作者选择了 公共利益软件以作为 写给捐赠计划的一部分获得捐赠。
介绍
Elastic Stack - 以前被称为 ELK Stack - 是一个由 Elastic生产的开源软件集合,允许您搜索,分析和可视化从任何来源在任何格式生成的日志,这种做法被称为 ELK Stack。
Elastic Stack有四个主要成分:
- Elasticsearch :一个分布式的 RESTful搜索引擎,存储所有收集的数据。
- Logstash ):Elastic Stack的数据处理组件,将输入数据发送到Elasticsearch。
- Kibana :用于搜索和可视化日志的Web接口。
在本教程中,您将在 CentOS 7 服务器上安装 Elastic Stack。您将学习如何安装 Elastic Stack 的所有组件 - 包括 Filebeat,用于转发和集中日志和文件的 Beat - 并配置它们以收集和可视化系统日志。此外,因为Kibana通常只能在本地主机上使用,您将使用 Nginx来代理它,以便通过 Web 浏览器访问。
<$>[注] 注 :在安装 Elastic Stack 时,您应该在整个堆栈中使用相同的版本.本教程使用每个组件的最新版本,这些版本在本文写作时是 Elasticsearch 6.5.2, Kibana 6.5.2, Logstash 6.5.2 和 Filebeat 6.5.2. <$>
前提条件
要完成本教程,您将需要以下内容:
- One CentOS 7 服务器设置如下 Initial Server Setup with CentOS 7,包括具有 sudo 特权和 firewall的非根用户。 您的 Elastic Stack 服务器所需的 CPU、RAM 和存储量取决于您打算收集的日志量。 对于本教程,您将使用一个 VPS 使用我们 Elastic Stack 服务器的下列规格:
- OS: CentOS 7.5
- RAM: 4GB
- CPU: 2
- Java 8 - 这是 Elasticsearch 和 Logstash 所要求的 - 安装在您的服务器上。 注意到 Java 9 不受支持。 为了安装
此外,由于 Elastic Stack 用于访问有关您的服务器的宝贵信息,您不希望未经授权的用户访问,因此通过安装 TLS/SSL 证书来保护您的服务器很重要。
如果您打算在您的服务器上配置 Let's Encrypt,您需要在执行之前执行以下操作:
您可以在 Namecheap购买域名,在 Freenom获得一个免费的域名,或使用您选择的域名注册器。
- 以下两个 DNS 记录为您的服务器设置。 您可以遵循 DigitalOcean DNS 的介绍以获取如何添加它们的详细信息。
- 一个记录与
example.com指向您的服务器的公共 IP 地址。 - 一个记录与
www.example.com指向您的服务器的公共 IP 地址。
步骤 1 – 安装和配置 Elasticsearch
Elastic Stack 组件默认情况下不是通过包管理器可用的,但您可以通过添加 Elastic 的包库来安装它们。
所有 Elastic Stack 包都使用 Elasticsearch 签名密钥签名,以保护您的系统免受包裹欺骗。 使用该密钥身份验证的包裹将被您的包管理器视为可信赖的包裹。 在此步骤中,您将导入 Elasticsearch 公共 GPG 密钥并添加 Elastic 存储库以安装 Elasticsearch。
运行以下命令来下载和安装 Elasticsearch 公共签名密钥:
1sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
接下来,添加 Elastic 存储库. 使用您偏好的文本编辑器在 /etc/yum.repos.d/ 目录中创建 elasticsearch.repo 文件. 在这里,我们将使用 vi 文本编辑器:
1sudo vi /etc/yum.repos.d/elasticsearch.repo
要为 yum 提供下载和安装 Elastic Stack 组件所需的信息,请按i键进入插入模式,并将下列行添加到文件中。
1[label /etc/yum.repos.d/elasticsearch.repo]
2[elasticsearch-6.x]
3name=Elasticsearch repository for 6.x packages
4baseurl=https://artifacts.elastic.co/packages/6.x/yum
5gpgcheck=1
6gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
7enabled=1
8autorefresh=1
9type=rpm-md
在这里,您包括了可人读的repo的名称,repo的数据目录的baseurl,以及验证Elastic包所需的gpgkey。
完成后,请按ESC来离开插入模式,然后按:wq和ENTER来保存和退出文件. 有关文本编辑器 vi 及其继任者 vim 的更多信息,请参阅我们的 在云服务器上安装和使用 Vim 文本编辑器教程。
随着重新安装,您现在可以安装 Elastic Stack. 根据 官方文档,您应该在其他组件之前安装 Elasticsearch。
使用以下命令安装 Elasticsearch:
1sudo yum install elasticsearch
一旦 Elasticsearch 已完成安装,请在您的编辑器中打开其主要配置文件 elasticsearch.yml:
1sudo vi /etc/elasticsearch/elasticsearch.yml
<$>[注] 注: Elasticsearch 的配置文件是 YAML 格式,这意味着插入非常重要!请确保您在编辑此文件时不添加任何额外的空间。
Elasticsearch 在端口9200上听取来自任何地方的流量。您将想要限制对您的 Elasticsearch 实例的外部访问,以防止外部人员阅读您的数据或通过 REST API 关闭您的 Elasticsearch 集群。
1[label /etc/elasticsearch/elasticsearch.yml]
2. . .
3network.host: localhost
4. . .
保存并关闭elasticsearch.yml,然后使用systemctl启动Elasticsearch服务:
1sudo systemctl start elasticsearch
接下来,运行以下命令,以允许 Elasticsearch 每次启动服务器时启动:
1sudo systemctl enable elasticsearch
您可以通过发送 HTTP 请求来测试您的 Elasticsearch 服务是否正在运行:
1curl -X GET "localhost:9200"
您将看到显示有关本地节点的一些基本信息的响应,类似于此:
1[secondary_label Output]
2{
3 "name" : "8oSCBFJ",
4 "cluster_name" : "elasticsearch",
5 "cluster_uuid" : "1Nf9ZymBQaOWKpMRBfisog",
6 "version" : {
7 "number" : "6.5.2",
8 "build_flavor" : "default",
9 "build_type" : "rpm",
10 "build_hash" : "9434bed",
11 "build_date" : "2018-11-29T23:58:20.891072Z",
12 "build_snapshot" : false,
13 "lucene_version" : "7.5.0",
14 "minimum_wire_compatibility_version" : "5.6.0",
15 "minimum_index_compatibility_version" : "5.0.0"
16 },
17 "tagline" : "You Know, for Search"
18}
现在Elasticsearch正在运行,让我们安装Kibana,这是Elastic Stack的下一个组件。
步骤 2 — 安装和配置Kibana仪表板
根据官方文档(https://www.elastic.co/guide/en/elastic-stack/current/installing-elastic-stack.html)中的安装顺序,您应该安装Kibana作为Elasticsearch之后的下一个组件,设置Kibana后,我们将能够使用其界面来搜索和可视化Elasticsearch存储的数据。
由于您在上一步中已经添加了 Elastic 存储库,您可以使用 `yum' 来安装 Elastic Stack 的剩余组件:
1sudo yum install kibana
然后启用并启动Kibana服务:
1sudo systemctl enable kibana
2sudo systemctl start kibana
由于Kibana配置为只听本地主机,我们必须设置一个反向代理(https://andsky.com/tech/tutorials/digitalocean-community-glossary# reverse-proxy)来允许外部访问它,我们将为此使用 Nginx,它应该已经安装在您的服务器上。
首先,使用openssl命令创建一个管理的Kibana用户,您将使用它来访问Kibana Web接口. 例如,我们将这个帐户命名为kibanaadmin,但为了确保更大的安全性,我们建议您为您的用户选择一个难以猜测的非标准名称。
下列命令将创建管理 Kibana 用户名和密码,并将其存储在 `htpasswd.users 文件中. 您将配置 Nginx 以要求此用户名和密码,并暂时阅读此文件:
1echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
请记住或记住此登录,因为您将需要它来访问Kibana Web接口。
接下来,我们将创建一个 Nginx 服务器封锁文件. 作为一个例子,我们将把这个文件称为 'example.com.conf',尽管你可能会觉得给你的更为描述性的名字是有帮助的。
1sudo vi /etc/nginx/conf.d/example.com.conf
将下列代码块添加到文件中,确保更新 example.com 和 www.example.com 以匹配您的服务器的 FQDN 或公共 IP 地址. 此代码配置 Nginx 以将您的服务器的 HTTP 流量导向 Kibana 应用程序,该应用程序正在收听 localhost:5601。
请注意,如果您遵循 前提 Nginx 教程直到最后,您可能已经创建了此文件并填充了一些内容,在这种情况下,在添加以下内容之前,请删除文件中的所有现有内容:
1[label /etc/nginx/conf.d/example.com.conf]
2server {
3 listen 80;
4
5 server_name example.com www.example.com;
6
7 auth_basic "Restricted Access";
8 auth_basic_user_file /etc/nginx/htpasswd.users;
9
10 location / {
11 proxy_pass http://localhost:5601;
12 proxy_http_version 1.1;
13 proxy_set_header Upgrade $http_upgrade;
14 proxy_set_header Connection 'upgrade';
15 proxy_set_header Host $host;
16 proxy_cache_bypass $http_upgrade;
17 }
18}
完成后,保存并关闭文件。
然后检查语法错误的配置:
1sudo nginx -t
如果您的输出中报告了任何错误,请返回并双重检查您在配置文件中添加的内容是否正确。一旦您在输出中看到‘syntax is ok’,请继续并重新启动 Nginx 服务:
1sudo systemctl restart nginx
默认情况下,SELinux 安全策略设置为执行. 运行以下命令以允许 Nginx 访问代理服务:
1sudo setsebool httpd_can_network_connect 1 -P
您可以在教程中了解更多关于SELinux的信息 CentOS 7上的SELinux介绍。
Kibana现在可以通过您的 FQDN 或您的 Elastic Stack 服务器的公共 IP 地址访问,您可以通过导航到以下地址检查 Kibana 服务器的状态页面,并在提示时输入您的登录凭证:
1http://your_server_ip/status
此状态页显示了服务器资源使用情况的信息,并列出了已安装的插件。
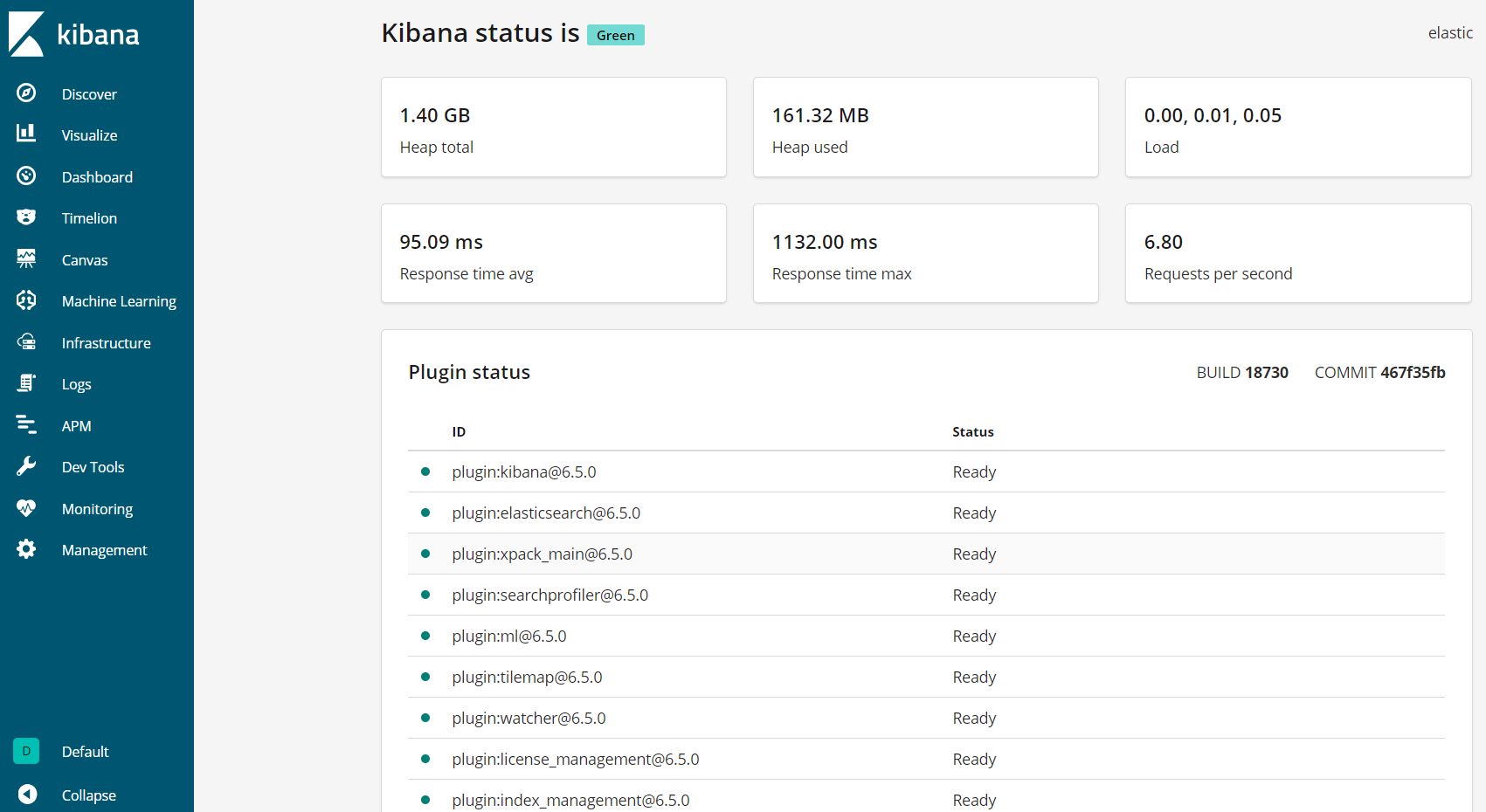
<$>[注] 注 :如前提在前提部分中所述,建议您在您的服务器上启用SSL/TLS。您可以遵循 本教程现在获得免费的SSL证书的NGINX在CentOS 7. 获得SSL/TLS证书后,您可以回来完成本教程。
现在,Kibana仪表板已配置,让我们安装下一个组件:Logstash。
步骤 3 – 安装和配置 Logstash
虽然 Beats 可以直接将数据发送到 Elasticsearch 数据库,但我们建议使用 Logstash 首先处理数据,这将允许您从不同的来源收集数据,将其转换为通用格式,并将其导出到另一个数据库。
使用此命令安装 Logstash:
1sudo yum install logstash
在安装 Logstash 后,您可以继续配置它。 Logstash 的配置文件是以 JSON 格式写的,并位于 `/etc/logstash/conf.d 目录中。当您配置它时,将 Logstash 视为一个管道,该管道在一个端拿入数据,以某种方式处理数据,并将其发送到其目的地(在这种情况下,目的地是 Elasticsearch)。
创建一个名为 `02-beats-input.conf 的配置文件,在那里您将设置您的 Filebeat 输入:
1sudo vi /etc/logstash/conf.d/02-beats-input.conf
插入以下输入配置,指定一个打击输入,该输入将听到TCP端口5044。
1[label /etc/logstash/conf.d/02-beats-input.conf]
2input {
3 beats {
4 port => 5044
5 }
6}
然后,创建一个名为10-syslog-filter.conf的配置文件,该文件将添加系统日志的过滤器,也称为 syslogs:
1sudo vi /etc/logstash/conf.d/10-syslog-filter.conf
插入以下 syslog 过滤器配置. 此示例的系统日志配置是从 官方 Elastic 文档中提取的。
1[label /etc/logstash/conf.d/10-syslog-filter.conf]
2filter {
3 if [fileset][module] == "system" {
4 if [fileset][name] == "auth" {
5 grok {
6 match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?",
7 "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}",
8 "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}",
9 "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}",
10 "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}",
11 "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$",
12 "%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] }
13 pattern_definitions => {
14 "GREEDYMULTILINE"=> "(.|\n)*"
15 }
16 remove_field => "message"
17 }
18 date {
19 match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
20 }
21 geoip {
22 source => "[system][auth][ssh][ip]"
23 target => "[system][auth][ssh][geoip]"
24 }
25 }
26 else if [fileset][name] == "syslog" {
27 grok {
28 match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] }
29 pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" }
30 remove_field => "message"
31 }
32 date {
33 match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
34 }
35 }
36 }
37}
保存并关闭文件完成后。
最后,创建一个名为 `30-elasticsearch-output.conf 的配置文件:
1sudo vi /etc/logstash/conf.d/30-elasticsearch-output.conf
插入以下输出配置. 此输出配置 Logstash 以存储在 Elasticsearch 中运行的 Beats 数据,该数据运行在localhost:9200,以使用的 Beat 命名的索引中。
1[label /etc/logstash/conf.d/30-elasticsearch-output.conf]
2output {
3 elasticsearch {
4 hosts => ["localhost:9200"]
5 manage_template => false
6 index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
7 }
8}
保存并关闭文件。
如果您想为使用 Filebeat 输入的其他应用程序添加过滤器,请确保将文件命名,以便它们在输入和输出配置之间进行排序,这意味着文件名应该以02和30之间的两位数开始。
使用此命令测试您的 Logstash 配置:
1sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
如果没有语法错误,您的输出将在几秒钟后显示配置顺利,如果您在输出中看不到这些错误,请检查输出中出现的任何错误,并更新您的配置以纠正它们。
如果您的配置测试成功,请启动并允许 Logstash 执行配置更改:
1sudo systemctl start logstash
2sudo systemctl enable logstash
现在Logstash运行正确,并且已完全配置,让我们安装FileBeat。
步骤 4 – 安装和配置 Filebeat
Elastic Stack 使用几个名为 Beats 的轻量级数据传输器来收集来自各种来源的数据,并将其传输到 Logstash 或 Elasticsearch。
- Filebeat:收集和运输日志文件。
- Metricbeat:收集您的系统和服务的指标。
- Packetbeat:收集和分析网络数据。
- Winlogbeat:收集Windows事件日志。
- Auditbeat:收集Linux审计框架数据并监控文件完整性。
在本教程中,我们将使用 Filebeat 将本地日志转发到我们的 Elastic Stack。
使用「yum」來安裝 Filebeat:
1sudo yum install filebeat
接下来,配置 Filebeat 以连接到 Logstash. 在这里,我们将修改附有 Filebeat 的示例配置文件。
打开 FileBeat 配置文件:
1sudo vi /etc/filebeat/filebeat.yml
<$>[注] 注: 与 Elasticsearch 一样,Filebeat 的配置文件是 YAML 格式,这意味着正确的入口是至关重要的,所以请确保在这些指示中使用相同数量的空间。
Filebeat 支持多种输出,但你通常只会直接向 Elasticsearch 或 Logstash 发送事件以进行额外处理。 在本教程中,我们将使用 Logstash 对 Filebeat 收集的数据进行额外处理。 Filebeat 不需要直接向 Elasticsearch 发送任何数据,所以让我们禁用该输出。
1[label /etc/filebeat/filebeat.yml]
2...
3#output.elasticsearch:
4 # Array of hosts to connect to.
5 #hosts: ["localhost:9200"]
6...
然后,配置output.logstash部分. 通过删除# 删除output.logstash:和hosts: [localhost:5044]的行,这将配置Fileebeat连接到您的Elastic Stack服务器上的Logstash在端口5044,该端口我们之前指定了Logstash输入:
1[label /etc/filebeat/filebeat.yml]
2output.logstash:
3 # The Logstash hosts
4 hosts: ["localhost:5044"]
保存并关闭文件。
在本教程中,您将使用 系统模块,该模块收集和分析由常见的Linux发行版系统日志服务创建的日志。
让我们让它:
1sudo filebeat modules enable system
您可以通过运行查看启用和禁用模块的列表:
1sudo filebeat modules list
你会看到一个类似于以下的列表:
1[secondary_label Output]
2Enabled:
3system
4
5Disabled:
6apache2
7auditd
8elasticsearch
9haproxy
10icinga
11iis
12kafka
13kibana
14logstash
15mongodb
16mysql
17nginx
18osquery
19postgresql
20redis
21suricata
22traefik
默认情况下,Filebeat 配置为使用默认路径为 syslog 和授权日志. 在本教程的情况下,您不需要更改任何配置。您可以在 /etc/filebeat/modules.d/system.yml 配置文件中查看模块的参数。
接下来,将索引模板加载到 Elasticsearch. 一个 Elasticsearch index是具有相似特征的文档集合。
要加载模板,请使用以下命令:
1sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
这将产生以下产出:
1[secondary_label Output]
2Loaded index template
Filebeat 配备了样本 Kibana 仪表板,允许您在 Kibana 中可视化 Filebeat 数据. 在您使用仪表板之前,您需要创建索引模式并将仪表板加载到 Kibana。
随着仪表板的加载,Filebeat 连接到 Elasticsearch 以检查版本信息. 若要在启用 Logstash 时加载仪表板,您需要手动禁用 Logstash 输出并启用 Elasticsearch 输出:
1sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
你会看到这样的输出:
1[secondary_label Output]
2. . .
32018-12-05T21:23:33.806Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
42018-12-05T21:23:33.811Z INFO elasticsearch/client.go:712 Connected to Elasticsearch version 6.5.2
52018-12-05T21:23:33.815Z INFO template/load.go:129 Template already exists and will not be overwritten.
6Loaded index template
7Loading dashboards (Kibana must be running and reachable)
82018-12-05T21:23:33.816Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
92018-12-05T21:23:33.819Z INFO elasticsearch/client.go:712 Connected to Elasticsearch version 6.5.2
102018-12-05T21:23:33.819Z INFO kibana/client.go:118 Kibana url: http://localhost:5601
112018-12-05T21:24:03.981Z INFO instance/beat.go:717 Kibana dashboards successfully loaded.
12Loaded dashboards
132018-12-05T21:24:03.982Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
142018-12-05T21:24:03.984Z INFO elasticsearch/client.go:712 Connected to Elasticsearch version 6.5.2
152018-12-05T21:24:03.984Z INFO kibana/client.go:118 Kibana url: http://localhost:5601
162018-12-05T21:24:04.043Z WARN fileset/modules.go:388 X-Pack Machine Learning is not enabled
172018-12-05T21:24:04.080Z WARN fileset/modules.go:388 X-Pack Machine Learning is not enabled
18Loaded machine learning job configurations
现在你可以开始并启用FileBeat:
1sudo systemctl start filebeat
2sudo systemctl enable filebeat
如果您正确设置了 Elastic Stack,Filebeat 将开始将您的 syslog 和授权日志发送到 Logstash,然后将这些数据加载到 Elasticsearch 中。
要验证 Elasticsearch 是否确实收到这些数据,请使用此命令查询 Filebeat 索引:
1curl -X GET 'http://localhost:9200/filebeat-*/_search?pretty'
您将看到一个类似于此的输出:
1[secondary_label Output]
2{
3 "took" : 1,
4 "timed_out" : false,
5 "_shards" : {
6 "total" : 3,
7 "successful" : 3,
8 "skipped" : 0,
9 "failed" : 0
10 },
11 "hits" : {
12 "total" : 3225,
13 "max_score" : 1.0,
14 "hits" : [
15 {
16 "_index" : "filebeat-6.5.2-2018.12.05",
17 "_type" : "doc",
18 "_id" : "vf5GgGcB_g3p-PRo_QOw",
19 "_score" : 1.0,
20 "_source" : {
21 "@timestamp" : "2018-12-05T19:00:34.000Z",
22 "source" : "/var/log/secure",
23 "meta" : {
24 "cloud" : {
25. . .
如果您的输出显示 0 个总次数,则 Elasticsearch 不会在您搜索的索引下加载任何日志,您将需要检查设置的错误。
步骤5 – 探索Kibana仪表板
让我们看看Kibana,我们之前安装的Web接口。
在 Web 浏览器中,前往您的 Elastic Stack 服务器的 FQDN 或公共 IP 地址,然后输入您在步骤 2 中定义的登录凭证后,您将看到 Kibana 主页:
在左侧的导航栏中,点击发现链接。在发现页面上,选择预定义的filebeat-***索引模式,以查看Filebeat数据。默认情况下,这将向您显示过去15分钟的所有日志数据。
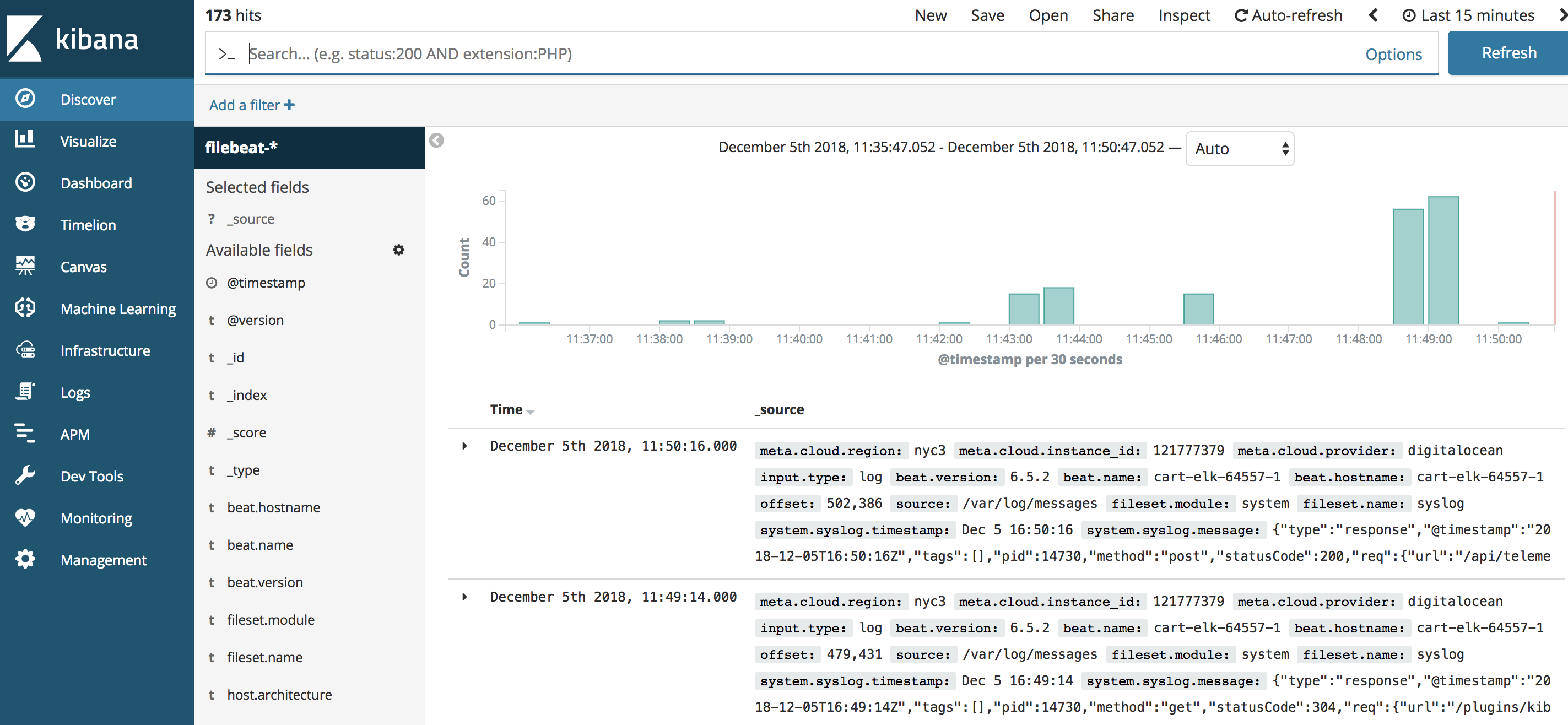
在这里,你可以搜索和浏览你的日志,并自定义你的仪表板. 然而,在这个时候,那里不会有很多,因为你只是从你的Elastic Stack服务器收集 syslogs。
使用左侧面板导航到 Dashboard 页面并搜索 ** Filebeat System** 仪表板. 一旦到达那里,您可以搜索带有 Filebeat 的系统模块的示例仪表板。
例如,您可以根据您的 syslog 消息查看详细的统计数据:

您还可以查看哪些用户使用了sudo命令以及何时:
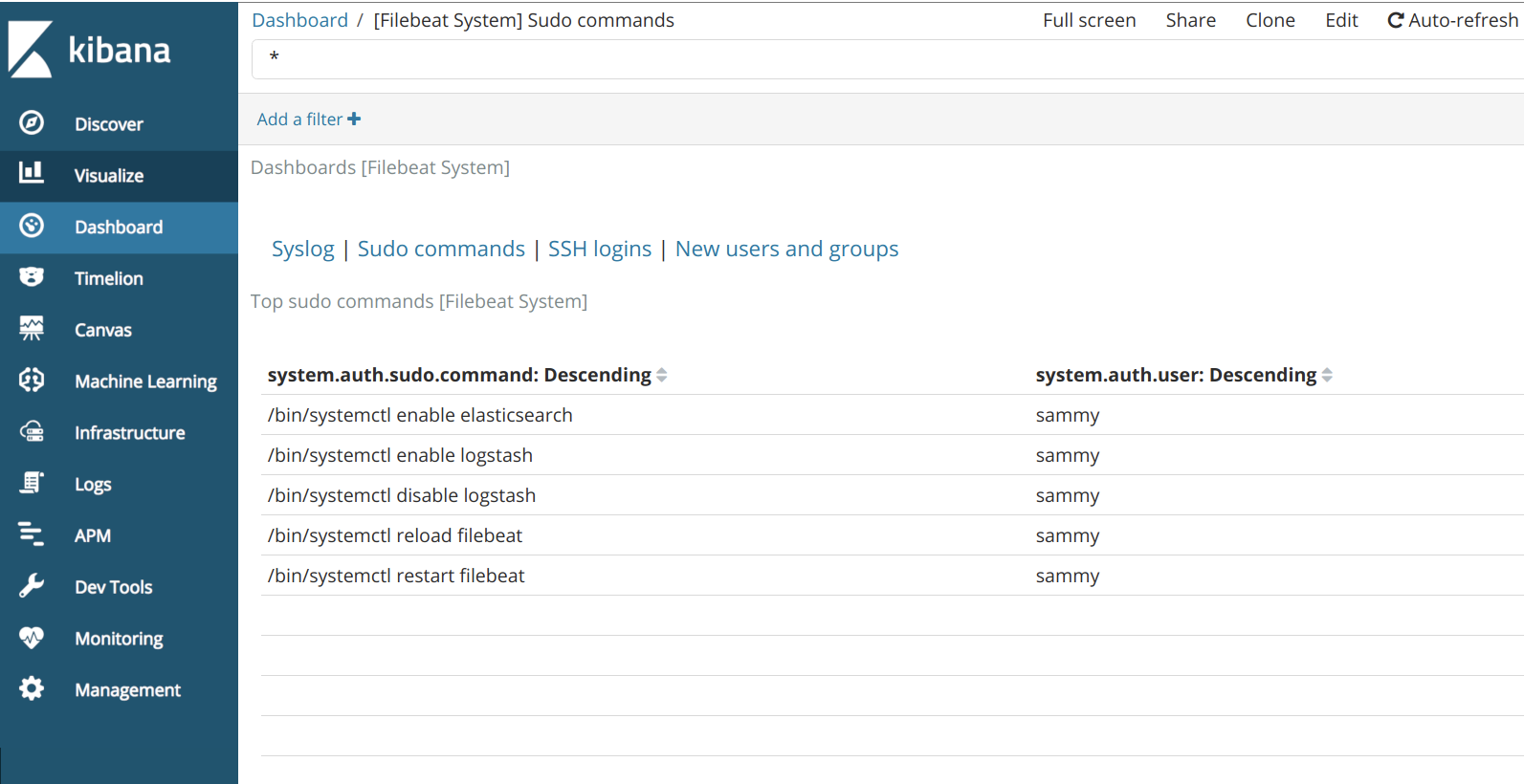
Kibana有许多其他功能,如图形和过滤,所以可以自由探索。
结论
在本教程中,您安装并配置了 Elastic Stack 来收集和分析系统日志. 请记住,您可以使用 Beats将几乎任何类型的日志或索引数据发送到 Logstash,但如果使用 Logstash 过滤器进行分析和结构,则数据将变得更加有用,因为这将数据转化为可通过 Elasticsearch 轻松阅读的一致格式。