服务器,最好是在不同的区域。
一旦登录(作为 root 或使用 sudo -i),创建一个镜子内容目录:
1mkdir -p /var/www/download.example.org
然后使用我们之前设置的 rsync URL 将内容复制到该目录:
1rsync -avzh rsync://download.example.org/main /var/www/download.example.org
如果您在使用 rsync 时遇到空间问题(IO 错误),有办法解决这个问题。您可以添加 --exclude 选项来排除对访问者不那么重要的目录。 MirrorBrain 会扫描您的服务器,而不会将用户发送到排除的文件中,而是将其发送到最接近的服务器上,其中有该文件。
1rsync -avzh rsync://download.example.org/main /var/www/download.example.org --exclude "movies/old" --exclude "songs/old"
然后,我们可以将您的镜像服务器设置为每小时自动同步主服务器,使用Cron(请记住,如果您使用过任何选项,请包括排除选项):
1echo '0 * * * * root rsync -avzh rsync://download.example.org/main /var/www/download.example.org' | crontab
现在我们需要在 HTTP (对于用户) 和 rsync (对于 MirrorBrain 扫描) 上发布我们的镜子。
阿帕奇
如果你已经在你的服务器上有一个HTTP服务器,你应该添加一个VirtualHost(或同等的),以服务到‘/var/www/download.example.org’目录。
1apt-get install apache2
然后,让我们添加一个 VirtualHost 文件:
1nano /etc/apache2/sites-available/london1.download.example.org.conf
添加以下内容. 确保您为 ServerName、 ServerAdmin 和 DocumentRoot 指令设置自己的值:
1<VirtualHost *:80>
2 ServerName london1.download.example.org
3 ServerAdmin webmaster@example.org
4 DocumentRoot /var/www/download.example.org
5</VirtualHost>
保存文件. 启用新的 VirtualHost:
1ln -s /etc/apache2/sites-available/london1.download.example.org.conf /etc/apache2/sites-enabled/london1.download.example.org.conf
重新启动Apache:
1service apache2 restart
rsync 的
接下来,我们需要设置 rsync daemon(用于 MirrorBrain 扫描)。
1nano /etc/rsyncd.conf
然后添加配置,确保 path 匹配您的下载目录。
1[main]
2 path = /var/www/download.example.org
3 comment = My Mirror Of Some Cool Files
4 read only = true
5 list = yes
保存此檔案
启动 rsync daemon:
1rsync --daemon --config=/etc/rsyncd.conf
在导演上打开镜子
现在,在 MirrorBrain 服务器上,我们需要添加镜子,我们可以使用 mb 命令(作为根)。
1mb new london1.download.example.org
2 -H http://london1.download.example.org
3 -R rsync://london1.download.example.org/main
4 --operator-name=Example --operator-url=example.org
5 -a "Pat Admin" -e pat@example.org
它不需要解决
- -H 应该解决到您的服务器;你可以使用域或 IP 地址
- -R 应该解决到您的服务器;你可以使用域或 IP 地址
- 您想要发布的 的设置应该是您的首选管理员联系信息。
然后,让我们扫描并启用镜子,您需要在新命令中使用相同的号:
1mb scan --enable london1.download.example.org
注意: 如果您在 @INC 中遇到无法找到 LWP/UserAgent.pm 等错误,您应该返回 ** 步骤两 ** 部分,然后再次运行 `perl -MCPAN -e 'install Bundle::LWP'。
假设扫描成功(MirrorBrain 可以连接到服务器),镜子将被添加到数据库中。
测试
现在尝试到目录服务器上的 MirrorBrain 实例(例如, download.example.org - 不是 london1.download.example.org)。
您可以用您自己的服务器在世界其他地方添加更多的镜子,或者您可以使用 mb new 添加其他人为您运行的镜子。
禁用和重新启用镜子
如果你想禁用镜子,这就像运行一样简单:
1mb disable london1.download.example.org
重启镜子使用mb scan – enable london1.download.example.org命令,如上所使用。