X# Apache 火种源
Apache Spark是一个开源数据处理框架,可以在分布式环境中对大数据执行分析操作。这是加州大学伯克利分校的一个学术项目,最初由加州大学伯克利分校AMPLab的Matei Zaharia于2009年启动。Apache Spark是在一个名为Mesos的集群管理工具之上创建的。这后来被修改和升级,以便它可以在具有分布式处理的基于集群的环境中工作。
ApacheSpark示例项目设置
我们将使用Maven为演示创建一个样例项目。要创建项目,请在将用作工作区的目录中执行以下命令:
1mvn archetype:generate -DgroupId=com.journaldev.sparkdemo -DartifactId=JD-Spark-WordCount -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
如果您是第一次运行maven,则需要几秒钟才能完成生成命令,因为maven必须下载所有必需的插件和构件才能完成生成任务。一旦创建了项目,就可以在您最喜欢的IDE中打开它。下一步是向项目添加适当的Maven依赖项。下面是带有适当依赖关系的pom.xml文件:
1<dependencies>
2
3 <!-- Import Spark -->
4 <dependency>
5 <groupId>org.apache.spark</groupId>
6 <artifactId>spark-core_2.11</artifactId>
7 <version>1.4.0</version>
8 </dependency>
9
10 <dependency>
11 <groupId>junit</groupId>
12 <artifactId>junit</artifactId>
13 <version>4.11</version>
14 <scope>test</scope>
15 </dependency>
16
17</dependencies>
18
19<build>
20 <plugins>
21 <plugin>
22 <groupId>org.apache.maven.plugins</groupId>
23 <artifactId>maven-compiler-plugin</artifactId>
24 <version>2.0.2</version>
25 <configuration>
26 <source>1.8</source>
27 <target>1.8</target>
28 </configuration>
29 </plugin>
30 <plugin>
31 <groupId>org.apache.maven.plugins</groupId>
32 <artifactId>maven-jar-plugin</artifactId>
33 <configuration>
34 <archive>
35 <manifest>
36 <addClasspath>true</addClasspath>
37 <classpathPrefix>lib/</classpathPrefix>
38 <mainClass>com.geekcap.javaworld.sparkexample.WordCount</mainClass>
39 </manifest>
40 </archive>
41 </configuration>
42 </plugin>
43 <plugin>
44 <groupId>org.apache.maven.plugins</groupId>
45 <artifactId>maven-dependency-plugin</artifactId>
46 <executions>
47 <execution>
48 <id>copy</id>
49 <phase>install</phase>
50 <goals>
51 <goal>copy-dependencies</goal>
52 </goals>
53 <configuration>
54 <outputDirectory>${project.build.directory}/lib</outputDirectory>
55 </configuration>
56 </execution>
57 </executions>
58 </plugin>
59 </plugins>
60</build>
由于这是一个基于maven的项目,实际上不需要在您的机器上安装和设置ApacheSpark 。当我们运行这个项目时,将启动一个运行时的ApacheSpark实例,一旦程序执行完毕,它将被关闭。最后,为了理解在添加依赖项时添加到项目中的所有JAR,我们可以运行一个简单的Maven命令,该命令允许我们在添加一些依赖项时看到项目的完整依赖关系树。以下是我们可以使用的命令:
1mvn dependency:tree
当我们运行此命令时,它将向我们显示以下依赖关系树:
1shubham:JD-Spark-WordCount shubham$ mvn dependency:tree
2
3[INFO] Scanning for projects...
4[WARNING]
5[WARNING] Some problems were encountered while building the effective model for com.journaldev:java-word-count:jar:1.0-SNAPSHOT
6[WARNING] 'build.plugins.plugin.version' for org.apache.maven.plugins:maven-jar-plugin is missing. @ line 41, column 21
7[WARNING]
8[WARNING] It is highly recommended to fix these problems because they threaten the stability of your build.
9[WARNING]
10[WARNING] For this reason, future Maven versions might no longer support building such malformed projects.
11[WARNING]
12[INFO]
13[INFO] -------------------< com.journaldev:java-word-count >-------------------
14[INFO] Building java-word-count 1.0-SNAPSHOT
15[INFO] --------------------------------[ jar ]---------------------------------
16[INFO]
17[INFO] --- maven-dependency-plugin:2.8:tree (default-cli) @ java-word-count ---
18[INFO] com.journaldev:java-word-count:jar:1.0-SNAPSHOT
19[INFO] +- org.apache.spark:spark-core_2.11:jar:1.4.0:compile
20[INFO] | +- com.twitter:chill_2.11:jar:0.5.0:compile
21[INFO] | | \- com.esotericsoftware.kryo:kryo:jar:2.21:compile
22[INFO] | | +- com.esotericsoftware.reflectasm:reflectasm:jar:shaded:1.07:compile
23[INFO] | | +- com.esotericsoftware.minlog:minlog:jar:1.2:compile
24[INFO] | | \- org.objenesis:objenesis:jar:1.2:compile
25[INFO] | +- com.twitter:chill-java:jar:0.5.0:compile
26[INFO] | +- org.apache.hadoop:hadoop-client:jar:2.2.0:compile
27[INFO] | | +- org.apache.hadoop:hadoop-common:jar:2.2.0:compile
28[INFO] | | | +- commons-cli:commons-cli:jar:1.2:compile
29[INFO] | | | +- org.apache.commons:commons-math:jar:2.1:compile
30[INFO] | | | +- xmlenc:xmlenc:jar:0.52:compile
31[INFO] | | | +- commons-io:commons-io:jar:2.1:compile
32[INFO] | | | +- commons-logging:commons-logging:jar:1.1.1:compile
33[INFO] | | | +- commons-lang:commons-lang:jar:2.5:compile
34[INFO] | | | +- commons-configuration:commons-configuration:jar:1.6:compile
35[INFO] | | | | +- commons-collections:commons-collections:jar:3.2.1:compile
36[INFO] | | | | +- commons-digester:commons-digester:jar:1.8:compile
37[INFO] | | | | | \- commons-beanutils:commons-beanutils:jar:1.7.0:compile
38[INFO] | | | | \- commons-beanutils:commons-beanutils-core:jar:1.8.0:compile
39[INFO] | | | +- org.codehaus.jackson:jackson-core-asl:jar:1.8.8:compile
40[INFO] | | | +- org.apache.avro:avro:jar:1.7.4:compile
41[INFO] | | | +- com.google.protobuf:protobuf-java:jar:2.5.0:compile
42[INFO] | | | +- org.apache.hadoop:hadoop-auth:jar:2.2.0:compile
43[INFO] | | | \- org.apache.commons:commons-compress:jar:1.4.1:compile
44[INFO] | | | \- org.tukaani:xz:jar:1.0:compile
45[INFO] | | +- org.apache.hadoop:hadoop-hdfs:jar:2.2.0:compile
46[INFO] | | | \- org.mortbay.jetty:jetty-util:jar:6.1.26:compile
47[INFO] | | +- org.apache.hadoop:hadoop-mapreduce-client-app:jar:2.2.0:compile
48[INFO] | | | +- org.apache.hadoop:hadoop-mapreduce-client-common:jar:2.2.0:compile
49[INFO] | | | | +- org.apache.hadoop:hadoop-yarn-client:jar:2.2.0:compile
50[INFO] | | | | | +- com.google.inject:guice:jar:3.0:compile
51[INFO] | | | | | | +- javax.inject:javax.inject:jar:1:compile
52[INFO] | | | | | | \- aopalliance:aopalliance:jar:1.0:compile
53[INFO] | | | | | +- com.sun.jersey.jersey-test-framework:jersey-test-framework-grizzly2:jar:1.9:compile
54[INFO] | | | | | | +- com.sun.jersey.jersey-test-framework:jersey-test-framework-core:jar:1.9:compile
55[INFO] | | | | | | | +- javax.servlet:javax.servlet-api:jar:3.0.1:compile
56[INFO] | | | | | | | \- com.sun.jersey:jersey-client:jar:1.9:compile
57[INFO] | | | | | | \- com.sun.jersey:jersey-grizzly2:jar:1.9:compile
58[INFO] | | | | | | +- org.glassfish.grizzly:grizzly-https:jar:2.1.2:compile
59[INFO] | | | | | | | \- org.glassfish.grizzly:grizzly-framework:jar:2.1.2:compile
60[INFO] | | | | | | | \- org.glassfish.gmbal:gmbal-api-only:jar:3.0.0-b023:compile
61[INFO] | | | | | | | \- org.glassfish.external:management-api:jar:3.0.0-b012:compile
62[INFO] | | | | | | +- org.glassfish.grizzly:grizzly-http-server:jar:2.1.2:compile
63[INFO] | | | | | | | \- org.glassfish.grizzly:grizzly-rcm:jar:2.1.2:compile
64[INFO] | | | | | | +- org.glassfish.grizzly:grizzly-http-servlet:jar:2.1.2:compile
65[INFO] | | | | | | \- org.glassfish:javax.servlet:jar:3.1:compile
66[INFO] | | | | | +- com.sun.jersey:jersey-json:jar:1.9:compile
67[INFO] | | | | | | +- org.codehaus.jettison:jettison:jar:1.1:compile
68[INFO] | | | | | | | \- stax:stax-api:jar:1.0.1:compile
69[INFO] | | | | | | +- com.sun.xml.bind:jaxb-impl:jar:2.2.3-1:compile
70[INFO] | | | | | | | \- javax.xml.bind:jaxb-api:jar:2.2.2:compile
71[INFO] | | | | | | | \- javax.activation:activation:jar:1.1:compile
72[INFO] | | | | | | +- org.codehaus.jackson:jackson-jaxrs:jar:1.8.3:compile
73[INFO] | | | | | | \- org.codehaus.jackson:jackson-xc:jar:1.8.3:compile
74[INFO] | | | | | \- com.sun.jersey.contribs:jersey-guice:jar:1.9:compile
75[INFO] | | | | \- org.apache.hadoop:hadoop-yarn-server-common:jar:2.2.0:compile
76[INFO] | | | \- org.apache.hadoop:hadoop-mapreduce-client-shuffle:jar:2.2.0:compile
77[INFO] | | +- org.apache.hadoop:hadoop-yarn-api:jar:2.2.0:compile
78[INFO] | | +- org.apache.hadoop:hadoop-mapreduce-client-core:jar:2.2.0:compile
79[INFO] | | | \- org.apache.hadoop:hadoop-yarn-common:jar:2.2.0:compile
80[INFO] | | +- org.apache.hadoop:hadoop-mapreduce-client-jobclient:jar:2.2.0:compile
81[INFO] | | \- org.apache.hadoop:hadoop-annotations:jar:2.2.0:compile
82[INFO] | +- org.apache.spark:spark-launcher_2.11:jar:1.4.0:compile
83[INFO] | +- org.apache.spark:spark-network-common_2.11:jar:1.4.0:compile
84[INFO] | +- org.apache.spark:spark-network-shuffle_2.11:jar:1.4.0:compile
85[INFO] | +- org.apache.spark:spark-unsafe_2.11:jar:1.4.0:compile
86[INFO] | +- net.java.dev.jets3t:jets3t:jar:0.7.1:compile
87[INFO] | | +- commons-codec:commons-codec:jar:1.3:compile
88[INFO] | | \- commons-httpclient:commons-httpclient:jar:3.1:compile
89[INFO] | +- org.apache.curator:curator-recipes:jar:2.4.0:compile
90[INFO] | | +- org.apache.curator:curator-framework:jar:2.4.0:compile
91[INFO] | | | \- org.apache.curator:curator-client:jar:2.4.0:compile
92[INFO] | | +- org.apache.zookeeper:zookeeper:jar:3.4.5:compile
93[INFO] | | | \- jline:jline:jar:0.9.94:compile
94[INFO] | | \- com.google.guava:guava:jar:14.0.1:compile
95[INFO] | +- org.eclipse.jetty.orbit:javax.servlet:jar:3.0.0.v201112011016:compile
96[INFO] | +- org.apache.commons:commons-lang3:jar:3.3.2:compile
97[INFO] | +- org.apache.commons:commons-math3:jar:3.4.1:compile
98[INFO] | +- com.google.code.findbugs:jsr305:jar:1.3.9:compile
99[INFO] | +- org.slf4j:slf4j-api:jar:1.7.10:compile
100[INFO] | +- org.slf4j:jul-to-slf4j:jar:1.7.10:compile
101[INFO] | +- org.slf4j:jcl-over-slf4j:jar:1.7.10:compile
102[INFO] | +- log4j:log4j:jar:1.2.17:compile
103[INFO] | +- org.slf4j:slf4j-log4j12:jar:1.7.10:compile
104[INFO] | +- com.ning:compress-lzf:jar:1.0.3:compile
105[INFO] | +- org.xerial.snappy:snappy-java:jar:1.1.1.7:compile
106[INFO] | +- net.jpountz.lz4:lz4:jar:1.2.0:compile
107[INFO] | +- org.roaringbitmap:RoaringBitmap:jar:0.4.5:compile
108[INFO] | +- commons-net:commons-net:jar:2.2:compile
109[INFO] | +- org.spark-project.akka:akka-remote_2.11:jar:2.3.4-spark:compile
110[INFO] | | +- org.spark-project.akka:akka-actor_2.11:jar:2.3.4-spark:compile
111[INFO] | | | \- com.typesafe:config:jar:1.2.1:compile
112[INFO] | | +- io.netty:netty:jar:3.8.0.Final:compile
113[INFO] | | +- org.spark-project.protobuf:protobuf-java:jar:2.5.0-spark:compile
114[INFO] | | \- org.uncommons.maths:uncommons-maths:jar:1.2.2a:compile
115[INFO] | +- org.spark-project.akka:akka-slf4j_2.11:jar:2.3.4-spark:compile
116[INFO] | +- org.scala-lang:scala-library:jar:2.11.6:compile
117[INFO] | +- org.json4s:json4s-jackson_2.11:jar:3.2.10:compile
118[INFO] | | \- org.json4s:json4s-core_2.11:jar:3.2.10:compile
119[INFO] | | +- org.json4s:json4s-ast_2.11:jar:3.2.10:compile
120[INFO] | | \- org.scala-lang:scalap:jar:2.11.0:compile
121[INFO] | | \- org.scala-lang:scala-compiler:jar:2.11.0:compile
122[INFO] | | +- org.scala-lang.modules:scala-xml_2.11:jar:1.0.1:compile
123[INFO] | | \- org.scala-lang.modules:scala-parser-combinators_2.11:jar:1.0.1:compile
124[INFO] | +- com.sun.jersey:jersey-server:jar:1.9:compile
125[INFO] | | \- asm:asm:jar:3.1:compile
126[INFO] | +- com.sun.jersey:jersey-core:jar:1.9:compile
127[INFO] | +- org.apache.mesos:mesos:jar:shaded-protobuf:0.21.1:compile
128[INFO] | +- io.netty:netty-all:jar:4.0.23.Final:compile
129[INFO] | +- com.clearspring.analytics:stream:jar:2.7.0:compile
130[INFO] | +- io.dropwizard.metrics:metrics-core:jar:3.1.0:compile
131[INFO] | +- io.dropwizard.metrics:metrics-jvm:jar:3.1.0:compile
132[INFO] | +- io.dropwizard.metrics:metrics-json:jar:3.1.0:compile
133[INFO] | +- io.dropwizard.metrics:metrics-graphite:jar:3.1.0:compile
134[INFO] | +- com.fasterxml.jackson.core:jackson-databind:jar:2.4.4:compile
135[INFO] | | +- com.fasterxml.jackson.core:jackson-annotations:jar:2.4.0:compile
136[INFO] | | \- com.fasterxml.jackson.core:jackson-core:jar:2.4.4:compile
137[INFO] | +- com.fasterxml.jackson.module:jackson-module-scala_2.11:jar:2.4.4:compile
138[INFO] | | +- org.scala-lang:scala-reflect:jar:2.11.2:compile
139[INFO] | | \- com.thoughtworks.paranamer:paranamer:jar:2.6:compile
140[INFO] | +- org.apache.ivy:ivy:jar:2.4.0:compile
141[INFO] | +- oro:oro:jar:2.0.8:compile
142[INFO] | +- org.tachyonproject:tachyon-client:jar:0.6.4:compile
143[INFO] | | \- org.tachyonproject:tachyon:jar:0.6.4:compile
144[INFO] | +- net.razorvine:pyrolite:jar:4.4:compile
145[INFO] | +- net.sf.py4j:py4j:jar:0.8.2.1:compile
146[INFO] | \- org.spark-project.spark:unused:jar:1.0.0:compile
147[INFO] \- junit:junit:jar:4.11:test
148[INFO] \- org.hamcrest:hamcrest-core:jar:1.3:test
149[INFO] ------------------------------------------------------------------------
150[INFO] BUILD SUCCESS
151[INFO] ------------------------------------------------------------------------
152[INFO] Total time: 2.987 s
153[INFO] Finished at: 2018-04-07T15:50:34+05:30
154[INFO] ------------------------------------------------------------------------
只需添加两个依赖项,Spark就收集了项目中所有必需的依赖项,其中包括Scala依赖项以及用Scala本身编写的ApacheSpark。
创建输入文件
当我们要创建一个Word Counter程序时,我们将在项目的根目录中为项目创建一个名为input.txt的示例输入文件。将任何内容放入其中,我们使用以下文本:
1Hello, my name is Shubham and I am author at JournalDev . JournalDev is a great website to ready
2great lessons about Java, Big Data, Python and many more Programming languages.
3
4Big Data lessons are difficult to find but at JournalDev , you can find some excellent
5pieces of lessons written on Big Data.
您可以随意使用此文件中的任何文本。
项目结构
在我们继续并开始处理该项目的代码之前,让我们在这里展示一下在我们完成将所有代码添加到该项目之后将拥有的项目结构:Caption id=)项目结构[/Caption]
{kind=link}
创建WordCounter
现在,我们准备开始编写程序。当你开始使用大数据程序时,导入可能会造成很多混乱。为了避免这种情况,以下是我们将在项目中使用的所有导入:
1import org.apache.spark.SparkConf;
2import org.apache.spark.api.java.JavaPairRDD;
3import org.apache.spark.api.java.JavaRDD;
4import org.apache.spark.api.java.JavaSparkContext;
5import scala.Tuple2;
6
7import java.util.Arrays;
接下来,下面是我们将使用的类的结构:
1package com.journaldev.sparkdemo;
2
3...imports...
4
5public class WordCounter {
6
7 private static void wordCount(String fileName) {
8 ...
9 }
10
11 public static void main(String[] args) {
12 ...
13 }
14}
所有逻辑都位于wordCount方法中。我们将从为SparkConf类定义一个对象开始。此类对象用于将各种Spark参数设置为程序的键-值对。我们只提供简单的参数:
1SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JD Word Counter");
master指定为local,表示该程序应该连接到localhost上运行的Spark线程。应用程序名称只是为Spark提供应用程序元数据的一种方式。现在,我们可以使用以下配置对象构造Spark上下文对象:
1JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
Spark认为它要处理的每一种资源都是RDD(弹性分布式数据集),这有助于它在Find数据结构中组织数据,这样分析起来要高效得多。现在我们将输入文件转换为JavaRDD对象本身:
1JavaRDD<String> inputFile = sparkContext.textFile(fileName);
现在我们将使用Java 8 API来处理JavaRDD文件,并将该文件包含的单词拆分成单独的单词:
1JavaRDD<String> wordsFromFile = inputFile.flatMap(content -> Arrays.asList(content.split(" ")));
同样,我们使用Java 8mapToPair(...)方法对单词进行计数,并提供一个`Word,number‘对,该对可以显示为输出:
1JavaPairRDD countData = wordsFromFile.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);
现在,我们可以将输出文件另存为文本文件:
1countData.saveAsTextFile("CountData");
最后,我们可以使用main()方法提供程序的入口点:
1public static void main(String[] args) {
2 if (args.length == 0) {
3 System.out.println("No files provided.");
4 System.exit(0);
5 }
6 wordCount(args[0]);
7}
完整的文件如下所示:
1package com.journaldev.sparkdemo;
2
3import org.apache.spark.SparkConf;
4import org.apache.spark.api.java.JavaPairRDD;
5import org.apache.spark.api.java.JavaRDD;
6import org.apache.spark.api.java.JavaSparkContext;
7import scala.Tuple2;
8
9import java.util.Arrays;
10
11public class WordCounter {
12
13 private static void wordCount(String fileName) {
14
15 SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JD Word Counter");
16
17 JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
18
19 JavaRDD<String> inputFile = sparkContext.textFile(fileName);
20
21 JavaRDD<String> wordsFromFile = inputFile.flatMap(content -> Arrays.asList(content.split(" ")));
22
23 JavaPairRDD countData = wordsFromFile.mapToPair(t -> new Tuple2(t, 1)).reduceByKey((x, y) -> (int) x + (int) y);
24
25 countData.saveAsTextFile("CountData");
26 }
27
28 public static void main(String[] args) {
29
30 if (args.length == 0) {
31 System.out.println("No files provided.");
32 System.exit(0);
33 }
34
35 wordCount(args[0]);
36 }
37}
现在我们将使用Maven本身来运行这个程序。
运行应用程序
要运行应用程序,请进入程序的根目录并执行以下命令:
1mvn exec:java -Dexec.mainClass=com.journaldev.sparkdemo.WordCounter -Dexec.args="input.txt"
在该命令中,我们为Maven提供了主类的完全限定名称和输入文件的名称。执行完此命令后,我们可以看到在我们的项目中创建了一个新目录:Caption id=)项目输出目录[/Caption]当我们打开该目录和其中名为)](https://journaldev.nyc3.digitaloceanspaces.com/2018/04/word-count-pairs.png)Word Counter OUTPUT[/Caption]
{kind=link}
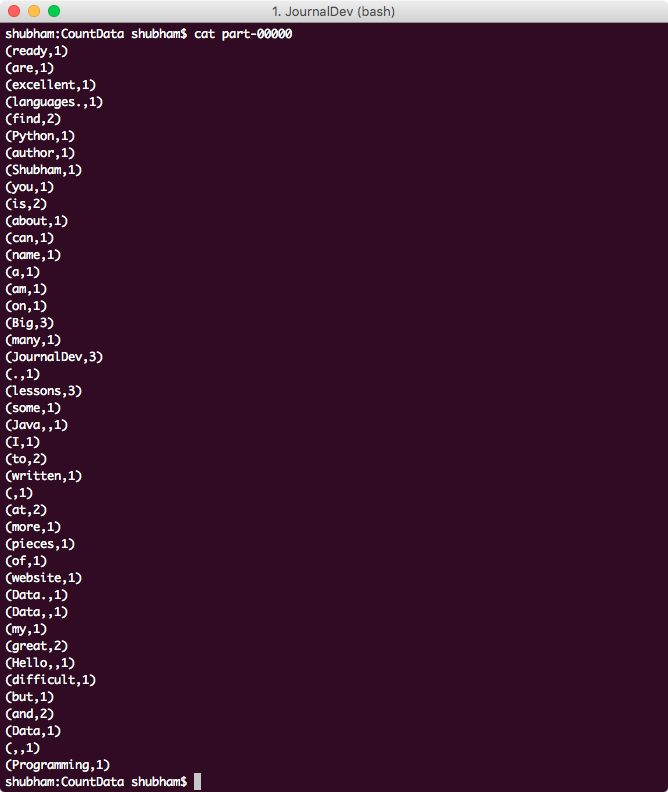Word){kind=link}
结论
在本课中,我们了解了如何在基于Maven的项目中使用ApacheSpark来创建简单但有效的单词计数器程序。阅读更多大数据帖子,以更深入地了解可用的大数据工具和处理框架。
源码下载
下载Spark WordCounter项目:JD-Spark-WordCount