简介
Python`Pandas‘包用于数据操作和分析,旨在让您以直观的方式处理标签或关系数据。
‘pandas’包提供了电子表格功能,但因为您使用的是Python,所以它比传统的图形电子表格程序更快、更高效。
在本教程中,我们将介绍如何设置要使用的大型数据集、Pandas的groupby()和Pivot_TABLE()函数,以及如何可视化数据。
要了解`pandas‘包,您可以阅读我们的教程介绍pandas包及其在Python 3.中的数据结构
前提条件
本指南将介绍如何在本地桌面或远程服务器上使用Pandas中的数据。处理大型数据集可能会占用大量内存,因此在任何一种情况下,计算机都将至少需要2 GB内存 来执行本指南中的一些计算。
在本教程中,我们将使用Jupyter Notebook 来处理数据。如果您还没有,您应该按照我们的[教程]来安装和设置Jupyter Notebook for Python 3](https://andsky.com/tech/tutorials/how-to-set-up-jupyter-notebook-for-python-3).
设置数据
在本教程中,我们将使用有关婴儿姓名的美国社会保障数据,这些数据可以从Social Security website]以8MB压缩文件的形式获得。
让我们在本地machine,上或正确目录下的server上]上激活我们的Python3编程环境:
1cd environments
1. my_env/bin/activate
现在让我们为我们的项目创建一个新目录。我们可以将其命名为Name,然后移到目录中:
1mkdir names
2cd names
在该目录下,我们可以使用curl命令从社保网站拉取压缩文件:
1curl -O https://www.ssa.gov/oact/babynames/names.zip
下载文件后,让我们验证我们是否安装了我们将使用的所有软件包:
numpy,支持多维数组matplotlib可视化数据- `熊猫‘,用于我们的数据分析
- `海运‘使我们的matplotlib统计图形更美观
如果您还没有安装任何包,请使用piap安装它们,如:
1pip install pandas
2pip install matplotlib
3pip install seaborn
如果您还没有numpy包,也会安装它。
现在,我们可以启动一个笔记本电脑:
1jupyter notebook
一旦你打开Jupyter Notebook的网络界面,你就会在那里看到names.zip文件。
要创建新的笔记本文件,请在右上角的下拉菜单中选择[新建]>[Python3]:
这将打开一个笔记本。
让我们从importing开始我们将使用的包。在笔记本的顶部,我们应该写下以下内容:
1import numpy as np
2import matplotlib.pyplot as pp
3import pandas as pd
4import seaborn
我们可以运行这段代码,并通过键入ALT+Enter进入新的代码块。
让我们也告诉Python Notebook保持我们的图形内联:
1matplotlib inline
让我们运行代码并输入ALT+Enter继续。
从这里开始,我们将继续解压Zip归档文件,将csv数据集加载到pandas中,然后连接`pandas‘DataFrames.
解压Zip档案
为了将压缩包解压到当前目录,我们将导入zipfile模块,然后使用文件名调用ZipFile函数(在我们的例子中是names.zip):
1import zipfile
2zipfile.ZipFile('names.zip').extractall('.')
我们可以运行代码并通过键入ALT+Enter继续。
现在,如果你回头看看你的names目录,你会有CSV格式的名称数据的.txt文件。这些文件将与1881年至2015年的文件数据相对应。这些文件中的每一个都遵循类似的命名约定。例如,2015年的文件名为yob2015.txt,而1927年的文件名为yob1927.txt。
要查看其中一个文件的格式,让我们使用Python打开一个文件并显示前5行:
1open('yob2015.txt','r').readlines()[:5]
运行代码并继续ALT+Enter。
1[secondary_label Output]
2['Emma,F,20355\n',
3 'Olivia,F,19553\n',
4 'Sophia,F,17327\n',
5 'Ava,F,16286\n',
6 'Isabella,F,15504\n']
数据的格式是先取名字(如‘Emma或’Olivia‘),然后是性别(如’F‘代表女性名字,M’代表男性名字),然后是那一年出生的同名婴儿数量(2015年出生的婴儿有20355个名字叫Emma)。
有了这些信息,我们就可以将数据加载到pandas中。
将CSV数据加载到pandas中
要将逗号分隔值数据加载到anda‘中,我们将使用pd.read_csv()函数,传递文本文件的名称以及我们决定的列名。我们会将其赋给一个变量,在本例中为name2015‘,因为我们使用的是2015年出生文件中的数据。
1names2015 = pd.read_csv('yob2015.txt', names = ['Name', 'Sex', 'Babies'])
键入ALT+ENTER运行代码并继续。
为了确保这一点,让我们显示表的顶部:
1names2015.head()
当我们运行代码并继续ALT+Enter时,我们将看到如下所示的输出:

我们的表现在包含了婴儿的名字、性别和出生人数的信息,每个名字都按列组织。
串接anda as对象
串连pandas‘对象将允许我们处理name`目录中的所有单独的文本文件。
要将这些连接起来,我们首先需要通过将变量赋给未填充的List Data type:]来初始化列表
1all_years = []
完成后,我们将使用forloop按年迭代所有文件,范围从1880年到2015年。我们将在2015年末加上+1,以便将2015年包含在循环中。
1all_years = []
2
3for year in range(1880, 2015+1):
在循环中,我们将使用字符串formatter来处理每个文件的不同名称,并将每个文本文件值附加到列表中。我们将把这些值传递给Year变量。同样,我们将为Name、Sex和Babies的数量指定列:
1all_years = []
2
3for year in range(1880, 2015+1):
4 all_years.append(pd.read_csv('yob{}.txt'.format(year),
5 names = ['Name', 'Sex', 'Babies']))
此外,我们将为每一年创建一个列,以保持这些年份的顺序。这可以在每次迭代之后完成,方法是在循环进行时使用-1的索引指向它们。
1all_years = []
2
3for year in range(1880, 2015+1):
4 all_years.append(pd.read_csv('yob{}.txt'.format(year),
5 names = ['Name', 'Sex', 'Babies']))
6 all_years[-1]['Year'] = year
最后,我们将使用pd.conat()函数将其添加到串联的anda as对象中。我们将使用变量ALL_NAME存储此信息。
1all_years = []
2
3for year in range(1880, 2015+1):
4 all_years.append(pd.read_csv('yob{}.txt'.format(year),
5 names = ['Name', 'Sex', 'Babies']))
6 all_years[-1]['Year'] = year
7
8all_names = pd.concat(all_years)
我们现在可以使用ALT+ENTER运行循环,然后通过调用结果表的尾部(最下面的行)来检查输出:
1all_names.tail()

我们的数据集现在已经完成,可以在‘熊猫’中使用它进行额外的工作。
数据分组
您可以使用.groupby()函数对数据进行按列分组。对整个数据集使用all_name变量,我们可以使用groupby()将数据拆分到不同的存储桶中。
让我们按性别和年份对数据集进行分组。我们可以这样设置:
1group_name = all_names.groupby(['Sex', 'Year'])
我们可以运行代码并继续ALT+Enter。
此时,如果我们只调用group_name变量,我们将得到以下输出:
1[secondary_label Output]
2<pandas.core.groupby.DataFrameGroupBy object at 0x1187b82e8>
这表明它是一个DataFrameGroupBy对象。此对象提供有关如何对数据进行分组的说明,但不提供有关如何显示值的说明。
要显示值,我们需要给出说明。例如,我们可以计算.Size()、.Means()和.sum()来返回表。
让我们从.Size()开始:
1group_name.size()
当我们运行代码并继续ALT+Enter时,我们的输出将如下所示:
1[secondary_label Output]
2Sex Year
3F 1880 942
4 1881 938
5 1882 1028
6 1883 1054
7 1884 1172
8...
这些数据看起来不错,但它可以更具可读性。我们可以通过添加.unstack函数使其更具可读性:
1group_name.size().unstack()
现在,当我们运行代码并继续键入ALT+Enter时,输出如下所示:

这些数据告诉我们,每年有多少个女性和男性的名字。例如,1889年有1,479个女性名字和1,111个男性名字。2015年有18993个女性名字和13959个男性名字。这表明,随着时间的推移,名字的多样性越来越大。
如果我们想要获得出生的婴儿总数,可以使用.sum()函数。让我们将其应用于一个较小的数据集,即我们之前创建的单个yob2015.txt文件中设置的name2015:
1names2015.groupby(['Sex']).sum()
让我们输入ALT+Enter来运行代码并继续:
![names2015.groupby('Sex']).sum()输出](https://assets.digitalocean.com/articles/eng_python/pandas/names2015-groupby-sex-sum-w.png)
{kind=link}
这向我们展示了2015年出生的男婴和女婴的总数,尽管只有当年名字被使用至少5次的婴儿才会被计算在数据集中。
anda as``.groupby()函数允许我们将数据分成有意义的组。
数据透视表
透视表对于汇总数据很有用。它们可以自动对存储在一个表中的数据进行排序、计数、总计或平均。然后,他们可以在汇总数据的新表格中显示这些操作的结果。
在anda as中,使用Pivot_TABLE()函数创建透视表。
为了构造一个透视表,我们将首先调用我们想要使用的DataFrame,然后调用我们想要显示的数据,以及它们是如何分组的。
在本例中,我们将使用all_name数据,并在一个维度中显示按名称分组的婴儿数据,在另一个维度中显示按年份分组的婴儿数据:
1pd.pivot_table(all_names, 'Babies', 'Name', 'Year')
当我们键入ALT+Enter以运行代码并继续时,我们将看到以下输出:

因为这会显示很多空值,所以我们可能希望将Name和Year保留为列,而不是在一种情况下保留为行,在另一种情况下保留为列。我们可以通过将数据分组在方括号中来做到这一点:
1pd.pivot_table(all_names, 'Babies', ['Name', 'Year'])
一旦我们键入ALT+ENTER来运行代码并继续,该表现在将只显示每个名称的记录年份的数据:
1[secondary_label Output]
2Name Year
3Aaban 2007 5.0
4 2009 6.0
5 2010 9.0
6 2011 11.0
7 2012 11.0
8 2013 14.0
9 2014 16.0
10 2015 15.0
11Aabha 2011 7.0
12 2012 5.0
13 2014 9.0
14 2015 7.0
15Aabid 2003 5.0
16Aabriella 2008 5.0
17 2014 5.0
18 2015 5.0
此外,我们可以对数据进行分组,将姓名和性别作为一个维度,年份作为另一个维度,如下所示:
1pd.pivot_table(all_names, 'Babies', ['Name', 'Sex'], 'Year')
当我们运行代码并继续ALT+Enter时,我们将看到下表:
![pd.Pivot_TABLE(ALL_NAMES,‘Baby’,[‘NAME’,‘Sex’],‘Year’)output](https://cdn.jsdelivr.net/gh/andsky/tutorials-images/assets/eng_python/pandas/pivot-babies-name-sex-year.png)
透视表允许我们从现有表创建新表,使我们能够决定如何对数据进行分组。
数据可视化
通过在matplotlib‘等其他包中使用pandas’,我们可以将笔记本中的数据可视化。
我们将可视化有关给定名称在过去几年中受欢迎程度的数据。为了做到这一点,我们需要设置和排序索引以重新处理数据,这样我们就可以看到特定名字的受欢迎程度的变化。
pandas包允许我们执行分层或多级索引,这允许我们存储和操作具有任意维数的数据。
我们将使用有关性别、姓名和年份的信息来索引我们的数据。我们还需要对索引进行排序:
1all_names_index = all_names.set_index(['Sex','Name','Year']).sort_index()
键入ALT+Enter以运行并继续到我们的下一行,在那里我们将使笔记本显示新的索引DataFrame:
1all_names_index
运行代码并继续ALT+Enter,输出将如下所示:

接下来,我们将编写一个函数,该函数将绘制一个名字随时间变化的受欢迎程度。我们将调用函数name_plot,并将sex和name作为其参数传递,在运行该函数时将调用这些参数。
1def name_plot(sex, name):
现在我们将设置一个名为data的变量来保存我们创建的表。我们还将使用anda asDataFrameLoc来根据索引值选择我们的行。在我们的例子中,我们希望Loc基于MultiIndex中的字段组合,同时引用sex和name数据。
让我们把这个结构写进我们的函数中:
1def name_plot(sex, name):
2 data = all_names_index.loc[sex, name]
最后,我们需要使用我们导入为pp的matplotlib.pyplot绘制这些值。然后我们将根据索引绘制性别和姓名数据值,对于我们的目的是年份。
1def name_plot(sex, name):
2 data = all_names_index.loc[sex, name]
3
4 pp.plot(data.index, data.values)
键入ALT+Enter以运行并移动到下一个单元格。我们现在可以用我们选择的性别和名字来调用函数,比如F‘代表女性名字,给定的名字是Danica’。
1name_plot('F', 'Danica')
现在当您键入ALT+Enter时,您将收到以下输出:

请注意,根据您使用的系统,您可能会收到有关字体替换的警告,但数据仍将正确打印。
从可视化的角度看,我们可以看到,女名丹妮卡在1990年前后人气小幅上升,并在2010年前达到顶峰。
我们创建的函数可以用于绘制来自多个名称的数据,以便我们可以看到不同名称随时间的趋势。
让我们从把我们的情节放大一点开始:
1pp.figure(figsize = (18, 8))
接下来,让我们创建一个列表,其中包含我们想要绘制的所有名称:
1pp.figure(figsize = (18, 8))
2
3names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
现在,我们可以使用一个`for‘循环遍历列表,并绘制每个名字的数据。首先,我们将尝试将这些中性名称作为女性名称:
1pp.figure(figsize = (18, 8))
2
3names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
4
5for name in names:
6 name_plot('F', name)
为了使这些数据更容易理解,让我们添加一个图例:
1pp.figure(figsize = (18, 8))
2
3names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
4
5for name in names:
6 name_plot('F', name)
7
8pp.legend(names)
我们将键入ALT+Enter来运行代码并继续,然后我们将收到以下输出:
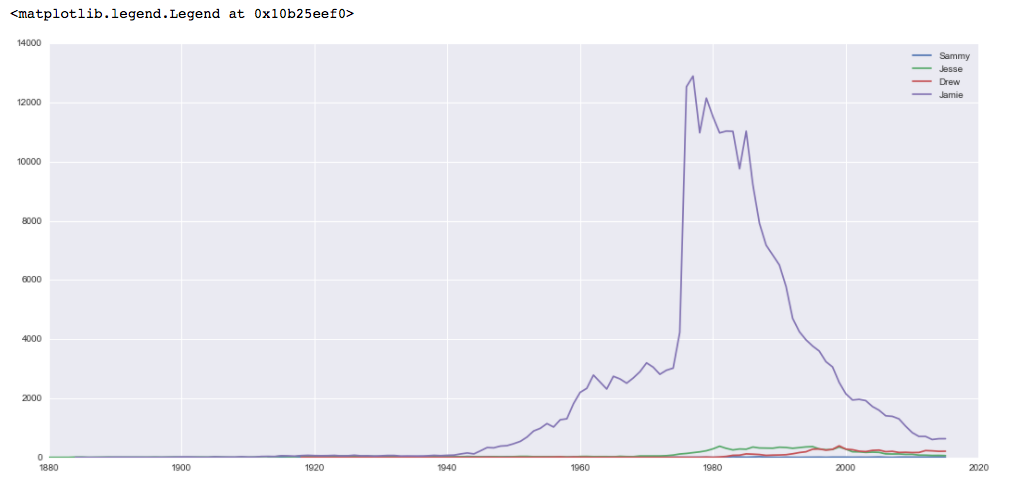
虽然每个名字都逐渐成为女性名字,但杰米这个名字在1980年左右作为一个女性名字非常受欢迎。
让我们画出相同的名字,但这一次是男性名字:
1pp.figure(figsize = (18, 8))
2
3names = ['Sammy', 'Jesse', 'Drew', 'Jamie']
4
5for name in names:
6 name_plot('M', name)
7
8pp.legend(names)
再次键入ALT+Enter以运行代码并继续。图表将如下所示:
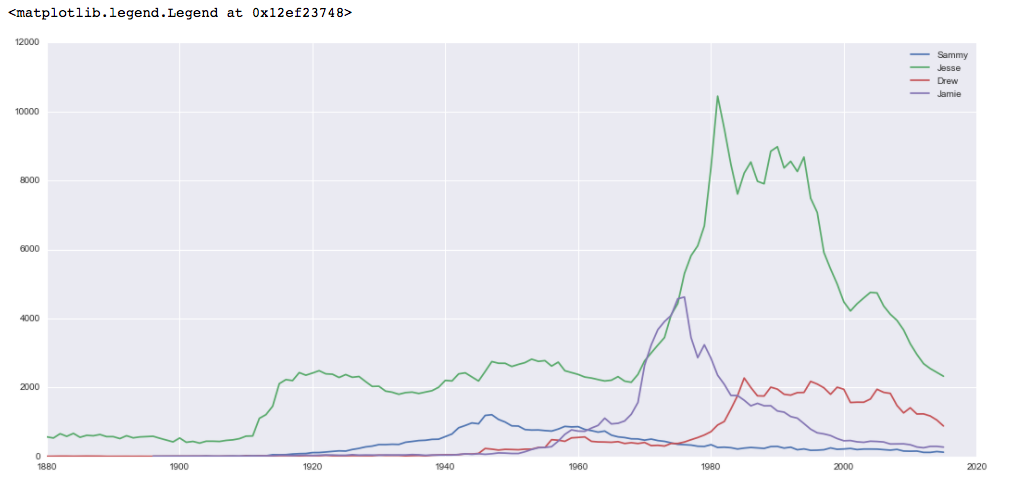
这一数据显示,各个名字都更受欢迎,杰西通常是最受欢迎的选择,在20世纪80年代和90年代尤其受欢迎。
从这里,您可以继续处理姓名数据,创建关于不同姓名及其受欢迎程度的可视化,并创建其他脚本以查看要可视化的不同数据。
结论
本教程向您介绍了处理大型数据集的方法,从设置数据,到使用groupby()和Pivot_table()对数据进行分组,使用MultiIndex对数据进行索引,以及使用matplotlib包可视化Pandas数据。
许多组织和机构提供了数据集,您可以使用这些数据集继续了解),)提供数据。
你可以通过我们的指南How to Plot Data in Python 3 Using matplotlib和How To Graph Word Frequency Using matplotlib with Python 3了解更多关于使用matplotlib可视化数据的信息。