作者选择了 Girls Who 代码作为 写给捐款计划的一部分,以获得捐款。
介绍
Keras是一个神经网络API,是写在Python上。它运行在顶部 TensorFlow, CNTK,或 Theano.它是一个高层次的抽象这些深度学习框架,因此使实验更快,更容易。Keras是模块化的,这意味着实现是无缝的,因为开发人员可以通过添加模块快速扩展模型。
TensorFlow是一个开源软件库,用于机器学习,它可以高效地使用涉及数组的计算;因此,它是您将在本教程中构建的模型的绝佳选择。
在这个教程中,你会建立一个深入的学习模式,预测员工离开公司的可能性. 留住最好的雇员是大多数组织的一个重要因素。 为了构建你的模型,你会使用[这个在Kaggle(英语:Kaggle (LINK0))中可用的数据集],该数据集具有测量公司员工满意度的特征. 要创建这个模型,您会使用 Keras [继 (https://keras.io/layers/core/) 层来为模型构建不同的层.
前提条件
在您开始本教程之前,您将需要以下内容:
- 机器上的Anaconda开发环境。
- AJupyter Notebook安装。 Anaconda将在安装期间为您安装了Jupyter Notebook. 您也可以在此学习如何导航和使用 Jupyter Notebook 的指南。
- 熟悉机器学习。 .
第1步:数据预处理
Data Pre-processing 是必要的,以一种深度学习模型可以接受的方式准备你的数据. 如果你的数据中有 _categorical 变量,你必须将它们转换为数字,因为算法只接受数字。
在您开始数据预处理之前,您将激活您的环境,并确保您在您的机器上安装了所有必要的包。 使用conda来安装keras和tensorflow是有利的,因为它将处理这些包的任何必要依赖的安装,并确保它们与keras和tensorflow兼容。
进入您在先决条件教程中创建的环境:
1conda activate my_env
运行以下命令来安装keras和tensorflow:
1conda install tensorflow keras
现在,打开Jupyter笔记本开始。Jupyter笔记本通过在您的终端键入以下命令打开:
1jupyter notebook
<$>[注] 注: 如果您正在从远程服务器工作,您将需要使用SSH隧道来访问笔记本。 请访问 步骤 2的先决性教程,以详细了解有关设置SSH隧道的说明。 您可以使用本地机器的以下命令启动您的SSH隧道:
1ssh -L 8888:localhost:8888 your_username@your_server_ip
美元
在访问 Jupyter 笔记本后,单击 anaconda3 文件,然后在屏幕顶部单击** 新** ,然后选择** Python 3** 来加载新笔记本。
现在,您将导入项目所需的模块,然后在笔记本单元格中加载数据集. 您将加载pandas模块来操纵您的数据,并numpy来将数据转换为numpy数组。
将以下代码插入笔记本单元格,然后单击 Run :
1import pandas as pd
2import numpy as np
3df = pd.read_csv("https://raw.githubusercontent.com/mwitiderrick/kerasDO/master/HR_comma_sep.csv")
您已导入numpy和pandas,然后使用pandas在模型数据集中加载。
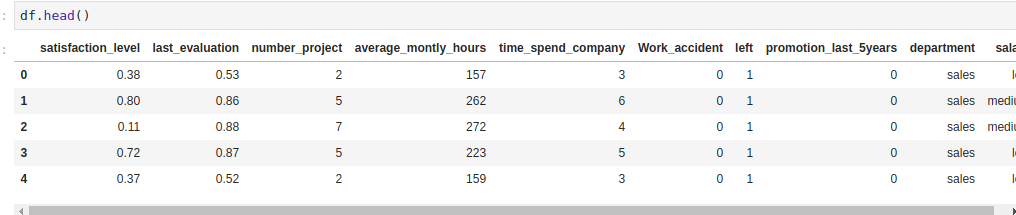
您可以通过head()查看您正在使用的数据集,这是一个从pandas中提供的有用的函数,允许您查看数据框架的前五个记录。
1df.head()
您现在将继续将分类列转换为数字。您通过将它们转换为 dummy 变量. Dummy 变量通常是指有或没有分类特征的变量和零。
<美元 > [注] 注: 假变量陷阱是指两个或两个以上变量高度相关的情况。 这导致你的模特表现不佳。 因此,你放下一个假变量 永远与N-1假变量在一起。 任意一个假变量都可以被丢弃,因为只要你保留N-1假变量,就不会有偏好. 这方面的一个例子是,如果您有一个打开/关闭开关。 当创建假变量时,将获得两栏:一栏为 " 上 " 一栏和一栏为 " 出 " 一栏。 你可以放下一列 因为如果开关没开,那就关了 < $ > (美元)
将此代码插入下一个笔记本单元格并执行:
1feats = ['department','salary']
2df_final = pd.get_dummies(df,columns=feats,drop_first=True)
feats = ['department','salary'] 定义了您要创建模糊变量的两个列。 pd.get_dummies(df,columns=feats,drop_first=True) 将生成您的员工保留模型所需的数值变量。
您已在数据集中加载并将工资和部门列转换为keras深度学习模型可以接受的格式。
步骤2 - 将您的培训和测试数据集分开
您将使用 scikit-learn将数据集划分为培训和测试组,因此您可以使用部分员工数据来训练模型,并使用部分数据来测试其性能。
重要的是要在数据集中实现这种分裂,以便您构建的模型在训练过程中没有访问测试数据,这确保模型只从训练数据中学习,然后您可以通过测试数据来测试其性能。
您将开始从scikit-learn包中导入train_test_split模块,这是提供分割功能的模块。 将此代码插入下一个笔记本单元格并运行:
1from sklearn.model_selection import train_test_split
随着train_test_split模块的导入,您将使用数据集中的左列来预测员工是否会离开公司,因此,重要的是您的深度学习模型不要与此列接触。
1X = df_final.drop(['left'],axis=1).values
2y = df_final['left'].values
因此,您使用 numpy 将数据转换为使用 .values 属性的 numpy 数组。
您现在已经准备好将数据集转换为测试和培训集,您将使用70%的数据用于训练和30%用于测试,训练比比比超过测试比,因为您需要使用大多数数据用于训练过程。
现在将此代码添加到下一个单元格,然后运行以将您的训练和测试数据分割到指定的比例:
1X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)

您现在已经将数据转换为Keras预计的类型(‘numpy’数组),并且您的数据被分成训练和测试集,您将在教程中晚些时候将这些数据传递给Keras模型。
第3步:转换数据
在构建深层学习模型时,通常的良好做法是_缩放_您的数据集,以便提高计算效率. 在此步骤中, 您将使用 标准比例尺 来缩放数据 ; 这将确保您的数据集值的平均值为 0, 单位变量 。 这将转换数据集,使其正常分布。 将使用skikt-learn'标准比例尺'来缩放相同范围内的特性。 这将改变数值的平均值为0,标准偏差为1。 这个步骤很重要,因为你正在比较那些有不同测量的特性;所以在机器学习中通常需要这个步骤.
若要扩展训练集和测试集,请将此代码添加到笔记本单元格并运行:
1from sklearn.preprocessing import StandardScaler
2sc = StandardScaler()
3X_train = sc.fit_transform(X_train)
4X_test = sc.transform(X_test)
在这里,您开始通过导入StandardScaler并调用一个实例,然后使用其fit_transform方法来扩展培训和测试集。
您已将所有数据集功能扩展到相同范围内,您可以在下一步开始构建人工神经网络。
第4步:构建人工神经网络
现在你将使用keras来构建深度学习模型。 要做到这一点,你将导入keras,该模型将默认使用tensorflow作为后端。 从keras开始,你将导入Sequential模块来初始化人工神经网络。
在构建深度学习模型时,您通常会指定三个层类型:
- 联合国 _输入层_是您会传递到您数据集的特性的层. 此图层没有进行计算 。 它的作用是将特征传递到隐藏的地层.
- 联合国 _隐藏地层_通常是输入地层和输出地层之间的地层——并且可以有多个. 这些层进行计算,并将信息传递到输出层.
- 联合国 _输出层_代表您神经网络的层,在训练了您的模型后会给出结果. 它负责生产产出变量。 .
要导入Keras、Sequential和Dense模块,请在笔记本单元格中运行以下代码:
1import keras
2from keras.models import Sequential
3from keras.layers import Dense
您将使用序列来初始化一个线性层堆栈. 由于这是一个 _classification 问题,您将创建一个分类变量。 一个 _classification 问题是您已标记数据并希望根据标记数据做出一些预测的任务。
1classifier = Sequential()
您已使用序列来初始化分类器。
您现在可以开始将层添加到您的网络中,然后在下一个单元格中运行此代码:
1classifier.add(Dense(9, kernel_initializer = "uniform",activation = "relu", input_dim=18))
您可以在分类器上使用 .add() 函数添加层,并指定一些参数:
- 联合国 第一个参数是您的网络应该拥有的节点数 。 不同节点之间的连接是构成神经网络的是什么. 确定节点数的策略之一是取出输入层和输出层中节点的平均值.
- 联合国 第二个参数是
内核_初始化器。 当你适应了深层的学习模型时, 权重将被初始化为接近于零, 而不是零。 要达到这个目的,您使用统一分布初始化器。 `内核-初始化'是初始化权重的函数。 - 联合国 第三个参数是 " 激活 " 功能。 你的深层学习模式将会通过这个功能学习. 通常有线性和非线性活化功能. 您使用 ['relu' (https://keras.io/activations/]] 活化函数, 因为它很好地概括了您的数据 。 线性函数对此类问题不利,因为它们会形成直线.
- 联合国 最后一个参数是`输入-dim',它代表了您数据集中的特性数量。 .
现在你会添加输出层,它会给你预测:
1classifier.add(Dense(1, kernel_initializer = "uniform",activation = "sigmoid"))
输出层采用以下参数:
- 联合国 输出节点数. 你期望得到一个产出: 如果员工离开公司。 因此您指定一个输出节点 。
- 对于
内核-初始化器,您使用[sigmoid](https://keras.io/activations/)活化功能,以便获得雇员离开的概率。 如果您涉及两个以上类别,您将使用[softmax' (https://keras.io/activations/)活化函数,这是sigmoid'活化函数的一个变体。 .
接下来,你将应用一个 gradient descent 到神经网络. 这是一个 optimization 策略,在训练过程中减少错误。
梯度下降的目的是达到错误最少的点,这样做是通过找到成本函数在最低点的位置,这被称为本地最低点。在梯度下降中,你会区分,以便在特定点找到斜点,并找出斜点是否为负或积极 - 你正在下降到成本函数的最低点。
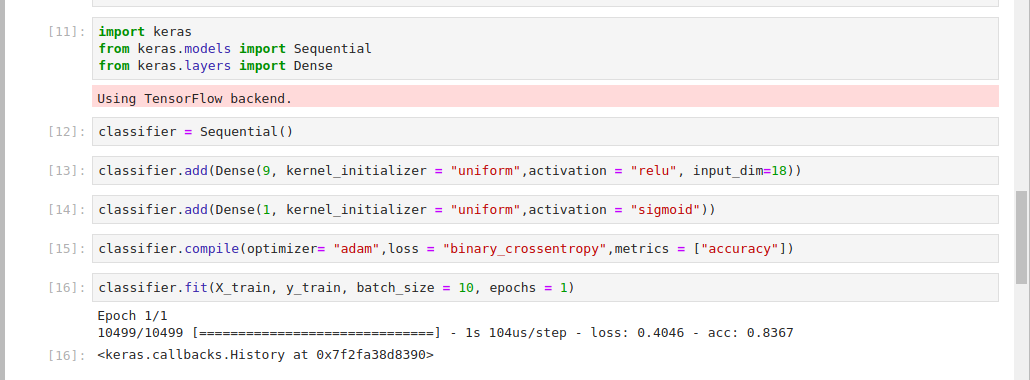
将此代码添加到您的笔记本细胞并运行它:
1classifier.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])
应用梯度下降是通过编译函数进行的,该函数采用以下参数:
优化器是梯度降级。 *损失是您在梯度降级中使用的函数. 由于这是一个二进制分类问题,您使用二进制是损失函数。
您已准备好将分类器匹配到您的数据集中。Keras 通过 .fit() 方法使此成为可能。 要做到这一点,请将以下代码插入您的笔记本并运行,以便将模型匹配到您的数据集:
1classifier.fit(X_train, y_train, batch_size = 10, epochs = 1)

.fit() 方法需要几个参数:
- 第一个参数是与功能相关的训练套件。 * 第二个参数是您正在做预测的列。 *
batch_size表示每个训练周期将通过神经网络的样本数量。 *epochs表示数据集将通过神经网络传输的次数。
您已经创建了深度学习模型,编译了它,并将其合并到您的数据集中,您已经准备好使用深度学习模型进行一些预测。
步骤5 — 在测试集中运行预测
要开始预测,您将使用您创建的模型中的测试数据集,Keras 允许您使用 .predict() 函数进行预测。
在下一个笔记本单元格中插入以下代码,开始预测:
1y_pred = classifier.predict(X_test)
由于你已经训练了分类器与培训套件,这个代码将使用从培训过程的学习,在测试套件上做出预测。这将给你一个员工离开的概率。
在笔记本单元格中输入以下代码行以设置此门槛:
1y_pred = (y_pred > 0.5)
您使用预测方法创建了预测,并设置了确定员工是否有可能离开的门槛。
第6步:检查混淆矩阵
在此步骤中,您将使用 confusion matrix 来检查正确和错误预测的数目。 一个混淆矩阵,也称为错误矩阵,是一个方块矩阵,报告分类器的真实正数(tp),假正数(fp),真实负数(tn)和假负数(fn)的数目。
- 一个 ** 真正的正面 是模型正确预测正面的类的结果(也称为敏感性或回忆)。 * ** 一个** 真正的负面** 是模型正确预测负面的类的结果。
要做到这一点,你会使用scikit-learn提供的混淆矩阵。
将此代码插入下一个笔记本单元格以导入scikit-learn混淆矩阵:
1from sklearn.metrics import confusion_matrix
2cm = confusion_matrix(y_test, y_pred)
3cm
混淆矩阵输出意味着您的深度学习模型做出了) / 4500`。您数据集中的观测总数为4500个,这为您提供了81.7%的准确性,这是一个非常好的准确度,因为您可以从您的模型中获得至少81%的正确预测。
1[secondary_label Output]
2array([[3305, 106],
3 [ 714, 375]])
您使用混淆矩阵评估了您的模型,接下来,您将使用您开发的模型进行单个预测。
第7步:做一个单一的预测
在此步骤中,您将根据您的模型对一个员工的细节进行单个预测,您将通过预测一个员工离开公司的概率来实现这一目标,您将该员工的特性传递到预测方法中。
要将员工的功能传输,请在单元格中运行下列代码:
1new_pred = classifier.predict(sc.transform(np.array([[0.26,0.7 ,3., 238., 6., 0.,0.,0.,0., 0.,0.,0.,0.,0.,1.,0., 0.,1.]])))
这些特征代表了单个员工的特征,正如步骤 1 中的数据集所示,这些特征代表了:满意度水平、最后的评估、项目数量等等。
添加以下代码为50%的门槛:
1new_pred = (new_pred > 0.5)
2new_pred
这个门槛表明,如果概率高于50%,员工将离开公司。
您可以在您的输出中看到员工不会离开公司:
1[secondary_label Output]
2array([[False]])
您可能决定为您的模型设置较低或较高门槛,例如,您可以将门槛设置为 60%:
1new_pred = (new_pred > 0.6)
2new_pred
这个新的门槛仍然表明员工不会离开公司:
1[secondary_label Output]
2array([[False]])
在此步骤中,您已经看到如何根据单个员工的特点进行单个预测,在下一步,您将致力于提高您的模型的准确性。
第8步:改进模型精度
如果你多次训练你的模型,你会继续获得不同的结果。每个训练的准确性都有很高的差异性。为了解决这个问题,你会使用 K-fold cross-validation. 通常,K 设置为 10. 在这种技术中,模型在前 9 个折叠上进行训练,并在最后 9 个折叠上进行测试。
「Keras」可讓您透過「KerasClassifier」包裝實施 K-fold 交叉驗證。 此包裝源自「scikit-learn」交叉驗證。 您將從輸入「cross_val_score」交叉驗證功能和「KerasClassifier」開始。 要做到這一點,請在筆記本細胞中插入並執行以下代碼:
1from keras.wrappers.scikit_learn import KerasClassifier
2from sklearn.model_selection import cross_val_score
要创建您将转移到KerasClassifier的函数,请将此代码添加到下一个单元格:
1def make_classifier():
2 classifier = Sequential()
3 classifier.add(Dense(9, kernel_initializer = "uniform", activation = "relu", input_dim=18))
4 classifier.add(Dense(1, kernel_initializer = "uniform", activation = "sigmoid"))
5 classifier.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])
6 return classifier
在这里,你会创建一个函数,将其转移到)初始化分类器,然后使用Dense`添加输入和输出层。
要将您所构建的函数传输到KerasClassifier,请在笔记本中添加以下代码行:
1classifier = KerasClassifier(build_fn = make_classifier, batch_size=10, nb_epoch=1)
KerasClassifier有三个论点:
build_fn:具有神经网络设计的函数 *batch_size:每个迭代中通过网络传输的样本数 *nb_epoch:网络将运行的时代数
接下来,您使用 Scikit-learn 的 cross_val_score 应用交叉验证,将以下代码添加到笔记本细胞并运行:
1accuracies = cross_val_score(estimator = classifier,X = X_train,y = y_train,cv = 10,n_jobs = -1)
此函数将为您提供十个精度,因为您已将折数数指定为10个,因此,您将其分配给精度变量,然后使用它来计算平均精度。
estimator:您刚刚定义的分类器 *X:培训集功能 *y:在训练集中预测的值 *cv:折叠数 *n_jobs:使用的CPU数量(指定为 -1将利用所有可用的CPU)
现在你已经应用了交叉验证,你可以计算准确度的平均值和差异性. 要做到这一点,请在笔记本中插入以下代码:
1mean = accuracies.mean()
2mean
在您的输出中,您将看到平均值为 83%:
1[secondary_label Output]
20.8343617910685696
要计算精度的差异性,请将此代码添加到下一个笔记本单元格:
1variance = accuracies.var()
2variance
您可以看到差异为 0.00109. 由于差异非常低,这意味着您的模型表现非常好。
1[secondary_label Output]
20.0010935021002275425
您通过使用 K-Fold 交叉验证来提高您的模型的准确性。
步骤9 - 添加退出规则化来打击过度配套
预测模型容易出现一个被称为 overfitting 的问题. 这是一个场景,该模型会记住训练集中的结果,并且无法对未见的数据进行概括。
在神经网络中, dropout regularization 是通过在你的神经网络中添加一个Dropout层来打击过剩的技术,它有一个率参数,表明在每个迭代中会失效的神经元的数量。失效神经元的过程通常是随机的。
若要添加Dropout层,请在下一个单元格中添加以下代码:
1from keras.layers import Dropout
2
3classifier = Sequential()
4classifier.add(Dense(9, kernel_initializer = "uniform", activation = "relu", input_dim=18))
5classifier.add(Dropout(rate = 0.1))
6classifier.add(Dense(1, kernel_initializer = "uniform", activation = "sigmoid"))
7classifier.compile(optimizer= "adam",loss = "binary_crossentropy",metrics = ["accuracy"])
您已在输入和输出层之间添加了一个Dropout层。设置一个 0.1 的 droppout 率意味着在训练过程中15 个神经元将被关闭,以便分类器不会超过训练套件。
您在这个步骤中使用了一个Dropout层来打击过度配对,接下来,您将通过调整您在创建模型时使用的参数来进一步改进模型。
第10步:超参数调节
_Grid search_是您可以用不同模型参数进行实验的技术,以获得给予您最佳准确性的技术. 该技术通过尝试不同的参数并返回那些给出最佳结果的参数来达到这个目的. 你会用网格搜索 寻找你深层学习模型的最佳参数 这将有助于提高模型的准确性。 scikit-learn'提供GridSearchCV ' 功能,以便实现这一功能。 您现在将开始修改 make_ classifier 函数,以尝试不同的参数.
将此代码添加到笔记本中以修改make_classifier函数,以便您可以测试不同的优化函数:
1from sklearn.model_selection import GridSearchCV
2def make_classifier(optimizer):
3 classifier = Sequential()
4 classifier.add(Dense(9, kernel_initializer = "uniform", activation = "relu", input_dim=18))
5 classifier.add(Dense(1, kernel_initializer = "uniform", activation = "sigmoid"))
6 classifier.compile(optimizer= optimizer,loss = "binary_crossentropy",metrics = ["accuracy"])
7 return classifier
您开始通过导入GridSearchCV。 然后,您对make_classifier函数进行了更改,以便您可以尝试不同的优化器。 您已经初始化了分类器,添加了输入和输出层,然后编译了分类器。
如同步骤 4 中所示,请插入以下代码行来定义分类器:
1classifier = KerasClassifier(build_fn = make_classifier)
您已使用KerasClassifier定义分类器,该分类器通过build_fn参数预期函数。
您现在将继续设置您想要实验的几个参数. 将此代码输入到单元格中并运行:
1params = {
2 'batch_size':[20,35],
3 'epochs':[2,3],
4 'optimizer':['adam','rmsprop']
5}
在这里,您已经添加了不同的批量大小,时代的数量和不同类型的优化功能。
对于像你这样的小数据集,分数大小在 20 到 35 之间是很好的。对于大数据集来说,使用较大的批量大小进行实验很重要。使用低数字来计算时代的数量,可以确保在短时间内获得结果。
现在你将使用你定义的不同参数来搜索使用GridSearchCV函数的最佳参数。
1grid_search = GridSearchCV(estimator=classifier,
2 param_grid=params,
3 scoring="accuracy",
4 cv=2)
网格搜索函数预计下列参数:
估计器:您正在使用的分类器. *param_grid:您要测试的参数组. *分数:您正在使用的指标. *cv:您将测试的折叠数。
接下来,您将这个grid_search匹配到您的培训数据集:
1grid_search = grid_search.fit(X_train,y_train)
您的输出将类似于以下,请等待一段时间才能完成:
1[secondary_label Output]
2Epoch 1/2
35249/5249 [==============================] - 1s 228us/step - loss: 0.5958 - acc: 0.7645
4Epoch 2/2
55249/5249 [==============================] - 0s 82us/step - loss: 0.3962 - acc: 0.8510
6Epoch 1/2
75250/5250 [==============================] - 1s 222us/step - loss: 0.5935 - acc: 0.7596
8Epoch 2/2
95250/5250 [==============================] - 0s 85us/step - loss: 0.4080 - acc: 0.8029
10Epoch 1/2
115249/5249 [==============================] - 1s 214us/step - loss: 0.5929 - acc: 0.7676
12Epoch 2/2
135249/5249 [==============================] - 0s 82us/step - loss: 0.4261 - acc: 0.7864
将以下代码添加到笔记本单元格中,以使用 best_params_ 属性从此搜索中获取最佳参数:
1best_param = grid_search.best_params_
2best_accuracy = grid_search.best_score_
您现在可以用以下代码检查您的模型的最佳参数:
1best_param
您的输出显示,最佳的批量大小为20,最佳的时代数为2,而adam优化器是最适合您的模型:
1[secondary_label Output]
2{'batch_size': 20, 'epochs': 2, 'optimizer': 'adam'}
您可以检查您的模型的最佳精度. 最佳精度数代表您在运行网格搜索后从最佳参数中获得的最高精度:
1best_accuracy
你的输出将是相似的如下:
1[secondary_label Output]
20.8533193637489285
你使用GridSearch来找出分类器的最佳参数,你看到最好的batch_size是20,最好的optimizer是adam的优化器,最好的时代数是2;你也获得了分类器的最佳准确度为85%,你建立了一个员工保留模型,可以预测员工是否留下或离开,准确度高达85%。
结论
在这个教程中,您已经使用 [Keras] (https://keras.io)来构建一个人工神经网络,来预测员工离开公司的可能性. 你将你以前在机器学习中的知识结合起来,利用skit-learn'来实现这一目标。 为了进一步改进你的模型,你可以尝试不同的[活化函数](https://keras.io/activations/)或[优化函数](https://keras.io/optimizers/)与keras'. 也可以用不同的折叠数进行实验,甚至用不同的数据集构建一个模型.
对于机器学习领域的其他教程或使用TensorFlow,您可以尝试构建(https://andsky.com/tech/tutorials/how-to-build-a-neural-network-to-recognize-handwritten-digits-with-tensorflow)或其他DigitalOcean 机器学习教程。