介绍
许多开发人员没有时间或经验来为他们的应用程序设置和管理基础设施. 为了跟上截止日期和降低成本,开发人员需要找到解决方案,使他们能够尽快和高效地将应用程序部署到云端,专注于编写代码并为客户提供新功能。 共同,DigitalOcean的 应用平台和 Fauna提供这种功能。
DigitalOcean App Platform是一个平台作为服务(PaaS),它抽象了运行应用程序的基础设施,还允许您通过将代码推到Git分支来部署应用程序。
Fauna 是一个强大的数据层,适用于任何尺寸的应用程序. 正如您将在本教程中看到的那样,通过 Fauna,您可以快速创建和运行数据库,而无需担心数据库操作。
这两种解决方案可以让您专注于应用程序,而不是管理基础设施。
在本教程中,您将通过使用 Flask 框架来编写最小 REST API 来集成 Fauna 与 Python。
- 用于在
用户集合中创建用户的公共/signupPOST 终端 * 用于与用户集合中的文档进行身份验证的公共/loginPOST 终端 * 用于从Things集合中提取动物文档列表的私人/thingsGET 终端。
已完成的 Python 项目可在 这个 Github 存储库找到。
前提条件
在开始本教程之前,您将需要:
- [法 账户(https://dashboard.fauna.com/accounts/register)。
- [数字海洋帐户] (https://cloud.digitalocean.com/registrations/new),并配置了支付方法。
- AGithub账户,可以将您的项目部署到App平台.
- Python 3和 " pip " 安装在你的开发机器上。 遵循 [如何安装和设置 Python 3 本地编程环境] (https://www.digitalocean.com/community/tutorial_series/how-to-install-and-set-up-a-local-programming-environment-for-python-3) 设置此设置 。
- 安装在您的本地机器上。 您可以遵循 [如何帮助打开源码: 开始使用 Git] (https://andsky.com/tech/tutorials/contributing-to-open-source-getting-started-with-git ) 在您的计算机上安装和设置 Git 。
- 文本编辑。 您可以使用 [Visual Studio Code (https://code.visualstudio.com/download) 或您最喜欢的文本编辑器. .
第1步:创建动物数据库
在第一个步骤中,您将配置 Fauna 数据库并为 API 创建收藏。 Fauna 是一个基于文档的数据库(https://www.digitalocean.com/community/conceptual_articles/an-introduction-to-document-oriented-databases),而不是传统的基于表的关系数据库。 Fauna 将您的数据存储在文档和收藏中,这些数据是文档组。
要创建集合,您将使用 FQL 执行查询,这是 Fauna 的原生查询语言。
请点击 登录 Fauna 的仪表板.登录后,点击顶部的 创建数据库 按钮。
在新数据库表格中,为数据库名称使用PYTHON_API:
离开 预定位与演示数据 未检查. 点击** 保存 ** 按钮。
创建数据库后,您将看到您的数据库的首页部分:
现在你将创建两个收藏:
- 将文件存储与身份验证信息的
用户集合。 * 存储一些模仿数据的事物集合来测试您的API。
要创建这些集合,您将在仪表板的壳中执行一些 FQL 查询。
在壳底板中写下以下 FQL 查询以使用 CreateCollection函数创建一个名为 Things 的集合:
1CreateCollection({name: "Things"})
点击 RUN QUERY 按钮,您将在壳的顶部面板中获得类似的结果:
1{
2 ref: Collection("Things"),
3 ts: 1614805457170000,
4 history_days: 30,
5 name: "Things"
6}
结果显示了四个领域:
ref是指集合本身。 *ts是它在微秒内创建的时间标签。 *history_days是指 Fauna 将对文档的更改保存多长时间。
接下来,使用以下查询创建用户集合:
1CreateCollection({name: "Users"})
现在,既然两个集合都存在,您将创建您的第一个文档。
文档可以存储字符串、数字和数组,但它们也可以使用 Fauna 数据类型. 一个常见的 Fauna 类型是 Ref,它代表了收藏中的文档的参考。
Create函数将创建一个新文档到所指定的集合中。 运行下列查询,在Things集合中创建一个文档,其中有两个字段:
1Create(
2 Collection("Things"),
3 {
4 data: {
5 name: "Banana",
6 color: "Yellow"
7 }
8 }
9)
运行此查询后, Fauna 将返回创建的文档:
1{
2 ref: Ref(Collection("Things"), "292079274901373446"),
3 ts: 1614807352895000,
4 data: {
5 name: "Banana",
6 color: "Yellow"
7 }
8}
结果显示了以下领域:
ref类型为Ref是Things收藏中的该文档的参考,其 ID 是292079274901373446。 请注意,您的文档将具有不同的 ID。
这个结果看起来类似于创建集合时获得的结果,因为 Fauna 中的所有实体(集合、索引、角色等)实际上都作为文档存储。
要阅读文档,请使用 Get函数,该函数接受文档的引用。 使用文档的引用来运行Get查询:
1Get(Ref(Collection("Things"), "292079274901373446"))
结果是完整的文件:
1{
2 ref: Ref(Collection("Things"), "292079274901373446"),
3 ts: 1614807352895000,
4 data: {
5 name: "Banana",
6 color: "Yellow"
7 }
8}
要获取藏品中存储的所有文档参考,请使用 文档 函数与 Paginate 函数:
1Paginate(Documents(Collection("Things")))
此查询返回具有参照数组的页面:
1{
2 data: [Ref(Collection("Things"), "292079274901373446")]
3}
要获得实际的文档而不是引用,重复使用的引用 Map 然后使用一个 Lambda (一个匿名函数)重复的范围的引用和 Get 每个引用:
1Map(
2 Paginate(Documents(Collection("Things"))),
3 Lambda("ref", Get(Var("ref")))
4)
结果是一个包含完整文件的数组:
1{
2 data: [
3 {
4 ref: Ref(Collection("Things"), "292079274901373446"),
5 ts: 1614807352895000,
6 data: {
7 name: "Banana",
8 color: "Yellow"
9 }
10 }
11 ]
12}
您通常在 Fauna 中使用索引来目录、过滤和排序数据,但您也可以使用它们用于其他目的,例如强制执行独特限制。
Users_by_username索引会根据他们的用户名找到用户,并执行一个独特的限制,以防止两个文档具有相同的用户名。
在壳中运行此代码来创建索引:
1CreateIndex({
2 name: "Users_by_username",
3 source: Collection("Users"),
4 terms: [{ field: ["data", "username"] }],
5 unique: true
6})
CreateIndex函数将创建一个索引,并配置下面的设置:
- )。 *
术语是您在使用索引来查找文档时将该索引传输到索引的搜索/过滤术语。 *独特意味着索引值将是唯一的。
要测试索引,请在用户集合中创建一个新的文档,在 Fauna 壳中运行以下代码:
1Create(
2 Collection("Users"),
3 {
4 data: {
5 username: "sammy"
6 }
7 }
8)
你会看到一个结果如下:
1{
2 ref: Ref(Collection("Users"), "292085174927098368"),
3 ts: 1614812979580000,
4 data: {
5 username: "sammy"
6 }
7}
现在尝试创建具有相同用户名值的文档:
1Create(
2 Collection("Users"),
3 {
4 data: {
5 username: "sammy"
6 }
7 }
8)
您现在将收到一个错误:
1Error: [
2 {
3 "position": [
4 "create"
5 ],
6 "code": "instance not unique",
7 "description": "document is not unique."
8 }
9]
现在该索引已经在位,您可以查询它并检索一个单一的文档。在壳中运行此代码以检索使用索引的sammy用户:
1Get(
2 Match(
3 Index("Users_by_username"),
4 "sammy"
5 )
6)
以下是它如何运作:
这个查询的结果将是:
1{
2 ref: Ref(Collection("Users"), "292085174927098368"),
3 ts: 1614812979580000,
4 data: {
5 username: "sammy"
6 }
7}
通过将其引用到 删除函数来删除此测试文档:
1Delete(Ref(Collection("Users"), "292085174927098368"))
接下来,您将配置 Fauna 的安全设置,以便您可以从您的代码连接到它。
步骤 2 — 配置服务器密钥和授权规则
在此步骤中,您将创建一个服务器密钥,您的Python应用程序将用于与Fauna进行通信,然后您将配置访问权限。
要创建一个密钥,请使用左侧的主菜单进入 Fauna 仪表板的 安全性 部分。
- 按下 新密钥 按钮 2. 选择 ** 服务器** 角色 3. 按下 ** 保存** 。
保存后,仪表板将向您展示密钥的秘密,将秘密保存在安全的地方,永远不要将其委托给您的Git存储库。
<$>[警告] 警告 :** 服务器** 角色是万能的,任何拥有这个秘密的人都可以完全访问您的数据库,正如其名称所暗示的那样,这是通常由受信任的服务器应用程序使用的角色,尽管也可以创建具有有限权限的自定义角色的密钥。
默认情况下,Fauna 中的所有内容都是私密的,因此您现在将创建一个新的角色,以允许登录的用户从Things 集合中阅读文档。
在仪表板的安全部分中,转到角色并创建一个名为用户的新自定义角色。
在集合下载框中,添加事物集合并按阅读权限,以显示绿色标记:
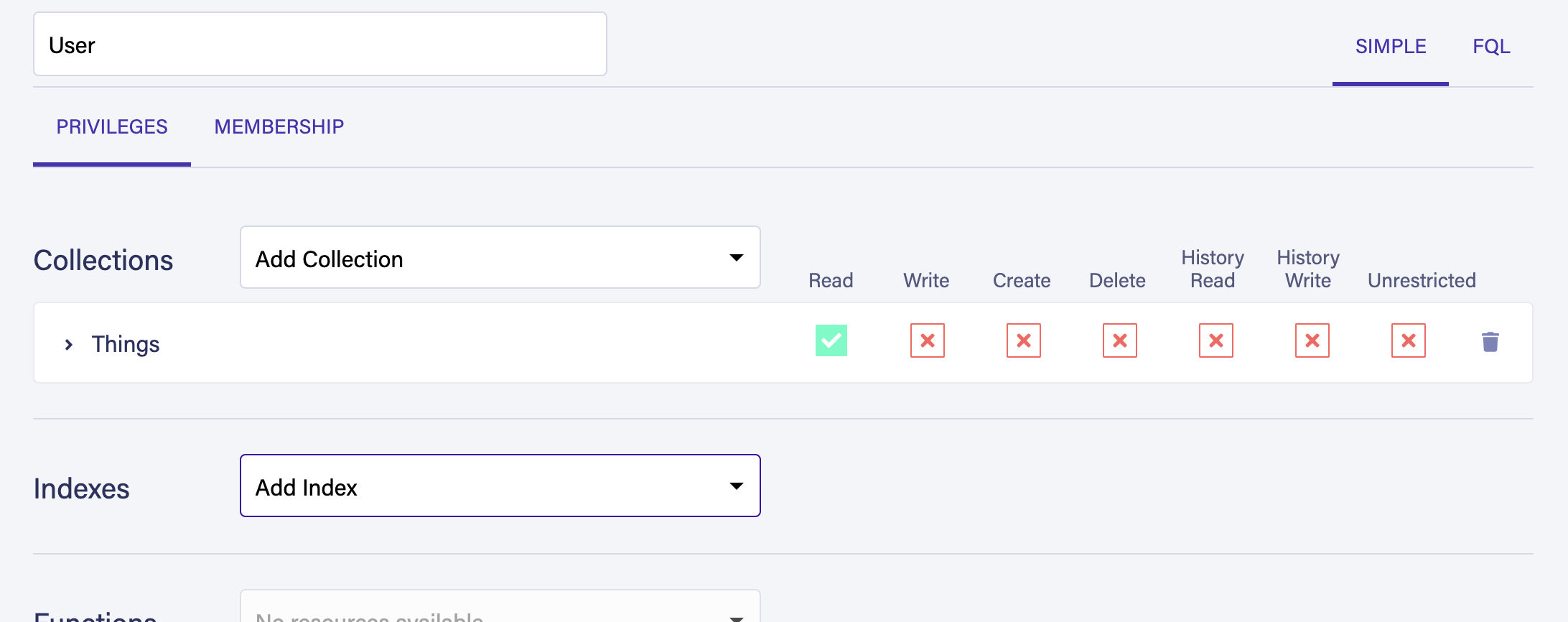
在保存角色之前,请前往 会员 选项卡,并将用户集合添加到角色中:
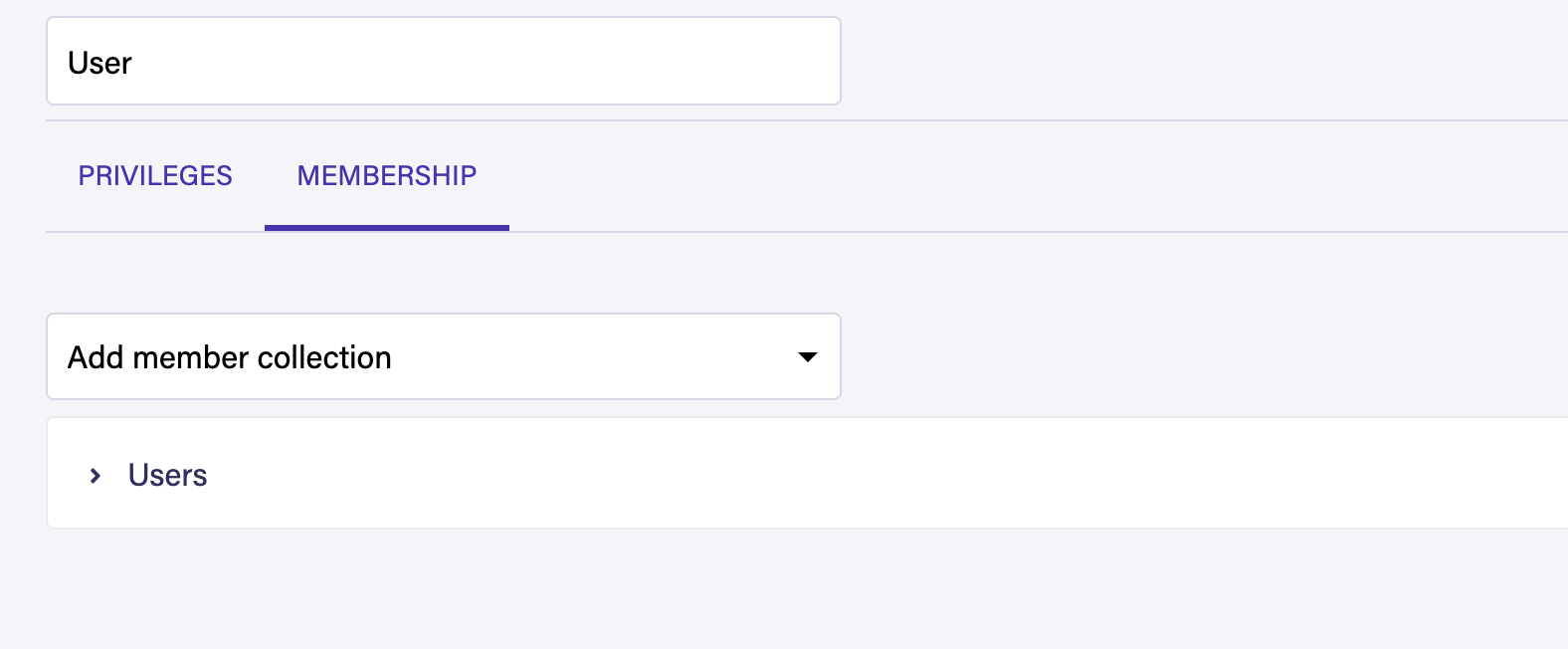
您现在可以通过点击保存按钮来保存您的用户自定义角色。
现在,从用户集合中的文档中登录的任何用户都可以阅读来自物品集合的任何文档。
有了身份验证和授权,现在让我们创建 Python API 来与 Fauna 交谈。
第3步:构建Python应用程序
在此步骤中,您将使用Flask框架构建一个小型REST API,并在Python中编写FQL查询,并使用 Fauna 驱动程序连接到您的 Fauna 数据库。
要开始,创建一个项目文件夹,并从终端访问它。
首先安装 Flask:
1pip install flask
然后安装 Fauna Python 驱动程序:
1pip install faunadb
在您的项目文件夹中,创建main.py文件,并将以下代码添加到文件中,添加必要的导入、FAUNA_SECRET环境变量以及Flask应用程序的基本配置:
1[label main.py]
2import os
3FAUNA_SECRET = os.environ.get('FAUNA_SECRET')
4
5import flask
6from flask import request
7
8import faunadb
9from faunadb import query as q
10from faunadb.client import FaunaClient
11
12app = flask.Flask(__name__)
13app.config["DEBUG"] = True
「FAUNA_SECRET」环境变量将携带您之前创建的服务器秘密。要在本地或云端运行此应用程序,需要注入此变量。
现在将/signup路线添加到main.py文件中,从而在用户集合中创建新文档:
1[label main.py]
2@app.route('/signup', methods=['POST'])
3def signup():
4
5 body = request.json
6 client = FaunaClient(secret=FAUNA_SECRET)
7
8 try:
9 result = client.query(
10 q.create(
11 q.collection("Users"),
12 {
13 "data": {
14 "username": body["username"]
15 },
16 "credentials": {
17 "password": body["password"]
18 }
19 }
20 )
21 )
22
23 return {
24 "userId": result['ref'].id()
25 }
26
27 except faunadb.errors.BadRequest as exception:
28 error = exception.errors[0]
29 return {
30 "code": error.code,
31 "description": error.description
32 }, 409
请注意, Fauna 客户端在使用服务器秘密的每个请求上被实例化:
1[label main.py]
2...
3client = FaunaClient(secret=FAUNA_SECRET)
4...
一旦用户登录,API将使用不同的秘密代表每个用户执行查询,这就是为什么在每个请求中实例化客户端是有意义的。
与其他数据库不同, Fauna 客户端不保持永久连接. 从外部世界来看, Fauna 行为就像一个 API;每个查询都是单一的 HTTP 请求。
客户端完成后,FQL 查询会执行,在用户集合中创建一个新文档。每个 Fauna 驱动程序都会将语法语法翻译成 FQL 陈述。
1[label main.py]
2...
3q.create(
4 q.collection("Users"),
5 {
6 "data": {
7 "user": json["user"]
8 },
9 "credentials": {
10 "password": json["password"]
11 }
12 }
13)
14...
这就是本地 FQL 中的此查询的样子:
1Create(
2 Collection("Users"),
3 {
4 "data": {
5 "user": "sammy"
6 },
7 "credentials": {
8 "password": "secretpassword"
9 }
10 }
11)
除了文档数据外,您还使用用户密码添加了身份验证配置,文档的这个部分是完全私密的,您将永远无法读取文档的身份验证。
最后,如果已经有具有相同用户名的用户,则会提到一个faunadb.errors.BadRequest例外,并返回一个包含错误信息的409响应。
接下来,在 main.py 文件中添加 /login 路径来验证用户和密码. 这跟上一个示例类似的模式;你使用 Fauna 连接执行查询,如果验证失败,你会提到 faunadb.errors.BadRequest' 例外,并返回一个 401' 回复,并包含错误信息。
1[label main.py]
2@app.route('/login', methods=['POST'])
3def login():
4
5 body = request.json
6 client = FaunaClient(secret=FAUNA_SECRET)
7
8 try:
9 result = client.query(
10 q.login(
11 q.match(
12 q.index("Users_by_username"),
13 body["username"]
14 ),
15 {"password": body["password"]}
16 )
17 )
18
19 return {
20 "secret": result['secret']
21 }
22
23 except faunadb.errors.BadRequest as exception:
24 error = exception.errors[0]
25 return {
26 "code": error.code,
27 "description": error.description
28 }, 401
以下是用于用 Fauna 验证用户的 FQL 查询:
1[label main.py]
2q.login(
3 q.match(
4 q.index("Users_by_username"),
5 body["username"]
6 ),
7 {"password": body["password"]}
8)
这就是本地 FQL 中的此查询的样子:
1Login(
2 Match(
3 Index("Users_by_username"),
4 "sammy"
5 ),
6 {"password": "secretpassword"}
7)
'Match' 返回使用我们之前创建的 'Users_by_username' 索引的文档引用。
如果提供的密码匹配参照的文档,‘登录’将创建一个新的代币,并返回一个字典,其中包含以下密钥:
- 「ref」是指新文档的代币。 * 「ts」是指交易的时间标签。 * 「实例」是指用于进行身份验证的文档。 * 「秘密」是指代币的秘密,将用于向 Fauna 提出进一步查询。
如果您将该 FQL 查询运行到您的 Fauna 仪表板的壳中,您将看到类似于此的东西:
1{
2 ref: Ref(Ref("tokens"), "292001047221633538"),
3 ts: 1614732749110000,
4 instance: Ref(Collection("Users"), "291901454585692675"),
5 secret: "fnEEDWVnxbACAgQNBIxMIAIIKq1E5xvPPdGwQ_zUFH4F5Dl0neg"
6}
根据项目的安全要求,您必须决定如何处理代币的秘密。如果这个API是用来被浏览器消耗的,您可能会返回安全cookie或加密的JSON Web Token(JWT)中的秘密,或者您可能会将其作为会话数据存储在其他地方,如Redis实例。
最后,添加这个代码到main.py,它将启动Flask应用程序:
1[label main.py]
2app.run(host=os.getenv('IP', '0.0.0.0'), port=int(os.getenv('PORT', 8080)))
重要的是要指定0.0.0.0地址.一旦部署到云端,此应用程序将运行在 Docker 容器中.如果运行在127.0.0.1,它将无法接收远程客户端的请求,这是 Flask 应用程序的默认地址。
以下是迄今为止完整的 main.py 文件:
1[label main.py]
2import os
3FAUNA_SECRET = os.environ.get('FAUNA_SECRET')
4
5import flask
6from flask import request
7
8import faunadb
9from faunadb import query as q
10from faunadb.client import FaunaClient
11
12app = flask.Flask(__name__)
13app.config["DEBUG"] = True
14
15@app.route('/signup', methods=['POST'])
16def signup():
17
18 body = request.json
19 client = FaunaClient(secret=FAUNA_SECRET)
20
21 try:
22 result = client.query(
23 q.create(
24 q.collection("Users"),
25 {
26 "data": {
27 "username": body["username"]
28 },
29 "credentials": {
30 "password": body["password"]
31 }
32 }
33 )
34 )
35
36 return {
37 "userId": result['ref'].id()
38 }
39
40 except faunadb.errors.BadRequest as exception:
41 error = exception.errors[0]
42 return {
43 "code": error.code,
44 "description": error.description
45 }, 409
46
47@app.route('/login', methods=['POST'])
48def login():
49
50 body = request.json
51 client = FaunaClient(secret=FAUNA_SECRET)
52
53 try:
54 result = client.query(
55 q.login(
56 q.match(
57 q.index("Users_by_username"),
58 body["username"]
59 ),
60 {"password": body["password"]}
61 )
62 )
63
64 return {
65 "secret": result['secret']
66 }
67
68 except faunadb.errors.BadRequest as exception:
69 error = exception.errors[0]
70 return {
71 "code": error.code,
72 "description": error.description
73 }, 401
74
75app.run(host=os.getenv('IP', '0.0.0.0'), port=int(os.getenv('PORT', 8080)))
保存檔案
要从您的终端本地启动此服务器,请使用下列命令使用FAUNA_SECRET环境变量,并使用您在创建服务器密钥时获得的秘密:
1FAUNA_SECRET=your_fauna_server_secret python main.py
启动该命令后,Flask 会显示一个警告,通知您它正在与开发 WSGI 服务器一起运行。
通过使用‘curl’ 命令进行 HTTP 请求来测试您的 API. 打开一个新的终端窗口并执行以下命令:
使用以下命令创建用户:
1curl -i -d '{"user":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST http://0.0.0.0:8080/signup
您将看到以下响应,表明成功的用户创建:
1HTTP/1.0 200 OK
2Content-Type: application/json
3Content-Length: 37
4Server: Werkzeug/1.0.1 Python/3.9.2
5Date: Thu, 04 Mar 2021 01:00:47 GMT
6
7{
8 "userId": "292092166117786112"
9}
现在用这个命令验证该用户:
1curl -i -d '{"user":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST http://0.0.0.0:8080/login
你会得到这个成功的答案:
1HTTP/1.0 200 OK
2Content-Type: application/json
3Content-Length: 70
4Server: Werkzeug/1.0.1 Python/3.9.2
5Date: Thu, 04 Mar 2021 01:01:19 GMT
6
7{
8 "secret": "fnEEDbhO3jACAAQNBIxMIAIIOlDxujk-VJShnnhkZkCUPKIHxbc"
9}
关闭您运行弯曲命令的终端窗口,然后返回运行 Python 服务器的终端。
现在该应用程序正在工作,我们将添加一个私人终端,需要用户进行身份验证。
步骤4:添加私人终端
在此步骤中,您将向 API 添加一个私人终端,这将要求用户先进行身份验证。
首先,在 main.py 文件中创建一个新的路线,该路线将响应到 /things' 终端点,并将其放置在开始服务器使用 app.run() 方法的行上:
1[label main.py]
2@app.route('/things', methods=['GET'])
3def things():
接下来,在/things路径中,实时化 Fauna 客户端:
1[label main.py]
2 userSecret = request.headers.get('fauna-user-secret')
3 client = FaunaClient(secret=userSecret)
而不是使用服务器秘密,这个路径是使用用户的秘密从fauna-user-secret HTTP 标题,这是用于实例化 Fauna 客户端. 通过使用用户的秘密而不是服务器秘密,FQL 查询现在将受到我们之前在仪表板中配置的授权规则。
然后将此试用块添加到路径中以执行查询:
1[label main.py]
2 try:
3 result = client.query(
4 q.map_(
5 q.lambda_("ref", q.get(q.var("ref"))),
6 q.paginate(q.documents(q.collection("Things")))
7 )
8 )
9
10 things = map(
11 lambda doc: {
12 "id": doc["ref"].id(),
13 "name": doc["data"]["name"],
14 "color": doc["data"]["color"]
15 },
16 result["data"]
17 )
18
19 return {
20 "things": list(things)
21 }
这会执行 FQL 查询,并将 Fauna 响应解析成可序列化类型,然后作为 HTTP 响应的体内 JSON 字符串返回。
最后,将这个除块添加到路线中:
1[label main.py]
2 except faunadb.errors.Unauthorized as exception:
3 error = exception.errors[0]
4 return {
5 "code": error.code,
6 "description": error.description
7 }, 401
如果请求不包含有效的秘密,则将提到faunadb.errors.Unauthorized例外,并返回包含错误信息的401响应。
这是‘/things’路线的完整代码:
1[label main.py]
2@app.route('/things', methods=['GET'])
3def things():
4
5 userSecret = request.headers.get('fauna-user-secret')
6 client = FaunaClient(secret=userSecret)
7
8 try:
9 result = client.query(
10 q.map_(
11 q.lambda_("ref", q.get(q.var("ref"))),
12 q.paginate(q.documents(q.collection("Things")))
13 )
14 )
15
16 things = map(
17 lambda doc: {
18 "id": doc["ref"].id(),
19 "name": doc["data"]["name"],
20 "color": doc["data"]["color"]
21 },
22 result["data"]
23 )
24
25 return {
26 "things": list(things)
27 }
28
29 except faunadb.errors.Unauthorized as exception:
30 error = exception.errors[0]
31 return {
32 "code": error.code,
33 "description": error.description
34 }, 401
保存文件并重新运行服务器:
1FAUNA_SECRET=your_fauna_server_secret python main.py
要测试这个终端点,首先通过使用有效的身份验证获得一个秘密,打开一个新的终端窗口,并执行下面的‘curl’命令:
1curl -i -d '{"username":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST http://0.0.0.0:8080/login
此命令返回了成功的答案,尽管秘密的值会有所不同:
1HTTP/1.0 200 OK
2Content-Type: application/json
3Content-Length: 70
4Server: Werkzeug/1.0.1 Python/3.9.2
5Date: Thu, 04 Mar 2021 01:01:19 GMT
6
7{
8 "secret": "fnEEDb...."
9}
现在 hen 使用秘密来执行 GET 请求到 /things:
1curl -i -H 'fauna-user-secret: fnEEDb...' -X GET http://0.0.0.0:8080/things
你会得到另一个成功的答案:
1HTTP/1.0 200 OK
2Content-Type: application/json
3Content-Length: 118
4Server: Werkzeug/1.0.1 Python/3.9.2
5Date: Thu, 04 Mar 2021 01:14:49 GMT
6
7{
8 "things": [
9 {
10 "color": "Yellow",
11 "id": "292079274901373446",
12 "name": "Banana"
13 }
14 ]
15}
关闭您运行弯曲命令的终端窗口,返回您的服务器正在运行的窗口,并用CTRL+C停止服务器。
现在你有一个工作应用程序,你已经准备好部署它。
第4步:部署到DigitalOcean
在本教程的最后一步中,您将在App平台上创建一个应用程序,并从GitHub存储库部署它。
在将项目推到 Git 存储库之前,请确保在项目文件夹中运行以下命令:
1pip freeze > requirements.txt
这将创建一个requirements.txt文件,列出需要安装应用程序部署后依赖的列表。
现在将您的项目目录初始化为 Git 存储库:
1git init
现在执行以下命令将文件添加到您的存储库:
1git add .
这将添加当前目录中的所有文件。
随着添加的文件,创建您的初始承诺:
1git commit -m "Initial version of the site"
你的檔案將會執行。
打开您的浏览器并导航到 GitHub,登录您的个人资料,并创建一个名为sharkopedia的新存储库。创建一个没有README或许可证文件的空存储库。
一旦您创建了存储库,请返回命令行,将本地文件推到GitHub。
首先,添加 GitHub 作为远程存储库:
1git remote add origin https://github.com/your_username/sharkopedia
接下来,重新命名默认分支主,以匹配GitHub所期望的:
1git branch -M main
最后,把你的主要分支推到GitHub的主要分支:
1git push -u origin main
您的文件将被传输,您现在已经准备好部署您的应用程序。
注:要在 App Platform 上创建应用程序,您首先需要将付款方式添加到您的 DigitalOcean 帐户中。
该应用程序将运行在一个容器上,每月费用为5美元,尽管只需要几分钱来测试它。
进入 DigitalOcean 仪表板的 应用程序 部分,然后单击** 启动您的应用程序** :
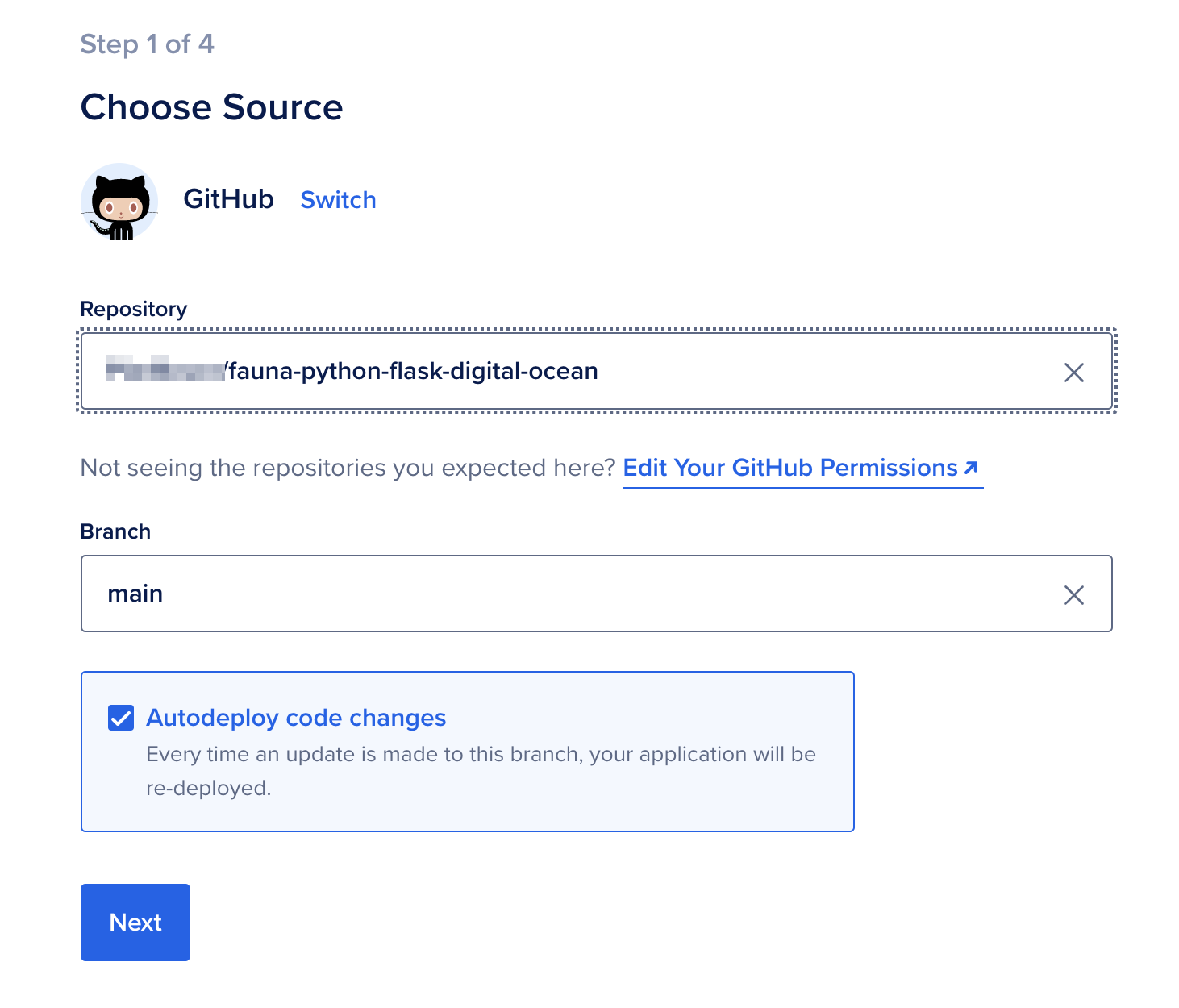
选择要部署的源头. 您需要授权DigitalOcean读取您的Github存储库. 一旦您授权访问,请选择与您的Python项目的存储库和包含您想要部署的应用程序版本的分支机构:
在此时,App Platform将确定您的项目是否使用Python,并允许您配置一些应用程序选项:
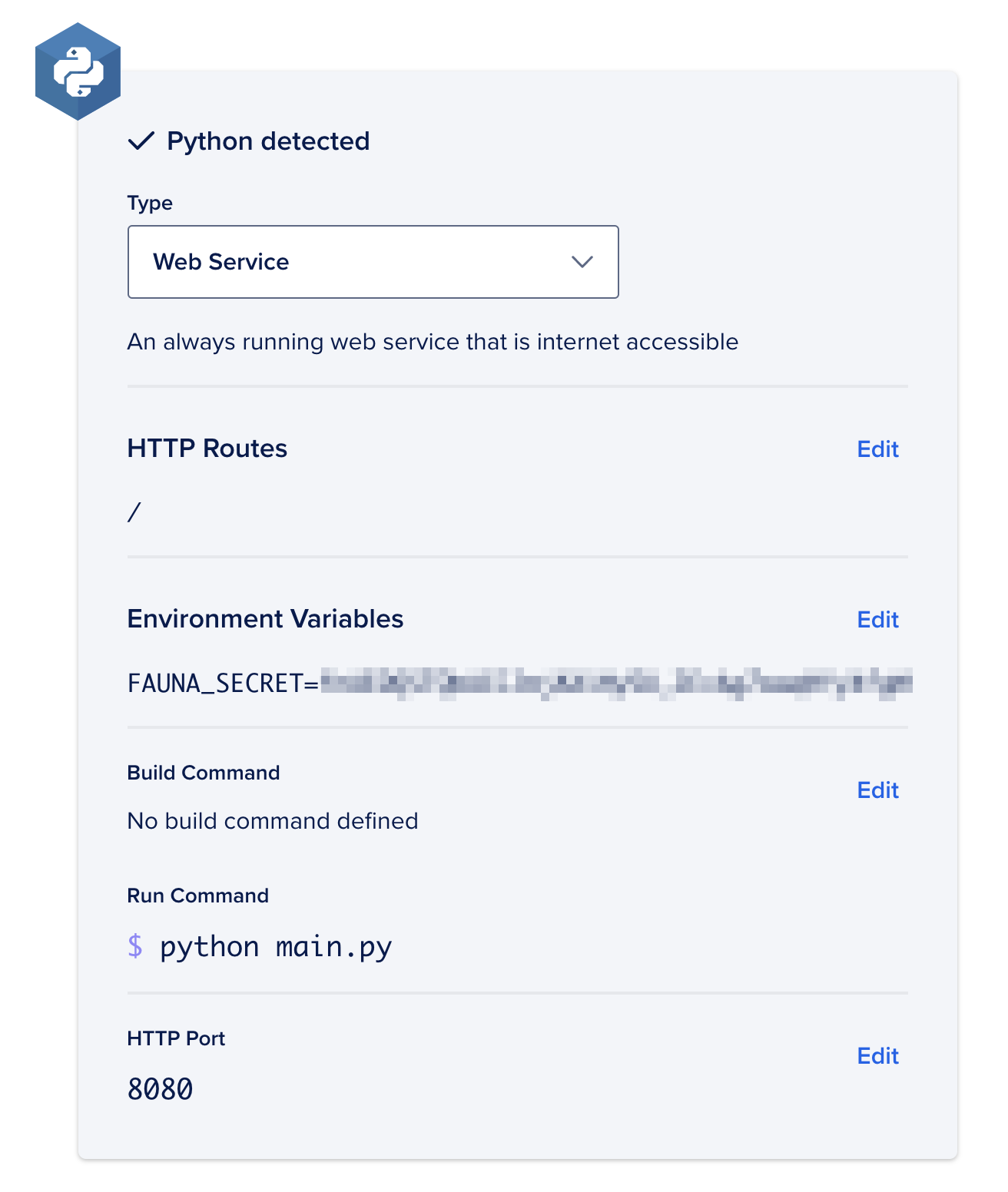
设置下列选项
- 确保 ** Type 是** Web Service** . * ** 使用您的服务器秘密创建一个
FAUNA_SECRET环境变量. * 将** Run 命令设置为python main.py. * ** 将 ** HTTP 端口设置为80。
接下来,输入您的应用程序的名称,然后选择部署区域:
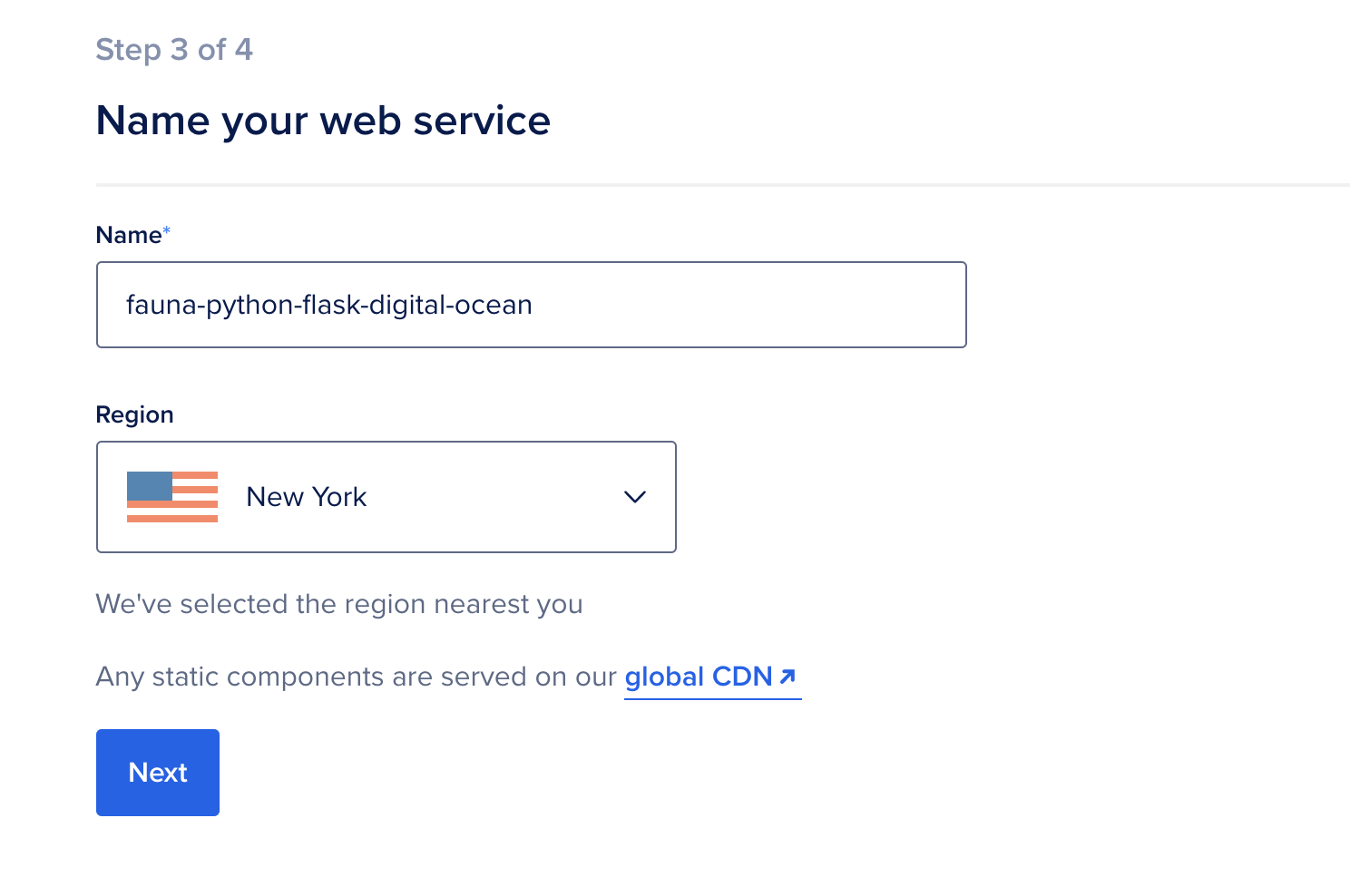
接下来,选择 Basic 计划和** Basic Size** ,每月费用为5美元:
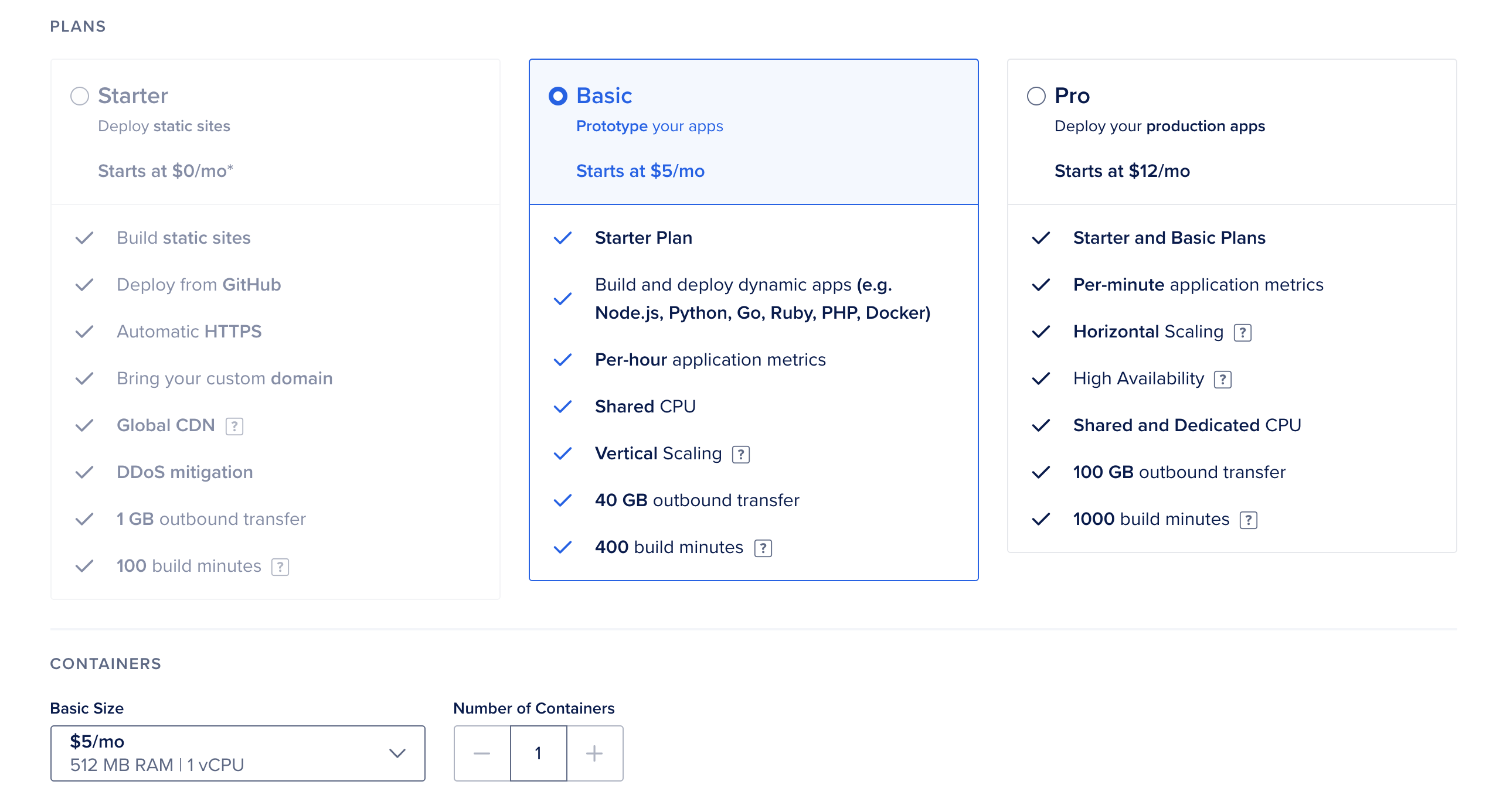
之后,向下滚动,然后单击 启动您的应用程序 。
一旦您完成配置应用程序,将创建一个容器并与您的应用程序一起部署,第一次初始化需要几分钟,但随后的部署将更快。
在应用程序的仪表板中,您将看到一个绿色标记,表示部署过程已成功完成:
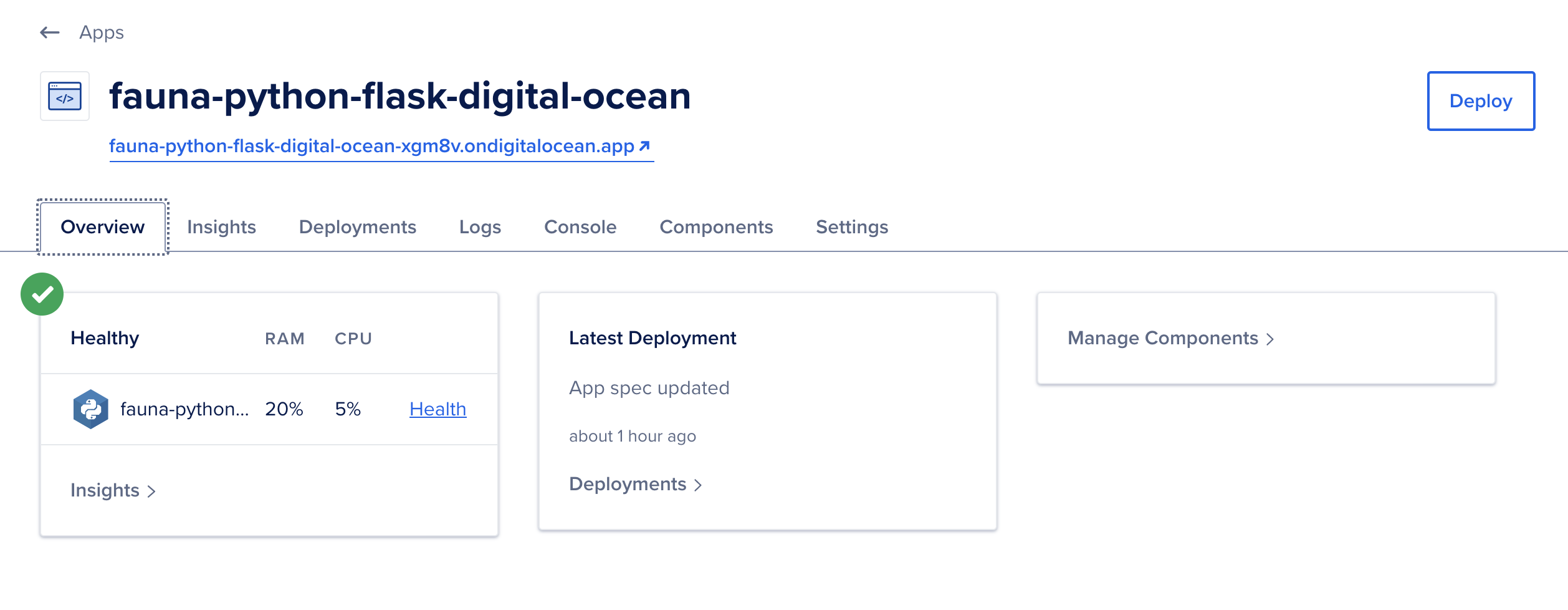
您现在将能够执行HTTP请求到提供的应用域,在终端中执行以下命令,以实际的应用名称代替your_app_name,以返回sammy用户的新秘密:
1curl -i -d '{"user":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST https://your_app_name.ondigitalocean.app/login
您将收到类似于以下的答案:
1HTTP/1.0 200 OK
2Content-Type: application/json
3Content-Length: 70
4Server: Werkzeug/1.0.1 Python/3.9.2
5Date: Thu, 04 Mar 2021 01:01:19 GMT
6
7{
8 "secret": "fnAADbhO3jACEEQNBIxMIAOOIlDxujk-VJShnnhkZkCUPKIskdjfh"
9}
您的应用程序现在在数字海洋上运行。
结论
在本教程中,您创建了使用 Fauna 作为数据层的 Python REST API,并将其部署到 DigitalOcean App Platform。
要继续学习关于动物的知识,并深入FQL,请查看《动物文档》(https://docs.fauna.com/fauna/current/)。