作者选择了 Girls Who 代码作为 写给捐款计划的一部分,以获得捐款。
介绍
[Reinforcement learning] (https://en.wikipedia.org/wiki/Reinforcement_learning)是控制理论内的一个子领域,它涉及随时间而变化的控制系统,并广泛包括自驾汽车,机器人等应用,以及游戏用bots等. 在整个指南中,你将使用强化学习为Atari电子游戏建造一个机器人. 此bot没有获得游戏的内部信息. 取而代之的是,它只能获得游戏制作的显示和对显示的奖励,这意味着它只能看到人类玩家所看到的.
在机器学习中,机器人正式被称为代理人。在本教程的情况下,代理人是系统中的玩家,该系统根据一个决策功能,称为 policy。
您将训练一个基本的强化学习代理, 在玩"太空入侵者"时采取随机动作, 经典的 Atari 街机游戏, 作为您进行比较的基准。 在此之后,你们将探索其他几种技术——包括Q-learning,Depen Q-learning,https://en.wikipedia.org/wiki/Q-learning# Deep_Q-learning,和[最东方 (https://en.wikipedia.org/wiki/Least_squares)——在建造代理玩"太空入侵者"和"冰冻湖"的同时,包括Gym,[OpenAI (https://openai.com/)发布的强化学习工具包等. 通过遵循这个教程,你将获得对指导一个人在机器学习中选择模型复杂性的基本概念的理解.
前提条件
要完成本教程,您将需要:
- 运行 Ubuntu 18.04 的服务器,至少具有 1 GB 的 RAM. 该服务器应该具有非根用户配置的
sudo特权,以及与 UFW 设置的防火墙. 您可以通过遵循此设置设置此 Ubuntu 18.04 初始服务器设置指南 * 通过阅读我们的指南如何在 Ubuntu 18.04 服务器上安装 Python 3 和设置编程环境(https://andsky.com/tech/tutorials/how-to-install-python-3-and-set-up-a-programming-environment-on-an-ubuntu-18-04-server)来实现的 Python 3 虚拟环境。
或者,如果您正在使用本地机器,您可以通过我们的 Python 安装和设置系列阅读适当的操作系统教程来安装 Python 3 并设置本地编程环境。
步骤 1 – 创建项目并安装依赖性
为了为您的机器人设置开发环境,您必须下载游戏本身和计算所需的库。
首先,为此项目创建一个名为AtariBot的工作空间:
1mkdir ~/AtariBot
导航到新的AtariBot目录:
1cd ~/AtariBot
然后为项目创建一个新的虚拟环境. 你可以将这个虚拟环境命名为任何你想要的;在这里,我们将命名它为ataribot:
1python3 -m venv ataribot
激活你的环境:
1source ataribot/bin/activate
在Ubuntu上,从版本 16.04 开始,OpenCV 需要安装一些更多的包才能运行,这些包包括CMake - 管理软件构建流程的应用程序 - 以及会话管理器,不同细胞的扩展和数字图像组成。
1sudo apt-get install -y cmake libsm6 libxext6 libxrender-dev libz-dev
<$>[注] 注: 如果您在运行 MacOS 的本地计算机上遵循此指南,您需要安装的唯一额外软件是 CMake。
1brew install cmake
美元
接下来,使用管道来安装轮子包,这是轮子包装标准的参考实现。 作为一个Python库,该包作为构建轮子的扩展,并包含一个命令行工具来处理 .whl文件:
1python -m pip install wheel
除了轮子,您还需要安装以下软件包:
- [Gym ] (https://gym.openai.com/),一个Python库,提供各种游戏可供研究,以及Atari游戏的所有依赖. 由OpenAI开发, Gym为每款游戏提供公开的基准,这样各种代理和算法的性能就可以被统一/评价.
- [Tensorflow ] (https://www.tensorflow.org/),一个深层学习图书馆. 这个库让我们能够更有效地运行计算. 具体地说,它通过建立数学函数来达到这个目的,它使用 Tensorflow 的抽象,这些抽象完全运行在您的GPU上.
- OpenCV ,前面提到的计算机视觉图书馆。
- SciPy ,一个提供高效优化算法的科学计算库.
- [NumPy ] (http://www.numpy.org/),一个线性代数库. .
请注意,此命令指示每个软件包的哪个版本要安装:
1python -m pip install gym==0.9.5 tensorflow==1.5.0 tensorpack==0.8.0 numpy==1.14.0 scipy==1.1.0 opencv-python==3.4.1.15
接下来,再一次使用pip来安装健身房的Atari环境,其中包括各种Atari视频游戏,包括太空入侵者:
1python -m pip install gym[atari]
如果您安装的gym[atari]包成功,您的输出将结束如下:
1[secondary_label Output]
2Installing collected packages: atari-py, Pillow, PyOpenGL
3Successfully installed Pillow-5.4.1 PyOpenGL-3.1.0 atari-py-0.1.7
有了这些依赖性安装,你准备好继续前进并构建一个随机演奏的代理,作为你的基线进行比较。
步骤2 — 创建基线随机代理与健身房
现在所需的软件已经在您的服务器上,您将设置一个代理,它将播放经典的Atari游戏Space Invaders的简化版本. 对于任何实验,您需要获得一个基线,以帮助您了解您的模型的性能。 因为这个代理在每个框架上采取随机行动,我们将它称为我们的随机,基线代理。 在这种情况下,您将与这个基线代理进行比较,以了解您的代理在以后的步骤中表现得有多好。
通过健身房,你保持自己的 game loop. 这意味着你处理游戏的执行的每个步骤:在每个时间步骤,你给健身房一个新的行动,并要求健身房的 _game状态。
使用您喜爱的文本编辑器,创建一个名为bot_2_random.py 的 Python 文件。
1nano bot_2_random.py
<$>[注] 注: 在本指南中,机器人的名称与它们出现的步骤号而不是它们出现的顺序一致,因此,这个机器人被命名为bot_2_random.py而不是bot_1_random.py。
这些行包括一个评论块,解释了这个脚本会做什么,以及两个导入陈述,将导入这个脚本最终需要的包,以便运作:
1[label /AtariBot/bot_2_random.py]
2"""
3Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
4"""
5
6import gym
7import random
在此函数中,创建游戏环境――SpaceInvaders-v0,然后使用env.reset开始游戏:
1[label /AtariBot/bot_2_random.py]
2. . .
3import gym
4import random
5
6def main():
7 env = gym.make('SpaceInvaders-v0')
8 env.reset()
接下来,添加一个 `sql.step' 函数. 此函数可以返回以下类型的值:
- `国家': 游戏的新状态,在应用了提供的动作后.
奖励': 州内得分的增加。 举例来说,这可能是当一发子弹已经摧毁了外星,得分增加50分的时候. 然后,奖励=50'。 在任何基于分数的游戏中,玩家的目标是将分数最大化. 这是最大程度的奖励的同义词。- `done': 剧集是否已经结束,通常发生在玩家已经失去所有生命的时候.
- `信息': 你暂时搁置的不相干的信息 .
您还将使用完成来确定玩家何时死亡,即当完成返回真实时。
添加以下游戏循环,指示游戏循环直到玩家死亡:
1[label /AtariBot/bot_2_random.py]
2. . .
3def main():
4 env = gym.make('SpaceInvaders-v0')
5 env.reset()
6
7 episode_reward = 0
8 while True:
9 action = env.action_space.sample()
10 _, reward, done, _ = env.step(action)
11 episode_reward += reward
12 if done:
13 print('Reward: %s' % episode_reward)
14 break
最后,运行主函数. 包括一个__name__检查,以确保主仅在直接使用python bot_2_random.py调用时运行。 如果您不添加如果检查,在执行Python文件时,主将始终触发,即使在导入文件时。
1[label /AtariBot/bot_2_random.py]
2. . .
3def main():
4 . . .
5 if done:
6 print('Reward %s' % episode_reward)
7 break
8
9if __name__ == '__main__':
10 main()
保存文件并退出编辑器. 如果您使用nano,请按CTRL+X,Y,然后按ENTER。
1python bot_2_random.py
您的程序将输出一个数字,类似于以下内容. 请注意,每次运行文件时,您将获得不同的结果:
1[secondary_label Output]
2Making new env: SpaceInvaders-v0
3Reward: 210.0
这些随机结果呈现一个问题. 为了产生其他研究人员和从业者可以受益的工作,你的结果和试验必须是可重复的。
1nano bot_2_random.py
在随机导入后,添加random.seed(0)。在env = gym.make('SpaceInvaders-v0')后,添加env.seed(0)。 这些行将以一致的起点播种环境,确保结果始终可重现。
1[label /AtariBot/bot_2_random.py]
2"""
3Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
4"""
5
6import gym
7import random
8random.seed(0)
9
10def main():
11 env = gym.make('SpaceInvaders-v0')
12 env.seed(0)
13
14 env.reset()
15 episode_reward = 0
16 while True:
17 action = env.action_space.sample()
18 _, reward, done, _ = env.step(action)
19 episode_reward += reward
20 if done:
21 print('Reward: %s' % episode_reward)
22 break
23
24if __name__ == '__main__':
25 main()
保存文件并关闭编辑器,然后运行脚本,在终端中键入以下内容:
1python bot_2_random.py
这将产生以下奖励,具体地说:
1[secondary_label Output]
2Making new env: SpaceInvaders-v0
3Reward: 555.0
这是你的第一个机器人,虽然它相当不聪明,因为它在做出决定时不考虑周围环境。为了更可靠的估计你的机器人的性能,你可以让代理同时运行多个集,报告在多个集中的平均奖励。
1nano bot_2_random.py
在 'random.seed(0)' 之后,添加以下突出的行,告诉代理人玩游戏 10 集:
1[label /AtariBot/bot_2_random.py]
2. . .
3random.seed(0)
4
5num_episodes = 10
6. . .
在env.seed(0)之后,开始一个新的奖励列表:
1[label /AtariBot/bot_2_random.py]
2. . .
3 env.seed(0)
4 rewards = []
5. . .
在一个for循环中从env.reset()到main()的尽头,重复num_episodes时间,请确保从env.reset()到break的每个行按四个间隙进行注入:
1[label /AtariBot/bot_2_random.py]
2. . .
3def main():
4 env = gym.make('SpaceInvaders-v0')
5 env.seed(0)
6 rewards = []
7
8 for _ in range(num_episodes):
9 env.reset()
10 episode_reward = 0
11
12 while True:
13 ...
在打破之前,目前是主要游戏循环的最后一行,将当前集中的奖励添加到所有奖励列表中:
1[label /AtariBot/bot_2_random.py]
2. . .
3 if done:
4 print('Reward: %s' % episode_reward)
5 rewards.append(episode_reward)
6 break
7. . .
在主要函数结束时,报告平均奖励:
1[label /AtariBot/bot_2_random.py]
2. . .
3def main():
4 ...
5 print('Reward: %s' % episode_reward)
6 break
7 print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
8 . . .
请注意下面的代码块包含一些评论来澄清脚本的关键部分:
1[label /AtariBot/bot_2_random.py]
2"""
3Bot 2 -- Make a random, baseline agent for the SpaceInvaders game.
4"""
5
6import gym
7import random
8random.seed(0) # make results reproducible
9
10num_episodes = 10
11
12def main():
13 env = gym.make('SpaceInvaders-v0') # create the game
14 env.seed(0) # make results reproducible
15 rewards = []
16
17 for _ in range(num_episodes):
18 env.reset()
19 episode_reward = 0
20 while True:
21 action = env.action_space.sample()
22 _, reward, done, _ = env.step(action) # random action
23 episode_reward += reward
24 if done:
25 print('Reward: %d' % episode_reward)
26 rewards.append(episode_reward)
27 break
28 print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
29
30if __name__ == '__main__':
31 main()
保存文件,离开编辑器,然后运行脚本:
1python bot_2_random.py
这将打印以下平均奖励,准确地说:
1[secondary_label Output]
2Making new env: SpaceInvaders-v0
3. . .
4Average reward: 163.50
然而,要创建一个优越的代理人,你需要了解增强学习的框架。
理解加强学习
在任何一场比赛中,玩家的目标是最大限度地提高他们的分数。在本指南中,玩家的分数被称为其奖励。为了最大限度地提高他们的奖励,玩家必须能够完善其决策能力。正式来说,一个决定是观察游戏的过程,或观察游戏的状态,并选择一个行动。我们的决策功能被称为 policy;一个政策接受一个状态作为输入并决定一个行动:
1policy: state -> action
要构建这样一个功能,我们将从一组特定的增强学习算法开始,称为Q学习算法。 为了说明这些,考虑一个游戏的初始状态,我们将称之为state0:你的太空船和外星人都在他们的起始位置。
| state | action | reward |
|---|---|---|
| state0 | shoot | 10 |
| state0 | right | 3 |
| state0 | left | 3 |
射击行动将最大限度地提高你的奖励,因为它会产生具有最高值的奖励:10正如你所看到的那样,Q表提供了基于观察到的状态做出决策的简单方法:
1policy: state -> look at Q-table, pick action with greatest reward
然而,大多数游戏中有太多的状态来列出在表中。在这种情况下,Q学习代理学习一个Q函数而不是一个Q表。我们使用这个Q函数类似于我们以前使用Q表的方式。
1Q(state0, shoot) = 10
2Q(state0, right) = 3
3Q(state0, left) = 3
鉴于一个特定的状态,我们很容易做出决定:我们只是看每一个可能的行动及其回报,然后采取与预期最高的回报相匹配的行动。
1policy: state -> argmax_{action} Q(state, action)
这满足了决策函数的要求:在游戏中的某个状态下,它决定了一项行动,但是,这个解决方案取决于知道Q(状态,行动)的每个状态和行动。
考虑到一个特工的状态,行动和奖励的许多观察,可以通过采取运行平均值来估计每个状态和行动的奖励。2.Space Invaders是一个有延迟奖励的游戏:玩家在外星人被吹爆时得到奖励,而不是当球员拍摄时得到奖励。
这两个见解是编码在以下方程式:
1Q(state, action) = (1 - learning_rate) * Q(state, action) + learning_rate * Q_target
2Q_target = reward + discount_factor * max_{action'} Q(state', action')
这些方程式使用以下定义:
*状态:当前时间步骤中的状态 *行动:当前时间步骤中所采取的行动 *奖励:当前时间步骤的奖励 *状态:下一次步骤的新状态,鉴于我们采取了行动a *行动:所有可能的行动 *学习率:学习率 *折扣因子:折扣因子,当我们传播时奖励降级多少
對於這兩種方程式的完整解釋,請參閱本文 理解Q-Learning。
考虑到这种对强化学习的理解,剩下的只是实际运行游戏并获得新的策略的这些Q值估计。
第3步:为冷冻湖创建一个简单的Q学习代理
现在你有一个基线代理人,你可以开始创建新的代理人,并将其与原始代理人进行比较. 在此步骤中,你将创建一个使用 Q-learning的代理人,这是一种加强学习技术,用于教给代理人采取什么样的行动。
翻译: 冬来已来. 你和你的朋友在公园里扔了只飞盘 在湖中抛出一只飞盘 水多为冰冻,但有几孔已融出冰来. 如果你走进其中一个洞里 你会掉入冰冻的水中 此时,国际飞盘短缺,因此绝对需要你横穿湖面取回盘子. 然而,冰是滑的, 所以你不会总是朝着你打算的方向去.
表面用如下网格描述:
1SFFF (S: starting point, safe)
2FHFH (F: frozen surface, safe)
3FFFH (H: hole, fall to your doom)
4HFFG (G: goal, where the frisbee is located)
玩家从左上方开始,标记为S,并向右下方的目标走路,标记为G。可用的行动是右,左 ,上** 和下** ,达到目标结果为1分。
在本节中,你将实施一个简单的Q学习代理。 使用你以前学到的东西,你将创建一个代理,在 exploration 和 exploitation 之间进行交易。 在这种情况下,探索意味着代理人以随机的方式行动,并利用其Q值来选择它认为是最佳的行动。
从步骤 2 创建你的脚本副本:
1cp bot_2_random.py bot_3_q_table.py
然后打开这个新文件进行编辑:
1nano bot_3_q_table.py
首先,更新描述脚本的目的的文件顶部的评论,因为这只是一个评论,所以这个更改对于脚本的正常运作是不必要的,但它可以有助于跟踪脚本所做的事情:
1[label /AtariBot/bot_3_q_table.py]
2"""
3Bot 3 -- Build simple q-learning agent for FrozenLake
4"""
5
6. . .
在您对脚本进行功能性修改之前,您需要为其线性算法实用程序导入numpy。
1[label /AtariBot/bot_3_q_table.py]
2"""
3Bot 3 -- Build simple q-learning agent for FrozenLake
4"""
5
6import gym
7import numpy as np
8import random
9random.seed(0) # make results reproducible
10. . .
在random.seed(0)下方,为numpy添加一个种子:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3import random
4random.seed(0) # make results reproducible
5np.random.seed(0)
6. . .
接下来,使游戏状态可访问. 更新env.reset()行,说下列,该行将游戏的初始状态存储在变量状态中:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 for _ in range(num_episodes):
4 state = env.reset()
5 . . .
更新env.step(...)行,说下列,存储下一个状态,state2。你需要当前的state和下一个state2来更新Q函数。
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 while True:
4 action = env.action_space.sample()
5 state2, reward, done, _ = env.step(action)
6 . . .
在 'episode_reward += reward' 之后,添加更新变量'state' 的行. 这将使变量'state' 更新为下一次迭代,因为您将期待'state' 反映当前状态:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 while True:
4 . . .
5 episode_reward += reward
6 state = state2
7 if done:
8 . . .
在如果完成块中,删除打印声明,该声明打印每集的奖励。
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 if done:
4 rewards.append(episode_reward)
5 break
6 . . .
经过这些修改后,您的游戏循环将匹配如下:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 for _ in range(num_episodes):
4 state = env.reset()
5 episode_reward = 0
6 while True:
7 action = env.action_space.sample()
8 state2, reward, done, _ = env.step(action)
9 episode_reward += reward
10 state = state2
11 if done:
12 rewards.append(episode_reward))
13 break
14 . . .
接下来,添加代理人在探索和挖掘之间进行交易的能力。在您的主要游戏循环(以for...开始)之前,创建 Q 值表:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 Q = np.zeros((env.observation_space.n, env.action_space.n))
4 for _ in range(num_episodes):
5 . . .
然后,重写for循环来曝光剧情号码:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 Q = np.zeros((env.observation_space.n, env.action_space.n))
4 for episode in range(1, num_episodes + 1):
5 . . .
在内部游戏循环中,创建噪音。噪音或无意义的随机数据,有时在训练深度神经网络时被引入,因为它可以提高模型的性能和准确性。请注意,噪音越高,在Q中的值就越少。
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 while True:
4 noise = np.random.random((1, env.action_space.n)) / (episode**2.)
5 action = env.action_space.sample()
6 . . .
請注意,隨著「節目」的增加,噪音的數量下降了四分之一:隨著時間的推移,代理人探索越來越少,因為他可以信任自己的評估遊戲的獎勵,並開始利用他的知識。
更新行动行以根据Q值表进行代理选择操作,其中包含一些内置的探索:
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 noise = np.random.random((1, env.action_space.n)) / (episode**2.)
4 action = np.argmax(Q[state, :] + noise)
5 state2, reward, done, _ = env.step(action)
6 . . .
您的主要游戏循环将匹配如下:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 Q = np.zeros((env.observation_space.n, env.action_space.n))
4 for episode in range(1, num_episodes + 1):
5 state = env.reset()
6 episode_reward = 0
7 while True:
8 noise = np.random.random((1, env.action_space.n)) / (episode**2.)
9 action = np.argmax(Q[state, :] + noise)
10 state2, reward, done, _ = env.step(action)
11 episode_reward += reward
12 state = state2
13 if done:
14 rewards.append(episode_reward)
15 break
16 . . .
接下来,您将使用 Bellman 更新方程式更新 Q 值表,该方程式在机器学习中广泛使用,以在特定环境中找到最佳策略。
贝尔曼方程包含了两个与这个项目高度相關的想法. 首先,从某个国家多次采取某项行动,将对该状态和行动相关的Q值作出良好的估计。 为此,您会增加此机器人必须播放的相片次数,以便返回更强的Q值估计. 第二,奖励必须经过时间传播,以便给予最初的行动非零奖励。 这种想法在延迟奖励的游戏中最为明显;例如在"太空入侵者"(Space Invaders)中,玩家被炸出外星后而不是玩家射击时会得到奖励. 然而,玩家射击是奖励的真正动力. 同样,Q职能必须给予(State0',shot')积极奖励.
首先,更新 num_episodes 到等于 4000:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3np.random.seed(0)
4
5num_episodes = 4000
6. . .
然后,将必要的超参数添加到文件的顶部,以另外两个变量的形式:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3num_episodes = 4000
4discount_factor = 0.8
5learning_rate = 0.9
6. . .
计算新的目标Q值,即包含‘env.step(...)’的行后:
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 state2, reward, done, _ = env.step(action)
4 Qtarget = reward + discount_factor * np.max(Q[state2, :])
5 episode_reward += reward
6 . . .
在Qtarget之后的行上,使用旧和新Q值的加权平均值来更新Q值表:
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 Qtarget = reward + discount_factor * np.max(Q[state2, :])
4 Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
5 episode_reward += reward
6 . . .
检查您的主要游戏循环是否与以下相匹配:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3 Q = np.zeros((env.observation_space.n, env.action_space.n))
4 for episode in range(1, num_episodes + 1):
5 state = env.reset()
6 episode_reward = 0
7 while True:
8 noise = np.random.random((1, env.action_space.n)) / (episode**2.)
9 action = np.argmax(Q[state, :] + noise)
10 state2, reward, done, _ = env.step(action)
11 Qtarget = reward + discount_factor * np.max(Q[state2, :])
12 Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
13 episode_reward += reward
14 state = state2
15 if done:
16 rewards.append(episode_reward)
17 break
18 . . .
我们培训代理人的逻辑现在已经完成了,剩下的只是添加报告机制。
虽然Python不强制严格的类型检查,但你可以将类型添加到你的函数声明中以确保清洁度。在文件的顶部,在第一个读取进口健身房前,请导入列表类型:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3from typing import List
4import gym
5. . .
在learning_rate = 0.9之后,在主要函数之外,声明报告的间隔和格式:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3learning_rate = 0.9
4report_interval = 500
5report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
6 '(Episode %d)'
7
8def main():
9 . . .
在主要函数之前,添加一个新函数,使用所有奖励列表来填充此报告字符串:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
4 '(Episode %d)'
5
6def print_report(rewards: List, episode: int):
7 """Print rewards report for current episode
8 - Average for last 100 episodes
9 - Best 100-episode average across all time
10 - Average for all episodes across time
11 """
12 print(report % (
13 np.mean(rewards[-100:]),
14 max([np.mean(rewards[i:i+100]) for i in range(len(rewards) - 100)]),
15 np.mean(rewards),
16 episode))
17
18def main():
19 . . .
将游戏更改为FrozenLake而不是SpaceInvaders:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3def main():
4 env = gym.make('FrozenLake-v0') # create the game
5 . . .
在「rewards.append(...)」之後,打印過去100集的平均獎金,並打印所有節目的平均獎金:
1[label /AtariBot/bot_3_q_table.py]
2 . . .
3 if done:
4 rewards.append(episode_reward)
5 if episode % report_interval == 0:
6 print_report(rewards, episode)
7 . . .
在 main() 函数的末尾,再报告两个平均值一次. 这样做是通过用以下突出的行更换读 `print('Average reward: %.2f' % (sum(rewards) / len(rewards)))' 的行:
1[label /AtariBot/bot_3_q_table.py]
2. . .
3def main():
4 ...
5 break
6 print_report(rewards, -1)
7. . .
最后,你已经完成了Q学习代理,检查你的脚本是否符合以下内容:
1[label /AtariBot/bot_3_q_table.py]
2"""
3Bot 3 -- Build simple q-learning agent for FrozenLake
4"""
5
6from typing import List
7import gym
8import numpy as np
9import random
10random.seed(0) # make results reproducible
11np.random.seed(0) # make results reproducible
12
13num_episodes = 4000
14discount_factor = 0.8
15learning_rate = 0.9
16report_interval = 500
17report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
18 '(Episode %d)'
19
20def print_report(rewards: List, episode: int):
21 """Print rewards report for current episode
22 - Average for last 100 episodes
23 - Best 100-episode average across all time
24 - Average for all episodes across time
25 """
26 print(report % (
27 np.mean(rewards[-100:]),
28 max([np.mean(rewards[i:i+100]) for i in range(len(rewards) - 100)]),
29 np.mean(rewards),
30 episode))
31
32def main():
33 env = gym.make('FrozenLake-v0') # create the game
34 env.seed(0) # make results reproducible
35 rewards = []
36
37 Q = np.zeros((env.observation_space.n, env.action_space.n))
38 for episode in range(1, num_episodes + 1):
39 state = env.reset()
40 episode_reward = 0
41 while True:
42 noise = np.random.random((1, env.action_space.n)) / (episode**2.)
43 action = np.argmax(Q[state, :] + noise)
44 state2, reward, done, _ = env.step(action)
45 Qtarget = reward + discount_factor * np.max(Q[state2, :])
46 Q[state, action] = (1-learning_rate) * Q[state, action] + learning_rate * Qtarget
47 episode_reward += reward
48 state = state2
49 if done:
50 rewards.append(episode_reward)
51 if episode % report_interval == 0:
52 print_report(rewards, episode)
53 break
54 print_report(rewards, -1)
55
56if __name__ == '__main__':
57 main()
保存文件,离开编辑器,然后运行脚本:
1python bot_3_q_table.py
您的输出将匹配如下:
1[secondary_label Output]
2100-ep Average: 0.11 . Best 100-ep Average: 0.12 . Average: 0.03 (Episode 500)
3100-ep Average: 0.25 . Best 100-ep Average: 0.24 . Average: 0.09 (Episode 1000)
4100-ep Average: 0.39 . Best 100-ep Average: 0.48 . Average: 0.19 (Episode 1500)
5100-ep Average: 0.43 . Best 100-ep Average: 0.55 . Average: 0.25 (Episode 2000)
6100-ep Average: 0.44 . Best 100-ep Average: 0.55 . Average: 0.29 (Episode 2500)
7100-ep Average: 0.64 . Best 100-ep Average: 0.68 . Average: 0.32 (Episode 3000)
8100-ep Average: 0.63 . Best 100-ep Average: 0.71 . Average: 0.36 (Episode 3500)
9100-ep Average: 0.56 . Best 100-ep Average: 0.78 . Average: 0.40 (Episode 4000)
10100-ep Average: 0.56 . Best 100-ep Average: 0.78 . Average: 0.40 (Episode -1)
现在你有你的第一个非平凡的游戏机器人,但让我们把这个平均奖励的0.78放在视野中。 根据Gym FrozenLake页面(https://gym.openai.com/envs/FrozenLake-v0/),`解决游戏意味着达到100集平均值的0.78。 非正式的,解决意味着玩游戏非常好`。
然而,游戏可能更为复杂. 在这里,你用一个表格来存储所有144个可能的状态, 但考虑ttic tac脚趾, 其中有19,683个可能的状态。 同样,考虑空间入侵者,那里可能存在太多的州。 随着游戏日益复杂,Q表是不可持续的。 为此,您需要某种方式来大致显示Q表. 在下一步继续试验时,您将设计一个功能,可以接受状态和行动作为输入,输出出Q值.
步骤4:为冷冻湖构建深度Q学习代理
在增强学习中,神经网络有效地根据状态和行动输入预测Q的值,使用表格来存储所有可能的值,但这在复杂的游戏中变得不稳定。
要习惯于 Tensorflow,您在步骤 1 中安装的深度学习库,您将重新实现迄今为止使用的所有逻辑与Tensorflow的抽象,您将使用神经网络来接近您的Q功能。
1Q(s) = Ws
再次重申,我们的目标是使用Tensorflow的抽象来重新实现我们已经构建的机器人的所有逻辑,这将使您的操作更有效率,因为Tensorflow可以在GPU上执行所有计算。
从步骤 3 开始复制您的 Q 表脚本:
1cp bot_3_q_table.py bot_4_q_network.py
然后使用nano或您喜爱的文本编辑器打开新文件:
1nano bot_4_q_network.py
首先,更新文件顶部的评论:
1[label /AtariBot/bot_4_q_network.py]
2"""
3Bot 4 -- Use Q-learning network to train bot
4"""
5
6. . .
接下来,通过在随机导入右下方添加一个导入指令来导入Tensorflow包。 此外,在np.random.seed(0)右下方添加tf.set_radon_seed(0)。
1[label /AtariBot/bot_4_q_network.py]
2. . .
3import random
4import tensorflow as tf
5random.seed(0)
6np.random.seed(0)
7tf.set_random_seed(0)
8. . .
重新定义文件顶部的超参数以匹配下列内容,并添加一个名为exploration_probability的函数,该函数将在每个步骤中返回探索的概率。
1[label /AtariBot/bot_4_q_network.py]
2. . .
3num_episodes = 4000
4discount_factor = 0.99
5learning_rate = 0.15
6report_interval = 500
7exploration_probability = lambda episode: 50. / (episode + 10)
8report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
9 '(Episode %d)'
10. . .
接下来,你会添加一个 one-hot encoding 函数. 简而言之,一个热编码是将变量转换成一种形式的过程,这有助于机器学习算法做出更好的预测。
直接在 report =... 下方,添加一个 one_hot 函数:
1[label /AtariBot/bot_4_q_network.py]
2. . .
3report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
4 '(Episode %d)'
5
6def one_hot(i: int, n: int) -> np.array:
7 """Implements one-hot encoding by selecting the ith standard basis vector"""
8 return np.identity(n)[i].reshape((1, -1))
9
10def print_report(rewards: List, episode: int):
11. . .
接下来,您将使用 Tensorflow 的抽象来重写算法逻辑,但在此之前,您需要先为您的数据创建 _placeholders。
在您的主要函数中,直接在奖励=[]下方,插入以下突出内容. 在这里,您为您的观测定义了时间 t (作为obs_t_ph)和时间 ** t+1** (作为obs_tp1_ph)的位置,以及您的行动,奖励和Q目标的位置:
1[label /AtariBot/bot_4_q_network.py]
2. . .
3def main():
4 env = gym.make('FrozenLake-v0') # create the game
5 env.seed(0) # make results reproducible
6 rewards = []
7
8 # 1. Setup placeholders
9 n_obs, n_actions = env.observation_space.n, env.action_space.n
10 obs_t_ph = tf.placeholder(shape=[1, n_obs], dtype=tf.float32)
11 obs_tp1_ph = tf.placeholder(shape=[1, n_obs], dtype=tf.float32)
12 act_ph = tf.placeholder(tf.int32, shape=())
13 rew_ph = tf.placeholder(shape=(), dtype=tf.float32)
14 q_target_ph = tf.placeholder(shape=[1, n_actions], dtype=tf.float32)
15
16 Q = np.zeros((env.observation_space.n, env.action_space.n))
17 for episode in range(1, num_episodes + 1):
18 . . .
直接在以 q_target_ph = 开头的行下面,插入以下突出的行. 此代码通过计算 Q(s, a) 对所有 ** a** 进行计算,以使 q_current 和 ** Q(s', a')** 对所有 ** a'** 进行计算,以使 q_target:
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 rew_ph = tf.placeholder(shape=(), dtype=tf.float32)
4 q_target_ph = tf.placeholder(shape=[1, n_actions], dtype=tf.float32)
5
6 # 2. Setup computation graph
7 W = tf.Variable(tf.random_uniform([n_obs, n_actions], 0, 0.01))
8 q_current = tf.matmul(obs_t_ph, W)
9 q_target = tf.matmul(obs_tp1_ph, W)
10
11 Q = np.zeros((env.observation_space.n, env.action_space.n))
12 for episode in range(1, num_episodes + 1):
13 . . .
再次,直接在你添加的最后一行下方,插入以下高亮代码。前两行等同于在步骤3中添加的行,该行计算Qtarget,其中Qtarget = reward + discount_factor * np.max(Q[state2, :])。
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 q_current = tf.matmul(obs_t_ph, W)
4 q_target = tf.matmul(obs_tp1_ph, W)
5
6 q_target_max = tf.reduce_max(q_target_ph, axis=1)
7 q_target_sa = rew_ph + discount_factor * q_target_max
8 q_current_sa = q_current[0, act_ph]
9 error = tf.reduce_sum(tf.square(q_target_sa - q_current_sa))
10 pred_act_ph = tf.argmax(q_current, 1)
11
12 Q = np.zeros((env.observation_space.n, env.action_space.n))
13 for episode in range(1, num_episodes + 1):
14 . . .
设置算法和损失函数后,定义您的优化程序:
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 error = tf.reduce_sum(tf.square(q_target_sa - q_current_sa))
4 pred_act_ph = tf.argmax(q_current, 1)
5
6 # 3. Setup optimization
7 trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
8 update_model = trainer.minimize(error)
9
10 Q = np.zeros((env.observation_space.n, env.action_space.n))
11 for episode in range(1, num_episodes + 1):
12 . . .
接下来,设置游戏循环的身体. 要做到这一点,将数据传递给Tensorflow的位置持有人,Tensorflow的抽象将处理GPU上的计算,返回算法的结果。
首先,删除旧Q表和逻辑,具体来说,删除定义Q的行(在for循环前),噪音(在while循环中),action、Qtarget和Q[state, action)的行。将state重命名为obs_t和state2重命名为obs_tp1,以与您先前设置的Tensorflow位置保持器一致。
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 # 3. Setup optimization
4 trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
5 update_model = trainer.minimize(error)
6
7 for episode in range(1, num_episodes + 1):
8 obs_t = env.reset()
9 episode_reward = 0
10 while True:
11
12 obs_tp1, reward, done, _ = env.step(action)
13
14 episode_reward += reward
15 obs_t = obs_tp1
16 if done:
17 ...
直接在for循环上方,添加以下两条突出线条,这些线条启动一个Tensorflow会话,从而管理在GPU上运行操作所需的资源。第二行启动计算图中的所有变量;例如,在更新它们之前,将重量启动为0。
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 trainer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
4 update_model = trainer.minimize(error)
5
6 with tf.Session() as session:
7 session.run(tf.global_variables_initializer())
8
9 for episode in range(1, num_episodes + 1):
10 obs_t = env.reset()
11 ...
在读取obs_tp1, reward, done, _ = env.step(action)的行前,插入以下行来计算action。
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 while True:
4 # 4. Take step using best action or random action
5 obs_t_oh = one_hot(obs_t, n_obs)
6 action = session.run(pred_act_ph, feed_dict={obs_t_ph: obs_t_oh})[0]
7 if np.random.rand(1) < exploration_probability(episode):
8 action = env.action_space.sample()
9 . . .
在包含 env.step(action) 的行后,插入以下内容来训练神经网络来估计您的 Q 值函数:
1[label /AtariBot/bot_4_q_network.py]
2 . . .
3 obs_tp1, reward, done, _ = env.step(action)
4
5 # 5. Train model
6 obs_tp1_oh = one_hot(obs_tp1, n_obs)
7 q_target_val = session.run(q_target, feed_dict={obs_tp1_ph: obs_tp1_oh})
8 session.run(update_model, feed_dict={
9 obs_t_ph: obs_t_oh,
10 rew_ph: reward,
11 q_target_ph: q_target_val,
12 act_ph: action
13 })
14 episode_reward += reward
15 . . .
你的最终文件将匹配 这个文件托管在GitHub。
1python bot_4_q_network.py
您的输出将结束如下,准确地说:
1[secondary_label Output]
2100-ep Average: 0.11 . Best 100-ep Average: 0.11 . Average: 0.05 (Episode 500)
3100-ep Average: 0.41 . Best 100-ep Average: 0.54 . Average: 0.19 (Episode 1000)
4100-ep Average: 0.56 . Best 100-ep Average: 0.73 . Average: 0.31 (Episode 1500)
5100-ep Average: 0.57 . Best 100-ep Average: 0.73 . Average: 0.36 (Episode 2000)
6100-ep Average: 0.65 . Best 100-ep Average: 0.73 . Average: 0.41 (Episode 2500)
7100-ep Average: 0.65 . Best 100-ep Average: 0.73 . Average: 0.43 (Episode 3000)
8100-ep Average: 0.69 . Best 100-ep Average: 0.73 . Average: 0.46 (Episode 3500)
9100-ep Average: 0.77 . Best 100-ep Average: 0.79 . Average: 0.48 (Episode 4000)
10100-ep Average: 0.77 . Best 100-ep Average: 0.79 . Average: 0.48 (Episode -1)
现在你已经训练了你的第一个深度Q学习代理人。对于像FrozenLake那样简单的游戏,你的深度Q学习代理人需要4000个集来训练。想象一下,如果游戏更为复杂,那么训练需要多少个训练样本?据了解,代理人可能需要数百万个样本。所需的样本数被称为 sample complexity,这个概念在下一节进一步探索。
理解偏差变量交易
一般来说,样本复杂性与机器学习中的模型复杂性相矛盾:
- 模型复杂性 :一个人想要一个足够复杂的模型来解决他们的问题.例如,一个模型像一条线一样简单,并不足够复杂,可以预测一辆汽车的轨道。
假设我们有两个模型,一个简单,一个极其复杂。 两种模型要达到相同的性能,偏差变异告诉我们,极其复杂的模型需要成倍地多的样本来训练. 例:您基于神经网络的Q学习代理需要4000集才能解冻Lake. 在神经网络代理中加入第二层,使必要的培训次数翻了四番. 随着神经网络日益复杂,这一鸿沟只会扩大. 为了保持同样的出错率,不断提高的模型复杂度使样本的复杂度指数地增加. 同样地,样本复杂性的降低降低了模型复杂性. 因此,我们不能使模型的复杂性最大化,也不能将样本的复杂性最小化到我们内心的欲望.
然而,我们可以利用我们对这种取舍的了解。 关于_bias-variance分解_背后的数学的视觉解释,参见[了解bias-variance difference (http://alvinwan.com/understanding-the-bias-variance-tradeoff). 在高水平上,偏差-变量分解是将"真错误"分解为两个组成部分:偏差和相差. 我们把"真实错误"称为_mean平方错误_(MSE),这是我们预测的标签和真实标签之间的预期差异. 以下为显示模型复杂度增加后"真错误"变化的图:
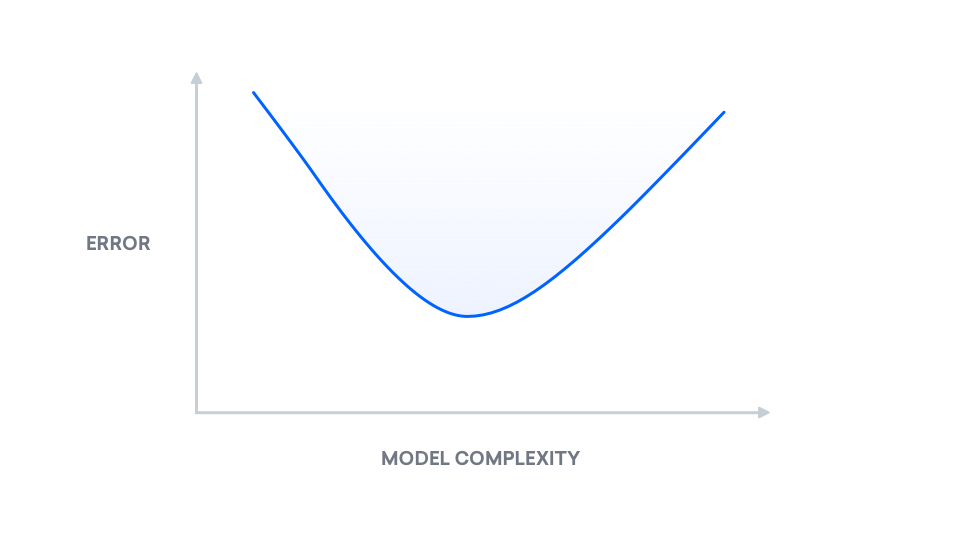
步骤5 - 构建冰冻湖的最少平方代理
least squares 方法,也称为 linear regression,是数学和数据科学领域广泛使用的回归分析手段,在机器学习中,它通常用于找到两个参数或数据集的最佳线性模型。
在步骤4中,你建立了一个神经网络来计算Q值,而不是神经网络,在这个步骤中,你将使用 ridge regression,一个最小的平方的变体,来计算这个Q值的矢量。
从步骤 3 开始复制脚本:
1cp bot_3_q_table.py bot_5_ls.py
打开新文件:
1nano bot_5_ls.py
再次,更新文件顶部的评论,描述这个脚本将做什么:
1[label /AtariBot/bot_4_q_network.py]
2"""
3Bot 5 -- Build least squares q-learning agent for FrozenLake
4"""
5
6. . .
在文件顶部附近的导入块之前,请为类型检查添加两个导入:
1[label /AtariBot/bot_5_ls.py]
2. . .
3from typing import Tuple
4from typing import Callable
5from typing import List
6import gym
7. . .
在您的超级参数列表中,添加另一个超级参数,即w_lr,以控制第二个 Q 函数的学习率。 此外,更新集数到 5000 和折扣因子到 0.85。
1[label /AtariBot/bot_5_ls.py]
2. . .
3num_episodes = 5000
4discount_factor = 0.85
5learning_rate = 0.9
6w_lr = 0.5
7report_interval = 500
8. . .
在print_report函数之前,添加以下更高序列的函数. 它返回一个lambda - 一个匿名函数 - 抽象模型:
1[label /AtariBot/bot_5_ls.py]
2. . .
3report_interval = 500
4report = '100-ep Average: %.2f . Best 100-ep Average: %.2f . Average: %.2f ' \
5 '(Episode %d)'
6
7def makeQ(model: np.array) -> Callable[[np.array], np.array]:
8 """Returns a Q-function, which takes state -> distribution over actions"""
9 return lambda X: X.dot(model)
10
11def print_report(rewards: List, episode: int):
12 . . .
在makeQ之后,添加另一个函数初始化,该函数使用正常分布的值来初始化模型:
1[label /AtariBot/bot_5_ls.py]
2. . .
3def makeQ(model: np.array) -> Callable[[np.array], np.array]:
4 """Returns a Q-function, which takes state -> distribution over actions"""
5 return lambda X: X.dot(model)
6
7def initialize(shape: Tuple):
8 """Initialize model"""
9 W = np.random.normal(0.0, 0.1, shape)
10 Q = makeQ(W)
11 return W, Q
12
13def print_report(rewards: List, episode: int):
14 . . .
在初始化块后,添加一个列车方法,该方法计算了边缘回归的封闭式解决方案,然后将旧模型与新模型重量。
1[label /AtariBot/bot_5_ls.py]
2. . .
3def initialize(shape: Tuple):
4 ...
5 return W, Q
6
7def train(X: np.array, y: np.array, W: np.array) -> Tuple[np.array, Callable]:
8 """Train the model, using solution to ridge regression"""
9 I = np.eye(X.shape[1])
10 newW = np.linalg.inv(X.T.dot(X) + 10e-4 * I).dot(X.T.dot(y))
11 W = w_lr * newW + (1 - w_lr) * W
12 Q = makeQ(W)
13 return W, Q
14
15def print_report(rewards: List, episode: int):
16 . . .
在列车之后,添加一个最后的函数,即one_hot,以执行您的状态和操作的单热编码:
1[label /AtariBot/bot_5_ls.py]
2. . .
3def train(X: np.array, y: np.array, W: np.array) -> Tuple[np.array, Callable]:
4 ...
5 return W, Q
6
7def one_hot(i: int, n: int) -> np.array:
8 """Implements one-hot encoding by selecting the ith standard basis vector"""
9 return np.identity(n)[i]
10
11def print_report(rewards: List, episode: int):
12 . . .
随后,您将需要修改训练逻辑. 在您所写的前一个脚本中,Q表被更新每一次迭代. 然而,此脚本将每次步骤收集样本和标签,并每10步训练一个新模型。
转到主要函数,并将Q表的定义(Q = np.zeros(...))更换为以下:
1[label /AtariBot/bot_5_ls.py]
2. . .
3def main():
4 ...
5 rewards = []
6
7 n_obs, n_actions = env.observation_space.n, env.action_space.n
8 W, Q = initialize((n_obs, n_actions))
9 states, labels = [], []
10 for episode in range(1, num_episodes + 1):
11 . . .
直接在此下方,添加下列行,如果存储过多的信息,将状态和标签列表重置:
1[label /AtariBot/bot_5_ls.py]
2. . .
3def main():
4 ...
5 for episode in range(1, num_episodes + 1):
6 if len(states) >= 10000:
7 states, labels = [], []
8 . . .
修改此行后直接的行,定义state = env.reset(),以便它成为下列。
1[label /AtariBot/bot_5_ls.py]
2. . .
3 for episode in range(1, num_episodes + 1):
4 if len(states) >= 10000:
5 states, labels = [], []
6 state = one_hot(env.reset(), n_obs)
7. . .
在你的同时主游戏循环中的第一行之前,更改状态列表:
1[label /AtariBot/bot_5_ls.py]
2. . .
3 for episode in range(1, num_episodes + 1):
4 ...
5 episode_reward = 0
6 while True:
7 states.append(state)
8 noise = np.random.random((1, env.action_space.n)) / (episode**2.)
9 . . .
更新「行動」的計算,減少噪音的概率,並修改 Q 函數的評估:
1[label /AtariBot/bot_5_ls.py]
2. . .
3 while True:
4 states.append(state)
5 noise = np.random.random((1, n_actions)) / episode
6 action = np.argmax(Q(state) + noise)
7 state2, reward, done, _ = env.step(action)
8 . . .
添加一个state2的单热版本,并如下修改Qtarget定义中的Q函数调用:
1[label /AtariBot/bot_5_ls.py]
2. . .
3 while True:
4 ...
5 state2, reward, done, _ = env.step(action)
6
7 state2 = one_hot(state2, n_obs)
8 Qtarget = reward + discount_factor * np.max(Q(state2))
9 . . .
刪除更新「Q[state,action] =...」的行,並用下列行取代它. 此代碼採取現行模型的輸出,並只更新該輸出中與所採取的現行動作相符的值。
1[label /AtariBot/bot_5_ls.py]
2. . .
3 state2 = one_hot(state2, n_obs)
4 Qtarget = reward + discount_factor * np.max(Q(state2))
5 label = Q(state)
6 label[action] = (1 - learning_rate) * label[action] + learning_rate * Qtarget
7 labels.append(label)
8
9 episode_reward += reward
10 . . .
在「state = state2」之后,向模型添加定期更新,每10个步骤训练您的模型:
1[label /AtariBot/bot_5_ls.py]
2. . .
3 state = state2
4 if len(states) % 10 == 0:
5 W, Q = train(np.array(states), np.array(labels), W)
6 if done:
7 . . .
重复检查您的文件是否匹配 源代码。然后,保存文件,离开编辑器,并运行脚本:
1python bot_5_ls.py
这将产生如下:
1[secondary_label Output]
2100-ep Average: 0.17 . Best 100-ep Average: 0.17 . Average: 0.09 (Episode 500)
3100-ep Average: 0.11 . Best 100-ep Average: 0.24 . Average: 0.10 (Episode 1000)
4100-ep Average: 0.08 . Best 100-ep Average: 0.24 . Average: 0.10 (Episode 1500)
5100-ep Average: 0.24 . Best 100-ep Average: 0.25 . Average: 0.11 (Episode 2000)
6100-ep Average: 0.32 . Best 100-ep Average: 0.31 . Average: 0.14 (Episode 2500)
7100-ep Average: 0.35 . Best 100-ep Average: 0.38 . Average: 0.16 (Episode 3000)
8100-ep Average: 0.59 . Best 100-ep Average: 0.62 . Average: 0.22 (Episode 3500)
9100-ep Average: 0.66 . Best 100-ep Average: 0.66 . Average: 0.26 (Episode 4000)
10100-ep Average: 0.60 . Best 100-ep Average: 0.72 . Average: 0.30 (Episode 4500)
11100-ep Average: 0.75 . Best 100-ep Average: 0.82 . Average: 0.34 (Episode 5000)
12100-ep Average: 0.75 . Best 100-ep Average: 0.82 . Average: 0.34 (Episode -1)
回顾,根据[Gym FrozenLake page] (https://gym.openai.com/envs/FrozenLake-v0/),"解"游戏意味着实现百集平均0.78. 在这里,代理机平均跳出0.82分,意味着它能在5000集中解出游戏. 虽然这并不能在更少的剧集中解决游戏,但这种最基本的最不平方方法仍然能够以大致相同的训练剧集数量解决简单的游戏. 虽然你的神经网络可能越来越复杂,但你已经表明简单的模型足以为"冰冻湖"服务.
有了这个,你已经探索了三个Q学习代理:一个使用Q表,另一个使用神经网络,第三个使用最少的方块。
第6步:为太空入侵者创建一个深度Q学习代理
假设你调整了以前的Q学习算法的模型复杂性和样本复杂性完美,无论你是否选择了神经网络或最少的方块方法. 正如你所看到的那样,这个不聪明的Q学习代理仍然在更复杂的游戏中表现不佳,即使有特别高的训练季节。
DeepMind的研究人员开发了第一个能够在没有任何人类干预的情况下不断调整其行为的通用代理,他们还训练了他们的代理来玩各种阿塔里游戏。
- 联合国 ** 与珊瑚有关的国家** : 以我们游戏的状态 0, 我们将叫** s0** 。 说我们更新QQ(s0)** ,按照我们之前得出的规则. 现在,在第一时间采取状态,我们称之为** s1** ,并按照同样的规则更新QQ(s1)** . 注意游戏时间0的状态与其时间状态非常相近 1. 联合国 例如在"太空入侵者"(Space Invaders)中,外星人可能各移动了一像素. 简言之,** s0** 和** s1** 非常相似。 同样,我们也期望+(s0)** 和+(s1)** 非常相似,因此更新一个影响另一个。 这导致Q值波动,因为更新到QQ(s0)** 实际上可能与更新到QQ(s1)** 相对应。 更正式地说,** s0** 和** s1** 为_cor相通_. 由于Q功能是决定性的,所以Q(s1)** 与Q(s0)** 相关。
- 联合国 功能不稳定**: 记得,QQ功能既是我们训练的模式,也是我们标签的来源. 说我们的标签是随机选择的,真正代表了_分配_,** L** . 每当我们更新QQ,我们改变** L** ,意味着我们的模型正在尝试学习移动的目标. 这是一个问题,因为我们使用的模型 假设一个固定的分布。 .
对抗相关状态和不稳定Q功能:
- 联合国 可以保留一个叫做"回放缓冲"的状态列表. 每一步,您都会将您观察到的游戏状态添加到这个回放缓冲器中. 您还随机抽取了列表中的一部分状态, 并对这些状态进行培训。
- 联合国 DepMind的团队重复了QQ(s, a). 一个叫做 QQ- current( s, a) ** , 这是您更新的 Q- 函数 。 您需要为继任国家再设置一个Q功能, QQ目标( s', a') ** , 您不会更新 。 回想起QQ目标(s), a') 用于生成您的标签 。 通过将 QQ current ** 从 QQ 目标 ** 中分离出来并修正 后者,您可以固定您的标签从中样本的分布 。 那么,你的深层学习模式 可以花一小段时间学习这种分布。 一段时间后,您将重复 QQ current ** 用于一个新的 QQ 目标 ** 。 .
您不会自己实现这些,但您将加载使用这些解决方案训练的预训练模型. 要做到这一点,创建一个新的目录,存储这些模型的参数:
1mkdir models
然后使用wget下载预训练的太空入侵者模型的参数:
1wget http://models.tensorpack.com/OpenAIGym/SpaceInvaders-v0.tfmodel -P models
接下来,下载一个 Python 脚本,指定与您刚刚下载的参数相关的模型。
- 状态必须下样,或大小减少,到84 x 84. * 输入由四个状态组成,堆积。
我们将在稍后更详细地解决这些限制,暂时通过键入下载脚本:
1wget https://github.com/alvinwan/bots-for-atari-games/raw/master/src/bot_6_a3c.py
现在你将运行这个预训练的 Space Invaders 代理,看看它是如何运作的. 与我们过去使用的几个机器人不同,你将从头开始写下这个脚本。
创建一个新的脚本文件:
1nano bot_6_dqn.py
开始这个脚本,添加一个标题评论,导入必要的实用程序,并开始主游戏循环:
1[label /AtariBot/bot_6_dqn.py]
2"""
3Bot 6 - Fully featured deep q-learning network.
4"""
5
6import cv2
7import gym
8import numpy as np
9import random
10import tensorflow as tf
11from bot_6_a3c import a3c_model
12
13def main():
14
15if __name__ == '__main__':
16 main()
直接在导入后,设置随机种子以使您的结果可重复。 此外,定义一个超参数 num_episodes,该参数会告诉脚本要运行多少集的代理:
1[label /AtariBot/bot_6_dqn.py]
2. . .
3import tensorflow as tf
4from bot_6_a3c import a3c_model
5random.seed(0) # make results reproducible
6tf.set_random_seed(0)
7
8num_episodes = 10
9
10def main():
11 . . .
在声明num_episodes后,定义一个下示例函数,将所有图像降示到84 x 84的尺寸。
1[label /AtariBot/bot_6_dqn.py]
2. . .
3num_episodes = 10
4
5def downsample(state):
6 return cv2.resize(state, (84, 84), interpolation=cv2.INTER_LINEAR)[None]
7
8def main():
9 . . .
在你的主要功能开始时创建游戏环境,并播种环境,使结果可重现:
1[label /AtariBot/bot_6_dqn.py]
2. . .
3def main():
4 env = gym.make('SpaceInvaders-v0') # create the game
5 env.seed(0) # make results reproducible
6 . . .
直接在环境种子后,初始化一个空列表,以保持奖励:
1[label /AtariBot/bot_6_dqn.py]
2. . .
3def main():
4 env = gym.make('SpaceInvaders-v0') # create the game
5 env.seed(0) # make results reproducible
6 rewards = []
7 . . .
初始化预训练模型与您在本步骤开始时下载的预训练模型参数:
1[label /AtariBot/bot_6_dqn.py]
2. . .
3def main():
4 env = gym.make('SpaceInvaders-v0') # create the game
5 env.seed(0) # make results reproducible
6 rewards = []
7 model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
8 . . .
接下来,添加一些行,告诉脚本要重复num_episodes 次数来计算平均性能,并将每集的奖励初始化为 0. 此外,添加一行来重置环境(env.reset()),收集进程中的新的初始状态,用 downsample()下示此初始状态,并使用一个 while 循环开始游戏循环:
1[label /AtariBot/bot_6_dqn.py]
2. . .
3def main():
4 env = gym.make('SpaceInvaders-v0') # create the game
5 env.seed(0) # make results reproducible
6 rewards = []
7 model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
8 for _ in range(num_episodes):
9 episode_reward = 0
10 states = [downsample(env.reset())]
11 while True:
12 . . .
因此,你必须等到状态列表至少包含四个状态,然后在应用预训练模型之前。 将下列行列添加到虽然是真的:字段下方,这些行列告诉代理人采取随机行动,如果有不到四个状态,或者将这些状态连接起来,并将其传递到预训练模型中,如果至少有四个状态:
1[label /AtariBot/bot_6_dqn.py]
2 . . .
3 while True:
4 if len(states) < 4:
5 action = env.action_space.sample()
6 else:
7 frames = np.concatenate(states[-4:], axis=3)
8 action = np.argmax(model([frames]))
9 . . .
然后采取行动并更新相关数据. 添加观察状态的下样版本,并更新此集的奖励:
1[label /AtariBot/bot_6_dqn.py]
2 . . .
3 while True:
4 ...
5 action = np.argmax(model([frames]))
6 state, reward, done, _ = env.step(action)
7 states.append(downsample(state))
8 episode_reward += reward
9 . . .
接下来,添加以下行,检查集是否完成,如果是,打印集会的总奖励,并更改所有结果列表,并提前打破同时循环:
1[label /AtariBot/bot_6_dqn.py]
2 . . .
3 while True:
4 ...
5 episode_reward += reward
6 if done:
7 print('Reward: %d' % episode_reward)
8 rewards.append(episode_reward)
9 break
10 . . .
在而和为环节之外,打印平均奖励,放到主要函数的末尾:
1[label /AtariBot/bot_6_dqn.py]
2def main():
3 ...
4 break
5 print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
检查您的文件是否符合以下内容:
1[label /AtariBot/bot_6_dqn.py]
2"""
3Bot 6 - Fully featured deep q-learning network.
4"""
5
6import cv2
7import gym
8import numpy as np
9import random
10import tensorflow as tf
11from bot_6_a3c import a3c_model
12random.seed(0) # make results reproducible
13tf.set_random_seed(0)
14
15num_episodes = 10
16
17def downsample(state):
18 return cv2.resize(state, (84, 84), interpolation=cv2.INTER_LINEAR)[None]
19
20def main():
21 env = gym.make('SpaceInvaders-v0') # create the game
22 env.seed(0) # make results reproducible
23 rewards = []
24
25 model = a3c_model(load='models/SpaceInvaders-v0.tfmodel')
26 for _ in range(num_episodes):
27 episode_reward = 0
28 states = [downsample(env.reset())]
29 while True:
30 if len(states) < 4:
31 action = env.action_space.sample()
32 else:
33 frames = np.concatenate(states[-4:], axis=3)
34 action = np.argmax(model([frames]))
35 state, reward, done, _ = env.step(action)
36 states.append(downsample(state))
37 episode_reward += reward
38 if done:
39 print('Reward: %d' % episode_reward)
40 rewards.append(episode_reward)
41 break
42 print('Average reward: %.2f' % (sum(rewards) / len(rewards)))
43
44if __name__ == '__main__':
45 main()
保存文件并退出编辑器,然后运行脚本:
1python bot_6_dqn.py
您的输出将以如下结尾:
1[secondary_label Output]
2. . .
3Reward: 1230
4Reward: 4510
5Reward: 1860
6Reward: 2555
7Reward: 515
8Reward: 1830
9Reward: 4100
10Reward: 4350
11Reward: 1705
12Reward: 4905
13Average reward: 2756.00
与第一个剧本的结果相比,你为"太空入侵者"运行了一个随机代理. 该案的平均奖励只有150分左右,这意味着这一结果要好20多倍。 然而,你只运行了三集代码,因为它相当缓慢,平均三集不是一个可靠的衡量标准. 运行这10多集,平均为2756集;超过100集,平均约为2500集. 只有这些平均值,你才能令人欣慰地断定 你的经纪人确实表现得更好, 而且你现在有一个经纪人 扮演 太空入侵者相当不错.
然而,回顾上一节就样本复杂性提出的问题。 事实证明,这个太空入侵者特工需要数百万样本来训练. 事实上,这个特工需要24小时在4个Titan X GPU上训练,才能达到目前的水平;换句话说,需要大量计算才能充分训练. 你能培养出一个 性能类似的高的毒剂 样本少得多吗? 以前的步骤应该使你有足够的知识来开始探讨这个问题。 使用更简单的模型和每个偏差-变异的取舍,可能是可能的.
结论
在本教程中,你为游戏构建了几个机器人,并探索了机器学习中的一个基本概念,称为偏差变化。一个自然的下一个问题是:你能否为更复杂的游戏构建机器人,如StarCraft 2? 正如它所示,这是一个正在进行的研究问题,由谷歌,DeepMind和Blizzard的合作者补充开源工具。
该教程的主要成果是偏差变异的交易,机器学习专业人员必须考虑模型复杂性的影响,而在计算,样本和时间过量的数量上,可以利用高度复杂的模型和层,而减少模型复杂性可以大大减少所需的资源。