作者选择了 自由和开源基金作为 写给捐款计划的一部分接受捐款。
介绍
网页扫描是从网页自动收集数据的过程,该过程通常部署了一个扫描器,它自动浏览网页,并从选定的页面中扫描数据。为什么您可能想要扫描数据有很多原因,主要是通过消除手动数据采集过程来使数据收集更快。
在本教程中,您将使用 Node.js和 Puppeteer构建一个网页扫描应用程序。随着您的进展,您的应用程序将变得更加复杂。 首先,您将编码您的应用程序以打开 Chromium并加载专门的网站,旨在作为网页扫描沙盒: books.toscrape.com. 在接下来的两个步骤中,您将扫描所有书籍在单页上的 books.toscrape,然后在多个页面上扫描所有书籍。 在剩余的步骤中,您将按书籍类别过滤扫描,然后将数据保存为JSON文件。
<$>[警告] **警告:**网络扫描的道德和合法性非常复杂,不断发展。它们也根据您的位置,数据的位置和所涉及的网站而有所不同。本教程扫描了一个特殊的网站, books.toscrape.com,该网站专门用于测试扫描应用程序。
前提条件
此教程已在 Node.js 版本 12.18.3 和 npm 版本 6.14.6 上测试。 [您可以按照本指南在 macOS 或 Ubuntu 18.04 上安装 Node.js。
步骤 1 — 设置网页扫描器
有了 Node.js 安装,您可以开始设置您的 Web 扫描仪。 首先,您将创建一个项目根目录,然后安装所需的依赖性。 本教程只需要一个依赖性,您将使用 Node.js 的默认包管理器 npm安装它。
创建该项目的文件夹,然后进入:
1mkdir book-scraper
2cd book-scraper
您将从此目录中运行所有后续命令。
我们需要使用 npm 或节点包管理器安装一个包,首先要初始化 npm 以创建一个 packages.json 文件,该文件将管理您的项目的依赖性和元数据。
对您的项目初始化 npm:
1npm init
npm 會顯示一系列提示,你可以按「ENTER」按每個提示,或者你可以添加個性化的描述。 請確保按「ENTER」並在提示「入口點:」和「測試指令:」時留下預設值。 另一個方法是,你可以將「y」標籤傳送到「npm」—「npm init -y'—,它將為你提交所有預設值。
你的输出将看起来像这样的东西:
1[secondary_label Output]
2{
3 "name": "sammy_scraper",
4 "version": "1.0.0",
5 "description": "a web scraper",
6 "main": "index.js",
7 "scripts": {
8 "test": "echo \"Error: no test specified\" && exit 1"
9 },
10 "keywords": [],
11 "author": "sammy the shark",
12 "license": "ISC"
13}
14
15Is this OK? (yes) yes
键入是并按下ENTER。npm将将此输出保存为您的package.json文件。
现在使用npm来安装Puppeteer:
1npm install --save puppeteer
此命令会安装 Puppeteer 和 Chromium 版本,Puppeteer 团队知道它将与其 API 一起工作。
在 Linux 机器上,Puppeteer 可能需要一些额外的依赖性。
如果你正在使用Ubuntu 18.04, 检查在Puppeteer的故障排除文件的Chrome headless doesn’t launch on UNIX部分中的Debian Dependencies下载部分。
1ldd chrome | grep not
有了 npm、Puppeteer 和任何其他依赖性,您的 package.json 文件在开始编码之前需要进行最后一个配置. 在本教程中,您将从命令行启动您的应用程序,使用npm run start。您必须在 package.json 中添加一些关于这个start脚本的信息。
在您喜爱的文本编辑器中打开文件:
1nano package.json
查找脚本:部分并添加以下配置. 请记住在测试脚本行的末尾放一个字节,否则您的文件将无法正确解析。
1[secondary_label Output]
2{
3 . . .
4 "scripts": {
5 "test": "echo \"Error: no test specified\" && exit 1",
6 "start": "node index.js"
7 },
8 . . .
9 "dependencies": {
10 "puppeteer": "^5.2.1"
11 }
12}
您还会注意到puppeteer现在出现在文件末尾的依赖下方。您的package.json文件将不再需要更改。
您现在已经准备好开始编码您的扫描仪,在下一步,您将设置一个浏览器实例,并测试您的扫描仪的基本功能。
步骤 2 — 设置浏览器实例
当你打开传统的浏览器时,你可以做点击按钮等事情,用鼠标导航,键入,打开开发工具等。像Chromium这样的无头浏览器允许你做这些事情,但在程序上和没有用户界面的情况下。在这个步骤中,你将设置你的扫描仪的浏览器实例。当你启动你的应用程序时,它将自动打开Chromium并导航到 books.toscrape.com。这些初始行动将形成你的程序的基础。
您的网页扫描器将需要四个.js 文件:browser.js、index.js、pageController.js 和 pageScraper.js. 在此步骤中,您将创建所有四个文件,然后不断更新它们,因为您的程序变得更加复杂。
从项目的根目录中,在文本编辑器中创建并打开browser.js:
1nano browser.js
首先,您将要求Puppeteer,然后创建一个名为startBrowser()的async函数,该函数将启动浏览器并返回一个实例。
1[label ./book-scraper/browser.js]
2const puppeteer = require('puppeteer');
3
4async function startBrowser(){
5 let browser;
6 try {
7 console.log("Opening the browser......");
8 browser = await puppeteer.launch({
9 headless: false,
10 args: ["--disable-setuid-sandbox"],
11 'ignoreHTTPSErrors': true
12 });
13 } catch (err) {
14 console.log("Could not create a browser instance => : ", err);
15 }
16 return browser;
17}
18
19module.exports = {
20 startBrowser
21};
Puppeteer 有一个 .launch() 方法,它启动了浏览器的实例。 此方法返回一个 Promise,所以你必须使用一个 .then 或 await 块(https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Asynchronous/Async_await)来确保承诺得到解决。
您正在使用等待来确保承诺得到解决,将此实例围绕 一个试捕代码块,然后返回浏览器的实例。
请注意,.launch() 方法采用 JSON 参数,具有几个值:
- headless -
false意味着浏览器将运行与接口,所以你可以观看你的脚本执行,而true意味着浏览器将运行在无头模式. 但是,请注意,如果你想将你的扫描器部署到云中,设置headless回到true。 大多数虚拟机是无头,不包含用户界面,因此只能在无头模式下运行浏览器. Puppeteer 还包括一个headful模式,但这应该仅用于测试目的 - 忽略HTTPSErrors -
true允许你访问未在安全的 HTTPS 协议上托管的网站,并忽略任何与 HTTPS 相关的错误
保存并关闭文件。
现在创建你的第二个.js 文件, index.js:
1nano index.js
在这里,您将要求``browser.js和pageController.js。然后,您将调用startBrowser()函数,并将创建的浏览器实例传递给我们的页面控制器,这将指导其操作。
1[label ./book-scraper/index.js]
2const browserObject = require('./browser');
3const scraperController = require('./pageController');
4
5//Start the browser and create a browser instance
6let browserInstance = browserObject.startBrowser();
7
8// Pass the browser instance to the scraper controller
9scraperController(browserInstance)
保存并关闭文件。
创建第三个.js 文件,pageController.js:
1nano pageController.js
pageController.js控制你的扫描过程. 它使用浏览器实例来控制pageScraper.js文件,这就是所有扫描脚本执行的地方。 最终,你会用它来指定你想要扫描的书籍类别。 然而,现在,你只想确保你可以打开Chromium并导航到网页:
1[label ./book-scraper/pageController.js]
2const pageScraper = require('./pageScraper');
3async function scrapeAll(browserInstance){
4 let browser;
5 try{
6 browser = await browserInstance;
7 await pageScraper.scraper(browser);
8
9 }
10 catch(err){
11 console.log("Could not resolve the browser instance => ", err);
12 }
13}
14
15module.exports = (browserInstance) => scrapeAll(browserInstance)
此代码导出一个在浏览器实例中使用的函数,并将其传输到一个名为 scrapeAll() 的函数中,该函数反过来将此实例传输到 pageScraper.scraper() 作为一个用来扫描页面的参数。
保存并关闭文件。
最后,创建你的最后一个.js 文件,pageScraper.js:
1nano pageScraper.js
在这里,你将创建一个字面对象,具有url属性和scraper()方法。url是你想要扫描的网页的网页URL,而scraper()方法包含执行你实际扫描的代码,尽管在这个阶段它只是导航到URL。
1[label ./book-scraper/pageScraper.js]
2const scraperObject = {
3 url: 'http://books.toscrape.com',
4 async scraper(browser){
5 let page = await browser.newPage();
6 console.log(`Navigating to ${this.url}...`);
7 await page.goto(this.url);
8
9 }
10}
11
12module.exports = scraperObject;
Puppeteer 使用「newPage()」方法在浏览器中创建新页面实例,这些页面实例可以做很多事情。在我们的「scraper()」方法中,您创建了页面实例,然后使用了 page.goto() 方法导航到 books.toscrape.com 主页。
保存并关闭文件。
您的程序的文件结构已经完成. 您的项目目录树的第一层将看起来像这样:
1[secondary_label Output]
2.
3├── browser.js
4├── index.js
5├── node_modules
6├── package-lock.json
7├── package.json
8├── pageController.js
9└── pageScraper.js
现在运行npm run start命令,并观看你的扫描仪应用程序执行:
1npm run start
它会自动打开 Chromium 浏览器实例,在浏览器中打开新页面,并导航到 books.toscrape.com。
在此步骤中,您创建了一个 Puppeteer 应用程序,打开了 Chromium,并加载了虚假的在线书店的主页:books.toscrape.com 在下一步中,您将扫描该主页上的每个书的数据。
步骤 3 —从单个页面中扫描数据
在添加更多的功能到你的扫描程序应用程序之前,打开你喜欢的网页浏览器,并手动导航到 书籍扫描主页。
您将在左侧找到一个类别部分和图书显示在右侧. 当您点击图书时,浏览器将导航到一个新的URL,显示有关该特定图书的相关信息。
在此步骤中,您将复制这种行为,但使用代码;您将自动化浏览网站并消耗其数据的业务。
首先,如果你使用你的浏览器中的Dev Tools检查主页的源代码,你会注意到该页面列出了每本书的数据在一个部分标签下。
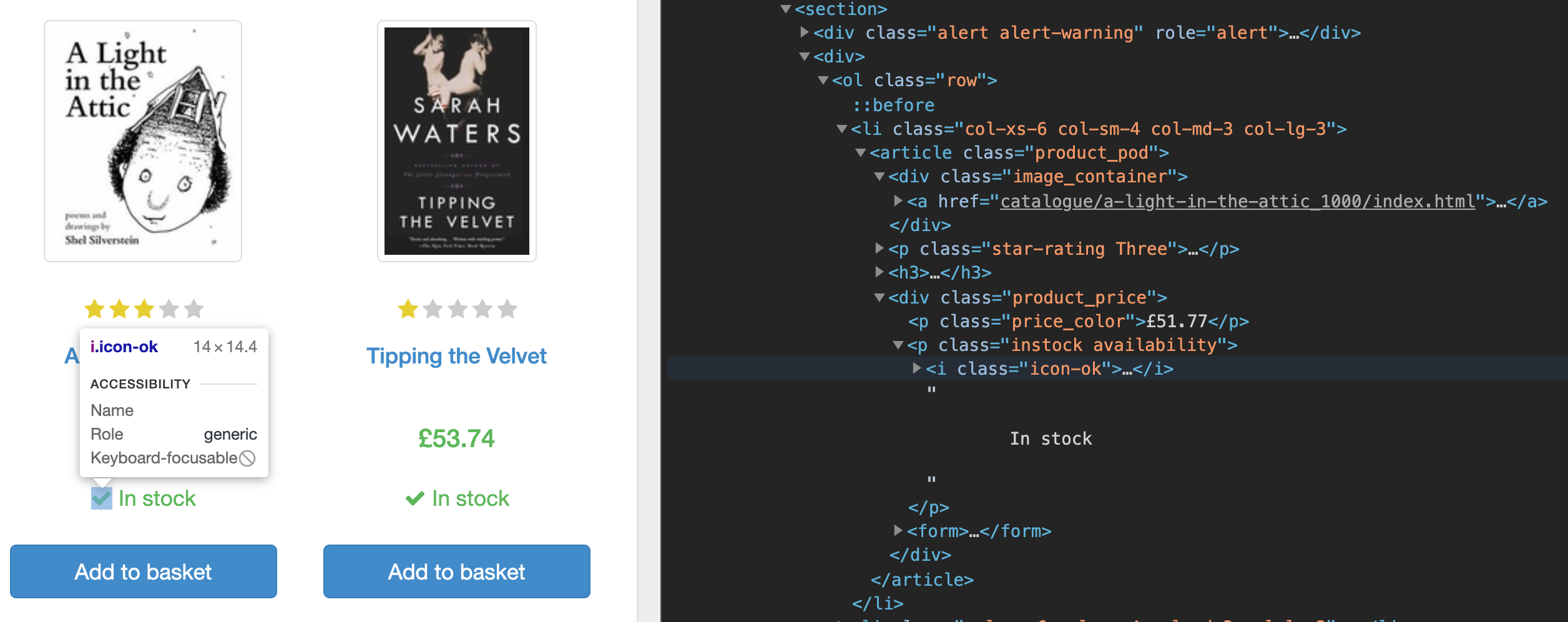
您将扫描这些书籍的URL,过滤存储的书籍,导航到每个单独的书籍页面,并扫描该书的数据。
重新開啟您的「pageScraper.js」檔案:
1nano pageScraper.js
添加以下突出的内容. 您将在等待页面.goto(this.url)内部插入另一个等待块:
1[label ./book-scraper/pageScraper.js]
2
3const scraperObject = {
4 url: 'http://books.toscrape.com',
5 async scraper(browser){
6 let page = await browser.newPage();
7 console.log(`Navigating to ${this.url}...`);
8 // Navigate to the selected page
9 await page.goto(this.url);
10 // Wait for the required DOM to be rendered
11 await page.waitForSelector('.page_inner');
12 // Get the link to all the required books
13 let urls = await page.$$eval('section ol > li', links => {
14 // Make sure the book to be scraped is in stock
15 links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
16 // Extract the links from the data
17 links = links.map(el => el.querySelector('h3 > a').href)
18 return links;
19 });
20 console.log(urls);
21 }
22}
23
24module.exports = scraperObject;
在这个代码块中,你叫了 the page.waitForSelector() 方法。这等待了包含所有与书籍相关的信息在 DOM 中渲染的 div,然后你叫了 the page.$eval() 方法。
每本书都有两种状态;一本书是在库存或在库存之外。你只想要扫描在库存的书籍,因为page.$$eval()返回了所有匹配元素的数组,所以你过滤了这个数组,以确保您只使用在库存中的书籍。
保存并关闭文件。
重启您的申请:
1npm run start
浏览器将打开,导航到网页,然后在任务完成后关闭。
1[secondary_label Output]
2> [email protected] start /Users/sammy/book-scraper
3> node index.js
4
5Opening the browser......
6Navigating to http://books.toscrape.com...
7[
8 'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
9 'http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html',
10 'http://books.toscrape.com/catalogue/soumission_998/index.html',
11 'http://books.toscrape.com/catalogue/sharp-objects_997/index.html',
12 'http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
13 'http://books.toscrape.com/catalogue/the-requiem-red_995/index.html',
14 'http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html',
15 'http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html',
16 'http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html',
17 'http://books.toscrape.com/catalogue/the-black-maria_991/index.html',
18 'http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html',
19 'http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html',
20 'http://books.toscrape.com/catalogue/set-me-free_988/index.html',
21 'http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html',
22 'http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html',
23 'http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html',
24 'http://books.toscrape.com/catalogue/olio_984/index.html',
25 'http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html',
26 'http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html',
27 'http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html'
28]
这是一个很好的开始,但你想扫描特定书籍的所有相关数据,而不仅仅是其URL. 你现在将使用这些URL打开每个页面,扫描书籍的标题,作者,价格,可用性,UPC,描述和图像URL。
重新打开pageScraper.js:
1nano pageScraper.js
添加以下代码,将循环通过每个被扫描的链接,打开一个新的页面实例,然后获取相关数据:
1[label ./book-scraper/pageScraper.js]
2const scraperObject = {
3 url: 'http://books.toscrape.com',
4 async scraper(browser){
5 let page = await browser.newPage();
6 console.log(`Navigating to ${this.url}...`);
7 // Navigate to the selected page
8 await page.goto(this.url);
9 // Wait for the required DOM to be rendered
10 await page.waitForSelector('.page_inner');
11 // Get the link to all the required books
12 let urls = await page.$$eval('section ol > li', links => {
13 // Make sure the book to be scraped is in stock
14 links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
15 // Extract the links from the data
16 links = links.map(el => el.querySelector('h3 > a').href)
17 return links;
18 });
19
20 // Loop through each of those links, open a new page instance and get the relevant data from them
21 let pagePromise = (link) => new Promise(async(resolve, reject) => {
22 let dataObj = {};
23 let newPage = await browser.newPage();
24 await newPage.goto(link);
25 dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
26 dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
27 dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
28 // Strip new line and tab spaces
29 text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
30 // Get the number of stock available
31 let regexp = /^.*\((.*)\).*$/i;
32 let stockAvailable = regexp.exec(text)[1].split(' ')[0];
33 return stockAvailable;
34 });
35 dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
36 dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
37 dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
38 resolve(dataObj);
39 await newPage.close();
40 });
41
42 for(link in urls){
43 let currentPageData = await pagePromise(urls[link]);
44 // scrapedData.push(currentPageData);
45 console.log(currentPageData);
46 }
47
48 }
49}
50
51module.exports = scraperObject;
您有所有URL的数组. 您希望通过这个数组循环,在新页面中打开URL,在该页面上扫描数据,关闭该页面,并在数组中为下一个URL打开新页面。 请注意,您将此代码包装成一个承诺。 这是因为您希望能够等待循环中的每个操作完成。
<$>[警告]
**警告:**请注意,您使用for-in循环等待了承诺。任何其他循环都足够,但避免使用forEach或使用回调函数的任何其他方法重复您的 URL 序列,因为回调函数必须先通过回调排列和事件循环,因此,多个页面实例将同时打开。
仔细看看你的PagePromise函数。你的扫描器首先为每个URL创建了一个新页面,然后你使用了page.$eval()函数来瞄准您想要在新页面上扫描的相关细节的选项。一些文本包含白色空间、卡片、新闻线和其他非字母数字字符,您使用常规表达式删除这些字符。
保存并关闭文件。
再次运行脚本:
1npm run start
浏览器打开主页,然后打开每个图书页面,并从每个页面中记录摘取的数据。
1[secondary_label Output]
2Opening the browser......
3Navigating to http://books.toscrape.com...
4{
5 bookTitle: 'A Light in the Attic',
6 bookPrice: '£51.77',
7 noAvailable: '22',
8 imageUrl: 'http://books.toscrape.com/media/cache/fe/72/fe72f0532301ec28892ae79a629a293c.jpg',
9 bookDescription: "It's hard to imagine a world without A Light in the Attic. [...]',
10 upc: 'a897fe39b1053632'
11}
12{
13 bookTitle: 'Tipping the Velvet',
14 bookPrice: '£53.74',
15 noAvailable: '20',
16 imageUrl: 'http://books.toscrape.com/media/cache/08/e9/08e94f3731d7d6b760dfbfbc02ca5c62.jpg',
17 bookDescription: `"Erotic and absorbing...Written with starling power."--"The New York Times Book Review " Nan King, an oyster girl, is captivated by the music hall phenomenon Kitty Butler [...]`,
18 upc: '90fa61229261140a'
19}
20{
21 bookTitle: 'Soumission',
22 bookPrice: '£50.10',
23 noAvailable: '20',
24 imageUrl: 'http://books.toscrape.com/media/cache/ee/cf/eecfe998905e455df12064dba399c075.jpg',
25 bookDescription: 'Dans une France assez proche de la nôtre, [...]',
26 upc: '6957f44c3847a760'
27}
28...
在此步骤中,您在 books.toscrape.com 主页上扫描了每本书的相关数据,但您可以添加更多功能. 例如,书籍的每个页面都是页面化;您如何从这些其他页面获取书籍? 此外,在网站的左侧,您发现了书籍类别;如果你不想要所有书籍,但只想要特定类别的书籍? 现在您将添加这些功能。
步骤 4 —从多个页面中提取数据
在 book.toscrape.com 上的页面有页面,其内容下方有下一步按钮,而没有页面的页面没有。
由于每个页面上的数据具有相同的结构和具有相同的标记,您将不会为每个可能的页面写一个扫描器,而是将使用 recursion的做法。
首先,您需要稍微改变代码的结构,以适应重复导航到多个页面。
重新打开pagescraper.js:
1nano pagescraper.js
您将添加一个名为scrapeCurrentPage()的新函数到您的scraper()方法. 此函数将包含从特定页面提取数据的所有代码,然后点击下一个按钮,如果存在的话。
1[label ./book-scraper/pageScraper.js scraper()]
2const scraperObject = {
3 url: 'http://books.toscrape.com',
4 async scraper(browser){
5 let page = await browser.newPage();
6 console.log(`Navigating to ${this.url}...`);
7 // Navigate to the selected page
8 await page.goto(this.url);
9 let scrapedData = [];
10 // Wait for the required DOM to be rendered
11 async function scrapeCurrentPage(){
12 await page.waitForSelector('.page_inner');
13 // Get the link to all the required books
14 let urls = await page.$$eval('section ol > li', links => {
15 // Make sure the book to be scraped is in stock
16 links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
17 // Extract the links from the data
18 links = links.map(el => el.querySelector('h3 > a').href)
19 return links;
20 });
21 // Loop through each of those links, open a new page instance and get the relevant data from them
22 let pagePromise = (link) => new Promise(async(resolve, reject) => {
23 let dataObj = {};
24 let newPage = await browser.newPage();
25 await newPage.goto(link);
26 dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
27 dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
28 dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
29 // Strip new line and tab spaces
30 text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
31 // Get the number of stock available
32 let regexp = /^.*\((.*)\).*$/i;
33 let stockAvailable = regexp.exec(text)[1].split(' ')[0];
34 return stockAvailable;
35 });
36 dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
37 dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
38 dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
39 resolve(dataObj);
40 await newPage.close();
41 });
42
43 for(link in urls){
44 let currentPageData = await pagePromise(urls[link]);
45 scrapedData.push(currentPageData);
46 // console.log(currentPageData);
47 }
48 // When all the data on this page is done, click the next button and start the scraping of the next page
49 // You are going to check if this button exist first, so you know if there really is a next page.
50 let nextButtonExist = false;
51 try{
52 const nextButton = await page.$eval('.next > a', a => a.textContent);
53 nextButtonExist = true;
54 }
55 catch(err){
56 nextButtonExist = false;
57 }
58 if(nextButtonExist){
59 await page.click('.next > a');
60 return scrapeCurrentPage(); // Call this function recursively
61 }
62 await page.close();
63 return scrapedData;
64 }
65 let data = await scrapeCurrentPage();
66 console.log(data);
67 return data;
68 }
69}
70
71module.exports = scraperObject;
您将nextButtonExist变量设置为最初为 false,然后检查按钮是否存在. 如果nextButtonExists按钮存在,您将nextButtonExists设置为true,然后继续点击next按钮,然后重复调用此函数。
如果「nextButtonExists」是假的,它会像往常一样返回「scrapedData」数组。
保存并关闭文件。
再次运行你的脚本:
1npm run start
这可能需要一段时间才能完成;毕竟,你的应用程序现在正在从800多本书中扫描数据. 请自由关闭浏览器或按CTRL + C来取消该过程。
现在你已经最大限度地提高了你的扫描仪的功能,但你在这个过程中创造了一个新的问题. 现在的问题不是太少的数据,而是太多的数据. 在下一步,你会调整你的应用程序来过滤你的扫描书籍类别。
步骤 5 — 按类别扫描数据
要按类别扫描数据,您需要修改您的pageScraper.js文件和您的pageController.js文件。
在文本编辑器中打开pageController.js:
1nano pageController.js
拨打扫描仪,以便它只扫描旅行书籍。
1[label ./book-scraper/pageController.js]
2const pageScraper = require('./pageScraper');
3async function scrapeAll(browserInstance){
4 let browser;
5 try{
6 browser = await browserInstance;
7 let scrapedData = {};
8 // Call the scraper for different set of books to be scraped
9 scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
10 await browser.close();
11 console.log(scrapedData)
12 }
13 catch(err){
14 console.log("Could not resolve the browser instance => ", err);
15 }
16}
17module.exports = (browserInstance) => scrapeAll(browserInstance)
您现在正在将两个参数传输到您的pageScraper.scraper()方法中,第二个参数是您想要扫描的书籍类别,这在本示例中是旅行。
保存并关闭文件。
打开pageScraper.js:
1nano pageScraper.js
添加以下代码,将添加您的类别参数,导航到该类别页面,然后开始扫描页面结果:
1[label ./book-scraper/pageScraper.js]
2const scraperObject = {
3 url: 'http://books.toscrape.com',
4 async scraper(browser, category){
5 let page = await browser.newPage();
6 console.log(`Navigating to ${this.url}...`);
7 // Navigate to the selected page
8 await page.goto(this.url);
9 // Select the category of book to be displayed
10 let selectedCategory = await page.$$eval('.side_categories > ul > li > ul > li > a', (links, _category) => {
11
12 // Search for the element that has the matching text
13 links = links.map(a => a.textContent.replace(/(\r\n\t|\n|\r|\t|^\s|\s$|\B\s|\s\B)/gm, "") === _category ? a : null);
14 let link = links.filter(tx => tx !== null)[0];
15 return link.href;
16 }, category);
17 // Navigate to the selected category
18 await page.goto(selectedCategory);
19 let scrapedData = [];
20 // Wait for the required DOM to be rendered
21 async function scrapeCurrentPage(){
22 await page.waitForSelector('.page_inner');
23 // Get the link to all the required books
24 let urls = await page.$$eval('section ol > li', links => {
25 // Make sure the book to be scraped is in stock
26 links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
27 // Extract the links from the data
28 links = links.map(el => el.querySelector('h3 > a').href)
29 return links;
30 });
31 // Loop through each of those links, open a new page instance and get the relevant data from them
32 let pagePromise = (link) => new Promise(async(resolve, reject) => {
33 let dataObj = {};
34 let newPage = await browser.newPage();
35 await newPage.goto(link);
36 dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
37 dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
38 dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
39 // Strip new line and tab spaces
40 text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
41 // Get the number of stock available
42 let regexp = /^.*\((.*)\).*$/i;
43 let stockAvailable = regexp.exec(text)[1].split(' ')[0];
44 return stockAvailable;
45 });
46 dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
47 dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
48 dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
49 resolve(dataObj);
50 await newPage.close();
51 });
52
53 for(link in urls){
54 let currentPageData = await pagePromise(urls[link]);
55 scrapedData.push(currentPageData);
56 // console.log(currentPageData);
57 }
58 // When all the data on this page is done, click the next button and start the scraping of the next page
59 // You are going to check if this button exist first, so you know if there really is a next page.
60 let nextButtonExist = false;
61 try{
62 const nextButton = await page.$eval('.next > a', a => a.textContent);
63 nextButtonExist = true;
64 }
65 catch(err){
66 nextButtonExist = false;
67 }
68 if(nextButtonExist){
69 await page.click('.next > a');
70 return scrapeCurrentPage(); // Call this function recursively
71 }
72 await page.close();
73 return scrapedData;
74 }
75 let data = await scrapeCurrentPage();
76 console.log(data);
77 return data;
78 }
79}
80
81module.exports = scraperObject;
此代码块使用您传入的类别来获取该类别的书籍所在的URL。
「page.$$eval()」可以通过将参数作为第三参数传递到「$$eval()」方法,并将其定义为回调中的第三参数:
1[label example page.$$eval() function]
2page.$$eval('selector', function(elem, args){
3 // .......
4}, args)
这就是你在代码中所做的;你通过了你想要扫描的书籍类别,通过所有类别来检查哪个匹配,然后返回了该类别的URL。
然后,该 URL 被用来导航到显示您要使用 page.goto(selectedCategory) 方法扫描的书籍类别的页面。
保存并关闭文件。
你会注意到它导航到旅行类别,在该类别页面上重复打开书籍,并记录结果:
1npm run start
在此步骤中,您将扫描数据跨多个页面,然后扫描数据跨多个页面从一个特定类别。
步骤6:从多个类别提取数据并将数据保存为JSON
在这个最后一步中,你会让你的脚本摘取尽可能多的类别的数据,然后更改你的输出方式,而不是记录结果,你会将其保存到一个名为data.json的结构化文件中。
您可以快速添加更多的类别来扫描;这样做只需要每类别添加一个额外的行。
打开pageController.js:
1nano pageController.js
调整您的代码以包括额外的类别。下面的示例将历史小说和神秘添加到我们现有的旅行类别中:
1[label ./book-scraper/pageController.js]
2const pageScraper = require('./pageScraper');
3async function scrapeAll(browserInstance){
4 let browser;
5 try{
6 browser = await browserInstance;
7 let scrapedData = {};
8 // Call the scraper for different set of books to be scraped
9 scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
10 scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
11 scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
12 await browser.close();
13 console.log(scrapedData)
14 }
15 catch(err){
16 console.log("Could not resolve the browser instance => ", err);
17 }
18}
19
20module.exports = (browserInstance) => scrapeAll(browserInstance)
保存并关闭文件。
再次运行脚本,并观看它为所有三个类别摘取数据:
1npm run start
有了全功能的扫描仪,你的最后一步就是将你的数据保存到一个更有用的格式,你现在会使用Node.js中的fs模块(https://nodejs.org/api/fs.html)将其存储在一个JSON文件中。
首先,重新打开「pageController.js」:
1nano pageController.js
添加以下突出的代码:
1[label ./book-scraper/pageController.js]
2const pageScraper = require('./pageScraper');
3const fs = require('fs');
4async function scrapeAll(browserInstance){
5 let browser;
6 try{
7 browser = await browserInstance;
8 let scrapedData = {};
9 // Call the scraper for different set of books to be scraped
10 scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
11 scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
12 scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
13 await browser.close();
14 fs.writeFile("data.json", JSON.stringify(scrapedData), 'utf8', function(err) {
15 if(err) {
16 return console.log(err);
17 }
18 console.log("The data has been scraped and saved successfully! View it at './data.json'");
19 });
20 }
21 catch(err){
22 console.log("Could not resolve the browser instance => ", err);
23 }
24}
25
26module.exports = (browserInstance) => scrapeAll(browserInstance)
首先,您需要Node,js的fs模块在pageController.js。这确保您可以将数据保存为JSON文件,然后添加代码,以便在扫描完成后,浏览器关闭时,程序会创建一个名为data.json的新文件。 请注意,data.json的内容是 stringified JSON。
保存并关闭文件。
您现在已经建立了一个网页扫描应用程序,它在多个类别中扫描书籍,然后将您的扫描数据存储在JSON文件中。随着您的应用程序的复杂性增加,您可能希望将这些扫描数据存储在数据库中或通过API服务。
结论
在本教程中,您构建了一种 web crawler,可反复扫描多个页面上的数据,然后将其保存到 JSON 文件中。
Puppeteer 有很多不属于本教程范围的功能. 要了解更多信息,请参阅 使用 Puppeteer for Easy Control Over Headless Chrome 。