介绍
Twitterbot 是一个与 Twitter 平台集成的程序,自动发布、重写、喜欢或跟随其他用户。
创建 Twitterbot 时要小心,因为不但骚扰和垃圾邮件不对,而且会导致您的 Twitterbot 帐户因违反 Twitter 服务条款而暂停使用。在创建 Twitterbot 之前,您应该熟悉 Twitter 的 自动化规则和最佳做法以确保您的 Twitterbot 是 Twitter 社区的良好成员。
此教程会带您通过两个Twitterbot程序,一个是[从一个文件转出 (https://andsky.com/tech/tutorials/how-to-create-a-twitterbot-with-python-3-and-the-tweepy-library# twitterbot-that-tweets-from-a-file),另一个是[检索,跟随,和最爱 (https://andsky.com/tech/tutorials/how-to-create-a-twitterbot-with-python-3-and-the-tweepy-library twitterbot-that-retweets,-follows,-and-favorites). 此外,我们将通过一个单独的程序文件存储您的资质,以及[保持Twitterbot运行在服务器上](https://andsky.com/tech/tutorials/how-to-create-a-twitterbot-with-python-3-and-the-tweepy-library keeping-the-twitterbot-running)。 这些步骤都是可选的.
前提条件
虽然您可以使用本地计算机来设置和运行 Twitterbot,但如果您希望它连续运行,则 Python 在服务器上的编程环境对于这个项目是理想的。
此外,您应该有一个与有效电话号码相联的[twitter] (https://twitter.com)账户,您可以在登录时通过**Mobile** 部分添加该账户。 您需要创建一款Twitter应用程序并安装 Python Tweepy 库, 您可以遵循我们的) 教程。 在开始这个教程之前, 您应该手持您的消费密钥、 消费密钥、 访问密钥和访问密钥 .
要了解如何在Python中使用文本文件,您可以阅读我们的)指南。
存储凭证
您可以将您的Twitter消费者密钥, 消费者秘密, Access Token, 以及 Access Token 密钥保存在程序文件的顶端, 但对于最佳做法, 我们应该把这些存储在单独的 Python 文件中, 我们的主要程序文件可以访问 。 任何人,如果可以使用这些[字符串] (https://www.digitalocean.com/community/tutorial_series/working-with-strings-in-python-3),都可以使用 推特账号, 除安全外,保存一个单独的文件可以让我们在每一个我们创建的程序文件中方便地访问我们的证书.
首先,我们应该确保我们在我们的虚拟环境中安装了 Tweepy 库. 随着环境的激活,我们可以为我们的项目创建一个目录,以保持其组织:
1mkdir twitterbot
2cd twitterbot
接下来,让我们打开一个文本编辑器,例如nano,并创建文件credentials.py,以存储这些凭证:
1nano credentials.py
我们将创建 变量为我们生成的每个密钥,秘密,和代币(如果你需要生成这些,按照 这些步骤. 用你独特的字符串从Twitter应用程序网站(和保持单一的代码)代替单独的引用项目。
1[label credentials.py]
2consumer_key = 'your_consumer_key'
3consumer_secret = 'your_consumer_secret'
4access_token = 'your_access_token'
5access_token_secret = 'your_access_token_secret'
创建这个单独的credentials.py文件还允许我们将其添加到我们的.gitignore文件中,如果我们计划通过Git发布我们的代码。
Twitterbot 来自文件的推文
我们可以使用Python的处理和读取文件的能力来更新我们的Twitter状态. 对于这个例子,我们将使用已经存在的文件,但您可能想要创建自己的文件,或修改现有文件。
设置程序文件
让我们开始创建我们的程序文件,使用文本编辑器,如nano:
1nano twitterbot_textfile.py
接下来,让我们通过将它们添加到我们的文件的顶部来设置我们的Twitter凭据,或者将我们存储在我们在上面的部分设置的 credentials.py 文件中所存储的内容导入(https://andsky.com/tech/tutorials/how-to-create-a-twitterbot-with-python-3-and-the-tweepy-library# storing-credentials)。
1[label twitterbot_textfile.py]
2# Import our Twitter credentials from credentials.py
3from credentials import *
4
5# Access and authorize our Twitter credentials from credentials.py
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
要了解更多关于这个设置,请确保看)。
获取文本文件阅读从
对于这个Twitterbot,我们需要一个文本文件来阅读,所以让我们下载一个来自Gutenberg项目,一个志愿者项目,为读者提供免费的电子书(主要是在公共领域)。
1curl http://www.gutenberg.org/cache/epub/164/pg164.txt --output verne.txt
我们将使用Python的文件处理功能,首先是 打开文件,然后是 [读从文件的线条](https://andsky.com/tech/tutorials/how-to-handle-plain-text-files-in-python-3 step-3%E2%80%94-reading-a-file),最后是 关闭文件。
使用 Python 打开和阅读文件
随着我们的文件下载,我们可以创建变量并在我们刚刚设置的行下添加相关函数来处理凭证。
1[label twitterbot_textfile.py]
2from credentials import *
3
4auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
5auth.set_access_token(access_token, access_token_secret)
6api = tweepy.API(auth)
7
8# Open text file verne.txt (or your chosen file) for reading
9my_file = open('verne.txt', 'r')
10
11# Read lines one by one from my_file and assign to file_lines variable
12file_lines = my_file.readlines()
13
14# Close file
15my_file.close()
有了这个设置,我们现在可以添加代码来将这些行输出作为 Twitter 帐户的状态更新。
从文本文件中推特行
随着我们文件的行存储在变量中,我们准备更新我们的Twitterbot帐户。
我们将使用Tweepy库与Twitter API互动,所以我们应该(https://andsky.com/tech/tutorials/how-to-import-modules-in-python-3)导入到我们的程序中。
我们还将以基于时间的方式自动化我们的推文,所以我们应该导入模块时间。
1[label twitterbot_textfile.py]
2# Add all import statements at top of file
3import tweepy
4from time import sleep
5from credentials import *
6...
我們的 Twitter 帳戶的狀態更新將來自「verne.txt」的行,我們已將其分配到「file_lines」變量中。 這些行需要重複,所以我們將開始創建一個 for loop。 要確保一切工作,讓我們使用「print()」函數來打印這些行:
1[label twitterbot_textfile.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10my_file=open('verne.txt','r')
11file_lines=my_file.readlines()
12my_file.close()
13
14# Create a for loop to iterate over file_lines
15for line in file_lines:
16 print(line)
如果您在这个时刻使用python twitter_textfile.py命令运行该程序,您将在您的终端窗口看到整个verne.txt文件输出,因为我们没有其他代码或要求它停止。
要做到这一点,我们需要使用 tweepy 函数 api.update_status(). 这用于更新认证用户的状态,但只会更新如果状态是: 1) 不是重复,或 2) 140 个字符或更少。
让我们添加该函数并将线变量传入其中:
1[label twitterbot_textfile.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10my_file=open('verne.txt','r')
11file_lines=my_file.readlines()
12my_file.close()
13
14for line in file_lines:
15 print(line)
16 api.update_status(line)
现在我们的程序已设置为向我们的帐户推文。
例外处理和定时推文
在这个时刻,如果我们运行代码,第一行将打印,但在我们收到错误之前,我们不会走得很远:
1[secondary_label Output]
2...
3tweepy.error.TweepError: [{'code': 170, 'message': 'Missing required parameter: status.'}]
这是因为文件中的第二行是一个空行,不能用作状态。 为了处理这个问题,我们只打印线,如果不是空行。
1if line != '\n':
在Python中, n是空行字符的 escape character,所以我们的 ifstatement是告诉程序,如果行不等于空行(!=),那么我们应该继续打印它。
另一个我们应该添加的是)与秒钟的计时单位工作,所以如果我们想要推文之间一个小时,我们应该把函数写成sleep(3600)`,因为一个小时里有3600秒。
對於我們的測試目的(只為我們的測試目的),讓我們使用5秒鐘,一旦我們經常運行我們的Twitterbot,我們會想要大大增加推文之間的時間。
你可以玩你添加睡眠(5)的地方 - 我们在下面放置它会导致推文之间的延迟,因为即使线是空的也会出现延迟。
1[label twitterbot_textfile.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10my_file=open('verne.txt','r')
11file_lines=my_file.readlines()
12my_file.close()
13
14for line in file_lines:
15 print(line)
16
17# Add if statement to ensure that blank lines are skipped
18 if line != '\n':
19 api.update_status(line)
20
21# Add an else statement with pass to conclude the conditional statement
22 else:
23 pass
24
25# Add sleep method to space tweets by 5 seconds each
26 sleep(5)
当你在这一点上运行该程序时 - 如果你以前没有运行该程序 - 你将开始在您的终端上获取文件的第一行输出。
但是,如果您已经运行该程序,您可能会收到以下错误:
1[secondary_label Output]
2tweepy.error.TweepError: [{'code': 187, 'message': 'Status is a duplicate.'}]
您可以通过从您的 Twitter 帐户中删除您之前的推文来修复此问题,或者通过删除您的文件verne.txt的第一行并保存它。
要阻止该程序向您的 Twitter 帐户输出状态更新,请将)和C键放在键盘上,以便在终端窗口中中断进程。
在此时,你的程序可以运行,但让我们处理当状态是重复时我们得到的错误. 为了做到这一点,我们将添加一个试用......除外块到我们的代码,并让控制台打印出错误的原因。
1[label twitterbot_textfile.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10my_file=open('verne.txt','r')
11file_lines=my_file.readlines()
12my_file.close()
13
14for line in file_lines:
15# Add try ... except block to catch and output errors
16 try:
17 print(line)
18 if line != '\n':
19 api.update_status(line)
20 else:
21 pass
22 except tweepy.TweepError as e:
23 print(e.reason)
24 sleep(5)
现在运行该程序将处理例外,以便您可以继续运行该程序. 您可以通过将)`来修改推文之间的时间,比如15分钟。
改进 Twitterbot 计划
为了继续改进您的程序,您可以考虑将一些这些代码块定义为函数,并添加额外的sleep()函数来处理不同的情况,例如:
1[label twitterbot_textfile.py]
2...
3# Tweet a line every 15 minutes
4def tweet():
5 for line in file_lines:
6 try:
7 print(line)
8 if line != '\n':
9 api.update_status(line)
10 sleep(900)
11 else:
12 pass
13 except tweepy.TweepError as e:
14 print(e.reason)
15 sleep(2)
16
17tweet()
当您继续在Python中使用文件时,您可以创建单独的脚本,以便以更有意义的方式缩小文件的行,同时要注意140个字符的推文限制。
在这个时候,我们有一个功能齐全的Twitterbot,它从源文件中推文。在下一节中,我们将讨论一个替代的Twitterbot,该bot重新推文,跟踪和喜好。您也可以跳到 [Keeping the Twitterbot Running]的部分(https://andsky.com/tech/tutorials/how-to-create-a-twitterbot-with-python-3-and-the-tweepy-library# keeping-the-twitterbot-running)。
Twitterbot 重复推文,追踪和喜好
通过使用Tweepy库,我们可以设置一个Twitterbot,它可以重写和喜欢他人的推文,以及跟踪其他用户。
设置程序文件
首先,让我们建立一个Python文件,名为twitterbot_retweet.py'。 我们要么将全权证书加到文件的顶端,要么通过证书'增加进口说明书和查阅我们每个钥匙、机密和信使的机会。 py ' 文件,我们在上面的[Storing Capitals] (https://andsky.com/tech/tutorials/how-to-create-a-twitterbot-with-python-3-and-the-tweepy-library# storing-credentials) 部分中创建。 透过Tweepy库.
1[label twitterbot_retweet.py]
2# Import Tweepy, sleep, credentials.py
3import tweepy
4from time import sleep
5from credentials import *
6
7# Access and authorize our Twitter credentials from credentials.py
8auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
9auth.set_access_token(access_token, access_token_secret)
10api = tweepy.API(auth)
要了解更多关于这个设置,请确保看)。
基于查询查找推文
接下来,我们将创建一个可以重复推文的循环。我们将查看具有 hashtag # ocean的推文,所以我们将使用q= ocean`来运行该查询作为我们的参数的一部分。
1# For loop to iterate over tweets with #ocean, limit to 10
2for tweet in tweepy.Cursor(api.search,q='#ocean').items(10):
3
4# Print out usernames of the last 10 people to use #ocean
5 print('Tweet by: @' + tweet.user.screen_name)
有许多额外的参数,我们可以添加到我们的循环,包括:
- 使用) * 一个)为您想要指定的语言
虽然这个特定的场景 实际上不会产生任何结果 ,但让我们保持我们的 # ocean 查询,然后指定一个为期两天的时间框架来检索推文,限制我们的位置到新加坡周围100公里,并请求法语推文。
1for tweet in tweepy.Cursor(api.search,
2 q='#ocean',
3 since='2016-11-25',
4 until='2016-11-27',
5 geocode='1.3552217,103.8231561,100km',
6 lang='fr').items(10):
7 print('Tweet by: @' + tweet.user.screen_name)
有关您可以通过此和其他 Tweepy 函数传输的不同参数的更多信息,请参阅 Tweepy API 参考。
对于我们这里的示例程序,我们只会搜索 # ocean 查询. 您可以让 .items() 方法打开,但您可能会收到以下错误,因为您已经提出了太多的请求并耗尽了资源:
1[secondary_label Output]
2tweepy.error.TweepError: Twitter error response: status code = 429
所有错误代码和响应都可通过Tweepy API(https://dev.twitter.com/overview/api/response-codes)提供。
例外处理
为了改进我们的代码,而不是仅仅打印相关的Twitter用户名,让我们使用一些错误处理与一个试用......除外块。
1[label twitterbot_retweet.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10for tweet in tweepy.Cursor(api.search, q='#ocean').items():
11 try:
12 print('Tweet by: @' + tweet.user.screen_name)
13
14 except tweepy.TweepError as e:
15 print(e.reason)
16
17 except StopIteration:
18 break
现在我们可以开始告诉我们的Twitterbot根据收集的数据采取一些行动。
重定向,偏好和跟随
我们还将向终端提供我们所做的事情的反馈,并添加一个\n线路打断来更好地组织这个输出:
1[label twitter_retweet.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10for tweet in tweepy.Cursor(api.search, q='#ocean').items():
11 try:
12 # Add \n escape character to print() to organize tweets
13 print('\nTweet by: @' + tweet.user.screen_name)
14
15 # Retweet tweets as they are found
16 tweet.retweet()
17 print('Retweeted the tweet')
18
19 sleep(5)
20
21 except tweepy.TweepError as e:
22 print(e.reason)
23
24 except StopIteration:
25 break
虽然程序正在运行,你应该打开一个浏览器来检查这些重复推文是否发布到你的Twitterbot帐户. 你的帐户应该开始被重复推文,并看起来像这样:
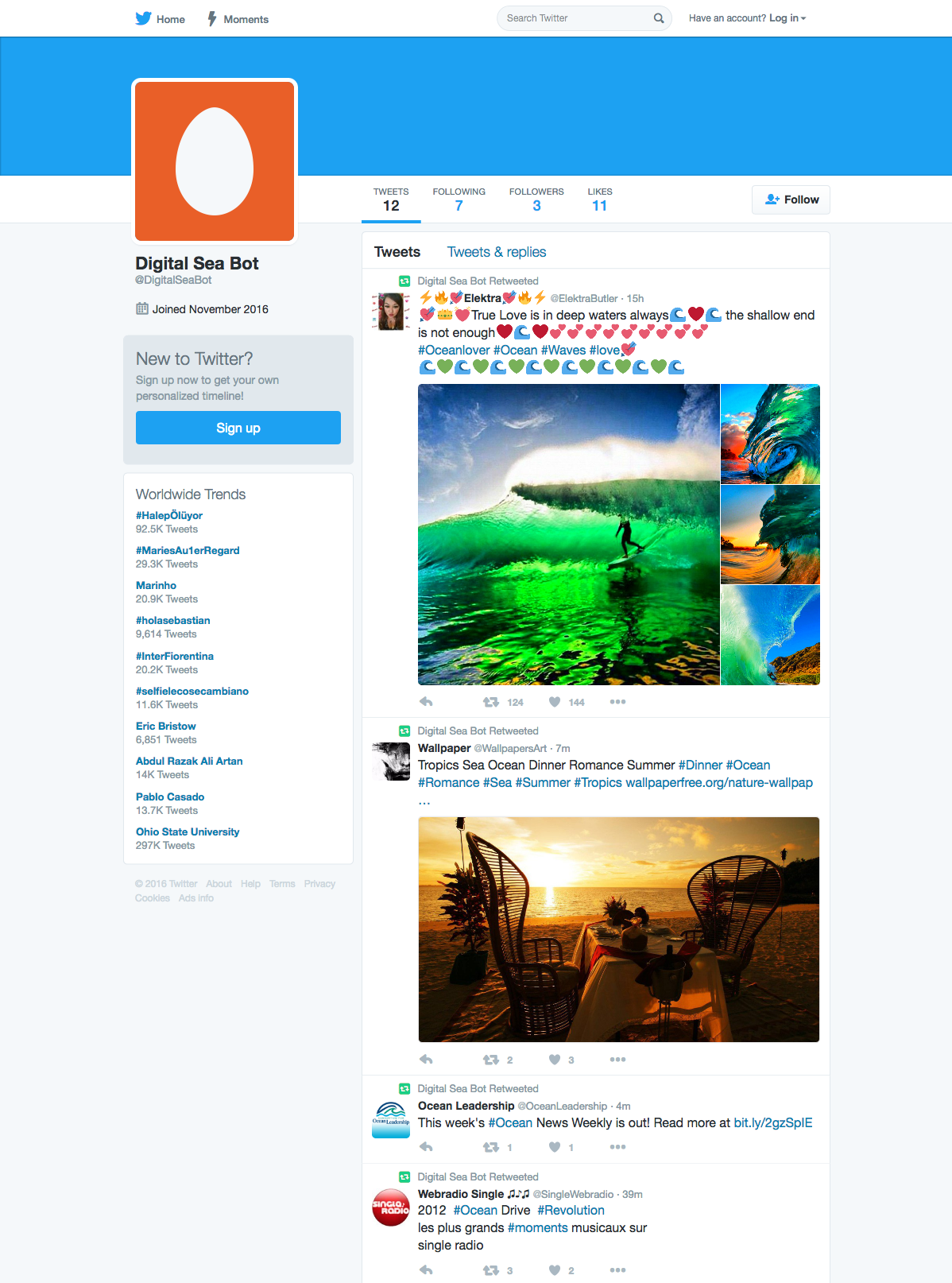
如果你运行该程序多次,你可能会发现Twitterbot正在再次找到相同的推文,但由于tweepy.TweepError的例外处理,你的Twitterbot不会重写这些,而是提供以下输出:
1[secondary_label Output]
2[{'message': 'You have already retweeted this tweet.', 'code': 327}]
我们可以添加功能,让Twitterbot喜欢找到的推文,并跟踪创建推文的用户。
1[label twitterbot_retweet.py]
2import tweepy
3from time import sleep
4from credentials import *
5
6auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
7auth.set_access_token(access_token, access_token_secret)
8api = tweepy.API(auth)
9
10for tweet in tweepy.Cursor(api.search, q='#ocean').items():
11 try:
12 print('\nTweet by: @' + tweet.user.screen_name)
13
14 tweet.retweet()
15 print('Retweeted the tweet')
16
17 # Favorite the tweet
18 tweet.favorite()
19 print('Favorited the tweet')
20
21 # Follow the user who tweeted
22 tweet.user.follow()
23 print('Followed the user')
24
25 sleep(5)
26
27 except tweepy.TweepError as e:
28 print(e.reason)
29
30 except StopIteration:
31 break
您可能会注意到,Tweepy 错误处理不会考虑以下已经被跟踪的用户,因此我们可以在.user.follow()函数之前输入一个如果语句:
1...
2 if not tweet.user.following:
3 # Don't forget to indent
4 tweet.user.follow()
5 print('Followed the user')
6...
您可以继续根据自己的喜好修改此代码,并引入更多方法来处理各种情况。
现在让我们来了解如何让这个Twitterbot在我们的服务器上运行。
保持Twitterbot运行
由于Twitterbots执行持续和自动化的任务,您可能希望让程序运行,即使您的计算机处于睡眠状态或关闭。
对于这个例子,我们将使用twitter_retweet.py文件,但您也可以使用twitterbot_textfile.py文件,或者您创建的任何其他Twitterbot文件。
<美元 > [注]
注: 在保持其中一项程序运行之前,最好修改您的程序,以便让更多的时间用于相关的 " 睡眠() " 功能。 Twitterbot将全天候运行,直到你手动停止(或直到你传给它的文本文件完成). 回顾睡眠()'功能以秒为参数,因此睡眠(3600)'将按小时计时你的微博,`睡眠(7200)'将按时计时你的微博每两小时等。 你推特上越频繁, 特别是给定标签, 你的推特机器人就越可能受到不受欢迎的注意, 如果你不确定如何最好地使用你的推特机器人,
< $ > (美元)
为了保持我们的 Twitterbot 程序运行,我们将使用) 信号. 通过使用nohup,通常出现在终端窗口的输出将被打印到名为nohup.out的文件中。
确保您位于您的 Python 环境中,可以访问 Tweepy 库,并在您的 Python 程序文件居住的目录中,然后键入以下命令:
1nohup python twitterbot_retweet.py &
您应该收到输出,其中包含一个数字([1]如果这是您开始的第一个过程)和一个数字序列:
1[secondary_label Output]
2[1] 21725
在此时,请通过检查您的帐户的 Twitter 页面来验证您的 Twitterbot 是否正在运行. 至少应该在程序进入您的sleep()功能之前发布一个新推文。
1nano nohup.out
检查是否有错误,并根据需要对程序进行更改,杀死过程,然后再次运行nohup命令,并检查您的Twitter帐户新推文。
一旦您确认您的Twitterbot正在运行,请使用登录来关闭与您的服务器的连接。
1logout
如果长时间不监测程序运行,并视服务器容量而定,nohup.out ' 可以填补您的磁盘空间。 你想或需要的时候,你可以停止你的 通过登录回你的服务器并使用 " 杀 " 命令,推特机器人。 您将使用上面生成的数字串命令 。 我们以杀死21725'为例。 由于你可能不再有这个数字的手动性,通过运行 ps 命令来获取数字的字符串以获取进程状态,并且使用-x旗子来包含所有不附在终端上的流程:
1ps -x
你应该收到一个看起来像这样的输出:
1[secondary_label Output]
2 PID TTY STAT TIME COMMAND
321658 ? Ss 0:00 /lib/systemd/systemd --user
421660 ? S 0:00 (sd-pam)
521725 ? S 0:02 python twitterbot_retweet.py
621764 ? S 0:00 sshd: sammy@pts/0
721765 pts/0 Ss 0:00 -bash
821782 pts/0 R+ 0:00 ps xw
你应该看到你的Python程序在运行,在我们的情况下它的ID是21725,在第三行。
1kill 21725
如果您再次运行ps -x命令,Python Twitterbot 的进程将不再存在。
结论
本教程通过设置和运行两个不同的版本的Twitterbots,以自动与Twitter社交媒体平台互动。
从这里,您还可以深入 Tweepy 库和 Twitter API 来创建列表,将用户添加到列表中,与直接消息进行交互,并与 Twitter 进行流媒体以实时下载推文。