介绍
假設您的網站或應用程式比平常慢得多. 您如何開始調查這個問題? 緩慢的應用程式有很多原因,但有時是因為您的伺服器的 CPU 被最大化了。
我们将首先了解在任何 Linux 服务器上使用资源的两种最常见的指标: CPU utilization 和 load average. 我们将探索这两种指标之间的差异,然后看看如何使用两种命令行实用程序,uptime和top来检查它们的值。
前提条件
要跟随这个指南,你需要:
若您不知道如何创建一个Droplet,请阅读 我们的文档,也可以阅读指南 如何安装DigitalOcean Metrics Agent以了解如何在您的新Droplet上启用监控,或将监控代理添加到现有的Droplet。
- 安装在您的Droplet上的
压力实用程序。 使用apt或dnf从您的分布库中安装压力。
本指南中介绍的两个命令行实用程序uptime和top在大多数Linux发行版上默认可用。
背景
在我们看看如何检查和跟踪CPU利用率和负载平均值之前,让我们从概念上考虑它们。
CPU 使用率 vs.负载平均值
這兩個經常檢查的指標有時會混淆,因為兩者都與CPU有關,當伺服器顯然過載時,兩者都可能很高,但它們並不衡量相同的事情,而且並不總是直接相互相關。
<$>[注] **注:**由于CPU任务队列可以从一毫秒到下一毫秒大幅缩小和膨胀,即时拍摄的CPU负载并不太有用。
想象一个服务器的CPU作为杂货店的收银员和作为客户的任务。CPU负载是线上总人数的计数,包括目前在收银机上服务的人。
当然,这两个指标是相互关联的:一个显而易见的原因,支票线可能长期是,如果商店有太慢(或太少)支票员,但这些支票线可能会被备份出于其他原因,如果客户要求对某个项目进行价格检查,支票员会要求另一名员工这样做。支票员可能会继续扫描等待价格检查的其他项目,但如果支票在其他项目被扫描时没有返回 - 也许价格检查器已经退出一会儿 - 支票员和客户将无聊地等待,而线路在增长。
现在想象一下,价格检查器在午餐时30分钟就消失了,与此同时,还有几位客户需要价格检查(假设一个空闲的钱包师不能自行进行价格检查,就像CPU不能执行磁盘的功能一样)钱包师将所有这些客户排除在一边,并通过剩余的客户工作,空白了支票线。钱包师现在空闲(~0%利用率),但仍有几位客户站着(非零负载)仍然需要她的时间,尽管她还不能完成支票,因为每个人都在等待价格检查员返回。
你可能会想象其他杂货店的问题,这会导致等待时间增长,而不是货币交易员的错,但考虑到这些问题会导致我们深入讨论CPU利用率,负载平均值,I / O等待和CPU时间安排。
1.负载平均不是CPU利用的代理,它们不是相同的。 2.CPU负载意味着CPU需求。 低功率的CPU可以膨胀这种需求,但其他东西也可以等待,即I/O等待。 负载平均通常被认为是CPU相关的指标,但不仅仅是CPU。
那么,服务器如何代表这些指标?
衡量单位
CPU 利用率是指系统内总 CPU 容量的百分比,在单处理器系统中,总 CPU 容量始终为 100%,在多处理器系统中,容量可以以两种不同的方式表示:正常化或非正常化。
正常化容量意味着所有处理器的综合容量被视为100%,无论处理器数量如何。
非标准化容量将每个处理器计算为具有100%容量的单位,因此,一个两个处理器系统有200%的容量,一个四个处理器系统有400%的容量,等等。
负载平均是以十进制数字来表示,这又代表了所有CPU正在等待或目前正在服务的任务的平均数目。在四个处理器系统上,有四个处理器排队,如果平均而言,四个处理器每一个都在执行一个任务而没有任务在排队中等待,负载平均将为4.0。
负载平均值永远不会正常化. 没有工具会将四个处理器四个任务的情况报告为负载平均为0. 如果平均有四个任务正在运行或等待CPU,负载平均值将始终是4.0,无论有多少CPU。
因此,要了解你要探索的指标,你首先需要知道你的服务器有多少CPU。
你有多少CPU?
你已经知道你有两个核心的Droplet,但你可以使用nproc命令与--all选项来显示任何服务器上的处理器数量。
1nproc --all
1[secondary_label Output of nproc]
22
在大多数现代的Linux发行版中,您还可以使用lscpu命令,该命令不仅显示了处理器的数量,还显示了架构、模型名称、速度等等:
1lscpu
1[secondary_label Output of lscpu]
2Architecture: x86_64
3CPU op-mode(s): 32-bit, 64-bit
4Byte Order: Little Endian
5CPU(s): 2
6On-line CPU(s) list: 0,1
7Thread(s) per core: 1
8Core(s) per socket: 1
9Socket(s): 2
10NUMA node(s): 1
11Vendor ID: GenuineIntel
12CPU family: 6
13Model: 63
14Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz
15Stepping: 2
16CPU MHz: 1797.917
17BogoMIPS: 3595.83
18Virtualization: VT-x
19Hypervisor vendor: KVM
20Virtualization type: full
21L1d cache: 32K
22L1i cache: 32K
23L2 cache: 256K
24L3 cache: 30720K
25NUMA node0 CPU(s): 0,1
26Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
CPU 使用率和负载平均值的最佳值是什么?
一个服务器的最佳CPU利用率取决于它的作用. 一些服务器的目的是充分利用CPU。 其他不是。 执行统计分析或加密工作的应用程序或批量工作可能会不断对CPU在或接近全容量征税,而Web服务器通常不应该。 如果您的Web服务器正在最大限度地利用CPU,不要无意中升级到具有更多或更快CPU的服务器。
虽然你从来不想在任何服务器上看到100%的持续CPU利用率(正常化),但对于计算密集型应用程序来说,低于100%是合适的,如果不是,你可能有更多的CPU功率,而服务器降级(或使用更少的服务器)可能会节省你的钱。
负载平均值的最佳值是CPU数量或以下的任何东西. 只要两个处理器系统的负载平均值仍然低于2.0,您可以肯定CPU时间很少存在争议。
检查负载平均值与uptime
uptime命令是一个快速的方法来检查负载平均值. 它可以是有帮助的,因为它是轻量级的,并且运行很快,即使系统在命令行上反复缓慢响应(即由于高负载)。
uptime命令显示:
- 系统时间
- 服务器运行了多久
- 目前有多少用户登录
- 过去一、五、十五分钟的负载平均值
1uptime
1[secondary_label Output]
2 14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
在这个例子中,该命令在2点08分在一个服务器上运行了将近23个小时。两个用户被登录了。第一个负载平均值,‘2.00’,是1分钟的负载平均值。由于这个服务器有两个CPU,负载平均值为2.00意味着在运行前的分钟中,平均有两个过程使用CPU,而没有任何过程等待。五分钟的负载平均值表明,在该间隔中,有一个空闲的处理器大约60%的时间。
这个实用程序提供了负载平均值的有用视图,但为了获得更深入的信息,我们将转向顶部。
检查CPU使用率与顶部
与uptime一样,top 可以在 Linux 和 Unix 系统上使用,但除了显示与uptime相同的负载平均值外,它还提供 CPU 利用率、内存使用率和更多数据的总系统和过程数据。
在运行顶部之前,给您的 Droplet 做点工作,运行以下命令来对 CPU 施加一些压力:
1stress -c 2
现在打开您的Droplet另一个终端并运行顶部:
1top
这将带来一个交互式屏幕,显示资源利用概述以及所有系统流程的表格。
标签:Header Block
以下是顶部中的前五行:
1[secondary_label Output]
2top - 22:05:28 up 1:02, 3 users, load average: 2.26, 2.27, 2.19
3Tasks: 109 total, 3 running, 106 sleeping, 0 stopped, 0 zombie
4%Cpu(s): 99.8 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.2 st
5MiB Mem : 1975.7 total, 1134.7 free, 216.4 used, 624.7 buff/cache
6MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1612.0 avail Mem
第一行几乎与uptime的输出相同。与uptime一样,显示一个、五分钟和十五分钟的负载平均值。这个行和uptime的输出之间的唯一区别是,行开始时显示命令名称top,并且每次top更新数据时更新时间。
第二行概括了所有系统任务的状态:过程的总数,其次是它们的运行、睡眠、停止或僵尸数量。
第三行告诉你关于CPU利用率. 这些数字被正常化并显示为百分比(不含 %符号),所以在这个行上的所有值都应该增加到100%,无论CPU的数量如何。
第四条和第五条线分别告诉您关于内存和交换使用,本指南不探讨内存和交换使用,但它在您需要时为您提供。
此标题块随后有一个表,包含有关每个个别过程的信息,我们将在一瞬间查看。
在下面的示例标题块中,一分钟的平均负载超过了处理器数量的77,这表明有很少的等待时间的短排。
1[secondary_label Output]
2top - 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91
3Tasks: 117 total, 3 running, 114 sleeping, 0 stopped, 0 zombie
4%Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st
5KiB Mem : 4046532 total, 3244112 free, 72372 used, 730048 buff/cache
6KiB Swap: 0 total, 0 free, 0 used. 3695452 avail Mem
7 . . .
让我们更深入地看看CPU线上的每个领域:
- 我们,用户:运行时间非用户流程
这个类别是指没有明确的规划优先级启动的用户流程。
Linux 系统(使用好命令来设置一个流程的规划优先级)(https://andsky.com/tech/tutorials/how-to-use-ps-kill-and-nice-to-manage-processes-in-linux#how-to-adjust-process-priorities),因此不划定意味着好没有被用来改变默认值。
- sy,系统:时间运行内核流程
大多数应用程序都有用户和内核组件. 当Linux内核做某些事情,例如进行系统调用,检查权限,或代表应用程序与设备进行交互时,内核对CPU的使用在这里显示。
- ni, nice:时间运行的用户流程
与 user一样, nice指的是不涉及内核的CPU时间,但在 nice中,这些任务的规划优先级被明确设定。一个过程的优先级在标题 NI下的过程表的第四列中表示。需要大量CPU时间的1到20之间的优先级值的过程通常不是一个问题,因为具有正常或更高的优先级的任务将能够在需要时获得处理功率。但是,如果具有较高的优先级的任务,在 -1 和 -20之间,需要不成比例的CPU时间,它们可以轻松影响系统的响应能力,并需要进一步调查。
- id, idle:在内核的 idle 处理器中花费的时间
该数字表明CPU既可用又无用的时间的百分比,系统通常在CPU方面处于良好工作状态,当 用户、 nice和 idle数字相结合时接近100%。
wa,IO等待:等待I/O完成的时间*
IO等待数字显示了处理器花了多少时间等待I/O操作完成。对于NFS和LDAP等网络资源的阅读/写作操作也会在IO等待中计算。
- hi,硬件中断:花费时间维修硬件中断
这是从磁盘和硬件网络接口等外围设备发送到CPU的物理中断所花费的时间。
- 是的,软件中断:服务时间中断软件
软件中断是由流程而不是物理设备发送的。与CPU级发生的硬件中断不同,软件中断发生在内核级。
- st, steal:这个vm被超视窗偷来的时间**
steal 值表示虚拟 CPU 花了多长时间等待物理 CPU,而超视觉正在维修自己或另一个虚拟 CPU. 基本上,这个领域的 CPU 使用量表明您的 VM 准备好使用的处理功率是多少,但这并不适用于您的应用程序,因为它被物理主机或其他虚拟机使用。
现在我们已经查看了顶部标题中提供的CPU使用概述,我们将看看下面出现的过程表,注意CPU特定的列。
过程表
以下是某些示例顶部输出中过程表的前六行:
1[secondary_label Output]
2
3 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
49966 sammy 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress
59967 sammy 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress
6 7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched
71431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid
89968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top
99977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd
10. . .
服务器上的所有进程,在任何状态下,都列出在标题下方. 默认情况下,进程表按 %CPU 列进行排序,因此您将在顶部看到消耗最多 CPU 时间的进程。
%CPU值以百分比值呈现,但与标题中的CPU利用率数字不同,进程表中的进度数不正常化,因此在这个两核系统上,进程表中的所有值的总数应在两个进度器完全使用时增加到200%。
<$>[注]
注: 如果您喜欢在这里看到正常化的值,请按SHIFT+I来将显示器从Irix模式切换到Solaris模式.现在%CPU值的总和不会超过100%。
1[secondary_label Output]
2 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
310081 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.18 stress
410082 sammy 20 0 9528 96 0 R 50.0 0.0 0:49.08 stress
5 1439 root 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
6 1 root 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 systemd
美元
您可以使用不同的键键来互动地控制顶部 - 以及服务器的流程,包括:
SHIFT-M以记忆使用来排序流程.SHIFT-P以 CPU 使用来排序流程.k,然后是进程 ID (PID) 和信号,以杀死不规则的进程. 输入 PID 后,先尝试一个 15 (SIGTERM) 信号,这是默认值。 不要使用 9 (SIGKILL) 不小心。r,然后是进程 ID,以放弃(重新优先)一个进程。c以在简短描述(默认)和完整命令字符串之间切换命令说明。d以更改
阅读顶部的男人页面(人顶部)以获取更多细节。
到目前为止,你已经检查了两个Linux命令,这些命令通常用于查看负载平均值和CPU利用率。尽管这些工具是有用的,但它们只是在短时间窗口中提供服务器状态的见解。 只有这样,你才能坐在那里观看顶部。 为了更好地了解服务器资源使用的长期模式,你需要某种监控解决方案。
跟踪指数随着时间的推移与数字海洋监测
默认情况下,所有 Droplets 在 控制面板中点击 Droplet 名称时都会显示带宽、CPU 和磁盘 I/O 图表。
这些图表有助于您可视化每个资源在过去 1 小时、6 小时、24 小时、7 天和 14 天中的使用情况。CPU 图表提供了CPU 使用情况的信息。暗蓝线表示用户流程使用CPU。蓝色显示系统流程使用CPU。
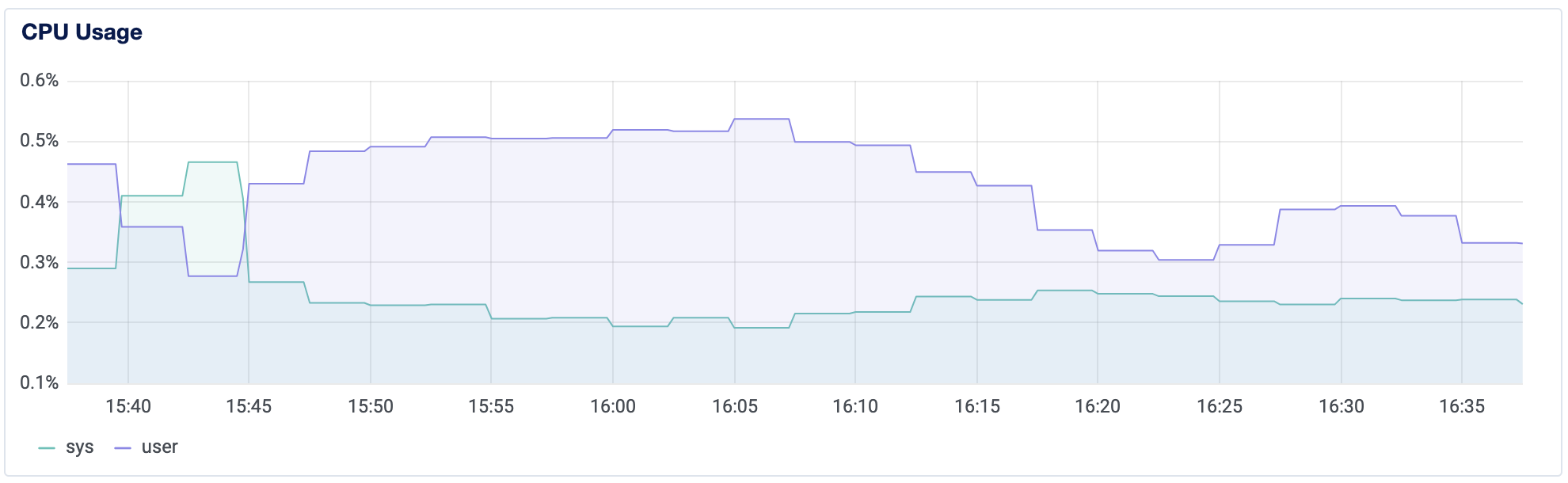
图表允许您看到您是否正在经历间歇性或持续的使用变化,并有助于发现服务器的CPU使用模式的变化。
为了补充这些默认图表,您可以将DigitalOcean Agent安装在Droplet上,以收集和显示额外的数据,如负载平均值、磁盘使用率和内存使用率。
一旦 Agent 安装,您可以设置警报策略来通知您资源使用情况. 您选择的门槛将取决于服务器的典型工作负载。
<$>[注] 注: 安装 DigitalOcean Monitoring Agent 时:
您将只看到一个 CPU 利用值值. 您将不再看到系统与用户空间利用值。 2. 您将失去在安装代理之前的所有指标的历史。
美元
示例警报
变更监控:CPU超过1%
如果您使用 Droplet 主要用于集成和浸泡测试代码,您可能会设置一个警报,仅仅略高于历史模式,以检测新代码推向服务器是否增加了 CPU 使用率。
在 DigitalOcean 控制面板中,在左侧的 MANAGE 菜单下,单击 Monitoring. 在 Resource Alerts 选项卡(默认情况下突出),单击 Create Resource Alert. 填写表单,然后单击 Create resource alert。
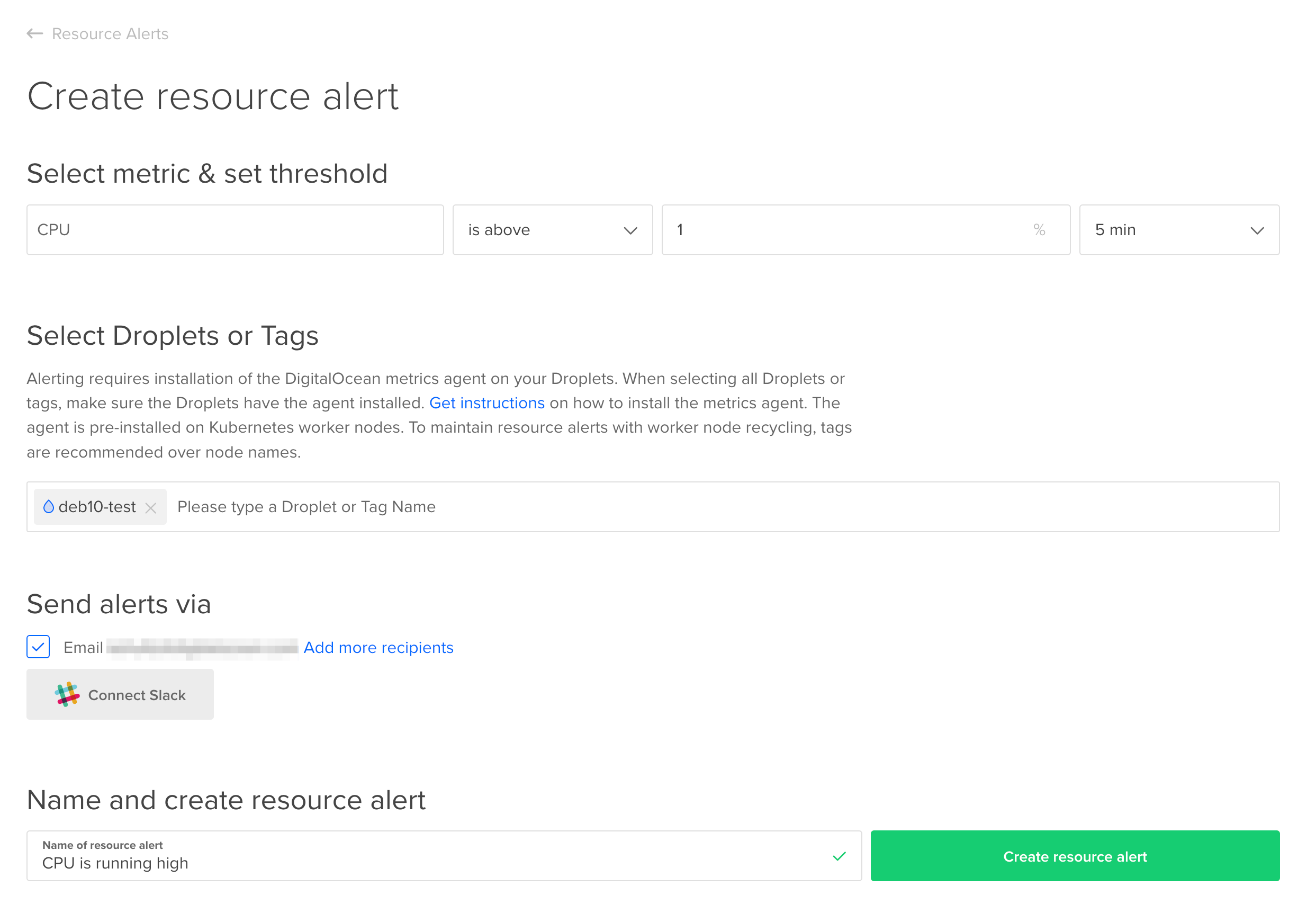
在大多数系统中,这个门槛很可能完全不合适,但如果你可以在正常工作负载期间通过检查 CPU 图表来确定典型的 CPU 利用率,你可以创建略高于正常利用率的警报,并早期了解新代码或新服务如何影响 CPU 利用率。
紧急情况监控:CPU使用率超过90%
您可能还想设置一个远高于平均值的门槛,一个您认为至关重要,这将要求立即调查。例如,如果一个服务器经历了持续的CPU使用50%的五分钟间隔相当经常突然拍摄到90%,你可能想立即登录以调查情况。
结论
在本文中,我们探索了uptime和top,两种常见的Linux实用程序,这些实用程序提供了Linux系统的CPU利用率和负载平均值的见解,以及如何使用DigitalOcean Monitoring来查看Droplet上的历史CPU利用率,并提醒您发生变化和紧急情况。
要帮助您决定您需要为工作负载使用什么类型的 Droplet,请阅读 选择正确的 Droplet 计划。