简介
如果您正在积极开发应用程序,使用Docker可以简化您的工作流程以及将应用程序部署到生产环境的过程。在开发中使用容器提供了以下好处:
- 环境是一致的,这意味着您可以为项目选择所需的语言和依赖项,而无需担心系统冲突。
- 环境是隔离的,因此可以更轻松地排除故障并加入新的团队成员。
- 环境是可移植的,允许您打包代码并与他人共享。
本教程将向您展示如何使用Docker为Ruby on rails应用程序)设置开发环境。您将为应用程序本身、postgresql数据库、redis,)和一个sidekiq服务)以及Docker Compose.)创建多个容器安装程序将执行以下操作:
- 将宿主机上的应用程序代码与容器中的代码同步,便于开发过程中的更改。
- 容器重启之间的应用数据持久化。
- 配置Sidekiq工作人员以按预期处理作业。
在本教程结束时,您将拥有一个在Docker Containers上运行的鲨鱼信息应用程序:

预约
要学习本教程,您需要:
- 运行Ubuntu 18.04的本地开发机器或服务器,以及具有
sudo权限和活动防火墙的非超级用户。有关如何设置这些的指导,请参阅初始服务器设置guide. - 在您的本地机器或服务器上安装Docker,按照如何在Ubuntu 18.04.上安装和使用Docker》的步骤1和2进行
- Docker Compose安装在您的本地机器或服务器上,按照如何在Ubuntu 18.04.上安装Docker Compose》第一步操作
第一步-克隆项目并添加依赖项
我们的第一步是从DigitalOcean社区GitHub帐户克隆https://github.com/do-community).存储库这个资源库包含了How to Add Sidekiq and Redis to a Ruby on rails Application,]中描述的设置代码,其中解释了如何将Sidekiq添加到现有的rails 5项目中。
将仓库克隆到名为rails-docker的目录下:
1git clone https://github.com/do-community/rails-sidekiq.git rails-docker
导航到rails-docker目录:
1cd rails-docker
在本教程中,我们将使用PostgreSQL作为数据库。为了使用PostgreSQL而不是SQLite3,您需要将pggem)添加到项目的依赖项中,这些依赖项列在其Gemfile中。使用nan或您最喜欢的编辑器打开该文件进行编辑:
1nano Gemfile
在主项目依赖项(开发依赖项以上)中的任意位置添加gem:
1[label ~/rails-docker/Gemfile]
2. . .
3# Reduces boot times through caching; required in config/boot.rb
4gem 'bootsnap', '>= 1.1.0', require: false
5gem 'sidekiq', '~>6.0.0'
6gem 'pg', '~>1.1.3'
7
8group :development, :test do
9. . .
我们还可以注释掉sqlitegem,,因为我们将不再使用它:
1[label ~/rails-docker/Gemfile]
2. . .
3# Use sqlite3 as the database for Active Record
4# gem 'sqlite3'
5. . .
最后,注释掉gem](https://github.com/jonleighton/spring-watcher-listen)下的[Spring-Watcher-listen:
1[label ~/rails-docker/Gemfile]
2. . .
3gem 'spring'
4# gem 'spring-watcher-listen', '~> 2.0.0'
5. . .
如果我们不禁用这个gem,我们将在访问Rails控制台时看到持续的错误消息。这些错误消息源于这样一个事实,即这个gem让Rail使用listen来监视开发中的更改,而不是轮询文件系统的更改。因为这个gem监视project,的根目录,包括node_modes目录,所以它会抛出有关正在监视哪些目录的错误消息,从而使控制台变得混乱。但是,如果您关心的是节省CPU资源,那么禁用此gem可能对您不起作用。在这种情况下,将您的Rails应用程序升级到Rails6可能是个好主意。
编辑完成后,保存并关闭文件。
准备好项目存储库,将pggem添加到Gemfile中,并注释掉Spring-Watcher-listengem,您就可以配置您的应用程序以使用PostgreSQL了。
第二步-配置应用程序使用PostgreSQL和Redis
要在开发中使用PostgreSQL和Redis,我们需要执行以下操作:
- 将应用程序配置为使用PostgreSQL作为默认适配器。
- 在工程中添加一个
.env文件,其中包含我们的数据库用户名和密码以及Redis主机。 - 创建
init.sql脚本,为数据库创建sammy用户。 - 为Sidekiq添加一个initializer,以便它可以与我们的容器化
redis服务配合使用。 - 将
.env文件等相关文件添加到工程的gitignore和dockernore文件中。 - 创建数据库种子,以便我们的应用程序在启动时有一些记录可供我们使用。
首先,打开您的数据库配置文件,该文件位于config/database ase.yml:
1nano config/database.yml
目前,该文件包括以下default设置,这些设置在没有其他设置的情况下应用:
1[label ~/rails-docker/config/database.yml]
2default: &default
3 adapter: sqlite3
4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
5 timeout: 5000
我们需要更改这些设置,以反映我们将使用postgresql适配器的事实,因为我们将使用Docker Compose创建一个PostgreSQL服务来持久化我们的应用程序数据。
删除将SQLite设置为适配器的代码,并将其替换为以下设置,这些设置将相应地设置适配器以及连接所需的其他变量:
1[label ~/rails-docker/config/database.yml]
2default: &default
3 adapter: postgresql
4 encoding: unicode
5 database: <%= ENV['DATABASE_NAME'] %>
6 username: <%= ENV['DATABASE_USER'] %>
7 password: <%= ENV['DATABASE_PASSWORD'] %>
8 port: <%= ENV['DATABASE_PORT'] || '5432' %>
9 host: <%= ENV['DATABASE_HOST'] %>
10 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
11 timeout: 5000
12. . .
接下来,我们将修改`Development‘环境的设置,因为这是我们在此设置中使用的环境。
删除现有的SQLite数据库配置,使该部分如下所示:
1[label ~/rails-docker/config/database.yml]
2. . .
3development:
4 <<: *default
5. . .
最后,同时删除Production和Test环境的datase设置:
1[label ~/rails-docker/config/database.yml]
2. . .
3test:
4 <<: *default
5
6production:
7 <<: *default
8. . .
这些对默认数据库设置的修改将允许我们使用.env文件中定义的环境变量动态设置数据库信息,这些环境变量不会提交给版本控制。
编辑完成后,保存并关闭文件。
请注意,如果您正在从头开始创建一个Rails项目,您可以使用rails new命令设置适配器。如How to Use PostgreSQL with Your Ruby on rails Application on Ubuntu 18.04.]的[步骤PostgreSQL]所述这会将您的适配器设置在config/database ase.yml中,并自动将pggem添加到工程中。
既然我们已经引用了我们的环境变量,我们就可以使用我们的首选设置为它们创建一个文件。以这种方式提取配置设置是12因素方法的一部分,该方法定义了分布式环境中应用程序弹性的最佳实践。现在,当我们将来设置我们的生产和测试环境时,配置我们的数据库设置将涉及创建额外的.env文件并引用我们的Docker合成文件中的适当文件。
打开.env文件:
1nano .env
将下列值添加到文件中:
1[label ~/rails-docker/.env]
2DATABASE_NAME=rails_development
3DATABASE_USER=sammy
4DATABASE_PASSWORD=shark
5DATABASE_HOST=database
6REDIS_HOST=redis
除了设置数据库名称、用户名和密码之外,我们还为DATABASE_HOST设置了一个值。 值database指的是我们将使用Docker Compose创建的PostgreSQL服务。我们还设置了一个REDIS_HOST来指定我们的redis服务。
编辑完成后,保存并关闭文件。
要创建sammy数据库用户,我们可以编写一个init.sql脚本,然后在启动时挂载到数据库容器中。
打开脚本文件:
1nano init.sql
添加以下代码以创建具有管理权限的sammy用户:
1[label ~/rails-docker/init.sql]
2CREATE USER sammy;
3ALTER USER sammy WITH SUPERUSER;
该脚本将在数据库上创建适当的用户,并授予该用户管理权限。
在脚本上设置适当的权限:
1chmod +x init.sql
接下来,我们将配置Sidekiq以使用我们的容器化redis服务。我们可以在config/Initializers目录中添加一个初始化器,一旦加载了框架和插件,Rails就会在该目录中查找配置设置,从而为Redis主机设置值。
打开idekiq.rb文件以指定这些设置:
1nano config/initializers/sidekiq.rb
将以下代码添加到文件中,以指定REDIS_HOST和REDIS_PORT的值:
1[label ~/rails-docker/config/initializers/sidekiq.rb]
2Sidekiq.configure_server do |config|
3 config.redis = {
4 host: ENV['REDIS_HOST'],
5 port: ENV['REDIS_PORT'] || '6379'
6 }
7end
8
9Sidekiq.configure_client do |config|
10 config.redis = {
11 host: ENV['REDIS_HOST'],
12 port: ENV['REDIS_PORT'] || '6379'
13 }
14end
就像我们的数据库配置设置一样,这些设置使我们能够动态设置主机和端口参数,允许我们在运行时替换适当的值,而无需修改应用程序代码本身。除了REDIS_HOST之外,我们还为REDIS_PORT设置了一个默认值,以防它在其他地方没有设置。
编辑完成后,保存并关闭文件。
接下来,为了确保应用程序的敏感数据不会复制到版本控制,我们可以在项目的.gitignore文件中添加.env,这会告诉Git忽略项目中的哪些文件。打开文件进行编辑:
1nano .gitignore
在文件的底部,为.env添加一个条目:
1[label ~/rails-docker/.gitignore]
2yarn-debug.log*
3.yarn-integrity
4.env
编辑完成后,保存并关闭文件。
接下来,我们将创建一个.dockerloonre文件来设置不应该复制到我们的容器中的内容。打开文件进行编辑:
1.dockerignore
将以下代码添加到文件中,这会告诉Docker忽略一些我们不需要复制到容器中的内容:
1[label ~/rails-docker/.dockerignore]
2.DS_Store
3.bin
4.git
5.gitignore
6.bundleignore
7.bundle
8.byebug_history
9.rspec
10tmp
11log
12test
13config/deploy
14public/packs
15public/packs-test
16node_modules
17yarn-error.log
18coverage/
在此文件的末尾也添加.env:
1[label ~/rails-docker/.dockerignore]
2. . .
3yarn-error.log
4coverage/
5.env
编辑完成后,保存并关闭文件。
作为最后一步,我们将创建一些种子数据,以便我们的应用程序在启动时具有一些记录。
打开db目录下的种子数据文件:
1nano db/seeds.rb
将以下代码添加到文件中,以创建四个演示鲨鱼和一个示例帖子:
1[label ~/rails-docker/db/seeds.rb]
2# Adding demo sharks
3sharks = Shark.create([{ name: 'Great White', facts: 'Scary' }, { name: 'Megalodon', facts: 'Ancient' }, { name: 'Hammerhead', facts: 'Hammer-like' }, { name: 'Speartooth', facts: 'Endangered' }])
4Post.create(body: 'These sharks are misunderstood', shark: sharks.first)
该种子数据将创建四条鲨鱼和一条与第一条鲨鱼相关联的帖子。
完成编辑后保存并关闭文件。
将应用程序配置为使用PostgreSQL并创建环境变量后,就可以编写应用程序Dockerfile了。
Step 3 -编写Dockerfile和Entrypoint文件
您的Dockerfile指定在创建应用程序容器时将包括哪些内容。使用Dockerfile允许您定义容器环境,并避免与依赖项或运行时版本的差异。
遵循这些构建优化containers,的指导方针],我们将使用阿尔卑斯基)并尝试将图像层降至最低,从而使我们的图像尽可能高效。
打开当前目录中的Docker文件:
1nano Dockerfile
Docker图像是使用一系列相互构建的分层图像创建的。我们的第一步将是为我们的应用程序添加_base Image_,它将构成应用程序构建的起点。
将以下代码添加到文件中,以添加Ruby AlMountain图像作为基础:
1[label ~/rails-docker/Dockerfile]
2FROM ruby:2.5.1-alpine
alpine镜像来自Alpine Linux项目,它将帮助我们缩小镜像大小。有关alpine镜像是否适合您的项目的更多信息,请参阅Docker Hub Ruby镜像页面镜像变体 部分的完整讨论。
在开发中使用alpine时需要考虑的一些因素:
- 保持较小的映像大小将减少页面和资源加载时间,特别是在您还将卷保持在最小的情况下。这有助于使您在开发过程中的用户体验更快、更接近于在非容器环境中本地工作时的用户体验。
- 开发映像和生产映像之间的对等有助于成功部署。由于团队经常选择在生产中使用阿尔卑斯山图像以获得速度优势,因此使用阿尔卑斯山基地进行开发有助于在转移到生产时抵消问题。
接下来,设置一个环境变量以指定Bundler版本:
1[label ~/rails-docker/Dockerfile]
2. . .
3ENV BUNDLER_VERSION=2.0.2
这是我们将采取的步骤之一,以避免我们环境中可用的默认bundler版本与我们的应用程序代码之间的版本冲突,应用程序代码需要bundler 2.0.2。
接下来,将使用应用程序所需的包添加到Docker文件中:
1[label ~/rails-docker/Dockerfile]
2. . .
3RUN apk add --update --no-cache \
4 binutils-gold \
5 build-base \
6 curl \
7 file \
8 g++ \
9 gcc \
10 git \
11 less \
12 libstdc++ \
13 libffi-dev \
14 libc-dev \
15 linux-headers \
16 libxml2-dev \
17 libxslt-dev \
18 libgcrypt-dev \
19 make \
20 netcat-openbsd \
21 nodejs \
22 openssl \
23 pkgconfig \
24 postgresql-dev \
25 python \
26 tzdata \
27 yarn
这些包包括nodejs‘和ya n`等。由于我们的应用程序通过webpack,为资产提供服务],因此我们需要包括Node.js和Yarn),以便应用程序能够正常工作。
请记住,alpine映像非常小:当您包装自己的应用程序时,这里列出的包并不是您在开发中可能想要或需要的全部。
接下来,安装相应的bundler版本:
1[label ~/rails-docker/Dockerfile]
2. . .
3RUN gem install bundler -v 2.0.2
这一步将确保我们的集装化环境与本项目的Gemfile.lock文件中的规范一致。
现在在容器上设置应用程序的工作目录:
1[label ~/rails-docker/Dockerfile]
2. . .
3WORKDIR /app
复制您的Gemfile和Gemfile.lock:
1[label ~/rails-docker/Dockerfile]
2. . .
3COPY Gemfile Gemfile.lock ./
将这些文件作为一个独立的步骤进行复制,然后执行Bundle Installation,这意味着您不需要在每次更改应用程序代码时都重新构建项目gem。这将与我们将包括在合成文件中的gem卷一起工作,在重新创建服务但项目gem保持不变的情况下,gem将装载到您的应用程序容器中。
接下来,设置nokogirigem内部版本的配置选项:
1[label ~/rails-docker/Dockerfile]
2. . .
3RUN bundle config build.nokogiri --use-system-libraries
4. . .
此步骤使用我们添加到Run apk Add versions](https://nokogiri.org/tutorials/installing_nokogiri.html# install-with-system-libraries)中的应用程序容器的libxml2和libxslt库…构建nokigiri[站在上面。
接下来,安装项目gems:
1[label ~/rails-docker/Dockerfile]
2. . .
3RUN bundle check || bundle install
这条指令在安装之前检查gem是否已经安装。
接下来,我们将重复我们对gem使用的相同过程,以及我们的JavaScript包和依赖项。首先复制包元数据,然后安装依赖项,最后将应用程序代码复制到容器映像中。
要开始使用Dockerfile的Java部分,请将主机上当前项目目录中的Package.json和ya n.lock复制到容器中:
1[label ~/rails-docker/Dockerfile]
2. . .
3COPY package.json yarn.lock ./
然后安装所需的包,并使用yansinstall:
1[label ~/rails-docker/Dockerfile]
2. . .
3RUN yarn install --check-files
此指令包括--check-files标志和ya n命令,该功能可确保之前安装的任何文件都未被删除。与我们的gem一样,我们将在编写合成文件时使用卷来管理node_modes目录中的包的持久性。
最后,复制其余的应用程序代码,并使用入口点脚本启动应用程序:
1[label ~/rails-docker/Dockerfile]
2. . .
3COPY . ./
4
5ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
使用入口点脚本允许我们将容器作为executable.运行
最终的Dockerfile将如下所示:
1[label ~/rails-docker/Dockerfile]
2FROM ruby:2.5.1-alpine
3
4ENV BUNDLER_VERSION=2.0.2
5
6RUN apk add --update --no-cache \
7 binutils-gold \
8 build-base \
9 curl \
10 file \
11 g++ \
12 gcc \
13 git \
14 less \
15 libstdc++ \
16 libffi-dev \
17 libc-dev \
18 linux-headers \
19 libxml2-dev \
20 libxslt-dev \
21 libgcrypt-dev \
22 make \
23 netcat-openbsd \
24 nodejs \
25 openssl \
26 pkgconfig \
27 postgresql-dev \
28 python \
29 tzdata \
30 yarn
31
32RUN gem install bundler -v 2.0.2
33
34WORKDIR /app
35
36COPY Gemfile Gemfile.lock ./
37
38RUN bundle config build.nokogiri --use-system-libraries
39
40RUN bundle check || bundle install
41
42COPY package.json yarn.lock ./
43
44RUN yarn install --check-files
45
46COPY . ./
47
48ENTRYPOINT ["./entrypoints/docker-entrypoint.sh"]
编辑完成后,保存并关闭文件。
接下来,为入口点脚本创建一个名为"entrypoints`的目录:
1mkdir entrypoints
该目录将包括我们的主入口点脚本和Sidekiq服务的脚本。
打开应用程序入口点脚本的文件:
1nano entrypoints/docker-entrypoint.sh
将以下代码添加到文件中:
1[label rails-docker/entrypoints/docker-entrypoint.sh]
2#!/bin/sh
3
4set -e
5
6if [ -f tmp/pids/server.pid ]; then
7 rm tmp/pids/server.pid
8fi
9
10bundle exec rails s -b 0.0.0.0
第一个重要的行是set-e,它告诉运行脚本的/bin/sh外壳在脚本稍后出现问题时快速失败。接下来,该脚本检查tmp/pids/server.pid是否不存在,以确保在启动应用程序时不会出现服务器冲突。最后,该脚本使用Bundle exec rails s命令启动Rails服务器。我们在此命令中使用-b选项将服务器绑定到所有IP地址,而不是默认的localhost。此调用使Rails服务器将传入请求路由到容器IP,而不是默认的localhost。
编辑完成后,保存并关闭文件。
使脚本可执行:
1chmod +x entrypoints/docker-entrypoint.sh
接下来,我们将创建一个脚本来启动我们的`side kiq‘服务,该服务将处理我们的Sidekiq作业。有关此应用程序如何使用Sidekiq的更多信息,请参阅如何将Sidekiq和Redis添加到Ruby on rails Application.
打开Sidekiq入口点脚本的文件:
1nano entrypoints/sidekiq-entrypoint.sh
将以下代码添加到文件以启动Sidekiq:
1[label ~/rails-docker/entrypoints/sidekiq-entrypoint.sh]
2#!/bin/sh
3
4set -e
5
6if [ -f tmp/pids/server.pid ]; then
7 rm tmp/pids/server.pid
8fi
9
10bundle exec sidekiq
此脚本在我们的应用程序包的上下文中启动Sidekiq。
编辑完成后,保存并关闭文件。使其可执行:
1chmod +x entrypoints/sidekiq-entrypoint.sh
有了入口点脚本和Dockerfile,就可以在Compose文件中定义服务了。
Step 4 -使用Docker Compose定义服务
使用Docker Compose,我们将能够运行设置所需的多个容器。我们将在主docker-compose.yml文件中定义我们的compose_services_。Compose中的服务是一个运行的容器,服务定义--您将包含在docker-compose.yml文件中--包含有关每个容器镜像将如何运行的信息。组合工具允许您定义多个服务来构建多容器应用程序。
我们的应用程序设置将包括以下服务:
- 应用程序本身
- PostgreSQL数据库
- 雷迪斯
- Sidekiq
我们还将把绑定挂载作为设置的一部分,这样我们在开发期间所做的任何代码更改都将立即与需要访问此代码的容器同步。
请注意,我们并没有定义一个[series](https://www.digitalocean.com/community/tutorial_series/rails-on-containers),‘服务,因为测试超出了本教程和测试测试的范围,但是您可以按照我们在这里为side kiq`服务使用的先例来进行测试。
打开docker-compose.yml文件:
1nano docker-compose.yml
首先,添加应用程序服务定义:
1[label ~/rails-docker/docker-compose.yml]
2version: '3.4'
3
4services:
5 app:
6 build:
7 context: .
8 dockerfile: Dockerfile
9 depends_on:
10 - database
11 - redis
12 ports:
13 - "3000:3000"
14 volumes:
15 - .:/app
16 - gem_cache:/usr/local/bundle/gems
17 - node_modules:/app/node_modules
18 env_file: .env
19 environment:
20 RAILS_ENV: development
app服务定义包括以下选项:
build:这定义了配置选项,包括context和dockerfile,当Compose构建应用程序映像时将应用这些选项。如果你想使用像Docker Hub这样的注册表中的现有镜像,你可以使用image指令,其中包含关于你的用户名、存储库和镜像标签的信息。context:这定义了镜像构建的构建上下文-在本例中,是当前项目目录。dockerfile:指定当前项目目录中的Dockerfile,因为Compose将使用该文件构建应用程序映像。depends_on:首先设置database和redis容器,以便它们在app之前启动和运行。ports:将主机的端口3000映射到容器的端口3000。volumes:我们在这里包括两种类型的挂载:- 第一个是bind mount,它将主机上的应用程序代码挂载到容器上的
/app目录。这将促进快速开发,因为您对主机代码所做的任何更改都将立即填充到容器中。 - 第二个是命名的卷,
gem_cache。当bundle install指令在容器中运行时,它将安装项目gems。添加此卷意味着如果重新创建容器,gem将被挂载到新容器。此挂载假定项目没有任何更改,因此如果您在开发中对项目gem进行了更改,则需要记住在重新创建应用程序服务之前删除此卷。 - 第三个卷是
node_modules目录的命名卷。而不是将node_modules挂载到主机,这可能导致开发中的包差异和权限冲突,此卷将确保此目录中的包被持久化并反映项目的当前状态。同样,如果修改项目的Node依赖项,则需要删除并重新创建此卷。
- 第一个是bind mount,它将主机上的应用程序代码挂载到容器上的
env_file:这告诉Compose,我们希望从构建上下文中名为.env的文件中添加环境变量。环境:使用此选项允许我们设置一个非敏感的环境变量,将有关Rails环境的信息传递给容器。
接下来,在app服务定义下面,添加以下代码来定义您的数据库服务:
1[label ~/rails-docker/docker-compose.yml]
2. . .
3 database:
4 image: postgres:12.1
5 volumes:
6 - db_data:/var/lib/postgresql/data
7 - ./init.sql:/docker-entrypoint-initdb.d/init.sql
与app服务不同,datase服务直接从Docker Hub.)拉取postgres镜像请注意,我们在这里也固定了版本,而不是将其设置为latest或不指定它(默认为latest)。通过这种方式,我们可以确保此设置与此处指定的版本一起工作,并避免因破坏映像的代码更改而带来意外意外。
我们还在这里包含了一个db_data卷,它将在容器启动之间持久化我们的应用程序数据。此外,为了创建我们的sammy数据库用户,我们已经将init.sql启动脚本挂载到容器上相应的目录docker-entry ypoint-initdb.d/。镜像入口点创建默认的postgres用户和数据库后,将运行docker-entry-initdb.d/目录中的所有脚本,您可以使用这些脚本来执行必要的初始化任务。有关更多详细信息,请参阅postgresql镜像documentation]的初始化脚本 部分
接下来,添加redis服务定义:
1[label ~/rails-docker/docker-compose.yml]
2. . .
3 redis:
4 image: redis:5.0.7
与数据库服务类似,redis服务使用来自Docker Hub的镜像。在本例中,我们没有持久化Sidekiq作业缓存。
最后,添加side kiq服务定义:
1[label ~/rails-docker/docker-compose.yml]
2. . .
3 sidekiq:
4 build:
5 context: .
6 dockerfile: Dockerfile
7 depends_on:
8 - app
9 - database
10 - redis
11 volumes:
12 - .:/app
13 - gem_cache:/usr/local/bundle/gems
14 - node_modules:/app/node_modules
15 env_file: .env
16 environment:
17 RAILS_ENV: development
18 entrypoint: ./entrypoints/sidekiq-entrypoint.sh
我们的side kiq‘服务在几个方面类似于我们的app服务:它使用相同的构建上下文和映像、环境变量和卷。但是,它依赖于app、redis和datase服务,因此将是最后启动的。此外,它还使用了一个入口点,该入口点将覆盖Dockerfile中设置的入口点。这个entry ypoint设置指向entry/side kiq-entry ypoint t.sh,其中包含启动side kiq`服务的相应命令。
最后一步,在side kiq服务定义下面添加卷定义:
1[label ~/rails-docker/docker-compose.yml]
2. . .
3volumes:
4 gem_cache:
5 db_data:
6 node_modules:
我们的顶级卷密钥定义了卷gem_cache、db_data和node_modes。当Docker创建卷时,卷的内容存储在由Docker管理的主机文件系统/var/lib/docker/volures/的一部分中。每个卷的内容都存储在/var/lib/docker/volvures/下的一个目录中,并挂载到使用该卷的任何容器中。这样,即使我们移除并重新创建数据库服务,我们的用户将创建的Shark信息数据也将保留在db_data卷中。
完成的文件将如下所示:
1[label ~/rails-docker/docker-compose.yml]
2version: '3.4'
3
4services:
5 app:
6 build:
7 context: .
8 dockerfile: Dockerfile
9 depends_on:
10 - database
11 - redis
12 ports:
13 - "3000:3000"
14 volumes:
15 - .:/app
16 - gem_cache:/usr/local/bundle/gems
17 - node_modules:/app/node_modules
18 env_file: .env
19 environment:
20 RAILS_ENV: development
21
22 database:
23 image: postgres:12.1
24 volumes:
25 - db_data:/var/lib/postgresql/data
26 - ./init.sql:/docker-entrypoint-initdb.d/init.sql
27
28 redis:
29 image: redis:5.0.7
30
31 sidekiq:
32 build:
33 context: .
34 dockerfile: Dockerfile
35 depends_on:
36 - app
37 - database
38 - redis
39 volumes:
40 - .:/app
41 - gem_cache:/usr/local/bundle/gems
42 - node_modules:/app/node_modules
43 env_file: .env
44 environment:
45 RAILS_ENV: development
46 entrypoint: ./entrypoints/sidekiq-entrypoint.sh
47
48volumes:
49 gem_cache:
50 db_data:
51 node_modules:
编辑完成后,保存并关闭文件。
编写了服务定义后,您就可以启动应用程序了。
第五步-测试应用程序
准备好docker-compose.yml文件后,您可以使用docker-compose up命令创建您的服务并为您的数据库设定种子。您还可以通过使用docker-compose down停止和删除容器并重新创建它们来测试您的数据是否持久。
首先构建容器镜像并创建服务,运行带有-d标志的docker-compose up,这将在后台运行容器:
1docker-compose up -d
您将看到已创建服务的输出:
1[secondary_label Output]
2Creating rails-docker_database_1 ... done
3Creating rails-docker_redis_1 ... done
4Creating rails-docker_app_1 ... done
5Creating rails-docker_sidekiq_1 ... done
您还可以通过显示服务的日志输出来获取有关启动进程的更详细信息:
1docker-compose logs
如果一切正常启动,您将看到类似以下内容:
1[secondary_label Output]
2sidekiq_1 | 2019-12-19T15:05:26.365Z pid=6 tid=grk7r6xly INFO: Booting Sidekiq 6.0.3 with redis options {:host=>"redis", :port=>"6379", :id=>"Sidekiq-server-PID-6", :url=>nil}
3sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Running in ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux-musl]
4sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: See LICENSE and the LGPL-3.0 for licensing details.
5sidekiq_1 | 2019-12-19T15:05:31.097Z pid=6 tid=grk7r6xly INFO: Upgrade to Sidekiq Pro for more features and support: http://sidekiq.org
6app_1 | => Booting Puma
7app_1 | => Rails 5.2.3 application starting in development
8app_1 | => Run `rails server -h` for more startup options
9app_1 | Puma starting in single mode...
10app_1 | * Version 3.12.1 (ruby 2.5.1-p57), codename: Llamas in Pajamas
11app_1 | * Min threads: 5, max threads: 5
12app_1 | * Environment: development
13app_1 | * Listening on tcp://0.0.0.0:3000
14app_1 | Use Ctrl-C to stop
15. . .
16database_1 | PostgreSQL init process complete; ready for start up.
17database_1 |
18database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: starting PostgreSQL 12.1 (Debian 12.1-1.pgdg100+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 8.3.0-6) 8.3.0, 64-bit
19database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
20database_1 | 2019-12-19 15:05:20.160 UTC [1] LOG: listening on IPv6 address "::", port 5432
21database_1 | 2019-12-19 15:05:20.163 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
22database_1 | 2019-12-19 15:05:20.182 UTC [63] LOG: database system was shut down at 2019-12-19 15:05:20 UTC
23database_1 | 2019-12-19 15:05:20.187 UTC [1] LOG: database system is ready to accept connections
24. . .
25redis_1 | 1:M 19 Dec 2019 15:05:18.822 * Ready to accept connections
您还可以使用docker-Compose ps:]检查容器的状态
1docker-compose ps
您将看到指示您的容器正在运行的输出:
1[secondary_label Output]
2 Name Command State Ports
3-----------------------------------------------------------------------------------------
4rails-docker_app_1 ./entrypoints/docker-resta ... Up 0.0.0.0:3000->3000/tcp
5rails-docker_database_1 docker-entrypoint.sh postgres Up 5432/tcp
6rails-docker_redis_1 docker-entrypoint.sh redis ... Up 6379/tcp
7rails-docker_sidekiq_1 ./entrypoints/sidekiq-entr ... Up
接下来,创建数据库并设置种子,并使用以下docker-compose execcommand:]在其上运行迁移
1docker-compose exec app bundle exec rake db:setup db:migrate
docker-compose exec命令允许您在您的服务中运行命令;我们在这里使用它在我们的应用程序包的上下文中运行rake db:setup和db:Migrate,以创建和播种数据库并运行迁移。当您从事开发工作时,当您想要针对您的开发数据库运行迁移时,docker-compose exec将被证明对您很有用。
运行此命令后,您将看到以下输出:
1[secondary_label Output]
2Created database 'rails_development'
3Database 'rails_development' already exists
4-- enable_extension("plpgsql")
5 -> 0.0140s
6-- create_table("endangereds", {:force=>:cascade})
7 -> 0.0097s
8-- create_table("posts", {:force=>:cascade})
9 -> 0.0108s
10-- create_table("sharks", {:force=>:cascade})
11 -> 0.0050s
12-- enable_extension("plpgsql")
13 -> 0.0173s
14-- create_table("endangereds", {:force=>:cascade})
15 -> 0.0088s
16-- create_table("posts", {:force=>:cascade})
17 -> 0.0128s
18-- create_table("sharks", {:force=>:cascade})
19 -> 0.0072s
当您的服务正在运行时,您可以在浏览器中访问本地主机:3000或http://your_server_ip:3000。您将看到如下所示的登录页:

我们现在可以测试数据持久性了。点击[获取鲨鱼信息]按钮,即可创建一个新的鲨鱼,进入Sharks/index路径:
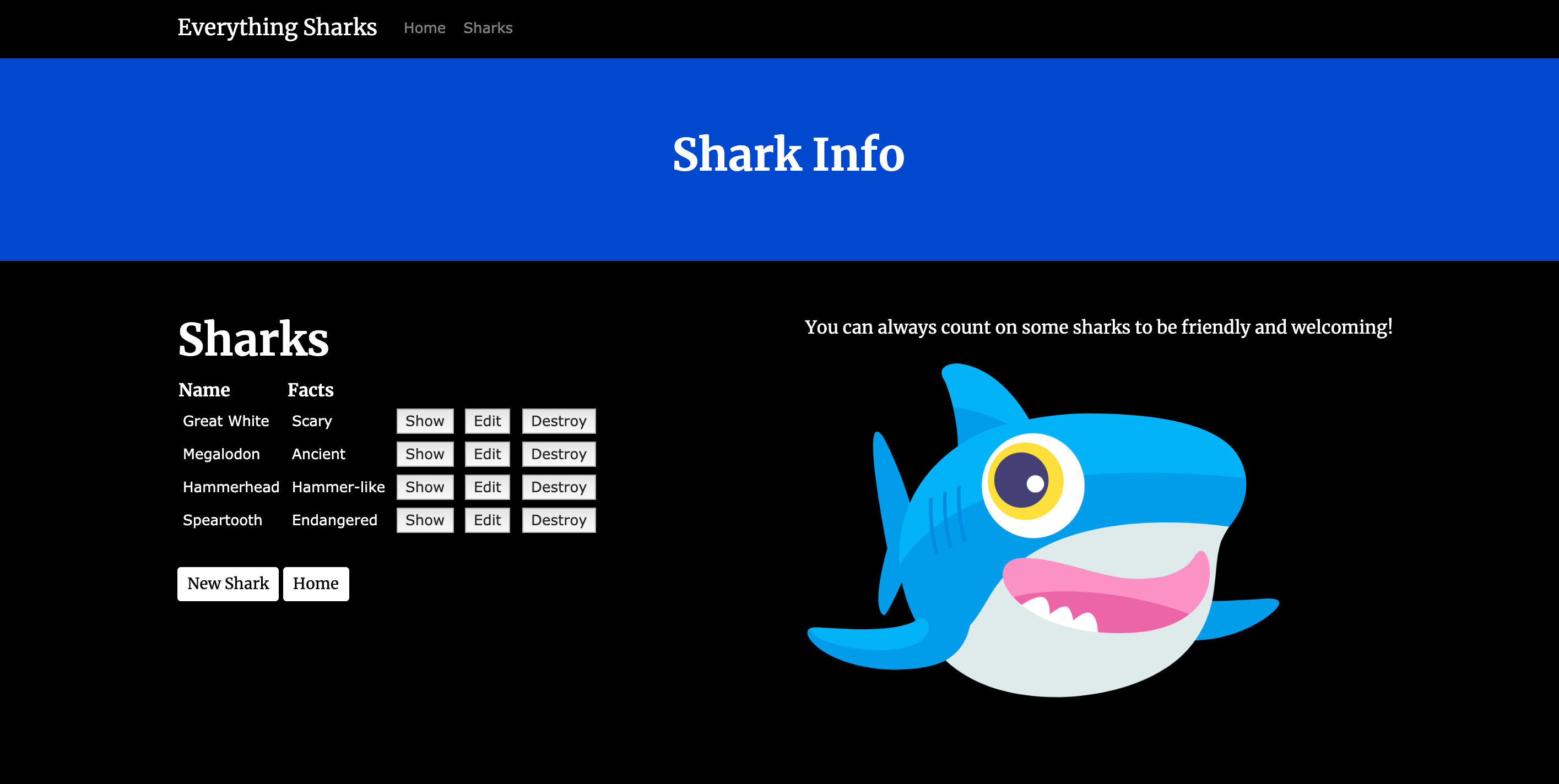
要验证应用程序是否正常工作,我们可以向其添加一些演示信息。点击新鲨鱼 。由于该项目的身份验证settings.],系统将提示您输入用户名(** sammy** )和密码(** Shark**
在新鲨鱼 页面中,在** 名称** 栏中输入Mako,在** 事实** 栏中输入Fast。
点击【创建鲨鱼】按钮,创建鲨鱼。一旦你创建了鲨鱼,点击网站导航栏上的 主页 返回到应用程序的主着陆页。我们现在可以测试Sidekiq是否有效。
点击哪些鲨鱼处于危险之中? 按钮。由于您尚未上传任何濒危鲨鱼,这将带您进入濒危``索引视图:

点击导入濒危鲨鱼 ,即可导入鲨鱼。您将看到一条状态消息,告诉您鲨鱼已导入:

您还将看到导入的开始。刷新页面以查看整个表格:

多亏了Sidekiq,我们成功地大批量上传了濒危鲨鱼,而没有锁定浏览器或干扰其他应用程序功能。
点击页面下方的[首页]按钮,即可返回应用程序主页面:

从这里,再次点击哪些鲨鱼处于危险之中? 。你会再次看到上传的鲨鱼。
既然我们知道我们的应用程序工作正常,我们就可以测试数据持久性了。
回到您的终端,键入以下命令以停止和移除您的容器:
1docker-compose down
请注意,我们没有包括--volumes选项;因此,我们的db_data卷不会被删除。
以下输出确认您的容器和网络已被删除:
1[secondary_label Output]
2Stopping rails-docker_sidekiq_1 ... done
3Stopping rails-docker_app_1 ... done
4Stopping rails-docker_database_1 ... done
5Stopping rails-docker_redis_1 ... done
6Removing rails-docker_sidekiq_1 ... done
7Removing rails-docker_app_1 ... done
8Removing rails-docker_database_1 ... done
9Removing rails-docker_redis_1 ... done
10Removing network rails-docker_default
重新创建容器:
1docker-compose up -d
使用docker-compose exec和bundle exec rails console打开app容器上的Rails控制台:
1docker-compose exec app bundle exec rails console
在提示符下,检查数据库中的lastShark记录:
1Shark.last.inspect
您将看到您刚刚创建的记录:
1[secondary_label IRB session]
2 Shark Load (1.0ms) SELECT "sharks".* FROM "sharks" ORDER BY "sharks"."id" DESC LIMIT $1 [["LIMIT", 1]]
3=> "#<Shark id: 5, name: \"Mako\", facts: \"Fast\", created_at: \"2019-12-20 14:03:28\", updated_at: \"2019-12-20 14:03:28\">"
然后,您可以使用以下命令进行检查,以查看您的濒危鲨鱼是否已被持久化:
1Endangered.all.count
1[secondary_label IRB session]
2 (0.8ms) SELECT COUNT(*) FROM "endangereds"
3=> 73
您的db_data卷已成功挂载到重新创建的datase服务中,您的app服务可以访问保存的数据。如果您通过访问本地主机:3000/Sharks或http://your_server_ip:3000/sharks直接导航到index``Shark页面,您也会看到显示该记录:

您的濒危鲨鱼也将出现在本地主机:3000/濒危/数据或http://your_server_ip:3000/endangered/data视图:
您的应用程序现在运行在已启用数据持久化和代码同步的Docker容器上。您可以继续在您的主机上测试本地代码更改,由于我们定义的绑定挂载是app服务的一部分,这些更改将同步到您的容器。
结论
通过学习本教程,您已经使用Docker容器为您的Rails应用程序创建了开发设置。通过提取敏感信息并将应用程序的状态与代码分离,您的项目变得更加模块化和可移植)。您还配置了一个样板docker-compose.yml文件,您可以根据开发需求和要求的变化进行修改。
在开发过程中,您可能会有兴趣了解更多有关为容器化和云Native工作流]设计应用程序的信息。有关这些主题的更多信息,请参阅构建Kubernetes应用程序和现代化Kubernetes应用程序]。或者,如果您想投资于Kubernetes学习序列,请查看Kubernetes for Full-Stack Developers curriculum.
要了解有关应用程序代码本身的更多信息,请参阅本series:中的其他教程