_ 作者选择了 免费和开源基金作为 写给捐款计划的一部分接受捐款。
介绍
网页扫描,也称为网页扫描,使用机器人提取,分析和从网站下载内容和数据。
您可以使用单台机器从几十个网页中提取数据,但如果您需要从数百甚至数千个网页中提取数据,您可能想考虑分配工作量。
在本教程中,您将使用 Puppeteer来扫描 books.toscrape,一个虚构的书店,作为初学者学习网页扫描和开发人员验证他们的扫描技术的安全场所。在写此时,有1000本书在 books.toscrape上,因此你可以扫描1000个网页。然而,在本教程中,您只会扫描第一个400个网页。 为了在短时间内扫描所有这些网页,您将构建和部署一个可扩展的应用程序,其中包含了包含的 Express网页框架和Puppeteer浏览器控制器到一个Kubernetes(https://kubernetes.io)集群。 为了与您的扫描器进行互动,您
当您完成本教程时,您将有一个可扩展的扫描器,可以同时从多个页面提取数据。使用默认设置和三节点集群,例如,在 books.toscrape 上扫描400页需要不到2分钟。
<$>[警告] 警告: 网络扫描的道德和合法性非常复杂,不断发展。它们也根据您的位置,数据的位置和所涉及的网站而有所不同。本教程扫描了一个特殊的网站, books.toscrape.com,明确旨在测试扫描应用程序。
前提条件
要遵循本教程,您将需要一台具有:
- 安装了Docker。 跟踪我们关于 [如何安装和使用 Docker] (https://www.digitalocean.com/community/tutorial_collections/how-to-install-and-use-docker] 的教程以获取指令 。 [Docker's website] (https://docs.docker.com/install/)为macOS和Windows等其他操作系统提供安装指令.
- 联合国 用于存储您 Docker 图像的账户 。
- Kubernetes 1.17+集群,您的连接配置设定为
kubectl默认值。 要创建数字海洋上的Kubernetes集群,请读取我们的Kubernetes Quickstart。 要连接到集群,请读作:[如何连接到数字海洋库伯内特斯集群 (https://www.digitalocean.com/docs/kubernetes/how-to/connect-to-cluster/). - 安装了 " Kubectl " 。 遵循 [此教程在 Kubernetes: a kubectl Cheet Sheet] (https://www.digitalocean.com/community/cheatsheets/getting-started-with-kubernetes-a-kubectl-cheat-sheet ) 启动后安装它 。
- 安装在开发机上的节点。 这个教程在Node.js版本12.18.3和npm版本6.14.6上进行了测试. [遵循本指南在macOS上安装Node.js (https://andsky.com/tech/tutorials/how-to-install-node-js-and-create-a-local-development-environment-on-macos),或[遵循本指南在各种Linux发行版上安装Node.js (https://www.digitalocean.com/community/tutorial_collections/how-to-install-node-js).
- 联合国 如果你使用数字海洋库伯内特,你还需要个人访问托肯。 要创建一个,您可以遵循我们关于如何创建个人访问Token的指南. 在安全的地方保存此标志, 它可以完全访问您的账户 。 .
步骤 1 —分析目标网站
在编写任何代码之前,请在 Web 浏览器中导航到 books.toscrape。
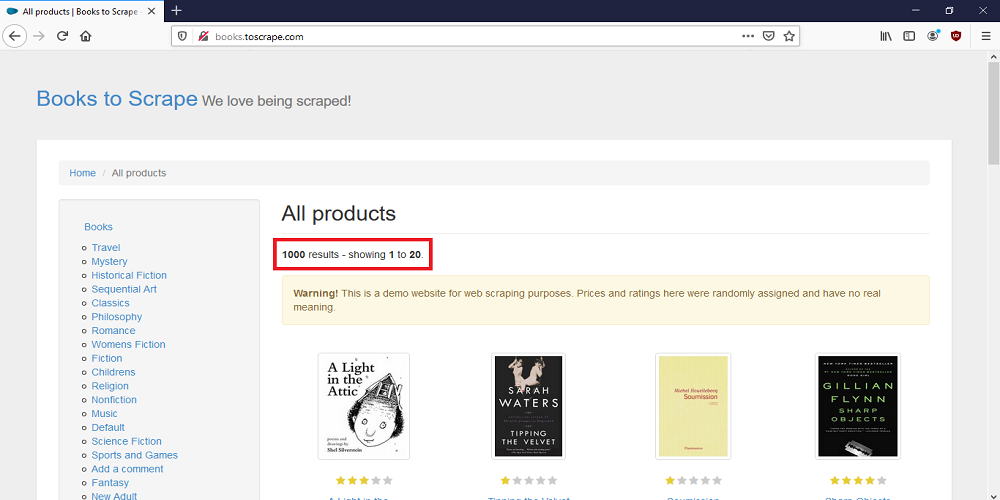
请注意,本网站上有1000本书,但每个页面只显示20本书。
滚到页面的底部。
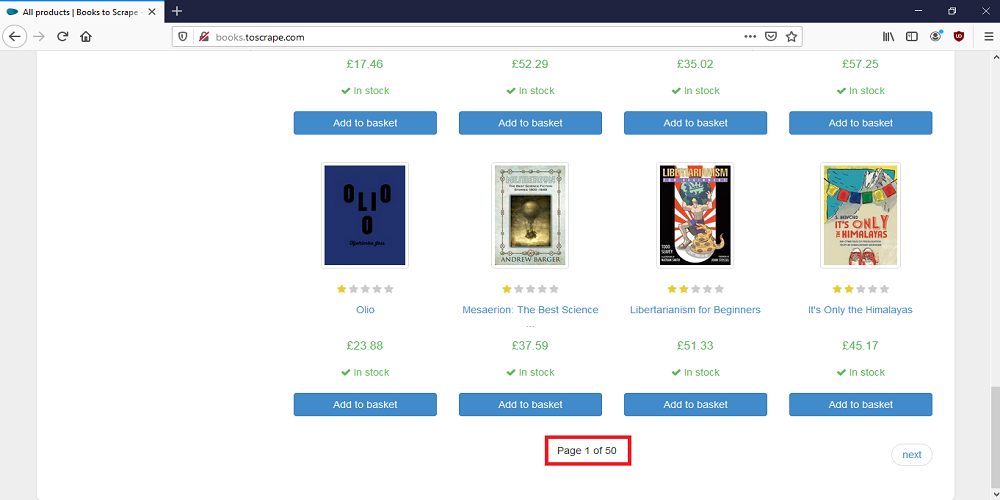
由于每个页面显示了20本书,你只想摘取前400本书,你只会获取每本书显示在前20页的标题,价格,评级和URL。
整个过程不应超过1分钟。
打开您的浏览器的开发工具,检查页面上的第一本书,您将看到以下内容:
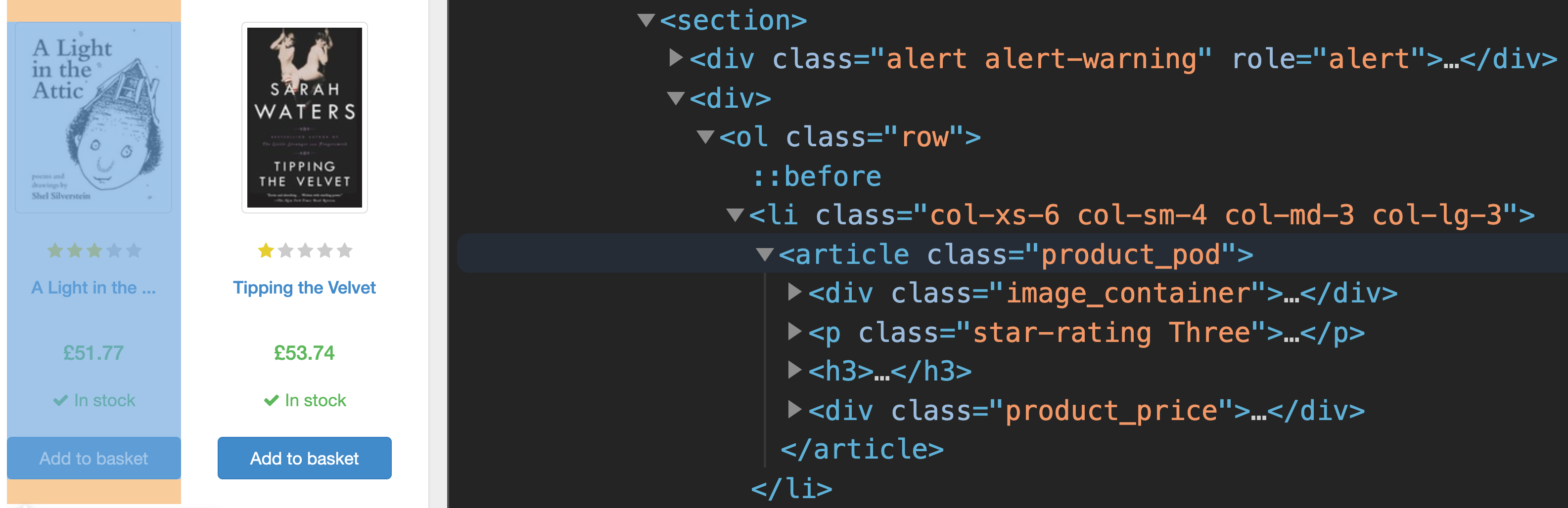
每本书都包含在<section>标签中,每本书都列在其自己的<li>标签下。在每个<li>标签中,有一个具有product_pod等级的<article>标签。
在获取每本书在前20页的元数据并存储后,您将有一个包含400本书的本地数据库。然而,由于本书本身有更详细的信息,您需要使用每个书的元数据中的URL导航400个额外的页面,然后您将获取您想要的缺少的书细节,并将这些数据添加到本地数据库。您要获取的缺少的数据是描述、UPC(通用书代码)、评论数量和本书的可用性。使用单一机器的400页面可以花费超过7分钟,这就是为什么您需要Kubernetes来将工作分割给多个机器。
现在点击主页上的第一本书的链接,这将打开该书的详细信息页面。
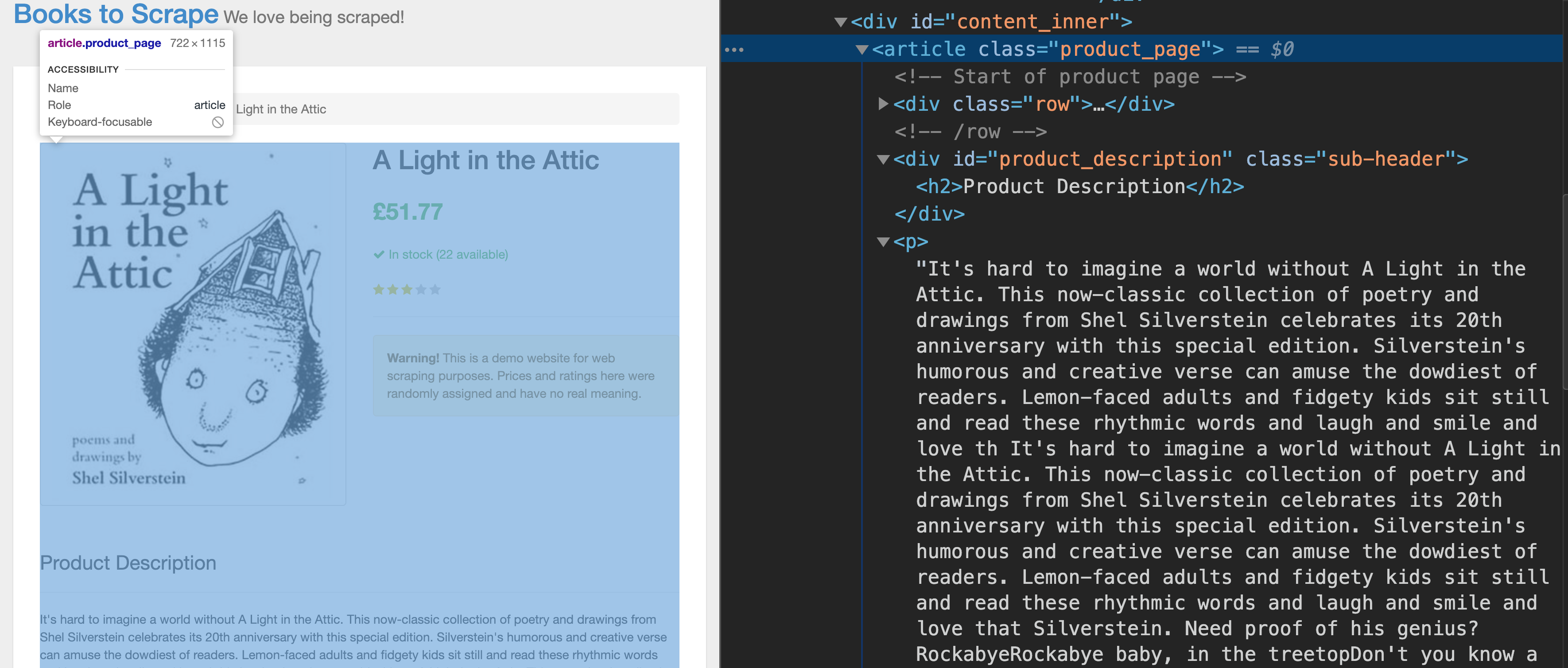
您想要提取的缺少的信息再次位于<文章>标签内,具有等于产品_页的类属性。
要与集群中的扫描仪进行交互,您需要创建一个客户端应用程序,可以将HTTP请求发送到我们的Kubernetes集群中。
在本节中,您已经审查了您的扫描仪将获取哪些信息,以及为什么您需要将这个扫描仪部署到Kubernetes集群中。
步骤 2 —创建项目根目录
在此步骤中,您将创建项目的目录结构,然后为您的客户端和服务器应用程序初始化 Node.js 项目。
打开终端窗口,创建一个名为竞争式webscraper的新目录:
1mkdir concurrent-webscraper
导航到目录:
1cd ./concurrent-webscraper
现在创建三个名为服务器,客户端和k8s的子目录:
1mkdir server client k8s
导航到服务器目录:
1cd ./server
运行 npm 的init命令将创建一个package.json文件,这将帮助您管理您的依赖和元数据。
运行初始化命令:
1npm init
若要接受默认值,请按ENTER按一下所有提示;或者,您可以个性化您的响应. 您可以阅读更多关于 npm 的初始化设置在我们的教程中,如何使用 Node.js 模块与 npm 和 package.json(https://andsky.com/tech/tutorials/how-to-use-node-js-modules-with-npm-and-package-json# step-1-%E2%80%94-creating-a-packagejson-file)。
打开package.json文件并编辑它:
1nano package.json
您需要修改主要属性,在脚本指令中添加一些信息,然后创建一个依赖指令。
用突出的代码取代文件内部的内容:
1[label ./server/package.json]
2{
3 "name": "server",
4 "version": "1.0.0",
5 "description": "",
6 "main": "server.js",
7 "scripts": {
8 "start": "node server.js"
9 },
10 "keywords": [],
11 "author": "",
12 "license": "ISC",
13 "dependencies": {
14 "body-parser": "^1.19.0",
15 "express": "^4.17.1",
16 "puppeteer": "^3.0.0"
17 }
18}
在这里,您更改了主和脚本属性,并编辑了依赖属性,因为服务器应用程序将在Docker容器内运行,您不需要运行npm install命令,该命令通常遵循初始化并自动将每个依赖添加到package.json。
保存并关闭文件。
导航到您的客户目录:
1cd ../client
创建另一个 Node.js 项目:
1npm init
遵循相同的程序来接受默认设置或自定义您的响应。
打开package.json文件并编辑它:
1nano package.json
用突出的代码取代文件内部的内容:
1[label ./client/package.json]
2{
3 "name": "client",
4 "version": "1.0.0",
5 "description": "",
6 "main": "main.js",
7 "scripts": {
8 "start": "node main.js"
9 },
10 "author": "",
11 "license": "ISC"
12}
在这里,您更改了主要和脚本属性。
此时,使用 npm 来安装必要的依赖:
1npm install axios lowdb --save
在这个代码块中,你已经安装了axios和lowdb。axios是基于浏览器和Node.js的HTTP客户端,您将使用此模块向我们的扫描仪中的REST终端发送非同步的HTTP请求,以便与其进行交互;lowdb是Node.js和浏览器的一个小型JSON数据库,您将使用它来存储您的扫描数据。
在此步骤中,您创建了一个项目目录,并为您的应用程序服务器初始化了一个 Node.js 项目,该项目将包含扫描器;然后您对您的客户端应用程序也做了同样的事情,该应用程序将与应用程序服务器交互。
步骤 3 — 构建第一个扫描器文件
在此步骤和步骤4中,您将创建服务器侧的扫描仪。本应用程序将由两个文件组成:puppeteerManager.js和server.js.puppeteerManager.js的文件将创建和管理浏览器会话,而server.js的文件将收到扫描单个或多个网页的请求。反过来,这些请求将呼叫一个在puppeteerManager.js内部的方法,该方法将扫描给定的网页并返回被扫描的数据。
首先,回到服务器目录,创建一个名为puppeteerManager.js的文件。
导航到服务器文件夹:
1cd ../server
使用您喜爱的文本编辑器创建和打开 puppeteerManager.js 文件:
1nano puppeteerManager.js
您的puppeteerManager.js文件将包含一个名为PuppeteerManager的类,这个类将创建和管理一个Puppeteer浏览器实例。
将下列代码添加到您的 puppeteerManager.js 文件中:
1[label puppeteerManager.js]
2class PuppeteerManager {
3 constructor(args) {
4 this.url = args.url
5 this.existingCommands = args.commands
6 this.nrOfPages = args.nrOfPages
7 this.allBooks = [];
8 this.booksDetails = {}
9 }
10}
11module.exports = { PuppeteerManager }
在这个第一个代码块中,您创建了PuppeteerManager类,并添加了 constructor。
url: 此属性将包含一个字符串,这将是您想要扫描的页面的地址。 *命令: 此属性将包含一个数组,为浏览器提供指示。 例如,它将指示浏览器点击按钮或解析特定‘DOM’元素。 每个‘命令’都有以下属性:‘描述’、‘locatorCss’和‘类型’。 `描述’告诉您‘命令’是怎么回事,‘locatorCss’在‘DOM’中找到合适的元素,而‘类型’选择了具体的操作。 * ‘nrOfPages’: 此属性将持有整数,您的应用程序将使用它来确定‘命令’应该重复多少次。 例如, books.toscrape.com
在此代码块中,您还将收到的对象属性分配给构建变量url,现有命令和nrOfPages。然后您创建了两个额外的变量:allBooks和booksDetails。
这个类将有以下方法: runPuppeteer(), executeCommand(), sleep(), getAllBooks(),和 getBooksDetails(). 因为这些方法构成你的扫描应用程序的核心,所以值得一看它们。
编码 runPuppeteer() 方法
PuppeteerManager类内的第一个方法是运行Puppeteer(),这将需要Puppeteer模块并启动您的浏览器实例。
在PuppeteerManager类的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async runPuppeteer() {
4 const puppeteer = require('puppeteer')
5 let commands = []
6 if (this.nrOfPages > 1) {
7 for (let i = 0; i < this.nrOfPages; i++) {
8 if (i < this.nrOfPages - 1) {
9 commands.push(...this.existingCommands)
10 } else {
11 commands.push(this.existingCommands[0])
12 }
13 }
14 } else {
15 commands = this.existingCommands
16 }
17 console.log('commands length', commands.length)
18 }
在这个代码块中,你创建了RunPuppeteer()方法. 首先,你需要puppeteer模块,然后创建了一个变量,以一个名为命令的空数组开头。 使用条件逻辑,你表示,如果要扫描的页数大于一个,则该代码应该穿过nrOfPages,并将每个页面的现有命令添加到命令数组。 然而,当它到达最后一页时,它不会将现有命令数组中的最后一个命令添加到命令数组,因为最后一个命令会点击下一页按钮。
下一步是创建一个浏览器实例。
在您刚刚创建的运行Puppeteer()方法的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async runPuppeteer() {
4 . . .
5
6 const browser = await puppeteer.launch({
7 headless: true,
8 args: [
9 "--no-sandbox",
10 "--disable-gpu",
11 ]
12 });
13 let page = await browser.newPage()
14
15 . . .
16 }
在此代码块中,您使用 内置的 puppeteer.launch() 方法创建了一个浏览器实例。您指定该实例在无头模式下运行。 这是该项目的默认选项,并且是必要的,因为您在 Kubernetes 上运行该应用程序。 下一个两个参数在创建没有图形用户界面的浏览器时是标准的。 最后,您使用 Puppeteer’s ‘browser.newPage()’ 方法创建了一个新的 ‘页面’对象。.launch()’ 方法返回了 ‘Promise’ 的值,这需要 等待’ 关键字。
您现在已经准备好将一些行为添加到您的新页面对象中,包括它将如何导航一个URL。
在运行Puppeteer()方法的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async runPuppeteer() {
4 . . .
5
6 await page.setRequestInterception(true);
7 page.on('request', (request) => {
8 if (['image'].indexOf(request.resourceType()) !== -1) {
9 request.abort();
10 } else {
11 request.continue();
12 }
13 });
14
15 await page.on('console', msg => {
16 for (let i = 0; i < msg._args.length; ++i) {
17 msg._args[i].jsonValue().then(result => {
18 console.log(result);
19 })
20 }
21 });
22
23 await page.goto(this.url);
24
25 . . .
26 }
在这个代码块中,页面对象使用Puppeteer的page.setRequestInterception()方法(https://pptr.dev/# ?product=Puppeteer&version=v5.2.1&show=api-pagesetrequestinterceptionvalue)拦截所有请求,如果请求是加载一个图像,它防止图像加载,从而减少加载网页所需的时间。
现在,将一些更多行为添加到你的页面对象中,这将控制它如何在DOM中找到元素并在它们上运行命令。
在运行Puppeteer()方法的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async runPuppeteer() {
4 . . .
5
6 let timeout = 6000
7 let commandIndex = 0
8 while (commandIndex < commands.length) {
9 try {
10 console.log(`command ${(commandIndex + 1)}/${commands.length}`)
11 let frames = page.frames()
12 await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
13 await this.executeCommand(frames[0], commands[commandIndex])
14 await this.sleep(1000)
15 } catch (error) {
16 console.log(error)
17 break
18 }
19 commandIndex++
20 }
21 console.log('done')
22 await browser.close()
23 }
在这个代码块中,你创建了两个变量,‘timeout’和‘commandIndex’. 第一个变量将限制代码在网页上等待一个元素的时间,第二个变量会控制你如何通过‘命令’数组。
在而循环中,代码通过命令数组中的每个命令进行。 首先,您正在使用page.frames()方法(https://pptr.dev/# ?product=Puppeteer&version=v5.2.1&show=api-pageframes)创建页面附带的所有框架的数组。 它会搜索页面的框架对象中的DOM元素,使用frame.waitForSelector()方法(https://pptr.dev/# ?product=Puppeteer&version=v5.2.1&show=api-framewaitforselectorselector-options)和locatorCss属性。 如果找到一个元素,它会调用executeCommand()方法,并将框架和命令作为参数。 执行命令返回后,它会调用sleep()方法,使代码在执行下一个命令之前等待1秒。 最后,当没有更多的命令时,浏览器实例会
这就完成了你的运行Puppeteer()方法,在这个时候,你的puppeteerManager.js文件应该是这样的:
1[label puppeteerManager.js]
2class PuppeteerManager {
3 constructor(args) {
4 this.url = args.url
5 this.existingCommands = args.commands
6 this.nrOfPages = args.nrOfPages
7 this.allBooks = [];
8 this.booksDetails = {}
9 }
10
11 async runPuppeteer() {
12 const puppeteer = require('puppeteer')
13 let commands = []
14 if (this.nrOfPages > 1) {
15 for (let i = 0; i < this.nrOfPages; i++) {
16 if (i < this.nrOfPages - 1) {
17 commands.push(...this.existingCommands)
18 } else {
19 commands.push(this.existingCommands[0])
20 }
21 }
22 } else {
23 commands = this.existingCommands
24 }
25 console.log('commands length', commands.length)
26
27 const browser = await puppeteer.launch({
28 headless: true,
29 args: [
30 "--no-sandbox",
31 "--disable-gpu",
32 ]
33 });
34
35 let page = await browser.newPage()
36 await page.setRequestInterception(true);
37 page.on('request', (request) => {
38 if (['image'].indexOf(request.resourceType()) !== -1) {
39 request.abort();
40 } else {
41 request.continue();
42 }
43 });
44
45 await page.on('console', msg => {
46 for (let i = 0; i < msg._args.length; ++i) {
47 msg._args[i].jsonValue().then(result => {
48 console.log(result);
49 })
50
51 }
52 });
53
54 await page.goto(this.url);
55
56 let timeout = 6000
57 let commandIndex = 0
58 while (commandIndex < commands.length) {
59 try {
60
61 console.log(`command ${(commandIndex + 1)}/${commands.length}`)
62 let frames = page.frames()
63 await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
64 await this.executeCommand(frames[0], commands[commandIndex])
65 await this.sleep(1000)
66 } catch (error) {
67 console.log(error)
68 break
69 }
70 commandIndex++
71 }
72 console.log('done')
73 await browser.close();
74 }
75}
现在您已经准备好对 puppeteerManager.js 的第二种方法进行编码: executeCommand()。
编码执行命令()方法
创建运行Puppeteer()方法后,现在是创建执行命令()方法的时候了,该方法负责决定Puppeteer应该执行哪些操作,例如点击按钮或解析一个或多个DOM元素。
在PuppeteerManager类的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async executeCommand(frame, command) {
4 await console.log(command.type, command.locatorCss)
5 switch (command.type) {
6 case "click":
7 break;
8 case "getItems":
9 break;
10 case "getItemDetails":
11 break;
12 }
13 }
在此代码块中,您创建了executeCommand()方法. 此方法预计两个参数,一个包含页面元素的框对象和一个包含命令的命令对象。
定义点击案例。
在点击的情况下,用以下代码取代break;:
1[label puppeteerManager.js]
2 async executeCommand(frame, command) {
3 . . .
4 case "click":
5 try {
6 await frame.$eval(command.locatorCss, element => element.click());
7 return true
8 } catch (error) {
9 console.log("error", error)
10 return false
11 }
12 . . .
13 }
您的代码将触发点击案例,当command.type等于点击时。
现在计划下一个案例声明。
在getItems的情况下,用以下代码取代break;
1[label puppeteerManager.js]
2 async executeCommand(frame, command) {
3 . . .
4 case "getItems":
5 try {
6 let books = await frame.evaluate((command) => {
7 function wordToNumber(word) {
8 let number = 0
9 let words = ["zero","one","two","three","four","five"]
10 for(let n=0;n<words.length;words++){
11 if(word == words[n]){
12 number = n
13 break
14 }
15 }
16 return number
17 }
18
19 try {
20 let parsedItems = [];
21 let items = document.querySelectorAll(command.locatorCss);
22 items.forEach((item) => {
23 let link = 'http://books.toscrape.com/catalogue/' + item.querySelector('div.image_container a').getAttribute('href').replace('catalogue/', '')
24 let starRating = item.querySelector('p.star-rating').getAttribute('class').replace('star-rating ', '').toLowerCase().trim()
25 let title = item.querySelector('h3 a').getAttribute('title')
26 let price = item.querySelector('p.price_color').innerText.replace('£', '').trim()
27 let book = {
28 title: title,
29 price: parseInt(price),
30 rating: wordToNumber(starRating),
31 url: link
32 }
33 parsedItems.push(book)
34 })
35 return parsedItems;
36 } catch (error) {
37 console.log(error)
38 }
39 }, command).then(result => {
40 this.allBooks.push.apply(this.allBooks, result)
41 console.log('allBooks length ', this.allBooks.length)
42 })
43 return true
44 } catch (error) {
45 console.log("error", error)
46 return false
47 }
48 . . .
49 }
getItems案例会触发command.type等于getItems。你正在使用frame.evaluate()方法(https://pptr.dev/# ?product=Puppeteer&version=v5.2.1&show=api-frameevaluatepagefunction-args)来切换浏览器的背景,然后创建一个名为wordToNumber()的函数。这个函数会将一本书的starRating从字符串转换为整数。代码会使用document.querySelectorAll()方法(https://developer.mozilla.org/en-US/docs/Web/API/Document/querySelectorAll)来解析和匹配DOM,并检索显示在网页的框架中显示的书籍的元数据。一旦获取元数据,代码会将其添加到All Books数组中。
现在你可以定义最后的案例陈述。
在getItemDetails的情况下,替换break;代码为以下代码:
1[label puppeteerManager.js]
2 async executeCommand(frame, command) {
3 . . .
4 case "getItemDetails":
5 try {
6 this.booksDetails = JSON.parse(JSON.stringify(await frame.evaluate((command) => {
7 try {
8 let item = document.querySelector(command.locatorCss);
9 let description = item.querySelector('.product_page > p:nth-child(3)').innerText.trim()
10 let upc = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(1) > td:nth-child(2)')
11 .innerText.trim()
12 let nrOfReviews = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(7) > td:nth-child(2)')
13 .innerText.trim()
14 let availability = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(2)')
15 .innerText.replace('In stock (', '').replace(' available)', '')
16 let details = {
17 description: description,
18 upc: upc,
19 nrOfReviews: parseInt(nrOfReviews),
20 availability: parseInt(availability)
21 }
22 return details;
23 } catch (error) {
24 console.log(error)
25 return error
26 }
27
28 }, command)))
29 console.log(this.booksDetails)
30 return true
31 } catch (error) {
32 console.log("error", error)
33 return false
34 }
35 }
getItemDetails案例会触发command.type等于getItemDetails。您又使用了frame.evaluate()和.querySelector()的方法来切换浏览器的背景并解析DOM。
这完成了你的executeCommand()方法,你的puppeteerManager.js文件现在将看起来像这样:
1[label puppeteerManager.js]
2class PuppeteerManager {
3 constructor(args) {
4 this.url = args.url
5 this.existingCommands = args.commands
6 this.nrOfPages = args.nrOfPages
7 this.allBooks = [];
8 this.booksDetails = {}
9 }
10
11 async runPuppeteer() {
12 const puppeteer = require('puppeteer')
13 let commands = []
14 if (this.nrOfPages > 1) {
15 for (let i = 0; i < this.nrOfPages; i++) {
16 if (i < this.nrOfPages - 1) {
17 commands.push(...this.existingCommands)
18 } else {
19 commands.push(this.existingCommands[0])
20 }
21 }
22 } else {
23 commands = this.existingCommands
24 }
25 console.log('commands length', commands.length)
26
27 const browser = await puppeteer.launch({
28 headless: true,
29 args: [
30 "--no-sandbox",
31 "--disable-gpu",
32 ]
33 });
34
35 let page = await browser.newPage()
36 await page.setRequestInterception(true);
37 page.on('request', (request) => {
38 if (['image'].indexOf(request.resourceType()) !== -1) {
39 request.abort();
40 } else {
41 request.continue();
42 }
43 });
44
45 await page.on('console', msg => {
46 for (let i = 0; i < msg._args.length; ++i) {
47 msg._args[i].jsonValue().then(result => {
48 console.log(result);
49 })
50
51 }
52 });
53
54 await page.goto(this.url);
55
56 let timeout = 6000
57 let commandIndex = 0
58 while (commandIndex < commands.length) {
59 try {
60
61 console.log(`command ${(commandIndex + 1)}/${commands.length}`)
62 let frames = page.frames()
63 await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
64 await this.executeCommand(frames[0], commands[commandIndex])
65 await this.sleep(1000)
66 } catch (error) {
67 console.log(error)
68 break
69 }
70 commandIndex++
71 }
72 console.log('done')
73 await browser.close();
74 }
75
76 async executeCommand(frame, command) {
77 await console.log(command.type, command.locatorCss)
78 switch (command.type) {
79 case "click":
80 try {
81 await frame.$eval(command.locatorCss, element => element.click());
82 return true
83 } catch (error) {
84 console.log("error", error)
85 return false
86 }
87 case "getItems":
88 try {
89 let books = await frame.evaluate((command) => {
90 function wordToNumber(word) {
91 let number = 0
92 let words = ["zero","one","two","three","four","five"]
93 for(let n=0;n<words.length;words++){
94 if(word == words[n]){
95 number = n
96 break
97 }
98 }
99 return number
100 }
101 try {
102 let parsedItems = [];
103 let items = document.querySelectorAll(command.locatorCss);
104
105 items.forEach((item) => {
106 let link = 'http://books.toscrape.com/catalogue/' + item.querySelector('div.image_container a').getAttribute('href').replace('catalogue/', '')
107 let starRating = item.querySelector('p.star-rating').getAttribute('class').replace('star-rating ', '').toLowerCase().trim()
108 let title = item.querySelector('h3 a').getAttribute('title')
109 let price = item.querySelector('p.price_color').innerText.replace('£', '').trim()
110 let book = {
111 title: title,
112 price: parseInt(price),
113 rating: wordToNumber(starRating),
114 url: link
115 }
116 parsedItems.push(book)
117 })
118 return parsedItems;
119 } catch (error) {
120 console.log(error)
121 }
122 }, command).then(result => {
123 this.allBooks.push.apply(this.allBooks, result)
124 console.log('allBooks length ', this.allBooks.length)
125 })
126 return true
127 } catch (error) {
128 console.log("error", error)
129 return false
130 }
131 case "getItemDetails":
132 try {
133 this.booksDetails = JSON.parse(JSON.stringify(await frame.evaluate((command) => {
134 try {
135 let item = document.querySelector(command.locatorCss);
136 let description = item.querySelector('.product_page > p:nth-child(3)').innerText.trim()
137 let upc = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(1) > td:nth-child(2)')
138 .innerText.trim()
139 let nrOfReviews = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(7) > td:nth-child(2)')
140 .innerText.trim()
141 let availability = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(2)')
142 .innerText.replace('In stock (', '').replace(' available)', '')
143 let details = {
144 description: description,
145 upc: upc,
146 nrOfReviews: parseInt(nrOfReviews),
147 availability: parseInt(availability)
148 }
149 return details;
150 } catch (error) {
151 console.log(error)
152 return error
153 }
154
155 }, command)))
156 console.log(this.booksDetails)
157 return true
158 } catch (error) {
159 console.log("error", error)
160 return false
161 }
162 }
163 }
164}
您现在已经准备好为您的PuppeteerManager类创建第三种方法:sleep()。
编码sleep()方法
通过创建executeCommand()方法,您的下一步是创建sleep()方法. 此方法将使您的代码在执行下一行代码之前等待一定时间。 这对于降低搜索率至关重要。
在PuppeteerManager类的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 sleep(ms) {
4 return new Promise(resolve => setTimeout(resolve, ms))
5 }
您正在将整数传递到sleep()方法. 这个整数是代码应该等待的毫秒时间。
现在编码PuppeteerManager类内的最后两种方法:getAllBooks()和getBooksDetails()。
编码getAllBooks()和getBooksDetails()方法
在创建sleep()方法后,创建getAllBooks()方法.在server.js文件中的一个函数将调用此函数。
在PuppeteerManager类的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async getAllBooks() {
4 await this.runPuppeteer()
5 return this.allBooks
6 }
注意这块块如何使用另一个承诺。
现在你可以创建最后的方法: getBooksDetails(). 像 getAllBooks(),在 server.js 内部的函数将调用此函数。
在PuppeteerManager类的底部,添加以下代码:
1[label puppeteerManager.js]
2. . .
3 async getBooksDetails() {
4 await this.runPuppeteer()
5 return this.booksDetails
6 }
您现在已经完成了您的 puppeteerManager.js 文件的编码。
在添加本节中描述的五种方法后,完成的文件将看起来如下:
1[label puppeteerManager.js]
2class PuppeteerManager {
3 constructor(args) {
4 this.url = args.url
5 this.existingCommands = args.commands
6 this.nrOfPages = args.nrOfPages
7 this.allBooks = [];
8 this.booksDetails = {}
9 }
10
11 async runPuppeteer() {
12 const puppeteer = require('puppeteer')
13 let commands = []
14 if (this.nrOfPages > 1) {
15 for (let i = 0; i < this.nrOfPages; i++) {
16 if (i < this.nrOfPages - 1) {
17 commands.push(...this.existingCommands)
18 } else {
19 commands.push(this.existingCommands[0])
20 }
21 }
22 } else {
23 commands = this.existingCommands
24 }
25 console.log('commands length', commands.length)
26
27 const browser = await puppeteer.launch({
28 headless: true,
29 args: [
30 "--no-sandbox",
31 "--disable-gpu",
32 ]
33 });
34
35 let page = await browser.newPage()
36 await page.setRequestInterception(true);
37 page.on('request', (request) => {
38 if (['image'].indexOf(request.resourceType()) !== -1) {
39 request.abort();
40 } else {
41 request.continue();
42 }
43 });
44
45 await page.on('console', msg => {
46 for (let i = 0; i < msg._args.length; ++i) {
47 msg._args[i].jsonValue().then(result => {
48 console.log(result);
49 })
50
51 }
52 });
53
54 await page.goto(this.url);
55
56 let timeout = 6000
57 let commandIndex = 0
58 while (commandIndex < commands.length) {
59 try {
60
61 console.log(`command ${(commandIndex + 1)}/${commands.length}`)
62 let frames = page.frames()
63 await frames[0].waitForSelector(commands[commandIndex].locatorCss, { timeout: timeout })
64 await this.executeCommand(frames[0], commands[commandIndex])
65 await this.sleep(1000)
66 } catch (error) {
67 console.log(error)
68 break
69 }
70 commandIndex++
71 }
72 console.log('done')
73 await browser.close();
74 }
75
76 async executeCommand(frame, command) {
77 await console.log(command.type, command.locatorCss)
78 switch (command.type) {
79 case "click":
80 try {
81 await frame.$eval(command.locatorCss, element => element.click());
82 return true
83 } catch (error) {
84 console.log("error", error)
85 return false
86 }
87 case "getItems":
88 try {
89 let books = await frame.evaluate((command) => {
90 function wordToNumber(word) {
91 let number = 0
92 let words = ["zero","one","two","three","four","five"]
93 for(let n=0;n<words.length;words++){
94 if(word == words[n]){
95 number = n
96 break
97 }
98 }
99 return number
100 }
101
102 try {
103 let parsedItems = [];
104 let items = document.querySelectorAll(command.locatorCss);
105
106 items.forEach((item) => {
107 let link = 'http://books.toscrape.com/catalogue/' + item.querySelector('div.image_container a').getAttribute('href').replace('catalogue/', '')
108 let starRating = item.querySelector('p.star-rating').getAttribute('class').replace('star-rating ', '').toLowerCase().trim()
109 let title = item.querySelector('h3 a').getAttribute('title')
110 let price = item.querySelector('p.price_color').innerText.replace('£', '').trim()
111 let book = {
112 title: title,
113 price: parseInt(price),
114 rating: wordToNumber(starRating),
115 url: link
116 }
117 parsedItems.push(book)
118 })
119 return parsedItems;
120 } catch (error) {
121 console.log(error)
122 }
123 }, command).then(result => {
124 this.allBooks.push.apply(this.allBooks, result)
125 console.log('allBooks length ', this.allBooks.length)
126 })
127 return true
128 } catch (error) {
129 console.log("error", error)
130 return false
131 }
132 case "getItemDetails":
133 try {
134 this.booksDetails = JSON.parse(JSON.stringify(await frame.evaluate((command) => {
135 try {
136 let item = document.querySelector(command.locatorCss);
137 let description = item.querySelector('.product_page > p:nth-child(3)').innerText.trim()
138 let upc = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(1) > td:nth-child(2)')
139 .innerText.trim()
140 let nrOfReviews = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(7) > td:nth-child(2)')
141 .innerText.trim()
142 let availability = item.querySelector('.table > tbody:nth-child(1) > tr:nth-child(6) > td:nth-child(2)')
143 .innerText.replace('In stock (', '').replace(' available)', '')
144 let details = {
145 description: description,
146 upc: upc,
147 nrOfReviews: parseInt(nrOfReviews),
148 availability: parseInt(availability)
149 }
150 return details;
151 } catch (error) {
152 console.log(error)
153 return error
154 }
155
156 }, command)))
157 console.log(this.booksDetails)
158 return true
159 } catch (error) {
160 console.log("error", error)
161 return false
162 }
163 }
164 }
165
166 sleep(ms) {
167 return new Promise(resolve => setTimeout(resolve, ms))
168 }
169
170 async getAllBooks() {
171 await this.runPuppeteer()
172 return this.allBooks
173 }
174
175 async getBooksDetails() {
176 await this.runPuppeteer()
177 return this.booksDetails
178 }
179}
180
181module.exports = { PuppeteerManager }
在此步骤中,您使用Puppeteer模块创建了puppeteerManager.js文件. 此文件构成您的扫描仪的核心。 在下一节中,您将创建server.js文件。
步骤 4 — 构建第二个扫描器文件
在此步骤中,您将创建server.js文件 - 应用程序服务器的第二半部分. 此文件将收到包含信息的请求,该请求将指示哪些数据被扫描,然后将该数据返回客户端。
创建server.js文件并打开它:
1nano server.js
添加以下代码:
1[label server.js]
2const express = require('express');
3const bodyParser = require('body-parser')
4const os = require('os');
5
6const PORT = 5000;
7const app = express();
8let timeout = 1500000
9
10app.use(bodyParser.urlencoded({ extended: true }))
11app.use(bodyParser.json())
12
13let browsers = 0
14let maxNumberOfBrowsers = 5
在这个代码块中,你需要表达和体分辨器模块。这些模块是必要的,以创建一个能够处理HTTP请求的应用程序服务器。表达模块会创建一个应用程序服务器,而体分辨器模块会在中间软件中分析到来的请求器体,然后获取身体的内容。然后,你需要os模块,该模块会检索运行你的应用程序的机器的名称。之后,你将为应用程序指定一个端口,并创建了变量浏览器和maxNumberOfBrowsers。这些变量将有助于管理服务器可以创建的浏览器实例的数量。在这种情况下,应用程序仅限于创建五个浏览器实例,这意味着扫描
我们的网页服务器将有以下路线: /, /api/books,和 /api/booksDetails。
在server.js文件的底部,用以下代码定义/路径:
1[label server.js]
2. . .
3
4app.get('/', (req, res) => {
5 console.log(os.hostname())
6 let response = {
7 msg: 'hello world',
8 hostname: os.hostname().toString()
9 }
10 res.send(response);
11});
向该路线发送的GET请求将返回包含两个属性的对象:msg,这只会说Hello world和hostname,这将识别运行应用程序服务器实例的机器。
现在定义/api/books路线。
在server.js文件的底部,添加以下代码:
1[label server.js]
2. . .
3
4app.post('/api/books', async (req, res) => {
5 req.setTimeout(timeout);
6 try {
7 let data = req.body
8 console.log(req.body.url)
9 while (browsers == maxNumberOfBrowsers) {
10 await sleep(1000)
11 }
12 await getBooksHandler(data).then(result => {
13 let response = {
14 msg: 'retrieved books ',
15 hostname: os.hostname(),
16 books: result
17 }
18 console.log('done')
19 res.send(response)
20 })
21 } catch (error) {
22 res.send({ error: error.toString() })
23 }
24});
「/api/books」路线将要求扫描器在某个网页上获取与书籍相关的元数据。向该路线的「POST」请求将检查运行的「浏览器」的数量是否等于「maxNumberOfBrowsers」,如果不是,则将调用方法为「getBooksHandler()」。这种方法将创建一个新的「PuppeteerManager」类的实例,并获取书籍的元数据。一旦获取了元数据,它将返回响应体到客户端。响应对象将包含一个字符串,即「msg」,读取了「恢复的书籍」,一个数组,即「书籍」,包含了元数据和另一个字符串,即「主机名」,将返回应用程序运行的机器/容器/pod的名称
我们有一个最后的路径来定义: /api/booksDetails。
将以下代码添加到您的 server.js 文件的底部:
1[label server.js]
2. . .
3
4app.post('/api/booksDetails', async (req, res) => {
5 req.setTimeout(timeout);
6 try {
7 let data = req.body
8 console.log(req.body.url)
9 while (browsers == maxNumberOfBrowsers) {
10 await sleep(1000)
11 }
12 await getBookDetailsHandler(data).then(result => {
13 let response = {
14 msg: 'retrieved book details',
15 hostname: os.hostname(),
16 url: req.body.url,
17 booksDetails: result
18 }
19 console.log('done', response)
20 res.send(response)
21 })
22 } catch (error) {
23 res.send({ error: error.toString() })
24 }
25});
将POST请求发送到/api/booksDetails路径将要求扫描器为特定书籍获取缺少的信息。应用程序服务器将检查运行的浏览器的数量是否等于maxNumberOfBrowsers。如果是,它将调用sleep()方法并等待1秒,然后再检查一次,如果不等,它将调用getBookDetailsHandler()方法。像getBooksHandler()方法一样,这种方法将创建一个新的PuppeteerManager类的实例并获取缺失的信息。
回复对象将包含一个字符串,即msg,表示恢复的书籍细节,一个字符串,即主机名,将返回运行应用程序的机器的名称,另一个字符串,即url,包含项目页面的URL。
您的 Web 服务器还将具有以下功能:getBooksHandler()、getBookDetailsHandler()和sleep()。
开始使用getBooksHandler()函数。
在server.js文件的底部,添加以下代码:
1[label server.js]
2. . .
3
4async function getBooksHandler(arg) {
5 let pMng = require('./puppeteerManager')
6 let puppeteerMng = new pMng.PuppeteerManager(arg)
7 browsers += 1
8 try {
9 let books = await puppeteerMng.getAllBooks().then(result => {
10 return result
11 })
12 browsers -= 1
13 return books
14 } catch (error) {
15 browsers -= 1
16 console.log(error)
17 }
18}
getBooksHandler()函数将创建一个新的PuppeteerManager类的实例,它将增加运行的浏览器的数量,通过包含必要信息的对象来获取书籍,然后调用getAllBooks()方法。
现在添加以下代码来定义getBookDetailsHandler()函数:
1[label server.js]
2. . .
3
4async function getBookDetailsHandler(arg) {
5 let pMng = require('./puppeteerManager')
6 let puppeteerMng = new pMng.PuppeteerManager(arg)
7 browsers += 1
8 try {
9 let booksDetails = await puppeteerMng.getBooksDetails().then(result => {
10 return result
11 })
12 browsers -= 1
13 return booksDetails
14 } catch (error) {
15 browsers -= 1
16 console.log(error)
17 }
18}
getBookDetailsHandler()函数将创建一个新的PuppeteerManager类的实例,它就像getBooksHandler()函数一样,但它处理每个书的缺失元数据,并将其返回到/api/booksDetails路线。
在server.js文件的底部,添加以下代码来定义sleep()函数:
1[label server.js]
2 function sleep(ms) {
3 console.log(' running maximum number of browsers')
4 return new Promise(resolve => setTimeout(resolve, ms))
5 }
sleep()函数使代码等待一定时间,当浏览器的数量等于maxNumberOfBrowsers时,我们将一个整数传递给这个函数,这个整数代表了代码应该等待的时间,直到它可以检查浏览器是否等于maxNumberOfBrowsers。
你的檔案已經完成了。
创建所有必要的路径和功能后,server.js 文件将看起来像这样:
1[label server.js]
2const express = require('express');
3const bodyParser = require('body-parser')
4const os = require('os');
5
6const PORT = 5000;
7const app = express();
8let timeout = 1500000
9
10app.use(bodyParser.urlencoded({ extended: true }))
11app.use(bodyParser.json())
12
13let browsers = 0
14let maxNumberOfBrowsers = 5
15
16app.get('/', (req, res) => {
17 console.log(os.hostname())
18 let response = {
19 msg: 'hello world',
20 hostname: os.hostname().toString()
21 }
22 res.send(response);
23});
24
25app.post('/api/books', async (req, res) => {
26 req.setTimeout(timeout);
27 try {
28 let data = req.body
29 console.log(req.body.url)
30 while (browsers == maxNumberOfBrowsers) {
31 await sleep(1000)
32 }
33 await getBooksHandler(data).then(result => {
34 let response = {
35 msg: 'retrieved books ',
36 hostname: os.hostname(),
37 books: result
38 }
39 console.log('done')
40 res.send(response)
41 })
42 } catch (error) {
43 res.send({ error: error.toString() })
44 }
45});
46
47app.post('/api/booksDetails', async (req, res) => {
48 req.setTimeout(timeout);
49 try {
50 let data = req.body
51 console.log(req.body.url)
52 while (browsers == maxNumberOfBrowsers) {
53 await sleep(1000)
54 }
55 await getBookDetailsHandler(data).then(result => {
56 let response = {
57 msg: 'retrieved book details',
58 hostname: os.hostname(),
59 url: req.body.url,
60 booksDetails: result
61 }
62 console.log('done', response)
63 res.send(response)
64 })
65 } catch (error) {
66 res.send({ error: error.toString() })
67 }
68});
69
70async function getBooksHandler(arg) {
71 let pMng = require('./puppeteerManager')
72 let puppeteerMng = new pMng.PuppeteerManager(arg)
73 browsers += 1
74 try {
75 let books = await puppeteerMng.getAllBooks().then(result => {
76 return result
77 })
78 browsers -= 1
79 return books
80 } catch (error) {
81 browsers -= 1
82 console.log(error)
83 }
84}
85
86async function getBookDetailsHandler(arg) {
87 let pMng = require('./puppeteerManager')
88 let puppeteerMng = new pMng.PuppeteerManager(arg)
89 browsers += 1
90 try {
91 let booksDetails = await puppeteerMng.getBooksDetails().then(result => {
92 return result
93 })
94 browsers -= 1
95 return booksDetails
96 } catch (error) {
97 browsers -= 1
98 console.log(error)
99 }
100}
101
102function sleep(ms) {
103 console.log(' running maximum number of browsers')
104 return new Promise(resolve => setTimeout(resolve, ms))
105}
106
107app.listen(PORT);
108console.log(`Running on port: ${PORT}`);
在下一步,您将为应用程序服务器创建一个图像,然后将其部署到您的Kubernetes集群中。
步骤 5 — 构建 Docker 图像
在此步骤中,您将创建包含您的扫描应用程序的Docker图像,在第 6 步中,您将将该图像部署到 Kubernetes 集群中。
要创建您的应用程序的Docker图像,您需要创建一个Dockerfile,然后构建容器。
请确保您仍处于/server文件夹中。
现在创建 Dockerfile 并打开它:
1nano Dockerfile
在Dockerfile里面写下以下代码:
1[label Dockerfile]
2FROM node:10
3
4RUN apt-get update
5
6RUN apt-get install -yyq ca-certificates
7
8RUN apt-get install -yyq libappindicator1 libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libnss3 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6
9
10RUN apt-get install -yyq gconf-service lsb-release wget xdg-utils
11
12RUN apt-get install -yyq fonts-liberation
13
14WORKDIR /usr/src/app
15
16COPY package*.json ./
17
18RUN npm install
19
20COPY . .
21
22EXPOSE 5000
23CMD [ "node", "server.js" ]
该块中的大部分代码是Dockerfile的标准命令行代码。您从node:10图像中构建了图像。接下来,您使用RUN命令来安装在Docker容器中运行Puppeteer所需的包裹,然后创建了应用程序目录。 您将扫描器的package.json文件复制到应用程序目录,并安装了package.json文件中所指定的依赖性。 最后,您将应用程序源组合起来,将应用程序暴露在端口5000上,并选择server.js作为输入文件。
现在创建一个.dockerignore 文件并打开它,这将使敏感和不必要的文件脱离版本控制。
使用您喜爱的文本编辑器创建文件:
1nano .dockerignore
将以下内容添加到文件中:
1[label ./server/.dockerignore]
2node_modules
3npm-debug.log
创建Dockerfile和.dockerignore文件后,您可以创建应用程序的 Docker 图像,并将其推到 Docker Hub 帐户中的存储库。
登录到 Docker Hub:
1docker login --username=your_username --password=your_password
构建图像:
1docker build -t your_username/concurrent-scraper .
现在是测试扫描仪的时候了. 在这个测试中,您将向每个路线发送请求。
首先,启动应用程序:
1docker run -p 5000:5000 -d your_username/concurrent-scraper
现在使用curl发送GET请求到/路线:
1curl http://localhost:5000/
通过将GET请求发送到/路径,您应该收到包含msg和hello world的响应,以及hostname。这个hostname是您的Docker容器的ID。
1[secondary_label Output]
2{"msg":"hello world","hostname":"0c52d53f97d3"}
现在将POST请求发送到/api/books路径,以获取在一个网页上显示的所有书籍的元数据:
1curl --header "Content-Type: application/json" --request POST --data '{"url": "http://books.toscrape.com/index.html" , "nrOfPages":1 , "commands":[{"description": "get items metadata", "locatorCss": ".product_pod","type": "getItems"},{"description": "go to next page","locatorCss": ".next > a:nth-child(1)","type": "Click"}]}' http://localhost:5000/api/books
通过将POST请求发送到/api/books路线,您将收到含有msg表示已获取的书籍,类似于上一个请求中的主机名称,以及包含在 books.toscrape网站的第一页上显示的所有20本书籍的书籍数组的响应。
1[secondary_label Output]
2{"msg":"retrieved books ","hostname":"0c52d53f97d3","books":[{"title":"A Light in the Attic","price":null,"rating":0,"url":"http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"},{"title":"Tipping the Velvet","price":null,"rating":0,"url":"http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html"}, [ . . . ] }]}
现在将POST请求发送到/api/booksDetails路径,以获取随机书籍所缺少的信息:
1curl --header "Content-Type: application/json" --request POST --data '{"url": "http://books.toscrape.com/catalogue/slow-states-of-collapse-poems_960/index.html" , "nrOfPages":1 , "commands":[{"description": "get item details", "locatorCss": "article.product_page","type": "getItemDetails"}]}' http://localhost:5000/api/booksDetails
通过将POST请求发送到/api/booksDetails路径,您将收到含有msg表示已获取的书籍详细信息,含有本书详细信息对象(http://books.toscrape.com/catalogue/slow-states-of-collapse-poems_960/index.html),含有产品页面的地址的url,以及类似于以前的请求中的主机名称。
1[secondary_label Output]
2{"msg":"retrieved book details","hostname":"0c52d53f97d3","url":"http://books.toscrape.com/catalogue/slow-states-of-collapse-poems_960/index.html","booksDetails":{"description":"The eagerly anticipated debut from one of Canada’s most exciting new poets In her debut collection, Ashley-Elizabeth Best explores the cultivation of resilience during uncertain and often trying times [...]","upc":"b4fd5943413e089a","nrOfReviews":0,"availability":17}}
如果你的弯曲命令没有返回正确的答案,请确保文件中的代码puppeteerManager.js和server.js匹配前两步中的最终代码块。
如果在尝试运行 Docker 图像时仍然遇到错误,请尝试阻止所有运行容器并在没有 -d 选项的情况下运行扫描图像。
首先停止所有集装箱:
1docker stop $(docker ps -a -q)
然后运行Docker命令而没有d旗:
1docker run -p 5000:5000 your_username/concurrent-scraper
如果您没有遇到任何错误,请清理终端窗口:
1clear
现在您已经成功测试了图像,您可以将其发送到您的存储库. 将图像推到您的 Docker Hub 帐户中的存储库:
1docker push your_username/concurrent-scraper:latest
有了你的扫描程序现在可在Docker Hub上作为图像,你已经准备好部署到Kubernetes。
步骤 6 — 部署扫描器到 Kubernetes
随着你的扫描仪图像被构建并推到你的存储库,你现在已经准备好部署了。
首先,使用kubectl创建一个新的名称空间,称为竞争性扫描框架:
1kubectl create namespace concurrent-scraper-context
将竞争者扫描框架设置为默认框架:
1kubectl config set-context --current --namespace=concurrent-scraper-context
要创建你的应用程序的部署,你需要创建一个名为app-deployment.yaml的文件,但首先,你必须导航到你的项目中的k8s目录。
进入项目内部的k8s目录:
1cd ../k8s
创建app-deployment.yaml文件并打开它:
1nano app-deployment.yaml
請在「app-deployment.yaml」內寫下以下代碼,請確保以您的獨特用戶名取代「your_DockerHub_username」:
1[label ./k8s/app-deployment.yaml]
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: scraper
6 labels:
7 app: scraper
8spec:
9 replicas: 5
10 selector:
11 matchLabels:
12 app: scraper
13 template:
14 metadata:
15 labels:
16 app: scraper
17 spec:
18 containers:
19 - name: concurrent-scraper
20 image: your_DockerHub_username/concurrent-scraper
21 ports:
22 - containerPort: 5000
在前一个块中的大多数代码都是Kubernetes的部署文件的标准。首先,你将应用程序部署的名称设置为scraper,然后将潜的数目设置为5,然后将容器的名称设置为竞争对手扫描器。
创建部署文件后,您已经准备好将应用部署到集群中。
安装 app:
1kubectl apply -f app-deployment.yaml
您可以通过运行以下命令监控部署的状态:
1kubectl get deployment -w
运行命令后,您将看到这样的输出:
1[secondary_label Output]
2NAME READY UP-TO-DATE AVAILABLE AGE
3scraper 0/5 5 0 7s
4scraper 1/5 5 1 23s
5scraper 2/5 5 2 25s
6scraper 3/5 5 3 25s
7scraper 4/5 5 4 33s
8scraper 5/5 5 5 33s
所有部署都需要几秒钟才能开始运行,但一旦运行,您将有五个扫描仪的实例运行. 每个实例可以同时扫描五页,因此您将能够同时扫描25页,从而减少扫描所有400页所需的时间。
要从群集外部访问您的应用程序,您需要创建一个服务。这个服务将是一个负载平衡器,并需要一个名为load-balancer.yaml的文件。
创建load-balancer.yaml文件并打开它:
1nano load-balancer.yaml
在load-balancer.yaml里面写下以下代码:
1[label load-balancer.yaml]
2apiVersion: v1
3kind: Service
4metadata:
5 name: load-balancer
6 labels:
7 app: scraper
8spec:
9 type: LoadBalancer
10 ports:
11 - port: 80
12 targetPort: 5000
13 protocol: TCP
14 selector:
15 app: scraper
上一块中的大部分代码是服务文件的标准代码. 首先,您将服务的名称设置为负载平衡器。 您指定了服务类型,然后在端口80上使服务可用。
现在你已经创建了你的 load-balancer.yaml 文件,部署该服务到群集。
部署服务:
1kubectl apply -f load-balancer.yaml
运行以下命令来监控您的服务的状态:
1kubectl get services -w
运行此命令后,您将看到这样的输出,但需要几秒钟才能显示外部 IP:
1[secondary_label Output]
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3load-balancer LoadBalancer 10.245.91.92 <pending> 80:30802/TCP 10s
4load-balancer LoadBalancer 10.245.91.92 161.35.252.69 80:30802/TCP 69s
您的服务的EXTERNAL-IP和CLUSTER-IP将与上述不同,请记住您的EXTERNAL-IP。
在此步骤中,您已部署到您的 Kubernetes 集群中,在下一步,您将创建一个客户端应用程序,以与新部署的应用程序进行交互。
步骤 7 — 创建客户端应用程序
在此步骤中,您将构建客户端应用程序,这将需要以下三个文件:main.js、lowdbHelper.js 和books.json。main.js 文件是客户端应用程序的主要文件。它将请求发送到您的应用程序服务器,然后使用您将创建在lowdbHelper.js文件中的一种方法来保存获取的数据。lowdbHelper.js 文件将数据保存到本地文件中并检索到该文件中的数据。books.json 文件是您将保存所有被扫描的数据的本地文件。
首先回到您的客户目录:
1cd ../client
因为它们小于main.js,所以首先要创建lowdbHelper.js 和books.json 文件。
创建并打开名为lowdbHelper.js的文件:
1nano lowdbHelper.js
将以下代码添加到 lowdbHelper.js 文件中:
1[label lowdbHelper.js]
2const lowdb = require('lowdb')
3const FileSync = require('lowdb/adapters/FileSync')
4const adapter = new FileSync('books.json')
在这个代码块中,你需要模块lowdb,然后需要适配器FileSync,你需要保存和读取数据,然后指示程序将数据存储在一个名为books.json的JSON文件中。
将以下代码添加到lowdbHelper.js文件的底部:
1[label lowdbHelper.js]
2. . .
3class LowDbHelper {
4 constructor() {
5 this.db = lowdb(adapter);
6 }
7
8 getData() {
9 try {
10 let data = this.db.getState().books
11 return data
12 } catch (error) {
13 console.log('error', error)
14 }
15 }
16
17 saveData(arg) {
18 try {
19 this.db.set('books', arg).write()
20 console.log('data saved successfully!!!')
21 } catch (error) {
22 console.log('error', error)
23 }
24 }
25}
26
27module.exports = { LowDbHelper }
在这里,你创建了一个名为LowDbHelper的类,这个类包含以下两种方法:getData()和saveData()。第一个将检索存储在books.json文件中的书籍,第二个将你的书籍保存到相同的文件中。
完成的lowdbHelper.js将看起来像这样:
1[label lowdbHelper.js]
2const lowdb = require('lowdb')
3const FileSync = require('lowdb/adapters/FileSync')
4const adapter = new FileSync('books.json')
5
6class LowDbHelper {
7 constructor() {
8 this.db = lowdb(adapter);
9 }
10
11 getData() {
12 try {
13 let data = this.db.getState().books
14 return data
15 } catch (error) {
16 console.log('error', error)
17 }
18 }
19
20 saveData(arg) {
21 try {
22 this.db.set('books', arg).write()
23 //console.log('data saved successfully!!!')
24 } catch (error) {
25 console.log('error', error)
26 }
27 }
28
29}
30
31module.exports = { LowDbHelper }
现在你已经创建了lowdbHelper.js文件,是时候创建books.json文件了。
创建books.json文件并打开它:
1nano books.json
添加以下代码:
1[label books.json]
2{
3 "books": []
4}
books.json文件由一个名为books的属性组成,该属性的初始值是空数组。
现在你已经创建了lowdbHelper.js和books.json文件,你将创建main.js文件。
创建main.js并打开它:
1nano main.js
将以下代码添加到main.js:
1[label main.js]
2let axios = require('axios')
3let ldb = require('./lowdbHelper.js').LowDbHelper
4let ldbHelper = new ldb()
5let allBooks = ldbHelper.getData()
6
7let server = "http://your_load_balancer_external_ip_address"
8let podsWorkDone = []
9let booksDetails = []
10let errors = []
在这个代码片段中,你需要lowdbHelper.js文件和一个名为axios的模块。你将使用axios发送HTTP请求到你的扫描仪;lowdbHelper.js文件将保存您获取的书籍,而allBooks变量将存储在books.json文件中保存的所有书籍。在获取任何书籍之前,这个变量将保留一个空的数组;服务器变量将存储您在上一节创建的负载平衡器的EXTERNAL-IP。请确保用您独特的IP代替。podsWorkDone变量将跟踪您扫描仪的每个实例处理的页面数量。booksDetails变量
现在我们需要为切割过程的每个部分构建一些功能。
将下一个代码块添加到main.js 文件的底部:
1[label main.js]
2. . .
3function main() {
4 let execute = process.argv[2] ? process.argv[2] : 0
5 execute = parseInt(execute)
6 switch (execute) {
7 case 0:
8 getBooks()
9 break;
10 case 1:
11 getBooksDetails()
12 break;
13 }
14}
您现在正在创建一个名为main()的函数,该函数由一个交换语句组成,该语句将根据传输的输入调用getBooks()或getBooksDetails()函数。
在getBooks()下面用以下代码取代break;字段:
1[label main.js]
2. . .
3function getBooks() {
4 console.log('getting books')
5 let data = {
6 url: 'http://books.toscrape.com/index.html',
7 nrOfPages: 20,
8 commands: [
9 {
10 description: 'get items metadata',
11 locatorCss: '.product_pod',
12 type: "getItems"
13 },
14 {
15 description: 'go to next page',
16 locatorCss: '.next > a:nth-child(1)',
17 type: "Click"
18 }
19 ],
20 }
21 let begin = Date.now();
22 axios.post(`${server}/api/books`, data).then(result => {
23 let end = Date.now();
24 let timeSpent = (end - begin) / 1000 + "secs";
25 console.log(`took ${timeSpent} to retrieve ${result.data.books.length} books`)
26 ldbHelper.saveData(result.data.books)
27 })
28}
在这里,你创建了一个名为getBooks()的函数。这个代码将包含所有 20 页信息的对象分配到一个称为数据的变量中。该对象的命令系列中的第一个命令会检索页面上显示的所有 20 本书,第二个命令会点击页面上的下一个按钮,从而使浏览器导航到下一个页面。这意味着第一个命令会重复 20 次,而第二个 19 次。使用axios发送到/api/books路径的POST请求会将该对象发送到您的服务器应用程序,然后扫描器会检索在 [books.toscrape(LINK0)]网站的前 20 页面上显示的每个书籍
现在编码第二个函数,该函数将处理单个页面的更具体的书籍数据。
在getBooksDetails()下方替换break;代码为以下代码:
1[label main.js]
2. . .
3
4function getBooksDetails() {
5 let begin = Date.now()
6 for (let j = 0; j < allBooks.length; j++) {
7 let data = {
8 url: allBooks[j].url,
9 nrOfPages: 1,
10 commands: [
11 {
12 description: 'get item details',
13 locatorCss: 'article.product_page',
14 type: "getItemDetails"
15 }
16 ]
17 }
18 sendRequest(data, function (result) {
19 parseResult(result, begin)
20 })
21 }
22}
getBooksDetails()函数将通过allBooks数组,其中包含所有书籍,并为该数组中的每个书籍创建一个对象,该对象将包含创建该对象后所需的信息,然后将其传输到sendRequest()函数。
将以下代码添加到main.js 文件的底部:
1[label main.js]
2. . .
3
4async function sendRequest(payload, cb) {
5 let book = payload
6 try {
7 await axios.post(`${server}/api/booksDetails`, book).then(response => {
8 if (Object.keys(response.data).includes('error')) {
9 let res = {
10 url: book.url,
11 error: response.data.error
12 }
13 cb(res)
14 } else {
15 cb(response.data)
16 }
17 })
18 } catch (error) {
19 console.log(error)
20 let res = {
21 url: book.url,
22 error: error
23 }
24 cb({ res })
25 }
26}
现在你正在创建一个名为sendRequest()的函数。你将使用这个函数将所有400个请求发送到你的应用程序服务器中,其中包含你的扫描仪。代码将包含必要信息的对象分配到一个名为书的变量中,然后将这个对象发送到你的应用程序服务器上的api/booksDetails路径,然后回复到getBooksDetails()函数。
现在创建parseResult()函数。
将以下代码添加到main.js 文件的底部:
1[label main.js]
2. . .
3
4function parseResult(result, begin){
5 try {
6 let end = Date.now()
7 let timeSpent = (end - begin) / 1000 + "secs ";
8 if (!Object.keys(result).includes("error")) {
9 let wasSuccessful = Object.keys(result.booksDetails).length > 0 ? true : false
10 if (wasSuccessful) {
11 let podID = result.hostname
12 let podsIDs = podsWorkDone.length > 0 ? podsWorkDone.map(pod => { return Object.keys(pod)[0]}) : []
13 if (!podsIDs.includes(podID)) {
14 let podWork = {}
15 podWork[podID] = 1
16 podsWorkDone.push(podWork)
17 } else {
18 for (let pwd = 0; pwd < podsWorkDone.length; pwd++) {
19 if (Object.keys(podsWorkDone[pwd]).includes(podID)) {
20 podsWorkDone[pwd][podID] += 1
21 break
22 }
23 }
24 }
25 booksDetails.push(result)
26 } else {
27 errors.push(result)
28 }
29 } else {
30 errors.push(result)
31 }
32 console.log('podsWorkDone', podsWorkDone, ', retrieved ' + booksDetails.length + " books, ",
33 "took " + timeSpent + ", ", "used " + podsWorkDone.length + " pods", " errors: " + errors.length)
34 saveBookDetails()
35 } catch (error) {
36 console.log(error)
37 }
38}
「parseResult()」接收包含缺失书籍细节的函数「sendRequest()」的「结果」。然后解析「结果」并检索处理请求的pod的「主机名」,并将其分配给「podID」变量。它检查是否这个「podID」已经是「podsWorkDone」数组的一部分;如果没有,则会将「podId」添加到「podsWorkDone」数组,并将完成的工作数量设置为1。
现在添加以下代码来构建saveBookDetails()函数:
1[label main.js]
2. . .
3
4function saveBookDetails() {
5 let books = ldbHelper.getData()
6 for (let b = 0; b < books.length; b++) {
7 for (let d = 0; d < booksDetails.length; d++) {
8 let item = booksDetails[d]
9 if (books[b].url === item.url) {
10 books[b].booksDetails = item.booksDetails
11 break
12 }
13 }
14 }
15 ldbHelper.saveData(books)
16}
17
18main()
「saveBookDetails()」使用「LowDbHelper」类来获取在「books.json」文件中存储的所有书籍,并将其分配到名为「books」的变量中,然后通过「books」和「booksDetails」数组进行循环,以查看它是否在具有相同的「url」属性的两个数组中找到元素。如果这样做,则会将「booksDetails()」元素的「booksDetails」属性添加到「booksDetails」数组中的元素,并将其分配到「books」数组中的元素中。然后,它会重写「books.json」文件的内容,并且在这个函数中循环的「books」数组的内容。创建「saveBookDetails()」函数
完成的「main.js」檔案將看起來像這樣:
1[label main.js]
2let axios = require('axios')
3let ldb = require('./lowdbHelper.js').LowDbHelper
4let ldbHelper = new ldb()
5let allBooks = ldbHelper.getData()
6
7let server = "http://your_load_balancer_external_ip_address"
8let podsWorkDone = []
9let booksDetails = []
10let errors = []
11
12function main() {
13 let execute = process.argv[2] ? process.argv[2] : 0
14 execute = parseInt(execute)
15 switch (execute) {
16 case 0:
17 getBooks()
18 break;
19 case 1:
20 getBooksDetails()
21 break;
22 }
23}
24
25function getBooks() {
26 console.log('getting books')
27 let data = {
28 url: 'http://books.toscrape.com/index.html',
29 nrOfPages: 20,
30 commands: [
31 {
32 description: 'get items metadata',
33 locatorCss: '.product_pod',
34 type: "getItems"
35 },
36 {
37 description: 'go to next page',
38 locatorCss: '.next > a:nth-child(1)',
39 type: "Click"
40 }
41 ],
42 }
43 let begin = Date.now();
44 axios.post(`${server}/api/books`, data).then(result => {
45 let end = Date.now();
46 let timeSpent = (end - begin) / 1000 + "secs";
47 console.log(`took ${timeSpent} to retrieve ${result.data.books.length} books`)
48 ldbHelper.saveData(result.data.books)
49 })
50}
51
52function getBooksDetails() {
53 let begin = Date.now()
54 for (let j = 0; j < allBooks.length; j++) {
55 let data = {
56 url: allBooks[j].url,
57 nrOfPages: 1,
58 commands: [
59 {
60 description: 'get item details',
61 locatorCss: 'article.product_page',
62 type: "getItemDetails"
63 }
64 ]
65 }
66 sendRequest(data, function (result) {
67 parseResult(result, begin)
68 })
69 }
70}
71
72async function sendRequest(payload, cb) {
73 let book = payload
74 try {
75 await axios.post(`${server}/api/booksDetails`, book).then(response => {
76 if (Object.keys(response.data).includes('error')) {
77 let res = {
78 url: book.url,
79 error: response.data.error
80 }
81 cb(res)
82 } else {
83 cb(response.data)
84 }
85 })
86 } catch (error) {
87 console.log(error)
88 let res = {
89 url: book.url,
90 error: error
91 }
92 cb({ res })
93 }
94}
95
96function parseResult(result, begin){
97 try {
98 let end = Date.now()
99 let timeSpent = (end - begin) / 1000 + "secs ";
100 if (!Object.keys(result).includes("error")) {
101 let wasSuccessful = Object.keys(result.booksDetails).length > 0 ? true : false
102 if (wasSuccessful) {
103 let podID = result.hostname
104 let podsIDs = podsWorkDone.length > 0 ? podsWorkDone.map(pod => { return Object.keys(pod)[0]}) : []
105 if (!podsIDs.includes(podID)) {
106 let podWork = {}
107 podWork[podID] = 1
108 podsWorkDone.push(podWork)
109 } else {
110 for (let pwd = 0; pwd < podsWorkDone.length; pwd++) {
111 if (Object.keys(podsWorkDone[pwd]).includes(podID)) {
112 podsWorkDone[pwd][podID] += 1
113 break
114 }
115 }
116 }
117 booksDetails.push(result)
118 } else {
119 errors.push(result)
120 }
121 } else {
122 errors.push(result)
123 }
124 console.log('podsWorkDone', podsWorkDone, ', retrieved ' + booksDetails.length + " books, ",
125 "took " + timeSpent + ", ", "used " + podsWorkDone.length + " pods,", " errors: " + errors.length)
126 saveBookDetails()
127 } catch (error) {
128 console.log(error)
129 }
130}
131
132function saveBookDetails() {
133 let books = ldbHelper.getData()
134 for (let b = 0; b < books.length; b++) {
135 for (let d = 0; d < booksDetails.length; d++) {
136 let item = booksDetails[d]
137 if (books[b].url === item.url) {
138 books[b].booksDetails = item.booksDetails
139 break
140 }
141 }
142 }
143 ldbHelper.saveData(books)
144}
145
146main()
您现在已经创建了客户端应用程序,并准备好与您的Kubernetes集群中的扫描仪进行交互。在下一步,您将使用该客户端应用程序和应用程序服务器扫描所有400本书。
步骤 8 — 扫描网站
现在你已经创建了客户端应用程序和服务器侧扫描应用程序,是时候扫描 books.toscrape网站了。你将首先获取所有400本书的元数据。
在./client目录中,运行以下命令. 这将检索所有400本书的基本元数据,并将其保存到您的books.json文件:
1npm start 0
您将获得以下输出:
1[secondary_label Output]
2getting books
3took 40.323secs to retrieve 400 books
查找所有 20 页显示的书籍的元数据需要 40.323 秒,尽管这个值可能因您的互联网速度而异。
现在,您想要获取存储在books.json文件中的每个书籍的缺失细节,同时监控每个pod处理的请求数量。
再次运行npm start以获取详细信息:
1npm start 1
您将收到这样的输出,但具有不同的pod ID:
1[secondary_label Output]
2. . .
3podsWorkDone [ { 'scraper-59cd578ff6-z8zdd': 69 },
4 { 'scraper-59cd578ff6-528gv': 96 },
5 { 'scraper-59cd578ff6-zjwfg': 94 },
6 { 'scraper-59cd578ff6-nk6fr': 80 },
7 { 'scraper-59cd578ff6-h2n8r': 61 } ] , retrieved 400 books, took 56.875secs , used 5 pods, errors: 0
使用 Kubernetes 恢复所有 400 本书的缺失细节需要不到 60 秒。 每个插件中包含的扫描器至少扫描了 60 页。
现在,你的 Kubernetes 集群中的 pods 数量加倍,以进一步加速检索:
1kubectl scale deployment scraper --replicas=10
在 pods 可用之前需要几分钟,所以在运行下一个命令之前至少等待 10 秒。
重复npm start以获取缺失的细节:
1npm start 1
您将收到类似于以下的输出,但具有不同的pod ID:
1[secondary_label Output]
2. . .
3podsWorkDone [ { 'scraper-59cd578ff6-z8zdd': 38 },
4 { 'scraper-59cd578ff6-6jlvz': 47 },
5 { 'scraper-59cd578ff6-g2mxk': 36 },
6 { 'scraper-59cd578ff6-528gv': 41 },
7 { 'scraper-59cd578ff6-bj687': 36 },
8 { 'scraper-59cd578ff6-zjwfg': 47 },
9 { 'scraper-59cd578ff6-nl6bk': 34 },
10 { 'scraper-59cd578ff6-nk6fr': 33 },
11 { 'scraper-59cd578ff6-h2n8r': 38 },
12 { 'scraper-59cd578ff6-5bw2n': 50 } ] , retrieved 400 books, took 34.925secs , used 10 pods, errors: 0
翻了一番,扫描所有400页所需的时间几乎减少了一半,而恢复所有缺失的细节只花了不到35秒。
在本节中,您向 Kubernetes 集群部署的应用程序服务器发送了 400 个请求,并在短时间内扫描了 400 个单独的 URL。
结论
在本指南中,您使用Puppeteer、Docker 和 Kubernetes 来构建一个能够快速扫描 400 个网页的并行网页扫描程序. 为了与扫描程序进行交互,您构建了一个 Node.js 应用程序,该应用程序使用 axios 向包含扫描程序的服务器发送多个HTTP请求。
Puppeteer 包含许多附加功能. 如果您想了解更多,请查看 Puppeteer 的官方文档(https://pptr.dev/)。 有关 Node.js 的更多信息,请参阅我们关于 Node.js 中的编码的教程系列(https://www.digitalocean.com/community/tutorial_series/how-to-code-in-node-js)。