作者选择了(https://www.brightfunds.org/funds/open-internet-free-speech)作为 Write for Donations计划的一部分的捐款。
介绍
Kubernetes允许用户使用单个命令创建灵活且可扩展的服务,就像任何听起来过于好看的内容一样,它都有一个问题:你必须先准备一个合适的 Docker图像,并仔细测试它。
Continuous Integration (CI)是对每个更新进行应用程序测试的做法. 手动进行此操作是无聊和容易出现错误的,但一个 CI 平台为您运行测试,提前捕捉错误,并找到错误的位置。 发布和部署程序往往复杂,耗时,需要可靠的构建环境。
为了自动化整个过程,您将使用 Semaphore,一个持续集成和交付(CI / CD)平台。
在本教程中,您将使用 Node.js构建一个地址簿 API 服务。 API 揭示了一个简单的 RESTful API接口,以创建、删除和在数据库中找到人员。您将使用 Git将代码推到 GitHub。
前提条件
在阅读之前,请确保您有以下内容:
按照 创建个人访问标记设置一个帐户。
- Docker Hub帐户。 GitHub帐户。
- Semaphore帐户;你可以使用你的GitHub帐户登录。
- 一个名为
addressbook的新的GitHub存储库为项目。 创建存储库时,请选择 Initialize this repository with a README checkbox 并选择 ** Node** 在 ** Add.Gitignore ** 菜单中。 Follow GitHub’s Create a Repo帮助页面详细信息。
步骤 1 – 创建数据库和Kubernetes集群
首先,提供将支持应用程序的服务:DigitalOcean数据库集群和DigitalOcean Kubernetes集群。
登录您的DigitalOcean帐户并创建一个项目(https://www.digitalocean.com/docs/projects/how-to/create/)。一个项目允许您组织构成应用程序的所有资源。
接下来,创建一个 PostgreSQL群集. PostgreSQL 数据库服务将保留应用程序的数据. 您可以选择可用的最新版本。
一旦 PostgreSQL 服务准备好了, 创建数据库和用户。 将数据库名称设置为 addessbook_db,并将用户名设置为 addressbook_user. 请注意为新用户生成的密码。 数据库是 PostgreSQL 组织数据的方式。 通常,每个应用程序都有自己的数据库,尽管对此没有严格的规则。 应用程序将使用用户名和密码访问数据库,以便保存和检索数据。
最后,创建一个 Kubernetes集群,选择运行数据库的区域,将集群命名为地址簿服务器,并将节点数设置为3。
虽然节点正在提供,您可以开始构建您的应用程序。
步骤2 - 编写申请
让我们构建您要部署的地址簿应用程序。 首先,在前提条件下克隆您创建的GitHub存储库,以便您有GitHub为您创建的‘.gitignore’文件的本地副本,并且您将能够快速委托您的应用程序代码,而无需手动创建存储库。 打开您的浏览器并前往您的新的GitHub存储库。 点击 克隆或下载 按钮并复制所提供的URL。 使用Git将空存储库克隆到您的机器:
1git clone https://github.com/your_github_username/addressbook
进入项目目录:
1cd addressbook
您将构建两个组件:一个与数据库互动的模块和一个提供HTTP服务的模块.数据库模块将知道如何从地址簿数据库中保存和检索人员,HTTP模块将接收请求并相应地响应。
虽然不是强制性的,但在你写代码时测试你的代码是很好的做法,所以你还会创建一个测试模块。
database.js:数据库模块. 它处理数据库操作.app.js:终端用户模块和主要应用程序. 它为用户提供HTTP服务连接到。
此外,您还需要一个 package.json文件为您的项目,其中描述了该项目及其所需的依赖性。您可以使用编辑器手动创建它,或者使用npm进行交互式创建它。
1npm init
该命令将要求一些信息来启动。如示例中所示,请填写值。如果您看不到列出的答案,请将答案留在空中,该答案使用插座中的默认值:
1[secondary_label npm output]
2package name: (addressbook) addressbook
3version: (1.0.0) 1.0.0
4description: Addressbook API and database
5entry point: (index.js) app.js
6test command:
7git repository: URL for your GitHub repository
8keywords:
9author: Sammy the Shark <sammy@example.com>"
10license: (ISC)
11About to write to package.json:
12
13{
14 "name": "addressbook",
15 "version": "1.0.0",
16 "description": "Addressbook API and database",
17 "main": "app.js",
18 "scripts": {
19 "test": "echo \"Error: no test specified\" && exit 1"
20 },
21 "author": "",
22 "license": "ISC"
23}
24
25Is this OK? (yes) yes
现在你可以开始编写代码. 数据库是你正在开发的服务的核心。 在编写任何其他组件之前,必须有一个精心设计的数据库模型。
您不必编码应用程序的所有位; Node.js 具有可重复使用的模块的大型库. 例如,如果您在项目中有 Sequelize ORM 模块,您不必写任何 SQL 查询。 该模块提供了处理数据库作为 JavaScript 对象和方法的界面。 它也可以在您的数据库中创建表。
使用npm install命令安装模块,使用--save选项,该选项告诉npm将模块保存到package.json。
1npm install --save sequelize pg
创建一个新的JavaScript文件以保留数据库代码:
1nano database.js
通过将此行添加到文件中导入sequelize模块:
1[label database.js]
2const Sequelize = require('sequelize');
3
4. . .
然后,在该行下方,用数据库连接参数初始化一个sequelize对象,您将从系统环境中获取该参数。这将使您的代码中的凭据保留在您的代码中,所以当您将代码推到GitHub时,您不会意外共享凭据。
1[label database.js]
2. . .
3
4const sequelize = new Sequelize(process.env.DB_SCHEMA || 'postgres',
5 process.env.DB_USER || 'postgres',
6 process.env.DB_PASSWORD || '',
7 {
8 host: process.env.DB_HOST || 'localhost',
9 port: process.env.DB_PORT || 5432,
10 dialect: 'postgres',
11 dialectOptions: {
12 ssl: process.env.DB_SSL == "true"
13 }
14 });
15
16. . .
现在定义人模型. 为了防止示例变得过于复杂,您只会创建两个字段:firstName和lastName,这两个字段都存储字符串值。
1[label database.js]
2. . .
3
4const Person = sequelize.define('Person', {
5 firstName: {
6 type: Sequelize.STRING,
7 allowNull: false
8 },
9 lastName: {
10 type: Sequelize.STRING,
11 allowNull: true
12 },
13});
14
15. . .
这定义了这两个字段,使firstName成为强制性的allowNull: false。
最后,导出序列对象和人模型,以便其他模块可以使用它们:
1[label database.js]
2. . .
3
4module.exports = {
5 sequelize: sequelize,
6 Person: Person
7};
在开发过程中可以随时调用的单独文件中有创建表的脚本很方便,这些类型的文件称为 migrations。
1nano migrate.js
将这些行添加到文件中,以导入您定义的数据库模型,然后调用sync()函数来初始化数据库,从而为您的模型创建表:
1[label migrate.js]
2var db = require('./database.js');
3db.sequelize.sync();
应用程序正在寻找系统环境变量中的数据库连接信息,创建一个名为 .env 的文件,以保持这些值,您将在开发过程中加载到环境中:
1nano .env
确保您将DB_HOST,DB_PORT和DB_PASSWORD设置为与您的DigitalOcean PostgreSQL集群相关的:
1[label .env]
2export DB_SCHEMA=addressbook_db
3export DB_USER=addressbook_user
4export DB_PASSWORD=your_db_user_password
5export DB_HOST=your_db_cluster_host
6export DB_PORT=your_db_cluster_port
7export DB_SSL=true
8export PORT=3000
保存檔案
<$>[警告] 警告 :永远不要检查环境文件进入源控制。
由于您在创建存储库时定义了默认 .gitignore 文件,因此该文件已经被忽略了。
您已准备好初始化数据库. 导入环境文件并运行 migrate.js:
1source ./.env
2node migrate.js
创建数据库表:
1[secondary_label Output]
2
3Executing (default): CREATE TABLE IF NOT EXISTS "People" ("id" SERIAL , "firstName" VARCHAR(255) NOT NULL, "lastName" VARCHAR(255), "createdAt" TIMESTAMP WITH TIME ZONE NOT NULL, "updatedAt" TIMESTAMP WITH TIME ZONE NOT NULL, PRIMARY KEY ("id"));
4Executing (default): SELECT i.relname AS name, ix.indisprimary AS primary, ix.indisunique AS unique, ix.indkey AS indkey, array_agg(a.attnum) as column_indexes, array_agg(a.attname) AS column_names, pg_get_indexdef(ix.indexrelid) AS definition FROM pg_class t, pg_class i, pg_index ix, pg_attribute a WHERE t.oid = ix.indrelid AND i.oid = ix.indexrelid AND a.attrelid = t.oid AND t.relkind = 'r' and t.relname = 'People' GROUP BY i.relname, ix.indexrelid, ix.indisprimary, ix.indisunique, ix.indkey ORDER BY i.relname;
输出显示了两个命令.第一个命令创建了按您的定义的人表.第二个命令通过在PostgreSQL目录中查看它来检查表是否确实被创建了。
通过测试,您可以验证代码的行为. 您可以为每个函数,方法或系统的任何其他部分写一个检查,并验证它以您预期的方式工作,而无需手动测试事物。
jest测试框架非常适合写对 Node.js 应用程序的测试。 Jest 扫描项目中的文件以检验文件,并一次执行它们。安装 Jest 使用 --save-dev 选项,该选项告诉 `npm' 模块不需要运行该程序,但它是开发应用程序的依赖:
1npm install --save-dev jest
这些测试将验证您的数据库连接和权限是否正确配置,并将提供一些测试,您可以在以后的 CI/CD 管道中使用。
创建database.test.js文件:
1nano database.test.js
添加以下内容. 通过导入数据库代码开始:
1[label database.test.js]
2const db = require('./database');
3
4. . .
要确保数据库已准备好使用,请在beforeAll函数中调用sync():
1[label database.test.js]
2. . .
3
4beforeAll(async () => {
5 await db.sequelize.sync();
6});
7
8. . .
第一次测试会创建数据库中的个人记录。sequelize库对所有查询进行非同步执行,这意味着它不会等待查询的结果。 要让测试等待结果,以便您可以验证结果,您必须使用async和Wait关键字。 这个测试会调用create()方法在数据库中插入新行。 使用expect将person.id列与1进行比较。 如果您获得了不同的值,测试将失败:
1[label database.test.js]
2. . .
3
4test('create person', async () => {
5 expect.assertions(1);
6 const person = await db.Person.create({
7 id: 1,
8 firstName: 'Sammy',
9 lastName: 'Davis Jr.',
10 email: '[email protected]'
11 });
12 expect(person.id).toEqual(1);
13});
14
15. . .
在下一个测试中,使用findByPk()方法获取id=1的行,然后验证firstName和lastName值。
1[label database.test.js]
2. . .
3
4test('get person', async () => {
5 expect.assertions(2);
6 const person = await db.Person.findByPk(1);
7 expect(person.firstName).toEqual('Sammy');
8 expect(person.lastName).toEqual('Davis Jr.');
9});
10
11. . .
最后,测试从数据库中删除某人. destroy() 方法删除具有 id=1 的某人. 要确保它工作,请尝试第二次检索该人并检查返回的值是否为 null:
1[label database.test.js]
2. . .
3
4test('delete person', async () => {
5 expect.assertions(1);
6 await db.Person.destroy({
7 where: {
8 id: 1
9 }
10 });
11 const person = await db.Person.findByPk(1);
12 expect(person).toBeNull();
13});
14
15. . .
最后,添加此代码以在所有测试完成后关闭连接到数据库的 close():
1[label app.js]
2. . .
3
4afterAll(async () => {
5 await db.sequelize.close();
6});
保存檔案
命令jest为您的程序运行测试套件,但您也可以将命令存储在package.json。
1nano package.json
查找脚本的关键字,并取代现有的测试行(这只是一个站点)。
1. . .
2
3 "scripts": {
4 "test": "jest"
5 },
6
7. . .
现在您可以调用npm run test来调用测试套件,这可能是一个更长的命令,但如果您需要更改jest命令后,外部服务将不需要改变;它们可以继续调用npm run test。
运行测试:
1npm run test
然后检查结果:
1[secondary_label Output]
2 console.log node_modules/sequelize/lib/sequelize.js:1176
3 Executing (default): CREATE TABLE IF NOT EXISTS "People" ("id" SERIAL , "firstName" VARCHAR(255) NOT NULL, "lastName" VARCHAR(255), "createdAt" TIMESTAMP WITH TIME ZONE NOT NULL, "updatedAt" TIMESTAMP WITH TIME ZONE NOT NULL, PRIMARY KEY ("id"));
4
5 console.log node_modules/sequelize/lib/sequelize.js:1176
6 Executing (default): SELECT i.relname AS name, ix.indisprimary AS primary, ix.indisunique AS unique, ix.indkey AS indkey, array_agg(a.attnum) as column_indexes, array_agg(a.attname) AS column_names, pg_get_indexdef(ix.indexrelid) AS definition FROM pg_class t, pg_class i, pg_index ix, pg_attribute a WHERE t.oid = ix.indrelid AND i.oid = ix.indexrelid AND a.attrelid = t.oid AND t.relkind = 'r' and t.relname = 'People' GROUP BY i.relname, ix.indexrelid, ix.indisprimary, ix.indisunique, ix.indkey ORDER BY i.relname;
7
8 console.log node_modules/sequelize/lib/sequelize.js:1176
9 Executing (default): INSERT INTO "People" ("id","firstName","lastName","createdAt","updatedAt") VALUES ($1,$2,$3,$4,$5) RETURNING *;
10
11 console.log node_modules/sequelize/lib/sequelize.js:1176
12 Executing (default): SELECT "id", "firstName", "lastName", "createdAt", "updatedAt" FROM "People" AS "Person" WHERE "Person"."id" = 1;
13
14 console.log node_modules/sequelize/lib/sequelize.js:1176
15 Executing (default): DELETE FROM "People" WHERE "id" = 1
16
17 console.log node_modules/sequelize/lib/sequelize.js:1176
18 Executing (default): SELECT "id", "firstName", "lastName", "createdAt", "updatedAt" FROM "People" AS "Person" WHERE "Person"."id" = 1;
19
20 PASS ./database.test.js
21 ✓ create person (344ms)
22 ✓ get person (173ms)
23 ✓ delete person (323ms)
24
25Test Suites: 1 passed, 1 total
26Tests: 3 passed, 3 total
27Snapshots: 0 total
28Time: 5.315s
29Ran all test suites.
通过测试数据库代码,您可以构建 API 服务来管理地址簿中的人员。
要服务 HTTP 请求,您将使用 Express Web Framework. 安装 Express 并使用 'npm install' 将其保存为依赖性:
1npm install --save express
您还需要 body-parser模块,您将使用它来访问 HTTP 请求体。
1npm install --save body-parser
创建主应用程序文件 app.js:
1nano app.js
导入express、body-parser和database模块,然后创建一个名为app的express模块的实例,以控制和配置该服务。您使用app.use()添加中间件等功能。 使用此功能添加body-parser模块,使应用程序可以读取 url-coded字符串:
1[label app.js]
2var express = require('express');
3var bodyParser = require('body-parser');
4var db = require('./database');
5var app = express();
6app.use(bodyParser.urlencoded({ extended: true }));
7
8. . .
接下来,将路径添加到应用程序中。路径类似于应用程序或网站中的按钮;它们会触发应用程序中的某些操作。路径将独特的 URL 链接到应用程序中的操作。
您定义的第一个路径将处理 /person/$ID 路径的 GET 请求,该路径将显示具有指定的 ID 的个人数据库记录。
应用程序必须用作为 JSON 字符串编码的个人数据来回复,正如您在数据库测试中所做的那样,请使用 findByPk() 方法以 id 获取该人并以 HTTP 状态回答请求,然后将该人的记录发送为 JSON. 添加以下代码:
1[label app.js]
2. . .
3
4app.get("/person/:id", function(req, res) {
5 db.Person.findByPk(req.params.id)
6 .then( person => {
7 res.status(200).send(JSON.stringify(person));
8 })
9 .catch( err => {
10 res.status(500).send(JSON.stringify(err));
11 });
12});
13
14. . .
错误会导致catch()中的代码被执行,例如,如果数据库处于停机状态,连接将失败,而这将执行。
添加另一个路径来创建数据库中的某人. 该路径将处理PUT请求,并从req.body获取该人的数据。
1[label app.js]
2. . .
3
4app.put("/person", function(req, res) {
5 db.Person.create({
6 firstName: req.body.firstName,
7 lastName: req.body.lastName,
8 id: req.body.id
9 })
10 .then( person => {
11 res.status(200).send(JSON.stringify(person));
12 })
13 .catch( err => {
14 res.status(500).send(JSON.stringify(err));
15 });
16});
17
18. . .
添加另一个路径来处理DELETE请求,这将从地址簿中删除记录。
1[label app.js]
2. . .
3
4app.delete("/person/:id", function(req, res) {
5 db.Person.destroy({
6 where: {
7 id: req.params.id
8 }
9 })
10 .then( () => {
11 res.status(200).send();
12 })
13 .catch( err => {
14 res.status(500).send(JSON.stringify(err));
15 });
16});
17
18. . .
为了方便,添加一条路径,使用/all路径检索数据库中的所有人:
1[label app.js]
2. . .
3
4app.get("/all", function(req, res) {
5 db.Person.findAll()
6 .then( persons => {
7 res.status(200).send(JSON.stringify(persons));
8 })
9 .catch( err => {
10 res.status(500).send(JSON.stringify(err));
11 });
12});
13
14. . .
如果请求不匹配任何之前的路径,请发送状态代码 404(未找到):
1[label app.js]
2. . .
3
4app.use(function(req, res) {
5 res.status(404).send("404 - Not Found");
6});
7
8. . .
如果环境变量PORT被定义,则该服务在该端口中倾听;否则,它默认为端口3000:
1[label app.js]
2. . .
3
4var server = app.listen(process.env.PORT || 3000, function() {
5 console.log("app is running on port", server.address().port);
6});
正如你所了解的,package.json文件允许你定义各种命令来运行测试,启动应用程序和其他任务,这通常允许你运行常见命令,输入少得多。
1nano package.json
添加开始命令,以便它看起来像这样:
1[label package.json]
2. . .
3
4 "scripts": {
5 "test": "jest",
6 "start": "node app.js"
7 },
8
9. . .
不要忘记在上一行中添加一个字符串,因为脚本部分需要它的条目分开的字符串。
保存文件并首次启动应用程序. 首先,将环境文件加载到源;这将变量导入到会话中,并使它们可供应用程序使用。
1source ./.env
2npm run start
应用程序在3000端口启动:
1[secondary_label Output]
2app is running on port 3000
打开一个浏览器并导航到 http://localhost:3000/all. 你会看到一个页面显示 []。
回到您的终端,然后按CTRL-C来停止应用程序。
现在是添加代码质量测试的好时机。代码质量工具,也称为 linters,扫描项目在代码中的问题。不良编码做法,如不使用变量,不用半色符号结束陈述,或缺少弯曲的轴承,可能会导致很难找到的错误。
安装 jshint工具,作为开发依赖的 JavaScript 启动器:
1npm install --save-dev jshint
多年来,JavaScript已经收到更新、功能和语法变化,该语言由ECMA International(http://ecma-international.org)以ECMAScript的名义进行标准化。
默认情况下,jshint 假设您的代码与 ES6 (ECMAScript 版本 6) 兼容,如果它找到任何在该版本中不受支持的关键字,则会出现错误。您将想要找到与您的代码兼容的版本。 如果您查看所有最近版本的 功能表,则您会发现直到 ES8 之前没有引入async/await的关键字。
要告诉你正在使用的版本jshint,创建一个名为.jshintrc的文件:
1nano .jshintrc
在文件中,指定esversion。jshintrc文件使用JSON,因此在文件中创建一个新的JSON对象:
1[label .jshintrc]
2{ "esversion": 8 }
保存文件并离开编辑器。
添加一个命令来运行jshint。
1nano package.json
在package.json的脚本部分中添加一个lint命令到您的项目,该命令会对您迄今为止创建的所有JavaScript文件调用lint工具:
1[label package.json]
2. . .
3
4 "scripts": {
5 "test": "jest",
6 "start": "node app.js",
7 "lint": "jshint app.js database*.js migrate.js"
8 },
9
10. . .
现在你可以运行灯泡来找到任何问题:
1npm run lint
不应出现任何错误信息:
1[secondary_label Output]
2> jshint app.js database*.js migrate.js
如果有任何错误,jshint将显示有问题的行。
您已完成该项目并确保它工作. 将文件添加到存储库中,委托,并推动更改:
1git add *.js
2git add package*.json
3git add .jshintrc
4git commit -m 'initial commit'
5git push origin master
现在,您可以配置 Semaphore 来测试,构建和部署应用程序,从配置 Semaphore 开始,使用您的 DigitalOcean 个人访问令牌和数据库凭证。
步骤 3 – 在 Semaphore 中创建秘密
有某些信息不属于GitHub存储库。密码和API代币是好例子,您将这些敏感数据存储在一个单独的文件中,并将其加载到您的环境中,当您使用Semaphore时,您可以使用秘密来存储敏感数据。
项目中有三种类型的秘密:
- Docker Hub:您的 Docker Hub 帐户的用户名和密码。
- DigitalOcean Personal Access Token: 用于部署应用程序到您的 Kubernetes 集群。
要创建第一个秘密,请打开您的浏览器并登录到 Semaphore网站。在左侧的导航菜单中,点击 秘密 在 ** CONFIGURATION** 标题下。
在秘密名称中,输入dockerhub,然后在环境变量下,创建两个环境变量:
DOCKER_USERNAME:您的 DockerHub 用户名。 *DOCKER_PASSWORD:您的 DockerHub 密码。
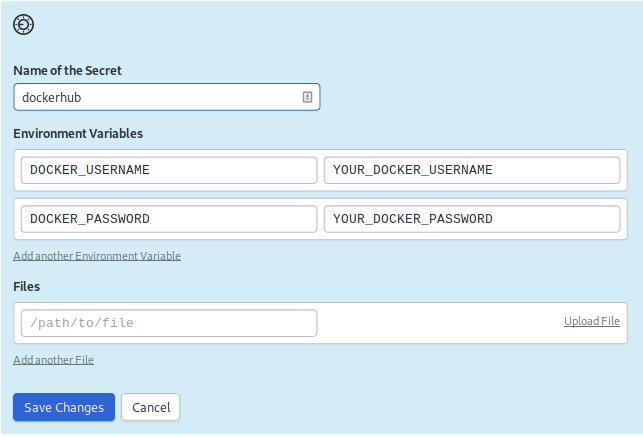
点击保存更改。
為您的 DigitalOcean Personal Access Token 創建第二個秘密. 再一次,在左側的導航菜單中點一下 Secrets ,然後點一下 ** Create New Secret** . 將此秘密稱為 do-access-token,並創建一個名為 DO_ACCESS_TOKEN 的環境值,其值設定為您的 Personal Access Token:
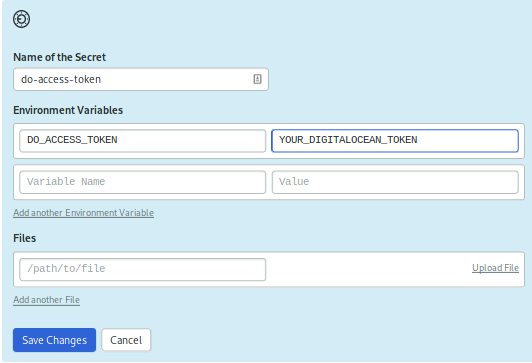
保守秘密。
对于下一个秘密,而不是直接设置环境变量,您将从项目的根上上传 .env 文件。
创建一个名为env-production的新秘密。在Files**部分,点击Upload file** 链接以查找并上传您的.env文件,并告诉Semaphore将其放置在/home/semaphore/env-production。
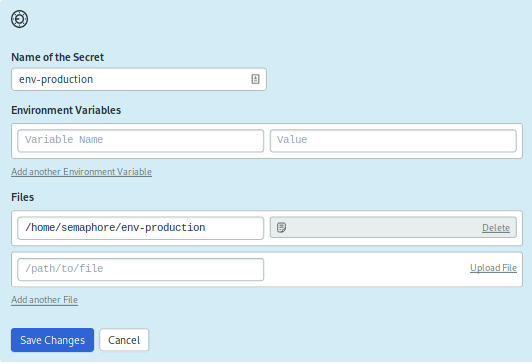
<$>[注]
** 注意:** 由于文件隐藏,您可能在计算机上很难找到它. 通常有一个菜单项或密钥组合来查看隐藏的文件,例如 CTRL+H. 如果其他一切都失败,您可以尝试用非隐藏的名称复制该文件:
1cp .env env
然后上传文件并重命名它:
1cp env .env
美元
所有环境变量都已配置,您现在可以启动连续集成设置。
步骤 4 – 将您的项目添加到 Semaphore
在此步骤中,您将添加您的项目到 Semaphore 并启动 持续集成 (CI) 管道。
首先,将您的 GitHub 存储库与 Semaphore 联系起来:
- 登录到您的 Semaphore帐户中。 2 点击 + 图标旁边的 ** PROJECTS** 。 3 点击你的存储库旁边的 Add Repository 按钮。

现在 Semaphore 已连接,它将自动收集存储库中的任何更改。
您现在已经准备好为应用程序创建连续集成管道。 管道定义了您的代码必须旅行的路径,以便构建、测试和部署。
首先,您应该确保 Semaphore 使用相同的 Node 版本,您可以在开发过程中使用。
1node -v
1[secondary_label Output]
2v10.16.0
您可以通过在您的存储库中创建一个名为.nvmrc的文件来告诉 Semaphore使用哪个版本的 Node.js。
1echo '10.16.0' > .nvmrc
Semaphore 管道进入.semaphore 目录,创建目录:
1mkdir .semaphore
创建一个新的管道文件. 最初的管道总是被称为 semaphore.yml. 在此文件中,您将定义构建和测试应用程序所需的所有步骤。
1nano .semaphore/semaphore.yml
<$>[注] **注:您正在创建一个文件在 YAML 格式。
第一行必须设置 Semaphore 文件版本;当前的稳定值为 v1.0. 此外,管道需要一个名称。
1[label .semaphore/semaphore.yml]
2version: v1.0
3name: Addressbook
4
5. . .
Semaphore 會自動提供虛擬機器來執行這些任務. 有 不同的機器可供選擇. 對於整合工作,請使用「e1-standard-2」(2 CPU 4 GB RAM) 以及 Ubuntu 18.04 OS。
1[label .semaphore/semaphore.yml]
2. . .
3
4agent:
5 machine:
6 type: e1-standard-2
7 os_image: ubuntu1804
8
9. . .
Semaphore 使用 blocks 来组织任务. 每个块可以有一个或多个 jobs. 一个块中的所有工作并行运行,每一个在一个孤立的机器上。
首先,定义第一个块,它安装了所有JavaScript依赖性来测试和运行应用程序:
1[label .semaphore/semaphore.yml]
2. . .
3
4blocks:
5 - name: Install dependencies
6 task:
7
8. . .
您可以定义所有工作中常见的环境变量,例如将NODE_ENV设置为测试,以便 Node.js 知道这是一个测试环境。
1[label .semaphore/semaphore.yml]
2. . .
3 task:
4 env_vars:
5 - name: NODE_ENV
6 value: test
7
8. . .
在 prologue 部分中的命令在块中的每个任务之前执行。 这是定义设置任务的方便地方。 您可以使用 checkout来克隆 GitHub 存储库。 然后,『nvm use』会激活您在『.nvmrc』中指定的相应 Node.js 版本。 添加‘prologue’ 部分:
1[label .semaphore/semaphore.yml]
2 task:
3. . .
4
5 prologue:
6 commands:
7 - checkout
8 - nvm use
9
10. . .
接下来,添加此代码来安装项目的依赖性。为了加速工作,Semaphore提供了Cache工具。您可以运行Cache store来将node_modules目录保存到Semaphore的缓存中。
1[label .semaphore/semaphore.yml]
2. . .
3
4 jobs:
5 - name: npm install and cache
6 commands:
7 - cache restore
8 - npm install
9 - cache store
10
11. . .
添加另一个块,它将运行两个任务. 一个运行带测试,另一个运行应用程序的测试套件。
1[label .semaphore/semaphore.yml]
2. . .
3
4 - name: Tests
5 task:
6 env_vars:
7 - name: NODE_ENV
8 value: test
9 prologue:
10 commands:
11 - checkout
12 - nvm use
13 - cache restore
14
15. . .
序列重复了与前一个区块相同的命令,并从缓存中恢复了node_module。
现在添加工作. 第一份工作是用 jshint 进行代码质量检查:
1[label .semaphore/semaphore.yml]
2. . .
3
4 jobs:
5 - name: Static test
6 commands:
7 - npm run lint
8
9. . .
下一项工作执行单元测试,您需要一个数据库来运行它们,因为您不希望使用您的生产数据库。 Semaphore 的 sem-service可以在完全隔离的测试环境中启动本地 PostgreSQL 数据库。
1[label .semaphore/semaphore.yml]
2. . .
3
4 - name: Unit test
5 commands:
6 - sem-service start postgres
7 - npm run test
保存.semaphore/semaphore.yml 文件。
现在将更改添加到 GitHub 存储库:
1git add .nvmrc
2git add .semaphore/semaphore.yml
3git commit -m "continuous integration pipeline"
4git push origin master
一旦代码被推到GitHub,Semaphore将启动CI管道:
您可以点击管道以显示块和工作,以及他们的输出。
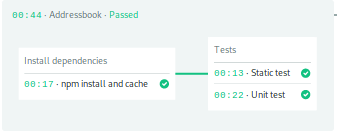
接下来,您将创建一个新的管道,为该应用程序构建一个Docker图像。
步骤 5 – 为应用程序构建 Docker 图像
Docker 图像是 Kubernetes 部署的基本单位. 图像应该具有运行应用程序所需的所有二进制文件、库和代码. Docker 容器不是一个轻量级的虚拟机,但它表现得像一个。
在此步骤中,您将添加一个新的管道,为您的应用构建自定义 Docker 图像,并将其推到 Docker Hub。
要创建一个自定义图像,创建一个Dockerfile:
1nano Dockerfile
「Dockerfile」是创建图像的一种食谱,你可以使用官方的(https://hub.docker.com/_/node/)Node.js分布作为起点,而不是从零开始。
1[label Dockerfile]
2FROM node:10.16.0-alpine
3
4. . .
然后添加一个复制package.json和package-lock.json的命令,然后在图像中安装节点模块:
1[label Dockerfile]
2. . .
3
4COPY package*.json ./
5RUN npm install
6
7. . .
首先安装依赖性将加快后续构建,因为Docker将缓存此步骤。
现在添加此命令,将项目根中的所有应用程序文件复制到图像中:
1[label Dockerfile]
2. . .
3
4COPY *.js ./
5
6. . .
最后,EXPOSE指示容器在应用程序正在收听的端口3000上听取连接,而CMD则设置了当容器启动时应该运行的命令。
1[label Dockerfile]
2. . .
3
4EXPOSE 3000
5CMD [ "npm", "run", "start" ]
保存檔案
随着Dockerfile完成,您可以创建一个新的管道,这样Semaphore可以为您创建图像,当您将代码推到GitHub。
1nano .semaphore/docker-build.yml
开始管道与CI管道相同的锅炉板,但名为Docker build:
1[label .semaphore/docker-build.yml]
2version: v1.0
3name: Docker build
4agent:
5 machine:
6 type: e1-standard-2
7 os_image: ubuntu1804
8
9. . .
此管道将只有一块块和一个任务。在步骤3中,您创建了一个名为dockerhub的秘密,包含您的Docker Hub用户名和密码。
1[label .semaphore/docker-build.yml]
2. . .
3
4blocks:
5 - name: Build
6 task:
7 secrets:
8 - name: dockerhub
9
10. . .
Docker 图像存储在存储库中,我们将使用官方 Docker Hub,允许无限数量的公共图像。 添加这些行以从 GitHub 检查代码,并使用docker login命令与 Docker Hub 进行身份验证。
1[label .semaphore/docker-build.yml]
2 task:
3. . .
4
5 prologue:
6 commands:
7 - checkout
8 - echo "${DOCKER_PASSWORD}" | docker login -u "${DOCKER_USERNAME}" --password-stdin
9
10. . .
每个 Docker 图像是完全通过名称和标签的组合来识别的. 该名称通常与产品或软件相符,该标签与软件的特定版本相符. 例如, node.10.16.0. 当没有标签提供时,Docker 默认为特殊的 最新 标签。
添加以下代码来构建图像并将其推到 Docker Hub:
1[label .semaphore/docker-build.yml]
2. . .
3
4 jobs:
5 - name: Docker build
6 commands:
7 - docker pull "${DOCKER_USERNAME}/addressbook:latest" || true
8 - docker build --cache-from "${DOCKER_USERNAME}/addressbook:latest" -t "${DOCKER_USERNAME}/addressbook:$SEMAPHORE_WORKFLOW_ID" .
9 - docker push "${DOCKER_USERNAME}/addressbook:$SEMAPHORE_WORKFLOW_ID"
当Docker构建图像时,它会重复使用现有图像的部分来加速过程。第一个命令试图从Docker Hub中提取最新的图像,以便它可以重复使用。如果任何命令返回的状态代码不同于零,Semaphore会停止管道。
第二个命令构建图像. 为了稍后引用此特定图像,您可以用一个独特的字符串标记它. Semaphore 提供了多个 环境变量 用于任务。 其中一个, $SEMAPHORE_WORKFLOW_ID 是独特的,在工作流中的所有管道之间共享。
第三个命令将图像推到Docker Hub。
构建管道已准备好,但除非您将其连接到主 CI 管道,否则 Semaphore 将不会启动。
编辑主要管道文件 .semaphore/semaphore.yml:
1nano .semaphore/semaphore.yml
添加下列行到文件的末尾:
1[label .semaphore/semaphore.yml]
2. . .
3
4promotions:
5 - name: Dockerize
6 pipeline_file: docker-build.yml
7 auto_promote_on:
8 - result: passed
auto_promote_on定义了启动docker build管道的条件,在这种情况下,它在semaphore.yml文件中定义的所有任务完成后运行。
要测试新管道,您需要添加、委托并将所有修改的文件推送到GitHub:
1git add Dockerfile
2git add .semaphore/docker-build.yml
3git add .semaphore/semaphore.yml
4git commit -m "docker build pipeline"
5git push origin master
CI 管道完成后,Docker 构建管道开始。
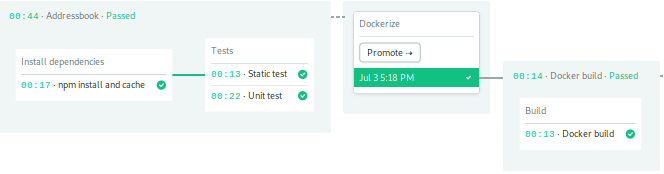
当它完成时,你会在你的 Docker Hub 存储库中看到你的新图像。
您已经完成了构建流程的测试并创建了图像,现在您将创建最终的管道,将应用程序部署到您的Kubernetes集群中。
步骤6:为Kubernetes设置连续部署
Kubernetes 部署的构建块是 pod。 一个 pod 是作为单个单元管理的集装箱的一组。 一个 pod 内部的集装箱开始和停止一致,并始终在同一台机器上运行,共享其资源。
Pods是短暂的;它们经常被创建和破坏. 您无法告诉每个pod将被分配到哪个IP地址,直到它开始。 要解决这个问题,您将使用服务,这些服务有固定的公共IP地址,以便接入的连接可以负荷平衡并传送到pods。
您可以直接管理 pods,但最好让 Kubernetes 通过使用 部署来处理此问题。 在本节中,您将创建一个声明性宣言,描述您的集群所需的最终状态。
- 部署:根据需要启动集群节点中的 pods,并跟踪其状态. 由于在本教程中我们正在使用3节点集群,我们将部署3个 pods。
- 服务:作为用户的入口点。
创建一个名为deployment.yml的文件:
1nano deployment.yml
使用部署资源启动宣言. 将下列内容添加到新文件中以定义部署:
1[label deployment.yml]
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: addressbook
6spec:
7 replicas: 3
8 selector:
9 matchLabels:
10 app: addressbook
11 template:
12 metadata:
13 labels:
14 app: addressbook
15 spec:
16 containers:
17 - name: addressbook
18 image: ${DOCKER_USERNAME}/addressbook:${SEMAPHORE_WORKFLOW_ID}
19 env:
20 - name: NODE_ENV
21 value: "production"
22 - name: PORT
23 value: "$PORT"
24 - name: DB_SCHEMA
25 value: "$DB_SCHEMA"
26 - name: DB_USER
27 value: "$DB_USER"
28 - name: DB_PASSWORD
29 value: "$DB_PASSWORD"
30 - name: DB_HOST
31 value: "$DB_HOST"
32 - name: DB_PORT
33 value: "$DB_PORT"
34 - name: DB_SSL
35 value: "$DB_SSL"
36
37. . .
对于该宣言中的每个资源,您需要设置一个apiVersion。 对于部署,请使用一个稳定版本的apiVersion: apps/v1。 然后,告诉Kubernetes,该资源是具有kind:Deployment的部署。
在spec部分中,你告诉Kubernetes想要的最终状态是什么。
Labels 是用于组织和交叉引用 Kubernetes 资源的关键值对,您可以用 metadata.labels 定义标签,并且可以寻找与 selector.matchLabels 匹配的标签。
spec.template 键定义了 Kubernetes 将使用的模型来创建每个 pod. 在 spec.template.metadata.labels 中,您为 pods 设置了一个标签: app:地址簿。
使用spec.selector.matchLabels,您可以将部署管理任何 pods 标签为app:地址簿。
最后,您定义了在 pods 中运行的图像。在「spec.template.spec.containers」中,您将设置图像名称。Kubernetes将根据需要从注册表中提取图像。在这种情况下,它将从Docker Hub中提取图像)。
要保持部署的灵活性,您将依赖变量。YAML格式,然而,不允许变量,所以文件尚未有效。
这是部署的目的,但这只定义了 pods. 你仍然需要一个服务,允许流量流到你的 pods. 只要你使用三个字符串(---)作为分离器,你可以在同一文件中添加另一个 Kubernetes 资源。
添加以下代码来定义连接到地址簿标签的 pods 的负载平衡服务:
1[label deployment.yml]
2. . .
3
4---
5
6apiVersion: v1
7kind: Service
8metadata:
9 name: addressbook-lb
10spec:
11 selector:
12 app: addressbook
13 type: LoadBalancer
14 ports:
15 - port: 80
16 targetPort: 3000
负荷平衡器将在端口80上接收连接,并将其传送到应用程序正在收听的3000端口。
保存檔案
现在,为 Semaphore 创建一个部署管道,该管道将使用宣言部署应用程序。
1nano .semaphore/deploy-k8s.yml
像往常一样开始管道,指定版本、名称和图像:
1[label .semaphore/deploy-k8s.yml]
2version: v1.0
3name: Deploy to Kubernetes
4agent:
5 machine:
6 type: e1-standard-2
7 os_image: ubuntu1804
8
9. . .
该管道将有两个块,第一个块将应用程序部署到Kubernetes集群中。
定义区块并导入所有秘密:
1[label .semaphore/deploy-k8s.yml]
2. . .
3
4blocks:
5 - name: Deploy to Kubernetes
6 task:
7 secrets:
8 - name: dockerhub
9 - name: do-access-token
10 - name: env-production
11
12. . .
将您的 DigitalOcean Kubernetes 集群名存储在环境变量中,以便您稍后可以参考它:
1[label .semaphore/deploy-k8s.yml]
2. . .
3
4 env_vars:
5 - name: CLUSTER_NAME
6 value: addressbook-server
7
8. . .
DigitalOcean Kubernetes集群是由两个程序组合管理的: kubectl和 doctl. 前者已经包含在Semaphore的图像中,但后者不是,所以你需要安装它。
添加此前文部分:
1[label .semaphore/deploy-k8s.yml]
2. . .
3
4 prologue:
5 commands:
6 - wget https://github.com/digitalocean/doctl/releases/download/v1.20.0/doctl-1.20.0-linux-amd64.tar.gz
7 - tar xf doctl-1.20.0-linux-amd64.tar.gz
8 - sudo cp doctl /usr/local/bin
9 - doctl auth init --access-token $DO_ACCESS_TOKEN
10 - doctl kubernetes cluster kubeconfig save "${CLUSTER_NAME}"
11 - checkout
12
13. . .
第一个命令下载了doctl官方版本(https://github.com/digitalocean/doctl/releases)的wget。第二个命令用tar解压缩了它,并将其复制到本地路径中。一旦安装了doctl,它可以用来通过DigitalOcean API进行身份验证,并要求我们集群的Kubernetes配置文件。在检查我们的代码后,我们完成了prologue:
接下来是我们管道的最后一部分:部署到集群。
请记住,在deployment.yml中存在一些环境变量,而YAML不允许这样做。因此,deployment.yml在其当前状态下不会起作用。 要绕过这一点,请源环境文件加载变量,然后使用envsubst命令以实际值扩展变量。 结果,一个名为deploy.yml的文件是完全有效的YAML,值被插入。
1[label .semaphore/deploy-k8s.yml]
2. . .
3
4 jobs:
5 - name: Deploy
6 commands:
7 - source $HOME/env-production
8 - envsubst < deployment.yml | tee deploy.yml
9 - kubectl apply -f deploy.yml
10
11. . .
第二个块将最新的标签添加到 Docker Hub 上的图像中,表示这是部署的最新版本。
1[label .semaphore/deploy-k8s.yml]
2. . .
3
4 - name: Tag latest release
5 task:
6 secrets:
7 - name: dockerhub
8 prologue:
9 commands:
10 - checkout
11 - echo "${DOCKER_PASSWORD}" | docker login -u "${DOCKER_USERNAME}" --password-stdin
12 - checkout
13 jobs:
14 - name: docker tag latest
15 commands:
16 - docker pull "${DOCKER_USERNAME}/addressbook:$SEMAPHORE_WORKFLOW_ID"
17 - docker tag "${DOCKER_USERNAME}/addressbook:$SEMAPHORE_WORKFLOW_ID" "${DOCKER_USERNAME}/addressbook:latest"
18 - docker push "${DOCKER_USERNAME}/addressbook:latest"
保存檔案
此管道执行部署,但只有在 Docker 图像被成功生成并推到 Docker Hub 后才能启动。
1nano .semaphore/docker-build.yml
将促销添加到文件的末尾:
1[label .semaphore/docker-build.yml]
2. . .
3
4promotions:
5 - name: Deploy to Kubernetes
6 pipeline_file: deploy-k8s.yml
7 auto_promote_on:
8 - result: passed
您已完成设置 CI/CD 工作流程。
剩下的只是推移修改的文件,让Semaphore完成工作. 添加,承诺,并推动您的存储库的更改:
1git add .semaphore/deploy-k8s.yml
2git add .semaphore/docker-build.yml
3git add deployment.yml
4git commit -m "kubernetes deploy pipeline"
5git push origin master
部署将需要几分钟才能完成。
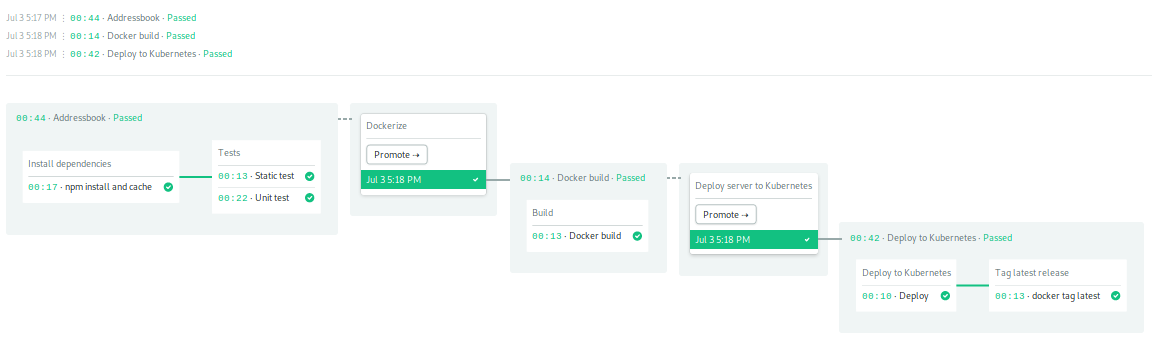
接下来我们来测试应用程序。
步骤7:测试应用程序
在此时,应用程序已启动并运行,在此步骤中,您将使用弯曲来测试 API 终端。
您需要知道 DigitalOcean 给您的集群的公共 IP。
- 登录到您的 DigitalOcean 帐户中.
- 选择地址簿项目
- 点击 网络 .
- 点击 负载平衡器 .
- 显示了 IP 地址 。 复制 IP 地址。
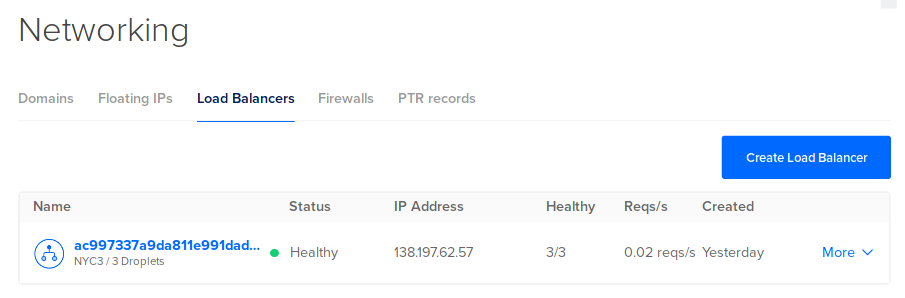
让我们检查使用curl的/all路径:
1curl -w "\n" YOUR_CLUSTER_IP/all
您可以使用w\n选项来确保curl`打印所有行:
由于数据库中尚无记录,因此您会得到一个空的 JSON 数组:
1[secondary_label Output]
2[]
创建一个新的个人记录,将PUT请求发送到/person终端:
1curl -w "\n" -X PUT \
2 -d "firstName=Sammy&lastName=the Shark" YOUR_CLUSTER_IP/person
API 返回 JSON 对象为该人:
1[secondary_label Output]
2{
3 "id": 1,
4 "firstName": "Sammy",
5 "lastName": "the Shark",
6 "updatedAt": "2019-07-04T23:51:00.548Z",
7 "createdAt": "2019-07-04T23:51:00.548Z"
8}
创建第二个人:
1curl -w "\n" -X PUT \
2 -d "firstName=Tommy&lastName=the Octopus" YOUR_CLUSTER_IP/person
输出表明创建了第二个人:
1[secondary_label Output]
2{
3 "id": 2,
4 "firstName": "Tommy",
5 "lastName": "the Octopus",
6 "updatedAt": "2019-07-04T23:52:08.724Z",
7 "createdAt": "2019-07-04T23:52:08.724Z"
8}
现在做一个GET请求,以获取具有2的id的人:
1curl -w "\n" YOUR_CLUSTER_IP/person/2
服务器用您请求的数据回复:
1[secondary_label Output]
2{
3 "id": 2,
4 "firstName": "Tommy",
5 "lastName": "the Octopus",
6 "createdAt": "2019-07-04T23:52:08.724Z",
7 "updatedAt": "2019-07-04T23:52:08.724Z"
8}
要删除该人,请发送删除请求:
1curl -w "\n" -X DELETE YOUR_CLUSTER_IP/person/2
此命令不会返回任何输出。
你应该在你的数据库中只有一个人,一个有ID的1。
1curl -w "\n" YOUR_CLUSTER_IP/all
服务器以只包含一个记录的数组响应:
1[secondary_label Output]
2[
3 {
4 "id": 1,
5 "firstName": "Sammy",
6 "lastName": "the Shark",
7 "createdAt": "2019-07-04T23:51:00.548Z",
8 "updatedAt": "2019-07-04T23:51:00.548Z"
9 }
10]
此时,数据库中只剩下一个人。
这完成了我们应用程序中的所有终点的测试,并标志着教程的结束。
结论
在本教程中,您从头开始编写了一个完整的Node.js应用程序,该应用程序使用了DigitalOcean管理的PostgreSQL数据库服务,然后使用Semaphore的CI/CD管道来完全自动化一个工作流程,测试并构建一个容器图像,将其上传到Docker Hub,并部署到DigitalOcean Kubernetes。
要了解更多关于Kubernetes的信息,您可以阅读《对Kubernetes的介绍》(LINK0),以及DigitalOcean的其他内容(Kubernetes教程)(LINK1)。