R中的混淆矩阵是将预测与实际值进行分类的表。它包括两个维度,其中一个维度表示预测值,另一个维度表示实际值。
_混淆矩阵中的每一行将代表预测值,列将负责实际值。反之亦然。尽管这些矩阵很简单,但它们背后的术语似乎很复杂。总是有可能对课程感到困惑。因此,术语--混淆矩阵 _
在大多数参考资料中,您可能已经看到了2x2R中的矩阵。但请注意,您可以创建包含任意数量的类值的矩阵。您可以在下面看到两类和三类二元模型的混淆矩阵。
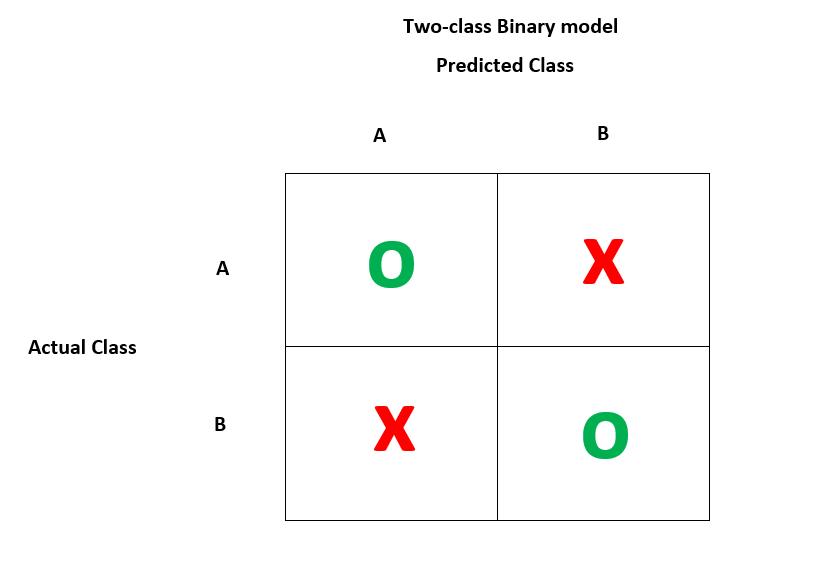 中的混淆矩阵
中的混淆矩阵
这是一个两类二元模型,显示了预测值和实际值的分布。
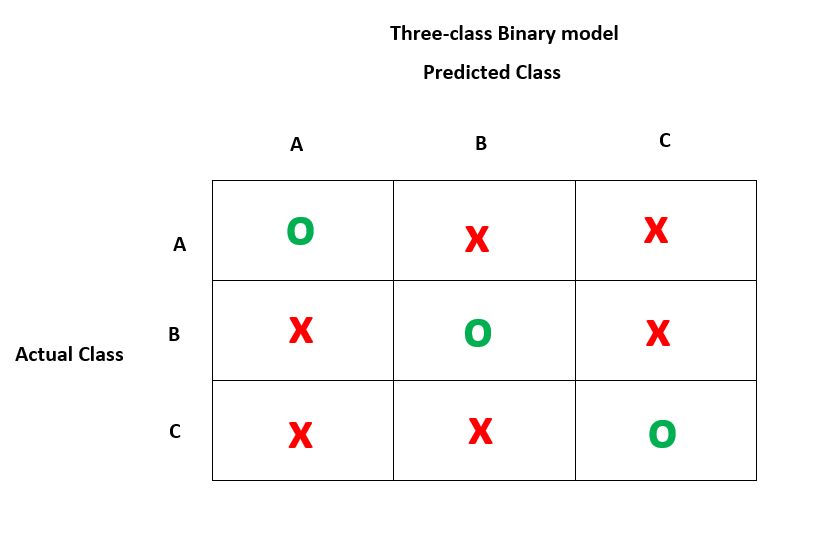 中的混淆矩阵
中的混淆矩阵
这是一个三类二元模型,它显示了数据的预测值和实际值的分布。
在R中的混淆矩阵中,感兴趣的类或我们的目标类将是正* ** 类,其余的将是 负类。**
你可以借助2x2混淆矩阵来表达正类和负类之间的关系。它将包括4个类别-
- True Positive(TN) -如果感兴趣/目标,则将其正确归类为类别。
- True Negative(TN) -这被正确归类为非兴趣/目标类别。
- 假阳性(FP) -这被错误地归类为兴趣/目标类别。
- 假否定(FN) -这被错误地归类为非兴趣/目标类别。
使用R创建简单的混淆矩阵
在本节中,我们将使用我们将在此处创建的演示编号数据。在这里,我们的兴趣/目标类将为0。
让我们看看如何使用混淆矩阵来计算这个。您可以将目标类设置为0并观察结果。
这可能会让人有点困惑,但请慢慢来,深入挖掘,让它变得更好。让我们使用脱字符 库来完成此操作。
1#Insatll required packages
2install.packages('caret')
3
4#Import required library
5library(caret)
6
7#Creates vectors having data points
8expected_value <- factor(c(1,0,1,0,1,1,1,0,0,1))
9predicted_value <- factor(c(1,0,0,1,1,1,0,0,0,1))
10
11#Creating confusion matrix
12example <- confusionMatrix(data=predicted_value, reference = expected_value)
13
14#Display results
15example
1Confusion Matrix and Statistics
2
3 Reference
4Prediction 0 1
5 0 3 2
6 1 1 4
7
8 Accuracy : 0.7
9 95% CI : (0.3475, 0.9333)
10 No Information Rate : 0.6
11 P-Value [Acc > NIR] : 0.3823
12
13 Kappa : 0.4
14
15 Mcnemar's Test P-Value : 1.0000
16
17 Sensitivity : 0.7500
18 Specificity : 0.6667
19 Pos Pred Value : 0.6000
20 Neg Pred Value : 0.8000
21 Prevalence : 0.4000
22 Detection Rate : 0.3000
23 Detection Prevalence : 0.5000
24 Balanced Accuracy : 0.7083
25
26 'Positive' Class : 0
哇!那很酷啊。现在我相信事情在你那边已经很清楚了。仅此输出就可以回答现在在您脑海中滚动的大量问题!
性能测评
使用2x2混淆矩阵可以很容易地计算出模型的成功率或精度。计算准确度的公式为-
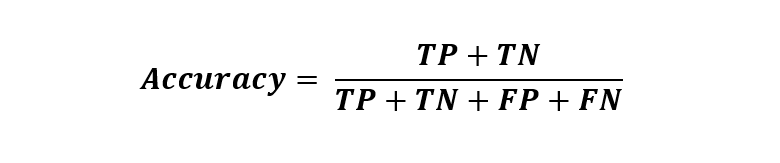
这里,Tp、Tn、Fp和Fn将表示属于它们的特定值计数。精确度将通过按公式求和和除值来计算。
在此之后,我们鼓励您找到我们的模型预测错误的错误率。错误率的公式为:
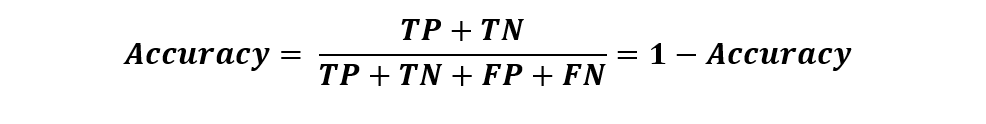
错误率计算简单,切中要害。如果一个模型将以90%的准确率执行,那么错误率将是10%。就这么简单。
获得R中的混淆矩阵的简单方法是使用table()函数。让我们看看它是如何工作的。
1table(expected_value,predicted_value)
1predicted_value
2expected_value 0 1
3 0 3 1
4 1 2 4
让我为你把它做得更漂亮。
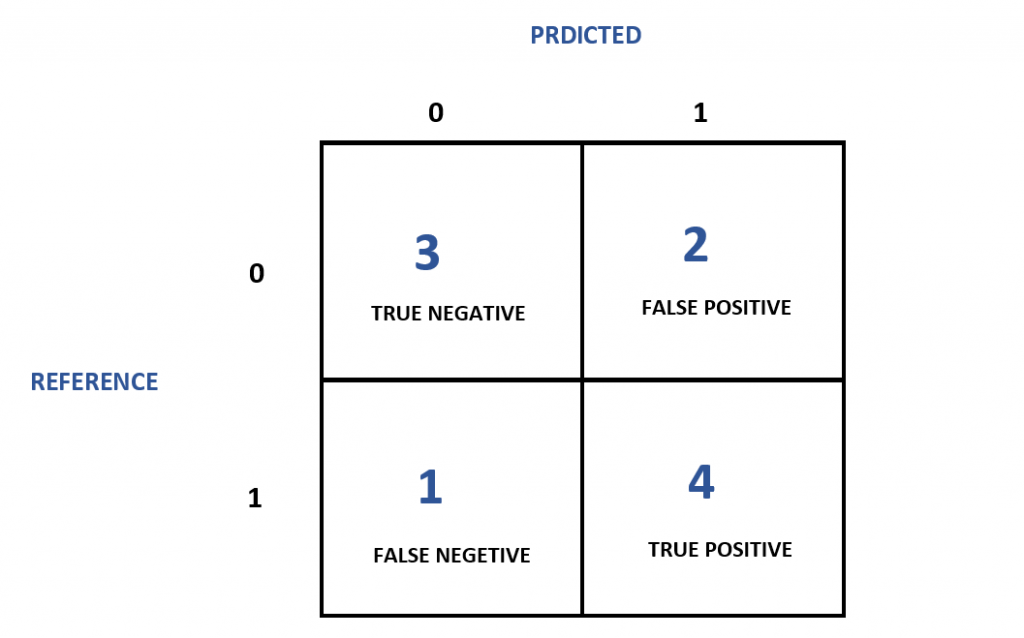
完美!现在您可以观察以下几点-
- 模型预测0为0,3次,0为1,1次
- 模型预测1为0,2次,1为1,4次
- 模型的准确率为70%。
使用gdels的混淆矩阵
如果您想对混淆矩阵有更多的了解,可以使用R中的‘gModel’包。
让我们安装这个包,看看它是如何工作的。GModels包为模型提供了一个可定制的解决方案。
1#install required packages
2install.packages('gmodels')
3#import required library
4library(gmodels)
5
6#Computes the crosstable calculations
7CrossTable(expected_value,predicted_value)
1Cell Contents
2|-------------------------|
3| N |
4| Chi-square contribution |
5| N / Row Total |
6| N / Col Total |
7| N / Table Total |
8|-------------------------|
9
10Total Observations in Table: 10
11
12 | predicted_value
13expected_value | 0 | 1 | Row Total |
14---------------|-----------|-----------|-----------|
15 0 | 3 | 1 | 4 |
16 | 0.500 | 0.500 | |
17 | 0.750 | 0.250 | 0.400 |
18 | 0.600 | 0.200 | |
19 | 0.300 | 0.100 | |
20---------------|-----------|-----------|-----------|
21 1 | 2 | 4 | 6 |
22 | 0.333 | 0.333 | |
23 | 0.333 | 0.667 | 0.600 |
24 | 0.400 | 0.800 | |
25 | 0.200 | 0.400 | |
26---------------|-----------|-----------|-----------|
27 Column Total | 5 | 5 | 10 |
28 | 0.500 | 0.500 | |
29---------------|-----------|-----------|-----------|
太让人吃惊了!您可以看到gModel库根据给定数据返回的大量信息。信息很多,不是吗?
使用混淆矩阵计算时间
最后,是时候使用我们的混淆矩阵进行一些严肃的计算了。我们定义了实现精度和错误率的公式。
勇敢点儿!
1Accuracy = (3 + 4) / (3+2+1+4)
10.7 = 70 %
对于给定的数据和观测,准确率分数为70%。现在,很简单,错误率将是30%,明白吗?
如果不是,我们可以通过我们的公式。
1Error rate = (2+1) / (3+2+1+4)
10.30 = 30%
凉爽的!该模型错误地预测了30%的数值。错误率为30%。
这也等于公式-
1error rate = 1 - accuracy
11 - 0.70 = 0.30 = 30%
你可以简单地用1减去精确值,就可以得到错误率。不过,事情进展得相当顺利!
总结
混淆矩阵是表示数据点的预测值和实际值的值表。您可以使用最有用的R库(如插入符号、gModel)和函数(如table()和cross table())来更深入地了解数据。
R语言中的混淆矩阵将是分类数据问题的关键方面。尝试将上述所有技术应用于您首选的数据集并观察结果。
现在就到这里吧。快乐R!
更多内容阅读: R documentation