介绍
文本数据存在于许多不同的形式,从新闻到社交媒体到电子邮件. 当我们分析和可视化文本数据时,我们可以揭示一般趋势,这些趋势可以改变我们解释文本的方式。
在本教程中,我们将探索在文本中绘制单词频率. 我们将创建的程序将搜索一个简单的文本文档,并根据其频率组织每个单词。
前提条件
要能够使用本教程,请确保您具备以下前提条件:
- 您应该有 Python 3 和已安装在您的本地计算机(https://www.digitalocean.com/community/tutorial_series/how-to-install-and-set-up-a-local-programming-environment-for-python-3)或服务器(https://andsky.com/tech/tutorials/how-to-install-python-3-and-set-up-a-programming-environment-on-an-ubuntu-16-04-server)上的编程环境。 * 为了充分利用本指南,您应该熟悉 Python 3 以及关于 字典数据类型的知识。
最后,请确保您遵循 步骤 1 - 导入 matplotlib 我们的 如何在 Python 3 使用 matplotlib 的 Plot 数据,因为对于这个项目,安装 matplotlib 至关重要。
步骤1 - 设置程序文件
现在我们已经在计算机上安装了matplotlib,我们可以开始创建我们的项目。
使用您选择的文本编辑器,创建一个新的Python文件,并将其称为word_freq.py。
在这个程序中,我们将 进口 matplotlib 和我们需要的 类 (这是 pyplot),通过它 plt alias 。
1[label word_freq.py]
2import matplotlib.pyplot as plt
接下来,我们将在Python中导入一些默认包,这些包将用于设置和输入命令行输入. 需要注意的重要包是argparse。
让我们在 Python 中导入以下默认包:
1[label word_freq.py]
2import matplotlib.pyplot as plt
3import sys
4import operator
5import argparse
最后,创建标准的主要方法和调用,内部的主要方法是我们将写大部分代码的地方。
1[label word_freq.py]
2import matplotlib.pyplot as plt
3import sys
4import operator
5import argparse
6
7def main():
8
9if __name__ == "__main__":
10 main()
现在我们已经导入了一切,并为我们的项目设置了骨骼,我们可以继续使用我们已经导入的包。
步骤 2 – 设置参数参数
对于这个部分,我们将创建命令行论点,并将它们存储在一个 变量以便快速访问。
在我们的主要方法中,让我们创建我们的分析变量,并将其分配到默认构建器argparse提供,然后我们将分配我们将在文件中寻找的单词的预期参数。
1[label word_freq.py]
2...
3def main():
4 parser = argparse.ArgumentParser()
5 parser.add_argument(
6 "word",
7 help="the word to be searched for in the text file."
8 )
9 parser.add_argument(
10 "filename",
11 help="the path to the text file to be searched through"
12 )
13
14if __name__ == "__main__":
15 main()
目前,方法中的第一个参数是指令行中我们所期望的内容的标题,第二个参数 `help= "..." 被用来为用户提供指令行参数应该是什么样的信息。
接下来,我们将保存给出的参数到另一个变量中,我们将称之为args。
1[label word_freq.py]
2...
3def main():
4 parser = argparse.ArgumentParser()
5 parser.add_argument(
6 "word",
7 help="the word to be searched for in the text file."
8 )
9 parser.add_argument(
10 "filename",
11 help="the path to the text file to be searched through"
12 )
13
14 args = parser.parse_args()
15
16if __name__ == "__main__":
17 main()
为了一个好的尺度,我们应该总是检查我们的输入,如果命令行参数中有一个打字符号。 这也是为了防止我们的脚本突然崩溃。
1[label word_freq.py]
2...
3def main():
4 ...
5 args = parser.parser_args()
6
7 try:
8 open(args.filename)
9
10 except FileNotFoundError:
11 sys.stderr.write("Error: " + args.filename + " does not exist!")
12 sys.exit(1)
13
14if __name__ == "__main__":
15 main()
我们正在使用sys.exit(1)来向用户表示,代码存在问题,并且无法成功完成。
我们的项目现在可以使用命令行参数,下一步是解析我们的输入文件。
步骤 3 - 解析文件
在此步骤中,我们将采取一个文件,阅读每个单词,记录它们的出现频率,并将其全部保存到一个字典数据类型。
让我们创建一个名为word_freq()的函数(https://andsky.com/tech/tutorials/how-to-define-functions-in-python-3),它需要两个命令行参数(单词和文件名),然后在main()中调用该函数。
1[label word_freq.py]
2...
3def main():
4 ...
5 word_freq(args.word, args.filename)
6
7def word_freq(word, filename):
8
9if __name__ == "__main__":
10 main()
解析文件的第一步是创建一个词典数据类型,我们将称之为doc。这将保留文件中发现的每个单词,并跟踪它出现了多少次。
1[label word_freq.py]
2...
3def word_freq( word, filename ):
4 doc = {}
5
6if __name__ == "__main__":
7 main()
接下来的步骤是通过给定的文件进行迭代,这是用一个 nested for loop进行的。
第一个for循环旨在打开文件并从中取出第一个行,然后采取每个行中的内容,并根据单词之间的白空间字符串进行分割,同时将单词存储在一个数组中。
第二个for循环采取了这个数组,然后循环通过它检查它是否在字典中或没有。
1[label word_freq.py]
2...
3def word_freq(word, filename):
4 doc = {}
5
6 for line in open(filename):
7 split = line.split(' ')
8 for entry in split:
9 if (doc.__contains__(entry)):
10 doc[entry] = int(doc.get(entry)) + 1
11 else:
12 doc[entry] = 1
13
14if __name__ == "__main__":
15 main()
现在,我们已经完成了这个项目的一半。
要复制,‘我们的主要()’方法应该设置我们的命令行输入,并将其传送到‘word_freq()’函数。
接下来,我们将采取这些数据,并在我们的图表中进行使用。
步骤4 - 存储和排序数据
在我们创建图表之前,我们必须确保该单词实际上存在于我们打开的文件中,我们可以用一个 if 条件陈述来做到这一点。
1[label word_freq.py]
2...
3def word_freq(word, filename):
4 ...
5 else:
6 doc[entry] = 1
7 if (not word in doc):
8 sys.stderr.write("Error: " + word + " does not appear in " + filename)
9 sys.exit(1)
10
11if __name__ == "__main__":
12 main()
现在我们知道这个词在文件中,我们可以开始为我们的图表设置数据。
首先,我们必须从最高到最低的字典数据类型进行分类,并为以后的使用初始化变量,我们必须将我们的字典分类,以便在图表上适当地可视化。
1[label word_freq.py]
2...
3def word_freq(word, filename):
4 ...
5 if (not word in doc):
6 sys.stderr.write("Error: " + word + " does not appear in " + filename)
7 sys.exit(1)
8
9 sorted_doc = (sorted(doc.items(), key = operator.itemgetter(1)))[::-1]
10 just_the_occur = []
11 just_the_rank = []
12 word_rank = 0
13 word_frequency = 0
14
15if __name__ == "__main__":
16 main()
要注意的两个变量是 just_the_occur,这就是包含一个单词出现了多少次的数据,另一个变量是 just_the_rank,这就是将包含有关单词排名数据的变量。
现在我们有排序字典,我们将循环通过它来找到我们的单词和排名,以及填充我们的图表与这些数据。
1[label word_freq.py]
2...
3def word_freq( word, filename ):
4 ...
5
6 sortedDoc = (sorted(doc.items(), key = operator.itemgetter(1)))[::-1]
7 just_the_occur = []
8 just_the_rank = []
9 word_rank = 0
10 word_frequency = 0
11
12 entry_num = 1
13 for entry in sorted_doc:
14 if (entry[0] == word):
15 word_rank = entryNum
16 word_frequency = entry[1]
17
18 just_the_rank.append(entry_num)
19 entry_num += 1
20 just_the_occur.append(entry[1])
21
22if __name__ == "__main__":
23 main()
在这里,我们必须确保两个变量just_the_occur和just_the_rank都是相同的长度,否则matplotlib不会让我们创建图表。
我们还在循环中添加了一个如果,以找到我们的单词(我们已经知道它在那里),并提取其排名和频率。
现在我们拥有创建我们的图表所需的一切,我们的下一步是最终创建它。
步骤5:创建图表
在这一点上,我们可以插入我们最初创建的plt变量. 为了创建我们的图表,我们需要一个标题,y轴标签,x轴标签,一个尺度和一个图表类型。
在我们的情况下,我们将创建一个日志基础10图形来组织我们的数据. 标题和轴标签可以是任何你想要的,但描述性越大,它将是更好的人谁正在看你的图形。
1[label word_freq.py]
2...
3def word_freq( word, filename ):
4 ...
5 just_the_rank.append(entry_num)
6 entry_num += 1
7 just_the_occur.append(entry[1])
8
9 plt.title("Word Frequencies in " + filename)
10 plt.ylabel("Total Number of Occurrences")
11 plt.xlabel("Rank of word(\"" + word + "\" is rank " + str(word_rank) + ")")
12 plt.loglog(
13 just_the_rank,
14 just_the_occur,
15 basex=10
16 )
17 plt.scatter(
18 [word_rank],
19 [word_frequency],
20 color="orange",
21 marker="*",
22 s=100,
23 label=word
24 )
25 plt.show()
26
27if __name__ == "__main__":
28 main()
标题, plt.ylabel() 和 plt.xlabel() 函数为每个轴的标签。
plt.log()函数分别为 x 和 y 轴使用just_the_rank和just_the_occur。
我们更改日志基础并将其设置为10。
然后,我们设置了插曲以散布并突出我们的点,我们把它变成一个橙色的星星,大小为100,所以它是发音的。
一旦为我们的图表完成了所有操作,我们会告诉它以plt.show()显示。
现在我们的代码终于完成了,我们可以测试运行它。
步骤6 - 运行程序
对于我们的文本样本,我们需要一个文本文件来阅读,所以让我们下载一个来自Gutenberg项目,一个志愿者项目,为读者提供免费的电子书(主要是在公共领域)。
让我们将小说文本 A Tale of Two Cities 保存为一个名为cities.txt的文件,并将其卷入我们的当前目录中,其中包含我们的Python脚本:
1curl http://www.gutenberg.org/files/98/98-0.txt --output cities.txt
接下来,让我们运行我们的代码,通过我们选择的单词的参数(我们将使用鱼)和文本文件的名称:
1python word_freq.py fish cities.txt
如果一切顺利,你应该看到这个:
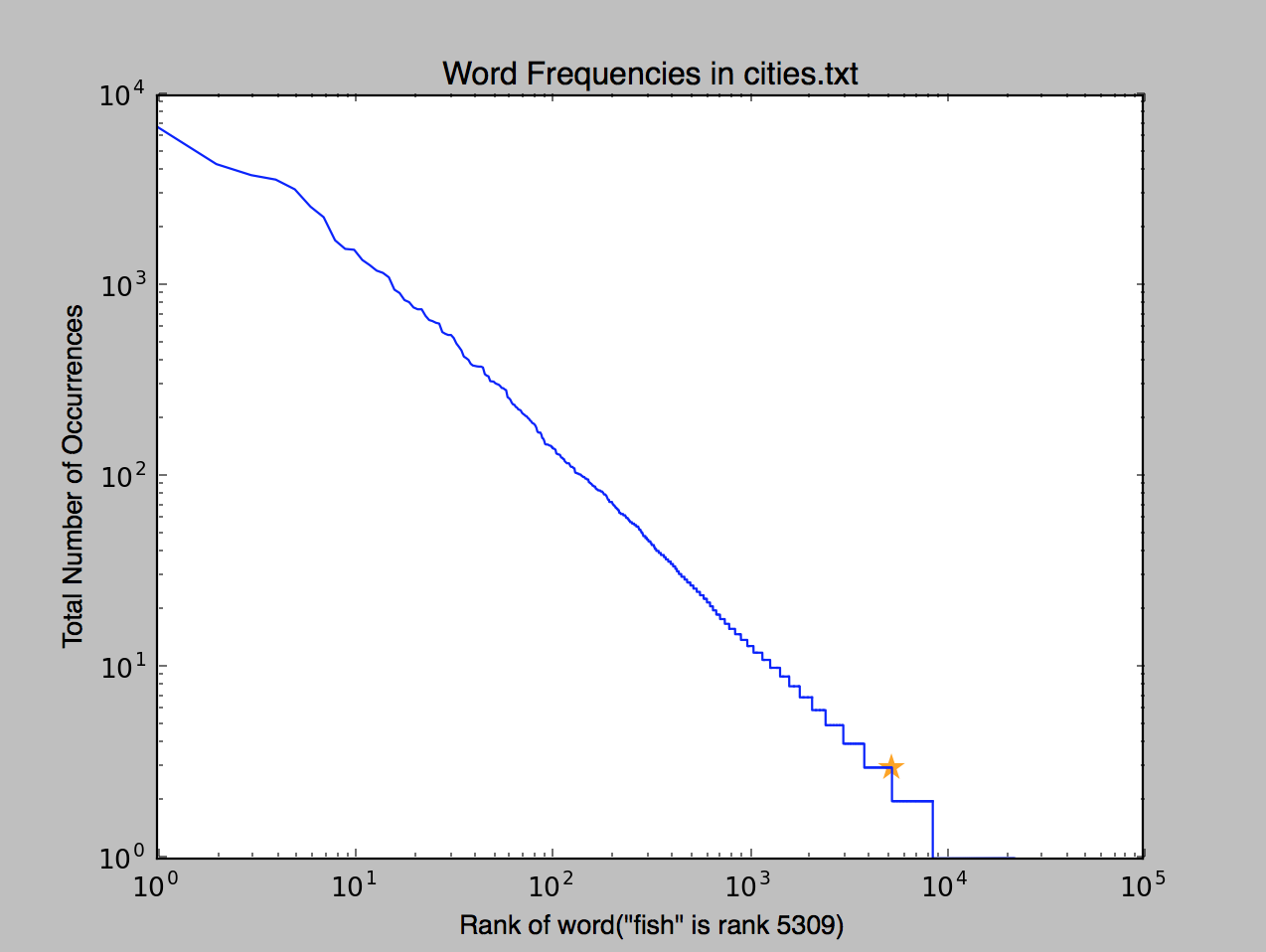
我们看到鱼这个词的排名是5309和出现的可视化。
现在,您可以继续用不同的单词和不同的文本文件进行实验,您可以通过阅读我们的教程(How To Handle Plain Text Files in Python 3)(https://andsky.com/tech/tutorials/how-to-handle-plain-text-files-in-python-3)来了解更多有关文本文件的工作。
完成的代码和代码改进
在此时刻,你应该有一个功能齐全的程序,它会确定在.txt 文件中的某个单词的单词频率。
下面是我们为这个项目完成的代码。
1[label word_freq.py]
2import matplotlib.pyplot as plt
3import sys
4import operator
5import argparse
6
7def main():
8 parser = argparse.ArgumentParser()
9 parser.add_argument(
10 "word",
11 help="the word to be searched for in the text file."
12 )
13 parser.add_argument(
14 "filename",
15 help="the path to the text file to be searched through"
16 )
17
18 args = parser.parse_args()
19
20 try:
21 open(args.filename)
22 except FileNotFoundError:
23
24 # Custom error print
25 sys.stderr.write("Error: " + args.filename + " does not exist!")
26 sys.exit(1)
27
28 word_freq(args.word, args.filename)
29
30def word_freq(word, filename):
31 doc = {}
32
33 for line in open(filename):
34
35 # Assume each word is separated by a space
36 split = line.split(' ')
37 for entry in split:
38 if (doc.__contains__(entry)):
39 doc[entry] = int(doc.get(entry)) + 1
40 else:
41 doc[entry] = 1
42
43 if (word not in doc):
44 sys.stderr.write("Error: " + word + " does not appear in " + filename)
45 sys.exit(1)
46
47 sorted_doc = (sorted(doc.items(), key=operator.itemgetter(1)))[::-1]
48 just_the_occur = []
49 just_the_rank = []
50 word_rank = 0
51 word_frequency = 0
52
53 entry_num = 1
54 for entry in sorted_doc:
55
56 if (entry[0] == word):
57 word_rank = entry_num
58 word_frequency = entry[1]
59
60 just_the_rank.append(entry_num)
61 entry_num += 1
62 just_the_occur.append(entry[1])
63
64 plt.title("Word Frequencies in " + filename)
65 plt.ylabel("Total Number of Occurrences")
66 plt.xlabel("Rank of word(\"" + word + "\" is rank " + str(word_rank) + ")")
67 plt.loglog(just_the_rank, just_the_occur, basex=10)
68 plt.scatter(
69 [word_rank],
70 [word_frequency],
71 color="orange",
72 marker="*",
73 s=100,
74 label=word
75 )
76 plt.show()
77
78if __name__ == "__main__":
79 main()
现在一切已经完成了,我们可以对这个代码做一些潜在的改进和修改。
如果我们想比较两个单词的频率,那么我们会在我们的命令行参数中添加一个额外的单词位置。
我们还可以修改程序,以便将每个单词的长度与另一个单词的长度进行比较. 为了做到这一点,我们将单词的长度进行比较,并将每个单词的长度保存到字典中。
结论
我们刚刚创建了一个程序来阅读文本文件,并组织数据,以查看特定单词与文本中的其他单词的频率。
如果您对数据可视化感兴趣,您还可以参阅我们的 如何使用JavaScript和D3库创建条形图表教程。