介绍
RethinkDB 是一个 NoSQL 数据库,它有一个易于使用的 API 来与数据库进行交互。 RethinkDB 还使建立数据库集群变得简单;即服务器组为相同的数据库和表服务。
本教程将探讨如何设置集群,导入数据,并保护它. 如果您是新的RethinkDB,请查看本教程(https://andsky.com/tech/tutorials/how-to-install-and-configure-rethinkdb-on-an-ubuntu-12-04-vps)的基本知识,然后深入到更复杂的集群配置过程。
前提条件
本教程需要运行 Ubuntu 14.04 LTS 的至少 2 个 Droplets,名为 rethink1 & ** rethink2** (这些名称将在本教程中使用)。
本教程还引用了 Python 客户端驱动程序,这是在 本教程中解释的。
设置一个节点
RethinkDB 中的集群没有特殊节点;它是一种纯粹的对等网络. 在我们可以配置集群之前,我们需要安装 RethinkDB. 在每个服务器上,从您的主目录中添加 RethinkDB 键和存储库到 apt-get:
1source /etc/lsb-release && echo "deb http://download.rethinkdb.com/apt $DISTRIB_CODENAME main" | sudo tee /etc/apt/sources.list.d/rethinkdb.list
2
3wget -qO- http://download.rethinkdb.com/apt/pubkey.gpg | sudo apt-key add -
然后更新 apt-get 并安装 RethinkDB:
1sudo apt-get update
2sudo apt-get install rethinkdb
接下来,我们需要将 RethinkDB 设置为在启动时运行。
1sudo cp /etc/rethinkdb/default.conf.sample /etc/rethinkdb/instances.d/cluster_instance.conf
启动脚本也作为一个配置文件。让我们打开这个文件:
1sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
机器的名称(网页管理控制台和日志文件中的名称)在这个文件中设置,让我们通过找到行(在最底部)来使其与机器的主机名称相同:
1# machine-name=server1
把它改成:
1machine-name=rethink1
(注:如果您在首次启动 RethinkDB 之前没有设置该名称,则它会自动设置一个 Dota 主题的名称。
设置 RethinkDB 以便从所有网络接口中获取:
1# bind=127.0.0.1
把它改成:
1bind=all
保存配置并关闭nano(通过按Ctrl-X,然后按Y,然后按Enter)我们现在可以使用新的配置文件开始RethinkDB:
1sudo service rethinkdb start
你应该看到这个输出:
1rethinkdb: cluster_instance: Starting instance. (logging to `/var/lib/rethinkdb/cluster_instance/data/log_file')
RethinkDB现在正在运行。
RethinkDB 的安全性
我们已经启用了bind=all选项,使RethinkDB从服务器外部可访问,这是不安全的,所以我们需要阻止RethinkDB从互联网上访问,但我们需要允许从授权的计算机访问其服务。
对于集群端口,我们将使用防火墙来关闭我们的集群,对于 Web 管理控制台和驱动器端口,我们将使用 SSH 隧道从服务器外部访问它们。
在所有 RethinkDB 服务器上重复这些步骤。
首先,阻止所有外部连接:
1# The Web Management Console
2sudo iptables -A INPUT -i eth0 -p tcp --dport 8080 -j DROP
3sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 8080 -j ACCEPT
4
5# The Driver Port
6sudo iptables -A INPUT -i eth0 -p tcp --dport 28015 -j DROP
7sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 28015 -j ACCEPT
8
9# The Cluster Port
10sudo iptables -A INPUT -i eth0 -p tcp --dport 29015 -j DROP
11sudo iptables -I INPUT -i eth0 -s 127.0.0.1 -p tcp --dport 29015 -j ACCEPT
有关配置 IPTables 的更多信息,请参阅 此教程。
让我们安装iptables-persistent来保存我们的规则:
1sudo apt-get update
2sudo apt-get install iptables-persistent
你会看到这样的菜单:
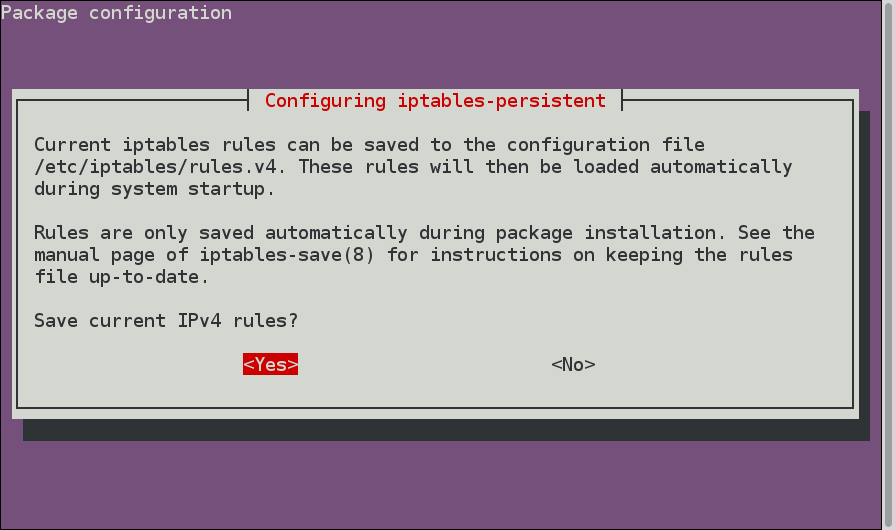
选择Yes选项(按Enter)来保存防火墙规则,您还会看到有关IPv6规则的类似菜单,您也可以保存。
设置管理用户
要访问 RethinkDB 的 Web 管理控制台和驱动程序接口,我们需要设置 SSH 隧道。
1sudo adduser ssh-to-me
然后为我们的新用户设置授权密钥文件:
1sudo mkdir /home/ssh-to-me/.ssh
2sudo touch /home/ssh-to-me/.ssh/authorized_keys
如果您正在使用 SSH 连接到云服务器,请在 本地计算机上 打开一个终端. 如果您没有,您可能想 了解有关 SSH 密钥的更多信息。
1cat ~/.ssh/id_rsa.pub
然后将该密钥添加到新帐户中,在服务器上打开 authorized_keys 文件 **:
1sudo nano /home/ssh-to-me/.ssh/authorized_keys
将键插入文件中,然后保存并关闭 nano(‘Ctrl-X’,然后‘Y’,然后‘Enter’)。
您需要对其他集群节点重复所有这些步骤。
导入或创建数据库
您可能想将现有数据库导入到您的集群中,但如果您在另一个服务器上或在该服务器上拥有现有数据库,则只需要这样做;否则,RethinkDB 会自动创建一个空的数据库。
** 如果您需要导入外部数据库:**
如果你想要导入的数据库没有存储在rethink1,你需要复制它。 首先,找到你当前的RethinkDB数据库的路径。 如果你使用rethinkdb命令启动旧数据库,这将是自动创建的rethinkdb_data目录。
1sudo scp -rpC From Server User@From Server IP:/RethinkDB Data Folder/* /var/lib/rethinkdb/cluster_instance/data
例如:
1sudo scp -rpC root@111.222.111.222:/home/user/rethinkdb_data/* /var/lib/rethinkdb/cluster_instance/data
然后重新启动 RethinkDB:
1sudo service rethinkdb restart
** 如果您在 rethink1 上有现有数据库:**
如果您在 rethink1 上有现有的 RethinkDB 数据库,则该过程是不同的。
1sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
然后,找到您想要导入的 RethinkDB 数据库的路径. 如果您使用rethinkdb命令启动旧数据库,这将是自动创建的rethinkdb_data目录。
1directory=/home/user/rethink/rethinkdb_data/
關閉檔案以儲存變更(使用「Ctrl-X」,然後使用「Y」,然後使用「Enter」)。
1sudo service rethinkdb restart
重要的是要注意,导入现有数据库意味着 rethink1 将继承数据库的旧机器的名称。
创建一个集群
要创建一个集群,你需要允许所有集群机器通过对方的防火墙。在你的 rethink1 机器上,添加一个IPTables规则以允许其他节点通过防火墙。
1sudo iptables -I INPUT -i eth0 -s rethink2 IP -p tcp --dport 29015 -j ACCEPT
重复对您想要添加的任何其他节点的命令。
然后保存防火墙规则:
1sudo sh -c "iptables-save > /etc/iptables/rules.v4"
然后对其他节点重复这些步骤. 对于两个服务器的设置,您现在应该连接到 rethink2 并解锁 ** rethink1** 的 IP。
现在你需要连接所有节点来创建一个集群. 使用SSH连接到 rethink2 并打开配置文件:
1sudo nano /etc/rethinkdb/instances.d/cluster_instance.conf
加入选项指定了要加入的群集的地址,在配置文件中找到加入行:
1# join=example.com:29015
并将其替换为:
1join=rethink1 IP
保存并关闭配置文件(使用Ctrl-X,然后Y,然后Enter),然后重新启动RethinkDB:
1sudo service rethinkdb restart
第一个节点, rethink1 ,不需要加入更新. 重复对所有其他节点的配置文件编辑,除了 ** rethink1** 。
您现在拥有一个功能齐全的 RethinkDB 集群!
连接到 Web 管理控制台
Web 管理控制台是一个易于使用的在线接口,可以访问 RethinkDB 的基本管理功能. 当您需要查看群集状态、运行单个 RethinkDB 命令和更改基本表设置时,此控制台非常有用。
集群中的每个 RethinkDB 实例都服务于管理控制台,但这只能从服务器的 localhost 名称空间获得,因为我们使用防火墙规则来阻止它从世界其他地方。我们可以使用 SSH 隧道将我们对 localhost:8080 的请求重定向到 rethink1 ,该请求将在其名称空间中发送到 localhost:8080。
1ssh -L 8080:localhost:8080 ssh-to-me@rethink1 IP
如果您在浏览器中访问 localhost:8080,您现在将看到您的 RethinkDB Web 管理控制台。
如果您收到一个连接:已使用的地址错误,则您已经在计算机上使用端口 8080. 您可以将 Web 管理控制台转发到您的计算机上可用的另一个端口,例如,您可以将其转发到端口 8081 并到 localhost:8081:
1ssh -L 8081:localhost:8080 ssh-to-me@rethink1 IP
如果您看到有两个测试数据库的冲突,您可以更名其中一个。
使用 Python 驱动程序连接到集群
在此设置中,所有 RethinkDB 服务器(Web 管理控制台、驱动器端口和集群端口)都被阻止从外部世界。我们可以使用 SSH 隧道连接到驱动器端口,就像 Web 管理端口一样。
首先,选择一个节点来连接。如果您有多个客户端(例如,Web 应用程序服务器)连接到集群,您将希望在集群中平衡它们。写一个客户端列表,然后为每个客户端分配一个服务器是很好的想法。
在本示例中,我们将使用 rethink2 作为我们的连接服务器,但是,在一个较大的系统中,您的数据库和Web应用程序服务器是分开的,您希望从实际上正在进行数据库调用的Web应用程序服务器中执行此操作。
然后,在 连接服务器 上,生成一个SSH密钥:
1ssh-keygen -t rsa
并将其复制到您的剪辑板:
1cat ~/.ssh/id_rsa.pub
然后,通过打开autorized_keys文件并粘贴在新行上,授权新的密钥到 群节节节点 (在本示例中, ** rethink1** ):
1sudo nano /home/ssh-to-me/.ssh/authorized_keys
关闭 nano 并保存文件(‘Ctrl-X’,然后是 ‘Y’,然后是 ‘Enter’)。
接下来,使用SSH隧道访问驱动器端口,从 连接分离 :
1ssh -L 28015:localhost:28015 ssh-to-me@Cluster Node IP -f -N
现在可以从 localhost:28015 访问该驱动程序。如果您收到一个连接:地址已经在使用错误,您可以更改端口。
1ssh -L 28016:localhost:28015 ssh-to-me@Cluster Node IP -f -N
在连接服务器上安装 Python 驱动程序. 这里有快速运行命令,您可以在 本教程中详细阅读它们。
安装 Python 虚拟环境:
1sudo apt-get install python-virtualenv
创建~/rethink目录:
1cd ~
2mkdir rethink
移动到目录并创建新的虚拟环境结构:
1cd rethink
2virtualenv venv
激活环境(您必须在启动 Python 界面之前每次激活环境,否则您会收到关于缺少模块的错误):
1source venv/bin/activate
安装 RethinkDB 模块:
1pip install rethinkdb
现在从 连接服务器 开始 Python:
1python
连接到数据库,如果需要,请确保用您所使用的端口代替「28015」:
1import rethinkdb as r
2r.connect("localhost", 28015).repl()
创建测试表:
1r.db("test").table_create("test").run()
将数据插入测试表中:
1r.db("test").table("test").insert({"hello":"world"}).run()
2r.db("test").table("test").insert({"hello":"world number 2"}).run()
然后打印数据:
1list(r.db("test").table("test").run())
你应该看到类似于以下的输出:
1[{u'hello': u'world number 2', u'id': u'0203ba8b-390d-4483-901d-83988e6befa1'},
2 {u'hello': u'world', u'id': u'7d17cd96-0b03-4033-bf1a-75a59d405e63'}]
设置 Sharding
在 RethinkDB 中,您可以配置表格分割(分割)到多个云服务器中。 分割是让数据集大于单台机器的RAM的数据集的简单方法,因为更多的RAM可用于缓存。
要做到这一点,请前往 Web 管理控制台中的 ** 表** 选项卡。
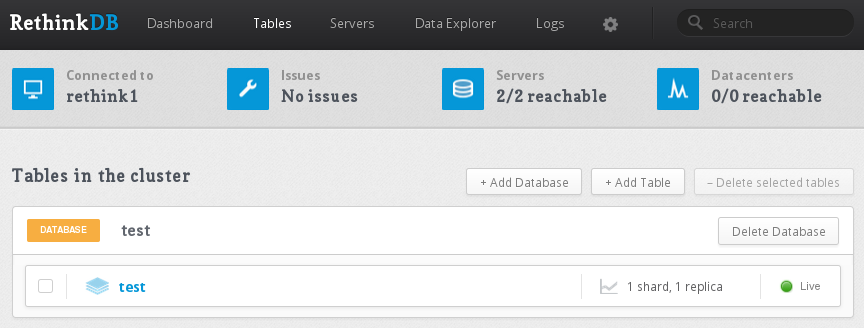
点击 test 表(我们在上一节创建的表)以输入其设置。
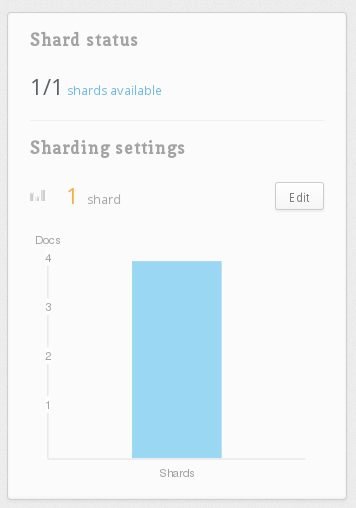
点击编辑按钮,在那里,您可以输入服务器的数量来分割表。输入 2 此示例。
您可能會注意到,您可以擁有最大數量的碎片,這等於資料庫中的文件數量. 如果您正在嘗試為新表設定碎片,您將需要等待更多的數據或添加虛假數據,以便自己添加更多碎片。
高级 Sharding
内部而言,RethinkDB 基于文档 ID 的范围分区,这意味着如果我们有一个具有 ID A、B、C 和 D 的数据集,RethinkDB 可能会将其分为 2 个分区: A、B(至 C 至 无限)和 C、D(至 + 至 无限) 如果您要插入一个具有 ID A1 的文档,那么它将位于第一个分区的范围内(至 C 至 无限),所以它将进入该分区。
在 Web 管理控制台的 Data Explorer 卡上,我们可以通过运行此命令创建一个表格(键入后单击 ** Run** ):
1r.db('test').tableCreate('testShards')
然后输入我们的测试数据:
1r.db("test").table("testShards").insert([
2 {id:"A"},
3 {id:"B"},
4 {id:"C"},
5 {id:"D"},
6 {id:"E"}])
现在我们可以详细配置碎片。 要做到这一点,我们需要输入 admin shell。 admin shell 是控制您的群集的一种更先进的方式,允许您精心调整设置。
1rethinkdb admin
接下来,我们可以看到关于我们的桌子的一些信息:
1ls test.testShards
预期产量:
1table 'testShards' b91fda27-a9f1-4aeb-bf6c-a7a4211fb674
2
3...
4
51 replica for 1 shard
6shard machine uuid name primary
7-inf-+inf 91d89c12-01c7-487f-b5c7-b2460d2da22e rethink1 yes
在 RethinkDB 中,可以使用 database.name (test.testShards),名称 (testShards) 或表 uuid (e780f2d2-1baf-4667-b725-b228c7869aab)。
让我们把这个碎片分成两部分: -infinity 到 C 和 C 到 +infinity:
1split shard test.testShards C
命令的通用形式是:
1split shard TABLE SPLIT-POINT
运行ls testShards再次表明,碎片已经分裂,您可能想将新碎片从一台机器移动到另一台机器。 对于这个例子,我们可以将碎片inf-C (-infinty to C)插入机器 rethink2 :
1pin shard test.testShards -inf-C --master rethink2
命令的通用形式是:
1pin shard TABLE SHARD-RANGE --master MACHINE-NAME
如果你再次测试Shards,你应该看到该碎片已经迁移到另一个服务器。
如果我们知道共同的边界,我们也可以合并2个碎片,让我们合并我们刚刚制作的碎片(无限到C和C到+无限):
1merge shard test.testShards C
命令的通用形式是:
1merge shard TABLE COMMON-BOUNDARY
要离开壳,键入出口
安全地移除机器
当一个文档被分割在多个机器上时,一台机器将始终保持其主要索引. 如果某个文档的主要索引的云服务器被脱机,该文档将丢失。
在本示例中,我们将尝试将数据从节点 rethink2 迁移到 ** rethink1** 作为唯一节点。
请在 rethink1 上输入 RethinkDB 管理壳:
1rethinkdb admin
首先,让我们列出 rethink2 负责的碎片(文件组):
1ls rethink2
你的输出应该像这样的东西:
1machine 'rethink2' bc2113fc-efbb-4afc-a2ed-cbccb0c55897
2in datacenter 00000000-0000-0000-0000-000000000000
3
4hosting 1 replicas from 1 tables
5table name shard primary
6b91fda27-a9f1-4aeb-bf6c-a7a4211fb674 testShards -inf-+inf yes
这表明 rethink2 是负责一个表的主要碎片的IDbdfceefb-5ebe-4ca6-b946-869178c51f93。
1pin shard test.testShards -inf-+inf --master rethink1
命令的通用形式是:
1pin shard TABLE SHARD-RANGE --master MACHINE-NAME
如果你现在运行ls rethink1,你会看到碎片已经移动到那个机器. 一旦每个碎片已经从 rethink2 移动到 ** rethink1** ,你应该离开管理员壳:
1exit
在不需要的服务器上停止 RethinkDB 现在是安全的,重要的是:在您想要删除_ 的机器上运行此功能。
1sudo service rethinkdb stop
下次您访问 Web 管理控制台时,RethinkDB 将显示一个明亮的红色警告。
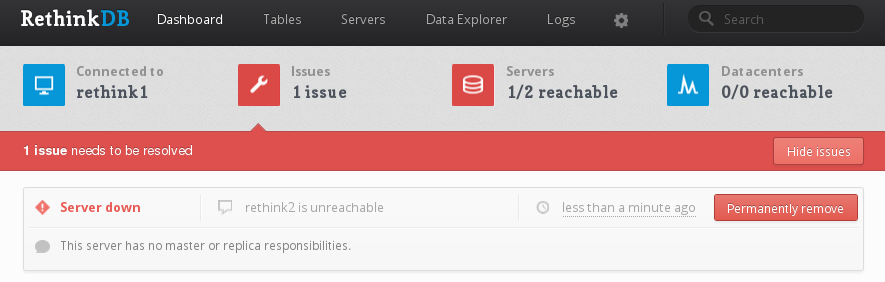
如果显示的问题看起来像上面的问题,没有主责任列出,请单击 永久删除 . 这将将机器从集群中删除。
注意: 如果您尝试将机器重新添加到集群中,您将看到有关僵尸机器的消息,您可以删除数据目录以修复此问题:
1sudo rm -r /var/lib/rethinkdb/cluster_instance/
2sudo service rethinkdb restart