作者选择了自由和开放源码基金作为为国家写作计划的一部分接受捐赠。
简介
数据库监控是系统跟踪各种指标的持续过程,这些指标可显示数据库的性能如何。通过观察性能数据,您可以获得有价值的见解,找出可能的瓶颈,并找到提高数据库性能的其他方法。此类系统通常会在出现问题时发出警报,通知管理员。收集到的统计数据不仅可用于改进数据库的配置和工作流程,还可用于改进客户端应用程序的配置和工作流程。
使用Elastic Stack(ELK 堆栈)监控受管数据库的好处是,它能很好地支持搜索,并能快速摄取新数据。它并不擅长更新数据,但对于监控和日志目的来说,这种权衡是可以接受的,因为过去的数据几乎从未改变过。Elasticsearch提供了强大的数据查询手段,你可以通过Kibana来更好地了解数据库在不同时间段的表现。这样,您就可以将数据库负载与实际事件关联起来,从而深入了解数据库的使用情况。
在本教程中,你将通过 Logstash 将 Redis INFO 命令生成的数据库指标导入 Elasticsearch。这需要配置 Logstash 定期运行该命令,解析其输出,然后立即将其发送到 Elasticsearch 进行索引。导入的数据随后可以在 Kibana 中进行分析和可视化。在本教程结束时,你将拥有一个自动系统,可以调入 Redis 统计数据供日后分析。
先决条件
- 一台 Ubuntu 18.04 服务器,至少有 8GB 内存、root 权限和一个二级非 root 账户。您可以按照本初始服务器设置指南进行设置。在本教程中,非 root 用户为
sammy。 - 服务器上安装 Java 8。有关安装说明,请访问 How To Install Java with
apton Ubuntu 18.04,并按照第一步中概述的命令进行操作。您不需要安装 Java 开发工具包(JDK)。 - 在服务器上安装 Nginx。有关如何安装的指南,请参阅如何在 Ubuntu 18.04 上安装 Nginx教程。
- 在服务器上安装 Elasticsearch 和 Kibana。完成 如何在 Ubuntu 18.04 上安装 Elasticsearch、Logstash 和 Kibana(Elastic Stack) 教程的前两个步骤。
- 从 DigitalOcean 提供一个有连接信息的 Redis 托管数据库。确保服务器的 IP 地址在白名单上。有关使用 DigitalOcean 控制面板创建 Redis 数据库的指南,请访问 Redis 快速入门指南。
- 根据How To Connect to a Managed Database on Ubuntu 18.04教程,在服务器上安装Redli。
第 1 步 - 安装和配置 Logstash
在本节中,您将安装 Logstash 并对其进行配置,以便从 Redis 数据库集群中提取统计数据,然后将其解析并发送到 Elasticsearch 以编制索引。
首先使用以下命令安装 Logstash:
1sudo apt install logstash -y
安装 Logstash 后,启用服务,使其在启动时自动启动:
1sudo systemctl enable logstash
在配置 Logstash 以获取统计数据之前,让我们先看看数据本身是什么样子的。要连接到 Redis 数据库,请前往受管数据库控制面板,在连接详细信息 面板下,从下拉菜单中选择** 标志** :
数据库管理控制面板](assets/redis_elk/step1.png)
你将看到 Redli 客户端的预配置命令,你将用它来连接数据库。点击 复制 ,然后在服务器上运行以下命令,用刚才复制的命令替换 redli_flags_command:
1redli_flags_command info
由于该命令的输出结果较长,我们将分成不同部分进行解释。
在 Redis info 命令的输出中,部分以 # 标记,表示注释。值以 key:value 的形式填充,这使得它们相对容易解析。
服务器 "部分包含有关 Redis 构建的技术信息,如版本和基于的 Git 提交,而 "客户 "部分则提供当前打开的连接数。
1[secondary_label Output]
2# Server
3redis_version:6.2.6
4redis_git_sha1:4f4e829a
5redis_git_dirty:1
6redis_build_id:5861572cb79aebf3
7redis_mode:standalone
8os:Linux 5.11.12-300.fc34.x86_64 x86_64
9arch_bits:64
10multiplexing_api:epoll
11atomicvar_api:atomic-builtin
12gcc_version:11.2.1
13process_id:79
14process_supervised:systemd
15run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
16tcp_port:25060
17server_time_usec:1640878632737564
18uptime_in_seconds:1679
19uptime_in_days:0
20hz:10
21configured_hz:10
22lru_clock:13488680
23executable:/usr/bin/redis-server
24config_file:/etc/redis.conf
25io_threads_active:0
26
27# Clients
28connected_clients:4
29cluster_connections:0
30maxclients:10032
31client_recent_max_input_buffer:24
32client_recent_max_output_buffer:0
33...
内存 "确认 Redis 为自己分配了多少内存,以及可能使用的最大内存量。如果内存开始耗尽,它会使用你在控制面板中指定的策略释放键(显示在此输出中的 maxmemory_policy 字段)。
1[secondary_label Output]
2...
3# Memory
4used_memory:977696
5used_memory_human:954.78K
6used_memory_rss:9977856
7used_memory_rss_human:9.52M
8used_memory_peak:977696
9used_memory_peak_human:954.78K
10used_memory_peak_perc:100.00%
11used_memory_overhead:871632
12used_memory_startup:810128
13used_memory_dataset:106064
14used_memory_dataset_perc:63.30%
15allocator_allocated:947216
16allocator_active:1273856
17allocator_resident:3510272
18total_system_memory:1017667584
19total_system_memory_human:970.52M
20used_memory_lua:37888
21used_memory_lua_human:37.00K
22used_memory_scripts:0
23used_memory_scripts_human:0B
24number_of_cached_scripts:0
25maxmemory:455081984
26maxmemory_human:434.00M
27maxmemory_policy:noeviction
28allocator_frag_ratio:1.34
29allocator_frag_bytes:326640
30allocator_rss_ratio:2.76
31allocator_rss_bytes:2236416
32rss_overhead_ratio:2.84
33rss_overhead_bytes:6467584
34mem_fragmentation_ratio:11.43
35mem_fragmentation_bytes:9104832
36mem_not_counted_for_evict:0
37mem_replication_backlog:0
38mem_clients_slaves:0
39mem_clients_normal:61504
40mem_aof_buffer:0
41mem_allocator:jemalloc-5.1.0
42active_defrag_running:0
43lazyfree_pending_objects:0
44...
在 "持久性 "部分,你可以看到 Redis 上一次将其存储的密钥保存到磁盘的时间,以及是否成功。统计 "部分提供了与客户端和集群内连接相关的数据、请求的密钥被找到(或未找到)的次数等。
1[secondary_label Output]
2...
3# Persistence
4loading:0
5current_cow_size:0
6current_cow_size_age:0
7current_fork_perc:0.00
8current_save_keys_processed:0
9current_save_keys_total:0
10rdb_changes_since_last_save:0
11rdb_bgsave_in_progress:0
12rdb_last_save_time:1640876954
13rdb_last_bgsave_status:ok
14rdb_last_bgsave_time_sec:1
15rdb_current_bgsave_time_sec:-1
16rdb_last_cow_size:217088
17aof_enabled:0
18aof_rewrite_in_progress:0
19aof_rewrite_scheduled:0
20aof_last_rewrite_time_sec:-1
21aof_current_rewrite_time_sec:-1
22aof_last_bgrewrite_status:ok
23aof_last_write_status:ok
24aof_last_cow_size:0
25module_fork_in_progress:0
26module_fork_last_cow_size:0
27
28# Stats
29total_connections_received:202
30total_commands_processed:2290
31instantaneous_ops_per_sec:0
32total_net_input_bytes:38034
33total_net_output_bytes:1103968
34instantaneous_input_kbps:0.01
35instantaneous_output_kbps:0.00
36rejected_connections:0
37sync_full:0
38sync_partial_ok:0
39sync_partial_err:0
40expired_keys:0
41expired_stale_perc:0.00
42expired_time_cap_reached_count:0
43expire_cycle_cpu_milliseconds:29
44evicted_keys:0
45keyspace_hits:0
46keyspace_misses:0
47pubsub_channels:0
48pubsub_patterns:0
49latest_fork_usec:452
50total_forks:1
51migrate_cached_sockets:0
52slave_expires_tracked_keys:0
53active_defrag_hits:0
54active_defrag_misses:0
55active_defrag_key_hits:0
56active_defrag_key_misses:0
57tracking_total_keys:0
58tracking_total_items:0
59tracking_total_prefixes:0
60unexpected_error_replies:0
61total_error_replies:0
62dump_payload_sanitizations:0
63total_reads_processed:2489
64total_writes_processed:2290
65io_threaded_reads_processed:0
66io_threaded_writes_processed:0
67...
通过查看 "复制 "下的 "角色",你就能知道自己连接的是主节点还是副本节点。该部分的其余部分提供了当前连接的副本数量以及副本相对于主节点所缺少的数据量。如果连接的实例是副本,则可能会有其他字段。
<$>[注] 注: Redis项目在其文档和各种命令中使用 "主 "和 "从 "两个术语。DigitalOcean 通常更喜欢使用 "主 "和 "副本 "这两个替代术语。本指南将尽可能默认使用 "主服务器 "和 "副本服务器 "这两个术语,但请注意,在某些情况下,"主服务器 "和 "从服务器 "这两个术语不可避免地会出现。 <$>
1[secondary_label Output]
2...
3# Replication
4role:master
5connected_slaves:0
6master_failover_state:no-failover
7master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
8master_replid2:0000000000000000000000000000000000000000
9master_repl_offset:0
10second_repl_offset:-1
11repl_backlog_active:0
12repl_backlog_size:45088768
13repl_backlog_first_byte_offset:0
14repl_backlog_histlen:0
15...
在 "CPU "下,你会看到 Redis 当前消耗的系统 CPU 能力("used_cpu_sys")和用户 CPU 能力("used_cpu_user")。集群 "部分只包含一个唯一字段,即 "cluster_enabled",用于表示 Redis 集群正在运行。
1[secondary_label Output]
2...
3# CPU
4used_cpu_sys:1.617986
5used_cpu_user:1.248422
6used_cpu_sys_children:0.000000
7used_cpu_user_children:0.001459
8used_cpu_sys_main_thread:1.567638
9used_cpu_user_main_thread:1.218768
10
11# Modules
12
13# Errorstats
14
15# Cluster
16cluster_enabled:0
17
18# Keyspace
Logstash 的任务是定期在 Redis 数据库上运行 info 命令(与刚才的操作类似),解析结果并将其发送到 Elasticsearch。之后,你就可以通过 Kibana 访问这些结果。
您将在 Logstash 存储配置文件的 /etc/logstash/conf.d 目录下名为 redis.conf 的文件中存储在 Elasticsearch 中索引 Redis 统计数据的配置。作为服务启动时,它会在后台自动运行这些文件。
使用自己喜欢的编辑器(如 nano)创建 redis.conf:
1sudo nano /etc/logstash/conf.d/redis.conf
添加以下几行
1[label /etc/logstash/conf.d/redis.conf]
2input {
3 exec {
4 command => "redis_flags_command info"
5 interval => 10
6 type => "redis_info"
7 }
8}
9
10filter {
11 kv {
12 value_split => ":"
13 field_split => "\r\n"
14 remove_field => [ "command", "message" ]
15 }
16
17 ruby {
18 code =>
19 "
20 event.to_hash.keys.each { |k|
21 if event.get(k).to_i.to_s == event.get(k) # is integer?
22 event.set(k, event.get(k).to_i) # convert to integer
23 end
24 if event.get(k).to_f.to_s == event.get(k) # is float?
25 event.set(k, event.get(k).to_f) # convert to float
26 end
27 }
28 puts 'Ruby filter finished'
29 "
30 }
31}
32
33output {
34 elasticsearch {
35 hosts => "http://localhost:9200"
36 index => "%{type}"
37 }
38}
请记住,将 redis_flags_command 替换为控制面板中显示的命令,即本步骤前面使用的命令。
您需要定义 "输入 "和 "输出"。"输入 "是一组将在收集的数据上运行的过滤器,而 "输出 "则是将过滤后的数据发送到 Elasticsearch。输入由 "exec "命令组成,它会在设定的 "间隔 "时间(以秒为单位)后定期在服务器上运行 "命令"。它还指定了一个 type 参数,用于定义 Elasticsearch 索引时的文档类型。exec 块会传递一个对象,其中包含两个字段,即 command 和 message 字符串。command "字段将包含运行的命令,"message "字段将包含其输出。
有两个过滤器会按顺序运行从输入中收集的数据。kv 过滤器代表键值过滤器,是 Logstash 的内置过滤器。它用于解析一般形式为 "keyvalue_separatorvalue "的数据,并提供用于指定值和字段分隔符的参数。字段分隔符与字符串有关,用于将一般格式的数据相互分隔开来。在 Redis INFO 命令的输出中,字段分隔符 (field_split) 是新行,值分隔符 (value_split) 是:`。不符合定义形式的行将被丢弃,包括注释。
要配置 kv 过滤器,需要将 : 传递给 value_split 参数,将 \r\n(表示新行)传递给 field_split 参数。您还可以命令它删除当前数据对象中的 command 和 message 字段,方法是将它们作为数组元素传给 remove_field ,因为它们包含的数据现在已无用处。
kv过滤器在设计上将其解析的值表示为字符串(文本)类型。这就产生了一个问题,因为 Kibana 无法轻松处理字符串类型,即使它实际上是一个数字。为了解决这个问题,您需要使用自定义 Ruby 代码,尽可能将纯数字字符串转换为数字。第二个过滤器是一个ruby块,提供一个code` 参数,接受一个包含要运行代码的字符串。
event 是 Logstash 提供给代码的变量,包含过滤器管道中的当前数据。如前所述,过滤器是一个接一个运行的,这意味着 Ruby 过滤器将接收来自 kv 过滤器的解析数据。Ruby 代码本身会将 event 转换为哈希值,并遍历键值,然后检查与键值相关的值是否可以表示为整数或浮点数(带小数点的数字)。如果可以,就用解析后的数字替换字符串值。当循环结束时,它会打印出一条信息("Ruby 过滤器已完成")来报告进度。
输出会将处理过的数据发送到 Elasticsearch 进行索引。生成的文档将存储在 redis_info 索引中,该索引在输入中定义,并作为参数传递给输出块。
保存并关闭文件。
您使用 apt 安装了 Logstash,并将其配置为定期从 Redis 请求统计数据、处理这些数据并将其发送到 Elasticsearch 实例。
第 2 步 - 测试 Logstash 配置
现在,您将运行 Logstash 测试配置,以验证它是否能正确提取数据。
Logstash 支持通过向 -f 参数传递文件路径来运行特定配置。运行以下命令测试上一步中的新配置:
1sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/redis.conf
显示输出结果可能需要一些时间,但你很快就会看到类似下面的内容:
1[secondary_label Output]
2Using bundled JDK: /usr/share/logstash/jdk
3OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
4WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
5Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
6[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
7[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
8[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
9[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
10[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
11[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
12[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
13[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
14[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
15[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
16[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
17[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
18[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
19[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
20[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
21[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
22[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
23[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
24[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
25[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
26[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
27[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
28[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
29Ruby filter finished
30Ruby filter finished
31Ruby filter finished
32...
你会看到 "Ruby filter finished"(Ruby 过滤器已完成)信息以固定间隔打印(上一步中设置为 10 秒),这意味着统计数据正在发送到 Elasticsearch。
点击键盘上的 CTRL + C 可以退出 Logstash。如前所述,Logstash 作为服务启动时,会在后台自动运行 /etc/logstash/conf.d 下的所有配置文件。运行以下命令启动它:
1sudo systemctl start logstash
你已经运行 Logstash 检查它是否能连接到 Redis 集群并收集数据。接下来,你将在 Kibana 中探索一些统计数据。
第 3 步 - 在 Kibana 中探索导入的数据
在本节中,您将在 Kibana 中探索描述数据库性能的统计数据并将其可视化。
在 Web 浏览器中,导航到作为先决条件的一部分暴露了 Kibana 的域。您将看到默认的欢迎页面:
Kibana - 欢迎页面](assets/68157/jDdYHaM.png)
在探索 Logstash 发送到 Elasticsearch 的数据之前,首先需要将 redis_info 索引添加到 Kibana。为此,首先从欢迎页面选择自行探索 ,然后打开左上角的汉堡包菜单。在** 分析** 下,点击** 发现** 。
然后,Kibana 会提示您创建新的索引模式:
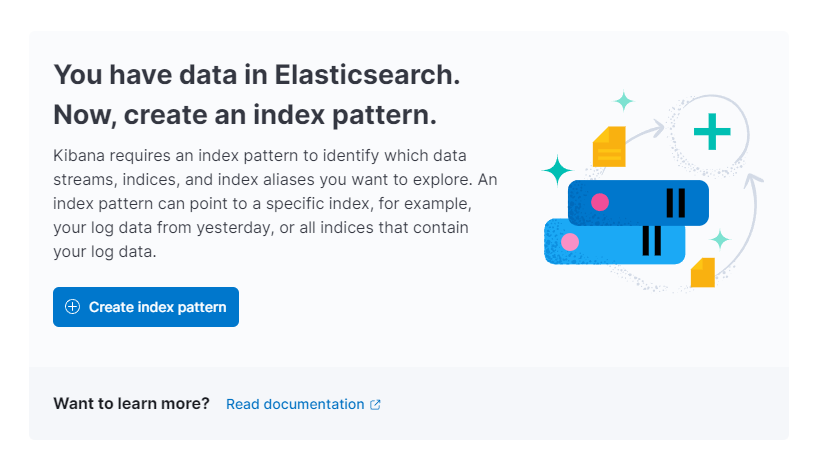
按下创建索引模式 。你会看到一个创建新** 索引模式** 的表单。Kibana 中的索引模式提供了一种一次性从多个 Elasticsearch 索引中提取数据的方法,并可仅用于探索一个索引。

在右侧,Kibana 会列出所有可用的索引,例如您已配置 Logstash 以使用的 redis_info。在名称 文本字段中键入它,并从下拉列表中选择 @timestamp作为** 时间戳字段** 。完成后,点击下方的** 创建索引模式** 按钮。
要创建和查看现有的可视化效果,请打开汉堡菜单。在分析 下,选择** 仪表板** 。加载完毕后,按** 创建可视化** 开始创建新的可视化:
Kibana - 新可视化](assets/68157/GYAdF4B.png)
左侧面板提供了 Kibana 可用于绘制可视化的值列表,这些值将显示在屏幕中央部分。屏幕右上方是日期范围选择器。如果在可视化中使用了 @timestamp 字段,Kibana 将只显示属于范围选择器中指定的时间间隔的数据。
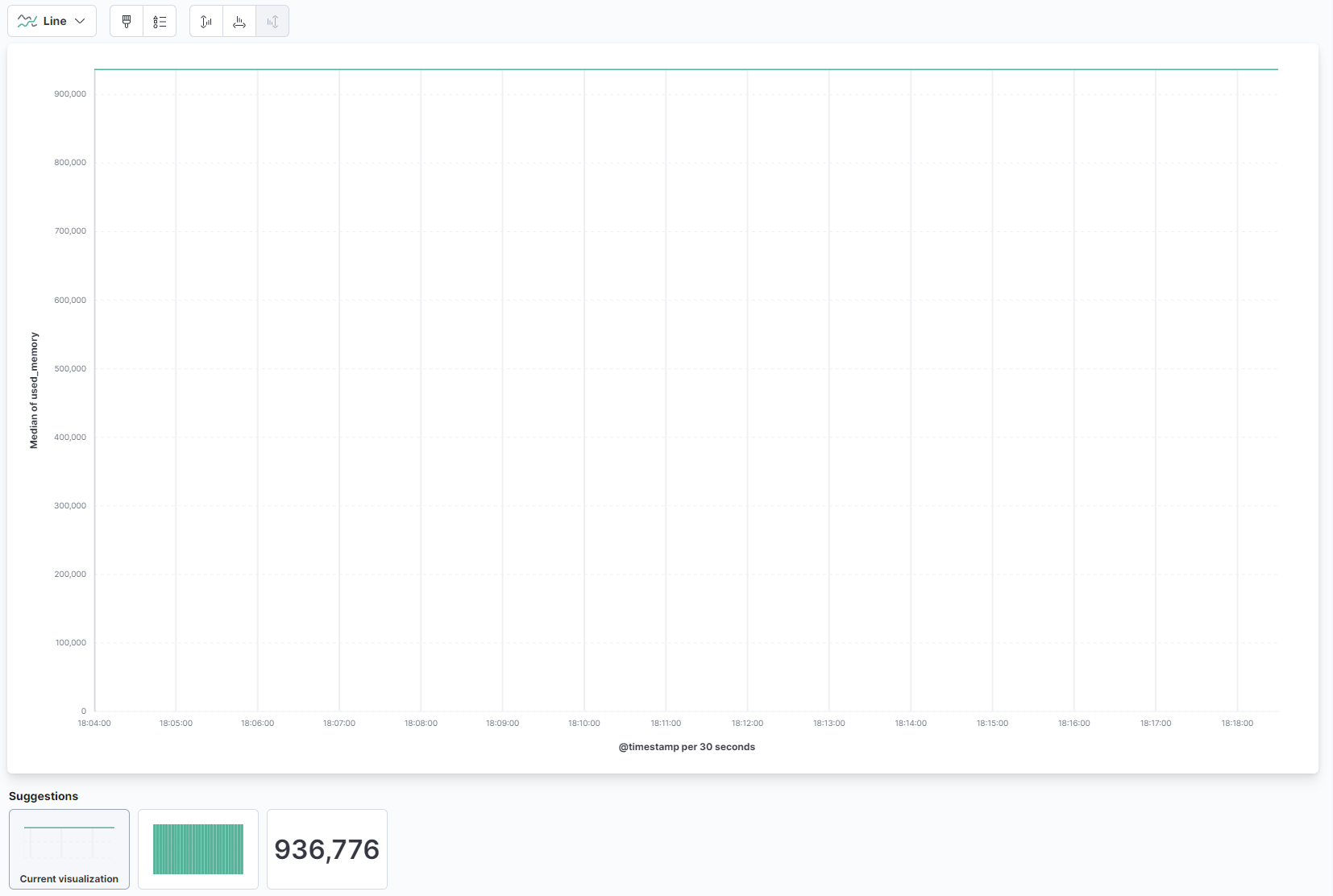
从页面主要部分的下拉菜单中,选择线和区域 部分下的** 线** 。然后,从左侧列表中找到 "used_memory "字段,并将其拖到中央部分。你很快就会看到一个线形可视化图,显示了不同时间段内存使用量的中位数:
在右侧,您可以配置横轴和纵轴的处理方式。在这里,您可以按下显示的坐标轴,将纵轴设置为显示平均值而非中位数:
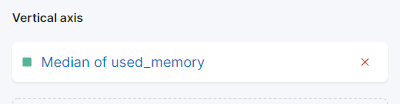
您可以选择不同的功能,或提供自己的功能:
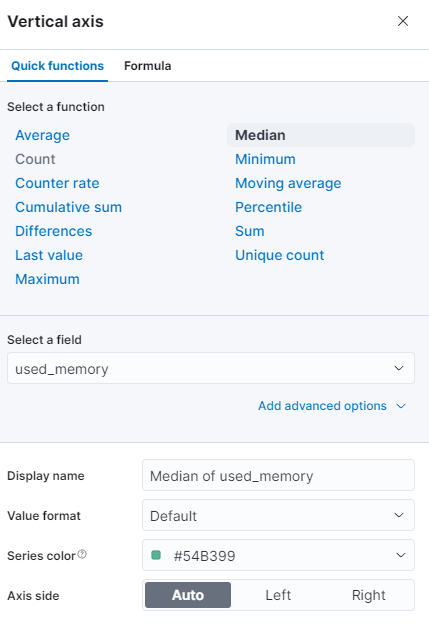
图表将立即用更新的数值刷新。
在本步骤中,您使用 Kibana 可视化了受管 Redis 数据库的内存使用情况。这将让你更好地了解数据库的使用情况,从而帮助你优化客户端应用程序和数据库本身。
结论
现在,您已在服务器上安装了 Elastic stack,并配置为定期从受管 Redis 数据库中提取统计数据。您可以使用 Kibana 或其他合适的软件对数据进行分析和可视化,这将有助于您对数据库的运行情况收集有价值的见解和现实世界中的相关信息。
有关 Redis 托管数据库的更多信息,请访问产品文档。如果你想使用另一种可视化类型来展示数据库统计信息,请查看 Kibana docs 了解更多说明。