作者选择了自由和开放源码基金作为为国家写作计划的一部分接受捐赠。
简介
数据库监控是系统跟踪各种指标的持续过程,这些指标可显示数据库的性能如何。通过观察性能数据,您可以获得有价值的见解,找出可能的瓶颈,并找到提高数据库性能的其他方法。此类系统通常会实施警报功能,在出现问题时通知管理员。收集到的统计数据不仅可用于改进数据库的配置和工作流程,还可用于改进客户端应用程序的配置和工作流程。
使用Elastic Stack(ELK 堆栈)监控受管数据库的好处是,它能很好地支持搜索,并能快速摄取新数据。它并不擅长更新数据,但就监控和日志记录目的而言,这种权衡是可以接受的,因为过去的数据几乎从未改变过。Elasticsearch提供了强大的数据查询手段,你可以通过Kibana来更好地了解数据库在不同时间段的表现。这样,您就可以将数据库负载与实际事件关联起来,从而深入了解数据库的使用情况。
在本教程中,您将通过 Logstash 将 PostgreSQL 统计收集器 生成的数据库指标导入 Elasticsearch。这需要配置 Logstash,使用PostgreSQL JDBC 连接器从数据库中提取数据,然后立即发送到 Elasticsearch 进行索引。导入的数据随后可以在 Kibana 中进行分析和可视化。然后,如果你的数据库是全新的,你可以使用 PostgreSQL 基准测试工具 pgbench,创建更有趣的可视化效果。最后,你就会拥有一个自动系统,可以提取 PostgreSQL 统计数据供日后分析。
先决条件
- 一台 Ubuntu 18.04 服务器,至少有 8GB 内存、root 权限和一个二级非 root 账户。您可以按照本初始服务器设置指南进行设置。在本教程中,非 root 用户为
sammy。 - 服务器上安装 Java 8。有关安装说明,请访问 How To Install Java with
apton Ubuntu 18.04。 - 服务器上安装 Nginx。有关如何安装的指南,请参阅 如何在 Ubuntu 18.04 上安装 Nginx。
- 在服务器上安装 Elasticsearch 和 Kibana。完成 如何在 Ubuntu 18.04 上安装 Elasticsearch、Logstash 和 Kibana(Elastic Stack) 教程的前两个步骤。
- 从 DigitalOcean 配置一个 PostgreSQL 13 托管数据库,并提供连接信息。确保服务器的 IP 地址在白名单上。有关使用DigitalOcean控制面板创建PostgreSQL托管数据库的指南,请访问PostgreSQL快速入门指南。
第 1 步 - 设置 Logstash 和 PostgreSQL JDBC 驱动程序
在本节中,您将安装 Logstash 并下载 PostgreSQL JDBC 驱动程序,以便 Logstash 能够连接到托管数据库。
首先使用以下命令安装 Logstash:
1sudo apt install logstash -y
安装 Logstash 后,启用服务,使其在启动时自动启动:
1sudo systemctl enable logstash
Logstash 是用 Java 编写的,因此要连接到 PostgreSQL,需要 PostgreSQL JDBC(Java 数据库连接)库在其运行的系统上可用。由于内部限制,Logstash 只有在 /usr/share/logstash/logstash-core/lib/jars目录下找到该库,才能正确加载该库。
前往 JDBC 库的 下载页面,复制最新版本的链接。然后,运行以下命令使用 curl 下载:
1sudo curl https://jdbc.postgresql.org/download/postgresql-42.3.3.jar -o /usr/share/logstash/logstash-core/lib/jars/postgresql-jdbc.jar
在撰写本文时,该库的最新版本为42.3.3,支持的运行时版本为 Java 8。请确保下载的是最新版本;将其与 JDBC 和 Logstash 都支持的正确 Java 版本配对。Logstash 将其配置文件存储在 /etc/logstash/conf.d,其本身存储在 /usr/share/logstash/bin。
您已使用 apt 安装了 Logstash,并下载了 PostgreSQL JDBC 库,这样 Logstash 就可以使用它连接到托管数据库。下一步,您将配置 Logstash 以从中提取统计数据。
第 2 步 - 配置 Logstash 以获取统计数据
在本节中,您将配置 Logstash 从托管的 PostgreSQL 数据库中提取指标。
您将配置 Logstash 以监控 PostgreSQL 中的三个系统数据库,即
pg_stat_database: 提供每个数据库的统计信息,包括名称、连接数、事务、回滚、查询数据库返回的行、死锁等。它有一个stats_reset字段,用于指定上次重置统计数据的时间。pg_stat_user_tables: 提供用户创建的每个表的统计数据,如插入、删除和更新的行数。- pg_stat_user_indexes`:收集用户创建表中所有索引的数据,如特定索引被扫描的次数。
在 Elasticsearch 中索引 PostgreSQL 统计数据的配置将存储在 Logstash 存储配置文件的 /etc/logstash/conf.d 目录下名为 postgresql.conf 的文件中。作为服务启动时,它会在后台自动运行这些文件。
使用您喜欢的编辑器(如 nano)创建 postgresql.conf 文件:
1sudo nano /etc/logstash/conf.d/postgresql.conf
添加以下几行
1[label /etc/logstash/conf.d/postgresql.conf]
2input {
3 # pg_stat_database
4 jdbc {
5 jdbc_driver_library => ""
6 jdbc_driver_class => "org.postgresql.Driver"
7 jdbc_connection_string => "jdbc:postgresql://host:port/defaultdb"
8 jdbc_user => "username"
9 jdbc_password => "password"
10 statement => "SELECT * FROM pg_stat_database"
11 schedule => "* * * * *"
12 type => "pg_stat_database"
13 }
14
15 # pg_stat_user_tables
16 jdbc {
17 jdbc_driver_library => ""
18 jdbc_driver_class => "org.postgresql.Driver"
19 jdbc_connection_string => "jdbc:postgresql://host:port/defaultdb"
20 jdbc_user => "username"
21 jdbc_password => "password"
22 statement => "SELECT * FROM pg_stat_user_tables"
23 schedule => "* * * * *"
24 type => "pg_stat_user_tables"
25 }
26
27 # pg_stat_user_indexes
28 jdbc {
29 jdbc_driver_library => ""
30 jdbc_driver_class => "org.postgresql.Driver"
31 jdbc_connection_string => "jdbc:postgresql://host:port/defaultdb"
32 jdbc_user => "username"
33 jdbc_password => "password"
34 statement => "SELECT * FROM pg_stat_user_indexes"
35 schedule => "* * * * *"
36 type => "pg_stat_user_indexes"
37 }
38}
39
40output {
41 elasticsearch {
42 hosts => "http://localhost:9200"
43 index => "%{type}"
44 }
45}
记住将 host 替换为主机地址,将 port 替换为可以连接数据库的端口,将 username 替换为数据库用户的用户名,将 password 替换为密码。所有这些值都可以在受管数据库的控制面板中找到。
在此配置中,您定义了三个 JDBC 输入和一个 Elasticsearch 输出。这三个输入分别从pg_stat_database、pg_stat_user_tables和pg_stat_user_indexes数据库中提取数据。它们都将 jdbc_driver_library 参数设置为空字符串,因为 PostgreSQL JDBC 库位于 Logstash 自动加载的文件夹中。
然后,它们设置 jdbc_driver_class(其值是 JDBC 库的特定值),并提供 jdbc_connection_string(其中详细说明了如何连接到数据库)。jdbc:部分表示这是一个 JDBC 连接,而postgres://`则表示目标数据库是 PostgreSQL。接下来是数据库的主机和端口,在斜线之后还要指定要连接的数据库;这是因为 PostgreSQL 要求连接到数据库才能发出任何查询。在这里,它被设置为始终存在且无法删除的默认数据库,命名为 "defaultdb"。
然后,设置访问数据库的用户的用户名和密码。statement "参数包含一个 SQL 查询,该查询应返回要处理的数据--在此配置中,它会从相应的数据库中选择所有行。
schedule 参数接受一个 cron 语法的字符串,它定义了 Logstash 运行此输入的时间;完全省略它将使 Logstash 只运行一次。完全省略它将使 Logstash 只运行一次,而指定 ***** 则会告诉 Logstash 每分钟运行一次。如果想以不同的时间间隔收集数据,可以指定自己的 cron 字符串。
只有一个输出,接受来自三个输入的数据。它们都向本地运行的 Elasticsearch 发送数据,Elasticsearch 的地址是 http://localhost:9200。index参数定义了向哪个 Elasticsearch 索引发送数据,其值由输入的type` 字段传入。
编辑完成后,保存并关闭文件。
您已经配置了 Logstash,以便从各种 PostgreSQL 统计表中收集数据,并将它们发送到 Elasticsearch 进行存储和索引。接下来,你将运行 Logstash 测试配置。
第 3 步 - 测试 Logstash 配置
在本节中,您将运行 Logstash 测试配置,以验证它是否能正确提取数据。然后,将此配置配置为 Logstash 管道,使其在后台运行。
Logstash 支持通过向 -f 参数传递文件路径来运行特定配置。运行以下命令测试上一步中的新配置:
1sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/postgresql.conf
可能需要一些时间才能显示任何输出,看起来与下面类似:
1[secondary_label Output]
2Using bundled JDK: /usr/share/logstash/jdk
3OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
4WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
5Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
6[INFO ] 2022-02-24 08:49:36.664 [main] runner - Starting Logstash {"logstash.version"=>"7.17.0", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
7[INFO ] 2022-02-24 08:49:36.671 [main] runner - JVM bootstrap flags: [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djruby.compile.invokedynamic=true, -Djruby.jit.threshold=0, -Djruby.regexp.interruptible=true, -XX:+HeapDumpOnOutOfMemoryError, -Djava.security.egd=file:/dev/urandom, -Dlog4j2.isThreadContextMapInheritable=true]
8[INFO ] 2022-02-24 08:49:36.700 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
9[INFO ] 2022-02-24 08:49:36.710 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
10[WARN ] 2022-02-24 08:49:36.992 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
11[INFO ] 2022-02-24 08:49:37.018 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"bfd27cc5-f2d0-4b19-8870-a125586135ed", :path=>"/usr/share/logstash/data/uuid"}
12[INFO ] 2022-02-24 08:49:38.085 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
13[INFO ] 2022-02-24 08:49:39.284 [Converge PipelineAction::Create<main>] Reflections - Reflections took 68 ms to scan 1 urls, producing 119 keys and 417 values
14...
15[INFO ] 2022-02-24 08:50:03.102 [Ruby-0-Thread-34@[d39f109727b9e1a2b881639e708f21ce1d65378257869071cbed233a3946468d]<jdbc__scheduler_worker-00: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-integration-jdbc-5.2.2/lib/logstash/plugin_mixins/jdbc/scheduler.rb:77] jdbc - (0.194969s) SELECT * FROM pg_stat_user_tables
16[INFO ] 2022-02-24 08:50:03.104 [Ruby-0-Thread-32@[bd7d166b46e4ae8c53b4d498eaec7d53de881ea0f8a9bdfb08f574f9cbd3a4f6]<jdbc__scheduler_worker-00: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/jobs.rb:284] jdbc - (0.192893s) SELECT * FROM pg_stat_database
17[INFO ] 2022-02-24 08:50:03.104 [Ruby-0-Thread-33@[fc2c0b0065c00ee9f942e75f35edf001a9e285c77ba7cf4ae127886e43c140fc]<jdbc__scheduler_worker-00: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/rufus-scheduler-3.0.9/lib/rufus/scheduler/jobs.rb:284] jdbc - (0.197744s) SELECT * FROM pg_stat_user_indexes
18...
如果 Logstash 没有显示任何错误,并且日志显示它已成功从三个数据库中 "SELECT"(选择)了记录,则数据库度量指标将被发送到 Elasticsearch。如果出现错误,请仔细检查配置文件中的所有值,确保运行 Logstash 的机器可以连接到托管数据库。
Logstash 会在指定时间继续导入数据。您可以按 CTRL+C安全地停止导入。
如果只为本教程创建了一个新数据库,则应该只有一个用户(doadmin)。这意味着 pg_stat_user_tables 和 pg_stat_user_indexes 表将为空(因为没有其他用户存在并创建了表),并且不会显示在 Elasticsearch 中。
如前所述,以服务形式启动时,Logstash 会在后台自动运行在 /etc/logstash/conf.d下找到的所有配置文件。运行以下命令将其作为服务启动:
1sudo systemctl start logstash
在这一步中,你将运行 Logstash 检查它是否能连接到你的数据库并收集数据。接下来,您将在 Kibana 中可视化并探索一些统计数据。
第 4 步 - 在 Kibana 中探索导入的数据
在本节中,您将在 Kibana 中探索描述数据库性能的统计数据并将其可视化。
在 Web 浏览器中,导航到作为先决条件的一部分暴露了 Kibana 的域。您将看到默认的欢迎页面:
Kibana - 欢迎页面](assets/68158/jDdYHaM.png)
在探索 Logstash 发送到 Elasticsearch 的数据之前,首先需要将 pg_stat_database 索引添加到 Kibana。为此,首先按下自行探索 ,然后打开左上角的汉堡包菜单。在** 分析** 下,点击** 发现** 。
然后,Kibana 会提示您创建新的索引模式:
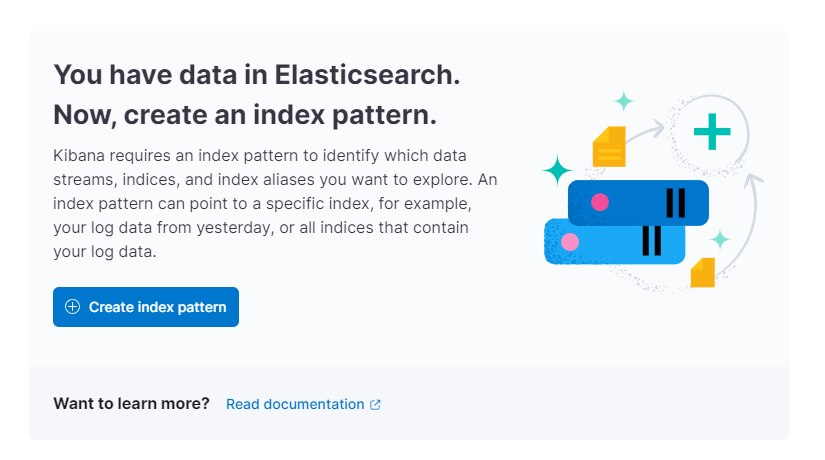
按下创建索引模式 。你会看到一个创建新** 索引模式** 的表单。Kibana 中的索引模式提供了一种一次性从多个 Elasticsearch 索引中提取数据的方法,并可仅用于探索一个索引。
右侧列出了 Logstash 发送统计数据的三个索引。在名称 文本字段中键入 "pg_stat_database",并从下拉菜单中选择"@timestamp "作为** 时间戳字段** 。完成后,点击下方的** 创建索引模式** 按钮。
要创建和查看现有的可视化效果,请打开汉堡菜单。在分析 下,选择** 仪表盘** 。 加载完毕后,点击** 创建新仪表盘** ,然后按下** 创建可视化** 开始创建新的仪表盘:
Kibana - 新可视化](assets/68158/JJazkOi.png)
左侧面板提供了 Kibana 可用于绘制可视化的值列表,这些值将显示在屏幕中央部分。屏幕右上方是日期范围选择器。如果在可视化中使用了 @timestamp 字段,Kibana 将只显示属于范围选择器中指定的时间间隔的数据。
现在,您可以直观地看到在给定时间间隔内,每分钟 "插入 "的数据元组平均数。从页面主要部分的下拉菜单中,选择线和区域 部分下的** 线** 。然后,从左侧列表中找到 "tup_inserted "字段,并将其拖动到中央部分。很快,您就会看到一个线形可视化图,其中显示了不同时间内的 "INSERT "查询量中位数。如果您的数据库是全新的,没有使用过,您还看不到任何东西。但在所有情况下,您都将看到数据库使用情况的准确描述:
INSERTs的Kibana中值可视化](assets/68158/AXJdbEo.png)
在右侧,您可以配置横轴和纵轴的处理方式。在这里,您可以按下显示的坐标轴,将纵轴设置为显示平均 值,而不是** 中位** 值:
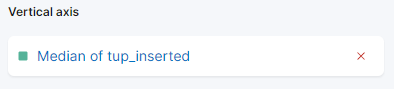
您可以选择不同的功能,或提供自己的功能:
Kibana - 轴功能](assets/68158/bikOsnX.png)
图表将立即用更新的数值刷新。
在本步骤中,您已学会如何使用 Kibana 可视化 PostgreSQL 的部分统计数据。
第 5 步 -(可选)使用 pgbench 进行基准测试
pgbench 将反复运行相同的 SQL 命令,模拟实际客户在真实世界中使用数据库的情况。
首先,您需要运行以下命令安装 pgbench:
1sudo apt install postgresql-contrib -y
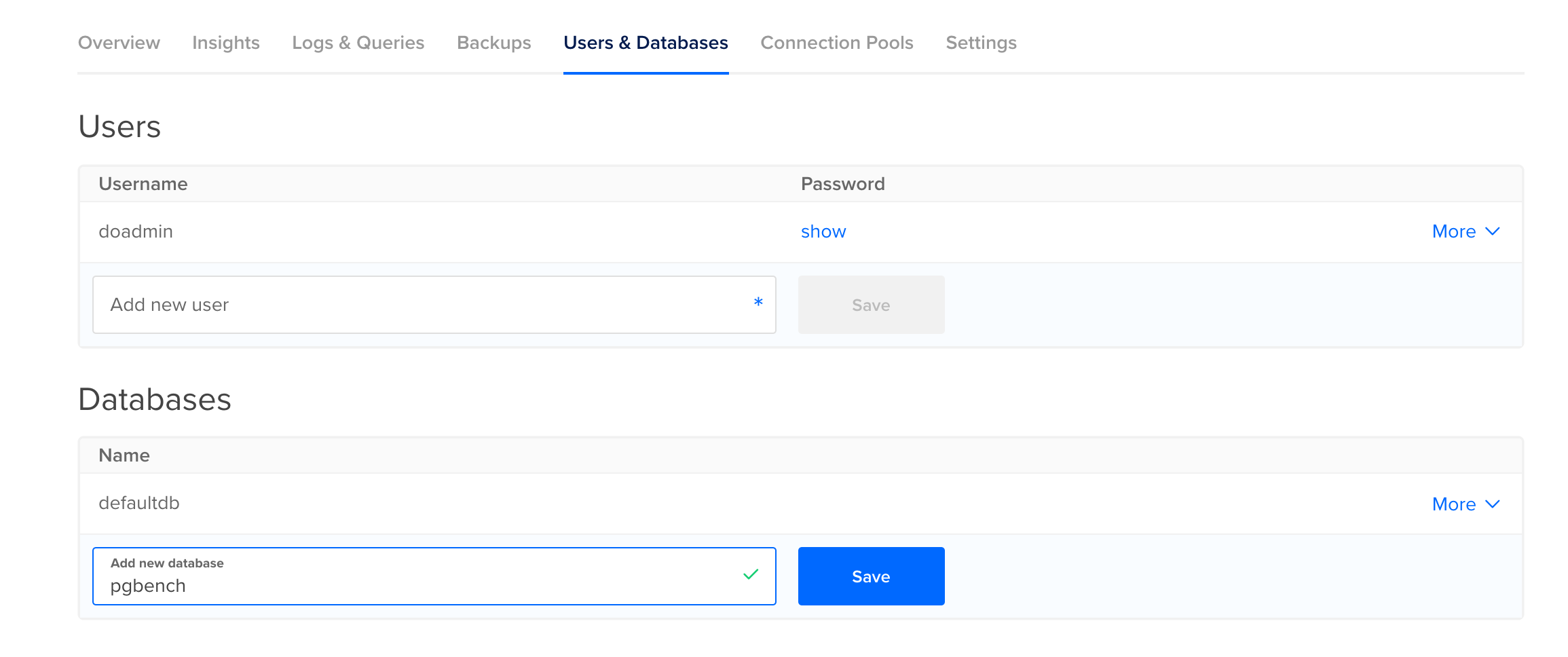
由于 pgbench 会插入和更新测试数据,因此您需要为其创建一个单独的数据库。为此,请前往受管数据库控制面板中的用户和数据库 选项卡,向下滚动到** 数据库** 部分。输入 "pgbench "作为新数据库的名称,然后按** 保存** 。你将把这个名称以及主机、端口和用户名信息传递给 pgbench。
在实际运行 pgbench 之前,需要使用 -i 标志运行它以初始化数据库:
1pgbench -h host -p port -U username -i pgbench
您需要将 host 替换为您的主机地址,将 port 替换为您可以连接到数据库的端口,将 username 替换为数据库用户的用户名。您可以在受管数据库的控制面板中找到所有这些值。
请注意,"pgbench "没有密码参数,而是每次运行时都会要求输入密码。
输出结果如下
1[secondary_label Output]
2NOTICE: table "pgbench_history" does not exist, skipping
3NOTICE: table "pgbench_tellers" does not exist, skipping
4NOTICE: table "pgbench_accounts" does not exist, skipping
5NOTICE: table "pgbench_branches" does not exist, skipping
6creating tables...
7100000 of 100000 tuples (100%) done (elapsed 0.16 s, remaining 0.00 s)
8vacuum...
9set primary keys...
10done.
pgbench 创建了四个用于基准测试的表,并在其中填充了一些示例行。现在就可以运行基准测试了。
限制基准运行时间的两个最重要参数是 -t(指定要完成的事务数量)和 -T(定义基准应运行多少秒)。这两个选项是相互排斥的。每次基准测试结束时,都会收到统计信息,例如每秒的事务数 (tps)。
现在,运行以下命令启动持续 30 秒的基准测试:
1pgbench -h host -p port -U username pgbench -T 30
输出结果将与此类似:
1[secondary_label Output]
2starting vacuum...end.
3transaction type: <builtin: TPC-B (sort of)>
4scaling factor: 1
5query mode: simple
6number of clients: 1
7number of threads: 1
8duration: 30 s
9number of transactions actually processed: 11991
10latency average = 2.502 ms
11tps = 399.664353 (including connections establishing)
12tps = 399.987202 (excluding connections establishing)
在此输出中,您可以看到有关该基准的一般信息,例如执行的事务总数。这些基准测试的效果是,Logstash 发送到 Elasticsearch 的统计数据将反映这一数字,这反过来又会使 Kibana 中的可视化效果更有趣、更接近真实世界的图表。你可以多运行几次上述命令,也可以改变持续时间。
完成后,前往 Kibana 并按下右上角的刷新 。现在你会看到与之前不同的一行,显示的是 "INSERT "的数量。通过更改刷新按钮上方选择器中的值,可以随意更改所显示数据的时间范围。以下是多个不同持续时间的基准测试后图表的效果:
Kibana - 基准测试后的可视化](assets/68158/h3c9iYx.png)
您使用 pgbench 对数据库进行了基准测试,并在 Kibana 中评估了生成的图表。
结论
现在,您已在服务器上安装了 Elastic 栈,并配置为定期从受管 PostgreSQL 数据库中提取统计数据。您可以使用 Kibana 或其他合适的软件对数据进行分析和可视化,这将有助于您收集有价值的洞察力和现实世界中的关联信息,了解数据库的运行情况。
有关 PostgreSQL 托管数据库的更多信息,请访问 product docs。