一个文章从 Fluentd
介绍
什么是流畅?什么是流畅?
Fluentd 是一个开源数据收集器,旨在统一日志基础设施,旨在使操作工程师,应用程序工程师和数据工程师通过简化和可扩展来收集和存储日志。
在流动之前
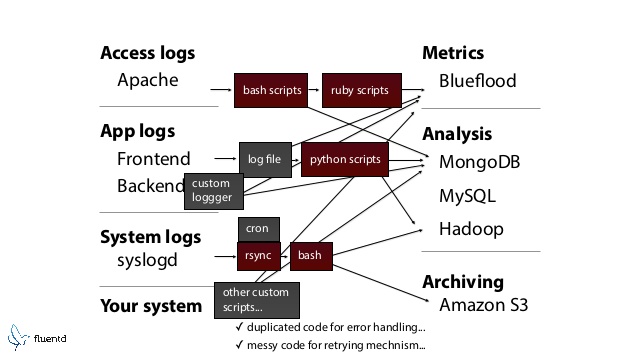
流动后
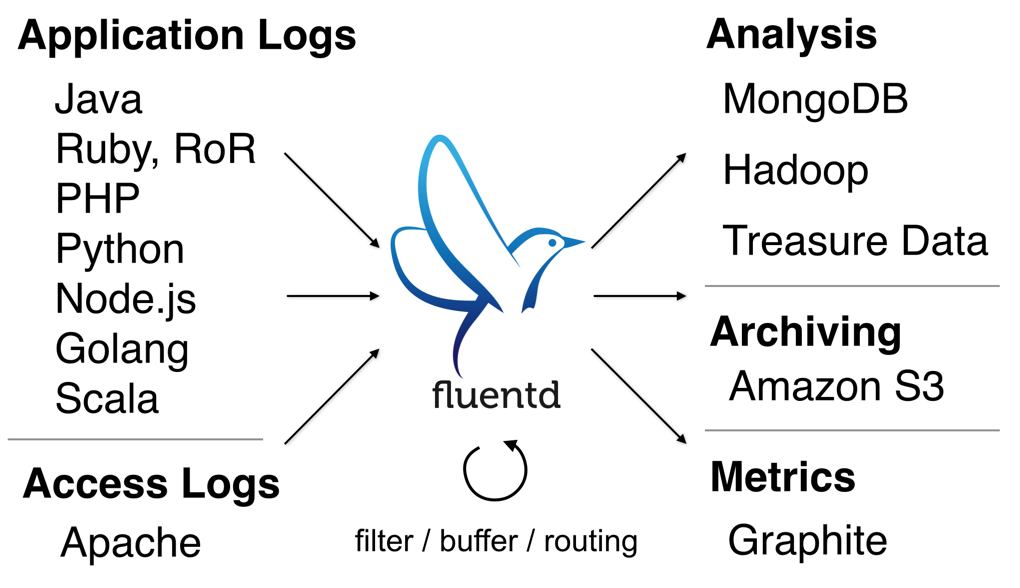
关键特征
Fluentd 有四个关键功能,使其适合建造清洁、可靠的木材管道:
*与JSON统一记录: 流利地尝试尽可能地将数据结构化为JSON. 这使得流利公司能够统一处理日志数据的所有方面:收集、过滤、缓冲和输出多个来源和目的地的日志。 JSON的下游数据处理要容易得多,因为它有足够的结构可以访问,而不会强制硬性计划 *可拆卸建筑: Fluentd有一个灵活的插件系统,允许社区扩展其功能. 300+由社区贡献的插件将数十个数据源连接到数十个数据输出,根据需要操纵数据. 通过插件,您可以马上更好地利用您的日志 *最低限度所需资源: 数据收集器应该是轻量级的,这样用户就可以在繁忙的机器上舒适地运行. Fluentd由C和Ruby组合而成,需要最少的系统资源. 香草实例运行在30-40MB的内存上,可以处理13 000个事件/秒/核心 *基本可靠性: 数据损失不应该发生。 Fluentd支持基于内存和基于文件的缓冲,以防止节点间数据丢失. 流利还支持强力故障,可以设置为高可用性
目标:使用 Fluentd 收集集中式 Docker 容器日志
随着Docker容器投入生产,需要越来越多地保持容器的日志比容器更少。
在本教程中,我们将向您展示如何安装Fluentd,并使用它来从Docker容器中收集日志,将其存储在外部,以便在容器停止后可以保存数据。
正如在 Kubernetes’s GitHub repo中所描述的那样,这种架构使用了Fluentd的能力来对每一个容器生产的Docker DAEMON的JSON-per-line日志文件进行复制。 对于最小的设置,请参阅(http://www.fluentd.org/guides/recipes/docker-logging)。
在本教程结束时,我们将讨论另外两个用例. 阅读本文后,您应该知道如何使用Fluentd的基本知识。
前提条件
请确保您完成本教程的这些前提条件。
- Ubuntu 14.04 Droplet * 使用者與 sudo access
第1步:安装Fluentd
最常见的部署方法是通过td-agent包。Treasure Data,Fluentd的原创作者,包装了Fluentd具有自己的Ruby运行时间,所以用户不需要设置自己的Ruby来运行Fluentd。
目前,td-agent支持以下平台:
- Ubuntu:清晰、准确和可靠 * Debian: Wheezy 和 Squeeze * RHEL/Centos: 5, 6 和 7 * Mac OSX: 10.9 及以上
在本教程中,我们假设您在DigitalOcean Droplet上运行Ubuntu 14.04 LTS(信任)。
使用以下命令安装td-agent:
1curl -L http://toolbelt.treasuredata.com/sh/install-ubuntu-trusty-td-agent2.sh | sh
开始TD代理:
1sudo /etc/init.d/td-agent start
检查日志以确保它已成功安装:
1tail /var/log/td-agent/td-agent.log
你应该看到类似于以下的输出:
1port 24230
2 </source>
3</ROOT>
42015-02-22 18:27:45 -0500 [info]: adding source type="forward"
52015-02-22 18:27:45 -0500 [info]: adding source type="http"
62015-02-22 18:27:45 -0500 [info]: adding source type="debug_agent"
72015-02-22 18:27:45 -0500 [info]: adding match pattern="td.*.*" type="tdlog"
82015-02-22 18:27:45 -0500 [info]: adding match pattern="debug.**" type="stdout"
92015-02-22 18:27:45 -0500 [info]: listening fluent socket on 0.0.0.0:24224
102015-02-22 18:27:45 -0500 [info]: listening dRuby uri="druby://127.0.0.1:24230" object="Engine"
另外,Fluentd 可用作 Ruby 宝石,并可与 gem install fluentd 一起安装。 如果您没有 sudo 特权,请在这里安装 Ruby(见 Installing Ruby并运行: > > > gem install fluentd --no-rdoc --no-ri >)
第2步:安装Docker
现在我们将安装Docker。本教程已在Docker v1.5.0中进行测试。
添加 Docker 存储库的密钥,以便我们可以获得最新的 Docker 包:
1sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9
将库存添加到您的来源:
1sudo sh -c "echo deb https://get.docker.com/ubuntu docker main > /etc/apt/sources.list.d/docker.list"
更新您的系统:
1sudo apt-get update
安装 Docker:
1sudo apt-get install lxc-docker
通过检查版本来验证 Docker 是否已安装:
1docker --version
你应该看到的输出如下:
1Docker version 1.5.0, build a8a31ef
步骤 3 — 将用户添加到 docker 组
Docker 运行为 root ,因此为了发出docker命令,请将 sudo 用户添加到** docker** 组中。
1sudo gpasswd -a sammy docker
然后重新启动 Docker。
1sudo service docker restart
最后,如果您目前作为 sudo 用户登录,则必须退出并重新登录。
步骤4 - 构建流畅的图像
在本节中,我们将为 Fluentd Docker 容器创建 Docker 图像。 如果您想了解更多关于 Docker 的信息,请阅读 此介绍性教程。
创建您的 Fluentd Docker 资源的新目录,并进入它:
1mkdir ~/fluentd-docker && cd ~/fluentd-docker
创建以下Dockerfile:
1sudo nano Dockerfile
这个文件告诉 Docker 更新 Docker 容器并安装 Ruby、Fluentd 和 Elasticsearch:
1FROM ruby:2.2.0
2MAINTAINER [email protected]
3RUN apt-get update
4RUN gem install fluentd -v "~>0.12.3"
5RUN mkdir /etc/fluent
6RUN apt-get install -y libcurl4-gnutls-dev make
7RUN /usr/local/bin/gem install fluent-plugin-elasticsearch
8ADD fluent.conf /etc/fluent/
9ENTRYPOINT ["/usr/local/bundle/bin/fluentd", "-c", "/etc/fluent/fluent.conf"]
您还需要在相同的目录中创建一个fluent.conf文件。
1sudo nano fluent.conf
該檔案的「fluent.conf」應該是這樣的,你可以完全複製這個檔案:
1<source>
2 type tail
3 read_from_head true
4 path /var/lib/docker/containers/*/*-json.log
5 pos_file /var/log/fluentd-docker.pos
6 time_format %Y-%m-%dT%H:%M:%S
7 tag docker.*
8 format json
9</source>
10# Using filter to add container IDs to each event
11<filter docker.var.lib.docker.containers.*.*.log>
12 type record_transformer
13 <record>
14 container_id ${tag_parts[5]}
15 </record>
16</filter>
17
18<match docker.var.lib.docker.containers.*.*.log>
19 type elasticsearch
20 logstash_format true
21 host "#{ENV['ES_PORT_9200_TCP_ADDR']}" # dynamically configured to use Docker's link feature
22 port 9200
23 flush_interval 5s
24</match>
此文件的目的是告诉 Fluentd 在哪里找到其他 Docker 容器的日志。
然后,构建你的Docker图像,名为fluentd-es:
1docker build -t fluentd-es .
這將需要幾分鐘才能完成. 檢查您是否成功建立了圖像:
1docker images
你应该看到这样的输出:
1REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
2fluentd-es latest 89ba1fb47b23 2 minutes ago 814.1 MB
3ruby 2.2.0 51473a2975de 6 weeks ago 774.9 MB
第5步:启动 Elasticsearch 容器
现在,回到您的 Elasticsearch 容器的首页目录或偏好目录:
1cd ~
下载并启动 Elasticsearch 容器. 为此已经有自动构建:
1docker run -d -p 9200:9200 -p 9300:9300 --name es dockerfile/elasticsearch
等待容器图像下载并启动。
接下来,通过检查 Docker 流程来确保 Elasticsearch 容器正常运行:
1docker ps
你应该看到这样的输出:
1CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2c474fd99ce43 dockerfile/elasticsearch:latest "/elasticsearch/bin/ 4 minutes ago Up 4 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp es
第6步:启动Fluentd-to-Elasticsearch容器
现在我们将启动运行 Fluentd 的容器,收集日志,并将其发送到 Elastcisearch。
1docker run -d --link es:es -v /var/lib/docker/containers:/var/lib/docker/containers fluentd-es
在上述命令中, --link es:es 部分将 Elasticsearch 容器链接到 Fluentd 容器. -v /var/lib/docker/containers:/var/lib/docker/containers 部分需要将主机容器的日志目录目录插入到 Fluentd 容器中,这样 Fluentd 就可以在创建容器时对日志文件进行尾声。
最后,通过检查我们的活跃的 Docker 流程来检查容器是否正在运行:
1docker ps
这一次,你应该看到Elasticsearch容器和新的fluentd-es容器:
1CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2f0d2cac81ac8 fluentd-es:latest "/usr/local/bundle/b 2 seconds ago Up 2 seconds stupefied_brattain
3c474fd99ce43 dockerfile/elasticsearch:latest "/elasticsearch/bin/ 6 minutes ago Up 6 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp es
步骤 7 – 确认 Elasticsearch 正在收到事件
最后,让我们确认Elasticsearch正在接收这些事件:
1curl -XGET 'http://localhost:9200/_all/_search?q=*'
输出应该包含看起来像这样的事件:
1{"took":66,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":0,"max_score":null,"hits":[]}}
2{"took":59,"timed_out":false,"_shards":{"tod","_id":"AUwLaKjcnpi39wqZnTXQ","_score":1.0,"_source":{"log":"2015-03-12 00:35:44 +0000 [info]: following tail of /var/lib/docker/containers/6abeb6ec0019b2198ed708315f4770fc7ec6cc44a10705ea59f05fae23b81ee9/6abeb6ec0019b2198ed708315f4770fc7ec6cc44a10705ea59f05fae23b81ee9-json.log\n","stream":"stdout","container_id":"6abeb6ec0019b2198ed708315f4770fc7ec6cc44a10705ea59f05fae23b81ee9","@timestamp":"2015-03-12T00:35:44+00:00"}}]}}
根据您的设置,您可能有相当多的事件登录,单一的事件应该从采取:`开始,并以时间标签结束。
正如这个输出显示的那样,Elasticsearch正在接收数据(您的容器ID将与上面显示的不同!)
步骤8 - 将事件日志带到下一个级别
现在您的集装箱事件正在 Elasticsearch 存储中,您接下来应该做什么?有许多有用的事情可以用 Elasticsearch 做。
- Basic Elasticsearch 操作 * 添加仪表板所以你可以可视化你的日志
结论
从 Docker 容器收集日志只是使用 Fluentd 的一种方法,在本节中,我们将介绍 Fluentd 的另外两种常见用例。
使用案例1:实时日志搜索和日志存档
许多用户来到Fluentd,构建一个日志管道,该管道既能实时搜索日志,又能长期存储。

在上述设置中,Elasticsearch用于实时搜索,而MongoDB和/或Hadoop用于批量分析和长期存储。
使用案例2:集中式应用程序日志
网页应用程序生成大量的日志,并且它们通常被任意格式化并存储在本地文件系统上。
- 日志很难编程分析(需要大量的常规表达式),因此对于那些希望通过统计分析(A / B 测试,欺诈检测等)了解用户行为的人来说并不容易访问 * 日志无法实时访问,因为文本日志大量加载到存储系统。
Fluentd 通过:
- 为各种编程语言提供一个一致的API的日志库:每个日志发送三倍(时刻印记,标签,JSON格式事件)到Fluentd. 目前,有日志库用于Ruby,Node.js,Go,Python,Perl,PHP,Java和C++ * 允许应用程序
点燃和忘记:日志可以同步登录到Fluentd,这反过来在上传到后端系统之前缓冲日志
资源:
- 閱讀關於 統一記錄層 * Fluentd + Elasticsearch for Kubernetes 由 Satnam Singh (Kubernetes 委員)