作者选择了 自由和开源基金作为 写给捐款计划的一部分接受捐款。
介绍
Flask是一个轻量级的Python网络框架,提供用于在Python语言中创建Web应用程序的有用工具和功能。 SQLAlchemy是一个SQL工具包,为关系数据库提供高效和高性能的数据库访问。它提供了与诸如SQLite、MySQL和PostgreSQL等多个数据库引擎进行交互的方式。它为您提供数据库的SQL功能。它还为您提供了一个Object Relational Mapper(ORM),允许您使用简单的Python对象和方法进行查询和处理数据。 Flask-SQLAlchemy是一个Flask扩展,使使用SQLAlchemy与Flask更容易,为您提供工具和方法来与您的Flask应用程序中的数据库
在本教程中,您将使用 Flask 和 Flask-SQLAlchemy 创建具有员工表的数据库的员工管理系统. 每个员工将有一个独特的 ID,姓名,姓名,唯一的电子邮件,年龄的整数值,他们加入公司的那一天的日期,以及一个布尔值来确定员工是否目前活跃或不在职。
您将使用 Flask 壳查询表,并根据列值(例如电子邮件)获取表记录。 您将根据某些条件获取员工记录,例如仅获取活跃员工或获取办公室外员工列表。
前提条件
*本地 Python 3 编程环境. 在 How To Install and Set Up a Local Programming Environment for Python 3 系列中跟随您的分布的教程。 在本教程中,我们将称呼我们的项目目录 flask_app.
- 对基本的 Flask 概念的理解,如路径,视图函数和模板。如果你不熟悉 Flask,请参阅 How to Create First Your Web Application Using Flask and Python 和 How to Use Templates in a Flask Application. 对基本的 HTML 概念的理解。 您可以查看我们的 How to Build a Website with HTML 教程
步骤 1 – 设置数据库和模型
在此步骤中,您将安装必要的包,并设置您的 Flask 应用程序、Flask-SQLAlchemy 数据库和代表员工表的员工模型,您将存储您的员工数据。
首先,随着虚拟环境的启用,安装Flask和Flask-SQLAlchemy:
1pip install Flask Flask-SQLAlchemy
一旦安装完成,您将收到输出,最后有下列行:
1[secondary_label Output]
2
3Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
安装所需的软件包后,请在您的flask_app目录中打开名为app.py的新文件,该文件将包含设置数据库和您的 Flask 路径的代码:
1nano app.py
将此代码设置一个 SQLite 数据库和一个代表你将使用来存储你的员工数据的员工表的员工数据库模型:
1[label flask_app/app.py]
2import os
3from flask import Flask, render_template, request, url_for, redirect
4from flask_sqlalchemy import SQLAlchemy
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8app = Flask(__name__)
9app.config['SQLALCHEMY_DATABASE_URI'] =\
10 'sqlite:///' + os.path.join(basedir, 'database.db')
11app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
12
13db = SQLAlchemy(app)
14
15class Employee(db.Model):
16 id = db.Column(db.Integer, primary_key=True)
17 firstname = db.Column(db.String(100), nullable=False)
18 lastname = db.Column(db.String(100), nullable=False)
19 email = db.Column(db.String(100), unique=True, nullable=False)
20 age = db.Column(db.Integer, nullable=False)
21 hire_date = db.Column(db.Date, nullable=False)
22 active = db.Column(db.Boolean, nullable=False)
23
24 def __repr__(self):
25 return f'<Employee {self.firstname} {self.lastname}>'
保存并关闭文件。
在这里,您将导入 os 模块,它为您提供访问不同的操作系统界面,您将使用它来构建您的 `database.db' 数据库文件的文件路径。
从flask包中,您可以导入应用程序所需的助手:用于创建 Flask 应用程序实例的 Flask 类,用于渲染模板的 render_template(),用于处理请求的 request 对象,用于构建 URL,以及用于重定向用户的 redirect() 功能。
然后,您从 Flask-SQLAlchemy 扩展中导入SQLAlchemy类,该类可以让您访问 SQLAlchemy 的所有函数和类,以及将 Flask 与 SQLAlchemy 集成到 Flask 的助手和功能。
要为您的数据库文件构建路径,您将基础目录定义为当前目录. 您使用 os.path.abspath() 函数获取当前文件目录的绝对路径。 特殊的 __file__ 变量具有当前 app.py 文件的路径名称. 您将基础目录的绝对路径存储在名为 basedir 的变量中。
然后创建一个名为app的Flask应用程序实例,您可以使用它来配置两个Flask-SQLAlchemy 配置密钥:
SQLALCHEMY_DATABASE_URI: 数据库 URI 用于指定您想要建立连接的数据库。在这种情况下, URI 会遵循格式sqlite:///path/to/database.db. 您使用os.path.join()函数来智能地连接您构建并存储在basedir变量中,以database.db文件名。 这将连接到您的flask_app目录中的database.db数据库文件。 该文件将在您启动数据库后创建。- SQL
ALCHEMY_TRACK_MODIFICATIONS: 一个配置允许或禁用对象的修改跟踪。
通过设置数据库 URI 并禁用跟踪来配置 SQLAlchemy 后,您使用SQLAlchemy类创建数据库对象,通过应用程序实例将您的 Flask 应用程序连接到 SQLAlchemy。
设置应用程序实例和数据库对象后,您将继承从db.Model类来创建名为Employee的数据库模型。
id: 员工ID,整数主要密钥.firstname: 员工的姓名,最长为 100 个字符的字符串.nullable=False意味着该列不应空.lastname: 员工的姓名,最长为 100 个字符的字符串。nullable=False意味着该列不应该空。email: 员工的电子邮件,最长为 100 个字符的字符串.unique=True意味着每个电子邮件都应该是唯一的。
特殊的 __repr__ 函数允许您给每个对象一个字符串表示,以便为调试目的识别它。
现在你已经设置了数据库连接和员工模型,你会写一个Python程序来创建你的数据库和员工表,并填充表中一些员工数据。
在您的flask_app目录中打开名为init_db.py的新文件:
1nano init_db.py
添加以下代码来删除现有数据库表,从清洁的数据库开始,创建员工表,并将九名员工插入其中:
1[label flask_app/init_db.py]
2from datetime import date
3from app import db, Employee
4
5db.drop_all()
6db.create_all()
7
8e1 = Employee(firstname='John',
9 lastname='Doe',
10 email='[email protected]',
11 age=32,
12 hire_date=date(2012, 3, 3),
13 active=True
14 )
15
16e2 = Employee(firstname='Mary',
17 lastname='Doe',
18 email='[email protected]',
19 age=38,
20 hire_date=date(2016, 6, 7),
21 active=True
22 )
23
24e3 = Employee(firstname='Jane',
25 lastname='Tanaka',
26 email='[email protected]',
27 age=32,
28 hire_date=date(2015, 9, 12),
29 active=False
30 )
31
32e4 = Employee(firstname='Alex',
33 lastname='Brown',
34 email='[email protected]',
35 age=29,
36 hire_date=date(2019, 1, 3),
37 active=True
38 )
39
40e5 = Employee(firstname='James',
41 lastname='White',
42 email='[email protected]',
43 age=24,
44 hire_date=date(2021, 2, 4),
45 active=True
46 )
47
48e6 = Employee(firstname='Harold',
49 lastname='Ishida',
50 email='[email protected]',
51 age=52,
52 hire_date=date(2002, 3, 6),
53 active=False
54 )
55
56e7 = Employee(firstname='Scarlett',
57 lastname='Winter',
58 email='[email protected]',
59 age=22,
60 hire_date=date(2021, 4, 7),
61 active=True
62 )
63
64e8 = Employee(firstname='Emily',
65 lastname='Vill',
66 email='[email protected]',
67 age=27,
68 hire_date=date(2019, 6, 9),
69 active=True
70 )
71
72e9 = Employee(firstname='Mary',
73 lastname='Park',
74 email='[email protected]',
75 age=30,
76 hire_date=date(2021, 8, 11),
77 active=True
78 )
79
80db.session.add_all([e1, e2, e3, e4, e5, e6, e7, e8, e9])
81
82db.session.commit()
在这里,您将从 datetime模块中导入 date()类以使用它来设置员工聘用日期。
您导入数据库对象和员工模型. 您调用db.drop_all()函数来删除所有现有表,以避免数据库中已经拥有的员工表存在的可能性,这可能导致问题。
然后,您创建多个员工模型实例,代表您将在本教程中查询的员工,并使用db.session.add_all()函数将其添加到数据库会话中。
保存并关闭文件。
运行init_db.py程序:
1python init_db.py
若要查看您添加到数据库的数据,请确保您的虚拟环境已启用,然后打开 Flask 壳以查询所有员工并显示他们的数据:
1flask shell
运行以下代码来查询所有员工并显示他们的数据:
1from app import db, Employee
2
3employees = Employee.query.all()
4
5for employee in employees:
6 print(employee.firstname, employee.lastname)
7 print('Email:', employee.email)
8 print('Age:', employee.age)
9 print('Hired:', employee.hire_date)
10 if employee.active:
11 print('Active')
12 else:
13 print('Out of Office')
14 print('----')
您使用查询属性的all()方法获取所有员工。您循环通过结果,并显示员工信息。对于活跃列,您使用有条件的陈述来显示员工的当前状态,无论是活跃还是离职。
您将收到以下输出:
1[secondary_label Output]
2John Doe
3Email: [email protected]
4Age: 32
5Hired: 2012-03-03
6Active
7----
8Mary Doe
9Email: [email protected]
10Age: 38
11Hired: 2016-06-07
12Active
13----
14Jane Tanaka
15Email: [email protected]
16Age: 32
17Hired: 2015-09-12
18Out of Office
19----
20Alex Brown
21Email: [email protected]
22Age: 29
23Hired: 2019-01-03
24Active
25----
26James White
27Email: [email protected]
28Age: 24
29Hired: 2021-02-04
30Active
31----
32Harold Ishida
33Email: [email protected]
34Age: 52
35Hired: 2002-03-06
36Out of Office
37----
38Scarlett Winter
39Email: [email protected]
40Age: 22
41Hired: 2021-04-07
42Active
43----
44Emily Vill
45Email: [email protected]
46Age: 27
47Hired: 2019-06-09
48Active
49----
50Mary Park
51Email: [email protected]
52Age: 30
53Hired: 2021-08-11
54Active
55----
您可以看到我们添加到数据库的所有员工都正确显示。
离开瓶子壳:
1exit()
接下来,您将创建一个Flask路线,以显示员工。
1nano app.py
添加下列路径到文件的末尾:
1[label flask_app/app.py]
2...
3
4@app.route('/')
5def index():
6 employees = Employee.query.all()
7 return render_template('index.html', employees=employees)
保存并关闭文件。
这将查询所有员工,渲染一个index.html模板,并传递给您收集的员工。
创建一个模板目录和一个 base template:
1mkdir templates
2nano templates/base.html
请在「base.html」中添加以下内容:
1[label flask_app/templates/base.html]
2<!DOCTYPE html>
3<html lang="en">
4<head>
5 <meta charset="UTF-8">
6 <title>{% block title %} {% endblock %} - FlaskApp</title>
7 <style>
8 .title {
9 margin: 5px;
10 }
11
12 .content {
13 margin: 5px;
14 width: 100%;
15 display: flex;
16 flex-direction: row;
17 flex-wrap: wrap;
18 }
19
20 .employee {
21 flex: 20%;
22 padding: 10px;
23 margin: 5px;
24 background-color: #f3f3f3;
25 inline-size: 100%;
26 }
27
28 .name {
29 color: #00a36f;
30 text-decoration: none;
31 }
32
33 nav a {
34 color: #d64161;
35 font-size: 3em;
36 margin-left: 50px;
37 text-decoration: none;
38 }
39
40 .pagination {
41 margin: 0 auto;
42 }
43
44 .pagination span {
45 font-size: 2em;
46 margin-right: 10px;
47 }
48
49 .page-number {
50 color: #d64161;
51 padding: 5px;
52 text-decoration: none;
53 }
54
55 .current-page-number {
56 color: #666
57 }
58
59 </style>
60</head>
61<body>
62 <nav>
63 <a href="{{ url_for('index') }}">FlaskApp</a>
64 <a href="#">About</a>
65 </nav>
66 <hr>
67 <div class="content">
68 {% block content %} {% endblock %}
69 </div>
70</body>
71</html>
保存并关闭文件。
在这里,你使用一个标题块并添加一些CSS风格。你添加了一个Navbar带有两个项目,一个用于索引页面,一个用于一个不活跃的关于页面。这个Navbar将在整个应用程序中重复使用,这些模板将继承从这个基础模板。内容块将被每个页面的内容取代。
接下来,打开您在app.py中渲染的新的index.html模板:
1nano templates/index.html
将以下代码添加到文件中:
1[label flask_app/templates/index.html]
2{% extends 'base.html' %}
3
4{% block content %}
5 <h1 class="title">{% block title %} Employees {% endblock %}</h1>
6 <div class="content">
7 {% for employee in employees %}
8 <div class="employee">
9 <p><b>#{{ employee.id }}</b></p>
10 <b>
11 <p class="name">{{ employee.firstname }} {{ employee.lastname }}</p>
12 </b>
13 <p>{{ employee.email }}</p>
14 <p>{{ employee.age }} years old.</p>
15 <p>Hired: {{ employee.hire_date }}</p>
16 {% if employee.active %}
17 <p><i>(Active)</i></p>
18 {% else %}
19 <p><i>(Out of Office)</i></p>
20 {% endif %}
21 </div>
22 {% endfor %}
23 </div>
24{% endblock %}
在这里,您将循环通过员工并显示每个员工的信息. 如果员工是活跃的,您将添加一个 **(活跃)**标签,否则您将显示一个 **(离职)**标签。
保存并关闭文件。
在您的flask_app目录中启用虚拟环境时,请使用FLASK_APP环境变量告诉Flask关于该应用程序(在这种情况下是app.py) 然后将FLASK_ENV环境变量设置为development,以便在开发模式下运行应用程序并获取调试器的访问。有关Flask调试器的更多信息,请参阅如何处理Flask应用程序中的错误(LINK0)。
1export FLASK_APP=app
2export FLASK_ENV=development
接下来,运行应用程序:
1flask run
当开发服务器运行时,请使用您的浏览器访问以下URL:
1http://127.0.0.1:5000/
您将看到您添加到数据库的员工在一个类似于以下的页面:
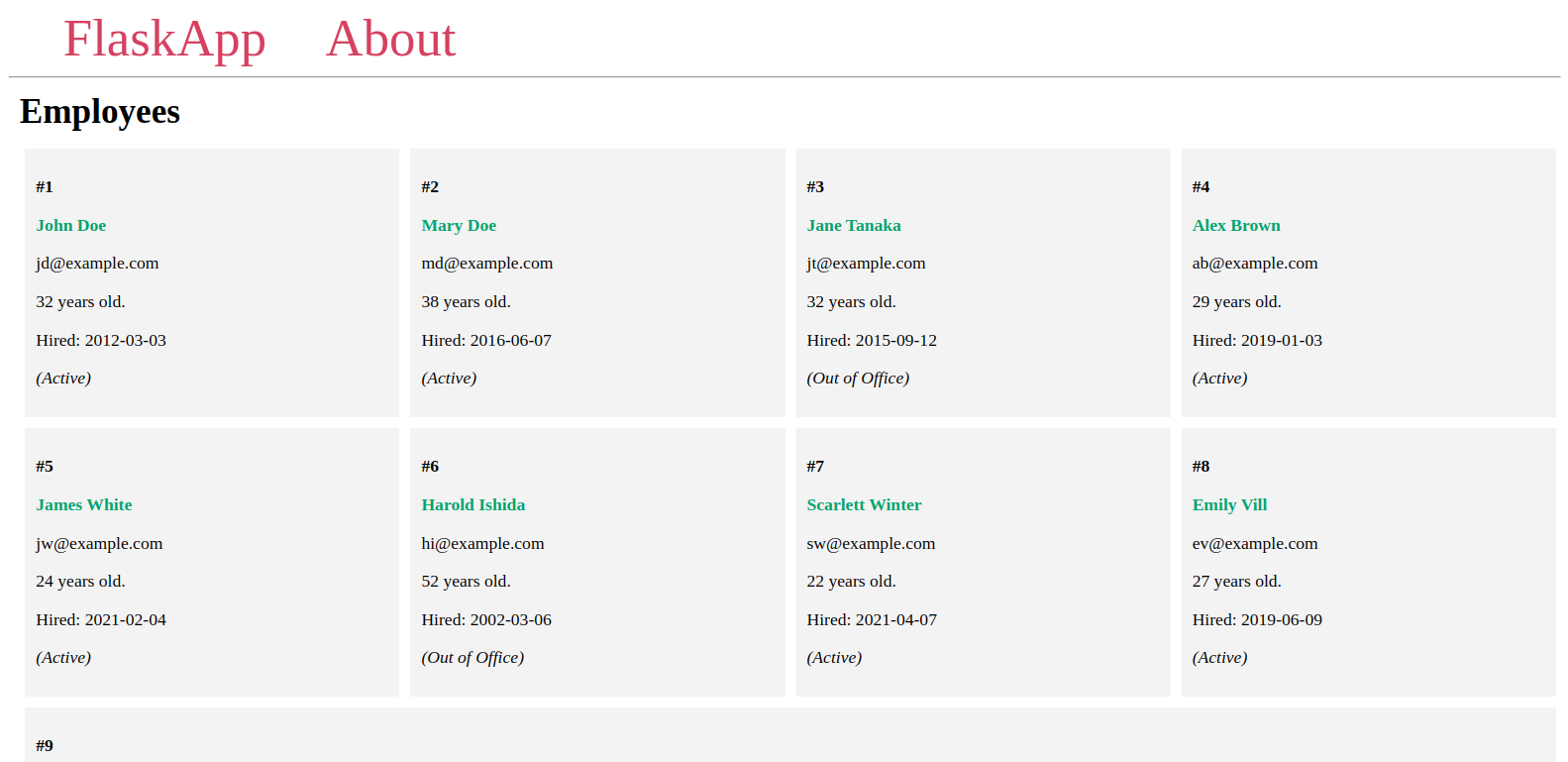
让服务器运行,打开另一个终端,然后继续到下一步。
您已经在索引页面上显示了数据库中的员工,接下来,您将使用 Flask 壳以使用不同的方法查询员工。
步骤2 - 寻求记录
在此步骤中,您将使用 Flask 壳来查询记录,并使用多个方法和条件过滤和检索结果。
启用您的编程环境时,设置FLASK_APP和FLASK_ENV变量,然后打开Flask壳:
1export FLASK_APP=app
2export FLASK_ENV=development
3flask shell
输入db对象和员工模型:
1from app import db, Employee
恢复所有记录
如前一步所示,您可以在查询属性上使用all()方法获取表中的所有记录:
1all_employees = Employee.query.all()
2print(all_employees)
输出将是代表所有员工的对象列表:
1[secondary_label Output]
2
3[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
恢复第一个纪录
同样,您可以使用first()方法来获取第一个记录:
1first_employee = Employee.query.first()
2print(first_employee)
输出将是一个包含第一个员工数据的对象:
1[secondary_label Output]
2<Employee John Doe>
通过 ID 获取记录
在大多数数据库表中,记录被识别为一个独特的ID。Flask-SQLAlchemy允许您使用其ID以get()方法获取记录:
1employee5 = Employee.query.get(5)
2employee3 = Employee.query.get(3)
3print(f'{employee5} | ID: {employee5.id}')
4print(f'{employee3} | ID: {employee3.id}')
1[secondary_label Output]
2<Employee James White> | ID: 5
3<Employee Jane Tanaka> | ID: 3
通过列值检索记录或多个记录
若要使用其中一个列的值获取记录,请使用 filter_by() 方法. 例如,若要使用其 ID 值获取记录,类似于 get() 方法:
1employee = Employee.query.filter_by(id=1).first()
2print(employee)
1[secondary_label Output]
2<Employee John Doe>
您使用first(),因为filter_by()可能会返回多个结果。
<$>[注]
注: 若要用 ID 获取记录,使用 get() 方法是更好的方法。
另一个例子是,你可以根据他们的年龄获得一名员工:
1employee = Employee.query.filter_by(age=52).first()
2print(employee)
1[secondary_label Output]
2<Employee Harold Ishida>
例如,如果查询结果包含多个匹配记录,请使用姓氏列和玛丽姓氏,这是两个员工共享的姓氏:
1mary = Employee.query.filter_by(firstname='Mary').all()
2print(mary)
1[secondary_label Output]
2[<Employee Mary Doe>, <Employee Mary Park>]
在这里,您可以使用all()来获取完整列表,也可以使用first()来获取只有第一个结果:
1mary = Employee.query.filter_by(firstname='Mary').first()
2print(mary)
1[secondary_label Output]
2<Employee Mary Doe>
您通过列值收集了记录,接下来,您将使用逻辑条件查询您的表。
步骤 3 – 使用逻辑条件过滤记录
在复杂、功能齐全的 Web 应用程序中,您通常需要使用复杂的条件来查询数据库中的记录,例如根据考虑其位置、可用性、角色和职责的条件组合来查找员工。在此步骤中,您将使用条件操作员来练习使用条件操作员。在查询属性上,您将使用filter()方法来过滤查询结果,使用不同操作员的逻辑条件。
平等
您可以使用的最简单的逻辑运算符是平等运算符 ==,该运算符以类似的方式运作于 filter_by(). 例如,要获取在 firstname 列值为 Mary 的所有记录,您可以使用 filter() 方法:
1mary = Employee.query.filter(Employee.firstname == 'Mary').all()
2print(mary)
在这里,您将使用语法 Model.column == 值 作为对 filter() 方法的参数。
结果与同一条件的 filter_by() 方法的结果相同:
1[secondary_label Output]
2[<Employee Mary Doe>, <Employee Mary Park>]
像「filter_by()」一樣,您也可以使用「first()」方法來獲得第一個結果:
1mary = Employee.query.filter(Employee.firstname == 'Mary').first()
2print(mary)
1[secondary_label Output]
2<Employee Mary Doe>
不平等
filter() 方法允许您使用 != Python 运算器来获取记录. 例如,要获取办公室外员工列表,您可以使用以下方法:
1out_of_office_employees = Employee.query.filter(Employee.active != True).all()
2print(out_of_office_employees)
1[secondary_label Output]
2[<Employee Jane Tanaka>, <Employee Harold Ishida>]
在这里,您使用Employee.active!= True条件来过滤结果。
少于
您可以使用<运算符来获取一个记录,该列的值小于该值,例如,要获取32岁以下员工的列表:
1employees_under_32 = Employee.query.filter(Employee.age < 32).all()
2
3for employee in employees_under_32:
4 print(employee.firstname, employee.lastname)
5 print('Age: ', employee.age)
6 print('----')
1[secondary_label Output]
2
3Alex Brown
4Age: 29
5----
6James White
7Age: 24
8----
9Scarlett Winter
10Age: 22
11----
12Emily Vill
13Age: 27
14----
15Mary Park
16Age: 30
17----
使用 <= 运算符的记录小于或等于给定的值. 例如,要在上一个查询中包括 32 岁的员工:
1employees_32_or_younger = Employee.query.filter(Employee.age <=32).all()
2
3for employee in employees_32_or_younger:
4 print(employee.firstname, employee.lastname)
5 print('Age: ', employee.age)
6 print('----')
1[secondary_label Output]
2
3John Doe
4Age: 32
5----
6Jane Tanaka
7Age: 32
8----
9Alex Brown
10Age: 29
11----
12James White
13Age: 24
14----
15Scarlett Winter
16Age: 22
17----
18Emily Vill
19Age: 27
20----
21Mary Park
22Age: 30
23----
大于
类似地,>运算器会收到一个记录,其中某个列的值大于该值,例如,要获得员工超过32岁:
1employees_over_32 = Employee.query.filter(Employee.age > 32).all()
2
3for employee in employees_over_32:
4 print(employee.firstname, employee.lastname)
5 print('Age: ', employee.age)
6 print('----')
1[secondary_label Output]
2Mary Doe
3Age: 38
4----
5Harold Ishida
6Age: 52
7----
并且 >= 运算符适用于大于或等于给定的值的记录,例如,您可以再次将 32 岁的员工列入上一个查询中:
1employees_32_or_older = Employee.query.filter(Employee.age >=32).all()
2
3for employee in employees_32_or_older:
4 print(employee.firstname, employee.lastname)
5 print('Age: ', employee.age)
6 print('----')
1[secondary_label Output]
2
3John Doe
4Age: 32
5----
6Mary Doe
7Age: 38
8----
9Jane Tanaka
10Age: 32
11----
12Harold Ishida
13Age: 52
14----
在
SQLAlchemy 还提供了一种方法来获取记录,其中列的值匹配给定的值列表中的值,使用列上的 in_() 方法,如下:
1names = ['Mary', 'Alex', 'Emily']
2employees = Employee.query.filter(Employee.firstname.in_(names)).all()
3print(employees)
1[secondary_label Output]
2[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
在这里,您使用的语法为Model.column.in-(iterable)的条件,其中iterable是任何类型的 object you can iterate through。 另一个例子是,您可以使用range() Python 函数来获取特定年龄段的员工。
1employees_in_30s = Employee.query.filter(Employee.age.in_(range(30, 40))).all()
2for employee in employees_in_30s:
3 print(employee.firstname, employee.lastname)
4 print('Age: ', employee.age)
5 print('----')
1[secondary_label Output]
2John Doe
3Age: 32
4----
5Mary Doe
6Age: 38
7----
8Jane Tanaka
9Age: 32
10----
11Mary Park
12Age: 30
13----
不是在
类似于in_()方法,您可以使用not_in()方法来获取列值不在给定的迭代值的记录:
1names = ['Mary', 'Alex', 'Emily']
2employees = Employee.query.filter(Employee.firstname.not_in(names)).all()
3print(employees)
1[secondary_label Output]
2
3[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
在这里,你可以找到所有员工,除了那些在名字列表中有一个名字的员工。
和
您可以使用 db.and_() 函数一起加入多个条件,该函数与 Python 的 and 运算器相似。
例如,假设您想要获得目前活跃的所有32岁的员工,首先,您可以使用filter_by()方法检查谁是32(如果您想要的话,您也可以使用filter()方法):
1for employee in Employee.query.filter_by(age=32).all():
2 print(employee)
3 print('Age:', employee.age)
4 print('Active:', employee.active)
5 print('-----')
1[secondary_label Output]
2<Employee John Doe>
3Age: 32
4Active: True
5-----
6<Employee Jane Tanaka>
7Age: 32
8Active: False
9-----
在这里,你可以看到约翰和简是32岁的员工,约翰是活跃的,简是退役的。
要获得 32 个 **和 ** 活跃的员工,您将使用两个条件使用 filter() 方法:
Employee.age == 32Employee.active == True
若要将这两个条件合并在一起,请使用db.and_()函数如下:
1active_and_32 = Employee.query.filter(db.and_(Employee.age == 32,
2 Employee.active == True)).all()
3print(active_and_32)
1[secondary_label Output]
2[<Employee John Doe>]
在这里,您使用的语法是 filter(db.and_condition1, condition2)。
在查询中使用 all() 将返回符合两个条件的所有记录的列表. 您可以使用 first() 方法获取第一个结果:
1active_and_32 = Employee.query.filter(db.and_(Employee.age == 32,
2 Employee.active == True)).first()
3print(active_and_32)
1[secondary_label Output]
2<Employee John Doe>
对于一个更复杂的示例,您可以使用db.and_()和date()函数来获取在特定时间段内被聘用的员工。
1from datetime import date
2
3hired_in_2019 = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2019, month=1, day=1), Employee.hire_date < date(year=2020, month=1, day=1))).all()
4
5for employee in hired_in_2019:
6 print(employee, ' | Hired: ', employee.hire_date)
1[secondary_label Output]
2<Employee Alex Brown> | Hired: 2019-01-03
3<Employee Emily Vill> | Hired: 2019-06-09
在这里,您导入date()函数,然后使用db.and_()函数过滤结果,将以下两个条件结合起来:
Employee.hire_date >=日期(年=2019,月=1,日=1):此为2019年1月1日或更晚招聘的员工的True:此为2020年1月1日前招聘的员工的True
结合这两个条件,将从2019年第一天和2020年第一天之前雇佣的员工获得。
或
类似于db.and_(),db.or_()函数结合了两种条件,并且在Python中表现得像or操作员一样。
1employees_32_or_52 = Employee.query.filter(db.or_(Employee.age == 32, Employee.age == 52)).all()
2
3for e in employees_32_or_52:
4 print(e, '| Age:', e.age)
1[secondary_label Output]
2<Employee John Doe> | Age: 32
3<Employee Jane Tanaka> | Age: 32
4<Employee Harold Ishida> | Age: 52
您还可以使用 startswith() 和 endswith() 方法在字符串值上,如果您转到 filter() 方法,例如,要获取所有以字符串 'M' 开头的员工和以字符串 'e' 结束的姓氏的员工:
1employees = Employee.query.filter(db.or_(Employee.firstname.startswith('M'), Employee.lastname.endswith('e'))).all()
2
3for e in employees:
4 print(e)
1[secondary_label Output]
2<Employee John Doe>
3<Employee Mary Doe>
4<Employee James White>
5<Employee Mary Park>
在这里,你结合了以下两个条件:
Employee.firstname.startswith('M'):匹配以 `'M'开始的姓氏的员工。Employee.lastname.endswith('e'):匹配以 `'e'结束的姓氏的员工。
现在,您可以在 Flask-SQLAlchemy 应用程序中使用逻辑条件过滤查询结果,然后将排序、限制和计算您从数据库中获得的结果。
步骤 4 – 排序,限制和计数结果
例如,您可能有一个页面显示每个部门的最新招聘,以便让其他团队知道新招聘,或者您可以通过显示最古老的招聘先来订购员工,以识别长期雇佣员工。
订购结果
若要使用特定列的值来排序结果,请使用 order_by() 方法,例如,以员工的姓名排序结果:
1employees = Employee.query.order_by(Employee.firstname).all()
2print(employees)
1[secondary_label Output]
2[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
正如输出显示的那样,结果按员工的姓名按字母顺序排序。
您可以按其他列进行排序. 例如,您可以使用姓名来排序员工:
1employees = Employee.query.order_by(Employee.lastname).all()
2print(employees)
1[secondary_label Output]
2[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
您也可以按雇佣日期订购员工:
1em_ordered_by_hire_date = Employee.query.order_by(Employee.hire_date).all()
2
3for employee in em_ordered_by_hire_date:
4 print(employee.firstname, employee.lastname, employee.hire_date)
1[secondary_label Output]
2
3Harold Ishida 2002-03-06
4John Doe 2012-03-03
5Jane Tanaka 2015-09-12
6Mary Doe 2016-06-07
7Alex Brown 2019-01-03
8Emily Vill 2019-06-09
9James White 2021-02-04
10Scarlett Winter 2021-04-07
11Mary Park 2021-08-11
正如输出显示的那样,这个订单结果从最早的租赁到最新的租赁. 要逆转订单并使其从最新的租赁降至最早的租赁,使用 desc() 方法如下:
1em_ordered_by_hire_date_desc = Employee.query.order_by(Employee.hire_date.desc()).all()
2
3for employee in em_ordered_by_hire_date_desc:
4 print(employee.firstname, employee.lastname, employee.hire_date)
1[secondary_label Output]
2Mary Park 2021-08-11
3Scarlett Winter 2021-04-07
4James White 2021-02-04
5Emily Vill 2019-06-09
6Alex Brown 2019-01-03
7Mary Doe 2016-06-07
8Jane Tanaka 2015-09-12
9John Doe 2012-03-03
10Harold Ishida 2002-03-06
您还可以将 order_by() 方法与 filter() 方法相结合,以排序过滤的结果。
1from datetime import date
2hired_in_2021 = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2021, month=1, day=1), Employee.hire_date < date(year=2022, month=1, day=1))).order_by(Employee.age).all()
3
4for employee in hired_in_2021:
5 print(employee.firstname, employee.lastname,
6 employee.hire_date, '| Age', employee.age)
1[secondary_label Output]
2Scarlett Winter 2021-04-07 | Age 22
3James White 2021-02-04 | Age 24
4Mary Park 2021-08-11 | Age 30
在这里,您使用的db.and_()函数有两种条件:Employee.hire_date >=日期(年份=2021,月份=1,日期=1)对于在2021年或之后的第一天招聘的员工,以及Employee.hire_date <日期(年份=2022,月份=1,日期=1)对于在2022年第一天之前招聘的员工。
限制结果
在大多数真实情况下,在查询数据库表时,您可能会收到数百万个匹配的结果,有时需要将结果限制到某个数字。
1employees = Employee.query.limit(3).all()
2print(employees)
1[secondary_label Output]
2[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
您可以使用limit()与其他方法,如过滤和order_by,例如,您可以使用limit()方法这样招聘2021年的最后两个员工:
1from datetime import date
2hired_in_2021 = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2021, month=1, day=1), Employee.hire_date < date(year=2022, month=1, day=1))).order_by(Employee.age).limit(2).all()
3
4for employee in hired_in_2021:
5 print(employee.firstname, employee.lastname,
6 employee.hire_date, '| Age', employee.age)
1[secondary_label Output]
2Scarlett Winter 2021-04-07 | Age 22
3James White 2021-02-04 | Age 24
在这里,您将使用上一节中的相同查询,并使用额外的限制(2)方法调用。
计数结果
要计算查询结果的数目,可以使用count()方法,例如,以获取当前在数据库中的员工数目:
1employee_count = Employee.query.count()
2print(employee_count)
1[secondary_label Output]
29
您可以将count()方法与类似于limit()的其他查询方法相结合,例如,要获取2021年雇佣的员工数量:
1from datetime import date
2hired_in_2021_count = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2021, month=1, day=1), Employee.hire_date < date(year=2022, month=1, day=1))).order_by(Employee.age).count()
3print(hired_in_2021_count)
1[secondary_label Output]
23
在这里,您使用之前使用的相同查询来获取2021年招聘的所有员工。
您已在 Flask-SQLAlchemy 中排序、限制和计数查询结果,接下来,您将学习如何将查询结果分成多个页面,以及如何在 Flask 应用程序中创建页面系统。
步骤 5 – 在多个页面上显示长记录列表
在此步骤中,您将更改主路径,使索引页面在多个页面上显示员工,以便更容易导航员工列表。
首先,您将使用 Flask shell 查看如何在 Flask-SQLAlchemy 中使用页面化功能的演示。
1flask shell
假设您想要将表中的员工记录分成多个页面,每个页面有两个项目,您可以使用paginate()查询方法这样做:
1page1 = Employee.query.paginate(page=1, per_page=2)
2print(page1)
3print(page1.items)
1[secondary_label Output]
2<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80>
3[<Employee John Doe>, <Employee Mary Doe>]
您使用page查询方法的page参数来指定您想要访问的页面,这在这种情况下是第一个页面。per_page参数指定每个页面必须有多少项目。
这里的page1变量是 _pagination 对象,它为您提供访问您将使用的属性和方法来管理您的页面。
您可以使用项目属性访问页面的项目。
要访问下一个页面,您可以使用页面对象的 next() 方法,因此返回的结果也是页面对象:
1page2 = page1.next()
2
3print(page2.items)
4print(page2)
1[secondary_label Output]
2[<Employee Jane Tanaka>, <Employee Alex Brown>]
3
4<flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
在下面的示例中,您可以访问第四页的页面对象,然后访问其上一页的页面对象,即第三页:
1page4 = Employee.query.paginate(page=4, per_page=2)
2print(page4.items)
3page3 = page4.prev()
4print(page3.items)
1[secondary_label Output]
2[<Employee Scarlett Winter>, <Employee Emily Vill>]
3
4[<Employee James White>, <Employee Harold Ishida>]
您可以使用页面属性访问当前页面号码,如下:
1print(page1.page)
2print(page2.page)
1[secondary_label Output]
21
32
若要获取页面总数,请使用页面对象的页面属性. 在下面的示例中,无论是page1.pages还是page2.pages都返回相同的值,因为页面总数是常数:
1print(page1.pages)
2print(page2.pages)
1[secondary_label Output]
25
35
对于项目总数,使用页面化对象的总属性:
1print(page1.total)
2print(page2.total)
1[secondary_label Output]
29
39
在这里,由于您查询所有员工,页面化中的项目总数为9个,因为数据库中有9名员工。
以下是页面化对象具有的其他属性:
prev_num:前一页的号码.next_num:下一页的号码.has_next:true如果有下一页,has_prev:true如果有前一页。
页面化对象还具有一个iter_pages()方法,您可以通过它来访问页面号码,例如,您可以这样打印所有页面号码:
1pagination = Employee.query.paginate(page=1, per_page=2)
2
3for page_num in pagination.iter_pages():
4 print(page_num)
1[secondary_label Output]
21
32
43
54
65
以下是如何使用页面对象和 iter_pages() 方法访问所有页面及其项目的演示:
1pagination = Employee.query.paginate(page=1, per_page=2)
2
3for page_num in pagination.iter_pages():
4 print('PAGE', pagination.page)
5 print('-')
6 print(pagination.items)
7 print('-'*20)
8 pagination = pagination.next()
1[secondary_label Output]
2
3PAGE 1
4-
5[<Employee John Doe>, <Employee Mary Doe>]
6--------------------
7PAGE 2
8-
9[<Employee Jane Tanaka>, <Employee Alex Brown>]
10--------------------
11PAGE 3
12-
13[<Employee James White>, <Employee Harold Ishida>]
14--------------------
15PAGE 4
16-
17[<Employee Scarlett Winter>, <Employee Emily Vill>]
18--------------------
19PAGE 5
20-
21[<Employee Mary Park>]
22--------------------
在这里,您创建一个从第一页开始的页面对象. 您通过页面循环使用for循环使用iter_pages()页面编码方法. 您打印页面号和页面项目,并使用next()方法将pagination对象设置为其下一页的页面编码对象。
您还可以使用 filter() 和 order_by() 方法使用 paginate() 方法来页面化过滤和排序查询结果,例如,您可以获得 30 岁以上的员工,并按年龄排序结果,并页面化结果:
1pagination = Employee.query.filter(Employee.age > 30).order_by(Employee.age).paginate(page=1, per_page=2)
2
3for page_num in pagination.iter_pages():
4 print('PAGE', pagination.page)
5 print('-')
6 for employee in pagination.items:
7 print(employee, '| Age: ', employee.age)
8 print('-'*20)
9 pagination = pagination.next()
1[secondary_label Output]
2PAGE 1
3-
4<Employee John Doe> | Age: 32
5<Employee Jane Tanaka> | Age: 32
6--------------------
7PAGE 2
8-
9<Employee Mary Doe> | Age: 38
10<Employee Harold Ishida> | Age: 52
11--------------------
现在你对Flask-SQLAlchemy中的页面化工作有很好的了解,你将编辑你的应用程序的索引页面,以便在多个页面上显示员工,以便更容易导航。
离开瓶子壳:
1exit()
若要访问不同的页面,您将使用 URL 参数,也称为 URL 查询字符串,它们是通过 URL 将信息传递给应用程序的一种方式。
1http://127.0.0.1:5000/?page=1
2http://127.0.0.1:5000/?page=3
在这里,第一个URL将值1传递给URL参数页面;第二个URL将值3传递给同一个参数。
打开app.py文件:
1nano app.py
编辑索引路径以显示如下:
1@app.route('/')
2def index():
3 page = request.args.get('page', 1, type=int)
4 pagination = Employee.query.order_by(Employee.firstname).paginate(
5 page, per_page=2)
6 return render_template('index.html', pagination=pagination)
在这里,您可以使用request.args对象及其get()方法获取页面 URL 参数的值,例如/?page=1将从页面 URL 参数中获取1值,您将1作为默认值,并将int Python 类型作为参数传递给type参数,以确保该值是整数。
接下来,您创建一个页面化对象,以第一名排序查询结果. 您将页面 URL 参数值传递到页面化()方法,并通过将值2传递到每页参数,将结果分成每页两个项目。
最后,您将您构建的页面化对象传输到渲染的index.html模板中。
保存并关闭文件。
接下来,编辑index.html模板以显示页面项目:
1nano templates/index.html
通过添加一个h2标题来更改内容div标签,标注当前页面,并更改for循环通过pagination.items对象而不是员工对象,该对象不再可用:
1<div class="content">
2 <h2>(Page {{ pagination.page }})</h2>
3 {% for employee in pagination.items %}
4 <div class="employee">
5 <p><b>#{{ employee.id }}</b></p>
6 <b>
7 <p class="name">{{ employee.firstname }} {{ employee.lastname }}</p>
8 </b>
9 <p>{{ employee.email }}</p>
10 <p>{{ employee.age }} years old.</p>
11 <p>Hired: {{ employee.hire_date }}</p>
12 {% if employee.active %}
13 <p><i>(Active)</i></p>
14 {% else %}
15 <p><i>(Out of Office)</i></p>
16 {% endif %}
17 </div>
18 {% endfor %}
19</div>
保存并关闭文件。
如果您还没有,请设置FLASK_APP和FLASK_ENV环境变量,并运行开发服务器:
1export FLASK_APP=app
2export FLASK_ENV=development
3flask run
现在,导航到具有不同值的页面URL参数的索引页面:
1http://127.0.0.1:5000/
2http://127.0.0.1:5000/?page=2
3http://127.0.0.1:5000/?page=4
4http://127.0.0.1:5000/?page=19
您将看到不同的页面,每个页面都有两个项目,每个页面都有不同的项目,就像您之前在Flask壳中看到的那样。
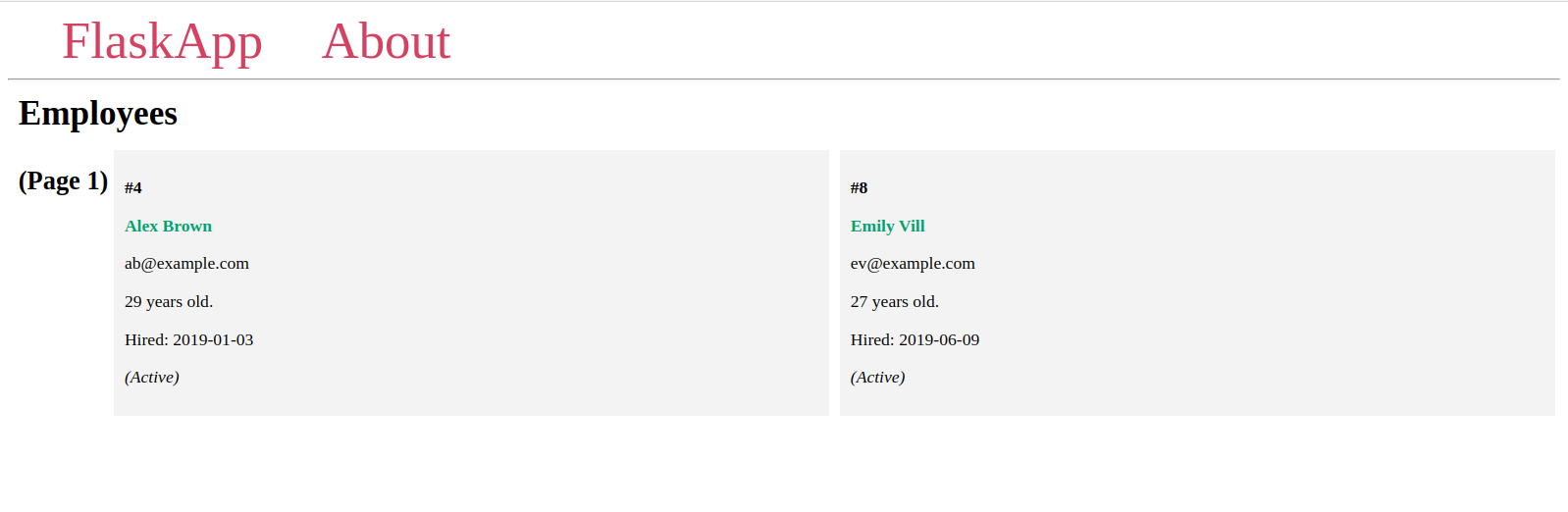
如果给定的页面号码没有退出,你会收到一个404 Not Found HTTP 错误,这是上一个 URL 列表中的最后一个 URL 的情况。
接下来,您将创建一个页面化 widget 来导航页面之间,您将使用页面化对象的几个属性和方法来显示所有页面号码,每个数字链接到其专用页面,以及一个<<<按钮,如果当前页面有以前的页面,然后一个>>>按钮,如果它存在的话,可以转到下一个页面。
Pagination Widget 将如下:
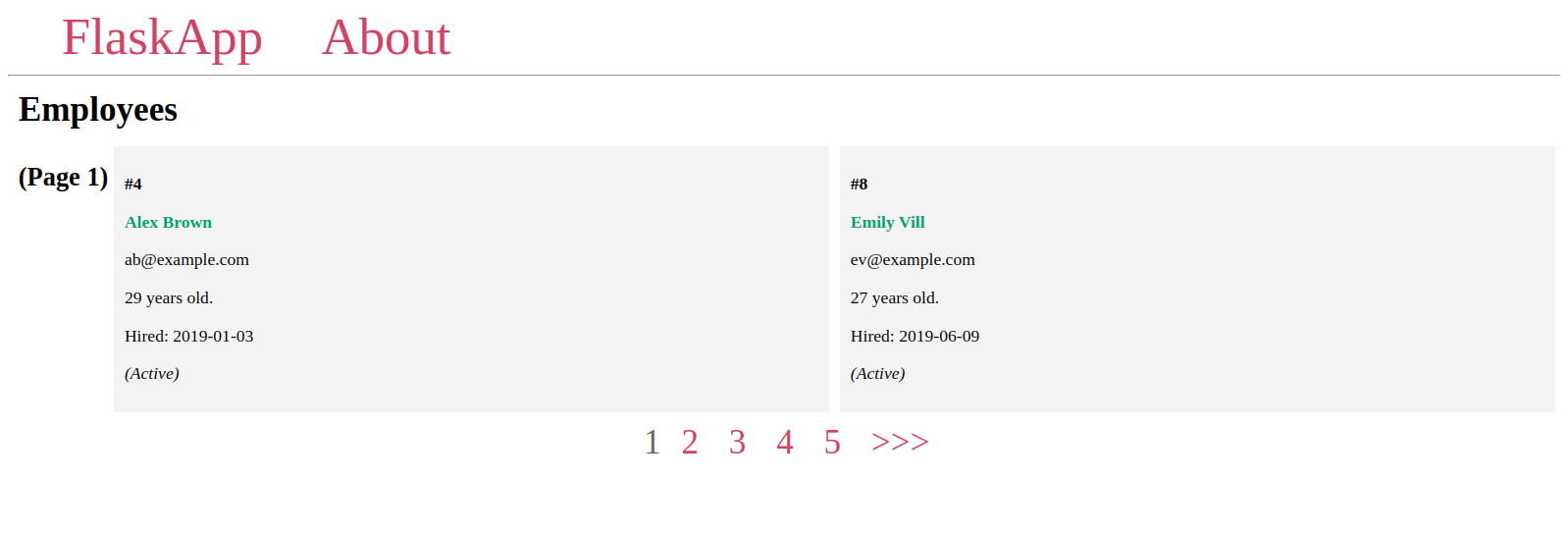
要添加它,请打开index.html:
1nano templates/index.html
通过在内容div标签下方添加以下突出div标签来编辑文件:
1[label flask_app/templates/index.html]
2<div class="content">
3 {% for employee in pagination.items %}
4 <div class="employee">
5 <p><b>#{{ employee.id }}</b></p>
6 <b>
7 <p class="name">{{ employee.firstname }} {{ employee.lastname }}</p>
8 </b>
9 <p>{{ employee.email }}</p>
10 <p>{{ employee.age }} years old.</p>
11 <p>Hired: {{ employee.hire_date }}</p>
12 {% if employee.active %}
13 <p><i>(Active)</i></p>
14 {% else %}
15 <p><i>(Out of Office)</i></p>
16 {% endif %}
17 </div>
18 {% endfor %}
19</div>
20
21<div class="pagination">
22 {% if pagination.has_prev %}
23 <span>
24 <a class='page-number' href="{{ url_for('index', page=pagination.prev_num) }}">
25 {{ '<<<' }}
26 </a>
27 </span>
28 {% endif %}
29
30 {% for number in pagination.iter_pages() %}
31 {% if pagination.page != number %}
32 <span>
33 <a class='page-number'
34 href="{{ url_for('index', page=number) }}">
35 {{ number }}
36 </a>
37 </span>
38 {% else %}
39 <span class='current-page-number'>{{ number }}</span>
40 {% endif %}
41 {% endfor %}
42
43 {% if pagination.has_next %}
44 <span>
45 <a class='page-number'
46 href="{{ url_for('index', page=pagination.next_num) }}">
47 {{ '>>>' }}
48 </a>
49 </span>
50 {% endif %}
51</div>
保存并关闭文件。
在这里,您使用条件 if pagination.has_prev 将一个 <<< 链接添加到之前的页面,如果当前页面不是第一个页面. 您使用函数调用 url_for('index', page=pagination.prev_num) 链接到之前的页面,在此您将链接到索引视图函数,将 pagination.prev_num 值传递到 page URL 参数。
要显示所有可用的页面号码的链接,您可以循环通过pagination.iter_pages()方法的项目,该方法为您提供每个环节的页面号码。
如果条件是真的,你将链接到页面,以允许用户更改当前页面到另一个页面。否则,如果当前页面与循环号相同,你会显示无链接的数字。
最后,您使用pagination.has_next条件查看当前页面是否有下一个页面,在这种情况下,您使用url_for('index', page=pagination.next_num)呼叫和>>>链接链接链接到它。
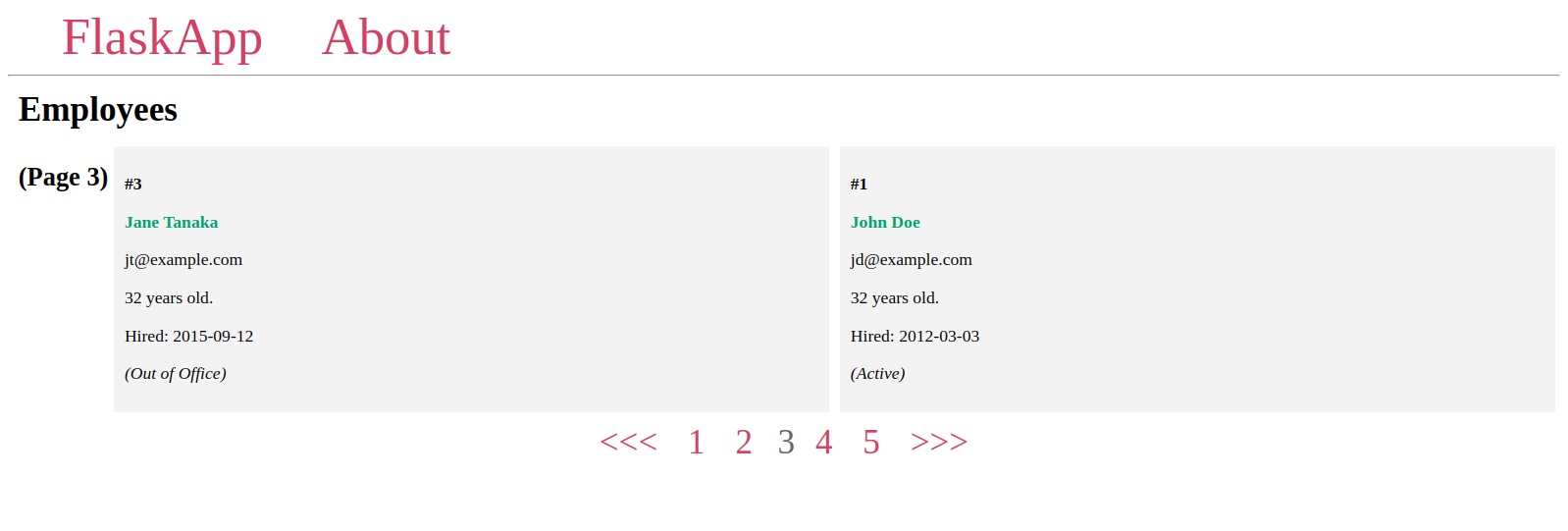
导航到您的浏览器中的索引页面: http://127.0.0.1:5000/
您将看到 Pagination 视图完全功能:
在这里,您可以使用>>>移动到下一页和<<<移动到上一页,但您也可以使用您想要的任何其他字符,例如>和<或<img>标签中的图像。
您已经在多个页面上显示了员工,并学会了如何在 Flask-SQLAlchemy 中处理页面化,现在您可以在您构建的其他 Flask 应用程序上使用页面化小工具。
结论
您使用 Flask-SQLAlchemy 创建了一个员工管理系统. 您查询了一个表,并根据列值和简单和复杂的逻辑条件过滤结果. 您订购,计算和限制查询结果。
您可以将本教程中学到的内容与我们其他Flask-SQLAlchemy教程中解释的概念结合使用,为您的员工管理系统增加更多功能:
- 如何使用Flask-SQLAlchemy来与Flask应用程序中的数据库互动 学习如何添加、编辑或删除员工。
- 如何使用Flask-SQLAlchemy的多对一数据库关系 学习如何使用一对多关系创建部门表,将每个员工链接到他们所属的部门。
如果您想了解更多关于 Flask 的信息,请参阅 如何使用 Flask 构建 Web 应用程序系列的其他教程。