介绍
Graphite 是一个图形库,允许您以灵活和强大的方式可视化不同类型的数据。
在之前的指南中,我们讨论了 如何安装和配置Graphite本身和 如何安装和配置 collectd编译系统和服务统计数据。
在本指南中,我们将讨论如何安装和配置StatsD。
StatsD 将统计数据清除到 Graphite,并与 Graphite 配置的写入间隔同步。
通过这种方式,StatsD允许应用程序在发送 Graphite 统计数据的有效率限制周围工作,它有许多编写在不同的编程语言的库,这使得与您的应用程序建立统计跟踪是微不足道的。
在本指南中,我们将安装和配置StatsD. 我们将假定您已遵循前面指南的安装说明,并且您在Ubuntu 14.04服务器上配置了Graphite和collectd。
安装 StatsD
StatsD 程序在 Ubuntu 默认存储库中不可用,但它可以在 GitHub 上使用,并且具有将其编译成 Ubuntu 包所需的配置文件。
购买组件
在我们安装实际程序之前,我们需要从存储库中获取几个包,我们需要git,以便我们可以克隆存储库,我们也需要node.js,因为StatsD是一个节点应用。
我们还需要一些包,这将使我们能够构建一个Ubuntu包。
1sudo apt-get install git nodejs devscripts debhelper
更具体地说,我们将在我们的家庭目录中创建一个名为构建的目录,以完成这个过程。
现在创建目录:
1mkdir ~/build
现在,我们会将StatsD项目克隆到该目录中,然后移动到目录中,然后发出克隆命令:
1cd ~/build
2git clone https://github.com/etsy/statsd.git
构建和安装包
移动到包含我们的 StatsD 文件的新目录:
1cd statsd
现在,我们可以通过简单地发出这个命令来创建 StatsD 包:
1dpkg-buildpackage
将创建一个 .deb 文件在 ~/build 目录中. 让我们回到该目录中。
1cd ..
在我们安装包之前,我们想要停止我们的 Carbon 服务,原因是StatsD 服务在安装时会立即开始发送信息,并且尚未正确配置。
暂时停止碳服务,发出此命令:
1sudo service carbon-cache stop
然后我们可以将包装安装到我们的系统中:
1sudo dpkg -i statsd*.deb
正如我们之前所说的,Statsd 过程会自动启动。让我们暂时停止,重新启动我们的 Carbon 服务。这将使我们能够配置 StatsD,同时仍然为我们的其他服务留下 Carbon 活跃:
1sudo service statsd stop
2sudo service carbon-cache start
StatsD 服务现在已安装在我们的服务器上! 但是,我们仍然需要配置所有组件以便一起正常工作。
配置 StatsD
我们应该做的第一件事是修改StatsD配置文件。
使用您的文本编辑器打开文件:
1sudo nano /etc/statsd/localConfig.js
它应该看起来像这样:
{
graphitePort: 2003
, graphiteHost: "localhost"
, port: 8125
}
我们只想在这个配置中调整一个设置,我们想要关闭所谓的遗留命名空间。
StatsD 使用此方法以不同的方式组织其数据,但在更新的版本中,它已经在一个更直观的结构上进行标准化。
为了做到这一点,我们需要添加以下几行:
{
graphitePort: 2003
, graphiteHost: "localhost"
, port: 8125
, graphite: {
legacyNamespace: false
}
}
这将允许我们使用更合理的命名惯例. 保存和关闭文件,当你完成。
为 StatsD 创建存储计划
接下来,我们需要定义一些更多的存储方案。
打开存储计划文件:
1sudo nano /etc/carbon/storage-schemas.conf
我们将使用完全相同的保留策略,我们定义的 collectd. 唯一的区别是名称和匹配模式。
StatsD 将其所有数据发送到 Graphite 以一个stats前缀,所以我们可以匹配该模式。
1[statsd]
2pattern = ^stats.*
3retentions = 10s:1d,1m:7d,10m:1y
保存并关闭文件,当你完成。
创建数据聚合配置
StatsD 以非常具体的方式发送数据,因此我们可以轻松地通过匹配正确的模式来确保我们正确地汇总数据。
在您的编辑器中打开文件:
1sudo nano /etc/carbon/storage-aggregation.conf
我们需要以灵活的方式配置我们的汇总,以便准确地转换我们的值。我们将从 StatsD 项目中获取一些提示,说明如何最好地汇总数据。
目前,合并看起来像这样:
[min] pattern = \.min$ xFilesFactor = 0.1 aggregationMethod = min [max] pattern = \.max$ xFilesFactor = 0.1 aggregationMethod = max [sum] pattern = \.count$ xFilesFactor = 0 aggregationMethod = sum [default_average] pattern = .* xFilesFactor = 0.5 aggregationMethod = average
我们想要匹配以),但它有点被错误标记,所以我们会调整。
我们还希望以 respectively.lower 和.upper 结尾的指标的 min 和 max 值。 这些指标名称可能在它们之后也有数字,因为它们可以用来表示某个百分比的顶部值(例如,upper_90)。
最后,我们想要配置我们的计量器,这些计量器基本上只是衡量某物的当前值(如速度计)。
最后,文件应该看起来像这样:
[min] pattern = \.min$ xFilesFactor = 0.1 aggregationMethod = min [max] pattern = \.max$ xFilesFactor = 0.1 aggregationMethod = max [count] pattern = \.count$ xFilesFactor = 0 aggregationMethod = sum [lower] pattern = \.lower(_\d+)?$ xFilesFactor = 0.1 aggregationMethod = min [upper] pattern = \.upper(_\d+)?$ xFilesFactor = 0.1 aggregationMethod = max [sum] pattern = \.sum$ xFilesFactor = 0 aggregationMethod = sum [gauges] pattern = ^.* \.gauges\..* xFilesFactor = 0 aggregationMethod = last [default_average] pattern = .* xFilesFactor = 0.5 aggregationMethod = average
保存并关闭它,当你完成。
开始服务
现在你已经配置了一切,我们可以做一些服务管理。
首先,你会想要重新启动Carbon以获取你刚刚设置的新设置,最好完全停止服务,等待几秒钟,然后启动它,而不是仅仅使用重新启动命令:
1sudo service carbon-cache stop ## wait a few seconds here
2sudo service carbon-cache start
现在,您还可以启动您的 StatsD 服务,该服务将连接到 Carbon:
1sudo service statsd start
就像 Carbon 本身一样,StatsD 也报告了自己的统计数据,这意味着您可以立即看到一些新的信息,如果您在浏览器中再次访问您的 Graphite 页面。
http://domain_name_or_ip
正如你所看到的,我们有很多不同的信息,所有这些都属于StatsD本身:
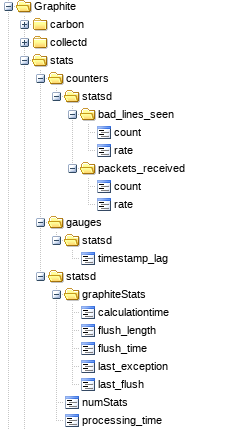
让我们来了解一下如何输入StatsD数据,以及我们如何与它进行交互。
StatsD 数据指数的解剖学
StatsD 服务通过 TCP 连接连接到 Graphite 服务,从而实现可靠的信息传输。
然而,StatsD 本身听取 UDP 包. 它收集在一段时间内发送给它的所有包(默认情况下是 10 秒)。
重要的是要意识到,10秒的冲洗间隔正是我们在存储计划中配置的最短的存储间隔,这两个配置值必须匹配,因为这正是 StatsD 能够绕过每间隔只接受一个值的碳限制。
由于这些程序之间的差异,我们以稍微不同的方式将数据发送到StatsD,而不是直接发送到Graphite。
echo "metric_name metric_value `date +%s` | nc -q0 127.0.0.1 2003
这有一些优点,例如允许您设置您正在接收的数据的时刻印,这可以允许您反复添加数据。
语法看起来像这样:
echo "metric_name:metric_value|type_specification" | nc -u -w0 127.0.0.1 8125
这将发送一个UDP包到StatsD正在收听的端口。
请记住,就像直接向图形发送统计数据一样,这仍然不是通常发送统计数据的方式。
有许多伟大的 StatsD 客户端库,可以轻松地从您使用任何编程逻辑来创建的应用程序发送统计数据。
计量名称和值相当自我解释,让我们来看看可能的计量类型是什么,以及它们对 StatsD 意味着什么:
- 联合国 ** ** c ** : 这表示一个"数". 基本上,它将 StatsD 在冲洗间隔内收到的一个度量的所有值加起来,并发送总值. 这与"碳"使用的"和"聚合法类似,这就是为什么我们告诉"碳"在存储更长的这种度量间隔时使用这个聚合法. ***** g : 这表示有轨迹 测量仪显示某物的现值,类似于速度计或燃料计. 在这种情况下,我们只对最近的价值感兴趣。 状态 D将继续发送同值的Carbon,直到它得到不同的值. 碳利用"最后"方法将这些数据相加,以保持信息的含义.
- **联合国 ** ** ** : 这个标记表示所传递的值是一个数学集. 数学中的集包含独特的值. 这样我们就可以在 StatsD 上抛出一串这种类型的值, 它会算出它得到独特值的次数。 这对计算独特用户数量等任务可能有用(假设您拥有与这些用户相关联的独特id属性).
- 联合国 ** 微秒 : 这表明该值是一个时间跨度。 状态 D取出计时值,实际上根据数据创造出相当多不同的信息. 它传递关于平均值,百分位数,标准差,和等的碳信息. 所有这些必须用碳进行正确汇总, 这就是为什么我们增加了相当多的汇总方法。 .
正如你可以看到的,StatsD做很多事情来使我们的指标更容易消化,它以对大多数应用程序有意义的方式谈论统计数据,只要你告诉它数据代表什么,它将使数据进入正确的格式。
探索不同类型的数据
彩票
让我们向StatsD发送一些数据来尝试这个。最简单的就是一个计量器。这将为当前状态设置一个指数,所以它只会在接收的最后一个值中传递:
1echo "sample.gauge:14|g" | nc -u -w0 127.0.0.1 8125
现在,如果在十秒之后(StatsD的流率)我们更新了Graphite界面,我们应该看到新的 stat(它将在)。
请注意,这一次线是如何不间断的。我们可以更新图表,每个间隔都会有一个值。以前,Graphite 会因为在一段时间内没有收到某些指标的值而在其数据中存在差距。
要查看变化,让我们将其发送给数值的其他几个值:
1echo "sample.gauge:10|g" | nc -u -w0 127.0.0.1 8125
现在请等待至少十秒,以便 StatsD 发送该值,然后发送:
1echo "sample.gauge:18|g" | nc -u -w0 127.0.0.1 8125
你会看到一个看起来有点类似的图表(我们正在看一个8分钟的时间框):
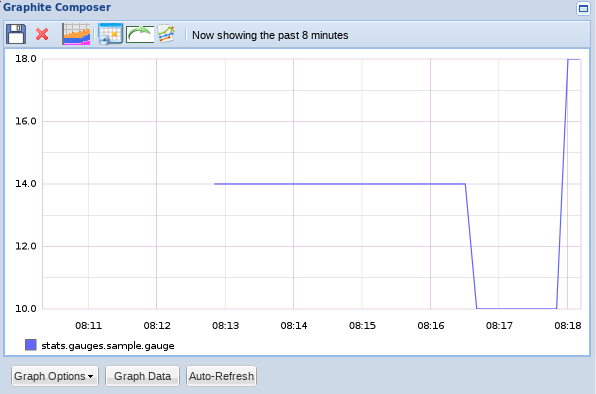
正如你所看到的,这与图形已经运作的方式非常相似,因为它每隔10秒记录一个值,而StatsD则确保每个间隔使用最后一个已知值。
计数
让我们通过配置一个计数指数来对比一下这一点。
StatsD 会收集它在其 10 秒 flush 间隔中接收的所有数据,并将它们合并,以发送该时间框架的单个值。
例如,我们可以连续多次向 StatsD 射出一个计数指数:
1echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
2echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
3echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
4echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
5echo "sample.count:1|c" | nc -u -w0 127.0.0.1 8125
现在,假设这些都是在相同的间隔中发送的(一些值可能在间隔划分的两侧下降),当我们更新接口时,我们应该看到一个数值。
实际上有两个指标被创建了,计数指标告诉我们在我们的冲浪间隔内发生的次数,而率指标将这个数字分为十来达到每秒发生的次数。
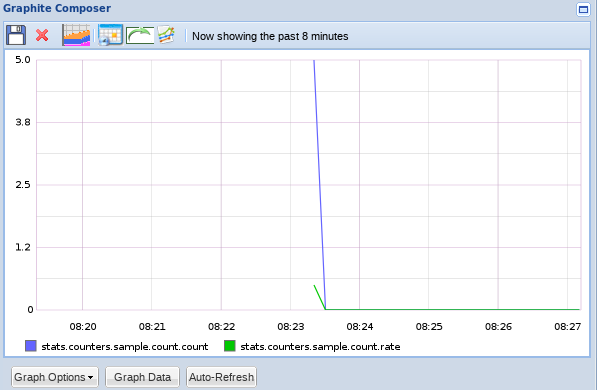
正如你可以看到的,与计量指标不同,计量指标不会保持它们的值在闪烁之间。这就是指数的含义。如果你在计数用户点击按钮的次数,仅仅因为他在十秒内击中它两次,并不意味着接下来的十秒数也将是两次。
设置
现在让我们试试一套。
因此,我们可以发送它五个记录,但如果四个有相同的值,那么记录的数目将是两,因为这是唯一的值的数目:
1echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
2echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
3echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
4echo "sample.set:50|s" | nc -u -w0 127.0.0.1 8125
5echo "sample.set:11|s" | nc -u -w0 127.0.0.1 8125
你可以在下面的图像中看到,我的值最初分为一个间隔,所以只有一个数字被记录下来. 我不得不再次尝试以获得序列第二次:
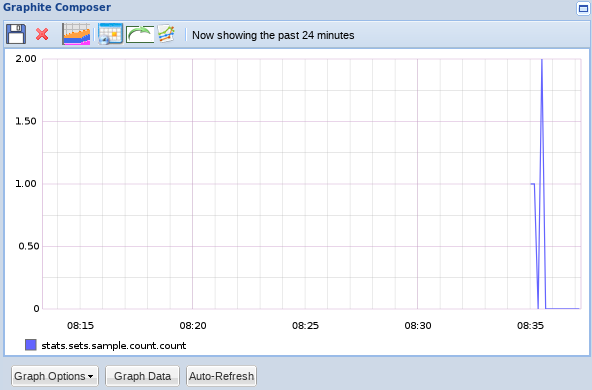
正如你所看到的,我们传递的实际 value 在一组中是微不足道的,我们只关心传递了多少个独特值。
时间表
计时器也许是最有趣的指标。
StatsD 在计算计时器的数据方面工作最多,它会发送许多不同的指标:
1echo "sample.timer:512|ms" | nc -u -w0 127.0.0.1 8125
如果我们在几分钟内发送多个值,我们可以看到许多不同的信息,如平均执行时间、计数指数、上和下值等。
它可能看起来像这样的东西:
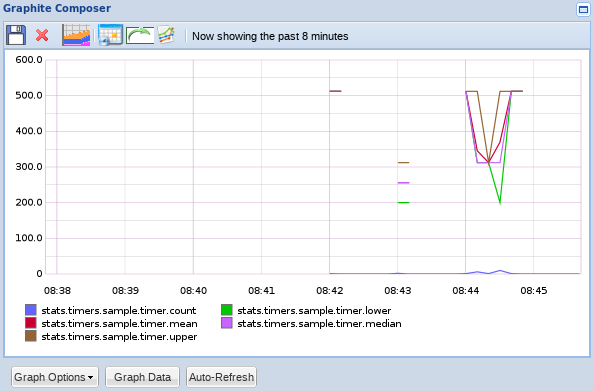
这是一个很好的指标,用于提供有关您正在创建的程序如何执行的信息,它可以告诉您您正在进行的更改是否会减慢您的应用程序。
喂养 StatsD 指数
现在你已经了解了如何构建数据包,让我们简要看看我们可以在我们的程序中使用的 StatsD 库之一,任何具有发送 UDP 数据包功能的语言都可以创建 StatsD 指标,但库可以使其特别简单。
由于Graphite使用Django,让我们留在这个环境中,看看一个Python库。
首先,安装pip,一个Python包管理器:
1sudo apt-get install python-pip
现在,我们可以告诉它通过键入安装python-statsd包的最新版本:
1sudo pip install python-statsd
这是一个非常简单的StatsD客户端。
启动 Python 交互式会话来加载库:
1python
现在,我们可以通过键入导入图书馆:
1import statsd
从这里开始,使用非常简单,我们可以创建代表我们各种指标的对象,然后根据我们的意愿调整它们。
例如,我们可以创建一个计量对象,然后通过键入将其设置为15:
1gauge = statsd.Gauge('Python_metric')
2gauge.send('some_value', 15)
然后我们可以使用gauge.send 将我们想要的值发送到 StatsD. 图书馆与其他计量类型具有相似的功能. 您可以通过 查看项目页面来了解它们。
您应该对如何在应用程序中构建跟踪有一个很好的想法. 将任意指标发送到StatsD进行跟踪和分析的能力使得跟踪统计数据变得如此容易,所以没有理由不收集数据。
结论
通过运行本教程和最后一个,您还配置了 collectd 来收集系统性能的指标, StatsD 来收集关于您自己的开发项目的任意数据。
通过学习如何利用这些工具,您可以开始创建复杂而可靠的统计跟踪,可以帮助您对环境的每个部分做出明智的决定。