作者选择了 COVID-19 救援基金作为 Write for Donations计划的一部分接受捐款。
介绍
在Node.js开发中,追踪一个编码出错回源头,可以在项目过程中节省大量时间. 但是,随着一个程序越来越复杂,高效地完成这项工作变得越来越困难. 为了解决这个问题,开发者使用工具如_debugger_,这个程序允许开发者在运行时检查他们的程序. 通过逐行重放代码并观察它如何改变程序状态,调试者可以提供对程序运行方式的洞察,使查找错误变得更容易.
程序员用来追踪其代码中的错误的一个常见做法是,在程序运行时打印语句. 在Node.js中,这涉及在其模块中添加额外的 'console.log ()' 或console.debug () 语句。 虽然这种技术可以被快速地使用,但它也是手工的,使得其可伸缩性更弱并更容易出错. 使用这种方法,有可能错误地将敏感信息登录到控制台,这可能会为恶意特工提供客户或您的应用的私人信息. 另一方面,调试器提供了一个系统的方法来观察一个程序正在发生的事情,而不会使你的程序暴露于安全威胁.
调试器的主要功能是 watching 对象和添加 _breakpoints。通过观察对象,调试器可以帮助跟踪变量的变化,因为程序员通过程序步骤。
在本文中,您将使用调试器来调试一些样本 Node.js 应用程序. 您将首先使用内置的 Node.js 调试工具调试代码,设置观察器和破坏点,以便您可以找到错误的根源原因。
前提条件
要在 macOS 或 Ubuntu 18.04 上安装此功能,请遵循 如何在 macOS 上安装 Node.js 和创建本地开发环境或 [如何在 Ubuntu 18.04] 上安装 Node.js 的 [How To Install Node.js**]部分的步骤。(https://andsky.com/tech/tutorials/how-to-install-node-js-on-ubuntu-18-04)。
- 对于本文,我们希望用户能够舒适地使用基本的 JavaScript,特别是创建和使用 功能。
步骤 1 — 使用 Node.js 调试器的观察员
调试器主要有助于两种功能:它们能够观察变量,并观察它们在运行程序时如何变化,以及它们能够在不同的位置停止和开始代码执行,称为 breakpoints。
观察变量,当我们通过代码时,会让我们了解变量值在程序运行时如何变化. 让我们练习观察变量,以帮助我们用一个例子找到和修复代码中的逻辑错误。
在您的终端中,创建一个名为debugging的新文件夹:
1mkdir debugging
现在输入这个文件夹:
1cd debugging
打开一个名为badLoop.js的新文件,我们将使用nano,因为它在终端中可用:
1nano badLoop.js
我们的代码将在一个数组(https://andsky.com/tech/tutorials/understanding-arrays-in-javascript)中迭代,并将数字添加到总数中,在我们的示例中将用于在一个商店一周内增加每日订单的数量。
1[label debugging/badLoop.js]
2let orders = [341, 454, 198, 264, 307];
3
4let totalOrders = 0;
5
6for (let i = 0; i <= orders.length; i++) {
7 totalOrders += orders[i];
8}
9
10console.log(totalOrders);
我们开始创建订单数组,存储五个数字,然后将总订单初始化为0,因为它将存储五个数字的总数。
保存和退出编辑器. 现在用节点运行此程序:
1node badLoop.js
终端将显示此输出:
1[secondary_label Output]
2NaN
NaN在JavaScript中意思是 Not a Number . 鉴于所有输入都是有效的数字,这是一种意想不到的行为. 要找到错误,让我们使用Node.js调试器来看看在for循环中更改的两个变量:totalOrders和i会发生什么。
当我们想在程序上使用内置的 Node.js 调试程序时,我们在文件名之前添加inspect。
1node inspect badLoop.js
当你启动调试器时,你会看到这样的输出:
1[secondary_label Output]
2< Debugger listening on ws://127.0.0.1:9229/e1ebba25-04b8-410b-811e-8a0c0902717a
3< For help, see: https://nodejs.org/en/docs/inspector
4< Debugger attached.
5Break on start in badLoop.js:1
6> 1 let orders = [341, 454, 198, 264, 307];
7 2
8 3 let totalOrders = 0;
第一行向我们展示了我们的调试服务器的URL,这是当我们想与外部客户端调试时使用的,比如我们稍后会看到的网页浏览器。 请注意,这个服务器默认情况下在端口:9229上收听本地主机(‘127.0.0.1’)。
调试器附加后,调试器输出在 badLoop.js:1 中停止启动。
破解点是我们代码中我们希望执行停止的地方,默认情况下,Node.js 的调试程序会在文件开始时停止执行。
然后,调试器会向我们显示一个代码片段,然后是特殊的调试提示:
1[secondary_label Output]
2...
3> 1 let orders = [341, 454, 198, 264, 307];
4 2
5 3 let totalOrders = 0;
6debug>
在1旁边的>表示我们在执行中达到了哪一行,而提示是我们将在调试器中输入我们的命令的地方。
在使用调试器时,我们通过代码步骤,告诉调试器进入程序将执行的下一行。
c或cont: 继续执行到下一个分区或到程序的末尾。n或next: 移动到下一个代码行.s或step: 步入函数. 默认情况下,我们只通过代码在块中或 范围进行调试。 通过步入函数,我们可以检查函数的代码,我们的代码调用,并观察它如何对我们的数据做出反应。- `o: 步入函数后,调试器返回函数返回主文件。 我们可以使用这个命令返回我们在执行函数完成之前调试的原始函数。
- `pause
我们将通过这个代码行后行。按n来进入下一行:
1n
我们的调试器现在将被困在代码的第三行:
1[secondary_label Output]
2break in badLoop.js:3
3 1 let orders = [341, 454, 198, 264, 307];
4 2
5> 3 let totalOrders = 0;
6 4
7 5 for (let i = 0; i <= orders.length; i++) {
如果我们在调试控制台中再次按n,我们的调试器将位于代码的第五行:
1[secondary_label Output]
2break in badLoop.js:5
3 3 let totalOrders = 0;
4 4
5> 5 for (let i = 0; i <= orders.length; i++) {
6 6 totalOrders += orders[i];
7 7 }
现在我们正在开始我们的循环. 如果终端支持颜色,那么在让我 = 0中的0将被突出。调试器将突出程序即将执行的代码的部分,在为循环中,计数初始化首先执行。
首先,我们将为TotalOrders变量添加一个观察器. 在交互式壳中,输入以下内容:
1watch('totalOrders')
要观看变量,我们使用内置的watch()函数与包含变量名称的string参数。当我们在watch()函数上按ENTER时,提示将移动到下一行,而不会提供反馈,但当我们将调试器移动到下一行时,观看单词将可见。
现在让我们为变量i添加一个观察器:
1watch('i')
现在我们可以看到我们的观察员在行动中。按n来进入下一步。
1[secondary_label Output]
2break in badLoop.js:5
3Watchers:
4 0: totalOrders = 0
5 1: i = 0
6
7 3 let totalOrders = 0;
8 4
9> 5 for (let i = 0; i <= orders.length; i++) {
10 6 totalOrders += orders[i];
11 7 }
调试器现在会显示TotalOrders和i的值,然后显示代码行,如输出所示。
在这个时刻,调试器在orders.length中突出显示长度。这意味着程序在执行代码之前即将检查状态。在代码被执行后,将执行最后的表达式i++。你可以在我们的 How To Construct For Loops in JavaScript指南中阅读更多关于for循环及其执行情况。
在控制台中输入n以输入for循环的身体:
1[secondary_label Output]
2break in badLoop.js:6
3Watchers:
4 0: totalOrders = 0
5 1: i = 0
6
7 4
8 5 for (let i = 0; i <= orders.length; i++) {
9> 6 totalOrders += orders[i];
10 7 }
11 8
此步骤更新TotalOrders变量,因此,在此步骤完成后,我们的变量和观察器将被更新。
按n来确认,你会看到:
1[secondary_label Output]
2Watchers:
3 0: totalOrders = 341
4 1: i = 0
5
6 3 let totalOrders = 0;
7 4
8> 5 for (let i = 0; i <= orders.length; i++) {
9 6 totalOrders += orders[i];
10 7 }
正如我们所指出的,总订单现在有第一个订单的值:341。
我们的调试器即将处理循环的最终状态,输入n,然后我们执行此行并更新i:
1[secondary_label Output]
2break in badLoop.js:5
3Watchers:
4 0: totalOrders = 341
5 1: i = 1
6
7 3 let totalOrders = 0;
8 4
9> 5 for (let i = 0; i <= orders.length; i++) {
10 6 totalOrders += orders[i];
11 7 }
初始化后,我们不得不通过代码四次查看变量更新。通过代码这样步骤可能很累;这个问题将在 步骤 2中得到解决,但目前,通过设置我们的观察员,我们已经准备好观察他们的价值,并找到我们的问题。
通过输入n再输入12次,观察输出,您的控制台将显示以下内容:
1[secondary_label Output]
2break in badLoop.js:5
3Watchers:
4 0: totalOrders = 1564
5 1: i = 5
6
7 3 let totalOrders = 0;
8 4
9> 5 for (let i = 0; i <= orders.length; i++) {
10 6 totalOrders += orders[i];
11 7 }
请记住,我们的订单数组有五个项目,而i现在处于5位置,但由于i被用作一个数组的索引,所以在订单5中没有值;订单数组的最后一个值是4的索引。
在控制台中输入n,你会注意到循环中的代码正在执行:
1[secondary_label Output]
2break in badLoop.js:6
3Watchers:
4 0: totalOrders = 1564
5 1: i = 5
6
7 4
8 5 for (let i = 0; i <= orders.length; i++) {
9> 6 totalOrders += orders[i];
10 7 }
11 8
输入n再次显示该迭代后TotalOrders的值:
1[secondary_label Output]
2break in badLoop.js:5
3Watchers:
4 0: totalOrders = NaN
5 1: i = 5
6
7 3 let totalOrders = 0;
8 4
9> 5 for (let i = 0; i <= orders.length; i++) {
10 6 totalOrders += orders[i];
11 7 }
通过调试和观察总订单和i,我们可以看到我们的循环在重复六次而不是五次。当i为5,订单被添加到总订单。由于订单5是未定义的,将这个添加到一个数字中会产生NaN。因此,我们的代码的问题在于我们的for循环状态。而不是检查i是否小于或等于orders系列的长度,我们只应该检查它是否小于长度。
让我们退出我们的调试器,做出更改,然后再次运行代码。在调试提示中,键入退出命令并按ENTER:
1.exit
现在你已经退出调试程序,在文本编辑器中打开badLoop.js:
1nano badLoop.js
更改for循环的条件:
1[label debugger/badLoop.js]
2...
3for (let i = 0; i < orders.length; i++) {
4...
保存和退出nano。现在让我们像这样执行我们的脚本:
1node badLoop.js
完成后,将打印正确的结果:
1[secondary_label Output]
21564
在本节中,我们使用调试器的观察命令在我们的代码中找到一个错误,修复它,并观察它按预期工作。
现在,我们已经有了对调试器用于监控变量的基本使用的经验,让我们看看我们如何使用断层,这样我们就可以调试,而不必从程序的开始穿过所有代码行。
步骤 2 — 使用 Node.js 调试器的突破点
Node.js 项目通常由许多相互连接的 模块组成。每一个模块的线上调试将耗时,特别是因为应用程序在复杂性上规模。
在 Node.js 中调试时,我们通过将调试关键字直接添加到我们的代码中添加一个分裂点,然后我们可以通过在调试控制台中按c而不是n来从一个分裂点到另一个分裂点。
在此步骤中,我们将设置一个程序,它会读取句子列表并确定整个文本中使用的最常见单词。
对于这个练习,我们将创建三个文件. 第一个文件, sentences.txt,将包含我们的程序将处理的原始数据. 我们将添加从 Encyclopaedia Britannica关于鲸鲨的文章的开头文本作为样本数据,并删除点缀。
打开文本编辑器中的文件:
1nano sentences.txt
接下来,输入以下代码:
1[label debugger/sentences.txt]
2Whale shark Rhincodon typus gigantic but harmless shark family Rhincodontidae that is the largest living fish
3Whale sharks are found in marine environments worldwide but mainly in tropical oceans
4They make up the only species of the genus Rhincodon and are classified within the order Orectolobiformes a group containing the carpet sharks
5The whale shark is enormous and reportedly capable of reaching a maximum length of about 18 metres 59 feet
6Most specimens that have been studied however weighed about 15 tons about 14 metric tons and averaged about 12 metres 39 feet in length
7The body coloration is distinctive
8Light vertical and horizontal stripes form a checkerboard pattern on a dark background and light spots mark the fins and dark areas of the body
保存和退出文件。
现在让我们将我们的代码添加到 textHelper.js. 这个模块将包含一些我们将用来处理文本文件的实用功能,使其更容易确定最流行的单词。
1nano textHelper.js
我们将创建三个函数来处理sentences.txt中的数据,第一个函数是读取文件,然后输入textHelper.js:
1[label debugger/textHelper.js]
2const fs = require('fs');
3
4const readFile = () => {
5 let data = fs.readFileSync('sentences.txt');
6 let sentences = data.toString();
7 return sentences;
8};
首先,我们导入了 fs Node.js 库,以便我们可以读取文件,然后我们创建了使用 readFileSync() 的 readFile() 函数来将数据从 sentences.txt 加载为 Buffer 对象和 toString() 方法以返回为字符串。
接下来我们将添加的函数处理一个文本字符串,并将其平滑到一个数组中,并添加以下代码到编辑器:
1[label textHelper.js]
2...
3
4const getWords = (text) => {
5 let allSentences = text.split('\n');
6 let flatSentence = allSentences.join(' ');
7 let words = flatSentence.split(' ');
8 words = words.map((word) => word.trim().toLowerCase());
9 return words;
10};
在这个代码中,我们正在使用方法 split(), join(),和 map()来操纵字符串成一个单个单词的数组。
最后一个需要的函数返回字符串数组中的不同单词的数目。
1[label debugger/textHelper.js]
2...
3
4const countWords = (words) => {
5 let map = {};
6 words.forEach((word) => {
7 if (word in map) {
8 map[word] = 1;
9 } else {
10 map[word] += 1;
11 }
12 });
13
14 return map;
15};
在这里,我们创建了一个名为地图的JavaScript对象(https://andsky.com/tech/tutorials/understanding-objects-in-javascript),它将单词作为其密钥和它们的计数作为值。我们通过数组循环,将一个添加到每个单词的计数中,当它是循环的当前元素。
1[label debugger/textHelper.js]
2...
3
4module.exports = { readFile, getWords, countWords };
保存和退出。
我们的第三个和最后的文件,我们将使用这个练习,将使用textHelper.js模块,在我们的文本中找到最流行的单词。
1nano index.js
我们通过导入textHelpers.js模块开始我们的代码:
1[label debugger/index.js]
2const textHelper = require('./textHelper');
继续创建一个包含 stop words的新数组:
1[label debugger/index.js]
2...
3
4const stopwords = ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now', ''];
停止词是我们在处理文本之前过滤的语言中常用的单词,我们可以用此来找到比英语文本中最流行的单词是the或a的结果更有意义的数据。
继续使用textHelper.js模块函数来获取包含单词和它们的计数的JavaScript对象:
1[label debugger/index.js]
2...
3
4let sentences = textHelper.readFile();
5let words = textHelper.getWords(sentences);
6let wordCounts = textHelper.countWords(words);
然后,我们可以通过确定具有最高频率的单词来完成这个模块。 为了做到这一点,我们将通过与单词计数的对象的每个键循环,并将其计数与以前存储的最大值进行比较。
添加以下代码行来计算最流行的单词:
1[label debugger/index.js]
2...
3
4let max = -Infinity;
5let mostPopular = '';
6
7Object.entries(wordCounts).forEach(([word, count]) => {
8 if (stopwords.indexOf(word) === -1) {
9 if (count > max) {
10 max = count;
11 mostPopular = word;
12 }
13 }
14});
15
16console.log(`The most popular word in the text is "${mostPopular}" with ${max} occurrences`);
在此代码中,我们正在使用 Object.entries() 将wordCounts对象中的关键值对转换为单个数组,这些数组都嵌入更大的数组中。
保存和退出文件。
现在让我们运行此文件,以便在动作中看到它. 在您的终端中输入此命令:
1node index.js
您将看到以下结果:
1[secondary_label Output]
2The most popular word in the text is "whale" with 1 occurrences
通过阅读文本,我们可以看到答案是错误的。在sentences.txt中快速搜索会突出显示鲸鱼一词出现过多次。
我们有很多可能导致此错误的功能:我们可能不会阅读整个文件,或者我们可能无法正确地将文本处理到数组和JavaScript对象中。
即使没有一个大的代码库,我们也不想花时间在代码的每个行中进行步骤,观察事情发生了变化,相反,我们可以使用中断点前往函数返回并观察输出之前的关键时刻。
让我们在textHelper.js模块中在每个函数中添加突破点. 为了做到这一点,我们需要在我们的代码中添加关键字debugger。
在文本编辑器中打开textHelper.js文件,我们将再次使用nano:
1nano textHelper.js
首先,我们会将分割点添加到readFile()函数,如下:
1[label debugger/textHelper.js]
2...
3
4const readFile = () => {
5 let data = fs.readFileSync('sentences.txt');
6 let sentences = data.toString();
7 debugger;
8 return sentences;
9};
10
11...
接下来,我们将为getWords()函数添加另一个分裂点:
1[label debugger/textHelper.js]
2...
3
4const getWords = (text) => {
5 let allSentences = text.split('\n');
6 let flatSentence = allSentences.join(' ');
7 let words = flatSentence.split(' ');
8 words = words.map((word) => word.trim().toLowerCase());
9 debugger;
10 return words;
11};
12
13...
最后,我们将为countWords()函数添加一个分割点:
1[label debugger/textHelper.js]
2...
3
4const countWords = (words) => {
5 let map = {};
6 words.forEach((word) => {
7 if (word in map) {
8 map[word] = 1;
9 } else {
10 map[word] += 1;
11 }
12 });
13
14 debugger;
15 return map;
16};
17
18...
保存和退出textHelper.js。
虽然破解点在textHelpers.js,但我们正在破解我们的应用程序的主要输入点:index.js。
1node inspect index.js
输入命令后,我们将被接到这个输出:
1[secondary_label Output]
2< Debugger listening on ws://127.0.0.1:9229/b2d3ce0e-3a64-4836-bdbf-84b6083d6d30
3< For help, see: https://nodejs.org/en/docs/inspector
4< Debugger attached.
5Break on start in index.js:1
6> 1 const textHelper = require('./textHelper');
7 2
8 3 const stopwords = ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now', ''];
这一次,在交互式调试器中输入c。 作为提醒,c是继续的缩短,这将调试器跳到代码中的下一个分区。 按下c并输入ENTER后,您将在您的控制台中看到以下内容:
1[secondary_label Output]
2break in textHelper.js:6
3 4 let data = fs.readFileSync('sentences.txt');
4 5 let sentences = data.toString();
5> 6 debugger;
6 7 return sentences;
7 8 };
我们现在已经节省了一些调试时间,直接前往我们的分手点。
在这个函数中,我们想确保文件中的所有文本都被返回. 添加一个观察器为句子变量,以便我们可以看到返回的内容:
1watch('sentences')
按n移动到下一行代码,以便我们可以观察句子中的内容。
1[secondary_label Output]
2break in textHelper.js:7
3Watchers:
4 0: sentences =
5 'Whale shark Rhincodon typus gigantic but harmless shark family Rhincodontidae that is the largest living fish\n' +
6 'Whale sharks are found in marine environments worldwide but mainly in tropical oceans\n' +
7 'They make up the only species of the genus Rhincodon and are classified within the order Orectolobiformes a group containing the carpet sharks\n' +
8 'The whale shark is enormous and reportedly capable of reaching a maximum length of about 18 metres 59 feet\n' +
9 'Most specimens that have been studied however weighed about 15 tons about 14 metric tons and averaged about 12 metres 39 feet in length\n' +
10 'The body coloration is distinctive\n' +
11 'Light vertical and horizontal stripes form a checkerboard pattern on a dark background and light spots mark the fins and dark areas of the body\n'
12
13 5 let sentences = data.toString();
14 6 debugger;
15> 7 return sentences;
16 8 };
17 9
似乎我们没有任何问题阅读文件;问题必须在我们的代码的其他地方。让我们通过再次按c来移动到下一个分割点。
1[secondary_label Output]
2break in textHelper.js:15
3Watchers:
4 0: sentences =
5 ReferenceError: sentences is not defined
6 at eval (eval at getWords (your_file_path/debugger/textHelper.js:15:3), <anonymous>:1:1)
7 at Object.getWords (your_file_path/debugger/textHelper.js:15:3)
8 at Object.<anonymous> (your_file_path/debugger/index.js:7:24)
9 at Module._compile (internal/modules/cjs/loader.js:1125:14)
10 at Object.Module._extensions..js (internal/modules/cjs/loader.js:1167:10)
11 at Module.load (internal/modules/cjs/loader.js:983:32)
12 at Function.Module._load (internal/modules/cjs/loader.js:891:14)
13 at Function.executeUserEntryPoint [as runMain] (internal/modules/run_main.js:71:12)
14 at internal/main/run_main_module.js:17:47
15
16 13 let words = flatSentence.split(' ');
17 14 words = words.map((word) => word.trim().toLowerCase());
18>15 debugger;
19 16 return words;
20 17 };
我们收到此错误消息是因为我们为句子变量设置了观察器,但该变量不存在于我们当前的函数范围内。
我们可以用unwatch()命令停止观看变量,所以我们不再需要看到这个错误消息,每次调试器打印输出时。
1unwatch('sentences')
调试器在您卸载变量时不会输出任何东西。
在getWords()函数中,我们希望确保我们返回从我们之前加载的文本中提取的单词列表。
1watch('words')
然后输入n,进入调试器的下一行,这样我们就可以看到在单词中存储的内容。
1[secondary_label Output]
2break in textHelper.js:16
3Watchers:
4 0: words =
5 [ 'whale',
6 'shark',
7 'rhincodon',
8 'typus',
9 'gigantic',
10 'but',
11 'harmless',
12 ...
13 'metres',
14 '39',
15 'feet',
16 'in',
17 'length',
18 '',
19 'the',
20 'body',
21 'coloration',
22 ... ]
23
24 14 words = words.map((word) => word.trim().toLowerCase());
25 15 debugger;
26>16 return words;
27 17 };
28 18
调试器不会打印整个数组,因为它相当长,并且会使输出更难读取。然而,输出满足了我们对应该存储的期望:从句子的文本分为下列字符串。
让我们继续观察countWords()函数. 首先,卸载words数组,这样我们在下一个分区时就不会造成任何调试错误。
1unwatch('words')
接下来,在提示中输入c,在我们最后的分割点上,我们将在壳中看到:
1[secondary_label Output]
2break in textHelper.js:29
3 27 });
4 28
5>29 debugger;
6 30 return map;
7 31 };
在这个函数中,我们要确保地图变量正确地包含我们句子中的每个单词的计数。
1watch('map')
按n移动到下一行,然后调试器会显示以下内容:
1[secondary_label Output]
2break in textHelper.js:30
3Watchers:
4 0: map =
5 { 12: NaN,
6 14: NaN,
7 15: NaN,
8 18: NaN,
9 39: NaN,
10 59: NaN,
11 whale: 1,
12 shark: 1,
13 rhincodon: 1,
14 typus: NaN,
15 gigantic: NaN,
16 ... }
17
18 28
19 29 debugger;
20>30 return map;
21 31 };
22 32
這看起來不對,似乎數字的方法會產生錯誤的結果.我們不知道為什麼這些值被輸入,所以我們的下一步是排除在「詞」數列中使用的循環中發生的事情。
首先,离开调试控制台:
1.exit
在您的文本编辑器中打开textHelper.js,以便我们可以编辑破解点:
1nano textHelper.js
首先,知道readFile()和getWords()正在运作,我们将删除它们的分割点,然后从函数的末尾删除countWords()中的分割点,并将两个新的分割点添加到forEach()块的开始和结束。
编辑textHelper.js以便它看起来像这样:
1[label debugger/textHelper.js]
2...
3
4const readFile = () => {
5 let data = fs.readFileSync('sentences.txt');
6 let sentences = data.toString();
7 return sentences;
8};
9
10const getWords = (text) => {
11 let allSentences = text.split('\n');
12 let flatSentence = allSentences.join(' ');
13 let words = flatSentence.split(' ');
14 words = words.map((word) => word.trim().toLowerCase());
15 return words;
16};
17
18const countWords = (words) => {
19 let map = {};
20 words.forEach((word) => {
21 debugger;
22 if (word in map) {
23 map[word] = 1;
24 } else {
25 map[word] += 1;
26 }
27 debugger;
28 });
29
30 return map;
31};
32
33...
保存和退出nano用CTRL+X。
让我们用这个命令重新启动调试器:
1node inspect index.js
首先,让我们为‘word’设置一个观察器,这是‘forEach()’循环中使用的参数,其中包含循环当前正在查看的字符串。
1watch('word')
到目前为止,我们只观察变量,但时钟不局限于变量,我们可以观察我们代码中使用的任何有效的JavaScript表达式。
实际上,我们可以为条件在地图中的单词添加一个观察器,这决定了我们如何计算数字。
1watch('word in map')
我们还会为在地图变量中修改的值添加一个观察器:
1watch('map[word]')
观察者甚至可以是我们代码中不使用的表达式,但可以用我们所拥有的代码进行评估。
1watch('word.length')
现在我们已经设置了所有观察器,让我们在调试器提示中输入c,这样我们就可以看到countWords()循环中的第一个元素是如何被评估的。
1[secondary_label Output]
2break in textHelper.js:20
3Watchers:
4 0: word = 'whale'
5 1: word in map = false
6 2: map[word] = undefined
7 3: word.length = 5
8
9 18 let map = {};
10 19 words.forEach((word) => {
11>20 debugger;
12 21 if (word in map) {
13 22 map[word] = 1;
循环中的第一个单词是鲸鱼。在这一点上,地图对象没有鲸鱼作为其空的密钥,因此,当我们在地图中搜索鲸鱼时,我们会得到无定义。最后,鲸鱼的长度是5。这并不帮助我们调解问题,但它确实验证了我们可以在调试过程中观察任何可以用代码进行评估的表达式。
再次点击c以查看循环结束时发生了什么变化。
1[secondary_label Output]
2break in textHelper.js:26
3Watchers:
4 0: word = 'whale'
5 1: word in map = true
6 2: map[word] = NaN
7 3: word.length = 5
8
9 24 map[word] += 1;
10 25 }
11>26 debugger;
12 27 });
13 28
在循环的末尾,地图中的单词现在是真实的,因为地图变量包含一个鲸鱼密钥。鲸鱼密钥的地图值是NaN,这凸显了我们的问题。
罪魁祸首是如果声明的条件,我们应该将map[word]设置为1,如果word没有在map中找到。 现在,我们正在添加一个,如果word被找到。 在循环的开始,map[whale]是未定义的。 在JavaScript中,undefined + 1评估为NaN`而不是一个数字。
解决方案是将如果声明的状态从(地图中的单词)更改为(地图中的单词),使用!运算器来测试单词是否不在地图。
首先,输出 Debugger:
1.exit
现在,用文本编辑器打开textHelper.js文件:
1nano textHelper.js
更改countWords()函数如下:
1[label debugger/textHelper.js]
2...
3
4const countWords = (words) => {
5 let map = {};
6 words.forEach((word) => {
7 if (!(word in map)) {
8 map[word] = 1;
9 } else {
10 map[word] += 1;
11 }
12 });
13
14 return map;
15};
16
17...
保存并关闭编辑器。
现在让我们在没有调试器的情况下运行这个文件。在终端中,输入以下内容:
1node index.js
脚本将输出以下句子:
1[secondary_label Output]
2The most popular word in the text is "whale" with 3 occurrences
这个输出似乎比我们之前所得到的要更有可能,借助调试器,我们找到了哪个函数引起了问题,哪个函数没有。
我们已经用内置的 CLI 调试器调试了两种不同的 Node.js 程序,现在我们可以用调试关键字设置中断点,并创建各种观察器来观察内部状态的变化,但有时,代码可以更有效地从 GUI 应用程序中调试。
在下一节中,我们将使用Google Chrome的DevTools中的调试器,在Node.js中启动调试器,在Google Chrome中导航到专门的调试页面,并使用GUI设置分解点和观察器。
步骤 3 — 使用 Chrome DevTools 调试 Node.js
由于 Node.js 使用的是 Chrome 使用的相同的 V8 JavaScript 引擎,故调试体验比其他调试器更具集成性。
对于这个练习,我们将创建一个新的 Node.js 应用程序,该应用程序运行 HTTP 服务器并返回 JSON 响应。
让我们创建一个名为server.js的新文件,将存储我们的服务器代码。
1nano server.js
此应用程序将以Hello World的问候返回一个 JSON。 它将包含多种不同语言的消息。 当收到请求时,它会随机选择一个问候,并在 JSON 体中返回它。
如果您想了解更多关于使用 Node.js 创建 HTTP 服务器的信息,请阅读我们的指南 如何使用 HTTP 模块创建 Node.js 中的 Web 服务器。
在文本编辑器中输入以下代码:
1[label debugger/server.js]
2const http = require("http");
3
4const host = 'localhost';
5const port = 8000;
6
7const greetings = ["Hello world", "Hola mundo", "Bonjour le monde", "Hallo Welt", "Salve mundi"];
8
9const getGreeting = function () {
10 let greeting = greetings[Math.floor(Math.random() * greetings.length)];
11 return greeting
12}
我们首先导入http模块,这需要创建一个HTTP服务器,然后我们设置了主机和端口变量,后面我们将使用它来运行服务器。
让我们添加处理 HTTP 请求的请求倾听器,并添加代码来运行我们的服务器。
1[label debugger/server.js]
2...
3
4const requestListener = function (req, res) {
5 let message = getGreeting();
6 res.setHeader("Content-Type", "application/json");
7 res.writeHead(200);
8 res.end(`{"message": "${message}"}`);
9};
10
11const server = http.createServer(requestListener);
12server.listen(port, host, () => {
13 console.log(`Server is running on http://${host}:${port}`);
14});
我们的服务器现在已经准备好使用,所以让我们设置Chrome调试程序。
我们可以使用以下命令启动Chrome调试程序:
1node --inspect server.js
<$>[注]
注: 请记住CLI调试器和Chrome调试器命令之间的区别。 使用CLI时,您使用inspect。
启动调试器后,你会发现以下输出:
1[secondary_label Output]
2Debugger listening on ws://127.0.0.1:9229/996cfbaf-78ca-4ebd-9fd5-893888efe8b3
3For help, see: https://nodejs.org/en/docs/inspector
4Server is running on http://localhost:8000
现在打开 Google Chrome 或 Chromium并在地址栏中输入「chrome://inspect」。 Microsoft Edge也使用 V8 JavaScript 引擎,因此可以使用相同的调试程序。
导航到URL后,您将看到以下页面:
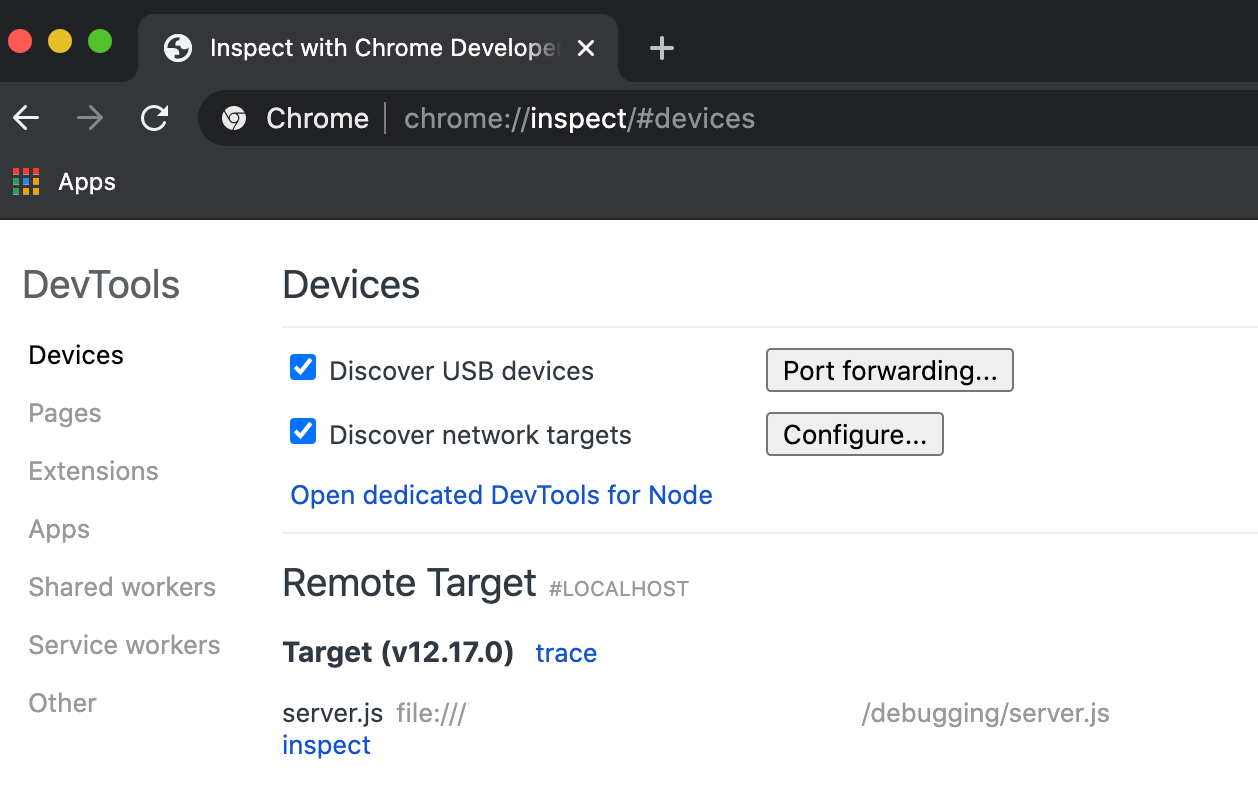
在Devices**标题下,点击Open dedicated DevTools for Node** 按钮。
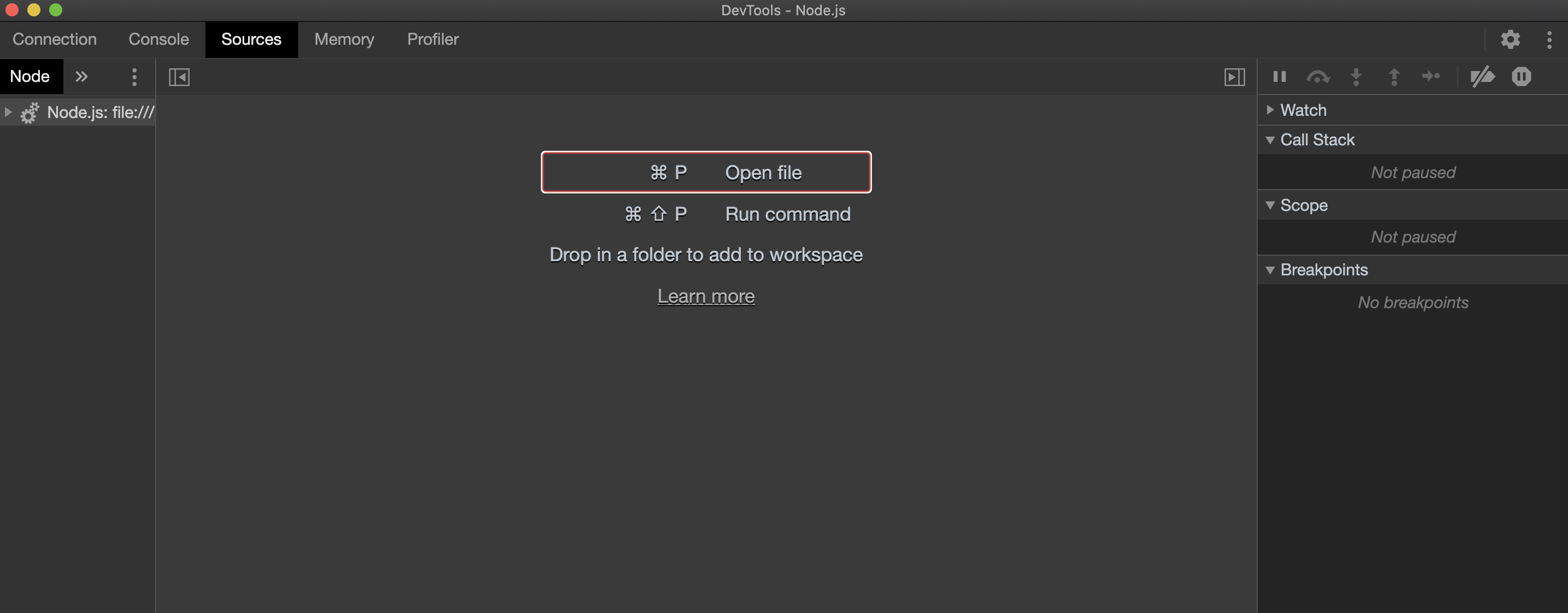
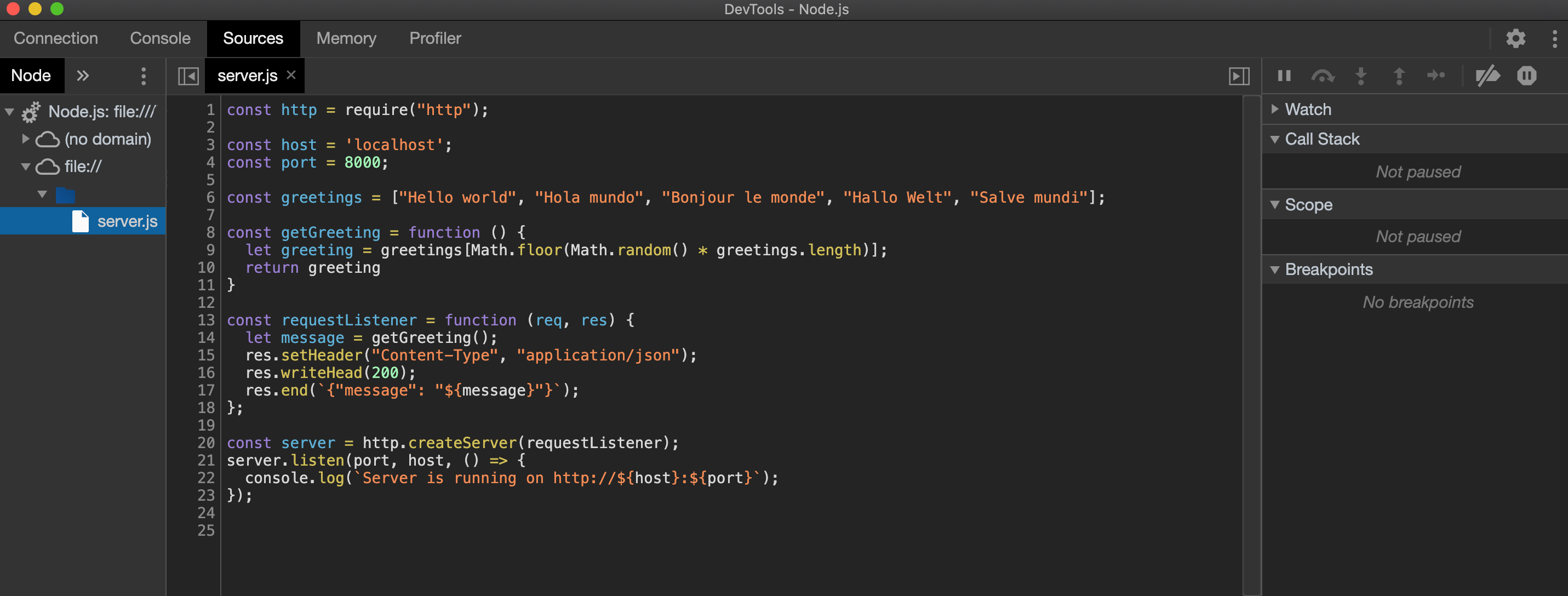
我们现在可以用Chrome来调试我们的Node.js代码。如果没有,请导航到 Sources 选项卡。在左侧,扩展文件树并选择 server.js:
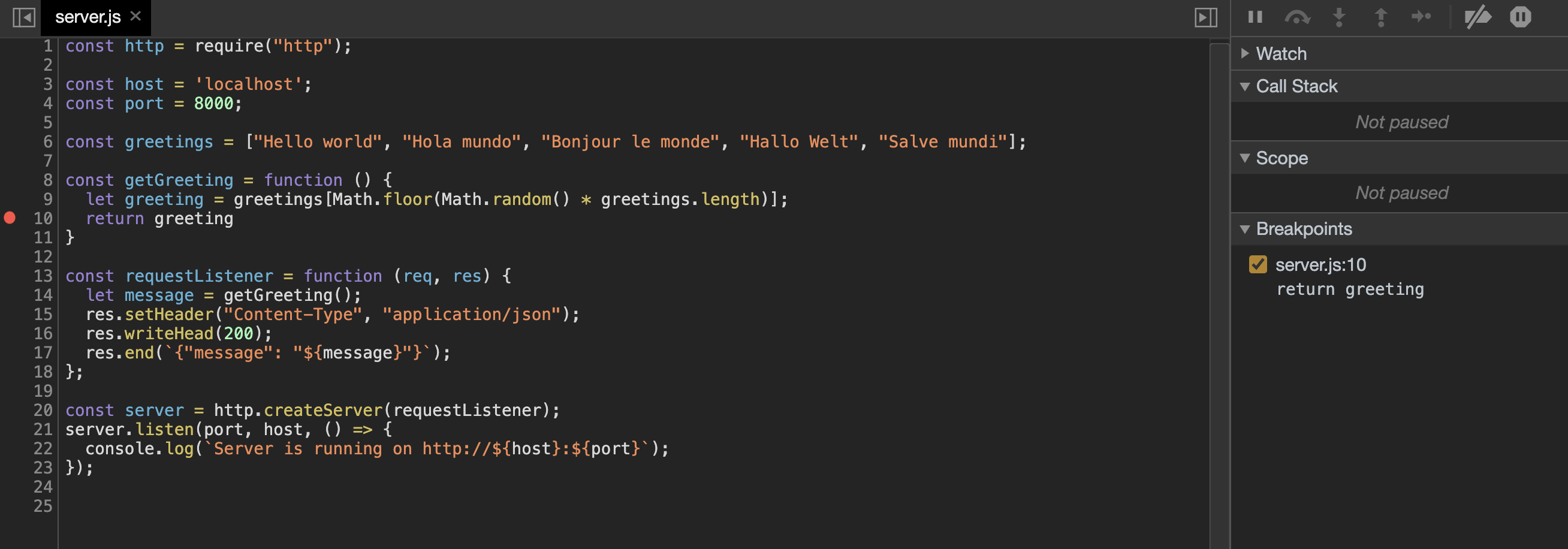
让我们在我们的代码中添加一个分区点. 当服务器选择了问候并即将返回它时,我们想要停止。 点击调试控制台中的行号 10 。 一个红点将出现在数字旁边,右边的面板将显示新分区点被添加:
现在让我们添加一个手表表达式 在右面板上,点击 ** Watch** 标题旁边的箭头来打开手表单词列表,然后点击 ** +** 。
接下来,让我们调试我们的代码。 打开一个新的浏览器窗口,并导航到http://localhost:8000――Node.js服务器正在运行的地址。 按下ENTER时,我们不会立即收到回复。 相反,调试窗口将再次出现。 如果它没有立即进入焦点,请导航到调试窗口以查看以下内容:
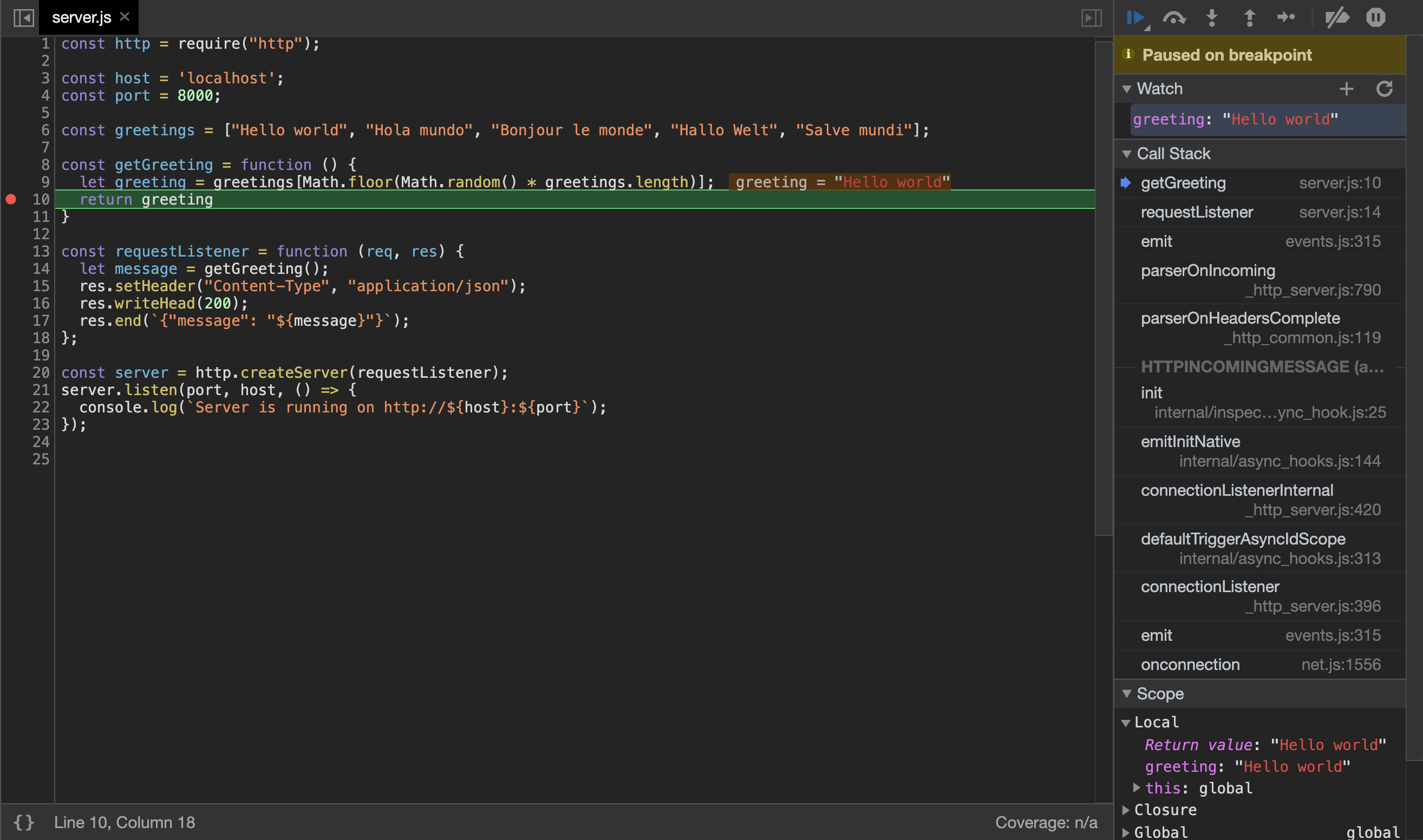
调试器暂停服务器的响应,在那里我们设置了我们的分割点. 我们观察的变量在右面板上以及创建它的代码行中更新。
让我们通过在右面板上按下继续按钮来完成响应的执行,就在 Paused on breakpoint 上方.当响应完成时,您将在用于与Node.js服务器交谈的浏览器窗口中看到成功的JSON响应:
1{"message": "Hello world"}
这样,Chrome DevTools 不需要对代码进行更改以添加突破点. 如果您更喜欢在命令行上使用图形应用程序来调试,Chrome DevTools 更适合您。
结论
在本文中,我们通过设置观察器来观察我们的应用程序的状态来调试样本 Node.js 应用程序,然后通过添加断层来使我们能够在程序执行的不同时刻暂停执行。
许多 Node.js 开发人员登录到控制台来调试他们的代码. 虽然这是有用的,但它并不像能够暂停执行并观察各种状态变化那样灵活。
要了解有关这些调试工具的更多信息,您可以阅读 Node.js 文档或 Chrome DevTools 文档。