介绍
ArangoDB 是一个 NoSQL 数据库,它创建于 2011 年,当时有很多 NoSQL 数据库已经存在,其目标是成为一个全面的数据库解决方案,可以涵盖各种用例。
在其核心 ArangoDB 是一个 文档存储,但这只是一个开始. 您可以使用完整的查询语言(名为 AQL)查询数据,进行 ACID 合规交易,以其 嵌入式 V8的 JavaScript 应用程序的形式添加自定义 HTTP 终端,等等。
由于ArangoDB有许多功能,起初它可能会令人恐惧,但在第二眼后,它根本不复杂,本文将帮助您安装ArangoDB,并将简要介绍如何使用其核心功能。
完成本教程后,你应该能够:
- 安装 ArangoDB 在 Ubuntu 14.04
- 配置 ArangoDB for basic usage
- 插入、修改和查询 data
核心概念
在整个文章中,我们将使用一些核心概念,您可能希望在建立 ArangoDB 项目之前熟悉这些概念:
- _文档存储 _: 阿朗戈 DB在文档中存储数据,与关系数据库存储数据的方式形成对比. 文档是任意的数据结构,由_key-value coups_所组成. _key_是一个将_value_命名的字符串(类似于关系数据库中的一列). _value_可以是任何数据类型,甚至另一个文档. 文档没有绑定到任何 schema. _Qwery Language:使用API或查询语言与您的数据交互. 虽然前者留给API用户很多细节,但一个查询语言将细节交给了数据库. 在关系数据库中,SQL是一个查询语言的测试包. ACID:四个属性A 通取性, C** 通取性,** I** 通取性,和** D** 耐取性描述数据库交易的保证. ArangoDB 支持符合 ACID 的交易. *V8: Google 的 JavaScript 引擎,可以授权 Chrome也可以轻易地被嵌入到其他软件中去. 在 ArangoDB 中使用它可以使用数据库中的 JavaScript 。 阿兰戈大部分地区 DB的内部功能由JavaScript. *HTTP API:ArangoDB提供HTTP API,允许客户端与数据库互动. API是[资源导向 (https://en.wikipedia.org/wiki/Representational_state_transfer),可以用JavaScript. 来扩展
前提条件
在我们开始之前,请确保您的 Droplet 设置正确:
- 使用 Ubuntu 14.04 创建一个 Droplet x64
- 添加一个 sudo 用户
现在你应该使用新创建的用户登录到你的服务器. 教程中的所有示例都可以从用户的家庭目录中执行:
1cd ~
步骤1:安装 ArangoDB
ArangoDB 是针对许多操作系统和发行版的预先构建版,很可能你不需要从源头上构建它,要了解更多细节,请参阅 ArangoDB 文档。
由于 ArangoDB 使用了 OpenSUSE 的 构建服务,所以首先要下载其存储库的公共密钥:
1wget https://www.arangodb.com/repositories/arangodb2/xUbuntu_14.04/Release.key
你需要sudo来安装密钥:
1sudo apt-key add Release.key
然后添加 apt 存储库并更新索引:
1sudo apt-add-repository 'deb https://www.arangodb.com/repositories/arangodb2/xUbuntu_14.04/ /'
2sudo apt-get update
安装 ArangoDB:
1sudo apt-get install arangodb
我们可以通过查询 HTTP API 来检查一切是否顺利:
1curl http://localhost:8529/_api/version
以下输出表示 ArangoDB 已启动并运行:
1[secondary_label Output]
2{"server":"arango","version":"2.5.5"}
步骤 2 – 使用 arangosh 访问命令行
ArangoDB配备了arangosh,一个命令行客户端,通过其JavaScript运行时间为您提供完全访问数据库,您可以使用它来执行管理任务或编写脚本。
它也非常适合开始使用 ArangoDB 及其核心功能,如下所示,请开始一个arangosh会话:
1arangosh
结果基本上是一个JavaScript壳,你可以运行任意JavaScript代码,例如,添加两个数字:
123 + 19
你会得到这个结果:
1[secondary_label Output]
242
如果你想深入这个主题,请在壳中输入教程。
步骤 3 – 添加数据库用户
出于安全原因,仅可以从arangosh命令行界面添加用户,您还应该从上一步进入arangosh壳。
现在,让我们添加一个新的用户, sammy . 这个用户将可以访问整个数据库. 此时此处是好的,但您可能希望在生产环境中创建更有限的用户。
1require("org/arangodb/users").save("sammy", "password");
现在离开arangosh壳:
1exit
步骤 4 – 配置 Web 界面
ArangoDB具有非常强大的 Web 界面,提供监控功能,数据浏览,交互式 API 文档,强大的查询编辑器,甚至是一个集成的arangosh。
为了使 Web 界面易于访问,我们需要做一些准备:
启用验证 2 将 ArangoDB 连接到公共网络接口
允许身份验证
ArangoDB 和许多其他 NoSQL 数据库一样,具有禁用身份验证的船只。如果您在共享环境中运行 ArangoDB 或想要使用 Web 接口,强烈建议启用身份验证,请参阅 ArangoDB 文档。
在 /etc/arangodb/arangod.conf 文件中激活身份验证. 您可以运行此命令创建备份文件并将 disable-authentication 参数设置为 no:
1sudo sed -i.bak 's/disable-authentication = yes/disable-authentication = no/g' /etc/arangodb/arangod.conf
或者,使用文本编辑器将禁用身份验证参数设置为不。
重新启动数据库:
1sudo service arangodb restart
将 ArangoDB 连接到公共网络接口
配置 ArangoDB 以在公共网络界面上聆听。 首先,打开 /etc/arangodb/arangod.conf 文件以编辑:
1sudo nano /etc/arangodb/arangod.conf
查找活跃的终点行,该行应该位于[服务器]块的末尾,示例部分下方更新如下所示的设置,使用您自己的服务器的IP地址和端口8529。
1[label /etc/arangodb/arangod.conf]
2
3. . .
4
5endpoint = tcp://your_server_ip:8529
由于arangosh 使用了自己的默认配置,所以我们也需要在 `/etc/arangodb/arangosh.conf 文件中更改端点:
1sudo nano /etc/arangodb/arangosh.conf
再次,请确保终点行设置为tcp://your_server_ip:8529。
1[label /etc/arangodb/arangosh.conf]
2pretty-print = true
3
4[server]
5endpoint = tcp://your_server_ip:8529
6disable-authentication = true
7
8. . .
<$>[注] 如果您更愿意运行两个多部分,一行命令来更新这两个文件,则可以运行以下命令:
1sudo sed -i.bak "s/^endpoint = .*/endpoint = tcp:\/\/$(sudo ifconfig eth0 | grep "inet " | cut -d: -f 2 | awk '{print $1}'):8529/g" /etc/arangodb/arangod.conf
1sudo sed -i.bak "s/^endpoint = .*/endpoint = tcp:\/\/$(sudo ifconfig eth0 | grep "inet " | cut -d: -f 2 | awk '{print $1}'):8529/g" /etc/arangodb/arangosh.conf
这些模糊的命令将提取当前的公共 IP 地址,并取代默认的绑定地址(127.0.0.1)。
现在再重新启动 ArangoDB:
1sudo service arangodb restart
步骤 5 – 访问 ArangoDB Web 接口
现在您应该能够访问您的浏览器中的 Web 界面:
1http://your_server_ip:8529
请使用您在步骤 3 中为数据库创建的用户名和密码登录。
<$>[警告] _警告:_虽然我们设置了身份验证,但传输尚未安全。在生产中,如果您从另一个主机访问 ArangoDB,您应该设置 TLS 加密。
您应该看到的第一个屏幕是指令板,其中包含有关数据库服务器的基本指标:
在顶部导航的中心,你会看到 DB: _system . 这表示当前选择的数据库. 默认是 _system 数据库. 某些管理任务只能在 _system 数据库中执行。
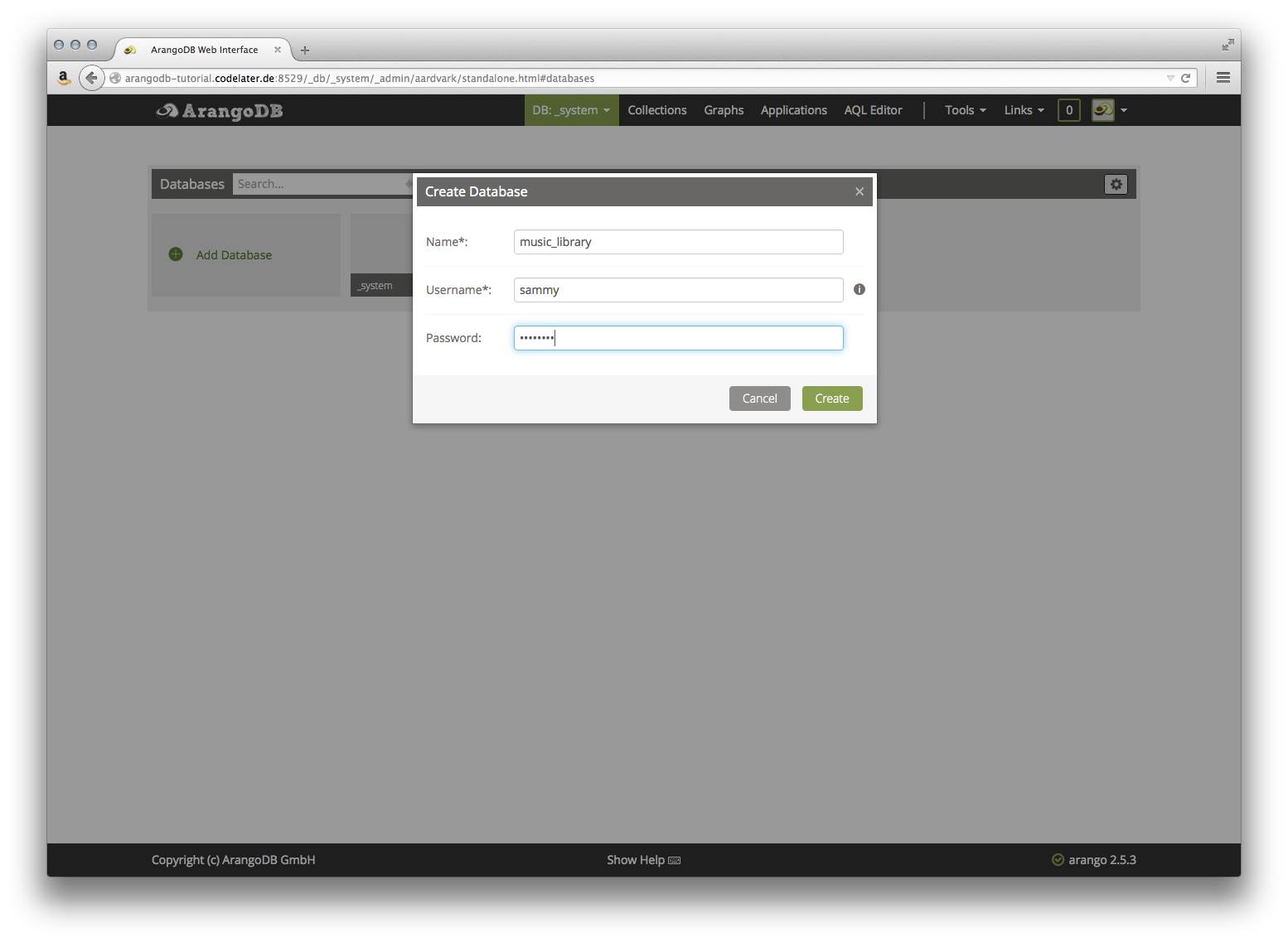
对于下列部分,我们将创建一个数据库,以便与之合作. 穿过 DB: _system 菜单项目,然后点击 ** Manage DBs** 链接。
在以下页面上,单击添加数据库按钮,填写表格以创建名为music_library的数据库,您必须在此对话中输入与之前相同的用户名和密码,否则您将无法在以后访问新数据库:
我们现在已经准备好开始实际上在ArangoDB上做一些事情。
步骤 6 – 使用 arangosh 执行 CRUD 操作
我们将暂时离开 Web 界面并返回 arangosh 命令行界面,以覆盖 ArangoDB 的基本 CRUD 操作,随后我们将再次覆盖 Web 界面中的相同操作,但在壳中进行操作有助于我们更好地了解事物如何工作。
若要跟进,请返回您的服务器的命令行. 使用您的用户和密码连接到新的music_library数据库:
1arangosh --server.database music_library --server.username sammy --server.password password
创建一个文档收藏
如果您来自关系数据库背景,则集合是 SQL 数据库中的表的 ArangoDB 等级,我们将创建一个集合来存储歌曲在我们的音乐库中:
1db._createDocumentCollection('songs')
ArangoDB 提供了一系列 管理收藏的方法. 其中大多数在这个时候并不感兴趣,但请在深入 ArangoDB 时仔细看看它们。
创建文件
在基于 SQL 的数据库中,ArangoDB 有 Documents。ArangoDB 中的文档是 JSON 对象. 每个文档都与一个集合相关,并且有三个核心属性: _id、 _rev 和 _key。
文档在数据库中被其 文档处理器所唯一识别,该文件由集合名称和 _key 组成,分隔为 /.文档处理器存储在文档的 _id 字段中。
<$>[注]
注: 如果你自己不指定任何东西,ArangoDB将为每个文档创建一个_key。如果你愿意,你可以指定一个自定义的_key,但你需要确保它是独一无二的。
让我们把我们的第一个文档添加到歌曲收藏中:
1db.songs.save(
2{ title: "Immigrant Song", album: "Led Zeppelin III", artist: "Led Zeppelin", year: 1970, length: 143, _key: "immigrant_song" }
3)
1[secondary_label Output]
2{
3 "error" : false,
4 "_id" : "songs/immigrant_song",
5 "_rev" : "11295857653",
6 "_key" : "immigrant_song"
7}
db对象将所有集合作为属性。每个集合都提供了与该集合中的文档互动的函数。保存函数将任何JSON对象存储为集合中的文档,返回上述核心属性以及是否发生错误。
要有东西要玩,我们需要一些更多的文档. 只需复制并粘贴下一个片段来添加更多的数据库条目:
1db.songs.save(
2{album: "Led Zeppelin III", title: "Friends", artist: "Led Zeppelin", year: 1970, length: 235, _key: "friends"}
3);
4
5db.songs.save(
6{album: "Led Zeppelin III", title: "Celebration Day", artist: "Led Zeppelin", year: 1970, length: 209, _key: "celebration_day"}
7);
8
9db.songs.save(
10{album: "Led Zeppelin III", title: "Since I've Been Loving You", artist: "Led Zeppelin", year: 1970, length: 445, _key: "since_i_ve_been_loving_you"}
11);
12
13db.songs.save(
14{album: "Led Zeppelin III", title: "Out On the Tiles", artist: "Led Zeppelin", year: 1970, length: 244, _key: "out_on_the_tiles"}
15);
16
17db.songs.save(
18{album: "Led Zeppelin III", title: "Gallows Pole", artist: "Led Zeppelin", year: 1970, length: 298, _key: "gallows_pole"}
19);
20
21db.songs.save(
22{album: "Led Zeppelin III", title: "Tangerine", artist: "Led Zeppelin", year: 1970, length: 192, _key: "tangerine"}
23);
24
25db.songs.save(
26{album: "Led Zeppelin III", title: "That's the Way", artist: "Led Zeppelin", year: 1970, length: 338, _key: "that_s_the_way"}
27);
28
29db.songs.save(
30{album: "Led Zeppelin III", title: "Bron-Y-Aur Stomp", artist: "Led Zeppelin", year: 1970, length: 260, _key: "bron_y_aur_stomp"}
31);
32
33db.songs.save(
34{album: "Led Zeppelin III", title: "Hats Off to (Roy) Harper", artist: "Led Zeppelin", year: 1970, length: 221, _key: "hats_off_to_roy_harper"}
35);
阅读文件
要获取文档,您可以使用文档握手或_key。 使用文档握手只需要在您不超过收藏本身的情况下。
1db.songs.document('immigrant_song');
1[secondary_label Output]
2{
3 "year" : 1970,
4 "length" : 143,
5 "title" : "Immigrant Song",
6 "album" : "Led Zeppelin III",
7 "artist" : "Led Zeppelin",
8 "_id" : "songs/immigrant_song",
9 "_rev" : "11295857653",
10 "_key" : "immigrant_song"
11}
现在我们可以创建和阅读文档,我们将看看如何更改它们:
文件更新
在更新您的数据时,您有两种选择: replace和 update。
替换函数将用新的代替整个文档,即使您提供完全不同的属性。
另一方面,更新函数只会通过将其与所述属性合并来修补一个文档,让我们先尝试一种不太破坏性的更新,在那里我们更新了我们的一首歌曲的流派:
1db.songs.update("songs/immigrant_song",
2
3{ genre: "Hard Rock" }
4
5);
让我们来看看更新后的歌曲入口:
1db.songs.document("songs/immigrant_song");
1[secondary_label Output]
2{
3 "year" : 1970,
4 "length" : 143,
5 "title" : "Immigrant Song",
6 "album" : "Led Zeppelin III",
7 "artist" : "Led Zeppelin",
8 "genre" : "Hard Rock",
9 "_id" : "songs/immigrant_song",
10 "_rev" : "11421424629",
11 "_key" : "immigrant_song"
12}
更新函数特别有用,当您有一个大文件,只需要更新其属性的一小部分时。
相反,使用与替换函数相同的 JSON 将破坏您的数据。
1db.songs.replace("songs/immigrant_song",
2
3{ genre: "Hard Rock" }
4
5);
现在再来看看更新后的歌曲:
1db.songs.document("songs/immigrant_song")
正如您所看到的,原始数据已从文档中删除:
1[secondary_label Output]
2{
3 "genre" : "Hard Rock",
4 "_id" : "songs/immigrant_song",
5 "_rev" : "11495939061",
6 "_key" : "immigrant_song"
7}
删除文件
若要从集合中删除文档,请使用文档处理器调用删除函数:
1db.songs.remove("songs/immigrant_song")
虽然arangosh壳是一个很好的工具,但它很难探索ArangoDB的其他功能,接下来我们将研究内置的Web界面,以进一步挖掘其功能。
步骤 7 – 使用 Web 接口执行 CRUD 操作
我们已经看到了如何在arangosh上处理文档,现在我们回到网页界面。 访问您的浏览器中的http://your_server_ip:8529/_db/music_library。
创建一个文档收藏
点击顶部导航栏中的收藏选项卡。
您可以从命令行查看我们添加的现有歌曲收藏;如果您喜欢,请点击它并查看条目。
从主页 ** 收藏 ** 点击 ** 添加收藏 ** 按钮。
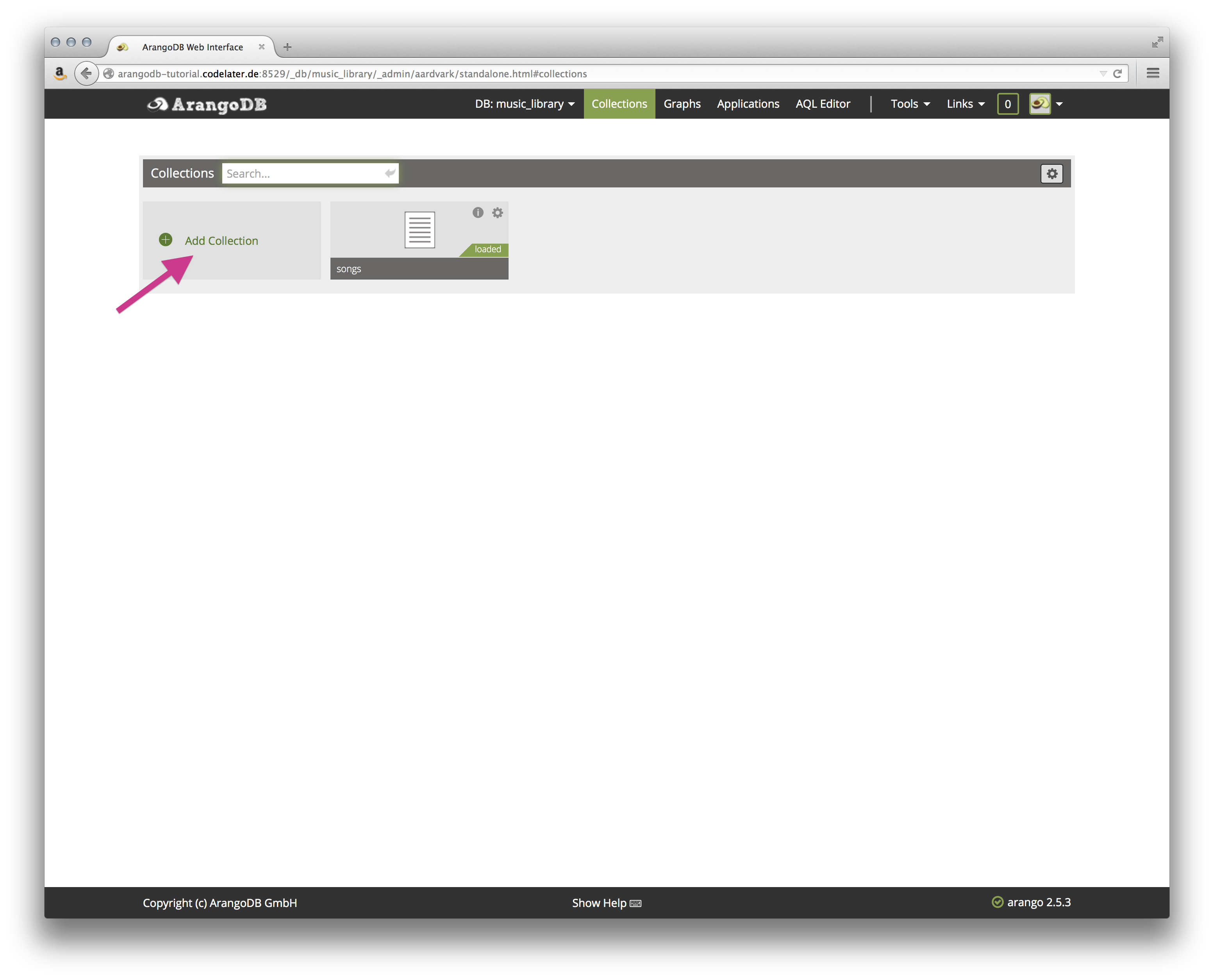
由于我们已经有歌曲,我们将添加一个专辑收藏。输入专辑作为名称在出现的新收藏对话框中。
点击保存,您现在应该在页面上看到两个集合。
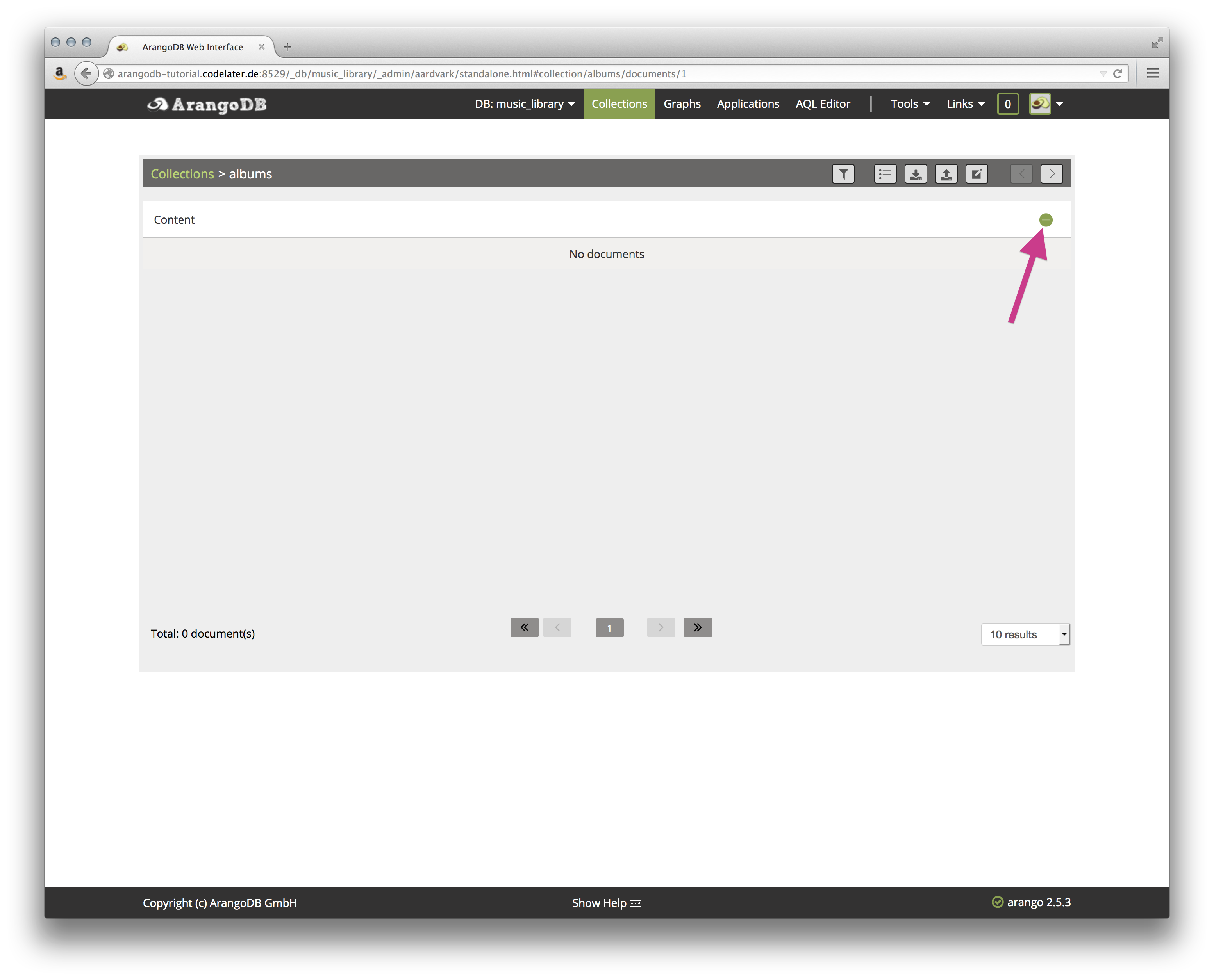
点击专辑收藏. 您将呈现一个空的收藏:
创建文件
点击右上角的 + 标志来添加文档. 您将首先被要求为一个 _key. 输入 led_zeppelin_III作为密钥。
接下来有一个表格,您可以编辑文档的内容. 有一个名为 Tree 的属性添加的图形方式,但目前,您可以从 ** Tree** 下载菜单中选择 ** Code** 视图:
请将下列 JSON 复制并粘贴到编辑器区域(请确保您只使用一组曲线):
1{
2"name": "Led Zeppelin III",
3"release_date": "1970-10-05",
4"producer": "Jimmy Page",
5"label": "Atlantic",
6"length": 2584
7}
请注意,在此模式中需要引用密钥。完成后,点击保存按钮。页面应该闪烁绿色一会儿,表示保存成功。
阅读文件
您需要在保存新文档后手动返回收藏页面。
如果你点击专辑集合,你会看到新的条目。
文件更新
若要编辑文档的内容,只需在文档概览中点击您想要编辑的行,您将收到与创建新文档时相同的编辑器。
删除文件
删除文档就像在每个文档行末尾按 - 图标一样简单。
此外,特定集合的 ** 收藏 ** 概览页面允许您导出和导入数据,管理索引,并过滤文档。
如前所述,Web界面有很多可供提供的。涵盖每一个功能都超出了本教程,所以您被邀请自行探索其他功能。
步骤 8 – 使用 AQL 查询数据
正如介绍中提到的,ArangoDB 配备了一个名为 AQL 的完整查询语言。
要在 Web 界面中与 AQL 进行交互,请点击顶部导航中的 AQL 编辑器 选项卡。
要在编辑器和结果视图之间切换,请使用右上角的 Query 和 ** Result** 选项卡:
编辑器具有语法突出,取消/删除功能,以及查询保存。下面的部分将探索AQL的一些功能. 对于完整的参考,请访问 全面文档。
AQL 基本
AQL是一个宣言语言,这意味着一个查询表达了应该达到的结果,而不是如何实现它。它允许查询数据,但也允许修改数据。
在 AQL 中读取和修改查询完全符合 ACID 的要求,操作要么完全完成,要么根本没有完成。
我们再次开始创建数据. 让我们在我们的歌曲收藏中添加更多歌曲. 只需复制并粘贴以下查询:
1FOR song IN [
2
3{ album: "Led Zeppelin", title: "Good Times Bad Times", artist: "Led Zeppelin", length: 166, year: 1969, _key: "good_times_bad_times" }
4
5,
6
7{ album: "Led Zeppelin", title: "Dazed and Confused", artist: "Led Zeppelin", length: 388, year: 1969, _key: "dazed_and_confused" }
8
9,
10
11{ album: "Led Zeppelin", title: "Communication Breakdown", artist: "Led Zeppelin", length: 150, year: 1969, _key: "communication_breakdown" }
12
13]
14
15INSERT song IN songs
点击提交按钮。
此查询已经是 AQL 工作方式的一个很好的例子:您通过FOR重复一个文档列表,并对每个文档执行操作。 该列表可能是您的数据库中的 JSON 对象或任何集合的数组。 操作包括过滤、修改、选择更多文档、创建新结构或(如本示例)将文档插入数据库。
要查看数据库中的所有歌曲,请运行以下查询. 它相当于 SQL 数据库中的SELECT * FROM 歌曲 (由于编辑器记得最后一个查询,您应该点击 trash can 图标来清除编辑器):
1FOR song IN songs RETURN song
现在你会看到歌曲数据库中的所有条目在文本框中. 返回 Query 选项卡,然后再次清除编辑器。
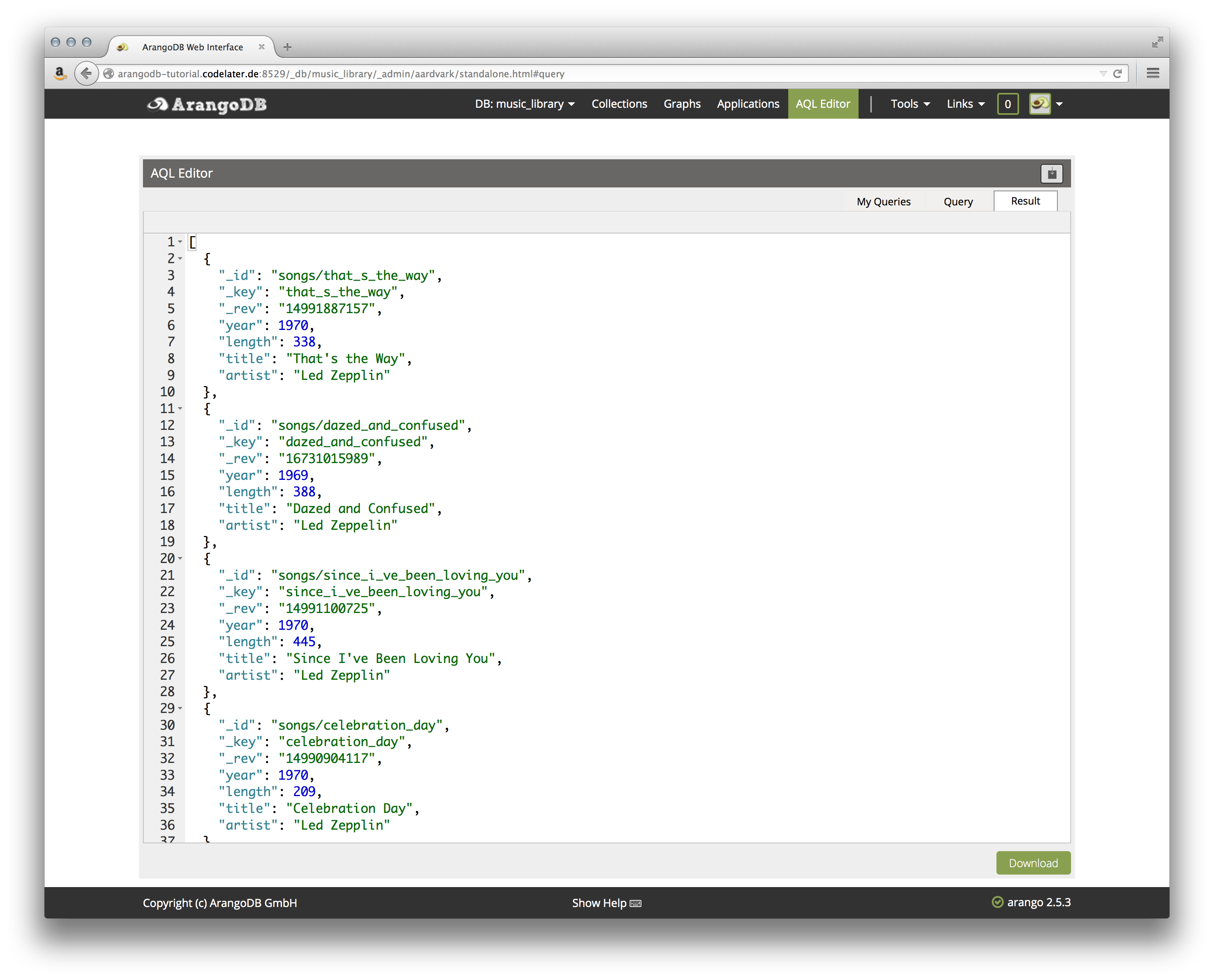
另一個例子包括超過三分鐘播放時間的歌曲的基本過濾:
1FOR song IN songs
2
3FILTER song.length > 180
4
5RETURN song
结果在编辑器的 ** 结果** 选项卡中呈现:
复杂的 AQL 示例
AQL 为所有受支持的数据类型提供了一套 函数集,甚至允许 添加新函数。 与在查询中分配变量的能力相结合,您可以构建非常复杂的构件。 这允许您将数据密集的操作更接近数据本身,而不是在客户端上执行它们。
1FOR song IN songs
2
3FILTER song.length > 180
4
5LET minutes = FLOOR(song.length / 60)
6
7LET seconds = song.length % 60
8
9RETURN
10
11{ title: song.title, duration: CONCAT_SEPARATOR(':', minutes, seconds) }
这一次,我们只会返回歌曲的标题和持续时间,而RETURN允许您为每个输入文档创建一个新的JSON对象。
AQL是一个具有许多功能的复杂语言,但还有一个值得一提的功能,尤其是在NoSQL数据库的背景下:加入。
加入 AQL
使用文档存储作为您的数据库有几个影响. 您应该以不同的方式对数据进行建模,而不是在使用关系数据库时。
在文档存储中,您可以嵌入其他情况下将数据建模为关系的数据,但这种方法并不总是可行的. 有些情况下,一个关系更有意义。 没有让数据库执行所需的合并的能力,您最终会连接客户端上的数据,或消极化您的数据模型并嵌入子文档。
那么,让我们一起加入吧。
为了说明这个功能,我们将将歌曲的专辑属性替换为专辑收藏的参考。我们以前已经创建了专辑 Led Zeppelin III 作为文件。
这个查询将成为这个伎俩:
1FOR album IN albums
2
3FOR song IN songs
4
5FILTER song.album == album.name
6
7LET song_with_album_ref = MERGE(UNSET(song, 'album'),
8
9{ album_key: album._key }
10
11)
12
13REPLACE song WITH song_with_album_ref IN songs
我们首先重复所有专辑,然后搜索所有这张专辑相关的歌曲。下一步是创建一个包含album_key属性和UNSET属性的新文档。我们将使用REPLACE而不是UPDATE更新歌曲文档。
此数据迁移后,我们现在可以将专辑文档保留在一个位置. 当收集歌曲数据时,我们可以使用连接来重新添加专辑名称到歌曲文档:
1FOR song IN songs
2
3FOR album IN albums
4
5FILTER album._key == song.album_key
6
7RETURN MERGE(song,
8
9{ album: album.name }
10
11)
我们几乎没有弄清楚AQL可以实现的表面,但你应该有一个很好的印象,什么是可能的。
(可选)步骤 9 – 创建备份
您应该开始考虑备份,一旦您将ArangoDB数据库投入生产,但在此之前建立备份是很好的做法。
此外,你可能想看看使用 arangodump和 arangorestore)有更精确的控制什么备份和存储备份的地方。
(可选)步骤 10 – 升级
发布新的 ArangoDB 版本时,它将通过配置的包库进行发布. 要安装最新版本,您需要先更新库索引:
1sudo apt-get update
现在停止数据库:
1sudo service arangodb stop
更新至最新版本:
1sudo apt-get install arangodb
<$>[note]
_ 注意:_ 安装更新后,系统会尝试启动 arangodb 服务. 这可能会因为数据库文件需要升级而失败。
您可能需要自行升级数据库文件:
1sudo service arangodb upgrade
然后,像往常一样启动服务器:
1sudo service arangodb start
通过Foxx应用程序扩展ArangoDB
在我们完成之前,还有一个值得一提的事情:由于ArangoDB有一个集成的V8引擎来处理所有JavaScript,并且它有一个内置的HTTP服务器,我们可以用自定义终端扩展现有的HTTP API。
Foxx 是一个框架,用于使用 ArangoDB 构建自定义微服务,使用持久数据。Foxx 应用程序以 JavaScript 编写,并在 ArangoDB 的 V8 背景下运行。该应用程序可以直接访问原生 JavaScript 接口,因此可以访问数据,而无需任何 HTTP 周期旅行。Foxx 提供了在 Sinatra for Ruby 或 Flask for Python 的意义上最小的框架。你编写控制器来处理到来的请求,并在模型中实施业务逻辑。
Foxx 应用程序可以通过 Web 界面进行管理,可以像任何其他应用程序一样开发,您可以将它们置于版本控制下,甚至可以直接从 Git 存储库中部署它们. 因为它们只是 JavaScript,单元测试它们很简单。
使用Foxx应用程序作为存储程序只是一个开始。想象一下,你有多个应用程序共享某些业务逻辑. 有了Foxx,你可以将这个业务逻辑更接近数据,使处理更快,并减少在组件之间分发共享实现的复杂性。
使用前端框架,如 Angular 或 Ember,您可以完全从数据库中运行应用程序. 无需额外的基础设施。 在生产环境中,您最终会把 Nginx 或类似的应用程序放在 ArangoDB 前面。 ArangoDB 搭载一些提供通用功能的 Foxx 应用程序,如身份验证和会话存储。 您甚至可以使用 npm 包,如果它们不依赖 HTTP 功能。
对于Foxx的良好介绍,请参阅此 cookbook。
结论
ArangoDB是一个强大的数据库,具有广泛的受支持的使用案例。它保持良好,并具有非常好的文档。 开始使用它很容易,因为每个主要操作系统都有包。 Web 界面降低了探索功能的负担,如果你来自关系背景,使用 AQL 与使用 SQL 没有那么不同。
有了可以用JavaScript应用程序扩展数据库的选项,以及图形功能,使ArangoDB成为一个完整的包,让应用程序启动和成长。
到目前为止,我们已经分享了ArangoDB的大图像。
作为下一步,我们建议如下:
- 对于任何真正的应用程序,您将与 HTTP API 进行交互。我们没有在这里覆盖它,因为您很可能不会直接使用它,而是通过许多 母语驱动程序之一。
- 在 ArangoDB 中与数据进行交互,大部分时间都是通过 AQL。如果您想在生产环境中使用 ArangoDB,必须使用它。
- ArangoDB不仅是一个文档存储器,而且还具有非常强大的图形功能。它允许您在定向图表中模拟数据顶点。