介绍
TICK Stack是时间序列数据库 InfluxDB的开发者的产品集合,由以下组件组成:
- Telegraf从各种来源收集时间序列数据。
- InfluxDB存储时间序列数据。
- Chronograf可可视化和绘制时间序列数据。
您可以单独使用这些组件,但如果一起使用它们,您将拥有可扩展的集成开源系统来处理时间序列数据。
在本教程中,您将设置和使用这个平台作为一个开源监控系统,您将产生一些CPU使用率,并在使用率过高时收到电子邮件警告。
前提条件
在你开始之前,你需要以下几点:
- 一台 CentOS 7 服务器通过遵循 CentOS 7 初始服务器设置指南设置,包括一个 sudo 非根用户和防火墙。
- 如果您希望按照步骤 7 所述来保护 Chronograf 用户界面,则需要一个 GitHub帐户,该帐户是 GitHub 组织的一部分。
步骤 1 – 添加 TICK Stack 存储库
所有 TICK 堆栈组件都使用相同的存储库,所以我们将设置一个存储库配置文件以使安装顺畅。
创建这个新文件:
1sudo vi /etc/yum.repos.d/influxdata.repo
在新文件中放置下列配置:
1[label /etc/yum.repos.d/influxdata.repo]
2[influxdb]
3name = InfluxData Repository - RHEL $releasever
4baseurl = https://repos.influxdata.com/rhel/$releasever/$basearch/stable
5enabled = 1
6gpgcheck = 1
7gpgkey = https://repos.influxdata.com/influxdb.key
保存文件并离开编辑器. 现在我们可以安装和配置 InfluxDB
步骤 2 — 安装 InfluxDB 和配置身份验证
InfluxDB 是一个开源数据库,用于快速、高可用性存储和检索时间序列数据。
运行以下命令来安装 InfluxDB:
1sudo yum install influxdb
在安装过程中,您将被要求导入 GPG 密钥. 确认您希望导入此密钥,以便继续安装。
安装完成后,启动 InfluxDB 服务:
1sudo systemctl start influxdb
然后确保服务正常运行:
1systemctl status influxdb
您将看到以下状态,确认该服务正在运行:
1[secondary_label Output
2 ● influxdb.service - InfluxDB is an open-source, distributed, time series database
3 Loaded: loaded (/usr/lib/systemd/system/influxdb.service; enabled; vendor preset: disabled)
4 Active: active (running) since Tue 2017-02-07 13:19:31 EET; 2min 46s ago
5 Docs: https://docs.influxdata.com/influxdb/
6 Main PID: 14290 (influxd)
InfluxDB 正在运行,但您需要启用用户身份验证来限制访问数据库。
启动 InfluxDB 控制台:
1influx
我们将创建一个sammy用户与密码sammy_admin,但你可以使用任何你想要的。
1CREATE USER "sammy" WITH PASSWORD 'sammy_admin' WITH ALL PRIVILEGES
检查用户是否已创建:
1show users
您将看到以下输出,验证您的用户是创建的:
1[secondary_label Output]
2 user admin
3 ---- -----
4 sammy true
现在用户已经存在,请退出 InfluxDB 控制台:
1exit
现在在您的编辑器中打开文件 /etc/influxdb/influxdb.conf 这是 InfluxDB 的配置文件。
1sudo vi /etc/influxdb/influxdb.conf
查找[http]部分,删除auth-enabled选项,并将其值设置为true:
1[label /etc/influxdb/influxdb.conf]
2...
3 [http]
4 # Determines whether HTTP endpoint is enabled.
5 # enabled = true
6
7 # The bind address used by the HTTP service.
8 # bind-address = ":8086"
9
10 # Determines whether HTTP authentication is enabled.
11 auth-enabled = true
12...
然后保存文件,离开编辑器,并重新启动 InfluxDB 服务:
1sudo systemctl restart influxdb
InfluxDB 现在已配置,所以让我们安装 Telegraf,一个用于收集指标的代理。
步骤 3 – 安装和配置电报
Telegraf 是一个开源代理,收集所运行系统或其他服务上的指标和数据,然后将数据写入 InfluxDB 或其他输出。
运行以下命令来安装 Telegraf:
1sudo yum install telegraf
Telegraf 使用插件输入和输出数据. 默认输出插件用于 InfluxDB. 由于我们已启用了 IndexDB 的用户身份验证,我们必须修改 Telegraf 的配置文件,以指定我们已配置的用户名和密码。
1sudo vi /etc/telegraf/telegraf.conf
查找[outputs.influxdb]部分,并提供用户名和密码:
1[label /etc/telegraf/telegraf.conf]
2 [[outputs.influxdb]]
3 ## The full HTTP or UDP endpoint URL for your InfluxDB instance.
4 ## Multiple urls can be specified as part of the same cluster,
5 ## this means that only ONE of the urls will be written to each interval.
6 # urls = ["udp://localhost:8089"] # UDP endpoint example
7 urls = ["http://localhost:8086"] # required
8 ## The target database for metrics (telegraf will create it if not exists).
9 database = "telegraf" # required
10
11 ...
12
13 ## Write timeout (for the InfluxDB client), formatted as a string.
14 ## If not provided, will default to 5s. 0s means no timeout (not recommended).
15 timeout = "5s"
16 username = "sammy"
17 password = "sammy_admin"
18 ## Set the user agent for HTTP POSTs (can be useful for log differentiation)
19 # user_agent = "telegraf"
20 ## Set UDP payload size, defaults to InfluxDB UDP Client default (512 bytes)
21 # udp_payload = 512
保存文件,离开编辑器,并启动 Telegraf:
1sudo systemctl start telegraf
然后检查服务是否正常运行:
1systemctl status telegraf
您将看到以下状态,表示 Telegraf 正在运行。
1[secondary_label Output]
2 ● telegraf.service - The plugin-driven server agent for reporting metrics into InfluxDB
3 Loaded: loaded (/usr/lib/systemd/system/telegraf.service; enabled; vendor preset: disabled)
4 Active: active (running) since Tue 2017-02-07 13:32:36 EET; 3min 27s ago
5 Docs: https://github.com/influxdata/telegraf
6 Main PID: 14412 (telegraf)
Telegraf 现在正在收集数据并将其写入 InfluxDB. 让我们打开 InfluxDB 控制台,看看 Telegraf 在数据库中存储哪些测量。
1influx -username 'sammy' -password 'sammy_admin'
一旦登录,执行此命令查看可用的数据库:
1show databases
您将看到输出中列出的电报数据库:
1[secondary_label Output]
2 name: databases
3 name
4 ----
5 _internal
6 telegraf
<$>[注意]
注意:如果您看不到电报数据库,请检查您配置的电报设置,以确保您已指定正确的用户名和密码。
让我们看看 Telegraf 在该数据库中存储了什么。 执行以下命令来切换到 Telegraf 数据库:
1use telegraf
显示通过执行此命令收集的各种测量:
1show measurements
您将看到以下输出:
1[secondary_label Output]
2 name: measurements
3 name
4 ----
5 cpu
6 disk
7 diskio
8 kernel
9 mem
10 processes
11 swap
12 system
正如你所看到的,Telegraf在这个数据库中收集和存储了大量信息。
它可以从许多流行的服务和数据库中收集指标,包括:
- Apache
- Cassandra
- Docker
- Elasticsearch
- Graylog
- IPtables
- MySQL
- PostgreSQL
- Redis
- SNMP
- and many others
您可以通过在终端窗口中运行telegraf -usage plugin-name来查看每个输入插件的使用说明。
退出 InfluxDB 控制台:
1exit
现在我们知道Telegraf正在存储测量,让我们设置Kapacitor来处理数据。
步骤4:安装容量
Kapacitor 是一个数据处理引擎. 它允许您插入自己的自定义逻辑来处理与动态门槛的警报,匹配模式的指标,或识别统计异常。
运行以下命令来安装 Kapacitor:
1sudo yum install kapacitor
在您的编辑器中打开 Kapacitor 配置文件:
1sudo vi /etc/kapacitor/kapacitor.conf
查找[influxdb]部分,并提供用户名和密码连接到 InfluxDB 数据库:
1[label /etc/kapacitor/kapacitor.conf]
2# Multiple InfluxDB configurations can be defined.
3# Exactly one must be marked as the default.
4# Each one will be given a name and can be referenced in batch queries and InfluxDBOut nodes.
5[[influxdb]]
6 # Connect to an InfluxDB cluster
7 # Kapacitor can subscribe, query and write to this cluster.
8 # Using InfluxDB is not required and can be disabled.
9 enabled = true
10 default = true
11 name = "localhost"
12 urls = ["http://localhost:8086"]
13 username = "sammy"
14 password = "sammy_admin"
15...
保存文件,离开编辑器,并启动 Kapacitor:
1sudo systemctl daemon-reload
2sudo systemctl start kapacitor
现在让我们验证 Kapacitor 是否正在运行. 使用以下命令检查 Kapacitor 的任务列表:
1kapacitor list tasks
如果 Kapacitor 已启动并运行,您将看到一个空的任务列表,如下:
1[secondary_label Output]
2 ID Type Status Executing Databases and Retention Policies
随着 Kapacitor 安装和配置,让我们安装 TICK 堆栈的用户界面组件,这样我们就可以看到一些结果并配置一些警报。
步骤 5 – 安装和配置计时器
Chronograf 是一个图形和可视化应用程序,提供工具来可视化监控数据并创建警报和自动化规则,包括对模板的支持,并为常见数据集提供智能预配置仪表板库。
下载并安装最新软件包:
1wget https://dl.influxdata.com/chronograf/releases/chronograf-1.2.0~beta3.x86_64.rpm
2sudo yum localinstall chronograf-1.2.0~beta3.x86_64.rpm
然后开始使用Cronograf服务:
1sudo systemctl start chronograf
<$>[注]
注:如果您正在使用 FirewallD,请将其配置为允许连接到端口8888:
1sudo firewall-cmd --zone=public --permanent --add-port=8888/tcp
2sudo firewall-cmd --reload
在 CentOS 7 上如何使用 FirewallD 设置防火墙(https://andsky.com/tech/tutorials/how-to-set-up-a-firewall-using-firewalld-on-centos-7)的教程中,了解有关防火墙规则的更多信息。
现在,您可以通过在您的 Web 浏览器中访问 http://your_server_ip:8888 访问 Chronograf 界面。
您将看到一个欢迎页面,如下图所示:
输入 InfluxDB 数据库的用户名和密码,然后单击 连接新源来继续。
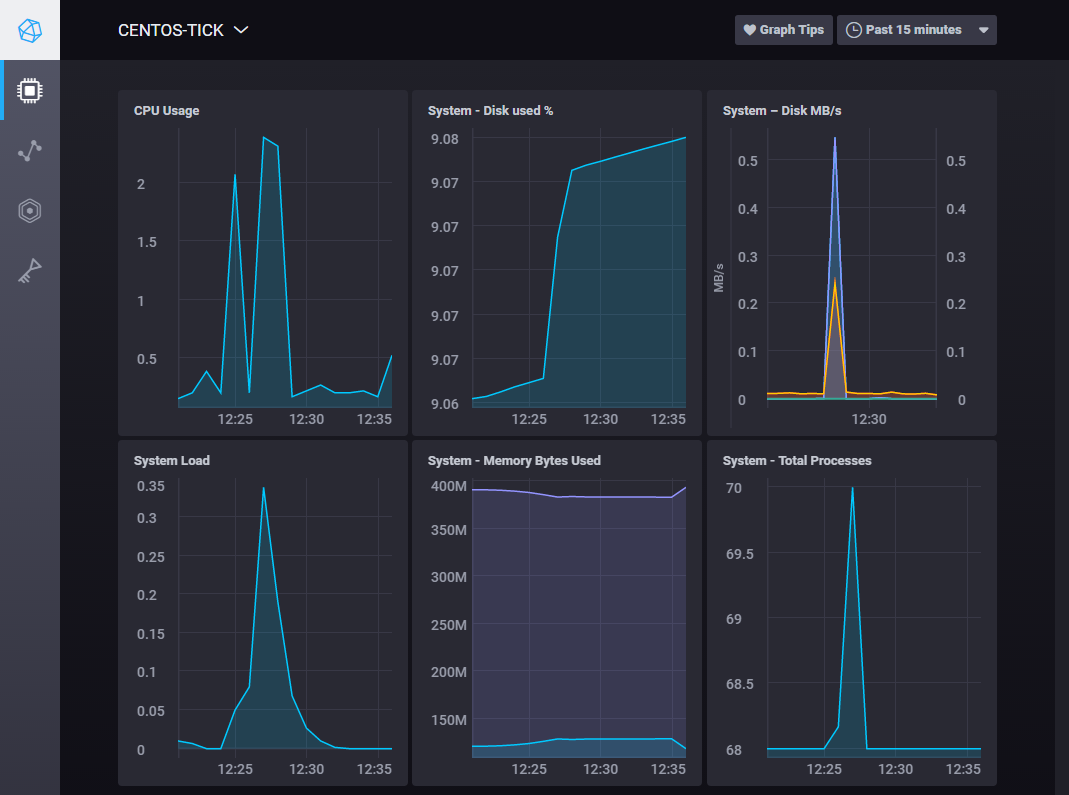
一旦连接,您将看到一个主机列表. 点击您的服务器的主机名称,以打开一组系统级图表的仪表板,如下图像所示:
现在,让我们将 Chronograf 连接到 Kapacitor 来设置警报。 跳过左导航菜单中的最后一个项目,然后点击 Kapacitor 来打开配置页面。
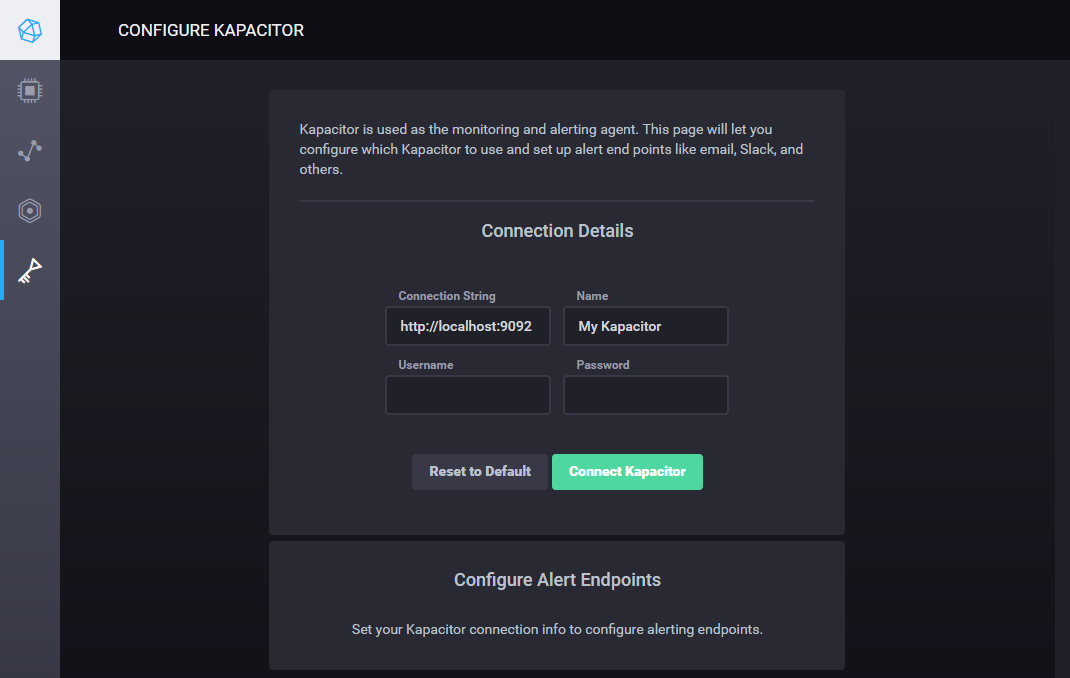
使用默认连接详细信息;我们没有为 Kapacitor 配置用户名和密码. 点击 连接 Kapacitor. 一旦 Kapacitor 成功连接,您将看到表单下方的 配置警告终端点部分。
Kapacitor 支持多个警报终端:
- HipChat
- OpsGenie
- PagerDuty
- Sensu
- Slack
- SMTP
- Talk
- Telegram
- VictorOps
最简单的通信方法是 SMTP,默认选择。 填写 从电子邮件的字段以发送警报的地址,然后点击 保存。
有了配置,让我们创建一些警报。
步骤 6 – 配置警报
让我们设置一个简单的警报,搜索高CPU使用率。
跳过左导航菜单,找到 ALERTING 部分,然后单击 Kapacitor Rules。
在第一个部分中,单击 telegraf.autogen来选择时间序列,然后从显示的列表中选择 system,然后选择 load1。
在图表上方,找到说发送警报的字段,其中 load1 是大于**,然后输入1.0值。
然后将以下文本粘贴到 **警报消息 ** 字段中,以配置警报消息的文本:
1{{ .ID }} is {{ .Level }} value: {{ index .Fields "value" }}
您可以滚动鼠标在 ** 模板** 部分中的条目,以获取每个字段的描述。
然后从将此警告发送到**下载列表中选择 Smtp选项,并在相关字段中输入您的电子邮件地址。
默认情况下,您将收到 JSON 格式的消息,如下:
1[label Example message]
2{
3 "Name":"system",
4 "TaskName":"chronograf-v1-50c67090-d74d-42ba-a47e-45ba7268619f",
5 "Group":"nil",
6 "Tags":{
7 "host":"centos-tick"
8 },
9 "ID":"TEST:nil",
10 "Fields":{
11 "value":1.25
12 },
13 "Level":"CRITICAL",
14 "Time":"2017-03-08T12:09:30Z",
15 "Message":"TEST:nil is CRITICAL value: 1.25"
16}
您可以为邮件警报设置更多可读的邮件. 要做到这一点,请在文本框中输入您的邮件,使用 ** 将电子邮件的身体文本放到这里 ** 位置。
您可以通过在页面的左上角点击该规则的名称重新命名并输入新名称来重命名该规则。
最后,点击右上角的保存规则以完成此规则的配置。
要测试这个新创建的警报,使用dd命令创建一个CPU峰值,从/dev/zero读取数据,然后将其发送到/dev/null:
1dd if=/dev/zero of=/dev/null
让命令运行几分钟,这应该足以创建一个顶点. 您可以随时通过按CTRL+C来停止命令。
过了一会儿,您将收到一封电子邮件,您还可以通过点击警报历史在Cronograf用户界面的左导航菜单中查看所有警报。
<$>[注]
注:一旦您确认可以接收警报,请确保停止您用CTRL+C启动的dd命令。
我们有运行警报,但任何人都可以登录Cronograf。
步骤 7 – 使用 OAuth 保护 chronograph
默认情况下,任何知道运行 Chronograf 应用程序的服务器地址的人都可以查看任何数据. 它适用于测试环境,但不适用于生产。 Chronograf 支持 Google、Heroku 和 GitHub 的 OAuth 身份验证。
首先,在 GitHub 注册一个新的应用程序。 登录您的 GitHub 帐户并导航到 https://github.com/settings/applications/new。
然后用以下细节填写表格:
- 填写 应用程序名称 用 Chronograf 或合适的描述名称。
- 对于 主页 URL,使用
http://your_server_ip:8888. - 填写 授权回调 URL 用
http://your_server_ip:8888/oauth/github/callback. - 点击 注册应用程序 保存设置。
- 复制在下一个屏幕上提供的 客户 ID 和 客户秘密 值。
接下来,编辑 Chronograf 的 systemd 脚本以启用身份验证。 打开 /usr/lib/systemd/system/chronograf.service 文件:
1sudo vi /usr/lib/systemd/system/chronograf.service
然后找到[服务]部分,并编辑以ExecStart=开始的行:
1[label /usr/lib/systemd/system/chronograf.service]
2[Service]
3User=chronograf
4Group=chronograf
5ExecStart=/usr/bin/chronograf --host 0.0.0.0 --port 8888 -b /var/lib/chronograf/chronograf-v1.db -c /usr/share/chronograf/canned -t 'secret_token' -i 'your_github_client_id' -s 'your_github_client_secret' -o 'your_github_organization'
6KillMode=control-group
7Restart=on-failure
secret_token是所有 OAuth 提供商所要求的。 将其设置为随机字符串。 使用您的 Github 客户 ID、 Github 客户秘密和 Github 组织等值。
<$>[警告] 警告:如果您在命令中忽略了 Github 组织选项,任何 Github 用户都可以登录您的 Chronograf 实例。
保存文件,离开编辑器,并重新启动Cronograf服务:
1sudo systemctl daemon-reload
2sudo systemctl restart chronograf
打开http://your_server_ip:8888以访问Cronograf接口. 这次你将被介绍一个 Login with Github按钮. 点击按钮登录,你将被要求允许应用程序访问你的Github帐户. 一旦你允许访问,你将被登录。
结论
在本教程中,您可以看到TICK堆栈如何成为存储、分析和可视化时间序列数据的强大工具,它具有许多功能和用例,例如,您可以使用Kapacitor来执行 异常检测或 构建游戏分数的现场榜单。