在前面的文章中,我们了解了如何使用图形方法执行EDA。在本文中,我们将重点介绍在PYTHON中用于EXPLEATIONAL Data Analysis]的PYTHON函数。众所周知,EDA有多重要它提供了一个对数据的简要了解。所以,不要浪费太多时间,让我们开始吧!
探索性数据分析-EDA
- EDA用于 调查** 数据和** 总结** 关键见解。
- 它会让你对你的数据有一个基本的了解,比如 分布** 、空值等等。
- 您可以使用图形或通过一些python 函数来浏览数据。**
- 将有两类分析。 单变量和Bivariate.** 在单变量中,您将分析单个属性。但在双变量中,您将分析具有目标属性的属性。
- 在 非图形方法** 中,您将使用形状、摘要、描述、isNULL、信息、数据类型等函数。
- 在 图形方法** 中,您将使用散点图、方框图、条形图、密度图和相关图。
加载数据
好吧,首先要做的就是。我们将把这个巨大的数据集加载到Python中来执行EDA。
1#Load the required libraries
2import pandas as pd
3import numpy as np
4import seaborn as sns
5
6#Load the data
7df = pd.read_csv('titanic.csv')
8
9#View the data
10df.head()
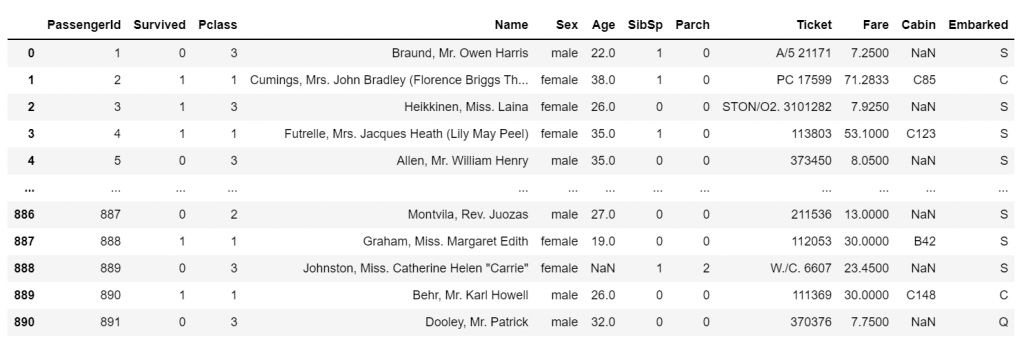
我们的数据已准备就绪,可供研究!
1.数据基本信息-EDA
Df.info()函数将为我们提供有关数据集的基本信息。对于任何数据,最好从了解其信息开始。让我们看看它是如何处理我们的数据的。
1#Basic information
2
3df.info()
4
5#Describe the data
6
7df.describe()
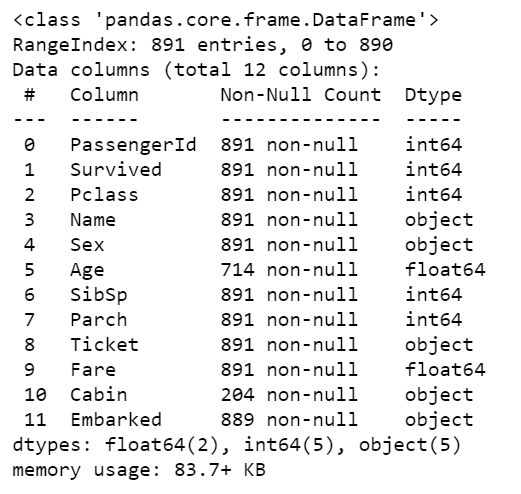
- 描述数据描述性统计。
{kind=link}
使用该函数,您可以看到空值的数量、数据类型和内存使用情况,如上面的输出以及描述性统计数据所示。
2.重复值
如果存在重复的值,则可以使用df.duplicate.sum()函数计算其总和。如果数据中存在重复值,它将显示重复值的数量。
1#Find the duplicates
2
3df.duplicated().sum()
0
那么,该函数返回了0。这意味着,我们的数据集中不存在任何重复的值,这是一件非常好的事情。
3.数据中的唯一值
你可以使用python中的unique()函数找到特定列中唯一值的数量。
1#unique values
2
3df['Pclass'].unique()
4
5df['Survived'].unique()
6
7df['Sex'].unique()
1array([3, 1, 2], dtype=int64)
2
3array([0, 1], dtype=int64)
4
5array(['male', 'female'], dtype=object)
UNIQUE()函数返回了数据中存在的唯一值,这非常酷!
4.可视化唯一计数
是的,您可以可视化数据中存在的唯一值。为此,我们将使用海运库。您必须调用ns.Countlot()函数并指定变量来绘制计数图。
1#Plot the unique values
2
3sns.countplot(df['Pclass']).unique()
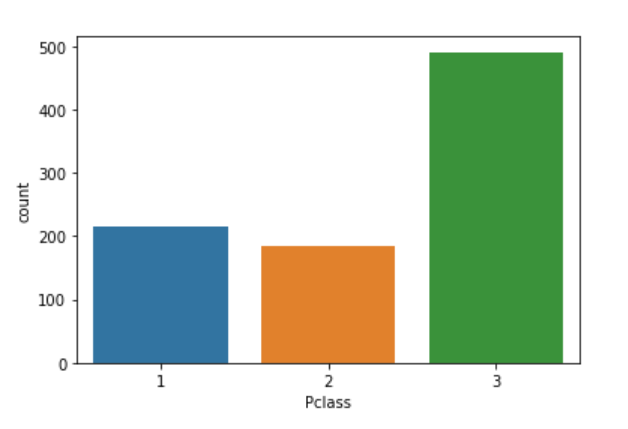
太好了!你做得很好。就这么简单。虽然EDA有两种方法,但图形和非图形的混合将为您提供更大的画面。
5.查找空值
找出空值是EDA中最重要的一步。正如我多次告诉大家的那样,确保数据质量是最重要的。那么,让我们看看如何找到空值。
1#Find null values
2
3df.isnull().sum()
1PassengerId 0
2Survived 0
3Pclass 0
4Name 0
5Sex 0
6Age 177
7SibSp 0
8Parch 0
9Ticket 0
10Fare 0
11Cabin 687
12Embarked 2
13
14dtype: int64
哦,不,我们在**‘Age’** 和** ‘Cabin’** 变量中有一些空值。不过,别担心。我们很快就会找到处理它们的方法。
6.替换空值
嘿,我们有一个place()函数来用特定的数据替换所有的空值。太棒了!
1#Replace null values
2
3df.replace(np.nan,'0',inplace = True)
4
5#Check the changes now
6df.isnull().sum()
1PassengerId 0
2Survived 0
3Pclass 0
4Name 0
5Sex 0
6Age 0
7SibSp 0
8Parch 0
9Ticket 0
10Fare 0
11Cabin 0
12Embarked 0
13
14dtype: int64
喔!太棒了很容易找到和替换数据中的空值,如图所示。我使用0来替换空值。你甚至可以选择更有意义的方法,如平均值或中位数。
7.了解数据类型
了解您正在探索的数据类型是非常重要的,也是一个简单的过程。让我们看看它是如何工作的。
1#Datatypes
2
3df.dtypes
1PassengerId int64
2Survived int64
3Pclass int64
4Name object
5Sex object
6Age object
7SibSp int64
8Parch int64
9Ticket object
10Fare float64
11Cabin object
12Embarked object
13
14dtype: object
就这样。您必须为此使用dtype函数,您将获得每个属性的数据类型。
8.数据过滤
可以,您可以根据某些逻辑对数据进行筛选。
1#Filter data
2
3df[df['Pclass']==1].head()

可以看到上面的代码只返回了属于类1的数据值。
9.快速框图
您可以使用一行代码为任何数值列创建框plot。
1#Boxplot
2
3df[['Fare']].boxplot()
{kind=link}
10.关联图-EDA
最后,为了找到变量之间的相关性,我们可以使用相关函数。这将使您对不同变量之间的相关强度有一个合理的概念。
1#Correlation
2
3df.corr()
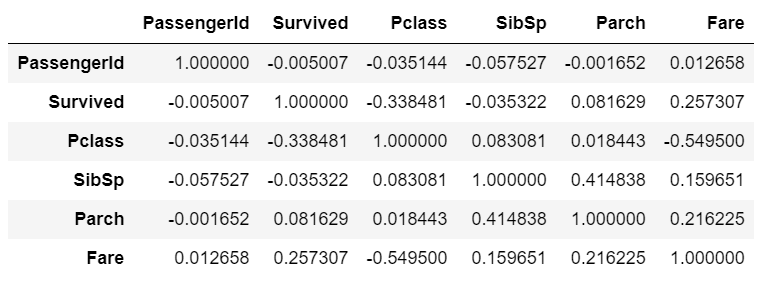
这是从+1到-1的范围内的相关矩阵,其中+1为高度正相关,-1为高度负相关。
您甚至可以使用Seborn library]可视化相关矩阵,如下所示。
1#Correlation plot
2
3sns.heatmap(df.corr())

结束语-EDA
EDA是所有分析中最重要的部分。您将了解有关您的数据的许多事情。通过EDA,您可以找到大多数问题的答案。我已经尝试通过可视化展示了用于研究数据的大多数Python函数。我希望你能从这篇文章中学到一些东西。
现在就到这里吧!Happy Python:)
更多内容请阅读: 探索性数据分析