作者选择了 计算机历史博物馆作为 写给捐赠计划的一部分获得捐赠。
介绍
Twitter机器人是管理社交媒体以及从微博网络中提取信息的强大方法。通过利用Twitter的多功能API,机器人可以做很多事情:推特、重复推特、最喜欢的推特,跟随某些兴趣的人,自动回复等。尽管人们可以,而且可以,滥用他们的机器人的力量,导致其他用户的负面体验,研究表明人们将Twitter机器人视为一个可靠的信息来源。例如,机器人可以让你的追随者参与内容,即使你不在网上。一些机器人甚至提供关键和有用的信息,如@EarthquakesSF(https://twitter.com/earthquakesSF?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor)。
在本教程中,您将使用 Python 的 Twitter API 库(https://github.com/sixohsix/twitter)构建一个 Twitter 机器人,您将使用您的 Twitter 帐户的 API 密钥来授权您的机器人,并构建一个能够从两个网站中扫描内容的机器人。
前提条件
您将需要以下内容来完成本教程:
- 一个本地的 Python 3 编程环境设置如下 如何安装和设置Python 的本地编程环境 3。
- 安装您所选择的文本编辑器,如 Visual Studio Code, Atom,或 Sublime Text。
<$>[注] **注:**您将与Twitter建立开发者帐户,这涉及Twitter对应用程序进行审查,然后您就可以访问这个机器人所需的API密钥。
步骤 1 – 设置您的开发者帐户并访问您的 Twitter API 密钥
在您开始编码机器人之前,您需要 Twitter 的 API 密钥来识别您的机器人的请求. 在此步骤中,您将设置您的 Twitter 开发人员帐户并访问您的 Twitter 机器人的 API 密钥。
要获取 API 密钥,请转到 developer.twitter.com并通过点击页面右上角的 Apply来注册您的bot 应用程序。
现在单击 ** 申请开发人员帐户**。
接下来,点击 继续 将您的 Twitter 用户名与您将在本教程中构建的机器人应用程序相关联。
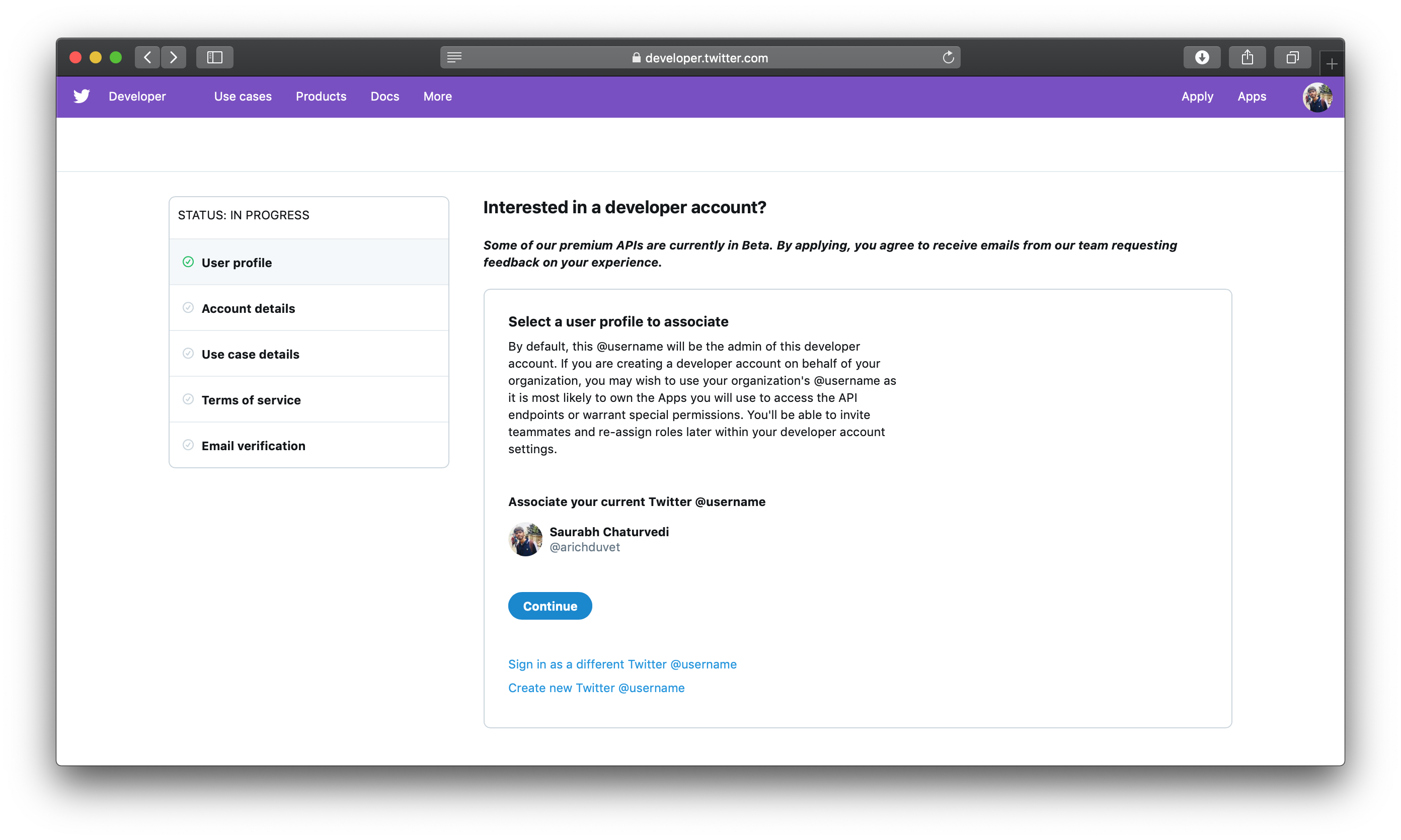
在下一页上,为本教程的目的,您将选择 我正在要求访问我的个人用途的选项,因为您将为自己的个人教育用途构建一个机器人。
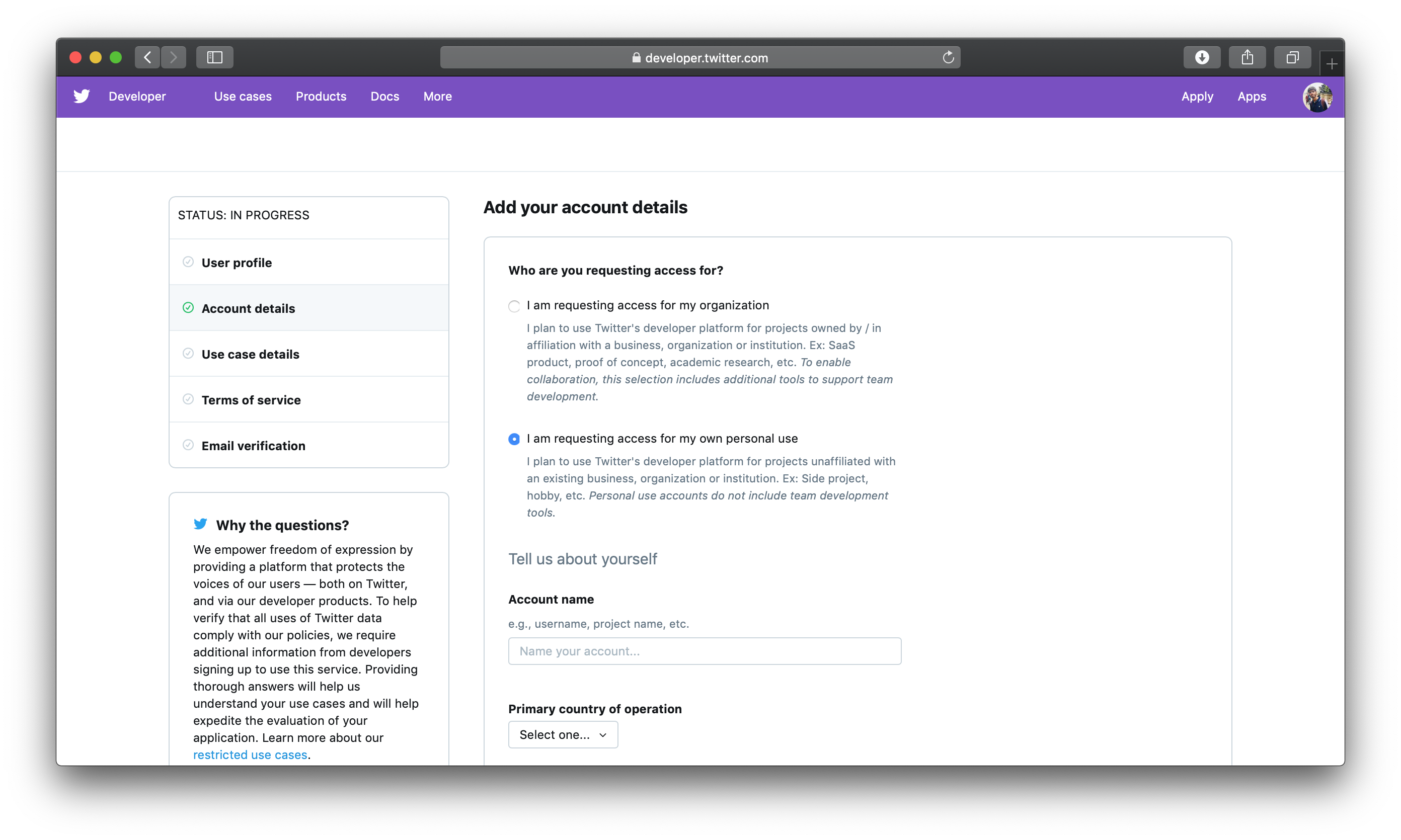
选择您的 帐户名称和 国家后,继续进入下一部分。 对于 你感兴趣的使用案例(s)?,选择 发布和策划推文和 学生项目 / 学习编码选项。
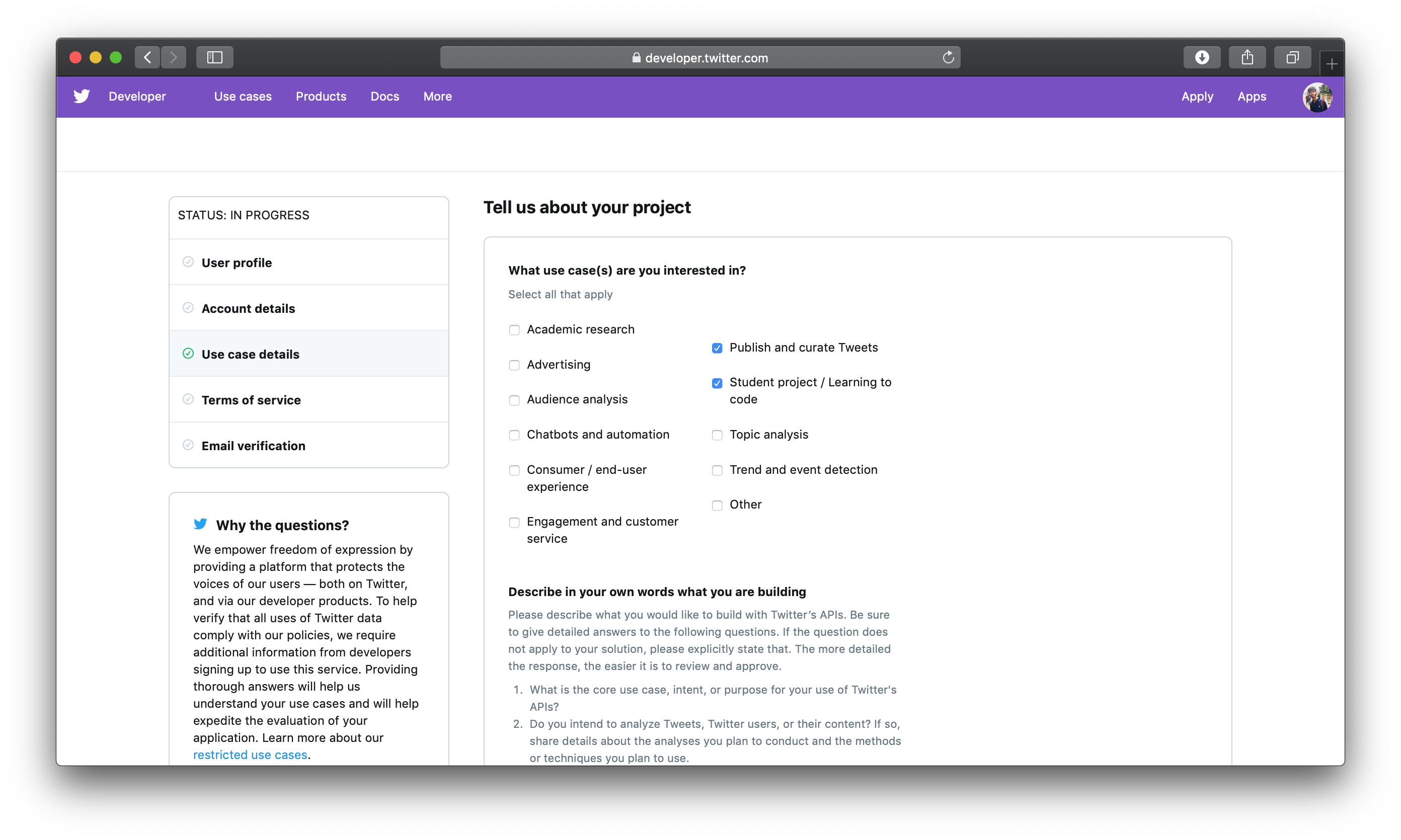
然后提供你试图构建的机器人的描述。Twitter要求这样做来防止机器人滥用;在2018年,他们引入了这种检查。
当决定在 description框中输入什么时,请为本教程的目的,用下列行来模拟你的答案:
我正在遵循一项教程来构建一个Twitter机器人,该机器人将从thenewstack.io(The New Stack)和blog.coursera.org(Coursera的博客)等网站中摘取内容,并从中推文引用。
最后,选择 不 选择 ** 您的产品、服务或分析是否会向政府实体提供 Twitter 内容或衍生信息?**
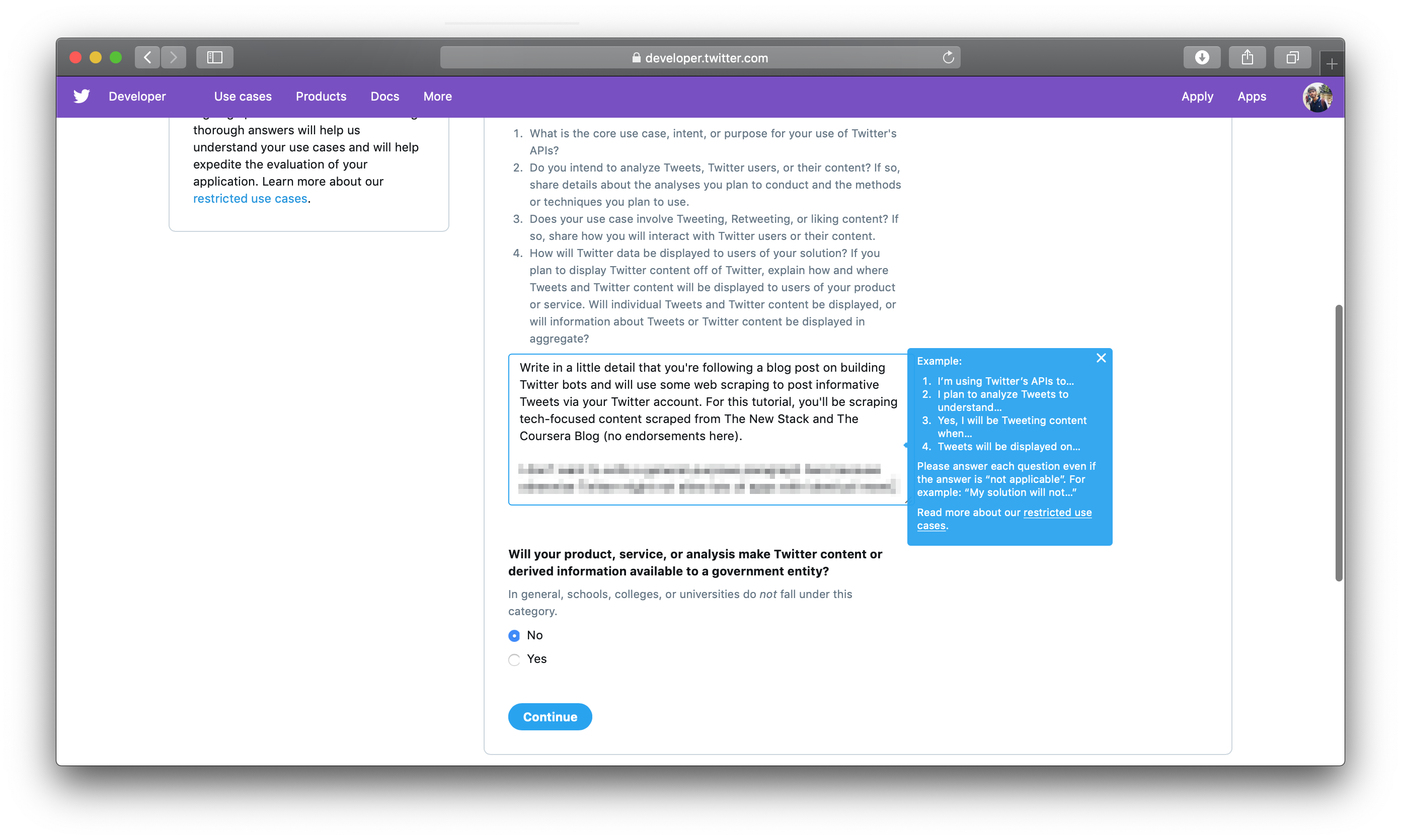
接下来,接受Twitter的条款和条件,点击提交申请,然后验证您的电子邮件地址。
一旦您验证您的电子邮件,您将收到一个 ** 审查中的应用程序 ** 页面,并为申请流程提供反馈表格。
您还将收到有关评论的另一封电子邮件:
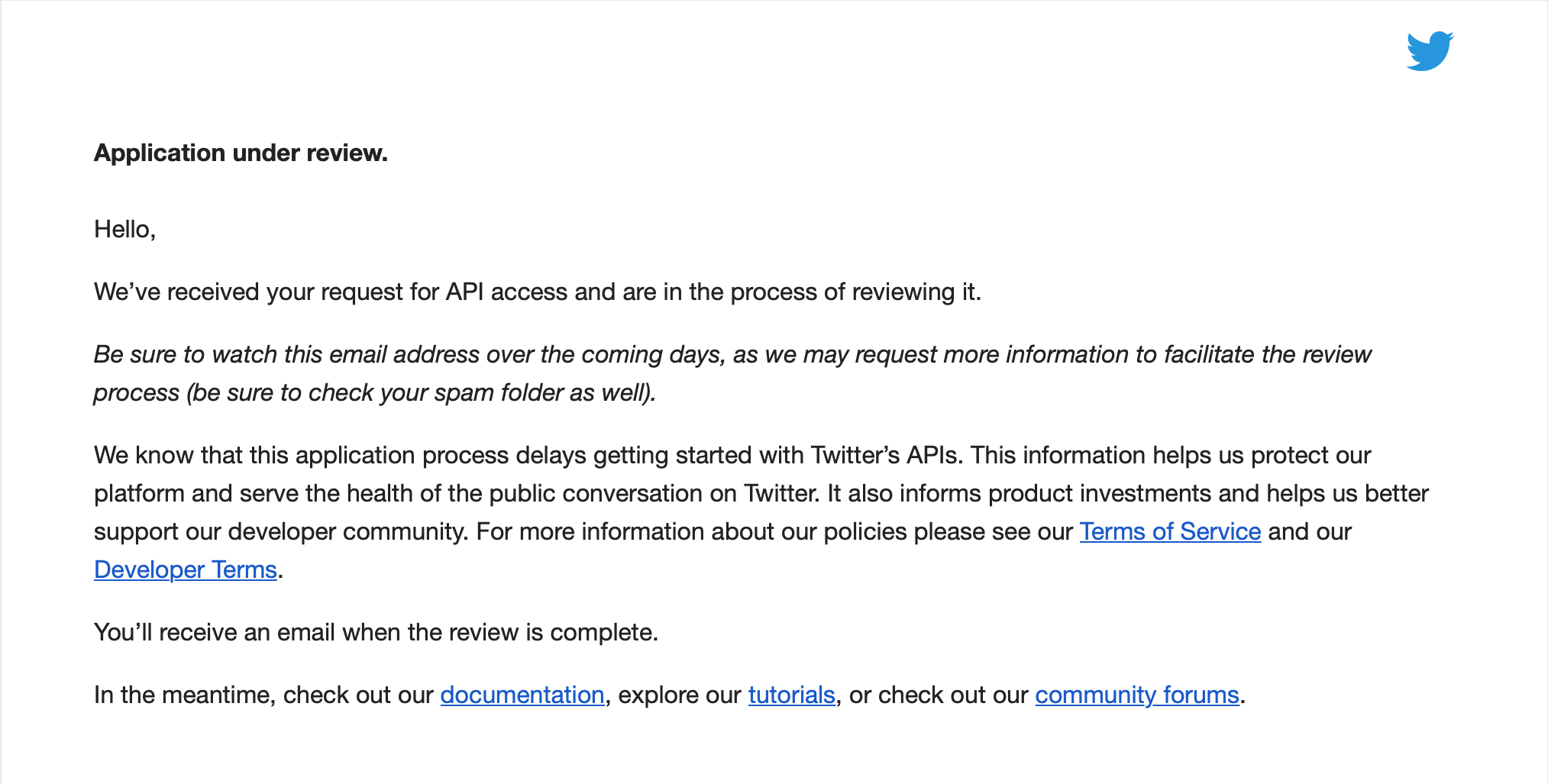
Twitter 的应用程序审查过程的时间表可能会有所不同,但 Twitter 通常会在几分钟内确认这一点,但是,如果您的应用程序的审查时间比此更长,这并不罕见,您应该在一天或两天内收到它。
最后,点击您的应用程序页面上的允许选项卡,并将访问权限选项设置为阅读和写选项,因为您也想写推文内容。
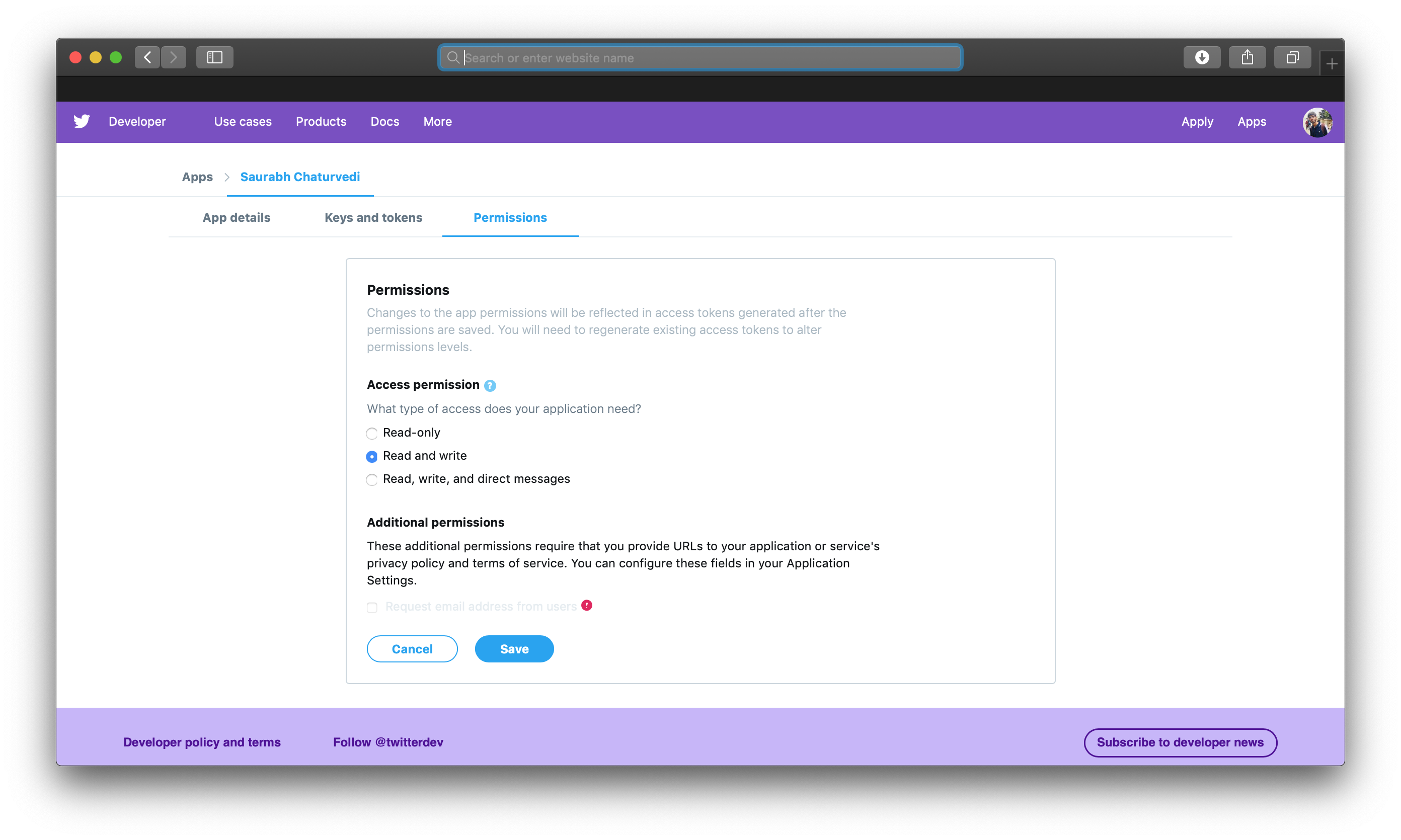
你可以访问Twitter的强大的API,这将是你的机器人应用程序的关键部分,现在你将设置你的环境,并开始建立你的机器人。
步骤2 - 构建基本
在此步骤中,您将编写代码以使用 API 密钥验证您的 Twitter 机器人,并通过您的 Twitter 操作创建第一个编程推文。
首先,您将为您的项目设置一个项目文件夹和特定的编程环境。
创建您的项目文件夹:
1mkdir bird
进入您的项目文件夹:
1cd bird
然后为您的项目创建一个新的Python虚拟环境:
1python3 -m venv bird-env
然后使用以下命令激活您的环境:
1source bird-env/bin/activate
这将添加一个(bird-env)前缀到您的终端窗口中的提示。
现在转到文本编辑器,创建一个名为credentials.py的文件,该文件将存储您的 Twitter API 密钥:
1nano credentials.py
添加以下内容,以您的 Twitter 密钥代替突出代码:
1[label bird/credentials.py]
2
3ACCESS_TOKEN='your-access-token'
4ACCESS_SECRET='your-access-secret'
5CONSUMER_KEY='your-consumer-key'
6CONSUMER_SECRET='your-consumer-secret'
现在,您将安装向 Twitter 发送请求的主要 API 库. 对于此项目,您将需要以下库:nltk、requests、twitter、lxml、random 和 time. 随机和 time 是 Python 标准库的一部分,因此您不需要单独安装这些库。
打开终端,确保您在项目文件夹中,然后运行以下命令:
1pip3 install lxml nltk requests twitter
lxml和requests:您将使用它们用于网页扫描twitter:这是向Twitter的服务器进行API调用的库nltk: (自然语言工具包)您将使用它们来将博客的段落分成句子随机:您将使用此工具随机选择整个被扫描的博客帖子的部分时间:您将在某些行动之后定期使用它来使您的机器人睡眠
一旦您安装了库,您将开始编程,现在,您将导入您的身份证件到主脚本中,该脚本将运行机器人. 与credentials.py一起,从您的文本编辑器创建一个文件在鸟项目目录中,并命名它为bot.py:
1nano bot.py
在实践中,你会将你的机器人的功能扩展到多个文件中,因为它变得越来越复杂,然而,在本教程中,你将把所有的代码放在一个单一的脚本中,bot.py,用于演示目的。
首先,您将通过授权您的机器人来测试您的 API 密钥. 首先,您可以将下列短片添加到bot.py:
1[label bird/bot.py]
2import random
3import time
4
5from lxml.html import fromstring
6import nltk
7nltk.download('punkt')
8import requests
9from twitter import OAuth, Twitter
10
11import credentials
在这里,你将导入所需的库;在某些情况下,你将从库中导入所需的 函数。你将使用fromstring函数后在代码中转换一个被扫描的网页的字符串源为一个树结构,这使得从页面中提取相关信息更容易。
现在将bot.py扩展到以下行:
1[label bird/bot.py]
2...
3tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
4
5oauth = OAuth(
6 credentials.ACCESS_TOKEN,
7 credentials.ACCESS_SECRET,
8 credentials.CONSUMER_KEY,
9 credentials.CONSUMER_SECRET
10 )
11t = Twitter(auth=oauth)
「nltk.download('punkt')」下载了一组用于解析段落并将其分解为较小的组件所必需的数据集。
oauth是通过将导入的OAuth类送入您的API密钥来构建的身份验证对象。您通过线条t = Twitter(auth=oauth)来验证您的机器人。ACCESS_TOKEN和ACCESS_SECRET帮助识别您的应用程序。最后,CONSUMER_KEY和CONSUMER_SECRET帮助识别该应用程序与Twitter互动的触摸器。
现在保存此文件并使用以下命令在终端中运行它:
1python3 bot.py
您的输出将看起来类似于以下,这意味着您的授权成功:
1[secondary_label Output]
2[nltk_data] Downloading package punkt to /Users/binaryboy/nltk_data...
3[nltk_data] Package punkt is already up-to-date!
如果您收到错误,请用 Twitter 开发人员帐户中的 API 密钥验证已保存的 API 密钥,然后再试一次,并确保所需的库安装正确。
现在你可以尝试编程地推特一些东西。在终端上用-i旗键入相同的命令,在执行脚本后打开Python解释器:
1python3 -i bot.py
接下来,输入以下内容以通过您的帐户发送推文:
1t.statuses.update(status="Just setting up my Twttr bot")
现在,在浏览器中打开你的Twitter时间线,你会看到你的时间线顶部的推文,其中包含你发布的内容。
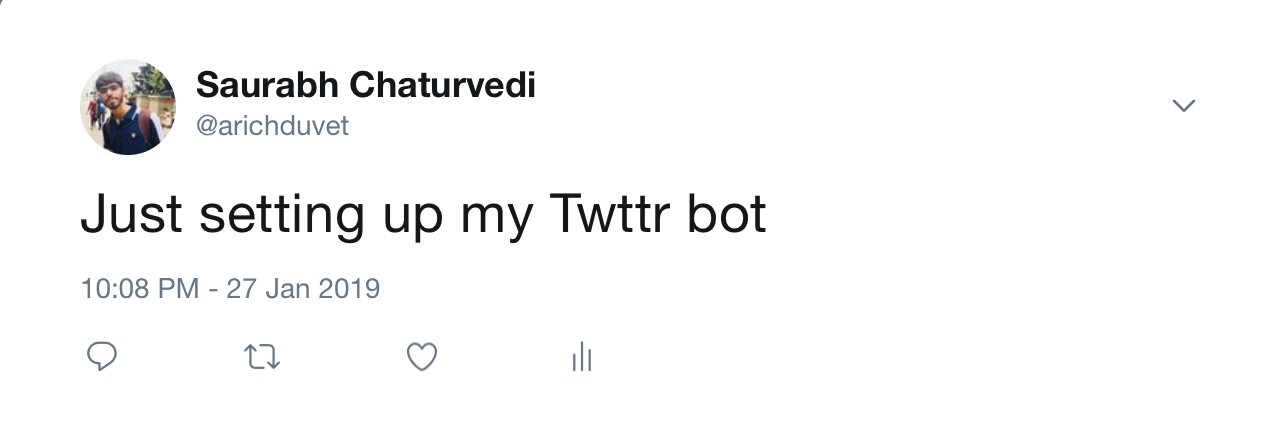
通过键入quit()或CTRL + D来关闭解释器。
你的机器人现在有基本的能力来推文. 为了开发你的机器人推文有用的内容,你将在下一步中纳入Web扫描。
步骤3 - 扫描您的推文内容的网站
要将一些更有趣的内容引入到你的时间线,你会从 新堆栈和 Coursera博客中摘取内容,然后以推文的形式将此内容发布到Twitter。一般来说,要从目标网站中摘取适当的数据,你必须用其HTML结构进行实验。你将在本教程中构建的每个推文都会有一个链接到所选网站的博客文章,以及来自该博客的随机引用。
首先打开bot.py:
1nano bot.py
将scrape_coursera()函数添加到文件的末尾:
1[label bird/bot.py]
2...
3t = Twitter(auth=oauth)
4
5def scrape_coursera():
要从博客中提取信息,你首先会从Coursera的服务器上请求相关的网页。 为此,你会从请求库中使用get()函数。get()会输入一个URL并收集相应的网页。因此,你会将blog.coursera.org作为一个论点传递给get()。但你还需要在你的GET请求中提供一个标题,这将确保Coursera的服务器将你识别为真正的客户端。
1[label bird/bot.py]
2def scrape_coursera():
3 HEADERS = {
4 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
5 ' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
6 }
只要此信息(通常称为用户代理)与真实的网页浏览器和操作系统相匹配,无论标题信息是否与您的计算机上的实际网页浏览器和操作系统相匹配,因此,此标题将适用于所有系统。
一旦您定义了标题,请通过指定博客网页的 URL 来向 Coursera 提交 GET 请求,添加以下突出的行:
1[label bird/bot.py]
2...
3def scrape_coursera():
4 HEADERS = {
5 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
6 ' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
7 }
8 r = requests.get('https://blog.coursera.org', headers=HEADERS)
9 tree = fromstring(r.content)
这将将网页带到您的计算机,并将整个网页的信息保存到变量r中,您可以使用r的内容属性来评估网页的HTML源代码,因此,r.content的值与您在浏览器中检查网页时看到的值相同,通过右键单击网页并选择 Inspect Element选项。
在这里,您还添加了fromstring函数,您可以将网页的源代码传输到从lxml库导入的fromstring函数,以构建网页的树结构,此 tree 结构将允许您方便地访问网页的不同部分。
现在,在浏览器中打开https://blog.coursera.org并使用浏览器的开发工具检查其HTML源. 右键单击页面,选择Inspect Element**选项。 您将看到一个窗口显示在浏览器的底部,显示页面的HTML源代码的一部分。
接下来,右键单击任何可见的博客帖子的小图形,然后检查它. HTML 源将突出定义该博客小图形的相关 HTML 行。
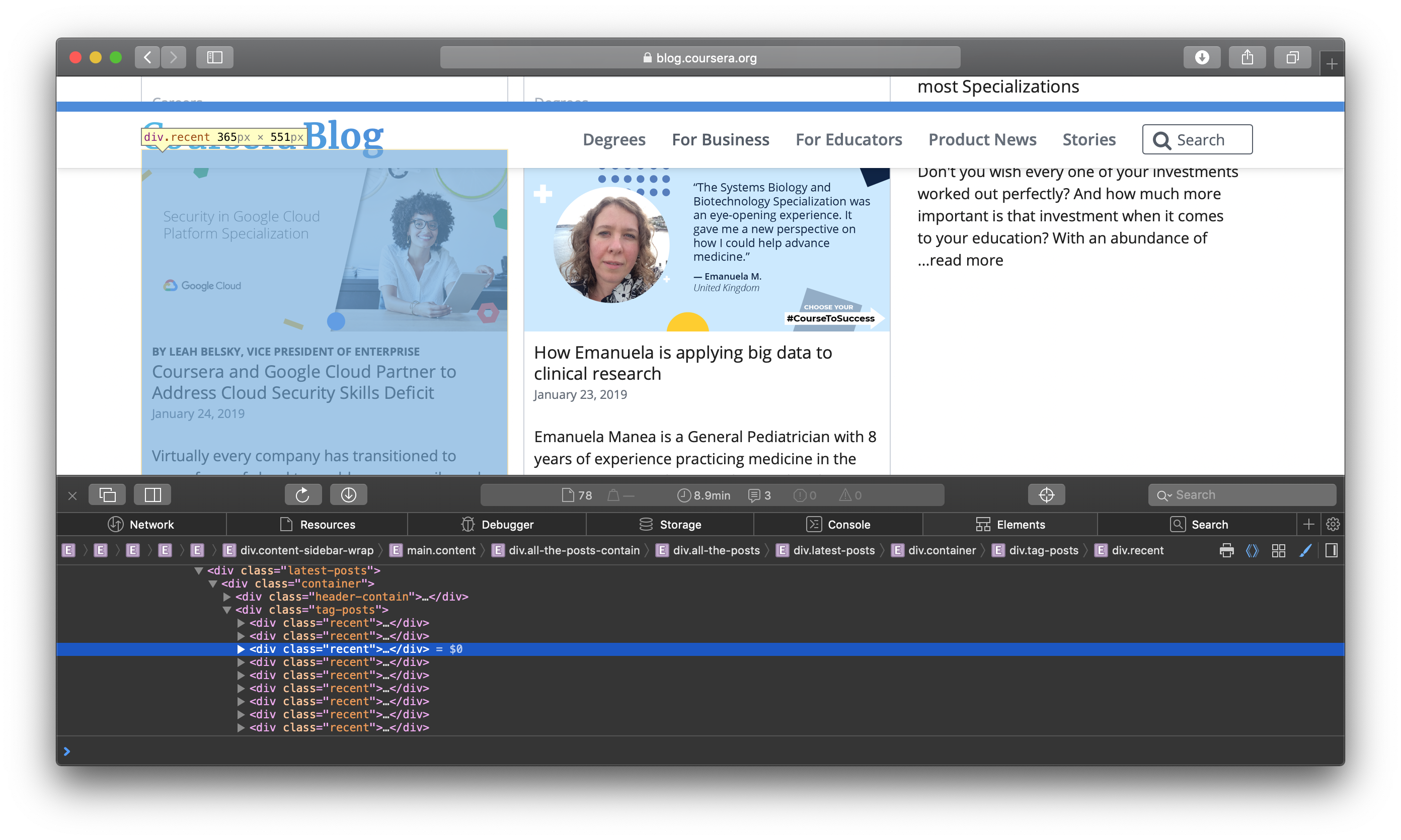
因此,在您的代码中,您将通过其 XPath使用所有此类博客帖子div元素,这是解决网页元素的方便方式。
要做到这一点,请在bot.py中如下扩展您的功能:
1[label bird/bot.py]
2...
3def scrape_coursera():
4 HEADERS = {
5 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
6 ' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
7 }
8 r = requests.get('https://blog.coursera.org', headers=HEADERS)
9 tree = fromstring(r.content)
10 links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
11 print(links)
12
13scrape_coursera()
在这里, XPath(将字符串转移到「tree.xpath()」)表示您想要从整个网页源中提取「div」元素,从 class「最近」中提取「div」。
然而,你不需要这些元素本身,你只需要他们指向的链接,这样你就可以访问个别博客帖子来摘取其内容。
要测试到目前为止的程序,请在bot.py的末尾调用scrape_coursera()函数。
保存和退出bot.py。
现在,用以下命令运行bot.py:
1python3 bot.py
在输出中,你会看到一个 list的URL如下:
1[secondary_label Output]
2['https://blog.coursera.org/career-stories-from-inside-coursera/', 'https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/', ...]
验证输出后,您可以从bot.py脚本中删除最后两行:
1[label bird/bot.py]
2...
3def scrape_coursera():
4 ...
5 tree = fromstring(r.content)
6 links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
7 ~~print(links)~~
8
9~~scrape_coursera()~~
现在,用下面的突出线来扩展bot.py中的功能,从博客帖子中提取内容:
1[label bird/bot.py]
2...
3def scrape_coursera():
4 ...
5 links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
6 for link in links:
7 r = requests.get(link, headers=HEADERS)
8 blog_tree = fromstring(r.content)
你重复每个链接,提取相应的博客帖子,从帖子中提取随机句子,然后推特这个句子作为引用,以及相应的URL。
抓住博客帖子中的所有段落作为列表 2.从段落列表中随机选择一个段落 3.从这个段落中随机选择一个句子
您将为每个博客帖子执行这些步骤. 为了收集一个,您会为其链接提出 GET 请求。
现在您可以访问博客的内容,您将引入执行这三个步骤的代码,从中提取您想要的内容。
1[label bird/bot.py]
2...
3def scrape_coursera():
4 ...
5 for link in links:
6 r = requests.get(link, headers=HEADERS)
7 blog_tree = fromstring(r.content)
8 paras = blog_tree.xpath('//div[@class="entry-content"]/p')
9 paras_text = [para.text_content() for para in paras if para.text_content()]
10 para = random.choice(paras_text)
11 para_tokenized = tokenizer.tokenize(para)
12 for _ in range(10):
13 text = random.choice(para_tokenized)
14 if text and 60 < len(text) < 210:
15 break
如果你通过打开第一个链接检查博客帖子,你会注意到所有段落都属于div标签,其类型是entry-content。
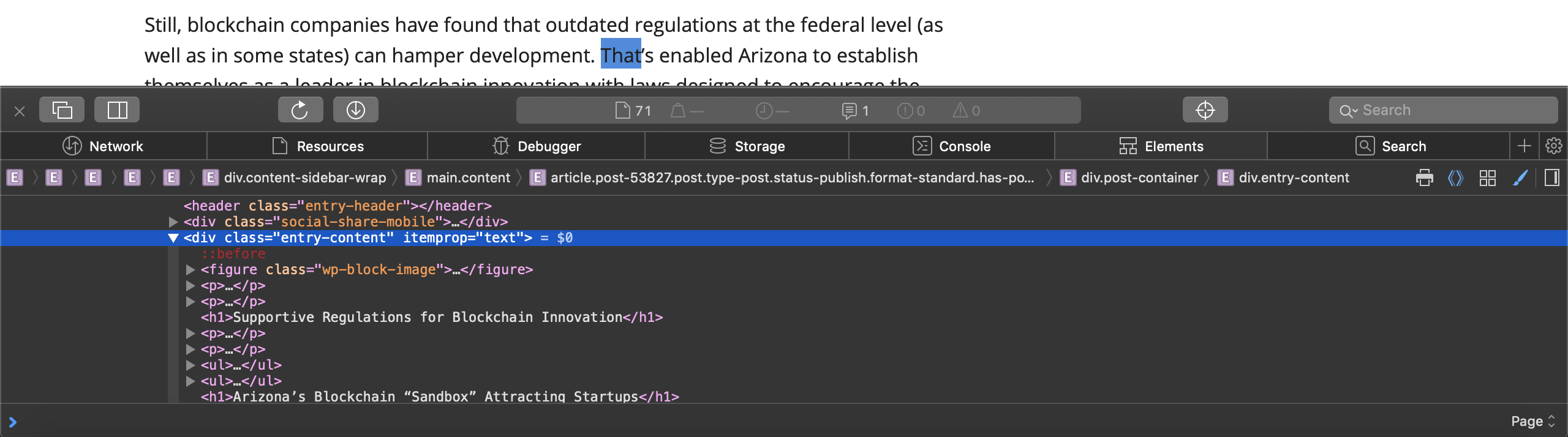
列表元素不是 literal 段落;它们是 Element objects. 要从这些 objects 中提取文本,您使用 text_content() 方法. 此行遵循 Python 的 list comprehension 设计模式,该模式使用一个循环来定义一个集合,通常在单行中写出来。 在 bot.py 中,您提取每个段落元素的文本 object 并将其存储在 list 中,如果文本不是空的。
最后,你必须从这个段落中随机选择一个句子,该句子存储在变量par中。 对于这个任务,你首先将段落分成句子。 实现这一目标的一种方法是使用Python的split()方法。 然而,这可能很困难,因为一个句子可以分成多个分割点。 因此,为了简化你的分割任务,你通过nltk图书馆利用自然语言处理。 在教程中早些时候定义的tokenizer对象对于这个目的很有用。
现在你有一个句子列表,你打电话给‘random.choice()’来提取一个随机句子。你想要这个句子成为一个推文的引用句子,所以它不能超过280个字符。然而,出于美学原因,你会选择一个句子,既不太大也不太小。你指定你的推文句子应该长度在60到210个字符之间。句子‘random.choice()’选择可能不符合这个标准。 为了确定正确的句子,你的脚本会做十次尝试,每次检查标准。 一旦随机采集的句子满足你的标准,你可以走出循环。
虽然概率很低,但可能没有一个句子在十次尝试内满足这个尺寸条件,在这种情况下,你会忽略相应的博客帖子并转到下一个。
现在你有一个句子要引用,你可以用相应的链接推特它. 你可以这样做,通过输出包含随机采集的句子以及相应的博客链接的字符串。
扩展您的功能如下:
1[label bird/bot.py]
2...
3def scrape_coursera():
4 ...
5 for link in links:
6 ...
7 para_tokenized = tokenizer.tokenize(para)
8 for _ in range(10):
9 text = random.choice(para)
10 if text and 60 < len(text) < 210:
11 break
12 else:
13 yield None
14 yield '"%s" %s' % (text, link)
因此,它只发生在循环无法找到适合您的尺寸条件的句子时。在这种情况下,您只是输出None,以便呼叫此函数的代码能够确定没有什么可推特的。它将继续呼叫该函数并获得下一个博客链接的内容。但是如果循环破解,则意味着该函数找到了合适的句子;该脚本不会执行else的句子,并且该函数将产生由该句子以及博客链接组成的字符串,分开一个单一的 whitespace。
如果你想做一个类似的功能来扫描另一个网站,你将不得不重复一些你写的代码来扫描Coursera的博客. 为了避免重写和重复代码的部分,并确保你的机器人脚本遵循DRY的原则(不要重复自己),你将识别和抽象出代码的部分,你会再次使用任何后面写的扫描函数。
无论该网站的功能是扫描的,您将不得不随机采集一个段落,然后从选择的段落中选择一个随机句子 - 您可以将这些功能提取到单独的函数中。然后,您可以从您的扫描函数中简单地调用这些函数,并获得所需的结果。您也可以在scrape_coursera()函数之外定义HEADERS,以便所有扫描函数都能使用它。因此,在以下代码中,HEADERS定义应该先于扫描函数,以便您最终能够将其用于其他扫描函数:
1[label bird/bot.py]
2...
3HEADERS = {
4 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
5 ' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
6 }
7
8def scrape_coursera():
9 r = requests.get('https://blog.coursera.org', headers=HEADERS)
10 ...
现在,您可以定义extract_paratext()函数来从段落对象列表中提取随机段落. 随机段落将作为一个paras参数传入该函数,并返回所选段落的代币化形式,您将在以后用于句子提取:
1[label bird/bot.py]
2...
3HEADERS = {
4 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
5 ' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
6 }
7
8def extract_paratext(paras):
9 """Extracts text from <p> elements and returns a clean, tokenized random
10 paragraph."""
11
12 paras = [para.text_content() for para in paras if para.text_content()]
13 para = random.choice(paras)
14 return tokenizer.tokenize(para)
15
16def scrape_coursera():
17 r = requests.get('https://blog.coursera.org', headers=HEADERS)
18 ...
接下来,您将定义一个函数,该函数将从其获得的代码段落中提取一个合适长度的随机句子(60 到 210 个字符)作为一个参数,您可以将其命名为par。如果在十次尝试后没有发现这样的句子,该函数将返回None。
1[label bird/bot.py]
2...
3
4def extract_paratext(paras):
5 ...
6 return tokenizer.tokenize(para)
7
8def extract_text(para):
9 """Returns a sufficiently-large random text from a tokenized paragraph,
10 if such text exists. Otherwise, returns None."""
11
12 for _ in range(10):
13 text = random.choice(para)
14 if text and 60 < len(text) < 210:
15 return text
16
17 return None
18
19def scrape_coursera():
20 r = requests.get('https://blog.coursera.org', headers=HEADERS)
21 ...
一旦定义了这些新的辅助函数,您可以重新定义 scrape_coursera() 函数以如下方式:
1[label bird/bot.py]
2...
3def extract_paratext():
4 for _ in range(10):
5 text = random.choice(para)
6 ...
7
8def scrape_coursera():
9 """Scrapes content from the Coursera blog."""
10
11 url = 'https://blog.coursera.org'
12 r = requests.get(url, headers=HEADERS)
13 tree = fromstring(r.content)
14 links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
15
16 for link in links:
17 r = requests.get(link, headers=HEADERS)
18 blog_tree = fromstring(r.content)
19 paras = blog_tree.xpath('//div[@class="entry-content"]/p')
20 para = extract_paratext(paras)
21 text = extract_text(para)
22 if not text:
23 continue
24
25 yield '"%s" %s' % (text, link)
保存和退出bot.py。
在这里,你使用yield而不是return,因为,在重复链接时,扫描函数将以连续的方式给你的推文字符串一个接一个。这意味着,当你首次拨打被定义为sc = scrape_coursera()的扫描器时,你会得到在扫描函数内计算的链接列表中的第一个链接的推文字符串。 如果你在翻译器中运行下面的代码,你会得到如下所示的string_1和string_2,如果在scrape_coursera()内的链接变量包含一个看起来像https://thenewstack.io/cloud-native-live-twistlocks-virtual-conference,`https://blog.coursera.
1python3 -i bot.py
即时化扫描器,并称之为sc:
1>>> sc = scrape_coursera()
它现在是一个生成器;它从Coursera生成或一次性地扫描相关内容,您可以通过连续调用next()到sc来访问被扫描的内容:
1>>> string_1 = next(sc)
2>>> string_2 = next(sc)
现在,您可以打印您定义的字符串来显示被扫描的内容:
1>>> print(string_1)
2"Other speakers include Priyanka Sharma, director of cloud native alliances at GitLab and Dan Kohn, executive director of the Cloud Native Computing Foundation." https://thenewstack.io/cloud-native-live-twistlocks-virtual-conference/
3>>>
4>>> print(string_2)
5"You can learn how to use the power of Python for data analysis with a series of courses covering fundamental theory and project-based learning." https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/
6>>>
如果你使用返回代替,你将无法获得字符串一个接一个,并在一个序列中。如果你只是用返回代替scrape_coursera(),你将总是得到与第一个博客帖子相符的字符串,而不是在第一个呼叫中得到第一个字符串,第二个字符串在第二次呼叫中,等等。你可以修改功能,以便简单地返回所有链接相应的字符串的 list,但这更具有内存密集性。此外,这种类型的程序可能会在短时间内向Coursera的服务器提出大量请求,如果你想要整个 list 快速。这可能会导致你的机器人暂时被禁止访问网站。因此,yield 是最适合广泛的扫描工作,你只需要一次性扫描信息。
步骤 4 – 删除额外的内容
在此步骤中,您将为 thenewstack.io构建一个扫描器。
在您的浏览器中打开网站并检查页面来源. 在这里,您会发现所有的博客部分都是类normalstory-box的div元素。
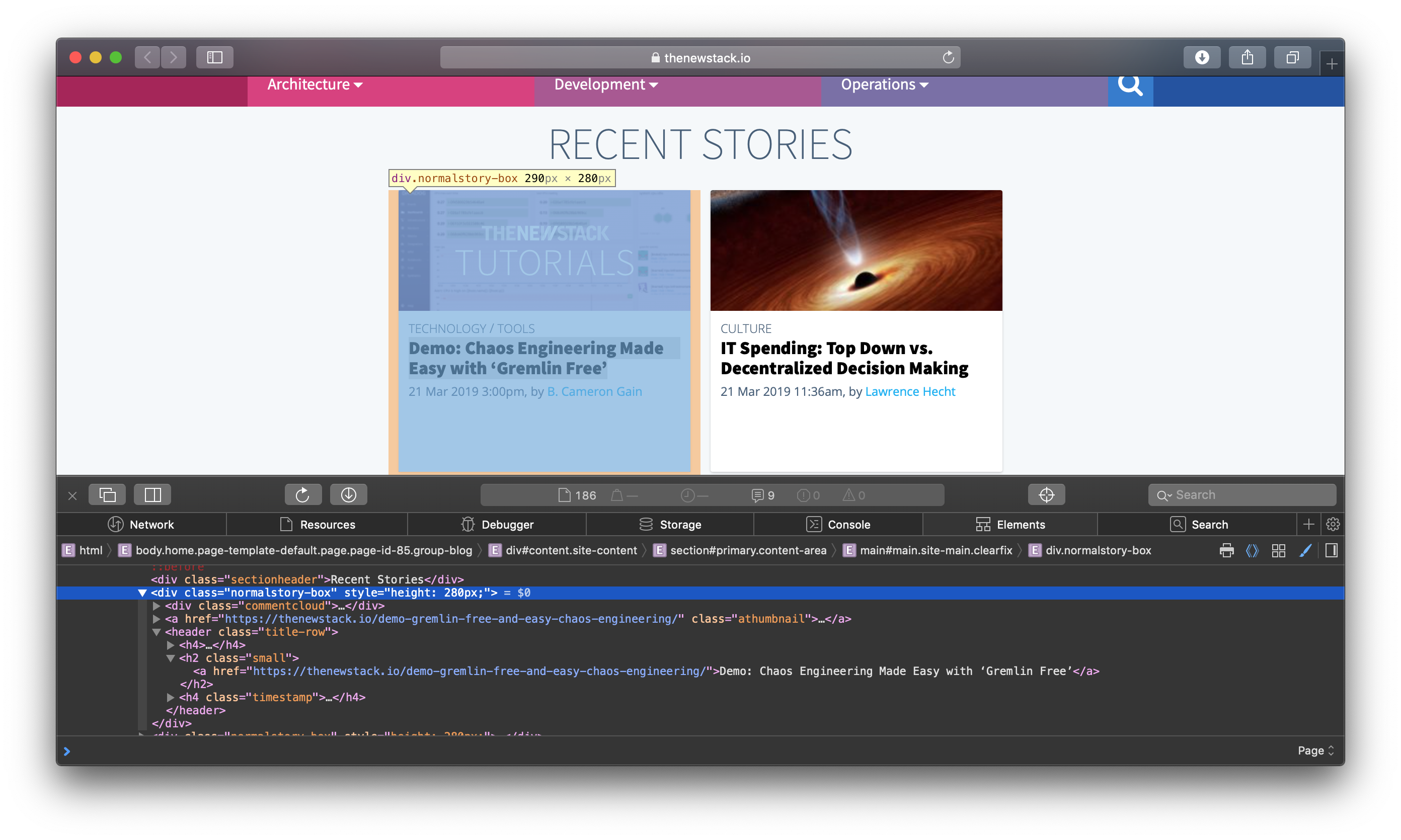
现在,您将创建一个名为scrape_thenewstack()的新扫描函数,并从其内部向 thenewstack.io提出 GET 请求。
1[label bird/bot.py]
2...
3def scrape_coursera():
4 ...
5 yield '"%s" %s' % (text, link)
6
7def scrape_thenewstack():
8 """Scrapes news from thenewstack.io"""
9
10 r = requests.get('https://thenewstack.io', verify=False)
11
12 tree = fromstring(r.content)
13 links = tree.xpath('//div[@class="normalstory-box"]/header/h2/a/@href')
14 for link in links:
您使用verify=False旗帜,因为网站有时可能有过期安全证书,如果没有涉及敏感数据,可以访问它们,就像这里的情况一样。
您现在可以提取与每个链接相符的博客段落,并使用您在上一个步骤中构建的extract_paratext()函数从可用的段落列表中提取随机段落。
1[label bird/bot.py]
2...
3def scrape_thenewstack():
4 ...
5 links = tree.xpath('//div[@class="normalstory-box"]/header/h2/a/@href')
6
7 for link in links:
8 r = requests.get(link, verify=False)
9 tree = fromstring(r.content)
10 paras = tree.xpath('//div[@class="post-content"]/p')
11 para = extract_paratext(paras)
12 text = extract_text(para)
13 if not text:
14 continue
15
16 yield '"%s" %s' % (text, link)
您现在有一个想法,一个扫描过程通常包括什么。您现在可以建立自己的自定义扫描器,例如,可以扫描博客帖子中的图像,而不是随机引用。 为此,您可以寻找相关的<img>标签。一旦您有正确的标签路径,这些标签作为它们的标识符,您可以使用相应属性的名称访问标签中的信息。
此时,您已经构建了两个扫描功能来扫描来自两个不同的网站的内容,您还建立了两个帮助功能来重复使用在两个扫描器中常见的功能。
步骤5 - 推特破碎的内容
在此步骤中,您将将机器人扩展到从两个网站中提取内容,并通过您的Twitter帐户推文。更准确地说,您希望它可以从两个网站中交替地推文内容,并且在十分钟的定期间隔下,在无限期内使用。
1[label bird/bot.py]
2...
3def scrape_thenewstack():
4 ...
5 yield '"%s" %s' % (text, link)
6
7def main():
8 """Encompasses the main loop of the bot."""
9 print('---Bot started---\n')
10 news_funcs = ['scrape_coursera', 'scrape_thenewstack']
11 news_iterators = []
12 for func in news_funcs:
13 news_iterators.append(globals()[func]())
14 while True:
15 for i, iterator in enumerate(news_iterators):
16 try:
17 tweet = next(iterator)
18 t.statuses.update(status=tweet)
19 print(tweet, end='\n\n')
20 time.sleep(600)
21 except StopIteration:
22 news_iterators[i] = globals()[newsfuncs[i]]()
您首先创建您先前定义的刮去函数的名称列表, 并将其称为 news_ funcs 。 然后创建一个空列表,该列表将具有实际的刮取器功能,并将该列表命名为"news_iterator". 然后通过在news_funcs'列表中逐一列出名字,并在news-iterators'列表中附上相应的延展者,来补充。 您正在使用 Python 内置的 globals () 函数 。 这将返回一个将变量名称映射到您脚本中实际变量的字典。 当您将刮刮函数称为刮刮函数时会得到什么:例如,如果您写出 coursera_iterator = scrape_coursera () , 那么 coursera_iterator 将是一个调取 next() 的调取函数。 每个next() 调用将返回一个字符串,其中包含一个引号及其相应的链接,确切定义在 scrape_courerra () 函数 的 输出 语句中。 每个next()' 调用是通过scrape_courerra ()函数中for循环的一个迭代。 因此,你只能制造尽可能多的next()' 因为 scrape_courerra () 函数中有博客链接。 一旦这一数字超过,将提出 " 停止 " 例外.
一旦两个迭代器都填充了news_iterators列表,主要的while循环就会开始。里面,你有一个for循环,通过每个迭代器并试图获得要推文的内容。获取内容后,你的机器人会推文,然后睡10分钟。如果迭代器没有更多的内容可供提供,就会产生一个StopIteration例外,你会通过重新实时化更新该迭代器,以检查源网站上新内容的可用性。
现在剩下的就是调用 main() 函数,当 Python 解释器调用 directly 时,你会这样做:
1[label bird/bot.py]
2...
3def main():
4 print('---Bot started---\n')
5 news_funcs = ['scrape_coursera', 'scrape_thenewstack']
6 ...
7
8if __name__ == "__main__":
9 main()
以下是「bot.py」脚本的完整版本,您也可以查看此GitHub存储中的脚本(https://github.com/do-community/chirps)。
1[label bird/bot.py]
2
3"""Main bot script - bot.py
4For the DigitalOcean Tutorial.
5"""
6
7import random
8import time
9
10from lxml.html import fromstring
11import nltk
12nltk.download('punkt')
13import requests
14
15from twitter import OAuth, Twitter
16
17import credentials
18
19tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
20
21oauth = OAuth(
22 credentials.ACCESS_TOKEN,
23 credentials.ACCESS_SECRET,
24 credentials.CONSUMER_KEY,
25 credentials.CONSUMER_SECRET
26 )
27t = Twitter(auth=oauth)
28
29HEADERS = {
30 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5)'
31 ' AppleWebKit/537.36 (KHTML, like Gecko) Cafari/537.36'
32 }
33
34def extract_paratext(paras):
35 """Extracts text from <p> elements and returns a clean, tokenized random
36 paragraph."""
37
38 paras = [para.text_content() for para in paras if para.text_content()]
39 para = random.choice(paras)
40 return tokenizer.tokenize(para)
41
42def extract_text(para):
43 """Returns a sufficiently-large random text from a tokenized paragraph,
44 if such text exists. Otherwise, returns None."""
45
46 for _ in range(10):
47 text = random.choice(para)
48 if text and 60 < len(text) < 210:
49 return text
50
51 return None
52
53def scrape_coursera():
54 """Scrapes content from the Coursera blog."""
55 url = 'https://blog.coursera.org'
56 r = requests.get(url, headers=HEADERS)
57 tree = fromstring(r.content)
58 links = tree.xpath('//div[@class="recent"]//div[@class="title"]/a/@href')
59
60 for link in links:
61 r = requests.get(link, headers=HEADERS)
62 blog_tree = fromstring(r.content)
63 paras = blog_tree.xpath('//div[@class="entry-content"]/p')
64 para = extract_paratext(paras)
65 text = extract_text(para)
66 if not text:
67 continue
68
69 yield '"%s" %s' % (text, link)
70
71def scrape_thenewstack():
72 """Scrapes news from thenewstack.io"""
73
74 r = requests.get('https://thenewstack.io', verify=False)
75
76 tree = fromstring(r.content)
77 links = tree.xpath('//div[@class="normalstory-box"]/header/h2/a/@href')
78
79 for link in links:
80 r = requests.get(link, verify=False)
81 tree = fromstring(r.content)
82 paras = tree.xpath('//div[@class="post-content"]/p')
83 para = extract_paratext(paras)
84 text = extract_text(para)
85 if not text:
86 continue
87
88 yield '"%s" %s' % (text, link)
89
90def main():
91 """Encompasses the main loop of the bot."""
92 print('Bot started.')
93 news_funcs = ['scrape_coursera', 'scrape_thenewstack']
94 news_iterators = []
95 for func in news_funcs:
96 news_iterators.append(globals()[func]())
97 while True:
98 for i, iterator in enumerate(news_iterators):
99 try:
100 tweet = next(iterator)
101 t.statuses.update(status=tweet)
102 print(tweet, end='\n')
103 time.sleep(600)
104 except StopIteration:
105 news_iterators[i] = globals()[newsfuncs[i]]()
106
107if __name__ == "__main__":
108 main()
保存和退出bot.py。
以下是 bot.py 的示例执行:
1python3 bot.py
您将收到显示您的机器人已经扫描的内容的输出,以类似于以下格式:
1[secondary_label Output]
2[nltk_data] Downloading package punkt to /Users/binaryboy/nltk_data...
3[nltk_data] Package punkt is already up-to-date!
4---Bot started---
5
6"Take the first step toward your career goals by building new skills." https://blog.coursera.org/career-stories-from-inside-coursera/
7
8"Other speakers include Priyanka Sharma, director of cloud native alliances at GitLab and Dan Kohn, executive director of the Cloud Native Computing Foundation." https://thenewstack.io/cloud-native-live-twistlocks-virtual-conference/
9
10"You can learn how to use the power of Python for data analysis with a series of courses covering fundamental theory and project-based learning." https://blog.coursera.org/unlock-the-power-of-data-with-python-university-of-michigan-offers-new-programming-specializations-on-coursera/
11
12"“Real-user monitoring is really about trying to understand the underlying reasons, so you know, ‘who do I actually want to fly with?" https://thenewstack.io/how-raygun-co-founder-and-ceo-spun-gold-out-of-monitoring-agony/
在您的机器人的样本运行后,您将看到您的机器人在您的Twitter页面上发布的完整的时间表,它将看起来如下:
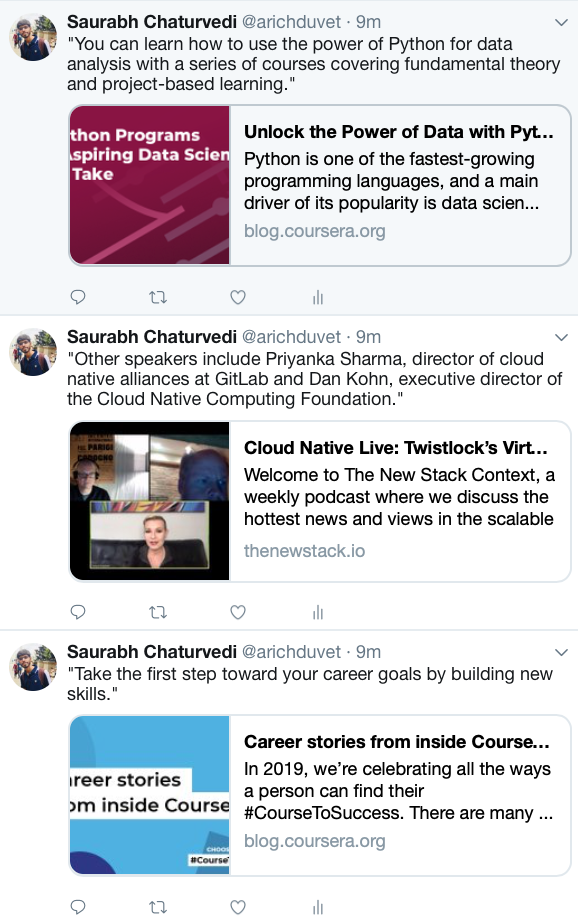
正如你所看到的,该机器人正在推特从每个博客中随机引用的删除的博客链接作为亮点。 此源现在是一个信息源,来自Coursera和thenewstack.io的博客引用之间交替的推文。 你已经建立了一个机器人,该机器人从网络中汇总内容,并在Twitter上发布它。
结论
在本教程中,你用Python构建了一个基本的Twitter机器人,并从网络上摘取了一些内容,让你的机器人推文。有很多机器人的想法可以尝试;你也可以为机器人的实用程序实施自己的想法。你可以结合Twitter的API提供的多功能功能,并创建一些更复杂的东西。对于一个更复杂的Twitter机器人的版本,请查看 chirps,一个使用一些先进的概念的Twitter机器人框架,例如多线,使机器人同时做多个事情。
最后,机器人标签或(bot etiquette)在构建你的下一个机器人时很重要。例如,如果你的机器人包含重复推文,请让所有的推文通过过滤器检测滥用语言,然后重复推文。你可以使用常规表达式和自然语言处理来实现这些功能。