简介
机器学习 是计算机科学、人工智能和统计学的一个研究领域。机器学习的重点是训练算法,以便从数据中学习模式并进行预测。机器学习尤其有价值,因为它能让我们利用计算机自动完成决策过程。
你会发现机器学习的应用无处不在。Netflix 和亚马逊利用机器学习进行新产品推荐。银行利用机器学习检测信用卡交易中的欺诈活动,医疗保健公司也开始利用机器学习监控、评估和诊断病人。
在本教程中,您将使用 Python 机器学习工具 Scikit-learn,在 Python 中实现一个简单的机器学习算法。使用乳腺癌肿瘤信息数据库,您将使用 Naive Bayes (NB) 分类器预测肿瘤是恶性还是良性。
本教程结束时,您将知道如何用 Python 构建自己的机器学习模型。
先决条件
要完成本教程,您需要
- 在计算机上设置 Python 3 和本地编程环境。您可以按照 适合您的操作系统的安装和设置指南 进行配置。
- 如果你是 Python 的新手,可以浏览 How to Code in Python 3 来熟悉这门语言。
- 在本教程的虚拟环境中安装 Jupyter Notebook。 Jupyter Notebook 在运行机器学习实验时非常有用。您可以运行简短的代码块并快速查看结果,从而轻松测试和调试您的代码。
步骤 1 - 导入 Scikit-learn
首先,让我们安装 Python 模块 Scikit-learn,它是 Python 机器学习库中最好、文档最多的模块之一。
为了开始我们的编码项目,让我们激活 Python 3 编程环境。确保您已进入环境所在的目录,然后运行以下命令:
1. my_env/bin/activate
激活编程环境后,检查是否已安装 Sckikit-learn 模块:
1python -c "import sklearn"
如果已安装 sklearn,该命令将无差错完成。如果未安装,则会出现以下错误信息:
1[secondary_label Output]
2Traceback (most recent call last): File "<string>", line 1, in <module> ImportError: No module named 'sklearn'
错误信息表明 sklearn 未安装,因此请使用 pip 下载该库:
1pip install scikit-learn[alldeps]
安装完成后,启动 Jupyter Notebook:
1jupyter notebook
在 Jupyter 中新建一个名为 ML Tutorial 的 Python Notebook。在笔记本的第一个单元中,导入 sklearn模块:
1[label ML Tutorial]
2import sklearn
您的笔记本应该如下图所示:

现在我们已经在笔记本中导入了 sklearn,可以开始处理机器学习模型的数据集了。
第 2 步 - 导入 Scikit-learn 的数据集
本教程将使用的数据集是乳腺癌威斯康星诊断数据库。该数据集包含乳腺癌肿瘤的各种信息,以及恶性 或** 良性** 的分类标签。该数据集包含 569 个肿瘤的 569 个_实例_(或数据),以及 30 个_属性_(或特征)的信息,如肿瘤半径、纹理、平滑度和面积。
利用这个数据集,我们将建立一个机器学习模型,利用肿瘤信息来预测肿瘤是恶性还是良性。
Scikit-learn 安装时附带了各种数据集,我们可以将其加载到 Python 中,我们想要的数据集也包括在内。导入并加载数据集:
1[label ML Tutorial]
2...
3from sklearn.datasets import load_breast_cancer
4
5# Load dataset
6data = load_breast_cancer()
数据"变量 表示一个 Python 对象,其工作方式类似于字典。需要考虑的重要字典键是分类标签名称 (target_names)、实际标签 (target)、属性/特征名称 (feature_names),以及属性 (data)。
属性是任何分类器的重要组成部分。属性捕捉了数据性质的重要特征。鉴于我们要预测的标签(恶性肿瘤与良性肿瘤),可能有用的属性包括肿瘤的大小、半径和纹理。
为每组重要信息创建新变量并分配数据:
1[label ML Tutorial]
2...
3# Organize our data
4label_names = data['target_names']
5labels = data['target']
6feature_names = data['feature_names']
7features = data['data']
现在,每组信息都有 lists。为了更好地了解我们的数据集,让我们通过打印类标签、第一个数据实例的标签、特征名称和第一个数据实例的特征值来看看我们的数据:
1[label ML Tutorial]
2...
3# Look at our data
4print(label_names)
5print(labels[0])
6print(feature_names[0])
7print(features[0])
运行代码后,您将看到以下结果:
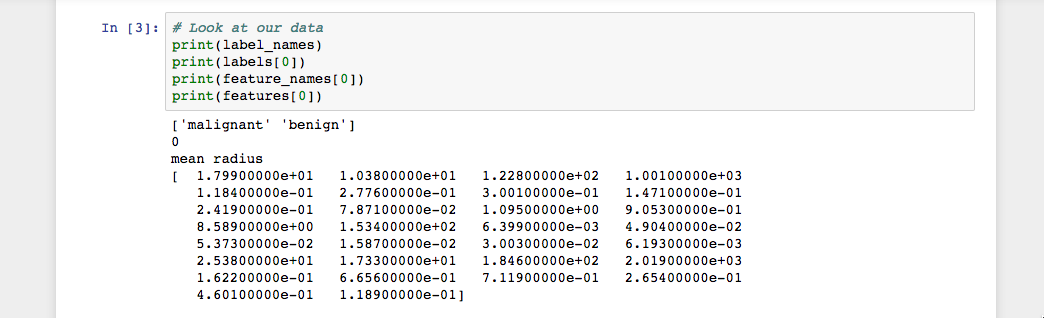
如图所示,我们的类名是恶性 和** 良性** ,然后将其映射为0和1的二进制值,其中0代表恶性肿瘤,1代表良性肿瘤。因此,我们的第一个数据实例是一个平均半径为 1.79900000e+01的恶性肿瘤。
现在我们已经加载了数据,可以使用数据构建机器学习分类器。
第 3 步 - 将数据整理成集
要评估分类器的性能如何,应始终在未见过的数据上测试模型。因此,在建立模型之前,应将数据分成两部分:训练集和测试集。
在开发阶段,您使用训练集来训练和评估模型。然后使用训练好的模型对未见过的测试集进行预测。通过这种方法,您可以了解模型的性能和鲁棒性。
幸运的是,"sklearn "有一个名为 "train_test_split() "的函数,可以将数据分成这些集。导入该函数,然后用它来分割数据:
1[label ML Tutorial]
2...
3from sklearn.model_selection import train_test_split
4
5# Split our data
6train, test, train_labels, test_labels = train_test_split(features,
7 labels,
8 test_size=0.33,
9 random_state=42)
该函数使用 test_size 参数随机分割数据。在这个例子中,我们现在有一个测试集(test),占原始数据集的 33%。剩下的数据(train)则构成训练数据。我们还有训练/测试变量各自的标签,即train_labels和test_labels。
现在我们可以开始训练第一个模型了。
步骤 4 - 建立和评估模型
机器学习有很多模型,每种模型都有自己的优缺点。 在本教程中,我们将重点介绍一种通常在二元分类任务中表现出色的简单算法,即Naive Bayes (NB)。
首先,导入 GaussianNB 模块。然后用GaussianNB()函数初始化模型,再用gnb.fit()根据数据拟合训练模型:
1[label ML Tutorial]
2...
3from sklearn.naive_bayes import GaussianNB
4
5# Initialize our classifier
6gnb = GaussianNB()
7
8# Train our classifier
9model = gnb.fit(train, train_labels)
训练模型后,我们可以使用训练好的模型对测试集进行预测,我们使用 predict() 函数来完成这项工作。predict() "函数为测试集中的每个数据实例返回一个预测数组。然后,我们可以打印预测结果,以了解模型的判断结果。
使用predict()函数和test集,并打印结果:
1[label ML Tutorial]
2...
3# Make predictions
4preds = gnb.predict(test)
5print(preds)
运行代码,您将看到以下结果:
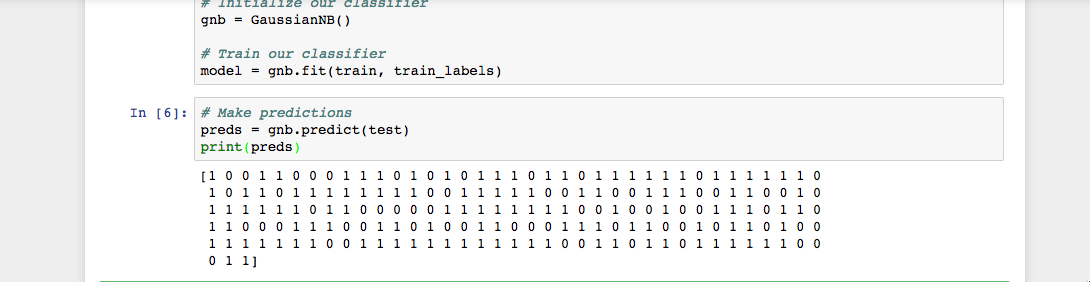
正如您在 Jupyter Notebook 输出中看到的,"predict() "函数返回了一个由 "0 "和 "1 "组成的数组,代表我们对肿瘤类别(恶性与良性)的预测值。
现在我们有了预测结果,让我们来评估一下分类器的性能如何。
步骤 5 - 评估模型的准确性
使用真实类标签数组,我们可以通过比较两个数组("test_labels "与 "preds")来评估模型预测值的准确性。我们将使用 sklearn 函数 accuracy_score() 来确定机器学习分类器的准确性。
1[label ML Tutorial]
2...
3from sklearn.metrics import accuracy_score
4
5# Evaluate accuracy
6print(accuracy_score(test_labels, preds))
您将看到以下结果:

正如您在输出结果中看到的,NB 分类器的准确率为 94.15%。这意味着分类器有 94.15% 的时间能够正确预测肿瘤是恶性还是良性。这些结果表明,我们的 30 个属性特征集是肿瘤类别的良好指标。
您已经成功构建了第一个机器学习分类器。让我们重新组织代码,将所有 "导入 "语句放在笔记本或脚本的顶部。代码的最终版本应该是这样的:
1[label ML Tutorial]
2from sklearn.datasets import load_breast_cancer
3from sklearn.model_selection import train_test_split
4from sklearn.naive_bayes import GaussianNB
5from sklearn.metrics import accuracy_score
6
7# Load dataset
8data = load_breast_cancer()
9
10# Organize our data
11label_names = data['target_names']
12labels = data['target']
13feature_names = data['feature_names']
14features = data['data']
15
16# Look at our data
17print(label_names)
18print('Class label = ', labels[0])
19print(feature_names)
20print(features[0])
21
22# Split our data
23train, test, train_labels, test_labels = train_test_split(features,
24 labels,
25 test_size=0.33,
26 random_state=42)
27
28# Initialize our classifier
29gnb = GaussianNB()
30
31# Train our classifier
32model = gnb.fit(train, train_labels)
33
34# Make predictions
35preds = gnb.predict(test)
36print(preds)
37
38# Evaluate accuracy
39print(accuracy_score(test_labels, preds))
现在,您可以继续处理您的代码,看看能否让分类器表现得更好。你可以尝试使用不同的特征子集,甚至尝试完全不同的算法。请访问 Scikit-learn 网站 了解更多机器学习的想法。
结论
在本教程中,您学会了如何用 Python 构建机器学习分类器。现在,您可以使用 Scikit-learn 在 Python 中加载数据、组织数据、训练、预测和评估机器学习分类器。本教程中的步骤将有助于您在 Python 中处理自己的数据。