介绍
收集有关您的系统和应用程序的信息可以为您提供有关基础设施、服务器和软件的明智决策所需的信息。
有许多不同的方法来获取这种信息,并以一种允许易于理解的方式显示它。
Graphite 是组织和渲染从您的系统中收集的数据的视觉表示的一个很好的工具,它非常灵活,可以配置,以便您可以获得详细的表示和您正在跟踪的指标的性能和健康的广泛概述的好处。
在以前的指南中,我们看了 图形和统计收集应用程序的概述,您可以将其链接在一起,以创建一个可靠的系统来显示统计数据。
安装图形
如果你看了我们对图形软件的介绍,你会注意到图形是由几个组件组成的:Web应用程序,一个名为Carbon的存储后端和一个名为whisper的数据库。
幸运的是,在Ubuntu 14.04中,我们需要的所有组件都可以在默认存储库中找到。
让我们更新我们的本地包索引,然后安装必要的包:
1sudo apt-get update
2sudo apt-get install graphite-web graphite-carbon
在安装过程中,您将被问及是否希望Carbon删除数据库文件,如果您决定清除安装。在这里选择不,以便您不会破坏您的统计数据。如果您需要重新开始,您可以随时手动删除文件(留在var/lib/graphite/whisper中)。
当安装完成时,将安装Graphite,我们需要做一些额外的配置,但要把一切从地面和运行。
创建 Django 数据库
虽然Graphite数据本身是由Carbon和语数据库处理的,但Web应用程序是一个Django Python应用程序,需要在某个地方存储数据。
默认情况下,这将配置为使用 SQLite3 数据库文件,但这些文件并不像一个完整的关系数据库管理系统那样强大,所以我们将配置我们的应用程序以使用 PostgreSQL。
安装 PostgreSQL 组件
我们可以通过键入我们需要的数据库软件和辅助包来安装:
1sudo apt-get install postgresql libpq-dev python-psycopg2
这将安装数据库软件,以及Python库,Graphite将使用连接和与数据库进行通信。
创建数据库用户和数据库
安装我们的数据库软件后,我们需要创建一个PostgreSQL用户和数据库,以便使用Graphite。
我们可以通过使用psql命令作为postgres系统用户登录到一个交互式的PostgreSQL提示:
1sudo -u postgres psql
现在,我们需要创建一个数据库用户帐户,Django将使用它在我们的数据库上运作,我们将将用户称为graphite。
CREATE USER graphite WITH PASSWORD 'password';
现在,我们可以创建一个数据库,并给我们的新用户拥有它. 我们将把数据库称为图形,以便轻松识别他们的关联:
1CREATE DATABASE graphite WITH OWNER graphite;
完成后,我们可以退出 PostgreSQL 会话:
1\q
您可能會看到一個訊息,說 Postgres 無法儲存檔案歷史. 這對我們來說不是問題,所以我們可以繼續。
配置 Graphite Web 应用程序
现在,我们有我们的数据库和用户准备好了,但是,我们仍然需要修改Graphite的设置,以便使用我们刚刚配置的组件。
打开 Graphite Web App 配置文件:
1sudo nano /etc/graphite/local_settings.py
首先,我们应该设定将作为盐使用的秘密密密钥,在创建哈希时,删除SECRET_KEY参数,并将值更改为长而独特的值。
SECRET_KEY = 'a_salty_string'
接下来,我们应该指定时区。这会影响我们图表上显示的时间,所以重要的是要设置。 将其设置为您的时区,如TZ列所指定(在本列表中)(http://en.wikipedia.org/wiki/List_of_tz_database_time_zones)。
TIME_ZONE = 'America/New_York'
当我们同步数据库时,我们将能够创建用户帐户,但我们需要通过不评论此行来启用身份验证:
1USE_REMOTE_USER_AUTHENTICATION = True
接下來,尋找「DATABASES」字典定義. 我們要改變值來反映我們的 Postgres 資訊. 您應該改變「NAME」、「ENGINE」、「USER」、「PASSWORD」和「HOST」鍵。
当你完成时,它应该看起来像这样:
DATABASES = {
'default': {
'NAME': 'graphite',
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'USER': 'graphite',
'PASSWORD': 'password',
'HOST': '127.0.0.1',
'PORT': ''
}
}
红色区域是您需要更改的值,请确保您将密码更改为您在 Postgres 中为图形用户选择的密码。
此外,请确保您设置了HOST参数. 如果您放空此参数,Postgres 将认为您正在使用同行身份验证来连接,这在我们的情况下不会正确身份验证。
保存并关闭文件,当你完成。
同步数据库
现在我们已经完成了我们的数据库部分,我们可以同步数据库以创建正确的结构。
您可以通过键入这样做:
1sudo graphite-manage syncdb
您将被要求为数据库创建一个超级用户帐户. 创建一个新的用户,以便您可以登录接口. 您可以将此称为任何您想要的。
碳配置
现在我们有一个数据库,我们可以开始配置碳,图形存储后端。
首先,让我们允许碳服务在启动时启动,我们可以通过打开服务配置文件来做到这一点:
1sudo nano /etc/default/graphite-carbon
这只有一种参数,它决定服务是否会在启动时启动。
1CARBON_CACHE_ENABLED=true
保存并关闭文件。
接下来,打开碳配置文件:
1sudo nano /etc/carbon/carbon.conf
这个文件的大部分已经为我们的目的正确配置,但我们会做出一个小小的改变。
启用日志旋转,将此指令设置调整为 true:
1ENABLE_LOGROTATION = True
保存并关闭文件。
配置存储计划
现在,打开存储方案文件,这告诉 Carbon 要存储值多长时间,这些值应该有多详细:
1sudo nano /etc/carbon/storage-schemas.conf
在里面,你会发现类似于此的条目:
[carbon] pattern = ^carbon\. retentions = 60:90d [default_1min_for_1day] pattern = .* retentions = 60s:1d
该文件目前有两个部分定义,第一个是决定如何处理来自碳本身的数据。碳实际上被配置为存储其自身性能的一些指标。底部定义是一个捕捉所有,旨在适用于任何没有被其他部分匹配的数据。
支架中的单词是用来定义新定义的章节标题,每个章节下方都有模式定义和保留策略。
模式定义是一种常规表达式,用于匹配发送给碳的任何信息. 发送给碳的信息包括一个指标名称,这就是它所检查的。
保留策略是由数组定义的. 每个数组由一个计数间隔(数值被记录的频率)组成,其次是,然后是存储这些值的时间长度。
为了演示,我们将定义一个新的方案,它将匹配我们以后使用的测试值。
在默认部分之前,为我们的测试值添加另一个部分. 让它看起来像这样:
[test] pattern = ^test\. retentions = 10s:10m,1m:1h,10m:1d
它会将收集的数据存储三次,在不同的细节中。第一个档案定义(10s:10m)将每10秒创建一个数据点。
第二个档案(1m:1h)将每分钟创建一个数据点。它将收集过去一分钟的所有数据(六个点,因为前一个档案每10秒创建一个点),并将其合并以创建点。
最后一个将创建的档案(10m:1d)将每10分钟创建一个数据点,以与第二个档案相同的方式汇总数据。
当我们从 Graphite 请求信息时,它会返回最详细的档案信息,测量我们正在请求的时间框架,所以如果我们请求过去五分钟的指标,则将返回第一个档案的信息,如果我们请求过去50分钟的图表,则数据将从第二个档案中提取。
保存并关闭文件,当你完成。
存储聚合方法
在将更详细的信息合并为一般化数字时,碳决定将数据合并的方式非常重要,如果您想要准确的指标,则非常重要。
正如我们上面提到的,默认行为是在汇总时采取平均值,这意味着,除了最详细的档案之外,碳将平均收到的数据点来创建数字。
例如,如果我们想要在不同时间段内发生事件的总次数,我们希望将数据点加起来,以创建我们的通用数据点,而不是平均它们。
我们可以定义我们希望聚合的方式发生在一个名为 storage-aggregation.conf 的文件中. 从 Carbon 示例目录复制到我们的 Carbon 配置目录:
1sudo cp /usr/share/doc/graphite-carbon/examples/storage-aggregation.conf.example /etc/carbon/storage-aggregation.conf
打开文本编辑器中的文件:
1sudo nano /etc/carbon/storage-aggregation.conf
这看起来有点像上一个文件. 你会发现类似于此的条目:
[min] pattern = \.min$ xFilesFactor = 0.1 aggregationMethod = min
部分名称和模式与存储方案文件完全相同. 它只是一个任意的名称和模式来匹配您定义的指标。
XFilesFactor是一个有趣的参数,因为它允许您指定最低百分比的值,碳应该进行汇总。 默认情况下,所有值都设置为0.5,这意味着如果要创建一个汇总点,50%的更详细的数据点必须可用。
例如,如果由于网络问题而丢失 70% 的数据,您可能不希望创建一个只代表数据的 30% 的点。
合并方法是下面的定义。可能的值是平均值、总值、最后值、最小值和最小值. 它们是相当自我解释的,但非常重要。 选择错误的值会导致您的数据以错误的方式记录。
** 注意** :重要的是要注意,如果您比最短的存档间隔长度更频繁地发送图形数据点,则部分数据将丢失!**
这是因为Graphite只在从详细的档案到一般化的档案时应用聚合。在创建详细的数据点时,它只在间隔过去时写入最新的数据,我们将在另一个指南中讨论 StatsD ,这可以通过缓存和聚合以更频繁的间隔来帮助缓解这个问题。
保存并关闭文件。
当你完成时,你可以通过键入开始碳:
1sudo service carbon-cache start
安装和配置Apache
为了使用 Web 界面,我们将安装和配置 Apache Web 服务器. Graphite 包含 Apache 的配置文件,所以选择非常简单。
通过键入安装组件:
1sudo apt-get install apache2 libapache2-mod-wsgi
当安装完成时,我们应该禁用默认的虚拟主机文件,因为它与我们的新文件相冲突:
1sudo a2dissite 000-default
接下来,将 Graphite Apache 虚拟主机文件复制到可用的网站目录:
1sudo cp /usr/share/graphite-web/apache2-graphite.conf /etc/apache2/sites-available
然后我们可以通过键入启用虚拟主机文件:
1sudo a2ensite apache2-graphite
重新加载服务以实现更改:
1sudo service apache2 reload
检查 Web 界面
现在我们已经配置了一切,我们可以检查Web界面。
在您的 Web 浏览器中,访问您的服务器的域名或 IP 地址:
http://server_domain_name_or_IP
你应该看到一个看起来像这样的屏幕:
在您进一步进入之前,您应该登录,以便您可以保存您可能做的任何图形设置。点击顶部菜单栏上的登录按钮,输入您在同步 Django 数据库时配置的用户名和密码。
接下来,如果你在左面板上打开Graphite的树,你应该看到碳的条目。这里是你可以找到碳自己记录的数据的图表的地方。点击几个选项。
现在,让我们尝试向 Graphite 发送一些数据。当您通过这些步骤时,请记住,您几乎从不像这样向 Graphite 发送统计数据。有更好的方法可以做到这一点,但这将有助于展示背景中正在发生的事情,并帮助您了解 Graphite 处理数据的方式的局限性。
计量信息需要包含一个计量名称、一个值和一个时刻印。我们可以在我们的终端中做到这一点。让我们创建一个与我们创建的测试存储方案相匹配的值。我们还将匹配其中一个定义,在汇总时将值加起来。我们将使用日期命令来制作我们的时刻印。
1echo "test.count 4 `date +%s`" | nc -q0 127.0.0.1 2003
如果您刷新页面,然后在左侧的Graphite树上查看,您将看到我们的新测试指标。 发送上面的命令几次,等待至少10秒。
现在,在 Web 界面中,告诉 Graphite 向你展示过去的 8 分钟。在测试指标的图表上,点击图标,这是一个带有绿色箭头的白色直角。
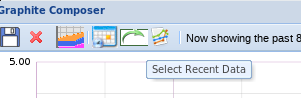
点击表示更新图表的图标以获取最新的数据。您应该看到一个图表,几乎没有任何信息。这是因为您只发送了几个值,每个值都是4,所以它没有变异。
但是,如果您查看过去 15 分钟的图表(假设您发送了命令几次,间隔大于 10 秒,但不到 1 分钟),则应该看到不同的东西:
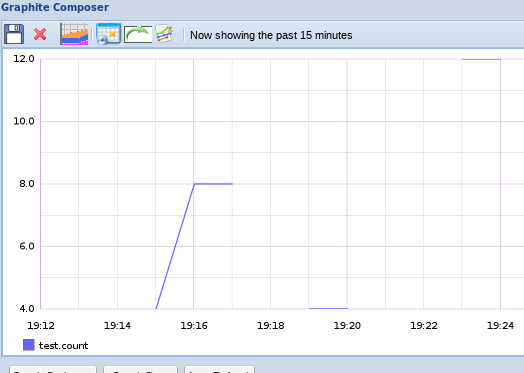
這是因為我們的第一個檔案不會儲存數據十五分鐘,所以 Graphite 尋找我們的第二個檔案來顯示數據。
计数合并告诉格拉菲特在其较大的间隔中收到的值加起来,而不是平均。
结论
您现在已经安装和设置了 Graphite,但它仍然在它所能做的事情上是相当有限的。我们不想经常手动输送数据,我们希望它不会丢弃数据,如果我们在最小间隔内有一个以上的指标。
在下一个指南中,我们将讨论如何设置 collectd一个系统统计数据收集模块,可用于输送图形数据并处理这些限制。