简介
InfluxDB 是一个时间序列、度量和分析数据库。时间序列数据库旨在解决存储一段时间内连续测量所得数据的问题。这些数据可能包括系统指标(如 CPU 和内存使用率)和应用程序指标(如应用程序错误和 REST 端点调用)等项目。
系统运行时间越长,积累的数据量就越大。InfluxDB 提供了高效存储这些数据的解决方案。它针对的是 DevOps、度量、传感器数据以及实时监控和分析的用例。使用 InfluxDB,您可以快速构建一个强大的实时监控框架,同时还能提供历史分析。
在本指南中,我们将介绍
- 如何在 CentOS 7 上安装和配置 InfluxDB。
- 如何从 collectd 系统统计守护进程向 InfluxDB 发送系统监控数据。
- 如何使用 InfluxDB 类 SQL 查询语言快速了解和分析受监控系统的性能。
- 如何使用 Grafana 可视化工具栈创建丰富的仪表板解决方案,以便更好地探索和展示存储在 InfluxDB 实例中的数据。
先决条件
开始之前,您需要准备以下材料:
- 一个 64 位 CentOS 7 Droplet。 服务器所需的 CPU、内存和存储空间取决于您打算收集的数据量,但通常 2GB 内存和 2 个 CPU 就足够了。
- 一个 sudo 非 root 用户。CentOS 7 初始服务器设置教程](https://andsky.com/tech/tutorials/initial-server-setup-with-centos-7) 解释了如何做到这一点。
- 4 GB 的交换空间。如何在 Centos 7 上添加交换空间教程](https://andsky.com/tech/tutorials/how-to-add-swap-on-centos-7) 介绍了如何添加交换空间。
步骤 1 - 安装 InfluxDB
在这一步中,我们将安装 InfluxDB。
InfluxDB 是作为自包含系统发布的。这意味着它没有外部依赖性;运行数据库所需的一切都包含在安装时使用的发布包中,因此安装非常简单。
首先,更新系统以确保您拥有最新的错误和安全修复。
1sudo yum -y update
接下来,安装最新版本的 InfluxDB,在撰写本文时为 v0.8.8。
1sudo yum -y install https://s3.amazonaws.com/influxdb/influxdb-latest-1.x86_64.rpm
软件包安装成功后,将在 /opt/influxdb/versions/0.8.8中安装一些文件,并在 /etc/init.d中为 InfluxDB 服务管理脚本创建一个符号链接。
第 2 步 - 配置和启动 InfluxDB
在这一步中,我们将自定义 InfluxDB 配置,禁用匿名数据报告并扩展默认读取超时限制。
InfluxDB 的主要配置文件是 /opt/influxdb/shared/config.toml。该文件使用 TOML格式,看起来与 INI 配置文件格式非常相似,由于其语义明显,因此被设计为易于阅读。
在自定义配置之前,请先备份原始配置。
1sudo cp /opt/influxdb/shared/config.toml /opt/influxdb/shared/config.toml_backup
从 0.7.1 版开始,InfluxDB 每 24 小时向 m.influxdb.com 报告一次匿名数据。为尽量减少带宽使用,我们将禁用该报告。首先,使用 nano 或您最喜欢的文本编辑器打开配置文件进行编辑。
1sudo nano /opt/influxdb/shared/config.toml
找到配置键 reporting-disabled 并将其更改为 true。编辑后,该部分应如下所示:
1[label /opt/influxdb/shared/config.toml excerpt]
2. . .
3# Change this option to true to disable reporting.
4reporting-disabled = true
5
6[logging]
7. . .
接下来,我们将更新默认读取超时,允许连接的准备时间稍长一些。读取超时控制数据库连接在关闭前允许等待的时间。
在同一配置文件中,找到配置键 read-timeout 并将其从 5s 改为 10s。
1[label /opt/influxdb/shared/config.toml excerpt]
2. . .
3# However, if a request is taking longer than this to complete, could be a problem.
4read-timeout = "10s"
5
6[input_plugins]
7. . .
保存并关闭文件,然后启动 InfluxDB 守护进程。
1sudo /etc/init.d/influxdb start
启动成功后,服务管理器脚本将提供以下输出。
1[label Successful daemon start output]
2Setting ulimit -n 65536
3Starting the process influxdb [ OK ]
4influxdb process was started [ OK ]
InfluxDB 启动后,在网络浏览器中导航到 http://your_server_ip:8083,以验证 InfluxDB 是否启动并运行。这将显示默认的管理用户界面,其中有两个部分标有连接 和** 主机名和端口设置** 。
第 3 步 - 更改默认 InfluxDB 管理凭据
每个 InfluxDB 都有一套默认的管理员凭据。为了安全起见,您应该更改此密码。
在连接 部分使用默认用户名** root** 和密码** root** 登录 InfluxDB 用户界面。数据库留空,然后单击蓝色的** 连接** 按钮。
在下一页的顶部菜单中,单击 群集管理员 。这将带您进入用户管理页面。在** 用户名** 部分,单击** 根** ,然后填写两次新密码并单击蓝色的** 更改密码** 按钮来更改密码。
最后,使用蓝色断开连接 按钮注销,然后使用新密码重新登录。
第 4 步 - 创建数据库
InfluxDB 首次设置时不包含任何实际数据库,因此我们需要创建一个数据库,最终用来存储我们的指标。
单击 Web 用户界面顶部菜单中的数据库 菜单。 在** 创建数据库** 部分的** 数据库详细信息** 下,输入** metrics** 作为数据库名称。可以保留** 碎片空间** 选项中的默认选项。 然后点击右下角蓝色的** 创建数据库** 按钮,创建数据库。
数据库创建成功后,您会看到它列在屏幕顶部,旁边有一个探索数据 链接。
InfluxDB 创建数据库屏幕](assets/influxdb/CPrvI85.png)
为了验证我们创建的数据库是否正常工作,我们可以使用数据用户界面向其中写入并检查一些示例数据。点击探索数据 链接,进入数据用户界面。您将看到以下界面:
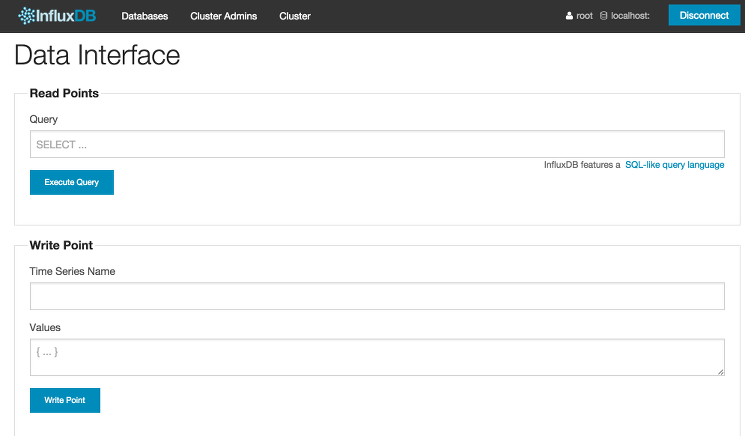
通过该界面,您可以向数据库写入一些测试数据。您还可以对数据库中存储的数据进行临时查询,并查看基本的可视化效果。让我们编写一些数据来验证数据库是否正常。
要使用网络用户界面输入数据,您需要提供系列名称和系列值。系列名称是一个不含空格的字母数字字符串,值字段应以 JSON 键值格式提供。
在写入点 部分,在** 时间序列名称** 中输入** test_metric** ,在** 值** 中输入{"值": 23.4}。然后,点击蓝色的** 写入点** 按钮输入数据。你会看到按钮旁边弹出绿色的** 200 OK** 。
使用相同的时间序列名称和以下每个值重复该过程:{"值":13.1}、{"值":13.1}、{"值":78.1}和{"值":90.4}`。请注意,我们有意将数值 13.1 写了两次。您将总共增加五个点。
现在我们已经编写了一些示例数据点,可以对其进行检查。在页面顶部的读取点 部分,在** 查询** 框中输入以下查询:
1[label InfluxDB query]
2select * from test_metric
然后按下蓝色的执行查询 按钮。查询结果将显示数据库中存储的 test_metric 系列的所有数据点。然后你会看到一个类似下面这样的图表:
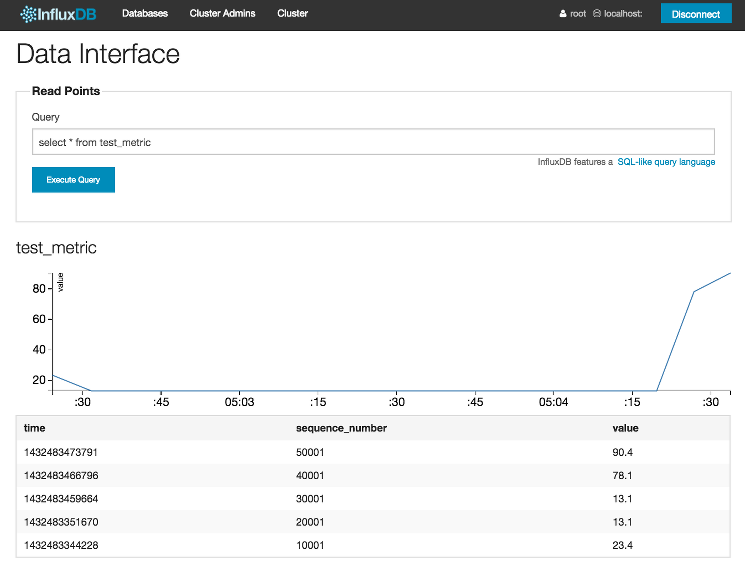
该屏幕显示的折线图总结了指标在时间序列中的变化趋势,数据表则总结了数据库中存储的数据。
我们还可以使用列标识符来缩小搜索范围。例如,要查找事件值为 13.1 的事件,请输入以下搜索查询:
1[label InfluxDB query]
2select * from test_metric where value = 13.1
这样,我们的示例数据将返回两行:
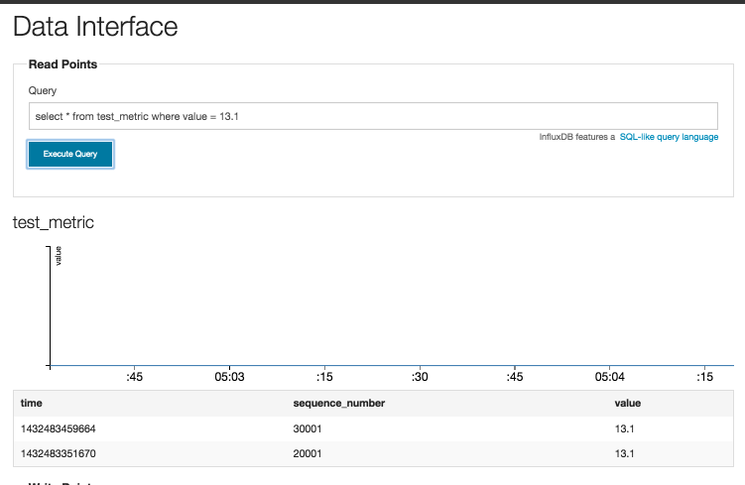
更详细地说,InfluxDB 中的数据是按时间序列组织的,在我们的示例中就是 "test_metric"。每个系列都有一组与事件相对应的数据点。我们在输入数据时创建了五个事件。每个事件都有一个时间、一个序列号和一些列,这些列与我们要测量的事件指标类似。在我们的示例中,五个事件中都有一个名为 "值 "的指标。
第 5 步 - 安装和配置 collectd
在这一步中,我们将设置并配置 collectd 以收集系统的指标。collectd 是一个收集、传输和存储性能数据的 Unix 守护进程。它有助于维护可用资源的总体情况,以检测现有的或即将出现的瓶颈。
首先,启用 EPEL(Extra Packages for Enterprise Linux)资源库:
1sudo yum -y install http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-5.noarch.rpm
然后安装 collectd。
1sudo yum -y install collectd
软件包安装成功后,将创建大量二进制文件、共享库和配置文件。需要注意的主要文件是 collectd 配置文件 /etc/collectd.conf,以及主要的 collectd 守护进程二进制文件 /usr/sbin/collectd。与之前使用 InfluxDB 时一样,让我们先复制原始配置文件。
1sudo cp /etc/collectd.conf /etc/collectd.conf_backup
接下来打开配置文件进行编辑。
1sudo nano /etc/collectd.conf
主 collectd 配置文件包含许多设置,其中大部分默认情况下都不激活,因为它们都被注释掉了。我们将取消注释并修改其中一些设置。
在文件配置顶部的全局部分,您将看到以下内容。您要编辑的部分用红色标出。
1[label /etc/collectd.conf original excerpt]
2. . .
3#Hostname "localhost"
4#FQDNLookup true
5#BaseDir "/var/lib/collectd"
6#PIDFile "/var/run/collectd.pid"
7#PluginDir "/usr/lib64/collectd"
8#TypesDB "/usr/share/collectd/types.db"
9. . .
通过删除行首的 # 取消注释 Hostname、BaseDir、PIDFile、PluginDir 和 TypesDB 字段。此外,将 Hostname 字段设置为 influxdb。完成后,文件的这一部分应如下所示:
1[label /etc/collectd.conf modified excerpt]
2
3Hostname "influxdb"
4#FQDNLookup true
5BaseDir "/var/lib/collectd"
6PIDFile "/var/run/collectd.pid"
7PluginDir "/usr/lib64/collectd"
8TypesDB "/usr/share/collectd/types.db"
接下来,向下滚动到 LoadPlugin 部分,其中按字母顺序列出了大量插件。滚动它们,删除 "LoadPlugin network "和 "LoadPlugin uptime "行开头的 "# ",取消注释。
最后,我们将配置 collectd 直接向 InfluxDB 发送数据。
向下滚动到插件配置部分。在分隔符后(如下图所示),添加网络插件配置(红色突出显示)。
1[label /etc/collectd.conf modified excerpt]
2
3. . .
4##############################################################################
5# Plugin configuration #
6#----------------------------------------------------------------------------#
7# In this section configuration stubs for each plugin are provided. A desc- #
8# ription of those options is available in the collectd.conf(5) manual page. #
9##############################################################################
10
11 <Plugin network>
12 Server "127.0.0.1" "8096"
13 </Plugin>
14
15#<Plugin "aggregation">
16. . .
现在保存并退出文件。我们应该检查配置,确保没有无意中引入任何错别字或语法错误。我们可以使用 collectd 测试配置,如下所示:
1sudo /usr/sbin/collectd -t
如果 collectd 配置没有错误,该命令将无输出返回。如果文件中有任何错误,则会在终端中列出。
配置无误后,重启 collectd 激活新配置。这可能需要一些时间。
1sudo service collectd start
第 6 步 - 配置 InfluxDB 以使用 collectd Metrics
要在 InfluxDB 中存储 collectd 收集的系统指标,我们需要启用并配置 InfluxDB collectd 输入插件。
首先,打开 InfluxDB 配置文件进行编辑。
1sudo nano /opt/influxdb/shared/config.toml
找到 input_plugins.collectd 插件配置,它看起来像这样。要修改的行用红色标出。
1[label /opt/influxdb/shared/config.toml original excerpt]
2. . .
3 # Configure the collectd api
4 [input_plugins.collectd]
5 enabled = false
6 # address = "0.0.0.0" # If not set, is actually set to bind-address.
7 # port = 25826
8 # database = ""
9 # types.db can be found in a collectd installation or on github:
10 # https://github.com/collectd/collectd/blob/master/src/types.db
11 # typesdb = "/usr/share/collectd/types.db" # The path to the collectd types.db file
12. . .
进行以下修改,使其与下面的节选内容一致:
- 将启用设置为 true。
- 将端口改为 8096。
- 将数据库更改为 metrics。
- 取消对端口、数据库和 typesdb 行的注释。
1. . .
2[label /opt/influxdb/shared/config.toml modified excerpt]
3 # Configure the collectd api
4 [input_plugins.collectd]
5 enabled = true
6 # address = "0.0.0.0" # If not set, is actually set to bind-address.
7 port = 8096
8 database = "metrics"
9 # types.db can be found in a collectd installation or on github:
10 # https://github.com/collectd/collectd/blob/master/src/types.db
11 typesdb = "/usr/share/collectd/types.db" # The path to the collectd types.db file
12. . .
保存文件并重启 InfluxDB 以激活新配置。
1sudo /etc/init.d/influxdb restart
接下来,让我们检查 InfluxDB 是否从 collectd 接收到系统指标。在用户界面的数据接口 中,也就是我们在步骤 5 中离开的地方,在** 读取点** 下的** 查询** 文本框中输入以下查询,然后按下蓝色的** 执行查询** 按钮。
1[label InfluxDB query]
2list series
如果从 collectd 接收到数据,则会看到类似下面的一长串序列:
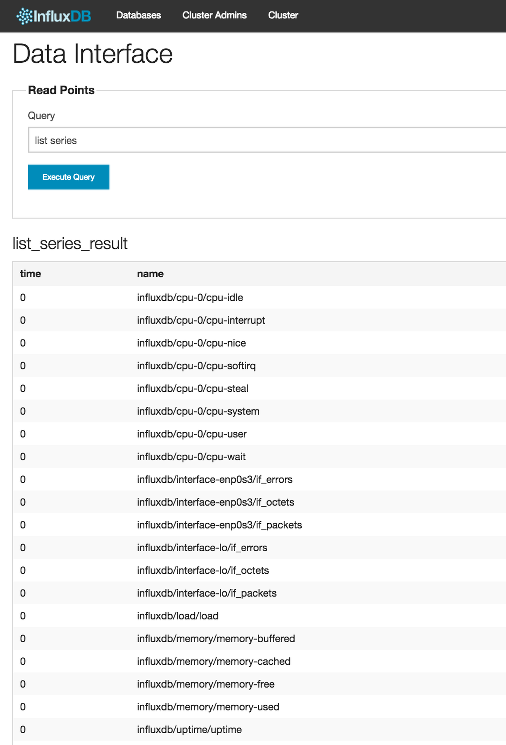
现在,我们可以像步骤 5 一样,通过探索这些数据来分析系统的性能。例如,发出以下查询就可以观察系统的内存使用情况:
1[label InfluxDB query]
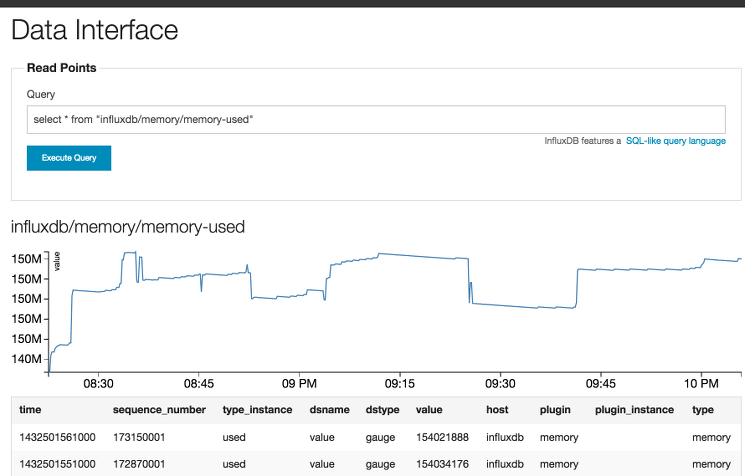
2select * from "influxdb/memory/memory-used"
数据显示结果清楚地显示了 InfluxDB 实例记录的内存使用量变化。下面是一个示例:
第 7 步 - 安装并启动 Grafana
我们可以使用 InfluxDB 的 Web 界面来探索数据,并从时间序列数据中可视化系统趋势。不过,网页用户界面有些简陋,并不适合展示我们正在收集的度量数据。
Grafana是一个功能丰富的度量仪表盘,可与 InfluxDB 完美集成。Grafana 将为我们提供创建仪表盘的能力,这些仪表盘可提供系统概览,适合共享或用作墙面展示。
要安装 Grafana,请输入以下命令。
1sudo yum -y install https://grafanarel.s3.amazonaws.com/builds/grafana-2.0.2-1.x86_64.rpm
首先重新加载 systemd 的守护进程,启动 Grafana 堆栈。
1sudo systemctl daemon-reload
然后启动 Grafana 服务器。
1sudo systemctl start grafana-server
最后,检查其状态。
1sudo systemctl status grafana-server
启动成功后,服务管理器状态将确认 Grafana 服务已启动,网络用户界面正在提供服务。您在终端中收到的输出将以以下内容开头:
1[label Grafana status output]
2grafana-server.service - Starts and stops a single grafana instance on this system
3 Loaded: loaded (/usr/lib/systemd/system/grafana-server.service; disabled)
4 Active: active (running) since Tue 2015-06-02 18:59:17 EDT; 3s ago
5. . .
第 8 步 - 更改默认的 Grafana 管理凭据
每个 Grafana 实例都随附一组默认的管理员凭据。为了安全起见,您应该更改该密码。您可以使用 Web UI 或 Grafana 配置文件来更改密码,但为了方便使用,我们将使用 Web UI。
Grafana 启动后,导航至 http://your_server_ip:3000。使用默认用户名 admin 和密码** admin** 登录 Grafana UI。点击屏幕左上角的 Graphana 徽标,然后在出现的菜单中点击** admin** 。这将带您进入以下配置文件管理页面。
点击顶部标题菜单中的更改密码 链接。在相应字段中填写新密码,然后点击** 更改密码** 。
第 9 步 - 将 InfluxDB 数据库添加到 Grafana
在这一步中,我们将在 Grafana 中添加 InfluxDB 数据库作为源。
要添加数据源,请单击顶部标题中的 Grafana 图标打开侧菜单。在侧菜单中,单击数据源 。单击顶部标题中的** 添加新** 链接,弹出数据源定义屏幕。
使用以下设置填充此屏幕:
- 名称 : influxdb
- 类型 :从下拉菜单中选择* InfluxDB 0.8.x** 。
- 默认 :确保选中该复选框。默认数据源意味着将为新面板预选该数据源。 Url :http://localhost:8086 访问 :从下拉菜单中选择** 代理** 。
- 基本认证 :不选择该复选框。
- 数据库 :度量
- 用户 :根用户
- 密码 :您在步骤 4 中选择的 InfluxDB 根数据库密码。
最后,点击屏幕下方的绿色添加 按钮。
第 10 步 - 创建 Grafana 仪表板
Grafana 提供了一种功能强大但用户友好的方法来创建信息丰富的图表和仪表盘。在本步骤中,我们将创建一个系统概览仪表盘,以显示我们在 InfluxDB 中收集的系统指标的趋势。
在 Grafana 中,仪表盘_是您工作的基本面板。仪表盘包含_显示元素(如图表和文本面板)。显示元素包含用于从数据源(本例中为 InfluxDB)获取数据的查询。因此,我们首先需要创建一个空的仪表盘,作为显示的基础。
导航至 Grafana 主页 http://your_server_ip:3000。单击顶部标题中的 Home 链接,弹出仪表盘列表屏幕。在屏幕底部,点击** + New** 。这将为您带来新的空白仪表板。
单击仪表板标题菜单中的齿轮,然后单击 设置 。您将看到以下界面:
此屏幕用于更改仪表板的主要设置。将 Title 字段从** New dashboard** 更改为** System Overview** 。接下来,单击顶部标题中的软盘图标保存仪表板。
现在,我们将在仪表板上填充显示元素,以创建一个可视化的系统概览信息辐射器。
在仪表板上单击行控制菜单,即位于仪表板左上方的绿色小矩形。在该菜单中,将鼠标悬停在添加面板 上,然后点击** 图表** 。这将在仪表板上创建一个空白图表。
点击图表顶部的图表标题,上面写着无标题(点击此处) ,然后点击菜单中的** 编辑** 。这将带您进入图表管理菜单。单击** 常规** 选项卡,将** 标题** 字段更改为** 网络** 。
接下来,点击 "指标 "选项卡,进入查询生成器。在** 系列** 字段中,我们可以指定希望用作图表数据源的指标。开始键入** 接口** ;然后您将看到一个自动完成选择。选择** influxdb/interface-eth0/if_errors** 指标。
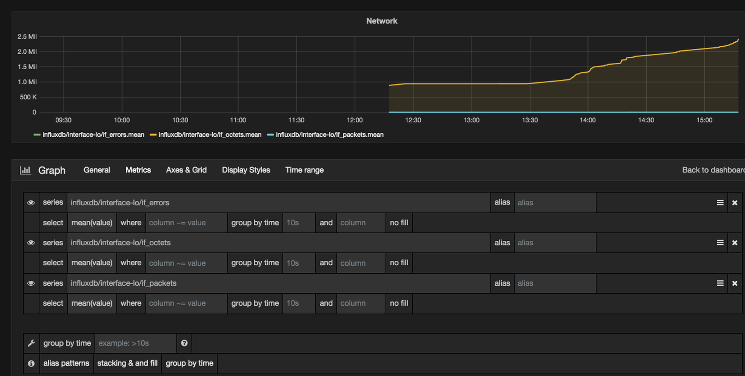
接下来,点击图表管理菜单底部的 + 添加查询 。这将在查询生成器中添加第二个查询行。使用与之前相同的方法为** influxdb/interface-eth0/if_octets** 指标添加查询,并再次为** influxdb/interface-eth0/if_packets** 指标添加查询。
添加三个查询后,您的度量屏幕应该如下所示:
最后,单击返回仪表板 链接,进入仪表板,其中包含显示系统网络趋势的图表,然后单击顶部标题中的软盘图标,保存新的显示图表和仪表板。
可以重复上述过程来创建可视化图表,以显示存储到 InfluxDB 系列中的任何数据。
结论
InfluxDB 是存储和分析时间序列数据(如监控运行系统性能时生成的数据)的强大工具。将 InfluxDB 与 Grafana 结合使用可提供高效存储和可视化此类数据的解决方案。
完成本教程后,您应该对 InfluxDB 有了大致的了解:如何安装、如何配置数据库的使用以及如何向其发送数据。此外,您还可以设置 Grafana 并使用它构建一个通用的系统监控仪表盘。
InfluxDB 和 Grafana 还有许多其他功能和用例。您可以使用 InfluxDB 提供的聚合函数对系统行为进行更深入的分析。您可能还希望开始收集分布式系统的数据,以便比较多个系统的性能,或者开始收集和分析其他非系统级指标类型(例如,每个用户的页面访问次数或 REST 端点的 API 调用次数)。InfluxDB 非常适合此类数据,InfluxDB 官方文档中列出了许多工具和库。