從 Prometheus共同創造者Julius Volz的文章
介绍
Prometheus 是一个开源监控系统和时间序列数据库,Prometheus 最重要的方面之一是其多维数据模型以及随附的查询语言,该查询语言允许您切割和拼写您的尺寸数据,以便以一次性方式回答操作问题,在仪表板中显示趋势,或生成系统故障警告。
在本教程中,我们将学习如何查询 Prometheus 1.3.1 以便有合适的示例数据来工作,我们将设置三个相同的演示服务实例,以出口各种类型的合成指标。
在本教程之后,您将知道如何根据其尺寸选择和过滤时间序列,汇总和转换时间序列,以及如何在不同的指标之间进行算法。
前提条件
要遵循本教程,您将需要:
- 一个 Ubuntu 14.04 服务器通过遵循 Ubuntu 14.04 初始服务器安装指南设置,包括一个 sudo 非 root 用户。
步骤 1 – 安装 Prometheus
在此步骤中,我们将下载、配置和运行Prometheus服务器来扫描三个(尚未运行)演示服务实例。
首先,下载 Prometheus:
1wget https://github.com/prometheus/prometheus/releases/download/v1.3.1/prometheus-1.3.1.linux-amd64.tar.gz
提取塔尔巴尔:
1tar xvfz prometheus-1.3.1.linux-amd64.tar.gz
在主机文件系统上创建一个最小的 Prometheus 配置文件在 ~/prometheus.yml:
1nano ~/prometheus.yml
将以下内容添加到文件中:
1[label ~/prometheus.yml]
2# Scrape the three demo service instances every 5 seconds.
3global:
4 scrape_interval: 5s
5
6scrape_configs:
7 - job_name: 'demo'
8 static_configs:
9 - targets:
10 - 'localhost:8080'
11 - 'localhost:8081'
12 - 'localhost:8082'
保存和退出Nano。
此示例配置使 Prometheus 扫描演示实例. Prometheus 使用拉动模型工作,这就是为什么它需要进行配置,以了解从中抽取指标的终端。
使用nohup开始Prometheus,并作为背景过程:
1nohup ./prometheus-1.3.1.linux-amd64/prometheus -storage.local.memory-chunks=10000 &
命令开始时的nohup将输出发送到文件~/nohup.out而不是stdout。命令结束时的&将允许过程在背景中继续运行,同时为您提供额外命令的提示。
如果一切顺利,在~/nohup.out文件中,你应该看到类似于以下的输出:
1[label Output from starting Prometheus]
2time="2016-11-23T03:10:33Z" level=info msg="Starting prometheus (version=1.3.1, branch=master, revision=be476954e80349cb7ec3ba6a3247cd712189dfcb)" source="main.go:75"
3time="2016-11-23T03:10:33Z" level=info msg="Build context (go=go1.7.3, user=root@37f0aa346b26, date=20161104-20:24:03)" source="main.go:76"
4time="2016-11-23T03:10:33Z" level=info msg="Loading configuration file prometheus.yml" source="main.go:247"
5time="2016-11-23T03:10:33Z" level=info msg="Loading series map and head chunks..." source="storage.go:354"
6time="2016-11-23T03:10:33Z" level=info msg="0 series loaded." source="storage.go:359"
7time="2016-11-23T03:10:33Z" level=warning msg="No AlertManagers configured, not dispatching any alerts" source="notifier.go:176"
8time="2016-11-23T03:10:33Z" level=info msg="Starting target manager..." source="targetmanager.go:76"
9time="2016-11-23T03:10:33Z" level=info msg="Listening on :9090" source="web.go:240"
在另一个终端中,您可以使用命令tail -f ~/nohup.out监控该文件的内容,当内容写入文件时,它将显示到终端。
默认情况下,Prometheus将从prometheus.yml下载其配置(我们刚刚创建)并将其指标数据存储在当前工作目录中的./data中。
在本教程中,-storage.local.memory-chunks旗帜将Prometheus的内存使用量调整为主机系统的非常小数量的RAM(仅有 512MB)和少量的存储时间序列。
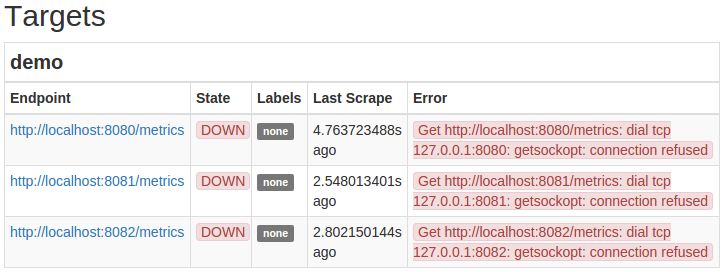
您现在应该能够访问您的 Prometheus 服务器在 http://your_server_ip:9090/. 检查它是否配置以从三个演示实例中收集指标,转到 http://your_server_ip:9090/status,并在目标部分中找到演示`任务的三个目标终端。
步骤 2:安装 demo 实例
在本节中,我们将安装和运行三个演示服务实例。
下载 demo 服务:
1wget https://github.com/juliusv/prometheus_demo_service/releases/download/0.0.4/prometheus_demo_service-0.0.4.linux-amd64.tar.gz
提取它:
1tar xvfz prometheus_demo_service-0.0.4.linux-amd64.tar.gz
在单独的端口上运行三次演示服务:
1./prometheus_demo_service -listen-address=:8080 &
2./prometheus_demo_service -listen-address=:8081 &
3./prometheus_demo_service -listen-address=:8082 &
他们不会记录任何东西,但他们会在各自的端口上暴露Prometheus指标的/metricsHTTP终端。
这些演示服务对几个模拟子系统出口合成指标,这些是:
- HTTP API 服务器暴露请求计数和延迟(按路径、方法和响应状态代码进行关键)
- 定期批量工作暴露其最后成功运行的时间标记和处理字节的数量
- 关于 CPU 数量及其使用情况的合成指标
- 关于磁盘总大小及其使用情况的合成指标
单个指标在后面的部分中的查询示例中引入。
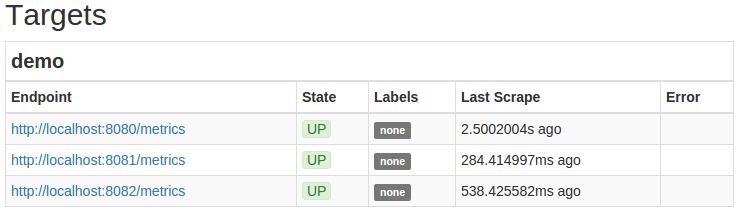
Prometheus 服务器现在应该自动开始扫描您的三个演示实例。 转到您的 Prometheus 服务器的状态页面,点击http://your_server_ip:9090/status,并验证演示任务的目标现在显示一个 UP状态:
步骤 3 – 使用 Query 浏览器
在此步骤中,我们将熟悉 Prometheus 内置的查询和图形 Web 接口. 虽然这个接口非常适合临时数据探索和学习 Prometheus 查询语言,但不适合构建持久仪表板,也不支持先进的可视化功能。
在您的 Prometheus 服务器上,点击 http://your_server_ip:9090/graph。它应该看起来像这样:
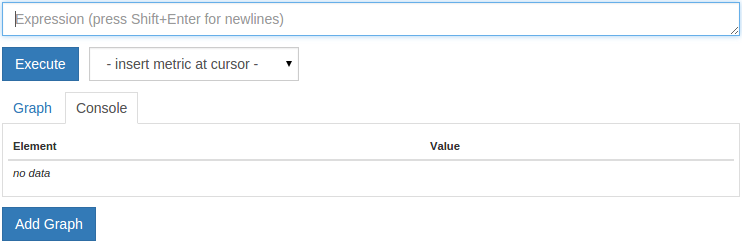
正如您所看到的,有两个选项卡: 图表和 控制台. Prometheus 允许您以两种不同的方式查询数据:
- Console 卡允许您在当前时间对查询表达式进行评估.在运行查询后,一个表将显示每个结果时间序列的当前值(每个输出序列为一行表)。
由于 Prometheus 可以扩展到数百万个时间序列,所以可以构建非常昂贵的查询(认为这类似于在 SQL 数据库中从一个大表中选择所有行)。
一旦你已经足够缩小了查询(在选择的序列上,它需要执行的计算,以及输出时间序列的数量),你可以切换到 ** 图表** 选项卡,以显示经过评估的表达式。
由于我们的测试 Prometheus 服务器不会扫描大量数据,我们实际上不会能够在本教程中制定任何昂贵的查询。
若要缩小或增加图表的时间范围,请点击 - 或 + 按钮。 若要移动图表的结束时间,请点击 < 或 >> 按钮。 您可以通过激活 stacked 检查框来堆积图表。 最后, Res. (s) 输入允许您指定自定义查询分辨率(本教程不需要)。
步骤 4 – 执行简单的时间系列查询
在我们开始查询之前,让我们快速审查普罗米修斯的数据模型和术语。普罗米修斯基本上将所有数据存储为时间序列。每个时间序列都由一个计量名称,以及普罗米修斯称之为 labels 的关键值对的一组。计量名称表示系统的整体方面(例如,自过程启动以来处理的 HTTP 请求的数量,http_requests_total)。标签用来区分 HTTP 方法(例如,method="POST``)或路径(例如,path="/api/foo`)。
例如,演示服务导出一个指数 demo_api_request_duration_seconds_count,它代表了模糊服务处理的合成 API HTTP 请求的数量。你可能会想知道为什么指数名包含字符串 duration_seconds. 这是因为这个计数器是名为 demo_api_request_duration_seconds 的较大的历史学指数的一部分,该指数主要跟踪请求持续时间的分布,但还显示了被跟踪请求的总数(由 _count在这里补充)作为一个有用的副产品。
请确保选中 Console 查询选项卡,在页面顶部的文本字段中输入以下查询,然后单击 Execute 按钮执行查询:
1demo_api_request_duration_seconds_count
由于 Prometheus 正在监控三个服务实例,您应该看到一个表输出,其中包含 27 个随后产生的时间序列,其中包含这个计量名称,每个被跟踪的服务实例、路径、HTTP 方法和 HTTP 状态代码每一个。
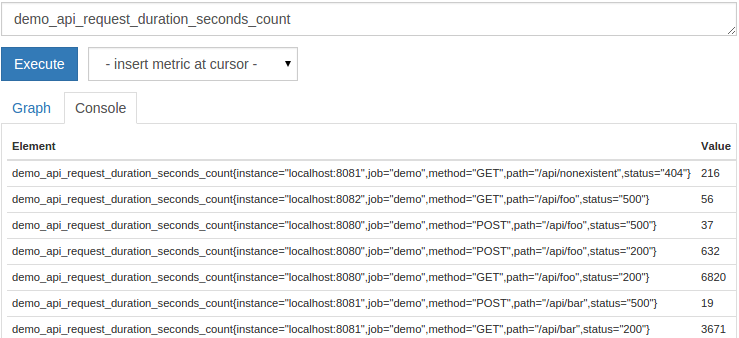
在右侧的表列中显示的数值是每个时间序列的当前值. 请自由地绘制输出(单击图表**选项卡,然后再单击执行**选项卡)以查看这个和随后的查询,以便看到值随着时间的推移而如何发展。
现在我们可以添加标签匹配者,以限制基于标签返回的序列。标签匹配者可以直接跟随弯曲的标签中的计量名称。在最简单的形式中,它们会过滤给给定标签有准确值的序列。
1demo_api_request_duration_seconds_count{method="GET"}
例如,我们还可以过滤仅从例子 localhost:8080 和任务 demo 的指标:
1demo_api_request_duration_seconds_count{instance="localhost:8080",method="GET",job="demo"}
结果将是这样的:
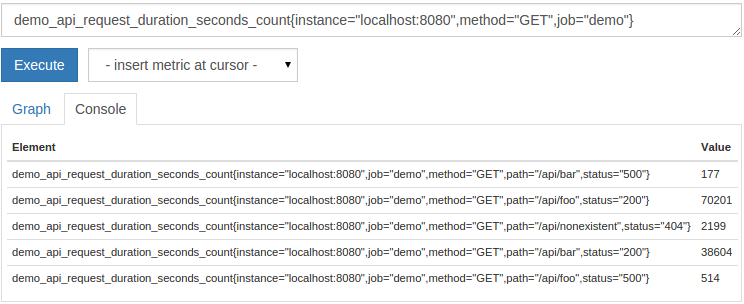
在组合多个匹配者时,所有匹配者都需要匹配以选择一个系列。上面的表达式只返回在端口 8080 上运行的服务实例的 API 请求计数,并且HTTP 方法是GET。
<$>[注]
注:在选择时间序列时,建议始终指定工作标签,这确保您不会意外从不同的工作中选择具有相同名称的指标(除非,当然,这确实是您的目标!).虽然我们在本教程中仅监控一个工作,但我们仍将在下面的大多数例子中根据工作名称进行选择,以强调这种做法的重要性。
除了平等匹配,Prometheus 还支持非平等匹配(!=),规律表达匹配(=~),以及负规律表达匹配(!~)。 您还可以使用标签匹配完全排除指标名称,并且仅使用查询。
1{path=~"/api.*"}
上面的正规表达式需要用.*结束,因为正规表达式在Prometheus中总是匹配一个完整的字符串。
由此产生的时间序列将是具有不同指标名称的序列的混合物:
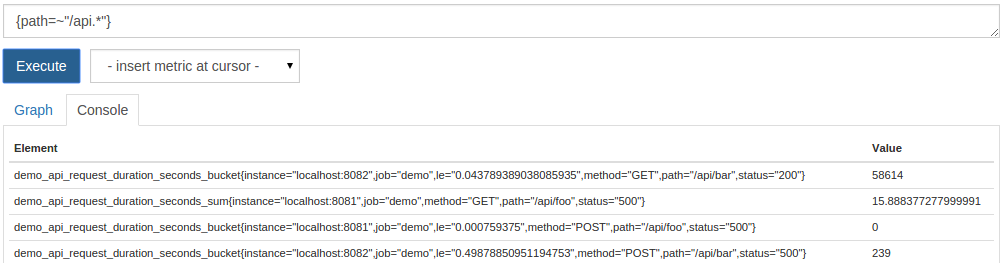
现在你知道如何根据他们的指标名称以及标签值的组合来选择时间序列。
第5步:计算利率和其他衍生品
在本节中,我们将学习如何按时计算指数的利率或德尔塔。
在 Prometheus 中,您将使用的最常见的功能之一是rate()。而不是直接在仪表服务中计算事件率,在 Prometheus 中通常使用原始计数来跟踪事件,并允许 Prometheus 服务器在查询时间内随时计算率(这具有许多优点,例如在查询时间内不丢失率峰值,以及在查询时间内能够选择动态平均窗口)。 计数器在监控服务开始时从0开始,并在服务流程的寿命中不断增加。
1demo_api_request_duration_seconds_count{job="demo"}
它将看起来有点像这样的:
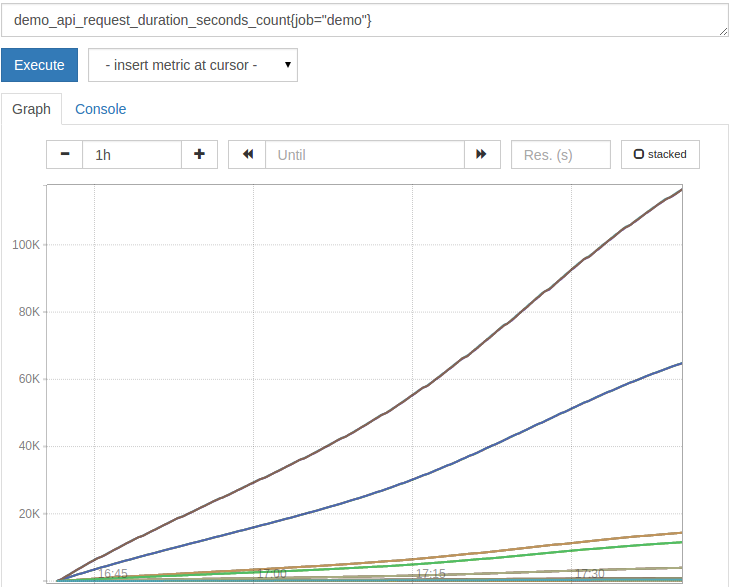
为了使计时器有用,我们可以使用 rate() 函数来计算它们的 per-second 增加率。我们需要告诉 rate() 在哪个时间窗口中平均速度,通过提供系列匹配之后的范围选择器(如 [5m])。
1rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
结果现在更有用:
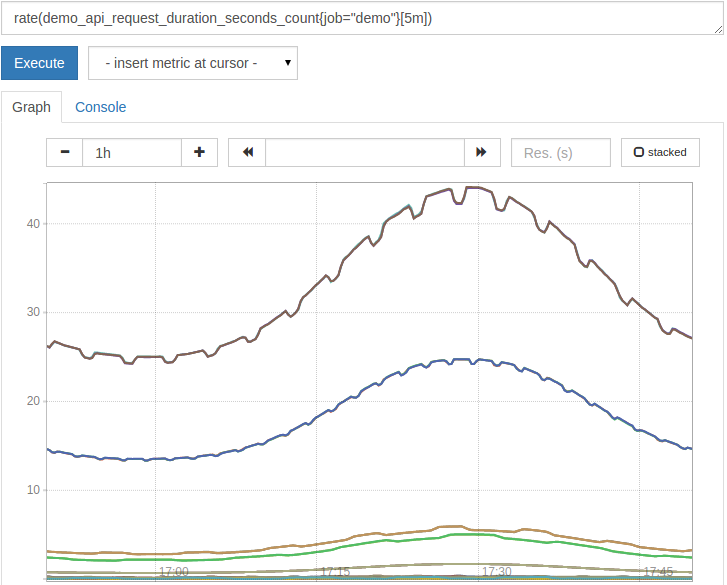
rate() 是智能的,并通过假设对应值的任何减少是重置来自动调整对应重置。
一个变体的 rate()是 irate().虽然 rate() 平均了给定的时间窗口中的所有样本的速度(在这种情况下是五分钟), irate() 只会回顾过去的两个样本。它仍然要求你指定一个时间窗口(如 [5m])来知道如何最大限度地回顾这两个样本的时间。 irate() 会更快地响应值变化,因此通常建议在图表中使用。
使用irate(),上面的图表看起来像这样,揭示了请求率中的短暂间歇性下降:
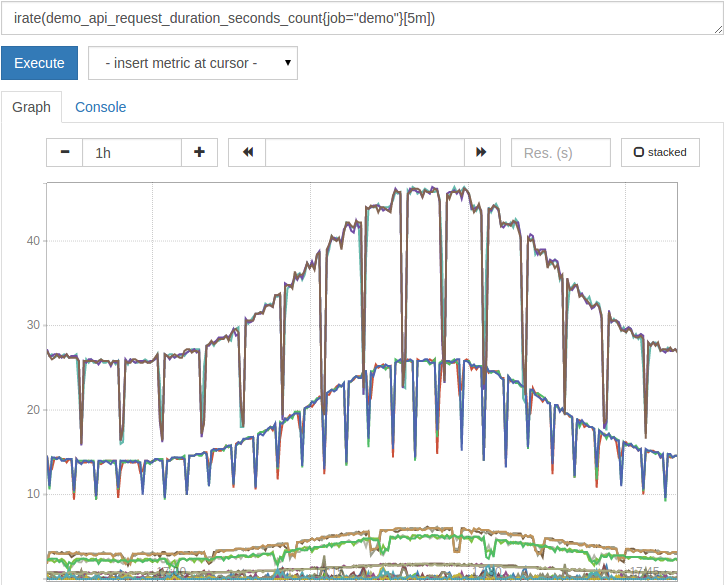
rate() 和 irate() 总是计算一个 per-second 率。有时你会想知道一个计时器在一个时间窗口增加的 total amount,但仍然正确的计时器重置。
1increase(demo_api_request_duration_seconds_count{job="demo"}[1h])
除了计数(只能增加)之外,还有计数指数。计数是可以随着时间的推移上升或下降的值,如温度或自由磁盘空间。如果我们想计算计数在时间的推移中的变化,我们不能使用 rate()/irate()/increase() 函数家族。这些都针对计数,因为它们将计数值的任何下降解释为计数重置并补偿它。相反,我们可以使用 deriv() 函数,该函数根据线性回归计算计的每秒衍生品。
例如,根据过去 15 分钟的线性回归,我们可以查询由我们的演示服务导出的虚构磁盘使用率增加或下降的速度(每秒 MiB)。
1deriv(demo_disk_usage_bytes{job="demo"}[15m])
结果应该是这样的:
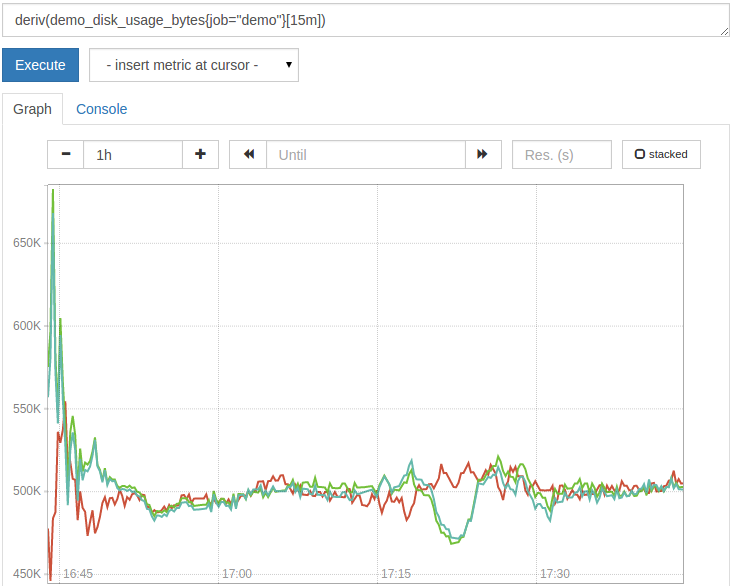
若要了解更多有关测量指标中的分数和趋势的计算,请参阅 delta() 和 predict_linear() 函数。
现在我们知道如何计算不同平均行为的每秒利率,如何在利率计算中处理计数重置,以及如何计算指标的衍生品。
步骤 6 - 汇总时间系列
在本节中,我们将学习如何汇总单个系列。
Prometheus 会以高维度的细节收集数据,这可能会导致每个指标名称出现许多序列。然而,你通常不关心所有维度,甚至可能有太多的序列以合理的方式绘制它们。 解决方案是在某些维度上汇总,并只保留你关心的维度。 例如,演示服务会根据方法,路径和状态跟踪 API HTTP 请求。 Prometheus 在从 Node Exporter 扫描该指标时,会添加额外的维度:跟踪指标的实例和工作标签。 现在,要查看所有维度的总请求率,我们可以使用sum()汇总操作员:
1sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
但是,这会汇总 all 维度,并创建一个单一的输出序列:
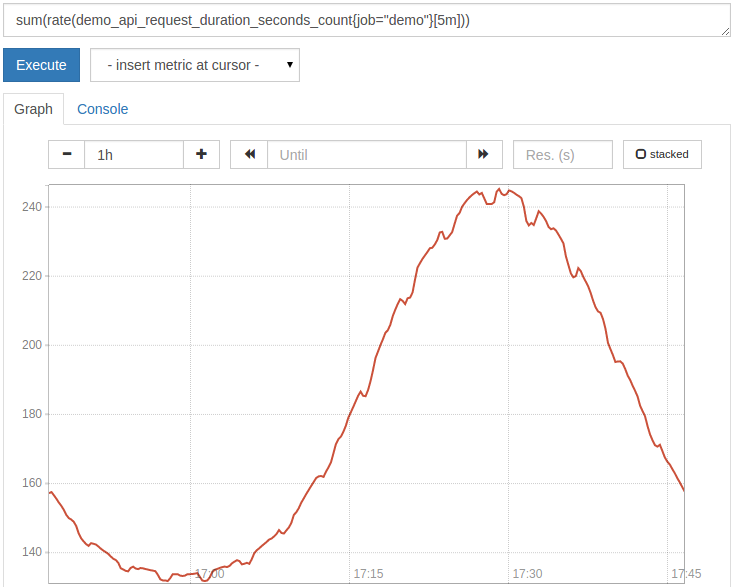
通常情况下,你会想要在输出中保留 some 的尺寸。 为此,‘sum()’ 和其他聚合器支持一个‘没有(
1sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
这相当于:
1sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
由此产生的总和现在由实例、路径和工作组成:
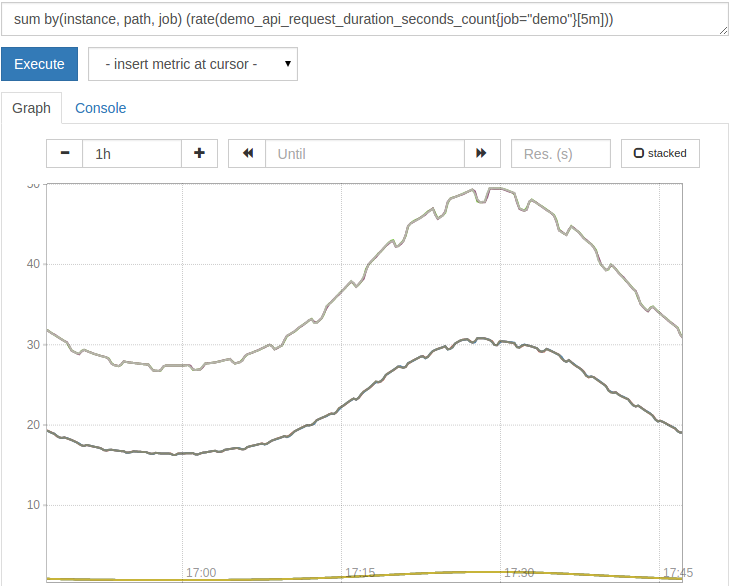
<$>[注]
注:在应用任何集合之前,始终计算 rate()、 irate() 或 increase()。
Prometheus 支持以下聚合操作员,每个操作员都支持by()或without()条款来选择要保存的维度:
sum:在集合组内所有值的总和min:在集合组内所有值的最小值的选择max:在集合组内所有值的最大值的选择avg:计算集合组内所有值的平均值(计数平均值)stddev:计算集合组内的所有值的 标准偏差stdvar:计算集合组内所有值的 标准偏差- `数:计算集合组内系列的总数。
现在你已经学会了如何汇总一个系列列表,以及如何只保留你关心的尺寸。
步骤7 - 执行算法
在本节中,我们将学习如何在普罗米修做算法。
作为最简单的算法示例,您可以使用 Prometheus 作为一个数字计算器,例如,在 Console 视图中运行以下查询:
1(4 + 7) * 3
您将获得单个33的尺度输出值:
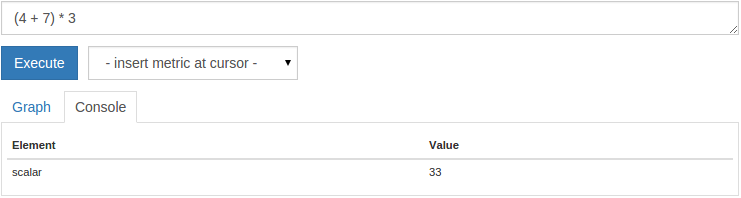
一个尺度值是一个简单的数值,没有任何标签. 为了使这一点更有用,Prometheus 允许您将常见的算术运算符(+, -, *, /, `%')应用到整个时间序列向量。
1demo_batch_last_run_processed_bytes{job="demo"} / 1024 / 1024
结果将在MIB中显示:
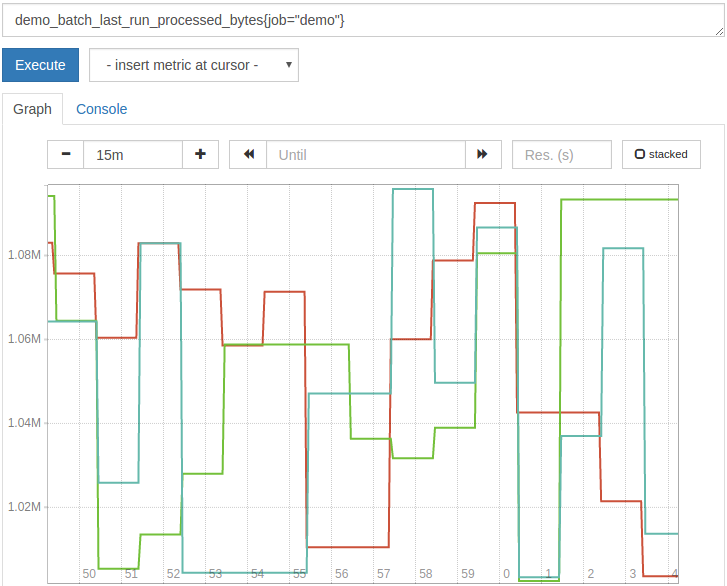
对于这些类型的单位转换,通常使用简单的算法,尽管良好的可视化工具(如Grafana)也为您处理转换。
Prometheus 的一个特征(以及 Prometheus 真正闪耀的地方!)是两组时间序列之间的二进制算法。当 Prometheus 使用两组序列之间的二进制运算器时,Prometheus 会自动匹配操作的左侧和右侧相同标签集的元素,并将运算器应用于每个匹配的对,以产生输出序列。
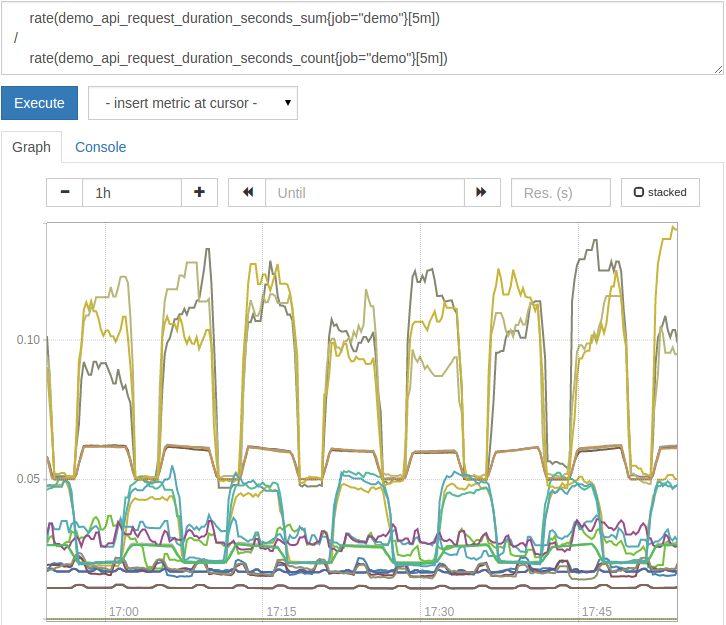
例如,demo_api_request_duration_seconds_sum指标告诉我们回答 HTTP 请求花了多少秒钟,而demo_api_request_duration_seconds_count指标告诉我们有多少 HTTP 请求。
1rate(demo_api_request_duration_seconds_sum{job="demo"}[5m])
2/
3 rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
请注意,我们还围绕操作的每一侧包装了rate()函数,以仅考虑在过去5分钟内发生的请求的延迟。
结果的平均请求延迟图应该是这样的:
但是,当标签在两侧不完全匹配时,我们会怎么做呢?这尤其会发生在操作两侧有不同的时间序列时,因为一侧的尺寸比另一侧多。例如,演示任务将在各种模式(‘idle’、‘user’、‘system’)中花费的虚构CPU时间导出为demo_cpu_usage_seconds_total标签尺寸的指标。它还将作为demo_num_cpus的虚构CPU总数导出(在这个指标上没有额外的尺寸)。
1# BAD!
2 # Multiply by 100 to get from a ratio to a percentage
3 rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
4/
5 demo_num_cpus{job="demo"}
在这些一对多或多对一匹配中,我们需要告诉Prometheus使用哪个标签子集来匹配,我们还需要说明如何处理额外的维度。为了解决匹配,我们将一个on(<label names>)条款添加到二进制操作器中,该条款指出了要匹配的标签。 为了对较大侧额外维度的个别值进行计算,我们添加一个group_left(<label names>)或group_right(<label names>)条款,分别列出左侧或右侧额外维度。
在这种情况下,正确的查询将是:
1# Multiply by 100 to get from a ratio to a percentage
2 rate(demo_cpu_usage_seconds_total{job="demo"}[5m]) * 100
3/ on(job, instance) group_left(mode)
4 demo_num_cpus{job="demo"}
结果应该是这样的:
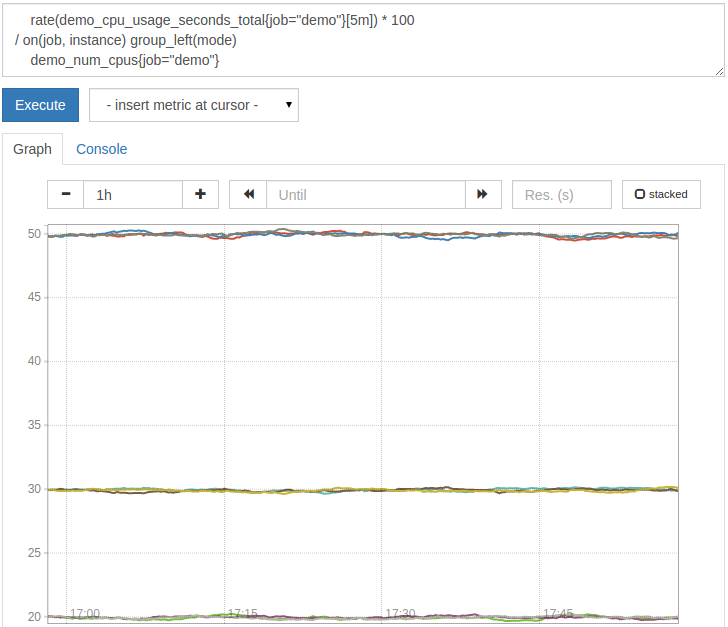
「on(job, instance)」告訴操作員只在他們的「job」和「instance」標籤上從左邊和右邊匹配系列(而不是在右邊不存在的「mode」標籤上),而「group_left(mode)」條款告訴操作員開啟並顯示每個模式的CPU使用平均值。
现在你知道如何在时间序列的集合之间使用算法,以及如何处理不同维度。
结论
在本教程中,我们设置了一组演示服务实例,并通过Prometheus监控它们,然后我们学会了如何对收集的数据应用各种查询技术,以回答我们关心的问题。你现在知道如何选择和过滤系列,如何对尺寸进行汇总,以及如何计算率或衍生品或做算法。
若要了解有关 Prometheus 查询语言的更多信息,包括如何从历史图计算百分位,如何处理基于时刻印的指标,或如何查询服务实例健康,请访问 [如何在 Ubuntu 14.04 部分 2] 上查询 Prometheus(LINK0))。