原文链接:
http://www.eygle.com/special/NLS_CHARACTER_SET_05.htm
** 原文发表于itpub技术丛书《Oracle数据库DBA专题技术精粹》,未经许可,严禁转载本文. **
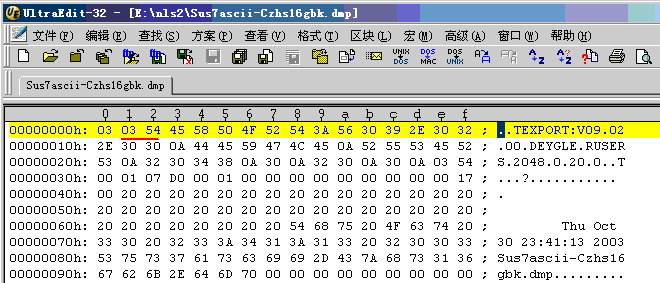
我们知道在导出文件中,记录着导出使用的字符集id,通过查看导出文件头的第2、3个字节,我们可以找到16进制表示的字符集ID,在Windows上,
我们可以使用UltraEdit等工具打开dmp文件,查看其导出字符集::
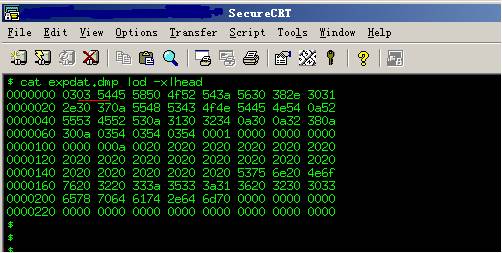
在Unix上我们可以通过以下命令来查看:
> > cat expdat.dmp | od -x | head >
Oracle提供标准函数,对字符集名称及ID进行转换:
>
>
> SQL> select nls_charset_id('ZHS16GBK') from dual;
>
> NLS_CHARSET_ID('ZHS16GBK')
> --------------------------
> 852
>
> 1 row selected.
>
> SQL> select nls_charset_name(852) from dual;
>
> NLS_CHAR
> --------
> ZHS16GBK
>
> 1 row selected.
>
> 十进制转换十六进制:
>
> SQL> select to_char('852','xxxx') from dual;
>
> TO_CH
> -----
> 354
>
> 1 row selected.
>
对应上面的图中第2、3字节,我们知道该导出文件字符集为ZHS16GBk.
查询数据库中有效的字符集可以使用以下脚本:
>
>
> col nls_charset_id for 9999
> col nls_charset_name for a30
> col hex_id for a20
> select
> nls_charset_id(value) nls_charset_id,
> value nls_charset_name,
> to_char(nls_charset_id(value),'xxxx') hex_id
> from v$nls_valid_values
> where parameter = 'CHARACTERSET'
> order by nls_charset_id(value)
> /
>
输出样例如下:
>
>
> NLS_CHARSET_ID NLS_CHARSET_NAME HEX_ID
> > -------------- ------------------------------ -------------
> > 1 US7ASCII 1
> > 2 WE8DEC 2
> > 3 WE8HP 3
> > 4 US8PC437 4
> > 5 WE8EBCDIC37 5
> > 6 WE8EBCDIC500 6
> > 7 WE8EBCDIC1140 7
> > 8 WE8EBCDIC285 8
> > ...................
> > 850 ZHS16CGB231280 352
> > 851 ZHS16MACCGB231280 353
> > 852 ZHS16GBK 354
> > 853 ZHS16DBCS 355
> > 860 ZHT32EUC 35c
> > 861 ZHT32SOPS 35d
> > 862 ZHT16DBT 35e
> > 863 ZHT32TRIS 35f
> > 864 ZHT16DBCS 360
> > 865 ZHT16BIG5 361
> > 866 ZHT16CCDC 362
> > 867 ZHT16MSWIN950 363
> > 868 ZHT16HKSCS 364
> > 870 AL24UTFFSS 366
> > 871 UTF8 367
> > 872 UTFE 368
>
> ..................................
>
>
>
在很多时候,当我们进行导入操作的时候,已经离开了源数据库,这时如果目标数据库的字符集和导出文件不一致,很多时候就需要进行特殊处理,
以下介绍几种方法,主要以US7ASCII和ZHS16GBK为例
1. 源数据库字符集为US7ASCII,导出文件字符集为US7ASCII或ZHS16GBK,目标数据库字符集为ZHS16GBK
在Oracle92中,我们发现对于这种情况,不论怎样处理,这个导出文件都无法正确导入到Oracle9i数据库中,这可能是因为Oracle9i的编码方案发生了较大改变。
以下是我们所做的简单测试,其中导出文件命名规则为:
S-Server ,后跟Server字符集
C-client , 后跟导出操作时客户端字符集
导入时客户端字符集设置在命令行完成,限于篇幅,我们省略了部分测试过程。
对于Oracle9iR2,我们的测试结果是US7ASCII字符集,不管怎样转换,都无法正确导入ZHS16GBK字符集的数据库中。
在进行导入操作时,如果字符不能正常转换,Oracle数据库会自动用一个”?”代替,也就是编码63。
>
>
> E:\nls2>set NLS_LANG=AMERICAN_AMERICA.US7ASCII
>
> E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle tables=test
>
> Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:14:39 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Export file created by EXPORT:V09.02.00 via conventional path
> import done in US7ASCII character set and AL16UTF16 NCHAR character set
> import server uses ZHS16GBK character set (possible charset conversion)
> . . importing table "TEST" 2 rows imported
> Import terminated successfully without warnings.
>
> E:\nls2>sqlplus eygle/eygle
>
> SQLPlus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:14:50 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select name,dump(name) from test;
>
> NAME DUMP(NAME)
> -----------------------------
> ???? Typ=1 Len=4: 63,63,63,63
> test Typ=1 Len=4: 116,101,115,116
>
> 2 rows selected.
>
> SQL> exit
> Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> E:\nls2> set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
>
> E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle tables=test ignore=y
>
> Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:15:28 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Export file created by EXPORT:V09.02.00 via conventional path
> import done in ZHS16GBK character set and AL16UTF16 NCHAR character set
> export client uses US7ASCII character set (possible charset conversion)
> . . importing table "TEST" 2 rows imported
> Import terminated successfully without warnings.
>
> E:\nls2>sqlplus eygle/eygle
>
> SQLPlus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:15:34 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select name,dump(name) from test;
>
> NAME DUMP(NAME)
> --------------------------------------------------------------------------------
> ???? Typ=1 Len=4: 63,63,63,63
> test Typ=1 Len=4: 116,101,115,116
> ???? Typ=1 Len=4: 63,63,63,63
> test Typ=1 Len=4: 116,101,115,116
>
>
> 4 rows selected.
>
> SQL> drop table test;
>
> Table dropped.
>
> SQL> exit
> Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> E:\nls2> set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
>
> E:\nls2>imp eygle/eygle file=Sus7ascii-Czhs16gbk.dmp fromuser=eygle touser=eygle tables=test ignore=y
>
> Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:17:21 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Export file created by EXPORT:V09.02.00 via conventional path
> import done in ZHS16GBK character set and AL16UTF16 NCHAR character set
> . . importing table "TEST" 2 rows imported
> Import terminated successfully without warnings.
>
> E:\nls2>sqlplus eygle/eygle
>
> SQLPlus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:17:30 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select name,dump(name) from test;
>
> NAME DUMP(NAME)
> ----------------------------------------------
> ???? Typ=1 Len=4: 63,63,63,63
> test Typ=1 Len=4: 116,101,115,116
>
> 2 rows selected.
>
> SQL> exit
> Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> E:\nls2> set NLS_LANG=AMERICAN_AMERICA.US7ASCII
>
> E:\nls2>imp eygle/eygle file=Sus7ascii-Czhs16gbk.dmp fromuser=eygle touser=eygle tables=test ignore=y
>
> Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:18:00 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Export file created by EXPORT:V09.02.00 via conventional path
> import done in US7ASCII character set and AL16UTF16 NCHAR character set
> import server uses ZHS16GBK character set (possible charset conversion)
> export client uses ZHS16GBK character set (possible charset conversion)
> . . importing table "TEST" 2 rows imported
> Import terminated successfully without warnings.
>
> E:\nls2>sqlplus eygle/eygle
>
> SQLPlus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:18:08 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select name,dump(name) from test;
>
> NAME DUMP(NAME)
> ----------------------------------------
> ???? Typ=1 Len=4: 63,63,63,63
> test Typ=1 Len=4: 116,101,115,116
> ???? Typ=1 Len=4: 63,63,63,63
> test Typ=1 Len=4: 116,101,115,116
>
> 4 rows selected.
>
> SQL>
>
>
对于这种情况,我们可以通过使用Oracle8i的导出工具,设置导出字符集为US7ASCII,导出后修改第二、三字符,修改 0001 为
0354,这样就可以将US7ASCII字符集的数据正确导入到ZHS16GBK的数据库中。
修改导出文件:
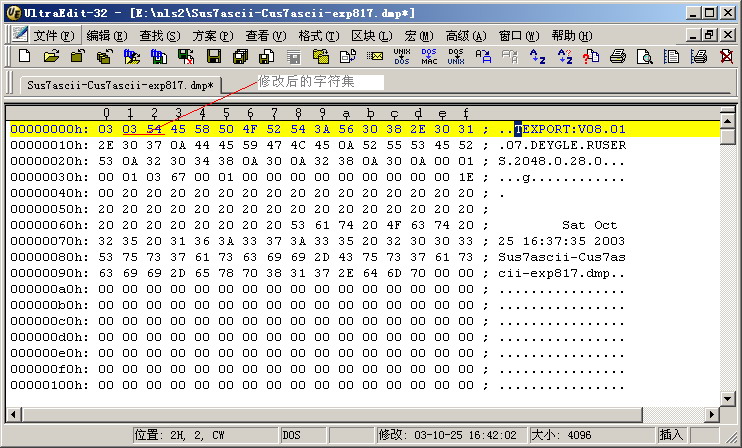
导入修改后的导出文件:
>
>
> E:\nls2>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
>
> E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii-exp817.dmp fromuser=eygle touser=eygle tables=test
>
> Import: Release 9.2.0.4.0 - Production on Mon Nov 3 17:37:17 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Export file created by EXPORT:V08.01.07 via conventional path
> import done in ZHS16GBK character set and AL16UTF16 NCHAR character set
> export server uses UTF8 NCHAR character set (possible ncharset conversion)
> . . importing table "TEST" 2 rows imported
> Import terminated successfully without warnings.
>
> E:\nls2>sqlplus eygle/eygle
>
> SQL*Plus: Release 9.2.0.4.0 - Production on Mon Nov 3 17:37:23 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select name,dump(name) from test;
>
> NAME DUMP(NAME)
> --------------------------------------------------------------------------------
> 测试 Typ=1 Len=4: 178,226,202,212
> Test Typ=1 Len=4: 116,101,115,116
>
> 2 rows selected.
>
> SQL>
>
2. 使用create database的方法
如果导出文件使用的字符集是US7ASCII,目标数据库的字符集是ZHS16GBK,我们可以使用create database的方法来修改,具体如下:
>
>
> SQL> col parameter for a30
> SQL> col value for a30
> SQL> select * from v$nls_parameters;
>
> PARAMETER VALUE
> ------------------------------ ------------------------------
> NLS_LANGUAGE AMERICAN
> NLS_TERRITORY AMERICA
> NLS_CURRENCY $
> NLS_ISO_CURRENCY AMERICA
> NLS_NUMERIC_CHARACTERS .,
> NLS_CALENDAR GREGORIAN
> NLS_DATE_FORMAT DD-MON-RR
> NLS_DATE_LANGUAGE AMERICAN
> NLS_CHARACTERSET ZHS16GBK
> NLS_SORT BINARY
> ……………….
>
> 19 rows selected.
>
> SQL> create database character set us7ascii;
> create database character set us7ascii
> *
> ERROR at line 1:
> ORA-01031: insufficient privileges
>
>
> SQL> select * from v$nls_parameters;
>
> PARAMETER VALUE
> ------------------------------ ------------------------------
> NLS_LANGUAGE AMERICAN
> NLS_TERRITORY AMERICA
> NLS_CURRENCY $
> NLS_ISO_CURRENCY AMERICA
> NLS_NUMERIC_CHARACTERS .,
> NLS_CALENDAR GREGORIAN
> NLS_DATE_FORMAT DD-MON-RR
> NLS_DATE_LANGUAGE AMERICAN
> NLS_CHARACTERSET US7ASCII
> NLS_SORT BINARY
> …………..
>
> 19 rows selected.
>
> SQL> exit
> Disconnected from Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> E:\nls2> set nls_lang=AMERICAN_AMERICA.US7ASCII
>
> E:\nls2>imp eygle/eygle file=Sus7ascii-Cus7ascii.dmp fromuser=eygle touser=eygle
>
> Import: Release 9.2.0.4.0 - Production on Sun Nov 2 14:53:26 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to: Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Export file created by EXPORT:V09.02.00 via conventional path
> import done in US7ASCII character set and AL16UTF16 NCHAR character set
> import server uses ZHS16GBK character set (possible charset conversion)
> . . importing table "TEST" 2 rows imported
> Import terminated successfully without warnings.
>
> E:\nls2>sqlplus eygle/eygle
>
> SQL*Plus: Release 9.2.0.4.0 - Production on Sun Nov 2 14:53:35 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select * from test;
>
> NAME
> ----------
> 测试
> test
>
> 2 rows selected.
>
>
我们看到,当发出 create database character set us7ascii ; 命令时,数据库v$nls_parameters中的字符集设置随之更改,该参数影响导入进程,
更改后可以正确导入数据,重起数据库后,该设置恢复。
提示:v$nls_paraemters来源于x$nls_parameters,该动态性能视图影响导入操作;而nls_database_parameters来源于props$数据表,影响数据存储。
3. Oracle提供的字符扫描工具csscan
我们说以上的方法只是应该在不得已的情况下使用,其本质是欺骗数据库,强制导入数据,可能损失元数据。
如果要确保数据的完整性,应该使用csscan扫描数据库,找出所有不兼容的字符,然后通过编写相应的脚本及代码,在转换之后进行更新,确保数据的正确性。
我们简单看一下csscan的使用。
要使用csscan之前,需要以sys用户身份创建相应数据字典对象:
>
>
> E:\nls2>sqlplus "/ as sysdba"
>
> SQL*Plus: Release 9.2.0.4.0 - Production on Sun Nov 2 19:42:07 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> SQL> select instance_name from v$intance;
> select instance_name from v$intance
> *
> ERROR at line 1:
> ORA-00942: table or view does not exist
>
>
> SQL> select instance_name from v$instance;
>
> INSTANCE_NAME
> ----------------
> penny
>
> 1 row selected.
>
> SQL> @?/rdbms/admin/csminst.sql
>
> User created.
>
>
> Grant succeeded.
>
> ………..
>
>
这个脚本创建相应用户(csmig)及数据字典对象,扫描信息会记录在相应的数据字典表里。
我们可以在命令行调用这个工具对数据库进行扫描:
>
>
> E:\nls2>csscan FULL=Y FROMCHAR=ZHS16GBK TOCHAR=US7ASCII LOG=US7check.log CAPTURE=Y ARRAY=1000000 PROCESS=2
>
>
> Character Set Scanner v1.1 : Release 9.2.0.1.0 - Production on Sun Nov 2 20:24:45 2003
>
> Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
>
>
> Username: eygle/eygle
>
> Connected to:
> Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
> With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
> JServer Release 9.2.0.4.0 - Production
>
> Enumerating tables to scan...
>
> . process 1 scanning SYS.SOURCE$[AAAABHAABAAAAIRAAA]
> . process 2 scanning SYS.ATTRIBUTE$[AAAAEoAABAAAAhZAAA]
> . process 2 scanning SYS.PARAMETER$[AAAAEoAABAAAAhZAAA]
> . process 2 scanning SYS.METHOD$[AAAAEoAABAAAAhZAAA]
> ……..
> . process 2 scanning SYSTEM.DEF$_AQERROR[AAAA8fAABAAACWJAAA]
> . process 1 scanning WMSYS.WM$ENV_VARS[AAABeWAABAAAFMZAAA]
> ………………….
> . process 2 scanning SYS.UGROUP$[AAAAA5AABAAAAGpAAA]
> . process 2 scanning SYS.CON$[AAAAAcAABAAAACpAAA]
> . process 1 scanning SYS.FILE$[AAAAARAABAAAABxAAA]
>
> Creating Database Scan Summary Report...
>
> Creating Individual Exception Report...
>
> Scanner terminated successfully.
>
然后我们可以检查输出的日志来查看数据库扫描情况:
>
>
> Database Scan Individual Exception Report
>
>
> [Database Scan Parameters]
>
> Parameter Value
> ------------------------------ ------------------------------------------------
> Scan type Full database
> Scan CHAR data? YES
> Current database character set ZHS16GBK
> New database character set US7ASCII
> Scan NCHAR data? NO
> Array fetch buffer size 1000000
> Number of processes 2
> Capture convertible data? YES
> ------------------------------ ------------------------------------------------
>
> [Data Dictionary individual exceptions]
>
>
> [Application data individual exceptions]
>
> User : EYGLE
> Table : TEST
> Column: NAME
> Type : VARCHAR2(10)
> Number of Exceptions : 1
> Max Post Conversion Data Size: 4
>
> ROWID Exception Type Size Cell Data(first 30 bytes)
> ------------------ ------------------ ----- ------------------------------
> AAABpIAADAAAAAMAAA lossy conversion 测试
> ------------------ ------------------ ----- ------------------------------
>
不能转换的数据将会被记录下来,我们可以根据这些信息在转换之后,对数据进行相应的更新,确保转换无误。