介绍
Benchmarking 允许您估计基础设施的性能,以便您可以确定一个特定的设置是否能满足您的工作负载需求。这是维持高服务器性能和扩展以满足日益增长的计算需求的重要组成部分。
在本教程中,我们将讨论最佳实践,通过模拟模仿您的应用程序的工作负载来对比您的DigitalOcean区块存储量。
Droplet 和 Block 存储量测试设置
您将想要确定您正在测试的工作负载的规格,以便配置适当的 Droplet 和 Block Storage Volume 设置. 如果您正在比较 DigitalOcean Volumes 与其他产品,请确保选择具有相似配置的计划,以便您获得更接近的比较。
关于设置 Droplet 的指导,请参考我们的教程)。 `
用符合您性能要求的文件系统格式化音量。 最受欢迎的默认文件系统是Ext4,它比前几代的Ext3和Ext2更能表现. XFS文件系统专门处理性能和大数据文件. 您可以在如何在 Linux( https://andsky.com/tech/tutorials/how-to-partition-and-format-digitalocean-block-storage-volumes-in-linux# formatting-the-partitions ) 中查看更多关于文件系统的文件 。 如果您没有特定的文件系统或配置偏好,在控制面板中为您创建和加载块卷的过程是自动化的.
有了您的设置,我们可以继续讨论您可以使用的基准测试工具和配置,以最大限度地利用您的性能测试。
Benchmarking 工具和配置
我们将讨论性能测量工具 fio测试性能,因为它是非常灵活和大多数分布支持。 您可能想要研究和使用的替代基准工具包括 Bonnie++, btest,和 Filebench.
要在 Ubuntu 服务器上安装 fio,您应该先更新您的包列表,然后使用以下命令安装它:
1sudo apt update
2sudo apt install fio
每个基准工具都有各种参数,您可以调整以获得测试的最佳性能。
一个值得调节的参数是队列深度,这就是音量表现出最佳性能的平行性。通常队列深度为1表示,工作负载不能开始另一个交易,直到之前的交易完成。
使用 Benchmarking 工具 fio,一些典型的配置选项包括:
建议
- -? - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
" 深入 " =========================================================================================================================================================================================================================================================== 为了达到最佳投入/产出率(一/O),建议采用大于 " io s深入=64 " 的数字。
用于I/O的以字节表示的块大小。 文件系统使用4K作为元数据,但倾向于以更大的块大小存储文件. 数据库一般会发行8-16K大小的I/O. 对于峰值带宽测试,我们建议以 " bs=64k " 或更大的区块大小。
" 运行时间 " = 运行基准的秒数。 我们建议运行时间超过60秒,通常在 " 运行时间=120秒 " 至 " 运行时间=300秒 " 之间。
" ioengine " 选项界定了工作如何将I/O问题提交档案。 我们建议
ioengine=libaio指Linux原生的同步I/O。直接 ' QQ 使用布尔值:0' 使用文件系统缓存返回最接近应用程序行为、可能导致高于典型基准结果的数值;1' 跳过任何文件系统缓存行为,将最接近的性能返回到块音量所能做的. 我们建议直接=1'。同步' QQ 对缓冲写作使用同步 I/O 。 此选项使用布尔值: " 0 " 表示不强制单位访问,允许回写缓存行为在普通磁盘驱动器上进行操作,其fio行为更像一个文件系统; " 1 " 表示I/O在磁盘保证实际放置之前无法完成。 我们建议同步=0'。 测试文件的大小,取整数。 我们通常推荐至少20千兆字节。 注意 DigitalOcean 的性能不会随体积大小而变化.
考虑到这些配置,我们现在可以谈谈一些您可能想要运行的基准测试示例。
运行基准测试
在本教程的下一节中,我们将讨论如何更深入地检查您接收的输出。
在下列命令中,我们指向一个基于NYC3数据中心的卷上的fio.test文件,请确保更新它以指向您想要使用的特定文件系统。
写带宽
此测试对块卷执行 1 MB 的随机写入。
1fio --filename=/mnt/volume-nyc3-04/fio.test \
2 --direct=1 \
3 --rw=randwrite \
4 --ioengine=libaio \
5 --bs=1024K \
6 --iodepth=32 \
7 --name=bw-test \
8 --runtime=120s \
对于标准的Droplet,我们预计输出为200MB/sec。
随机阅读测试
这将衡量一台设备可以读取多个小文件的速度。
1fio --filename=/mnt/volume-nyc3-04/fio.test \
2 --direct=1 \
3 --rw=randread \
4 --ioengine=libaio \
5 --bs=4K \
6 --iodepth=128 \
7 --name=rand-r \
8 --runtime=120s \
对于一个标准的Droplet,我们预计输出为每秒)。
随机写作测试
这将衡量多快可以编写多个小文件。
1fio --filename=/mnt/volume-nyc3-04/fio.test \
2 --direct=1 \
3 --rw=randwrite \
4 --ioengine=libaio \
5 --bs=4K \
6 --iodepth=128 \
7 --name=rand-w \
8 --runtime=120s \
5000 IOPS的输出是我们对标准Droplet的期望,而超过6000IOPS的输出是我们对高CPU Droplet的期望。
阅读延迟测试
我们将通过阅读延迟测试确定找到并访问磁盘上的正确数据块所需的时间。
1fio --filename=/mnt/volume-nyc3-04/fio.test \
2 --direct=1 \
3 --rw=randread \
4 --ioengine=libaio \
5 --bs=4K \
6 --iodepth=1 \
7 --name=lat-read \
8 --runtime=120s \
对于这个测试,我们预计输出返回小于5ms。
写延迟测试
此测试测量了从创建磁盘写请求到完成时的延迟。
1fio --filename=/mnt/volume-nyc3-04/fio.test \
2 --direct=1 \
3 --rw=randwrite \
4 --ioengine=libaio \
5 --bs=4K \
6 --iodepth=1 \
7 --name=lat-write \
8 --runtime=120s \
在这里,我们也预计这个测试的输出小于5ms。
检查输出
一旦您运行测试,您将检查结果,以检查DigitalOcean Volumes提供的读写操作的数量。
下面是写带宽测试的样本输出。
1fio --filename=/mnt/volume-nyc3-04/test.fio --direct=1 --rw=randwrite --ioengine=libaio --bs=1024k --iodepth=32 --name=bw-test --runtime=120s
1[secondary_label Output]
2bw-test: (groupid=0, jobs=1): err= 0: pid=2584: Fri Apr 20 17:14:19 2018
3 write: io=22937MB, bw=195468KB/s, iops=190, runt=120160msec
4 slat (usec): min=54, max=622, avg=135.46, stdev=23.21
5 clat (msec): min=7, max=779, avg=167.48, stdev=26.28
6 lat (msec): min=7, max=779, avg=167.62, stdev=26.28
7 clat percentiles (msec):
8 | 1.00th=[ 101], 5.00th=[ 155], 10.00th=[ 159], 20.00th=[ 163],
9 | 30.00th=[ 165], 40.00th=[ 167], 50.00th=[ 167], 60.00th=[ 167],
10 | 70.00th=[ 169], 80.00th=[ 169], 90.00th=[ 172], 95.00th=[ 178],
11 | 99.00th=[ 306], 99.50th=[ 363], 99.90th=[ 420], 99.95th=[ 474],
12 | 99.99th=[ 545]
13 bw (KB /s): min=137730, max=254485, per=100.00%, avg=195681.88, stdev=9590.24
14 lat (msec) : 10=0.01%, 20=0.03%, 50=0.37%, 100=0.58%, 250=97.55%
15 lat (msec) : 500=1.44%, 750=0.03%, 1000=0.01%
16 cpu : usr=1.76%, sys=1.83%, ctx=22777, majf=0, minf=11
17 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=99.9%, >=64=0.0%
18 submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
19 complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.1%, 64=0.0%, >=64=0.0%
20 issued : total=r=0/w=22937/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
21 latency : target=0, window=0, percentile=100.00%, depth=32
22
23Run status group 0 (all jobs):
24 WRITE: io=22937MB, aggrb=195468KB/s, minb=195468KB/s, maxb=195468KB/s, mint=120160msec, maxt=120160msec
上面的输出中突出的线路显示我们的平均带宽为)为iops=190。
執行閱讀延遲測試時,您會收到看起來如下的線上的指標:
1[secondary_label Output]
2lat-read: (groupid=0, jobs=1): err= 0: pid=2628: Fri Apr 20 17:32:51 2018
3 read : io=855740KB, bw=7131.2KB/s, iops=1782, runt=120001msec
4 slat (usec): min=8, max=434, avg=16.77, stdev= 5.92
5 clat (usec): min=2, max=450994, avg=539.15, stdev=2188.85
6 lat (usec): min=53, max=451010, avg=556.61, stdev=2188.91
在上面的示例中,我们可以看到 I/O 延迟为 556 usec 或微秒(或.5 ms 或 millisecond)。
延迟受到多种因素的影响,包括存储系统的性能,I/O的大小,排队深度和触发的任何排队限制。
当您的基准测试完成时,您可以删除Droplet和体积。
了解业绩结果
注:DigitalOcean Block Storage Volumes具有额外的性能增强功能(如爆炸),可能导致高于典型的基准值。
DigitalOcean Block Storage Volumes是基于SAN的SSD存储器,因此,给定的体积的性能与区块大小和排队深度相匹配,也就是说,存储器在给予大量工作时表现最好。
下面是一個圖表,顯示了平行性能的例子. 點擊圖像來擴大。
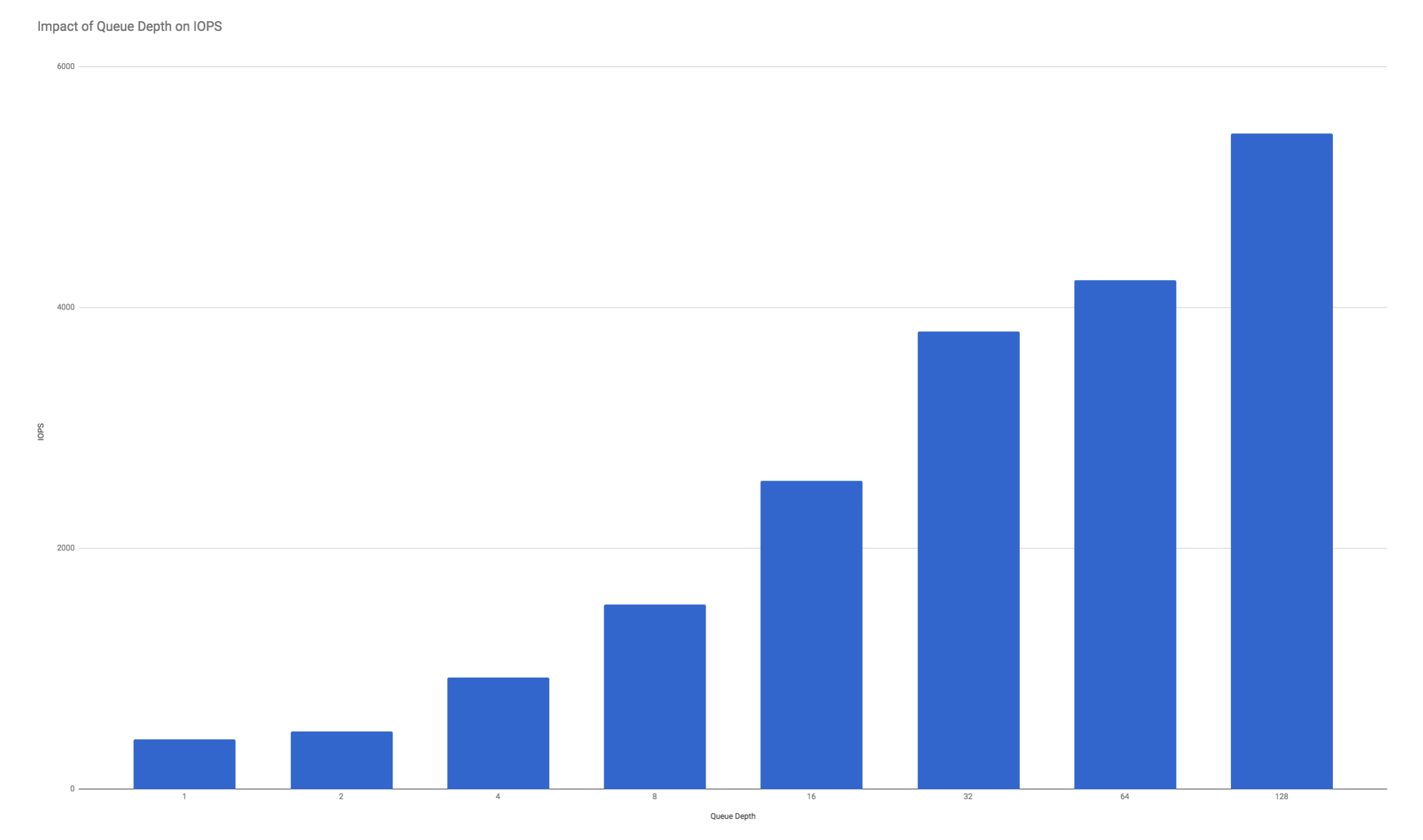
DigitalOcean的性能受到最大IOPS和最大带宽的限制,取决于哪个是先达到的。在DigitalOcean上,性能不会随着体积大小而变化。然而,由于IOPS和带宽在一定的速度上受到限制,会产生交叉效应。也就是说,在小型I/O上增加的排队深度不会达到200MB/sec的最高带宽,因为它会达到IOPS限制。
一般来说,使用32K或更大的区块大小将导致不到5000IOPS,因为它将达到200MB/秒的带宽限制,而使用区块大小或16K或更小将导致不到200MB/秒的带宽限制,因为它将达到5000IOPS。
作为一个实际的例子,让我们比较IOPS和带宽。
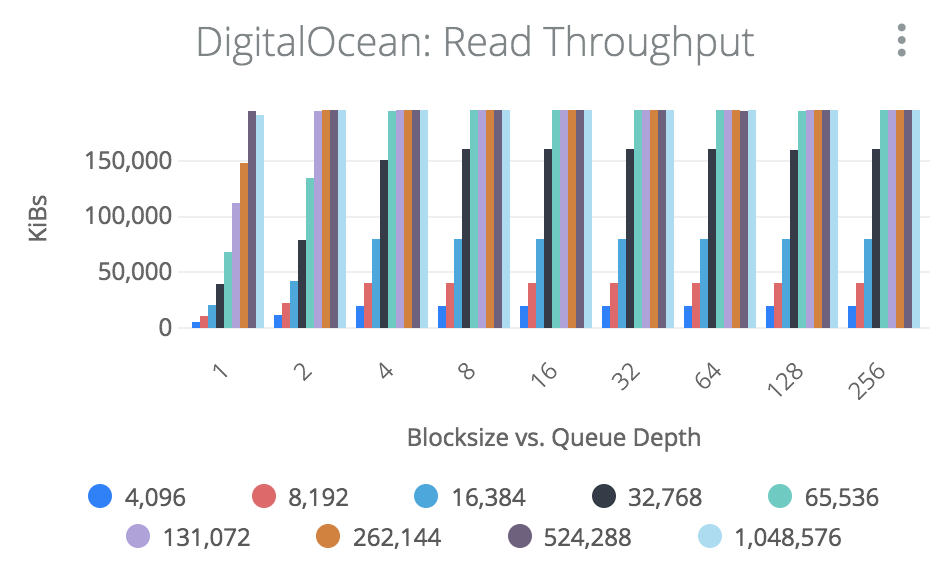
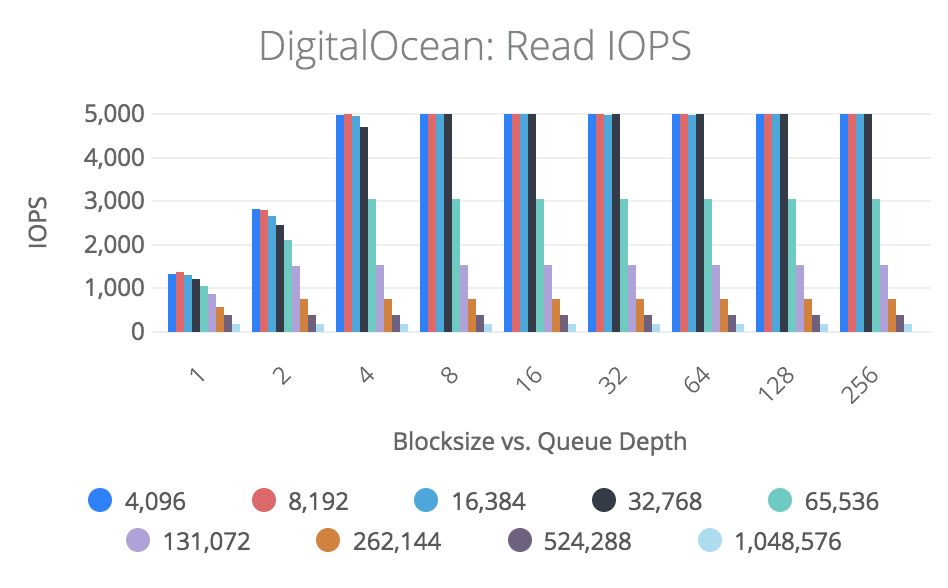
第一个图表显示一个应用程序的区块大小和排队深度的典型带宽,我们将考虑4K和256K的两个不同的区块大小。
当我们观察4K值时,我们看到它在4的队列深度上达到5000IOPS,但我们只看到它达到20MB/sec的带宽,这是因为5000IOPS * 4K = 20MB/sec。
当我们看看256K的工作负载时,我们看到它在2的排序深度达到200MB/秒,但它永远不会看到IOPS率高于800IOPS,因为200MB/秒 / 256K =800IOPS。
DigitalOcean Block Storage Volumes 针对典型的 16K-64K 文件系统工作负载进行了调整,在这些区块大小上,我们看到 IOPS 和带宽之间有一个很好的对比。
区块大小
一旦您收到模拟 I/O 工作负载的基准结果,您将能够根据应用程序的需求分析最佳设置。
结论
在本指南中,我们介绍了如何对您的 DigitalOcean 滴滴和区块存储量进行基准测量,以模拟预期的工作流程。
要继续了解如何与DigitalOcean Block Storage合作,您可以阅读)(https://andsky.com/tech/tutorials/how-to-work-with-digitalocean-block-storage-using-doctl)。